φ€Ä‰qëι¹΅εàνCΗÄδΗΣεΨàεΞ΅φÄΣγö³ι½°ιΔ‰εQ¨εÜôδΚÜδΗÄδΗΣγï¨ιùΔγ®΄εΚèοΦ¨εàöεΦÄεß΄φ≤Γφ€?η°³ΓΫ°ε≠½δΫ™εQ¨φïàγé΅ηΩ‰εè·δΜΞεQ¨δΫÜφ‰·ιΜ‰η°Λε≠½δۙ〴γùÄφ·îηΨÉιö³Γ€΄εQ¨εΑ±φîΙγî®δΚÜδΗÄδΗΣε≠½δΫ™οΦ¨ηΑ¹γüΞι¹™ε€®jdk1.4φâöw΅è΄Ι΄η·ï‰q΅γ®΄δΗ≠οΦ¨φïàγé΅ε±Öγ³Εφ·îεéüφùΞηΠ¹δΫéιùûεΗîRùûεΗΗγö³εΛöψÄ?br /> εêéφùΞεèëγéΑεΠ²φû€φ‰·jdk1.5εèäδΜΞδΗäγâàφ€§δΗΛηÄÖφïàγé΅ε΅†δΙéδΗÄφ†χPΦ¨ηß¹ιô³δΜΕφàΣε¦ΨψÄ?br /> ηĨδΗîû°±Swingφïàγé΅ε£¨εΔûεΦΚεäüηÉΫφùΞη°‘¨Φ¨JDK1.6u10εèäδΜΞδΗäγâàφ€§φ€âιùûεΗΗεΛßγö³φèêιΪ‰εQ?br /> φâÄδΜΞεΠ²φû€φùΓδΜΕηΩêηΓ¨οΦ¨‰q‰φ‰·εΜχô°°ιÉΫφîΙφàêJDK1.6u10εèäδΜΞδΗäγâàφ€?/font>
΄Ι΄η·ïδΜΘγ†¹εΠ²δΗ΄:

 public class FontDemo extends JPanel {
public class FontDemo extends JPanel {


 public static void main(String[] args) {
public static void main(String[] args) { JFrame f = new JFrame(); f.setTitle("TWaverδΗ≠φ•΅ΫCë÷¨Κ"); f.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE); f.setContentPane(new FontDemo()); f.setSize(800, 600); f.setLocationRelativeTo(null); f.setVisible(true);
JFrame f = new JFrame(); f.setTitle("TWaverδΗ≠φ•΅ΫCë÷¨Κ"); f.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE); f.setContentPane(new FontDemo()); f.setSize(800, 600); f.setLocationRelativeTo(null); f.setVisible(true);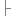 } private TDataBox box = new TDataBox(); private BarChart chart = new BarChart(box); private static final int times = 1000; private static final int style = Font.BOLD; private static final int size = 16; public FontDemo() { initBox(); initChart(); initGUI(); } private void initGUI() { this.setLayout(new BorderLayout()); JScrollPane pane = new JScrollPane(chart.getLegendPane()); this.add(chart, BorderLayout.CENTER); this.add(pane, BorderLayout.EAST); } private void initBox() { final List localFonts = new ArrayList(); List nativeFonts = new ArrayList(); // get all available fontFamily names Font[] fonts = SunGraphicsEnvironment.getLocalGraphicsEnvironment().getAllFonts(); for (int i = 0; i < fonts.length; i++) { // separate logical and native font if (SunGraphicsEnvironment.isLogicalFont(fonts[i])) { localFonts.add(fonts[i]); } else { nativeFonts.add(fonts[i]); } } System.out.println("///////////// localFonts test /////////////"); for (int i = 0; i < localFonts.size(); i++) { Font font = (Font) localFonts.get(i); long start = System.currentTimeMillis(); for (int k = 0; k < times; k++) { createFont(font); } long spendTime = System.currentTimeMillis() - start; Node n = new Node(); n.setName(font.getName()); n.putChartValue(spendTime); n.putChartColor(Color.GREEN); box.addElement(n); // System.out.println(">" + spendTime + "\t" + font.getName()); } System.out.println("\n///////////// nativeFonts test /////////////"); for (int i = 0; i < nativeFonts.size(); i++) { Font font = (Font) nativeFonts.get(i); long start = System.currentTimeMillis(); for (int k = 0; k < times; k++) { createFont(font); } long spendTime = System.currentTimeMillis() - start; Node n = new Node(); n.setName(font.getName()); n.putChartValue(spendTime); n.putChartColor(Color.RED); box.addElement(n); // System.out.println(">" + spendTime + "\t" + font.getName()); } System.out.println("\n$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$\n"); } private void createFont(Font font) { // font.deriveFont(style, size); new Font(font.getName(), style, size); } private void initChart() { chart.setLegendLayout(TWaverConst.LEGEND_LAYOUT_VERTICAL); chart.setLegendOrientation(TWaverConst.LABEL_ORIENTATION_HORIZONTAL); chart.setYScaleTextVisible(true); chart.setShadowOffset(1); }
} private TDataBox box = new TDataBox(); private BarChart chart = new BarChart(box); private static final int times = 1000; private static final int style = Font.BOLD; private static final int size = 16; public FontDemo() { initBox(); initChart(); initGUI(); } private void initGUI() { this.setLayout(new BorderLayout()); JScrollPane pane = new JScrollPane(chart.getLegendPane()); this.add(chart, BorderLayout.CENTER); this.add(pane, BorderLayout.EAST); } private void initBox() { final List localFonts = new ArrayList(); List nativeFonts = new ArrayList(); // get all available fontFamily names Font[] fonts = SunGraphicsEnvironment.getLocalGraphicsEnvironment().getAllFonts(); for (int i = 0; i < fonts.length; i++) { // separate logical and native font if (SunGraphicsEnvironment.isLogicalFont(fonts[i])) { localFonts.add(fonts[i]); } else { nativeFonts.add(fonts[i]); } } System.out.println("///////////// localFonts test /////////////"); for (int i = 0; i < localFonts.size(); i++) { Font font = (Font) localFonts.get(i); long start = System.currentTimeMillis(); for (int k = 0; k < times; k++) { createFont(font); } long spendTime = System.currentTimeMillis() - start; Node n = new Node(); n.setName(font.getName()); n.putChartValue(spendTime); n.putChartColor(Color.GREEN); box.addElement(n); // System.out.println(">" + spendTime + "\t" + font.getName()); } System.out.println("\n///////////// nativeFonts test /////////////"); for (int i = 0; i < nativeFonts.size(); i++) { Font font = (Font) nativeFonts.get(i); long start = System.currentTimeMillis(); for (int k = 0; k < times; k++) { createFont(font); } long spendTime = System.currentTimeMillis() - start; Node n = new Node(); n.setName(font.getName()); n.putChartValue(spendTime); n.putChartColor(Color.RED); box.addElement(n); // System.out.println(">" + spendTime + "\t" + font.getName()); } System.out.println("\n$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$\n"); } private void createFont(Font font) { // font.deriveFont(style, size); new Font(font.getName(), style, size); } private void initChart() { chart.setLegendLayout(TWaverConst.LEGEND_LAYOUT_VERTICAL); chart.setLegendOrientation(TWaverConst.LABEL_ORIENTATION_HORIZONTAL); chart.setYScaleTextVisible(true); chart.setShadowOffset(1); }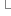 }
}
1.4΄Ι΄η·ïΨl™φû€
1.6΄Ι΄η·ïΨl™φû€
long total = runtime.totalMemory();
long free = runtime.freeMemory();
System.out.println(total+"-"+free);
totalMemory()
/**
* Returns the total amount of memory in the Java virtual machine.
* The value returned by this method may vary over time, depending on
* the host environment.
* <p>
* Note that the amount of memory required to hold an object of any
* given type may be implementation-dependent.
*
* @return the total amount of memory currently available for current
* and future objects, measured in bytes.
*/
freeMemory()
/**
* Returns the amount of free memory in the Java Virtual Machine.
* Calling the
* <code>gc</code> method may result in increasing the value returned
* by <code>freeMemory.</code>
*
* @return an approximation to the total amount of memory currently
* available for future allocated objects, measured in bytes.
*/
ιÄöηΩ΅‰qôδΗΣφ•“é≥ïεQ¨εè·δΜΞεÜôδΗÄδΗΣγ±ΜδΦιgΚéWindowsδΜ’däΓΫéΓγêÜεô®γö³ιùΔφùΩεQ?br />
Reflect&Proxy are two functions provided by java,
Following is some example about how to use it.
1.Reflect
By reflect, the Class instance can be created, not using 'new' method
as following:
(1)Creating the class instance:
Class clazz = Class.forName("twaver.Node");//Node.class;
Constructor cs = clazz.getConstructor(new Class[] { Object.class });
Object object = cs.newInstance(new Object[] { "ID-679" });
@param parameterTypes the parameter array
new Class[] { Object.class }
means that the process will use the construcor
which has one parameter to create the class instance.
cs.newInstance method will create the class instance with the parameter "new Object[] { "ID-679" }"
(2)Getting the class method:
Method getIDMethod = clazz.getMethod("getID", new Class[] {});
Method setNameMethod = clazz.getMethod("setName", new Class[] { String.class });
@param name the name of the method
@param parameterTypes the list of parameters
setNameMethod.invoke(object, new Object[] { "todd.zhang" });
Invokes the setNameMthod of object instance with the parameter new Object[] { "todd.zhang" }
public static void main(String[] args) throws Exception {
Node node = new Node("ID-679");
node.setName("todd.zhang");
System.out.println(node.getID());
System.out.println(node.getName());
System.out.println("-----------------------");
Class clazz = Class.forName("twaver.Node");//Node.class;
Constructor cs = clazz.getConstructor(new Class[] { Object.class });
Method getIDMethod = clazz.getMethod("getID", new Class[] {});
Method setNameMethod = clazz.getMethod("setName", new Class[] { String.class });
Method getNameMethod = clazz.getMethod("getName", new Class[] {});
Object object = cs.newInstance(new Object[] { "ID-679" });
setNameMethod.invoke(object, new Object[] { "todd.zhang" });
System.out.println(getIDMethod.invoke(object, new Object[] {}));
System.out.println(getNameMethod.invoke(object, new Object[] {}));
}
}
2.Proxy
Proxy is an application of reflect function.
ClassLoader classLoader = ProxyAnything.class.getClassLoader();
Class[] interfaces = new Class[] { Interface_A.class, Interface_B.class };
//the interface array that the proxy will realize
InvocationHandler handler = new ProxyAnything();
//the handler of the proxy , each invoked method of Interface_A and Interface_B will be hold up by handler
//the method invoke will turn to the handler first, and hanlder will deside how to deal with the invoke.
Proxy proxy = (Proxy) Proxy.newProxyInstance(classLoader, interfaces, handler);
//it is like the implement of interface ,so it can be transform to interface compulsively.
proxy instanceof Interface_A will be true
Interface_A a = (Interface_A) proxy;
Interface_B b = (Interface_B) proxy;
a.do_A1();
b.do_B2();
InvocationHandler may proxy sereval class,
public Object invoke(Object proxy, Method m, Object[] args) throws Throwable
the proxy can be used to judge which it is.
the proxy just is a rind, each operation will be deal with hanlder
interface Interface_A {
public void do_A1();
public void do_A2();
public void do_A3();
}
interface Interface_B {
public void do_B1();
public void do_B2();
public void do_B3();
}
public class ProxyAnything implements InvocationHandler {
private Interface_A businessA;
private Interface_B businessB;
public ProxyAnything() {
this.businessA = new Interface_A() {
public void do_A1() {
System.out.println("doing A1");
}
public void do_A2() {
System.out.println("doing A2");
}
public void do_A3() {
System.out.println("doing A3");
}
};
this.businessB = new Interface_B() {
public void do_B1() {
System.out.println("doing B1");
}
public void do_B2() {
System.out.println("doing B2");
}
public void do_B3() {
System.out.println("doing B3");
}
};
}
public Object invoke(Object proxy, Method m, Object[] args) throws Throwable {
if (m.getDeclaringClass() == Interface_A.class) {
if (m.getName().equals("do_A3")) {
System.out.println("you can not invoke do_A3");
} else {
return m.invoke(this.businessA, args);
}
}
if (m.getDeclaringClass() == Interface_B.class) {
System.out.println(m.getName() + " is called.");
return m.invoke(this.businessB, args);
}
return null;
}
public static void main(String[] args) throws Exception {
ClassLoader classLoader = ProxyAnything.class.getClassLoader();
Class[] interfaces = new Class[] { Interface_A.class, Interface_B.class };
InvocationHandler handler = new ProxyAnything();
Proxy proxy = (Proxy) Proxy.newProxyInstance(classLoader, interfaces, handler);
if (proxy instanceof Interface_A) {
System.out.println("proxy instanceof Interface_A");
}
if (proxy instanceof Interface_B) {
System.out.println("proxy instanceof Interface_B");
}
Interface_A a = (Interface_A) proxy;
Interface_B b = (Interface_B) proxy;
a.do_A1();
a.do_A2();
a.do_A3();
b.do_B1();
b.do_B2();
b.do_B3();
}
}
(ηΫ?
φ€§φ•΅ιΠ•εÖàδΜ΄γΜçδΚÜLuceneγö³δΗÄδΚ¦εüΚφ€§φΠ²εΩΒοΦ¨γ³ΕεêéεΦÄεèëδΚÜδΗÄδΗΣεΚîγî®γ®΄εΚèφΦîΫCόZΚÜεà©γî®LuceneεΜΚγΪ΄γ¥ΔεΦïρqΕε€®η·ΞγÉΠεΦïδΗä‰q¦ηΓ¨φê€γÉΠγö³ηΩ΅ΫE΄ψÄ?/span>
Lucene φ‰·δΗÄδΗΣεüΚδΚ?Java γö³εÖ®φ•΅δΩΓφ¹·φΘÄγ¥ΔεΖΞεÖΖε¨ÖεQ¨ε°ÉδΗçφ‰·δΗÄδΗΣε°¨φï¥γö³φê€γÉΠεΚîγî®ΫE΄εΚèεQ¨ηĨφ‰·δΗόZΫ†γö³εΚîγî®γ®΄εΚèφèêδΨ¦γÉΠεΦï壨φê€γÉΠεäüηÉΫψIJLucene γ¦°εâçφ‰?Apache Jakarta ε°Εφ½èδΗ≠γö³δΗÄδΗΣεΦÄφΚêιΓΙγ¦°ψIJδΙüφ‰·γ¦°εâçφ€ÄδΗΚφΒ¹ηΓ¨γö³εüόZΚé Java εΦÄφΚêεÖ®φ•΅φΘÄγ¥ΔεΖΞεÖΖε¨ÖψÄ?/span>
γ¦°εâçεΖ≤γΜèφ€âεΨàεΛöεΚîγî®γ®΄εΚèγö³φê€γÉΠεäüηÉΫφ‰·εüΚδΚ?Lucene γö³οΦ¨φ·îεΠ² Eclipse γö³εΗ°εä©γ≥ΜΨlüγö³φê€γÉΠεäüηÉΫψIJLucene ηÉΫεΛüδΗΚφ•΅φ€§γ±Μεû΄γö³φïΑφç°εΜΚγΪ΄γ¥ΔεΦïεQ¨φâÄδΜΞδΫ†εèΣηΠ¹ηÉΫφääδΫ†ηΠ¹γ¥ΔεΦïγö³φïΑφç°φ†ΦεΦèηù{娕γö³φ•΅φ€§γö³οΦ¨Lucene û°όpÉΫε·ΙδΫ†γö³φ•΅φΓΘηΩ¦ηΓ¨γÉΠεΦï壨φê€γÉΠψIJφ·îεΠ²δΫ†ηΠ¹ε·ΙδΗÄδΚ?HTML φ•΅φΓΘεQ¨PDF φ•΅φΓΘ‰q¦ηΓ¨γ¥ΔεΦïγö³η·ùδΫ†εΑ±ιΠ•εÖàι€ÄηΠ¹φää HTML φ•΅φΓΘε£?PDF φ•΅φΓΘηۧ娕φàêφ•΅φ€§φ†ΦεΦèγö³εQ¨γ³ΕεêéεΑÜηۧ娕εêéγö³εÜÖε°ΙδΚΛγΜô Lucene ‰q¦ηΓ¨γ¥ΔεΦïεQ¨γ³Εεêéφääεà¦εΨèεΞΫγö³γ¥ΔεΦïφ•΅δögδΩùε≠‰εàΑγΘ¹γ¦‰φà•ηÄÖεÜÖε≠‰δΗ≠εQ¨φ€Äεêéφ†Ιφç°γî®φà·²Ψ™εÖΞγö³φüΞη·ΔφùΓδögε€®γÉΠεΦïφ•΅δΜΕδΗä‰q¦ηΓ¨φüΞη·ΔψIJδΗçφ¨΅ε°öηΠ¹γÉΠεΦïγö³φ•΅φΓΘγö³φ†ΦεΦèδΙüδΫ?Lucene ηÉΫεΛü塆δΙéιIJγî®δΚéφâÄφ€âγö³φê€γÉΠεΚîγî®ΫE΄εΚèψÄ?/span>
ε¦?1 ηΓ®γΛΚδΚÜφê€γ¥ΔεΚîγî®γ®΄εΚè壨 Lucene δΙ΄ι½¥γö³εÖ≥ΨpΜοΦ¨δΙüεèçφ‰†δΚÜεà©γî® Lucene φû³εΨèφê€γÉΠεΚîγî®ΫE΄εΚèγö³φΒ¹ΫE΄οΦö
ε¦?. φê€γÉΠεΚîγî®ΫE΄εΚèε£?Lucene δΙ΄ι½¥γö³εÖ≥Ψp?/span>
γ¥ΔεΦïφ‰·γéΑδΜΘφê€γ¥ΔεΦïφ™éγö³φ†ΗεΩÉεQ¨εΨèγΪ΄γÉΠεΦïγö³‰q΅γ®΄û°±φ‰·φääφΚêφïΑφç°εΛ³γêÜφàêιùûεΗΗφ•ΙδΨΩφüΞη·Δγö³γ¥ΔεΦïφ•΅δögγö³ηΩ΅ΫE΄ψÄ²δΊ™δΜÄδΙàγÉΠεΦïηΩôδΙàι΅çηΠ¹εëΔεQ¨η·ïφÉ≥δΫ†γéΑε€®ηΠ¹ε€®εΛßι΅èγö³φ•΅φΓΘδΗ≠φê€γÉΠεêΪφ€âφüêδΗΣεÖ≥ιî°η·çγö³φ•΅φΓΘεQ¨ι²ΘδΙàεΠ²φû€δΗçεΜΚγΪ΄γ¥ΔεΦïγö³η·ùδΫ†εΑ±ι€ÄηΠ¹φää‰qôδΚ¦φ•΅φΓΘôεΚεΚèγö³η·ΜεÖΞεÜÖε≠‰οΦ¨γ³Εεêé΄²ÄφüΞηΩôδΗΣφ•΅γΪ†δΗ≠φ‰·δΗçφ‰·εêΪφ€âηΠ¹φüΞφâΨγö³εÖ≥ιî°η·çεQ¨ηΩôφ†οLö³η·ùεΑ±δΦöηĽη¥ΙιùûεΗΗεΛöγö³φ½âô½¥εQ¨φÉ≥φÉœxê€γ¥ΔεΦïφ™éεè·φ‰·ε€®φ·ΪγߣΨUßγö³φ½âô½¥εÜÖφüΞφâë÷΅ΚηΠ¹φê€γ¥Δγö³Ψl™φû€γö³ψIJηΩôû°±φ‰·γîΉÉΚéεΜΚγΪ΄δΚÜγÉΠεΦïγö³εéü妆εQ¨δΫ†εè·δΜΞφääγÉΠεΦïφÉ≥η±Γφàê‰qôφ†ΖδΗÄΩUçφïΑφç°γΜ™φû³οΦ¨δΜ•ηÉΫεΛüδ΄…δΫ†εΩΪιÄüγö³ιöèφ€Κη°âK½°ε≠‰ε²®ε€®γÉΠεΦïδΗ≠γö³εÖ≥ιî°η·çεQ¨ηΩ¦ηĨφâΨεàΑη·ΞεÖ≥ιî°η·çφâÄεÖ¨ô¹îγö³φ•΅φΓΘψIJLucene ι΅΅γî®γö³φ‰·δΗÄΩUçγßΑδΗΚεèçεêëγÉΠεΦïοΦàinverted indexεQâγö³φ€ΚεàΕψIJεèçεêëγÉΠεΦïεΑ±φ‰·η·¥φàëδΜ§Ψl¥φäΛδΚÜδΗÄδΗΣη·ç/γü≠η·≠ηΓ®οΦ¨ε·ΙδΚé‰qôδΗΣηΓ®δΗ≠γö³φ·èδΗΣη·ç/γü≠η·≠εQ¨ιÉΫφ€âδΗÄδΗΣι™ΨηΓ®φèè‰qνCΚÜφ€âε™ΣδΚ¦φ•΅φΓΘε¨ÖεêΪδΚ܉qôδΗΣη·?γü≠η·≠ψIJηΩôφ†Ζε€®γî®φàΖηΨ™εÖΞφüΞη·ΔφùΓδögγö³φ½ΕεÄôοΦ¨û°όpÉΫιùûεΗΗεΩΪγö³εΨ½εàΑφê€γÉΠΨl™φû€ψIJφàëδΜ§εΑÜε€®φ€§Ψp’dà½φ•΅γΪ†γö³γ§§δΚ¨ιÉ®εàÜη·ΠΨlÜδΜ΄Ψl?Lucene γö³γÉΠεΦïφ€Κεà”ûΦ¨γîΉÉΚé Lucene φèêδΨ¦δΚÜγ°Äεçïφ‰™γî®γö³ APIεQ¨φâÄδΜΞεç≥δΫΩη·ΜηÄÖεàöεΦÄεß΄ε·ΙεÖ®φ•΅φ€§ηΩ¦ηΓ¨γÉΠεΦïγö³φ€ΚεàΕρqΕδΗçεΛΣδΚÜηßΘοΦ¨δΙüεè·δΜΞιùûεΗΗε°Ιφ‰™γö³δΫΩγî® Lucene ε·ΙδΫ†γö³φ•΅φΓΘε°ûγéΑγÉΠεΦïψÄ?/span>
ε·“é•΅φΓΘεΨèγΪ΄εΞΫγ¥ΔεΦïεêéοΦ¨û°±εè·δΜΞε€®‰qôδΚ¦γ¥ΔεΦïδΗäιùΔ‰q¦ηΓ¨φê€γÉΠδΚÜψIJφê€γ¥ΔεΦïφ™éιΠ•εÖàδΦöε·“éê€γ¥Δγö³εÖ≥ιî°η·çηΩ¦ηΓ¨ηßΘφûêοΦ¨γ³ΕεêéεÜçε€®εΜΚγΪ΄εΞΫγö³γ¥ΔεΦïδΗäιùΔ‰q¦ηΓ¨φüΞφâΨεQ¨φ€ÄΨlàηΩîε¦û壨γî®φàΖηΨ™εÖΞγö³εÖ≥ιî°η·çγ¦ΗεÖ≥η¹îγö³φ•΅φΓΘψÄ?/span>
Lucene ηΫ·δögε¨Öγö³εèëεΗÉεΫΔεΦèφ‰·δΗÄδΗ?JAR φ•΅δögεQ¨δΗ΄ιùΔφàëδΜ§εàÜφûêδΗÄδΗ΄ηΩôδΗ?JAR φ•΅δög顨ιùΔγö³δΗΜηΠ¹γö³ JAVA ε¨ÖοΦ¨δΫΩη·ΜηÄÖε·ΙδΙ΄φ€âδΗΣεàùφ≠Ξγö³δΚÜηßΘψÄ?/span>
Package: org.apache.lucene.document
‰qôδΗΣε¨ÖφèêδΨ¦δΚÜδΗÄδΚ¦δΊ™û°¹ηΘÖηΠ¹γÉΠεΦïγö³φ•΅φΓΘφâÄι€ÄηΠ¹γö³ΨcΜοΦ¨φ·îεΠ² Document, FieldψIJηΩôφ†χPΦ¨φ·èδΗÄδΗΣφ•΅φΓΘφ€ÄΨlàηΔΪû°¹ηΘÖφàêδΚÜδΗÄδΗ?Document ε·Ιη±ΓψÄ?/span>
Package: org.apache.lucene.analysis
‰qôδΗΣε¨ÖδΗΜηΠ¹εäüηÉΫφ‰·ε·“é•΅φΓΘηΩ¦ηΓ¨εàÜη·çο֨妆亙φ•΅φΓΘε€®εΨèγΪ΄γÉΠεΦïδΙ΄εâçεΩÖôεΜηΠ¹‰q¦ηΓ¨εàÜη·çεQ¨φâÄδΜΞηΩôδΗΣε¨Öγö³δΫ€γî®εè·δΜΞ〴φàêφ‰·δΗΚεΨèγΪ΄γÉΠεΦïε¹öε΅ÜεΛ΅εΖΞδΫ€ψÄ?/span>
Package: org.apache.lucene.index
‰qôδΗΣε¨ÖφèêδΨ¦δΚÜδΗÄδΚ¦γ±ΜφùΞεçèεä©εà¦εΜΚγÉΠεΦïδΜΞεèäε·Ιεà¦εΨèεΞΫγö³γ¥ΔεΦï‰q¦ηΓ¨φ¦¥φ•ΑψIJηΩô顨ιùΔφ€âδΗΛδΗΣεüΚΦ΄Äγö³γ±ΜεQöIndexWriter ε£?IndexReaderεQ¨εÖΕδΗ?IndexWriter φ‰·γî®φùΞεà¦εΜΚγÉΠεΦïεΤàφΖ’dä†φ•΅φΓΘεàΑγÉΠεΦïδΗ≠γö³οΦ¨IndexReader φ‰·γî®φùΞεà†ιôΛγÉΠεΦïδΗ≠γö³φ•΅φΓΘγö³ψÄ?/span>
Package: org.apache.lucene.search
‰qôδΗΣε¨ÖφèêδΨ¦δΚÜε·Ιε€®εΜΚγΪ΄εΞΫγö³γ¥ΔεΦïδΗäηΩ¦ηΓ¨φê€γ¥ΔφâÄι€ÄηΠ¹γö³ΨcÖRIJφ·îεΠ?IndexSearcher ε£?Hits, IndexSearcher ε°öδΙâδΚÜε€®φ¨΅ε°öγö³γÉΠεΦïδΗä‰q¦ηΓ¨φê€γÉΠγö³φ•Ιφ≥ïοΦ¨Hits γî®φùΞδΩùε≠‰φê€γÉΠεΨ½εàΑγö³γΜ™φû€ψÄ?/span>
δΗÄδΗΣγ°Äεçïγö³φê€γÉΠεΚîγî®ΫE΄εΚè
ε¹΅η°ΨφàëδΜ§γö³γîΒη³ëγö³γ¦°εΫïδΗ≠εêΪφ€âεΨàεΛöφ•΅φ€§φ•΅φΓΘοΦ¨φàëδΜ§ι€ÄηΠ¹φüΞφâë÷™ΣδΚ¦φ•΅φΓΘεêΪφ€âφüêδΗΣεÖ≥ιî°η·çψÄ²δΊ™δΚÜε°ûγéΑηΩôΩUçεäüηÉΫοΦ¨φàëδΜ§ιΠ•εÖàεà©γî® Lucene ε·ΙηΩôδΗΣγ¦°εΫïδΗ≠γö³φ•΅φΓΘεΨèγΪ΄γÉΠεΦïοΦ¨γ³Εεêéε€®εΨèγΪ΄εΞΫγö³γÉΠεΦïδΗ≠φê€γÉΠφàëδΜ§φâÄηΠ¹φüΞφâ³Γö³φ•΅φΓΘψIJιÄöηΩ΅‰qôδΗΣδΨ΄ε≠êη·ΜηÄÖδΦöε·ΙεΠ²δΫïεà©γî?Lucene φû³εΨèη΅ΣεΖ±γö³φê€γ¥ΔεΚîγî®γ®΄εΚèφ€âδΗΣφ·îηΨÉφΗÖφΞöγö³η°Λη·ÜψÄ?/span>
δΗόZΚÜε·“é•΅φΓΘηΩ¦ηΓ¨γÉΠεΦïοΦ¨Lucene φèêδΨ¦δΚÜδΚîδΗΣεüΚΦ΄Äγö³γ±ΜεQ¨δΜ•δΜ§εàÜεàΪφ‰· Document, Field, IndexWriter, Analyzer, DirectoryψIJδΗ΄ιùΔφàëδΜ§εàÜεàΪδΜ΄ΨlçδΗÄδΗ΄ηΩôδΚîδΗΣΨc»ùö³γî®ιÄîοΦö
Document
Document φ‰·γî®φùΞφèè‰qΑφ•΅φΓΘγö³εQ¨ηΩô顨γö³φ•΅φΓΘεè·δΜΞφ¨΅δΗÄδΗ?HTML ôεΒιùΔεQ¨δΗÄû°¹γîΒε≠êι²°δΜ”ûΦ¨φà•ηÄÖφ‰·δΗÄδΗΣφ•΅φ€§φ•΅δΜΕψIJδΗÄδΗ?Document ε·Ιη±Γγî±εΛöδΗ?Field ε·Ιη±ΓΨl³φàêγö³ψIJεè·δΜΞφääδΗÄδΗ?Document ε·Ιη±Γφɨô±ΓφàêφïΑφç°εΚ™δΗ≠γö³δΗÄδΗΣη°ΑεΫïοΦ¨ηĨφ·èδΗ?Field ε·Ιη±Γû°±φ‰·η°ΑεΫïγö³δΗÄδΗΣε≠½¨DϋcÄ?/span>
Field
Field ε·Ιη±Γφ‰·γî®φùΞφèè‰qνCΗÄδΗΣφ•΅φΓΘγö³φüêδΗΣε±ûφÄßγö³εQ¨φ·îεΠ²δΗÄû°¹γîΒε≠êι²°δΜΕγö³φ†΅ιĉ壨εÜÖε°Ιεè·δΜΞγî®δΗΛδΗΣ Field ε·Ιη±ΓεàÜεàΪφèèηΩΑψÄ?/span>
Analyzer
ε€®δΗÄδΗΣφ•΅φΓΘηΔΪγ¥ΔεΦïδΙ΄εâçεQ¨ιΠ•εÖàι€ÄηΠ¹ε·Ιφ•΅φΓΘεÜÖε°Ι‰q¦ηΓ¨εàÜη·çεΛ³γêÜεQ¨ηΩôιÉ®εàÜεΖΞδΫ€û°±φ‰·γî?Analyzer φùΞε¹öγö³ψIJAnalyzer ΨcάL‰·δΗÄδΗΣφäΫη±Γγ±ΜεQ¨ε°Éφ€âεΛöδΗΣε°ûγéΑψIJι£àε·ΙδΗçεê¨γö³η·≠η®Ä壨εΚîγî®ι€ÄηΠ¹ιÄâφ΄©ιIJεêàγö?AnalyzerψIJAnalyzer φääεàÜη·çεêéγö³εÜÖε°ΙδΚΛΨl?IndexWriter φùΞεΨèγΪ΄γÉΠεΦïψÄ?/span>
IndexWriter
IndexWriter φ‰?Lucene γî®φùΞεà¦εΨèγ¥ΔεΦïγö³δΗÄδΗΣφ†ΗεΩÉγö³ΨcΜοΦ¨δΜ•γö³δΫ€γî®φ‰·φääδΗÄδΗΣδΗΣγö?Document ε·Ιη±Γεä†εàΑγ¥ΔεΦïδΗ≠φùΞψÄ?/span>
Directory
‰qôδΗΣΨc÷MΜΘηΓ®δΚÜ Lucene γö³γÉΠεΦïγö³ε≠‰ε²®γö³δΫçΨ|°οΦ¨‰qôφ‰·δΗÄδΗΣφäΫη±Γγ±ΜεQ¨ε°Éγ¦°εâçφ€âδΗΛδΗΣε°ûγééΆΦ¨ΫW§δΗÄδΗΣφ‰· FSDirectoryεQ¨ε°ÉηΓ®γΛΚδΗÄδΗΣε≠‰ε²®ε€®φ•΅δögΨp»ùΜüδΗ≠γö³γ¥ΔεΦïγö³δΫçΨ|°ψÄ²γ§§δΚ¨δΗΣφ‰?RAMDirectoryεQ¨ε°ÉηΓ®γΛΚδΗÄδΗΣε≠‰ε²®ε€®εÜÖε≠‰εΫ™δΗ≠γö³γÉΠεΦïγö³δΫçγΫ°ψÄ?/span>
γÜüφ²âδΚÜεΨèγΪ΄γÉΠεΦïφâÄι€ÄηΠ¹γö³‰qôδΚ¦Ψc’dêéεQ¨φàëδΜ§εΑ±εΦÄεß΄ε·ΙφüêδΗΣγ¦°εΫïδΗ΄ιùΔγö³φ•΅φ€§φ•΅δΜΕεΨèγΪ΄γÉΠεΦïδΚÜεQ¨φΗÖεç?Ψlôε΅ΚδΚÜε·ΙφüêδΗΣγ¦°εΫïδΗ΄γö³φ•΅φ€§φ•΅δögεΜΚγΪ΄γ¥ΔεΦïγö³φΚêδΜΘγ†¹ψÄ?/span>
φΗÖεçï 1. ε·“é•΅φ€§φ•΅δΜΕεΨèγΪ΄γÉΠεΦ?/span>
package TestLucene;
import java.io.File;
import java.io.FileReader;
import java.io.Reader;
import java.util.Date;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.IndexWriter;
/**
* This class demonstrate the process of creating index with Lucene
* for text files
*/
public class TxtFileIndexer {
public static void main(String[] args) throws Exception{
//indexDir is the directory that hosts Lucene's index files
File indexDir = new File("D:\\luceneIndex");
//dataDir is the directory that hosts the text files that to be indexed
File dataDir = new File("D:\\luceneData");
Analyzer luceneAnalyzer = new StandardAnalyzer();
File[] dataFiles = dataDir.listFiles();
IndexWriter indexWriter = new IndexWriter(indexDir,luceneAnalyzer,true);
long startTime = new Date().getTime();
for(int i = 0; i < dataFiles.length; i++){
if(dataFiles[i].isFile() && dataFiles[i].getName().endsWith(".txt")){
System.out.println("Indexing file " + dataFiles[i].getCanonicalPath());
Document document = new Document();
Reader txtReader = new FileReader(dataFiles[i]);
document.add(new Field("path", dataFiles[i].getCanonicalPath(),
|
ε€®φΗÖεç?δΗ≠οΦ¨φàëδΜ§φ≥®φ³èεàΑγ±Μ IndexWriter γö³φû³ιĆε΅ΫφïΑι€ÄηΠ¹δΗâδΗΣεè²φïéΆΦ¨ΫW§δΗÄδΗΣεè²φïΑφ¨΅ε°öδΚÜφâÄεà¦εΨèγö³γÉΠεΦïηΠ¹ε≠‰φîΨγö³δΫçΨ|°οΦ¨δΜ•εè·δΜΞφ‰·δΗÄδΗ?File ε·Ιη±ΓεQ¨δΙüεè·δΜΞφ‰·δΗÄδΗ?FSDirectory ε·Ιη±Γφà•ηÄ?RAMDirectory ε·Ιη±ΓψÄ²γ§§δΚ¨δΗΣεè²φïΑφ¨΅ε°öδΚ?Analyzer Ψc»ùö³δΗÄδΗΣε°ûγééΆΦ¨δΙüεΑ±φ‰·φ¨΅ε°öηΩôδΗΣγÉΠεΦïφ‰·γî®ε™ΣδΗΣεàÜη·çεô®ε·“é•΅φ¨ΓεÜÖε°ΙηΩ¦ηΓ¨εàÜη·çψÄ²γ§§δΗâδΗΣεè²φïΑφ‰·δΗÄδΗΣεΗÉû°îεû΄γö³εè‰ι΅èοΦ¨εΠ²φû€δΗ?true γö³η·ùû°ΉÉΜΘηΓ®εà¦εΜόZΗÄδΗΣφ•Αγö³γÉΠεΦïοΦ¨δΗ?false γö³η·ùû°ΉÉΜΘηΓ®ε€®εéüφùΞγ¥ΔεΦïγö³εüΚΦ΄ÄδΗäηΩ¦ηΓ¨φ™çδΫ€ψIJφéΞγùÄΫE΄εΚèι¹çεéÜδΚÜγ¦°εΫïδΗ΄ιùΔγö³φâÄφ€âφ•΅φ€§φ•΅φΓΘοΦ¨ρqΕδΊ™φ·èδΗÄδΗΣφ•΅φ€§φ•΅φΓΘεà¦εΜόZΚÜδΗÄδΗ?Document ε·Ιη±ΓψIJγ³Εεêéφääφ•΅φ€§φ•΅φΓΘγö³δΗΛδΗΣε±ûφÄßοΦöηΖ·εس壨εÜÖε°Ιεä†εÖΞεàΑδΚÜδΗΛδΗ?Field ε·Ιη±ΓδΗ≠οΦ¨φéΞγùÄε€®φää‰qôδΗΛδΗ?Field ε·Ιη±Γεä†εÖΞεà?Document ε·Ιη±ΓδΗ≠οΦ¨φ€Äεêéφää‰qôδΗΣφ•΅φΓΘγî?IndexWriter Ψc»ùö³ add φ•“é≥ïεä†εÖΞεàΑγÉΠεΦïδΗ≠εéÖRIJηΩôφ†δhàëδΜ§δΨΩε°¨φàêδΚÜγÉΠεΦïγö³εà¦εΨèψIJφéΞδΗ΄φùΞφàëδΜ§‰q¦εÖΞε€®εΨèγΪ΄εΞΫγö³γÉΠεΦïδΗä‰q¦ηΓ¨φê€γÉΠγö³ιÉ®εàÜψÄ?/span>
εà©γî®Lucene‰q¦ηΓ¨φê€γÉΠû°±εÉèεΜΚγΪ΄γ¥ΔεΦïδΗÄφ†ΖδΙüφ‰·ιùûεΗΗφ•ΙδΨΩγö³ψÄ²ε€®δΗäιùΔδΗÄιÉ®εàÜδΗ≠οΦ¨φàëδΜ§εΖ≤γΜèδΗόZΗÄδΗΣγ¦°εΫïδΗ΄γö³φ•΅φ€§φ•΅φΓΘεΨèγΪ΄εΞΫδΚÜγÉΠεΦïοΦ¨γéΑε€®φàëδΜ§û°όpΠ¹ε€®ηΩôδΗΣγÉΠεΦïδΗä‰q¦ηΓ¨φê€γÉΠδΜΞφâΨεàΑε¨ÖεêΪφüêδΗΣεÖ≥ιî°η·çφà•γü≠η·≠γö³φ•΅φΓΘψIJLuceneφèêδΨ¦δΚÜ塆δΗΣεüΚΦ΄Äγö³γ±ΜφùΞε°¨φàêηΩôδΗΣηΩ΅ΫE΄οΦ¨ε°ÉδΜ§εàÜεàΪφ‰·εëΔIndexSearcher, Term, Query, TermQuery, Hits. δΗ΄ιùΔφàëδΜ§εàÜεàΪδΜ΄γΜç‰qô塆δΗΣγ±Μγö³εäüηÉΫψÄ?/span>
Query
‰qôφ‰·δΗÄδΗΣφäΫη±Γγ±ΜεQ¨δΜ•φ€âεΛöδΗΣε°ûγééΆΦ¨φ·îεΠ²TermQuery, BooleanQuery, PrefixQuery. ‰qôδΗΣΨc»ùö³γ¦°γö³φ‰·φääγî®φàΖηΨ™εÖΞγö³φüΞη·Δε≠½ΫWΠδΗ≤û°¹ηΘÖφàêLuceneηÉΫεΛüη·ÜεàΪγö³QueryψÄ?/span>
Term
Termφ‰·φê€γ¥Δγö³εüΚφ€§εçïδΫçεQ¨δΗÄδΗΣTermε·Ιη±Γφ€âδΗΛδΗΣStringΨc’dû΄γö³εüüΨl³φàêψIJγîüφàêδΗÄδΗΣTermε·Ιη±Γεè·δΜΞφ€âεΠ²δΗ΄δΗÄφùΓη·≠εèΞφùΞε°¨φàêεQöTerm term = new Term(“fieldName”,”queryWord”); εÖΕδΗ≠ΫW§δΗÄδΗΣεè²φïνCΜΘηΓ®δΚÜηΠ¹ε€®φ•΅φΓΘγö³ε™ΣδΗÄδΗΣFieldδΗäηΩ¦ηΓ¨φüΞφâΨοΦ¨ΫW§δΚ¨δΗΣεè²φïνCΜΘηΓ®δΚÜηΠ¹φüΞη·Δγö³εÖ≥ιî°η·çψÄ?/span>
TermQuery
TermQueryφ‰·φäΫη±Γγ±ΜQueryγö³δΗÄδΗΣε≠êΨcΜοΦ¨ε°Éεê¨φ½ΕδΙüφ‰·Luceneφî·φ¨¹γö³φ€ÄδΗΚεüΚφ€§γö³δΗÄδΗΣφüΞη·Δγ±ΜψIJγîüφàêδΗÄδΗΣTermQueryε·Ιη±Γγî±εΠ²δΗ΄η·≠εèΞε°¨φàêοΦö TermQuery termQuery = new TermQuery(new Term(“fieldName”,”queryWord”)); ε°Éγö³φû³ιĆε΅ΫφïΑεèΣφéΞεè½δΗÄδΗΣεè²φïéΆΦ¨ι²ΘεΑ±φ‰·δΗÄδΗΣTermε·Ιη±ΓψÄ?/span>
IndexSearcher
IndexSearcherφ‰·γî®φùΞε€®εΜΚγΪ΄εΞΫγö³γ¥ΔεΦïδΗäηΩ¦ηΓ¨φê€γ¥Δγö³ψIJε°ÉεèΣηÉΫδΜΞεèΣη·»ùö³φ•ΙεΦèφâ™εΦÄδΗÄδΗΣγÉΠεΦïοΦ¨φâÄδΜΞεè·δΜΞφ€âεΛöδΗΣIndexSearcherγö³ε°ûδΨ΄ε€®δΗÄδΗΣγÉΠεΦïδΗä‰q¦ηΓ¨φ™çδΫ€ψÄ?/span>
Hits
Hitsφ‰·γî®φùΞδΩùε≠‰φê€γ¥Δγö³Ψl™φû€γö³ψÄ?/span>
δΜ΄γΜçε°¨ηΩôδΚ¦φê€γ¥ΔφâÄεΩÖιΓΜγö³γ±ΜδΙ΄εêéεQ¨φàëδΜ§εΑ±εΦÄεß΄ε€®δΙ΄εâçφâÄεΜΚγΪ΄γö³γÉΠεΦïδΗä‰q¦ηΓ¨φê€γÉΠδΚÜοΦ¨φΗÖεçï2Ψlôε΅ΚδΚÜε°¨φàêφê€γ¥ΔεäüηÉΫφâÄι€ÄηΠ¹γö³δΜΘγ†¹ψÄ?/span>
φΗÖεçï2 εQöε€®εΜΚγΪ΄εΞΫγö³γ¥ΔεΦïδΗäηΩ¦ηΓ¨φê€γ¥?/span>
package TestLucene;
import java.io.File;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.Hits;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.store.FSDirectory;
/**
* This class is used to demonstrate the
* process of searching on an existing
* Lucene index
*
*/
public class TxtFileSearcher {
public static void main(String[] args) throws Exception{
String queryStr = "lucene";
//This is the directory that hosts the Lucene index
File indexDir = new File("D:\\luceneIndex");
FSDirectory directory = FSDirectory.getDirectory(indexDir,false);
IndexSearcher searcher = new IndexSearcher(directory);
if(!indexDir.exists()){
System.out.println("The Lucene index is not exist");
return;
}
Term term = new Term("contents",queryStr.toLowerCase());
TermQuery luceneQuery = new TermQuery(term);
Hits hits = searcher.search(luceneQuery);
for(int i = 0; i < hits.length(); i++){
Document document = hits.doc(i);
System.out.println("File: " + document.get("path"));
}
}
}
|
ε€®φΗÖεç?δΗ≠οΦ¨ΨcΜIndexSearcherγö³φû³ιĆε΅ΫφïΑφéΞεè½δΗÄδΗΣγ±Μεû΄δΊ™Directoryγö³ε·Ιη±ΓοΦ¨Directoryφ‰·δΗÄδΗΣφäΫη±Γγ±ΜεQ¨ε°Éγ¦°εâçφ€âδΗΛδΗΣε≠êΨcΜοΦöFSDirctory壨RAMDirectory. φàëδΜ§γö³γ®΄εΚèδΗ≠δΦ†εÖΞδΚÜδΗÄδΗΣFSDirctoryε·Ιη±ΓδΫ€δΊ™εÖΕεè²φïéΆΦ¨δΜΘηΓ®δΚÜδΗÄδΗΣε≠‰ε²®ε€®Φ²¹γ¦‰δΗäγö³γ¥ΔεΦïγö³δΫçΨ|°ψIJφû³ιĆε΅ΫφïΑφâßηΓ¨ε°¨φàêεêéεQ¨δΜΘηΓ®δΚ܉qôδΗΣIndexSearcherδΜΞεèΣη·»ùö³φ•ΙεΦèφâ™εΦÄδΚÜδΗÄδΗΣγÉΠεΦïψIJγ³ΕεêéφàëδΜ§γ®΄εΚèφû³ιĆδΚÜδΗÄδΗΣTermε·Ιη±ΓεQ¨ιÄöηΩ΅‰qôδΗΣTermε·Ιη±ΓεQ¨φàëδΜ§φ¨΅ε°öδΚÜηΠ¹ε€®φ•΅φΓΘγö³εÜÖε°ΙδΗ≠φê€γÉΠε¨ÖεêΪεÖ≥ιî°η·?#8221;lucene”γö³φ•΅φΓΘψIJφéΞγùÄεà©γqôδΗΣTermε·Ιη±Γφû³ιĆε΅ΚTermQueryε·Ιη±ΓρqΕφää‰qôδΗΣTermQueryε·Ιη±ΓδΦ†εÖΞεàΑIndexSearcherγö³searchφ•“é≥ïδΗ≠ηΩ¦ηΓ¨φüΞη·ΔοΦ¨‰qîε¦ûγö³γΜ™φû€δΩùε≠‰ε€®Hitsε·Ιη±ΓδΗ≠ψIJφ€ÄεêéφàëδΜ§γî®δΚÜδΗÄδΗΣεσ@γé·η·≠εèΞφääφê€γÉΠεàΑγö³φ•΅φΓΘγö³ηΒ\εΨ³ιÉΫφâ™εçΑδΚÜε΅ΚφùΞψIJεΞΫδΚÜοΦ¨φàëδΜ§γö³φê€γ¥ΔεΚîγî®γ®΄εΚèεΖ≤ΨlèεΦÄεèëε°¨φ·ïοΦ¨φÄéδΙàφ†χPΦ¨εà©γî®LuceneεΦÄεèëφê€γ¥ΔεΚîγî®γ®΄εΚèφ‰·δΗçφ‰·εΨàγ°ÄεçïψÄ?/span>
φ€§φ•΅ιΠ•εÖàδΜ΄γΜçδΚ?Lucene γö³δΗÄδΚ¦εüΚφ€§φΠ²εΩΒοΦ¨γ³ΕεêéεΦÄεèëδΚÜδΗÄδΗΣεΚîγî®γ®΄εΚèφΦîΫCόZΚÜεà©γî® Lucene εΜΚγΪ΄γ¥ΔεΦïρqΕε€®η·ΞγÉΠεΦïδΗä‰q¦ηΓ¨φê€γÉΠγö³ηΩ΅ΫE΄ψIJεΗ¨φ€¦φ€§φ•΅ηÉΫεΛüδΊ™ε≠ΠδΙ† Lucene γö³η·ΜηÄÖφèêδΨ¦εΗ°εä©ψÄ?br />
ε¦ΨδΗÄφ‰³ΓΛΚδΚ?Lucene γö³γÉΠεΦïφ€ΚεàΕγö³φûΕφû³ψIJLucene δΫΩγî®εê³γßçηßΘφûêεô®ε·Ιεê³γßçδΗçεê¨Ψc’dû΄γö³φ•΅φΓΘηΩ¦ηΓ¨ηßΘφûêψIJφ·îεΠ²ε·ΙδΚ?HTML φ•΅φΓΘεQ¨HTML ηßΘφûêεô®δΦöε¹öδΗÄδΚ¦ιΔ³εΛ³γêÜγö³εΖΞδΫ€οΦ¨φ·îεΠ²‰q΅φΉoφ•΅φΓΘδΗ≠γö³ HTML φ†΅γ≠ΨΫ{âγ≠âψIJHTML ηßΘφûêεô®γö³ηΨ™ε΅Κγö³φ‰·φ•΅φ€§εÜÖε°ΙεQ¨φéΞγùÄ Lucene γö³εàÜη·çεô®(Analyzer)δΜéφ•΅φ€§εÜÖε°ΙδΗ≠φèêεè•ε΅ΚγÉΠεΦïιΓΙδΜΞεèäγ¦ΗεÖ≥δΩΓφ¹·εQ¨φ·îεΠ²γÉΠεΦïιΓΙγö³ε΅ΚγéΑιΔëγé΅ψIJφéΞγùÄ Lucene γö³εàÜη·çεô®φääηΩôδΚ¦δΩΓφ¹·εÜôεàΑγÉΠεΦïφ•΅δΜΕδΗ≠ψÄ?/p>
ε¦ΨδΗÄεQöLucene γ¥ΔεΦïφ€ΚεàΕφûΕφû³

φéΞδΗ΄φùΞφàëû°ÜδΗÄφ≠ΞδΗÄφ≠Ξγö³φùΞφΦîΫCΚεΠ²δΫïεà©γî?Lucene δΗόZΫ†γö³φ•΅φΓΘεà¦εΜΚγÉΠεΦïψIJεèΣηΠ¹δΫ†ηÉΫεΑÜηΠ¹γÉΠεΦïγö³φ•΅δögηۧ娕φàêφ•΅φ€§φ†ΦεΦèοΦ¨Lucene û°όpÉΫδΗόZΫ†γö³φ•΅φΓΘεΨèγΪ΄γÉΠεΦïψIJφ·îεΠ²οΦ¨εΠ²φû€δΫ†φÉ≥δΗ?HTML φ•΅φΓΘφà•ηÄ?PDF φ•΅φΓΘεΜΚγΪ΄γ¥ΔεΦïεQ¨ι²ΘδΙàιΠ•εÖàδΫ†û°±ι€ÄηΠ¹δΜé‰qôδΚ¦φ•΅φΓΘδΗ≠φèêεè•ε΅Κφ•΅φ€§δΩΓφ¹·εQ¨γ³Εεêéφääφ•΅φ€§δΩΓφ¹·δΚΛγΜô Lucene εΜΚγΪ΄γ¥ΔεΦïψIJφàëδΜ§φéΞδΗ΄φùΞγö³δΨ΄ε≠êγî®φùΞφΦîΫCΚεΠ²δΫïεà©γî?Lucene δΗΚεêéΨ~ÄεêçδΊ™ txt γö³φ•΅δΜΕεΨèγΪ΄γÉΠεΦïψÄ?/p>
1εQ?ε΅ÜεΛ΅φ•΅φ€§φ•΅δög
ιΠ•εÖàφääδΗÄδΚ¦δΜΞ txt δΗΚεêéΨ~Äεêçγö³φ•΅φ€§φ•΅δögφîë÷àΑδΗÄδΗΣγ¦°εΫïδΗ≠εQ¨φ·îεΠ²ε€® Windows ρq¦_èΑδΗäοΦ¨δΫ†εè·δΜΞφîΨεà?C:\\files_to_index δΗ΄ιùΔψÄ?/p>
2εQ?εà¦εΨèγ¥ΔεΦï
φΗÖεçï1φ‰·δΊ™φàëδΜ§φâÄε΅ÜεΛ΅γö³φ•΅φΓΘεà¦εΜΚγÉΠεΦïγö³δΜΘγ†¹ψÄ?/p>
φΗÖεçï1εQöγî® Lucene γ¥ΔεΦïδΫ†γö³φ•΅φΓΘ
package lucene.index;
import java.io.File;
import java.io.FileReader;
import java.io.Reader;
import java.util.Date;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.IndexWriter;
/**
* This class demonstrates the process of creating an index with Lucene
* for text files in a directory.
*/
public class TextFileIndexer {
public static void main(String[] args) throws Exception{
//fileDir is the directory that contains the text files to be indexed
File fileDir = new File("C:\\files_to_index ");
//indexDir is the directory that hosts Lucene's index files
File indexDir = new File("C:\\luceneIndex");
Analyzer luceneAnalyzer = new StandardAnalyzer();
IndexWriter indexWriter = new IndexWriter(indexDir,luceneAnalyzer,true);
File[] textFiles = fileDir.listFiles();
long startTime = new Date().getTime();
//Add documents to the index
for(int i = 0; i < textFiles.length; i++){
if(textFiles[i].isFile() >> textFiles[i].getName().endsWith(".txt")){
System.out.println("File " + textFiles[i].getCanonicalPath()
+ " is being indexed");
Reader textReader = new FileReader(textFiles[i]);
Document document = new Document();
document.add(Field.Text("content",textReader));
document.add(Field.Text("path",textFiles[i].getPath()));
indexWriter.addDocument(document);
}
}
indexWriter.optimize();
indexWriter.close();
long endTime = new Date().getTime();
System.out.println("It took " + (endTime - startTime)
+ " milliseconds to create an index for the files in the directory "
+ fileDir.getPath());
}
}
|
φ≠ΘεΠ²φΗÖεçï1φâÄΫCΚοΦ¨δΫ†εè·δΜΞεà©γî?Lucene ιùûεΗΗφ•ΙδΨΩγö³δΊ™φ•΅φΓΘεà¦εΨèγ¥ΔεΦïψIJφéΞδΗ΄φùΞφàëδΜ§εàÜφûêδΗÄδΗ΄φΗÖεç?δΗ≠γö³φ·îηΨÉεÖ≥ιî°γö³δΜΘγ†¹οΦ¨φàëδΜ§εÖàδΜéδΗ΄ιùΔγö³δΗÄφùΓη·≠εèΞεΦÄεß΄γ€΄ηΒ½ςÄ?/p>
Analyzer luceneAnalyzer = new StandardAnalyzer();
|
‰qôφùΓη·≠εèΞεà¦εΨèδΚÜγ±Μ StandardAnalyzer γö³δΗÄδΗΣε°ûδΨ΄οΦ¨‰qôδΗΣΨcάL‰·γî®φùΞδΜéφ•΅φ€§δΗ≠φèêεè•ε΅ΚγÉΠεΦïιΓΙγö³ψIJε°ÉεèΣφ‰·φäΫη±ΓΨc?Analyzer γö³εÖΕδΗ≠δΗÄδΗΣε°ûγéΑψIJAnalyzer δΙüφ€âδΗÄδΚ¦εÖΕε°Éγö³ε≠êγ±ΜεQ¨φ·îεΠ?SimpleAnalyzer Ϋ{âψÄ?/p>
φàëδΜ§φéΞγùÄ〴εèΠεΛ•δΗÄφùΓη·≠εèΞοΦö
IndexWriter indexWriter = new IndexWriter(indexDir,luceneAnalyzer,true);
|
‰qôφùΓη·≠εèΞεà¦εΨèδΚÜγ±Μ IndexWriter γö³δΗÄδΗΣε°ûδΨ΄οΦ¨η·Ξγ±ΜδΙüφ‰· Lucene γ¥ΔεΦïφ€ΚεàΕ顨ιùΔγö³δΗÄδΗΣεÖ≥ιî°γ±ΜψIJηΩôδΗΣγ±ΜηÉΫεà¦εΜόZΗÄδΗΣφ•Αγö³γÉΠεΦïφà•ηÄÖφâ™εΦÄδΗÄδΗΣεΖ≤ε≠‰ε€®γö³γÉΠεΦïεΤàδΗχô·ΞφâÄεΦïφΖΜεä†φ•΅φΓΘψIJφàëδΜ§φ≥®φ³èεàΑη·Ξγ±Μγö³φû³ιĆε΅ΫφïΑφéΞεè½δΗâδΗΣεè²φïéΆΦ¨ΫW§δΗÄδΗΣεè²φïΑφ¨΅ε°öδΚÜε≠‰ε²®γ¥ΔεΦïφ•΅δögγö³ηΒ\εΨ³ψÄ²γ§§δΚ¨δΗΣεè²φïΑφ¨΅ε°öδΚÜε€®γ¥ΔεΦï‰q΅γ®΄δΗ≠δ΄…γî®δΜÄδΙàφ†Ζγö³εàÜη·çεô®ψIJφ€ÄεêéδΗÄδΗΣεè²φïΑφ‰·δΗΣεΗÉû°îεè‰ι΅èοΦ¨εΠ²φû€εÄιgΊ™γ€üοΦ¨ι²ΘδΙàû°όpΓ®ΫCχôΠ¹εà¦εΨèδΗÄδΗΣφ•Αγö³γÉΠεΦïοΦ¨εΠ²φû€εÄιgΊ™ε¹΅οΦ¨û°όpΓ®ΫCΚφâ™εΦÄδΗÄδΗΣεΖ≤Ψlèε≠‰ε€®γö³γ¥ΔεΦïψÄ?/p>
φéΞδΗ΄φùΞγö³δΜΘγ†¹φΦîγΛΚδΚÜεΠ²δΫïφΖΜεä†δΗÄδΗΣφ•΅φΓΘεàΑγ¥ΔεΦïφ•΅δögδΗ≠ψÄ?/p>
Document document = new Document();
document.add(Field.Text("content",textReader));
document.add(Field.Text("path",textFiles[i].getPath()));
indexWriter.addDocument(document);
|
ιΠ•εÖàΫW§δΗÄηΓ¨εà¦εΜόZΚÜΨc?Document γö³δΗÄδΗΣε°ûδΨ΄οΦ¨ε°Éγî±δΗÄδΗΣφà•ηÄÖεΛöδΗΣγö³εü?Field)Ψl³φàêψIJδΫ†εè·δΜΞφääηΩôδΗΣγ±Μφɨô±ΓφàêδΜΘηΓ®δΚÜδΗÄδΗΣε°ûιôÖγö³φ•΅φΓΘεQ¨φ·îεΠ²δΗÄδΗ?HTML ôεΒιùΔεQ¨δΗÄδΗ?PDF φ•΅φΓΘεQ¨φà•ηÄÖδΗÄδΗΣφ•΅φ€§φ•΅δΜΕψIJηĨγ±Μ Document δΗ≠γö³εüüδΗÄηà§εΑ±φ‰·ε°ûιôÖφ•΅φΓΘγö³δΗÄδΚ¦ε±ûφÄßψIJφ·îεΠ²ε·ΙδΚéδΗÄδΗ?HTML ôεΒιùΔεQ¨ε°Éγö³εüüεè·ηÉΫε¨Öφ΄§φ†΅ιΔ‰εQ¨εÜÖε°ΙοΦ¨URL Ϋ{âψIJφàëδΜ§εè·δΜΞγî®δΗçεê¨Ψc’dû΄γö?Field φùΞφéßεàΕφ•΅φΓΘγö³ε™ΣδΚ¦εÜÖε°ΙεΚîη·Ξγ¥ΔεΦïεQ¨ε™ΣδΚ¦εÜÖε°ΙεΚîη·Ξε≠‰ε²®ψIJεΠ²φû€φÉ≥ηéΖεè•φ¦¥εΛöγö³εÖ≥δΚ?Lucene γö³εüüγö³δΩΓφ¹·οΦ¨εè·δΜΞεè²ηÄ?Lucene γö³εΗ°εä©φ•΅φΓΘψIJδΜΘγ†¹γö³ΫW§δΚ¨ηè壨ΫW§δΗâηΓ¨δΊ™φ•΅φΓΘφΖ’dä†δΚÜδΗΛδΗΣεüüεQ¨φ·èδΗΣεüüε¨ÖεêΪδΗΛδΗΣε±ûφÄßοΦ¨εàÜεàΪφ‰·εüüγö³εêçε≠½ε£¨εüüγö³εÜÖε°ΙψÄ²ε€®φàëδΜ§γö³δΨ΄ε≠êδΗ≠δΗΛδΗΣεüüγö³εêçε≠½εàÜεàΪφ‰?content"ε£?path"ψIJεàÜεàΪε≠‰ε²®δΚÜφàëδΜ§ι€ÄηΠ¹γÉΠεΦïγö³φ•΅φ€§φ•΅δögγö³εÜÖε°Ι壨ηΖ·εΨ³ψIJφ€ÄεêéδΗÄηΓ¨φääε΅ÜεΛ΅εΞΫγö³φ•΅φΓΘφΖ’dä†εàνCΚÜγ¥ΔεΦïεΫ™δΗ≠ψÄ?/p>
εΫ™φàëδΜ§φääφ•΅φΓΘφΖ’dä†εàΑγÉΠεΦïδΗ≠εêéοΦ¨δΗçηΠ¹εΩ‰η°ΑεÖ≥ι½≠γ¥ΔεΦïεQ¨ηΩôφ†δhâçδΩùη·¹ Lucene φääφΖΜεä†γö³φ•΅φΓΘεÜôε¦ûεàΑγç㦉δΗäψIJδΗ΄ιùΔγö³δΗÄεèΞδΜΘγ†¹φΦîΫCόZΚÜεΠ²δΫïεÖ≥ι½≠γ¥ΔεΦïψÄ?/p>
indexWriter.close();
|
εà©γî®φΗÖεçï1δΗ≠γö³δΜΘγ†¹εQ¨δΫ†û°±εè·δΜΞφàêεäüγö³û°Üφ•΅φ€§φ•΅φΓΘφΖΜεä†εàΑγ¥ΔεΦïδΗ≠εéΜψIJφéΞδΗ΄φùΞφàëδ̧〴〴ε·ΙγÉΠεΦïηΩ¦ηΓ¨γö³εèΠεΛ•δΗÄΩUçι΅çηΠ¹γö³φ™çδΫ€εQ¨δΜéγ¥ΔεΦïδΗ≠εà†ιôΛφ•΅φΓΘψÄ?/p>
ΨcΜIndexReaderη¥üη¥ΘδΜéδΗÄδΗΣεΖ≤Ψlèε≠‰ε€®γö³γ¥ΔεΦïδΗ≠εà†ιôΛφ•΅φΓΘοΦ¨εΠ²φΗÖεç?φâÄΫCΚψÄ?/p>
φΗÖεçï2εQöδΜéγ¥ΔεΦïδΗ≠εà†ιôΛφ•΅φΓ?/strong>
File indexDir = new File("C:\\luceneIndex");
IndexReader ir = IndexReader.open(indexDir);
ir.delete(1);
ir.delete(new Term("path","C:\\file_to_index\lucene.txt"));
ir.close();
|
ε€®φΗÖεç?δΗ≠οΦ¨ΫW§δΚ¨ηΓ¨γî®ιùôφĹφ•Ιφ≥?IndexReader.open(indexDir) εàùεß΄ε¨•δΚÜΨc?IndexReader γö³δΗÄδΗΣε°ûδΨ΄οΦ¨‰qôδΗΣφ•“é≥ïγö³εè²φïΑφ¨΅ε°öδΚÜγ¥ΔεΦïγö³ε≠‰ε²®ηΒ\εΨ³ψIJγ±Μ IndexReader φèêδΨ¦δΚÜδΗΛΩUçφ•Ιφ≥ïεéΜεà†ιôΛδΗÄδΗΣφ•΅φΓΘοΦ¨εΠ²γ®΄εΚèδΗ≠γö³γ§§δΗâηè壨㧧妦ηΓ¨φâÄΫCΚψÄ²γ§§δΗâηΓ¨εà©γî®φ•΅φΓΘγö³γΦ•εèδhùΞεà†ιôΛφ•΅φΓΘψIJφ·èδΗΣφ•΅φΓΘιÉΫφ€âδΗÄδΗΣγ≥ΜΨlüη΅Σεä®γîüφàêγö³Ψ~•εèΖψÄ²γ§§ε¦¦ηΓ¨εà†ιôΛδΚÜηΒ\εΨ³δΊ™"C:\\file_to_index\lucene.txt"γö³φ•΅φΓΘψIJδΫ†εè·δΜΞιÄöηΩ΅φ¨΅ε°öφ•΅δögηΖ·εΨ³φùΞφ•ΙδΨΩγö³εà†ιôΛδΗÄδΗΣφ•΅φΓΘψIJεÄΦεΨ½φ≥®φ³èγö³φ‰·ηôΫγ³Εεà©γî®δΗäηΩΑδΜΘγ†¹εà†ιôΛφ•΅φΓΘδΫΩεΨ½η·Ξφ•΅φΓΘδΗçηÉΫηΔΪ΄²Äγ¥ΔεàΑεQ¨δΫÜφ‰·εΤàφ≤Γφ€âγâ©γêÜδΗäεà†ιôΛη·Ξφ•΅φΓΘψIJLucene εèΣφ‰·ιÄöηΩ΅δΗÄδΗΣεêéΨ~ÄεêçδΊ™ .delete γö³φ•΅δΜΕφùΞφ†΅η°Αε™ΣδΚ¦φ•΅φΓΘεΖ≤γΜèηΔΪεà†ιôΛψIJφ½Δγ³Εφ≤Γφ€âγâ©γêÜδΗäεà†ιôΛεQ¨φàëδΜ§εè·δΜΞφ•ΙδΨΩγö³φääηΩôδΚ¦φ†΅η°νCΊ™εà†ιôΛγö³φ•΅φΓΘφ¹ΔεΛçηΩ΅φùΞοΦ¨εΠ²φΗÖεç?3 φâÄΫCΚοΦ¨ιΠ•εÖàφâ™εΦÄδΗÄδΗΣγÉΠεΦïοΦ¨γ³ΕεêéηΑÉγî®φ•“é≥ï ir.undeleteAll() φùΞε°¨φàêφ¹ΔεΛçεΖΞδΫ€ψÄ?/p>
φΗÖεçï3εQöφ¹ΔεΛçεΖ≤εà†ιôΛφ•΅φΓΘ
File indexDir = new File("C:\\luceneIndex");
IndexReader ir = IndexReader.open(indexDir);
ir.undeleteAll();
ir.close();
|
δΫ†γéΑε€®δΙüη°ΗφÉ≥γüΞι¹™εΠ²δΫïγâ©γêÜδΗäεà†ιôΛγÉΠεΦïδΗ≠γö³φ•΅φΓΘοΦ¨φ•“é≥ïδΙüιùûεΗΗγ°ÄεçïψIJφΗÖεç?4 φΦîγΛΚδΚÜηΩôδΗΣηΩ΅ΫE΄ψÄ?/p>
φΗÖεçï4εQöεΠ²δΫïγâ©γêÜδΗäεà†ιôΛφ•΅φΓΘ
File indexDir = new File("C:\\luceneIndex");
Analyzer luceneAnalyzer = new StandardAnalyzer();
IndexWriter indexWriter = new IndexWriter(indexDir,luceneAnalyzer,false);
indexWriter.optimize();
indexWriter.close();
|
ε€®φΗÖεç?4 δΗ≠οΦ¨ΫW§δΗâηΓ¨εà¦εΜόZΚÜΨc?IndexWriter γö³δΗÄδΗΣε°ûδΨ΄οΦ¨ρqΕδΗîφâ™εΦÄδΚÜδΗÄδΗΣεΖ≤Ψlèε≠‰ε€®γö³γ¥ΔεΦïψÄ²γ§§ 4 ηΓ¨ε·Ιγ¥ΔεΦï‰q¦ηΓ¨φΗÖγêÜεQ¨φΗÖγêÜηΩ΅ΫE΄δΗ≠û°ÜφääφâÄφ€âφ†΅η°νCΊ™εà†ιôΛγö³φ•΅φΓΘγâ©γêÜεà†ιôΛψÄ?/p>
Lucene φ≤Γφ€â㦥φéΞφèêδΨ¦φ•“é≥ïε·“é•΅φΓΘηΩ¦ηΓ¨φ¦¥φ•éΆΦ¨εΠ²φû€δΫ†ι€ÄηΠ¹φ¦¥φ•νCΗÄδΗΣφ•΅φΓΘοΦ¨ι²ΘδΙàδΫ†ιΠ•εÖàι€ÄηΠ¹φää‰qôδΗΣφ•΅φΓΘδΜéγÉΠεΦïδΗ≠εà†ιôΛεQ¨γ³Εεêéφääφ•Αγâàφ€§γö³φ•΅φΓΘεä†εÖΞεàΑγÉΠεΦïδΗ≠εéÖRÄ?/p>
εà©γî® LuceneεQ¨ε€®εà¦εΨèγ¥ΔεΦïγö³εΖΞΫE΄δΗ≠δΫ†εè·δΜΞεÖÖεàÜεà©γî®φ€Κεô®γö³Φ΄§δögηΒ³φΚêφùΞφèêιΪ‰γÉΠεΦïγö³φïàγé΅ψIJεΫ™δΫ†ι€ÄηΠ¹γÉΠεΦïεΛßι΅èγö³φ•΅δögφ½”ûΦ¨δΫ†δΦöφ≥®φ³èεàΑγÉΠεΦïηΩ΅ΫE΄γö³γ™âôΔàφ‰·ε€®εΨÄΦ²¹γ¦‰δΗäεÜôγ¥ΔεΦïφ•΅δögγö³ηΩ΅ΫE΄δΗ≠ψÄ²δΊ™δΚÜηßΘεܨôΩôδΗΣι½°ιΔ? Lucene ε€®εÜÖε≠‰δΗ≠φ¨¹φ€âδΗÄεù½γΦ™εÜ≤ε¨ΚψIJδΫÜφàëδΜ§εΠ²δΫïφéßεàΕ Lucene γö³γΦ™εÜ≤ε¨ΚεëΔοΦüρqΗηΩêγö³φ‰·εQ¨Lucene γö³γ±Μ IndexWriter φèêδΨ¦δΚÜδΗâδΗΣεè²φïΑγî®φùΞηΑÉφï¥γΦ™εÜ≤ε¨Κγö³εΛßû°èδΜΞεèäεΨÄΦ²¹γ¦‰δΗäεÜôγ¥ΔεΦïφ•΅δögγö³ιΔëγé΅ψÄ?/p>
1εQéεêàρqΕ妆ε≠êοΦàmergeFactorεQ?/p>
‰qôδΗΣεè²φïΑεܦ_°öδΚÜε€® Lucene γö³δΗÄδΗΣγÉΠεΦïεù½δΗ≠εè·δΜΞε≠‰φîë÷Λöû°ëφ•΅φΓΘδΜΞεèäφääΦ²¹γ¦‰δΗäγö³γ¥ΔεΦïεù½εêàρqΕφàêδΗÄδΗΣεΛßγö³γÉΠεΦïεù½γö³ιΔëγé΅ψIJφ·îεΠ²οΦ¨εΠ²φû€εêàεΤà妆ε≠êγö³εÄΦφ‰· 10εQ¨ι²ΘδΙàεΫ™εÜÖε≠‰δΗ≠γö³φ•΅φΓΘφïΑηΨΨεà?10 γö³φ½ΕεÄôφâÄφ€âγö³φ•΅φΓΘιÉΫεΩÖôε’dÜôεàΑγΘ¹γ¦‰δΗäγö³δΗÄδΗΣφ•Αγö³γÉΠεΦïεù½δΗ≠ψIJεΤàδΗîοΦ¨εΠ²φû€Φ²¹γ¦‰δΗäγö³γ¥ΔεΦïεù½γö³ιöîφïΑηΨë÷àΑ 10 γö³η·ùεQ¨ηΩô 10 δΗΣγÉΠεΦïεù½δΦöηΔΪεêàεΤàφàêδΗÄδΗΣφ•Αγö³γÉΠεΦïεù½ψIJηΩôδΗΣεè²φïΑγö³ιΜ‰η°ΛεÄΦφ‰· 10εQ¨εΠ²φû€ι€ÄηΠ¹γÉΠεΦïγö³φ•΅φΓΘφïΑιùûεΗΗεΛöγö³η·ù‰qôδΗΣεÄΦεΑÜφ‰·ιùûεΗφÄΗçεêàιIJγö³ψIJε·ΙφâΙεΛ³γêÜγö³γ¥ΔεΦïφùΞη°≤εQ¨δΊ™‰qôδΗΣεè²φïΑηΒ΄δΗÄδΗΣφ·îηΨÉεΛßγö³εÄιgΦöεΨ½εàΑφ·îηΨÉεΞΫγö³γ¥ΔεΦïφïàφû€ψÄ?/p>
2εQéφ€Äû°èεêàρqΕφ•΅φΓΘφïΑ
‰qôδΗΣεè²φïΑδΙüδΦöεΫ±ε™çγ¥ΔεΦïγö³φÄßηÉΫψIJε°Éεܦ_°öδΚÜεÜÖε≠‰δΗ≠γö³φ•΅φΓΘφïΑ硦_ΑëηΨë÷àΑεΛöεΑëφâçηÉΫû°Üε°ÉδΜ§εÜôε¦ûγΘ¹γ¦‰ψIJηΩôδΗΣεè²φïΑγö³ιΜ‰η°ΛεÄΦφ‰·10εQ¨εΠ²φû€δΫ†φ€âηÉωεΛüγö³εÜÖε≠‰εQ¨ι²ΘδΙàεΑ܉qôδΗΣεÄΦεΑΫι΅èη°Ψγö³φ·îηΨÉεΛßδΗÄδΚ¦εΑÜδΦöφ‰Ψηë½γö³φèêιΪ‰γ¥ΔεΦïφÄßηÉΫψÄ?/p>
3εQéφ€ÄεΛßεêàρqΕφ•΅φΓΘφïΑ
‰qôδΗΣεè²φïΑεܦ_°öδΚÜδΗÄδΗΣγÉΠεΦïεù½δΗ≠γö³φ€ÄεΛßγö³φ•΅φΓΘφïΑψIJε°Éγö³ιΜ‰η°ΛεÄΦφ‰· Integer.MAX_VALUEεQ¨εΑ܉qôδΗΣεè²φïΑη°³ΓΫ°δΗΚφ·îηΨÉεΛßγö³εÄΦεè·δΜΞφèêιΪ‰γÉΠεΦïφïàγé΅ε£¨΄²Äγ¥ΔιÄüεΚΠεQ¨γî±δΚéη·Ξεè²φïΑγö³ιΜ‰η°ΛεÄΦφ‰·φï¥εû΄γö³φ€ÄεΛßεÄϊ|Φ¨φâÄδΜΞφàëδΜ§δΗÄηà§δΗçι€ÄηΠ¹φîΙεä®ηΩôδΗΣεè²φïΑψÄ?/p>
φΗÖεçï 5 εà½ε΅ΚδΚÜηΩôδΗΣδΗâδΗΣεè²φïΑγî®φ≥ïοΦ¨φΗÖεçï 5 壨φΗÖεç?1 ιùûεΗΗγ¦φÄΦΦεQ¨ιôΛδΚÜφΗÖεç?5 δΗ≠δΦöη°³ΓΫ°εàöφâçφèêεàΑγö³δΗâδΗΣεè²φïΑψÄ?/p>
/**
* This class demonstrates how to improve the indexing performance
* by adjusting the parameters provided by IndexWriter.
*/
public class AdvancedTextFileIndexer {
public static void main(String[] args) throws Exception{
//fileDir is the directory that contains the text files to be indexed
File fileDir = new File("C:\\files_to_index");
//indexDir is the directory that hosts Lucene's index files
File indexDir = new File("C:\\luceneIndex");
Analyzer luceneAnalyzer = new StandardAnalyzer();
File[] textFiles = fileDir.listFiles();
long startTime = new Date().getTime();
int mergeFactor = 10;
int minMergeDocs = 10;
int maxMergeDocs = Integer.MAX_VALUE;
IndexWriter indexWriter = new IndexWriter(indexDir,luceneAnalyzer,true);
indexWriter.mergeFactor = mergeFactor;
indexWriter.minMergeDocs = minMergeDocs;
indexWriter.maxMergeDocs = maxMergeDocs;
//Add documents to the index
for(int i = 0; i < textFiles.length; i++){
if(textFiles[i].isFile() >> textFiles[i].getName().endsWith(".txt")){
Reader textReader = new FileReader(textFiles[i]);
Document document = new Document();
document.add(Field.Text("content",textReader));
document.add(Field.Keyword("path",textFiles[i].getPath()));
indexWriter.addDocument(document);
}
}
indexWriter.optimize();
indexWriter.close();
long endTime = new Date().getTime();
System.out.println("MergeFactor: " + indexWriter.mergeFactor);
System.out.println("MinMergeDocs: " + indexWriter.minMergeDocs);
System.out.println("MaxMergeDocs: " + indexWriter.maxMergeDocs);
System.out.println("Document number: " + textFiles.length);
System.out.println("Time consumed: " + (endTime - startTime) + " milliseconds");
}
}
|
ιÄöηΩ΅‰qôδΗΣδΨ΄ε≠êεQ¨φàëδΜ§φ≥®φ³èεàΑε€®ηΑÉφï¥γΦ™εÜ≤ε¨Κγö³εΛßû°èδΜΞεèäεÜôΦ²¹γ¦‰γö³ιΔëγé΅δΗäιù?Lucene ΨlôφàëδΜ§φèêδΨ¦δΚÜιùûεΗΗεΛßγö³γ¹â|¥ΜφÄßψIJγéΑε€®φàëδΜ§φùΞ〴δΗÄδΗ΄δΜΘγ†¹δΗ≠γö³εÖ≥ιî°η·≠εèΞψIJεΠ²δΗ΄γö³δΜΘγ†¹ιΠ•εÖàεà¦εΨèδΚÜγ±Μ IndexWriter γö³δΗÄδΗΣε°ûδΨ΄οΦ¨γ³Εεêéε·Ιε°Éγö³δΗâδΗΣεè²φïΑηΩ¦ηΓ¨ηΒ΄εÄΙ{Ä?/p>
int mergeFactor = 10;
int minMergeDocs = 10;
int maxMergeDocs = Integer.MAX_VALUE;
IndexWriter indexWriter = new IndexWriter(indexDir,luceneAnalyzer,true);
indexWriter.mergeFactor = mergeFactor;
indexWriter.minMergeDocs = minMergeDocs;
indexWriter.maxMergeDocs = maxMergeDocs;
|
δΗ΄ιùΔφàëδΜ§φùΞ〴δΗÄδΗ΄ηΩôδΗâδΗΣεè²φïΑεè•δΗçεê¨γö³εÄΦε·Ιγ¥ΔεΦïφ½âô½¥γö³εΣ³ε™çοΦ¨φ≥®φ³èεè²φïΑεÄΦγö³δΗçεê¨ε£¨γÉΠεΦïδΙ΄ι½¥γö³εÖ≥γ≥ΜψIJφàëδΜ§δΊ™‰qôδΗΣε°ûιΣ¨ε΅ÜεΛ΅δΚ?10000 δΗΣφΒ΄η·ïφ•΅φΓΘψIJηΓ® 1 φ‰³ΓΛΚδΚÜφΒ΄η·ïγΜ™φû€ψÄ?/p>
ιÄöηΩ΅ηΓ?1εQ¨δΫ†εè·δΜΞφΗÖφΞöε€Α〴εàνCΗâδΗΣεè²φïΑε·Ιγ¥ΔεΦïφ½âô½¥γö³εΣ³ε™çψÄ²ε€®ε°ûηΖΒδΗ≠οΦ¨δΫ†δΦöΨlèεΗΗγö³φîΙεè‰εêàρqΕ妆ε≠ê壨φ€Äû°èεêàρqΕφ•΅φΓΘφïΑγö³εÄΦφùΞφèêιΪ‰γ¥ΔεΦïφÄßηÉΫψIJεèΣηΠ¹δΫ†φ€âηÉωεΛüεΛßγö³εÜÖε≠‰οΦ¨δΫ†εè·δΜΞδΊ™εêàεΤà妆ε≠ê壨φ€Äû°èεêàρqΕφ•΅φΓΘφïΑ‰qôδΗΛδΗΣεè²φïΑηΒ΄û°Ϋι΅èεΛßγö³εÄιgΜΞφèêιΪ‰γ¥ΔεΦïφïàγé΅εQ¨εèΠεΛ•φàëδΜ§δΗÄηà§φ½†ι€Äφ¦¥φîΙφ€ÄεΛßεêàρqΕφ•΅φΓΘφïΑ‰qôδΗΣεè²φïΑγö³εÄϊ|֨妆亙Ψp»ùΜüεΖ≤γΜèιΜ‰η°Λû°Üε°Éη°³ΓΫ°φàêδΚÜφ€ÄεΛßψÄ?/p>
Lucene γ¥ΔεΦïφ•΅δögΨl™φû³εàÜφûê
ε€®εàÜφû?Lucene γö³γÉΠεΦïφ•΅δΜΕγΜ™φû³δΙ΄εâçοΦ¨φàëδΜ§εÖàηΠ¹γêÜηßΘεèçεêëγ¥ΔεΦïεQàInverted indexεQâηΩôδΗΣφΠ²εΩΒοΦ¨εèçεêëγ¥ΔεΦïφ‰·δΗÄΩUçδΜΞγ¥ΔεΦïôεΙδΊ™δΗ≠εΩÉφùΞγΜ³Ψl΅φ•΅φΓΘγö³φ•ΙεΦèεQ¨φ·èδΗΣγÉΠεΦïιΓΙφ¨΅εêëδΗÄδΗΣφ•΅φΓΘεΚèεà½οΦ¨‰qôδΗΣεΚèεà½δΗ≠γö³φ•΅φΓΘιÉΫε¨ÖεêΪη·Ξγ¥ΔεΦïôεèVIJγ¦ΗεèçοΦ¨ε€®φ≠ΘεêëγÉΠεΦïδΗ≠εQ¨φ•΅φΓΘεç†φç°δΚÜδΗ≠εΩÉγö³δΫçΨ|°οΦ¨φ·èδΗΣφ•΅φΓΘφ¨΅εêëδΚÜδΗÄδΗΣε°ÉφâÄε¨ÖεêΪγö³γÉΠεΦïιΓΙγö³εΚèεà½ψIJδΫ†εè·δΜΞεà©γî®εèçεêëγ¥ΔεΦïηΫάLùΨγö³φâΨεàΑι²ΘδΚ¦φ•΅φΓΘε¨ÖεêΪδΚÜγâΙε°öγö³γÉΠεΦïιΓΙψIJLuceneφ≠Θφ‰·δΫΩγî®δΚÜεèçεêëγÉΠεΦïδΫ€δΗΚεÖΕεüΚφ€§γö³γÉΠεΦïγΜ™φû³ψÄ?/p>
ε€®Lucene δΗ≠φ€âγ¥ΔεΦïεù½γö³φΠ²εΩΒεQ¨φ·èδΗΣγÉΠεΦïεù½ε¨ÖεêΪδΚÜδΗÄε°öφïΑγ¦°γö³φ•΅φΓΘψIJφàëδΜ§ηÉΫεΛüε·Ιεçï㴧γö³γÉΠεΦïεù½‰q¦ηΓ¨΄²Äγ¥ΔψIJε¦Ψ 2 φ‰³ΓΛΚδΚ?Lucene γ¥ΔεΦïΨl™φû³γö³ιÄΜηΨëηßÜε¦ΨψIJγÉΠεΦïεù½γö³δΗΣφïΑγî±γ¥ΔεΦïγö³φ•΅φΓΘγö³φÄάLïΑδΜΞεèäφ·èδΗΣγ¥ΔεΦïεù½φâÄηÉΫε¨ÖεêΪγö³φ€ÄεΛßφ•΅φΓΘφïΑφùΞεÜ≥ε°öψÄ?/p>
ε¦?εQöγÉΠεΦïφ•΅δΜΕγö³ιÄΜηΨëηßÜε¦Ψ

Lucene δΗ≠γö³εÖ≥ιî°γ¥ΔεΦïφ•΅δög
δΗ΄ιùΔγö³ιÉ®εàÜεΑÜδΦöεàÜφûêLuceneδΗ≠γö³δΗΜηΠ¹γö³γÉΠεΦïφ•΅δΜ”ûΦ¨εè·ηÉΫεàÜφûêφ€âδΚ¦γ¥ΔεΦïφ•΅δögγö³φ½ΕεÄôφ≤Γφ€âε¨ÖεêΪφ•΅δΜΕγö³φâÄφ€âγö³ε≠½φ°ΒεQ¨δΫÜδΗçδΦöεΫ±ε™çεàΑε·Ιγ¥ΔεΦïφ•΅δögγö³γêÜηßΘψÄ?/p>
1εQéγÉΠεΦïεù½φ•΅δög
‰qôδΗΣφ•΅δögε¨ÖεêΪδΚÜγÉΠεΦïδΗ≠γö³γÉΠεΦïεù½δΩΓφ¹·εQ¨ηΩôδΗΣφ•΅δΜΕε¨ÖεêΪδΚÜφ·èδΗΣγ¥ΔεΦïεù½γö³εêçε≠½δΜΞεèäεΛßεΑèΫ{âδΩΓφ¹·ψIJηΓ® 2 φ‰³ΓΛΚδΚÜηΩôδΗΣφ•΅δΜΕγö³Ψl™φû³δΩΓφ¹·ψÄ?/p>

2εQéεüüδΩΓφ¹·φ•΅δög
φàëδΜ§γüΞι¹™εQ¨γÉΠεΦïδΗ≠γö³φ•΅φΓΘγî±δΗÄδΗΣφà•ηÄÖεΛöδΗΣεüüΨl³φàêεQ¨ηΩôδΗΣφ•΅δΜΕε¨ÖεêΪδΚÜφ·èδΗΣγ¥ΔεΦïεù½δΗ≠γö³εüüγö³δΩΓφ¹·ψIJηΓ® 3 φ‰³ΓΛΚδΚÜηΩôδΗΣφ•΅δΜΕγö³Ψl™φû³ψÄ?/p>

3εQéγÉΠεΦïιΓΙδΩΓφ¹·φ•΅δög
‰qôφ‰·γ¥ΔεΦïφ•΅δög顨ιùΔφ€Äφ†ΗεΩÉγö³δΗÄδΗΣφ•΅δΜ”ûΦ¨ε°Éε≠‰ε²®δΚÜφâÄφ€âγö³γ¥ΔεΦïôεΙγö³εÄιgΜΞεèäγ¦ΗεÖ≥δΩΓφ¹·οΦ¨ρqΕδΗîδΜΞγÉΠεΦïιΓΙφùΞφé£εΚèψIJηΓ® 4 φ‰³ΓΛΚδΚÜηΩôδΗΣφ•΅δΜΕγö³Ψl™φû³ψÄ?/p>
ηΓ?εQöγÉΠεΦïιΓΙδΩΓφ¹·φ•΅δögΨl™φû³

4εQéιΔëγé΅φ•΅δΜ?/p>
‰qôδΗΣφ•΅δögε¨ÖεêΪδΚÜε¨ÖεêΪγÉΠεΦïιΓΙγö³φ•΅φΓΘγö³εà½ηΓ®εQ¨δΜΞεèäγÉΠεΦïιΓΙε€®φ·èδΗΣφ•΅φΓΘδΗ≠ε΅ΚγéΑγö³ιΔëγé΅δΩΓφ¹·ψIJεΠ²φû€Luceneε€®γÉΠεΦïιΓΙδΩΓφ¹·φ•΅δögδΗ≠εèëγéΑφ€âγ¥ΔεΦïôεΙ壨φê€γÉΠη·çγ¦Ηε¨öwÖçψIJι²ΘδΙ?Lucene û°ΉÉΦöε€®ιΔëγé΅φ•΅δΜΕδΗ≠φâΨφ€âε™ΣδΚ¦φ•΅δögε¨ÖεêΪδΚÜη·Ξγ¥ΔεΦïôεèVIJηΓ®5φ‰³ΓΛΚδΚÜηΩôδΗΣφ•΅δΜΕγö³δΗÄδΗΣεΛßη΅¥γö³Ψl™φû³εQ¨εΤàφ≤Γφ€âε¨ÖεêΪ‰qôδΗΣφ•΅δögγö³φâÄφ€âε≠½¨DϋcÄ?/p>

5εQéδΫçΨ|°φ•΅δΜ?/p>
‰qôδΗΣφ•΅δögε¨ÖεêΪδΚÜγÉΠεΦïιΓΙε€®φ·èδΗΣφ•΅φΓΘδΗ≠ε΅ΚγéΑγö³δΫçΨ|°δΩΓφ¹·οΦ¨δΫ†εè·δΜΞεà©γî®ηΩôδΚ¦δΩΓφ¹·φùΞεè²δΗéε·ΙγÉΠεΦïγΜ™φû€γö³φé£εΚèψIJηΓ® 6 φ‰³ΓΛΚδΚÜηΩôδΗΣφ•΅δΜΕγö³Ψl™φû³

εàΑγ¦°εâçδΊ™φ≠ΔφàëδΜ§δΜ΄ΨlçδΚÜ Lucene δΗ≠γö³δΗΜηΠ¹γö³γÉΠεΦïφ•΅δΜΕγΜ™φû³οΦ¨εΗ¨φ€¦ηÉΫε·ΙδΫ†γêÜηß?Lucene γö³γâ©γêÜγö³ε≠‰ε²®Ψl™φû³φ€âφâÄεΗ°εä©ψÄ?/p>
γ¦°εâçεΖ≤γΜèφ€âιùûεΗΗεΛöγö³γüΞεêçγö³Ψl³γΜ΅φ≠Θε€®δΫΩγî® LuceneεQ¨φ·îεΠ²οΦ¨Lucene δΗ?Eclipse γö³εΗ°εä©γ≥ΜΨlüοΦ¨ιΚ»ù€¹γêÜεΖΞε≠ΠιôΔγö?OpenCourseWare φèêδΨ¦δΚÜφê€γ¥ΔεäüηÉΫψIJιÄöηΩ΅ι‰Öη·Μ‰qôγ·΅φ•΅γΪ†εQ¨εΗ¨φ€¦δΫ†ηÉΫε·Ι Lucene γö³γÉΠεΦïφ€ΚεàΕφ€âφâÄδΚÜηßΘεQ¨εΤàδΗîδΫ†δΦöεèëγéΑεà©γî?Lucene εà¦εΨèγ¥ΔεΦïφ‰·ιùûεΗΗγ°Äεçïγö³δΚ΄φÉÖψÄ?/p>
ε≠ΠδΙ†
- φ²®εè·δΜΞεè²ι‰Öφ€§φ•΅ε€® developerWorks εÖ®γêÉγΪôγ²ΙδΗäγö³ η΄±φ•΅εéüφ•΅ ψÄ?br />
- ε°ûφà‰ Lucene: εàùη·Ü Lucene δΜ΄γΜçδΚ?Lucene γö³δΗÄδΚ¦εüΚφ€§φΠ²εΩΒοΦ¨γ³ΕεêéεΦÄεèëδΚÜδΗÄδΗΣεΚîγî®γ®΄εΚèφΦîΫCόZΚÜεà©γî® Lucene εΜΚγΪ΄γ¥ΔεΦïρqΕε€®η·ΞγÉΠεΦïδΗä‰q¦ηΓ¨φê€γÉΠγö³ηΩ΅ΫE΄ψÄ?
- Parsing, indexing, and searching XML with Digester and Lucene φ‰?Otis Gospodnetic ε€?developerWorks δΗäεèëηΓ®γö³δΗÄΫ΄΅εÖ≥δΚéεà©γî?Lucene ε£?Digester φùΞφ™çδΫ?XML φ•΅φΓΘγö³φ•΅γΪ†ψÄ?
- IBM Search and Index APIs (SIAPI) for WebSphere Information Integrator OmniFind Edition φ‰?Srinivas Varma Chitiveli ε€?developerWorks δΗäεèëηΓ®γö³δΗÄΫ΄΅εÖ≥δΚéεΠ²δΫïγî® SIAPI φùΞφû³εΜΚφê€γ¥ΔηßΘεÜœx•ΙφΓàγö³φ•΅γΪ†ψÄ?
- Luceneγö³ε°‰φ•ΙγΫëγΪ?/a>εQöδΗäιùΔφ€âεΛßι΅èγö?Lucene εΗ°εä©φ•΅φΓΘψÄ?
- δΗÄδΗΣεÖ≥δΚ?Lucene γö³φΦîη°?/a>εQöφ‰·γî?Lucene φ€Äεàùγö³δΫ€ηÄ?Doug Cutting ε€?Pisa εΛßε≠ΠφâÄδΫ€ψÄ?
- γéνCΜΘδΩΓφ¹·΄²Äγ¥?/em>φ‰·γî± Ricardo Baeza-Yates ε£?Berthier Ribeiro-Neto φâÄεÜôγö³εÖ≥δΚéδΩΓφ¹·΄²Äγ¥Δφ•ΙιùΔγö³δΗÄφ€§ηë½δΫ€ψÄ?
- developerWorks Web Architecture δΗ™ε¨ΚεQöδΗäιùΔφ€âεΨàεΛöεÖ≥δΚéεΠ²δΫïφû³εΨèΨ|ëγΪôγö³φäÄφ€·φ•΅γΪ†ψÄ?
- δΗÄδΗΣεÖ≥δΚ?Lucene γö³φΦîη°?/a>εQöφ‰·γî?Lucene φ€Äεàùγö³δΫ€ηÄ?Doug Cutting ε€?Pisa εΛßε≠ΠφâÄδΫ€ψÄ?
ηéΖεΨ½δΚßε™¹ε£¨φäÄφ€?/strong>
- δΗ΄ηù≤ Lucene φ€Äφ•Αγâàφ€§ψÄ?