sqlplus允許建立一個(gè)login.sql,通過設(shè)置環(huán)境變量SQLPATH,指向文件所在目錄,每次啟動(dòng)sqlplus都會(huì)執(zhí)行這個(gè)腳本。
CentOS 是 RHEL(Red Hat Enterprise Linux)源代碼再編譯的產(chǎn)物,而且在 RHEL 的基礎(chǔ)上修正了不少已知的 Bug ,相對(duì)于其他 Linux 發(fā)行版,其穩(wěn)定性值得信賴。
將上面所有文件(包括md5校驗(yàn)碼)下載到同一個(gè)目錄(文件夾)下。(這里,選擇了從CentOS的韓國(guó)鏡像站上下載。根據(jù)具體位置可以選擇距離近、速度快的景象站點(diǎn)。查找CentOS的鏡像請(qǐng)見
正態(tài)分布(normal distribution)
什么是正態(tài)分布
正態(tài)分布是一種概率分布。正態(tài)分布是具有兩個(gè)參數(shù)μ和σ2的連續(xù)型隨機(jī)變量的分布,第一參數(shù)μ是遵從正態(tài)分布的隨機(jī)變量的均值,第二個(gè)參數(shù)σ2是此隨機(jī)變量的方差,所以正態(tài)分布記作N(μ,σ2 )。遵從正態(tài)分布的隨機(jī)變量的概率規(guī)律為取 μ鄰近的值的概率大 ,而取離μ越遠(yuǎn)的值的概率越小;σ越小,分布越集中在μ附近,σ越大,分布越分散。正態(tài)分布的密度函數(shù)的特點(diǎn)是:關(guān)于μ對(duì)稱,在μ處達(dá)到最大值,在正(負(fù))無(wú)窮遠(yuǎn)處取值為0,在μ±σ處有拐點(diǎn)。它的形狀是中間高兩邊低 ,圖像是一條位于x 軸上方的鐘形曲線。當(dāng)μ=0,σ2 =1時(shí),稱為標(biāo)準(zhǔn)正態(tài)分布,記為N(0,1)。μ維隨機(jī)向量具有類似的概率規(guī)律時(shí),稱此隨機(jī)向量遵從多維正態(tài)分布。多元正態(tài)分布有很好的性質(zhì),例如,多元正態(tài)分布的邊緣分布仍為正態(tài)分布,它經(jīng)任何線性變換得到的隨機(jī)向量仍為多維正態(tài)分布,特別它的線性組合為一元正態(tài)分布。
正態(tài)分布的發(fā)展
正態(tài)分布是最重要的一種概率分布。正態(tài)分布概念是由德國(guó)的數(shù)學(xué)家和天文學(xué)家Moivre于1733年受次提出的,但由于德國(guó)數(shù)學(xué)家Gauss率先將其應(yīng)用于天文學(xué)家研究,故正態(tài)分布又叫高斯分布高斯這項(xiàng)工作對(duì)后世的影響極大,他使正態(tài)分布同時(shí)有了“高斯分布”的名稱,后世之所以多將最小二乘法的發(fā)明權(quán)歸之于他,也是出于這一工作。高斯是一個(gè)偉大的數(shù)學(xué)家,重要的貢獻(xiàn)不勝枚舉。但現(xiàn)今德國(guó)10馬克的印有高斯頭像的鈔票,其上還印有正態(tài)分布的密度曲線。這傳達(dá)了一種想法:在高斯的一切科學(xué)貢獻(xiàn)中,其對(duì)人類文明影響最大者,就是這一項(xiàng)。在高斯剛作出這個(gè)發(fā)現(xiàn)之初,也許人們還只能從其理論的簡(jiǎn)化上來評(píng)價(jià)其優(yōu)越性,其全部影響還不能充分看出來。這要到20世紀(jì)正態(tài)小樣本理論充分發(fā)展起來以后。皮埃爾-西蒙·拉普拉斯很快得知高斯的工作,并馬上將其與他發(fā)現(xiàn)的中心極限定理聯(lián)系起來,為此,他在即將發(fā)表的一篇文章(發(fā)表于1810年)上加上了一點(diǎn)補(bǔ)充,指出如若誤差可看成許多量的疊加,根據(jù)他的中心極限定理,誤差理應(yīng)有高斯分布。這是歷史上第一次提到所謂“元誤差學(xué)說”——誤差是由大量的、由種種原因產(chǎn)生的元誤差疊加而成。后來到1837年,海根(G.Hagen)在一篇論文中正式提出了這個(gè)學(xué)說。
其實(shí),他提出的形式有相當(dāng)大的局限性:海根把誤差設(shè)想成個(gè)數(shù)很多的、獨(dú)立同分布的“元誤差” 之和,每只取兩值,其概率都是1/2,由此出發(fā),按狄莫佛的中心極限定理,立即就得出誤差(近似地)服從正態(tài)分布。皮埃爾-西蒙·拉普拉斯所指出的這一點(diǎn)有重大的意義,在于他給誤差的正態(tài)理論一個(gè)更自然合理、更令人信服的解釋。因?yàn)椋咚沟恼f法有一點(diǎn)循環(huán)論證的氣味:由于算術(shù)平均是優(yōu)良的,推出誤差必須服從正態(tài)分布;反過來,由后一結(jié)論又推出算術(shù)平均及最小二乘估計(jì)的優(yōu)良性,故必須認(rèn)定這二者之一(算術(shù)平均的優(yōu)良性,誤差的正態(tài)性) 為出發(fā)點(diǎn)。但算術(shù)平均到底并沒有自行成立的理由,以它作為理論中一個(gè)預(yù)設(shè)的出發(fā)點(diǎn),終覺有其不足之處。拉普拉斯的理把這斷裂的一環(huán)連接起來,使之成為一個(gè)和諧的整體,實(shí)有著極重大的意義。
正態(tài)分布的主要特征
1、集中性:正態(tài)曲線的高峰位于正中央,即均數(shù)所在的位置。
2、對(duì)稱性:正態(tài)曲線以均數(shù)為中心,左右對(duì)稱,曲線兩端永遠(yuǎn)不與橫軸相交。
3、均勻變動(dòng)性:正態(tài)曲線由均數(shù)所在處開始,分別向左右兩側(cè)逐漸均勻下降。
4、正態(tài)分布有兩個(gè)參數(shù),即均數(shù)μ和標(biāo)準(zhǔn)差σ,可記作N(μ,σ):均數(shù)μ決定正態(tài)曲線的中心位置;標(biāo)準(zhǔn)差σ決定正態(tài)曲線的陡峭或扁平程度。σ越小,曲線越陡峭;σ越大,曲線越扁平。
5、u變換:為了便于描述和應(yīng)用,常將正態(tài)變量作數(shù)據(jù)轉(zhuǎn)換。
正態(tài)分布的應(yīng)用
1.估計(jì)正態(tài)分布資料的頻數(shù)分布
例1.某地1993年抽樣調(diào)查了100名18歲男大學(xué)生身高(cm),其均數(shù)=172.70cm,標(biāo)準(zhǔn)差s=4.01cm,①估計(jì)該地18歲男大學(xué)生身高在168cm以下者占該地18歲男大學(xué)生總數(shù)的百分?jǐn)?shù);②分別求 、
、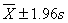 、
、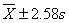 范圍內(nèi)18歲男大學(xué)生占該地18歲男大學(xué)生總數(shù)的實(shí)際百分?jǐn)?shù),并與理論百分?jǐn)?shù)比較。
范圍內(nèi)18歲男大學(xué)生占該地18歲男大學(xué)生總數(shù)的實(shí)際百分?jǐn)?shù),并與理論百分?jǐn)?shù)比較。
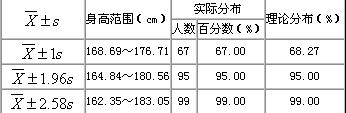
本例,μ、σ未知但樣本含量n較大,按式(3.1)用樣本均數(shù)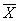 和標(biāo)準(zhǔn)差S分別代替μ和σ,求得u值,u=(168-172.70)/4.01=-1.17。查附表標(biāo)準(zhǔn)正態(tài)曲線下的面積,在表的左側(cè)找到-1.1,表的上方找到0.07,兩者相交處為0.1210=12.10%。該地18歲男大學(xué)生身高在168cm以下者,約占總數(shù)12.10%。其它計(jì)算結(jié)果見表3.1。
和標(biāo)準(zhǔn)差S分別代替μ和σ,求得u值,u=(168-172.70)/4.01=-1.17。查附表標(biāo)準(zhǔn)正態(tài)曲線下的面積,在表的左側(cè)找到-1.1,表的上方找到0.07,兩者相交處為0.1210=12.10%。該地18歲男大學(xué)生身高在168cm以下者,約占總數(shù)12.10%。其它計(jì)算結(jié)果見表3.1。
表:1100名18歲男大學(xué)生身高的實(shí)際分布與理論分布
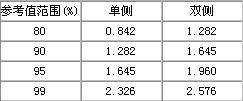
2.制定醫(yī)學(xué)參考值范圍:亦稱醫(yī)學(xué)正常值范圍。它是指所謂“正常人”的解剖、生理、生化等指標(biāo)的波動(dòng)范圍。制定正常值范圍時(shí),首先要確定一批樣本含量足夠大的 “正常人”,所謂“正常人”不是指“健康人”,而是指排除了影響所研究指標(biāo)的疾病和有關(guān)因素的同質(zhì)人群;其次需根據(jù)研究目的和使用要求選定適當(dāng)?shù)陌俜纸缰担?0%,90%,95%和99%,常用95%;根據(jù)指標(biāo)的實(shí)際用途確定單側(cè)或雙側(cè)界值,如白細(xì)胞計(jì)數(shù)過高過低皆屬不正常須確定雙側(cè)界值,又如肝功中轉(zhuǎn)氨酶過高屬不正常須確定單側(cè)上界,肺活量過低屬不正常須確定單側(cè)下界。另外,還要根據(jù)資料的分布特點(diǎn),選用恰當(dāng)?shù)挠?jì)算方法。常用方法有:
(1)正態(tài)分布法:適用于正態(tài)或近似正態(tài)分布的資料。
雙側(cè)界值: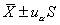 單側(cè)上界:
單側(cè)上界: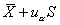 ,或單側(cè)下界:
,或單側(cè)下界: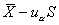
(2)對(duì)數(shù)正態(tài)分布法:適用于對(duì)數(shù)正態(tài)分布資料。
雙側(cè)界值: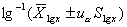 ;單側(cè)上界:
;單側(cè)上界: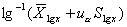 ,或單側(cè)下界:
,或單側(cè)下界: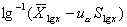 。
。
常用u值可根據(jù)要求由表3.2查出。
(3)百分位數(shù)法:常用于偏態(tài)分布資料以及資料中一端或兩端無(wú)確切數(shù)值的資料。
雙側(cè)界值:P2.5和P97.5;單側(cè)上界:P95,或單側(cè)下界:P5。
表:常用u值表
3.正態(tài)分布是許多統(tǒng)計(jì)方法的理論基礎(chǔ):如t分布、F分布、分布都是在正態(tài)分布的基礎(chǔ)上推導(dǎo)出來的,u檢驗(yàn)也是以正態(tài)分布為基礎(chǔ)的。此外,t分布、二項(xiàng)分布、Poisson分布的極限為正態(tài)分布,在一定條件下,可以按正態(tài)分布原理來處理。
http://baike.baidu.com/view/1052684.htm
均值
統(tǒng)計(jì)學(xué)術(shù)語(yǔ),與“平均”(***erage)意義相同。例如: l、3、6,10、20這5個(gè)數(shù)字的均值是8。
http://wiki.mbalib.com/wiki/%E6%96%B9%E5%B7%AE
方差(Variance)
什么是方差
方差和標(biāo)準(zhǔn)差是測(cè)度數(shù)據(jù)變異程度的最重要、最常用的指標(biāo)。
方差是各個(gè)數(shù)據(jù)與其算術(shù)平均數(shù)的離差平方和的平均數(shù),通常以σ2表示。方差的計(jì)量單位和量綱不便于從經(jīng)濟(jì)意義上進(jìn)行解釋,所以實(shí)際統(tǒng)計(jì)工作中多用方差的算術(shù)平方根——標(biāo)準(zhǔn)差來測(cè)度統(tǒng)計(jì)數(shù)據(jù)的差異程度。
標(biāo)準(zhǔn)差又稱均方差,一般用σ表示。方差和標(biāo)準(zhǔn)差的計(jì)算也分為簡(jiǎn)單平均法和加權(quán)平均法,另外,對(duì)于總體數(shù)據(jù)和樣本數(shù)據(jù),公式略有不同。
方差的計(jì)算公式
設(shè)總體方差為σ2,對(duì)于未經(jīng)分組整理的原始數(shù)據(jù),方差的計(jì)算公式為:
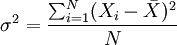
對(duì)于分組數(shù)據(jù),方差的計(jì)算公式為:
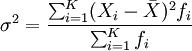
方差的平方根即為標(biāo)準(zhǔn)差,其相應(yīng)的計(jì)算公式為:
未分組數(shù)據(jù):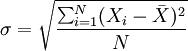
分組數(shù)據(jù):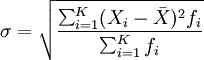
樣本方差和標(biāo)準(zhǔn)差
樣本方差與總體方差在計(jì)算上的區(qū)別是:總體方差是用數(shù)據(jù)個(gè)數(shù)或總頻數(shù)去除離差平方和,而樣本方差則是用樣本數(shù)據(jù)個(gè)數(shù)或總頻數(shù)減1去除離差平方和,其中樣本數(shù)據(jù)個(gè)數(shù)減1即n-1稱為自由度。設(shè)樣本方差為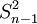 ,根據(jù)未分組數(shù)據(jù)和分組數(shù)據(jù)計(jì)算樣本方差的公式分別為:
,根據(jù)未分組數(shù)據(jù)和分組數(shù)據(jù)計(jì)算樣本方差的公式分別為:
未分組數(shù)據(jù):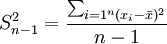
分組數(shù)據(jù):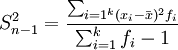
未分組數(shù)據(jù):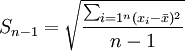
分組數(shù)據(jù):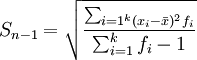
例:考察一臺(tái)機(jī)器的生產(chǎn)能力,利用抽樣程序來檢驗(yàn)生產(chǎn)出來的產(chǎn)品質(zhì)量,假設(shè)搜集的數(shù)據(jù)如下:
| 3.43 |
3.45 |
3.43 |
3.48 |
3.52 |
3.50 |
3.39 |
| 3.48 |
3.41 |
3.38 |
3.49 |
3.45 |
3.51 |
3.50 |
根據(jù)該行業(yè)通用法則:如果一個(gè)樣本中的14個(gè)數(shù)據(jù)項(xiàng)的方差大于0.005,則該機(jī)器必須關(guān)閉待修。問此時(shí)的機(jī)器是否必須關(guān)閉?
解:根據(jù)已知數(shù)據(jù),計(jì)算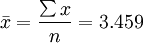
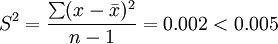
因此,該機(jī)器工作正常。
方差和標(biāo)準(zhǔn)差也是根據(jù)全部數(shù)據(jù)計(jì)算的,它反映了每個(gè)數(shù)據(jù)與其均值相比平均相差的數(shù)值,因此它能準(zhǔn)確地反映出數(shù)據(jù)的離散程度。方差和標(biāo)準(zhǔn)差是實(shí)際中應(yīng)用最廣泛的離散程度測(cè)度值。
---------------------------------------------------------------------
http://zh.wikipedia.org/wiki/%E6%96%B9%E5%B7%AE
方差
維基百科,自由的百科全書
在概率論和統(tǒng)計(jì)學(xué)中,一個(gè)隨機(jī)變量的“方差”描述的是它的離散程度,也就是該變量離其期望值的距離。 一個(gè)實(shí)隨機(jī)變量的方差也稱為它的二階距,恰巧也是它的二階culmulent。 方差的算術(shù)平方根稱為該隨機(jī)變量的標(biāo)準(zhǔn)差。
[編輯] 定義
設(shè) X 為服從分布 F 的隨機(jī)變量,則稱 Var(X) = E(X − EX)2 為隨機(jī)變量 X 或者分布 F 的方差。
如果 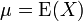 是隨機(jī)變數(shù) X 的期望值 (平均數(shù)) , 則其變異數(shù)為:
是隨機(jī)變數(shù) X 的期望值 (平均數(shù)) , 則其變異數(shù)為: 
[編輯] 特性
在樣本空間Ω上存在有限期望和方差的隨機(jī)變量構(gòu)成一個(gè)希爾伯特空間: L^2(Ω, dP),不過這里的內(nèi)積和長(zhǎng)度跟方差,標(biāo)準(zhǔn)差還是不大一樣。 所以,我們得把這個(gè)空間“除”常變量構(gòu)成的子空間,也就是說把相差一個(gè)常數(shù)的 所有原來那個(gè)空間的隨機(jī)變量做成一個(gè)等價(jià)類。這還是一個(gè)新的無(wú)窮維線性空間, 并且有一個(gè)從老空間內(nèi)積誘導(dǎo)出來的新內(nèi)積,而這個(gè)內(nèi)積就是方差
[編輯] 一般化
如果X是一個(gè)向量其取值范圍在Rn空間,并且其每個(gè)元素都是一個(gè)一維隨機(jī)變量,我們就把X稱為隨機(jī)向量。隨機(jī)向量的方差是一維隨機(jī)變量方差的自然推廣,其定義為E[(X − μ)(X − μ)T], 其中 μ = E(X) ,XT是X的轉(zhuǎn)秩. 這個(gè)方差是一個(gè)非負(fù)定方陣,通常稱為協(xié)方差矩陣。
如果X是一個(gè)復(fù)隨機(jī)變量,那么其方差定義則為E[(X − μ)(X − μ)*], 其中X*是X的復(fù)共軛向量。根據(jù)這個(gè)定義,方差為實(shí)數(shù)。
[編輯] 歷史
方差這個(gè)詞首先由Ronald Fisher在論文The Correlation Between Relatives on the Supposition of Mendelian Inheritance中引入.
[編輯] 參考出處
- ^ Press, W. H., Teukolsky, S. A., Vetterling, W. T. & Flannery, B. P. (1986) Numerical recipes: The art of scientific computing. Cambridge: Cambridge University Press. (online)
posted @
2009-03-12 22:51 donnie 閱讀(10899) |
評(píng)論 (0) |
編輯 收藏
工作若干年以來,荒廢了太多時(shí)間,昨天上課聽項(xiàng)目管理老師講到計(jì)劃,何不把日常學(xué)習(xí)也來計(jì)劃一下呢。
于是,訂計(jì)劃若干,時(shí)間涵蓋工作時(shí)間、晚上。 唯無(wú)人監(jiān)督,看我能堅(jiān)持多久,做記號(hào)。
看cd學(xué)日語(yǔ),大概瀏覽了一下, 寫法并不是十分特殊,要記的基礎(chǔ)比較多,發(fā)音要適應(yīng)一下。
起因:掉電。
現(xiàn)象:系統(tǒng)文件多找不到。
恢復(fù):嘗試修復(fù)文件系統(tǒng),失敗;
安裝盤引導(dǎo)修復(fù),失敗;
安裝盤引導(dǎo),覆蓋安裝,失敗;
安裝盤引導(dǎo),全新安裝,成功。tips: 定制安裝;手動(dòng)設(shè)置分區(qū),保留原raid設(shè)置。