 2008年8月11日
2008年8月11日
=單例模式=

單例模式需要考慮的重要問題是其生存周期問題,一種是不死鳥,永遠不銷毀,最為簡單,但是占用了資源
另一種是有生存周期, 但是又要考慮其引用可能無效的問題
* Lifetime: Dead reference
* Double check locking
=工廠模式=
工廠模式是很常用的模式, 常見的有
*簡單工廠
*抽象工廠
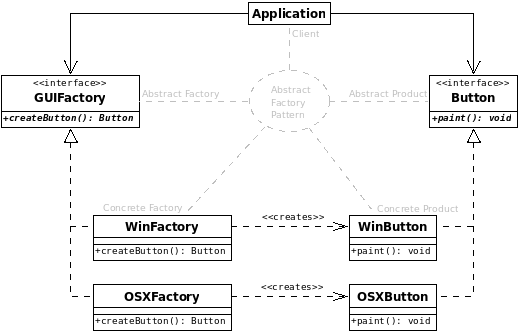
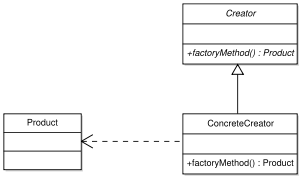
*工廠方法
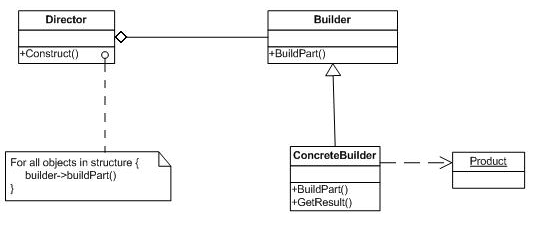
=生成器模式=
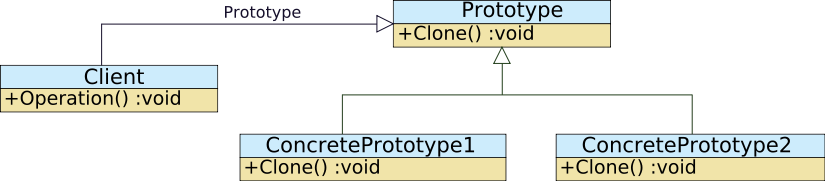
=原型模式=
這里只是簡單地用相應類圖來表示, 個中滋味, 在應用中自己慢慢體會吧
相似的一點是抽象的東西有具體的實現, 至于到底用哪個具體的實現, 交給工廠來創建吧
至于這個工廠, 視問題域的復雜性,可以是抽象的, 也可以是具體的,工廠模式大體如此
General Responsibility Assignment
Software Patterns 通用職責分配軟件模式
|
模式名稱
|
描述(問題/解決方案)
|
|
信息專家模式Information Expert
|
問題:對象設計和職責分配的一般原則是什么?
解決方案:將職責分配給擁有履行一個職責所必需信息的類--即信息專家。(也就是將職責分配給一個類,這個類必須擁有履行這個職責所需要的信息。)
|
|
創建者模式Creator
|
問題:誰應該負責產生類的實例(對應于GoF設計模式系列里的“工廠模式”)
解決方案:如果符合下面的一個或多個條件,則將創建類A實例的職責分配給類B.
.類B聚合類A的對象。
.類B包含類A的對象。
.類B記錄類A對象的實例。
.類B密切使用類A的對象。
.類B初始化數據并在創建類A的實例時傳遞給類A(類B是創建類A實例的一個專家)。
在以上情況下,類B是類A對象的創建者。
|
|
控制器模式
Controller
|
問題:誰處理一個系統事件?
解決方案:當類代表下列一種情況時,為它分配處理系統事件消息的職責。
.代表整個系統、設備或子系統(外觀控制器)。
.代表系統事件發生的用例場景(用例或回話控制器)。
|
|
低耦合Low Coupling
|
問題:如何支持低依賴性以及增加重用性?
解決方案:分配職責時使(不必要的)耦合保持為最低。
|
|
高內聚High Cohesion
|
問題:如何讓復雜性可管理?
解決方案:分配職責時使內聚保持為最高。
|
|
多態模式Polymorphism
|
問題:當行為隨類型變化而變化時誰來負責處理這些變化?
解決方案:當類型變化導致另一個行為或導致行為變化時,應用多態操作將行為的職責分配到引起行為變化的類型。
|
|
純虛構模式Pure Fabrication
|
問題:當不想破壞高內聚和低耦合的設計原則時,誰來負責處理這些變化?
解決方案:將一組高內聚的職責分配給一個虛構的或處理方便的“行為”類,它并不是問題域中的概念,而是虛構的事務,以達到支持高內聚、低耦合和重用的目的。
|
|
中介模式Indirection
|
問題:如何分配職責以避免直接耦合?
解決方案:分配職責給中間對象以協調組件或服務之間的操作,使得它們不直接耦合。
|
|
受保護變化模式Protected Variations
|
問題:如何分配職責給對象、子系統和系統,使得這些元素中的變化或不穩定的點不會對其他元素產生不利影響?
解決方案:找出預計有變化或不穩定的元素,為其創建穩定的“接口”而分配職責。
|
這些更象是一些OOD的原則, 模式會有很多, 但是萬變不離其宗, 大都遵循著一些基本的原則
-
OCP(Open-Closed Principle)
- DIP(Dependency Inversion
Principle)
-
LSP(Liskov Substitution
Principle)
- ISP(Interface Insolation
Principle)
- SRP(Single Resposibility
Principle)
- CARP(Composite/Aggregate Reuse
Principle)
- LoD(Law Of Demeter):don't talk
to stranger
之后我們來詳細討論這些原則
2008年8月10日
大名鼎鼎的GOF的設計模式是最著名的一本里程碑的作品
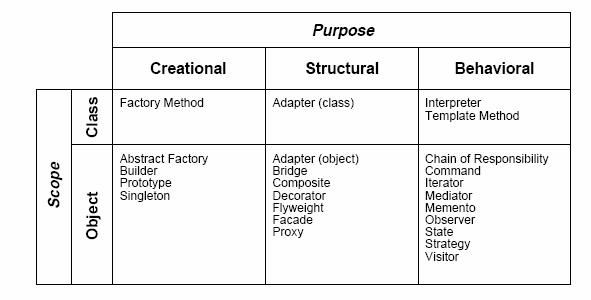
=模式分類=
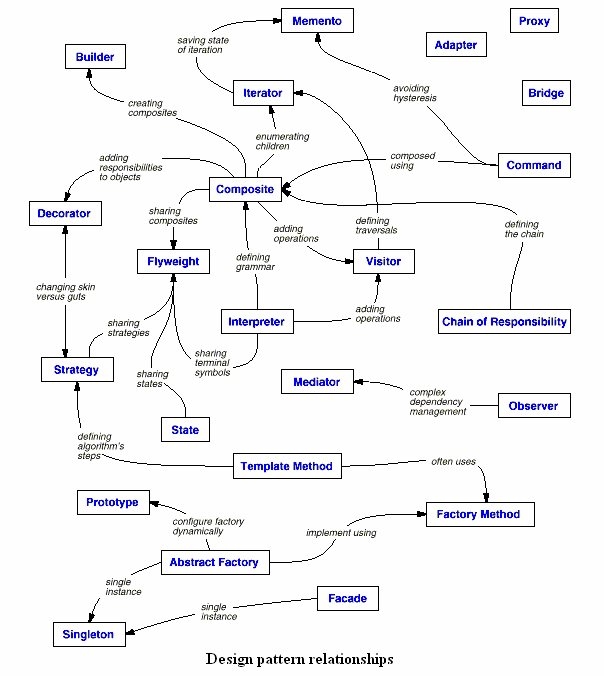
=模式之間的關系=
=如何應用模式=
DP中的引言說得很好,如何應該模式來解決設計問題
* 尋找合適的對象
對象包括數據和操作, 對象在收到請求(或消息)后, 執行相應的操作
客戶請求是使對象執行操作的唯一方法, 操作又是對象改變內部數據的唯一方法
(這就是封裝的意義,之所以強調對象的成員應該是私有的原因)
OOD最困難的部分就是將系統分解成對象集合,因為要考慮許多因素:
封裝,粒度,信賴關系,靈活性,性能,演化,復用等等,它們之間也互相有所影響或沖突.
設計模式可以幫助我們確定那些并不明顯的抽象和描述這些抽象的對象,如Strategy, State,etc.
==決定對象的粒度==
如何決定對象的大小,數目以及范圍呢, 設計模式亦有所幫助:
Facade 描述了怎樣用對象表示完整的子系統
Flyweight
Abstact Factory
Builder
Visitor
Command
==指定對象接口==
對象接口描述了該對象所能接受的全部請求的集合, 也就是它能夠提供哪些服務(方法)
當給對象發送請求時, 所引起的具體操作既與請求本身有關,又與接受對象有關
支持相同請求的不同對象可能對請求激發的操作有不同的實現(動態綁定和多態)
而設計模式通過確定接口的主要組成部分及經接口發送的數據類型, 來幫助你定義接口.
DP也許還會告訴你接口中不應包括哪些東西, 比如Memento模式所規定的接口
DP也指定了接口之間的關系,特別地,它常要求一些類具有相同或相似的接口,或對一些類的接口作出一些限制
如Decorator, Proxy模式要求修飾/代理對象和被修飾/受代理的對象接口保持一致
Visitor模式中Vistor接口必須反映能訪問的對象的所有類
==描述對象的實現==
* 類繼承還是接口繼承呢
* 針對接口編程,而不是針對實現編程
==運用復用機制==
1.優先使用對象組合,而不是類繼承
2.委托
3.繼承和泛型的比較
==關聯運行時刻和編譯時刻的結構==
==設計應支持變化==
* 設計中常出現的問題
** 通過顯式地指定一個類來創建對象
*** Factory , Prototype
** 對特殊操作的依賴
*** Chain of Reponsibility, Command
** 對硬件和軟件平臺的依賴
*** Abstract Factory, Bridge
** 對對象表示或實現的依賴
** 算法依賴
** 緊耦合
*** Abstract Factory, command, facade, mediator, observere,chain of responsibility
** 通過生成子類來擴充功能
*** Bridge, Chain of Reponsibility, composite, Decorator, Observer, Strategy
** 不能方便地對類進行修改
*** Adapter, Decorator, visitor
=如何選擇設計模式=
* 考慮設計模式是如何解決設計問題的
* 瀏覽模式的意圖部分
* 研究模式怎樣互相關聯
* 研究目的相似的模式
* 檢查重新設計的原因
* 考慮你的設計中哪些是可變的
=怎樣使用設計模式=
* 大致瀏覽一遍模式
* 回頭研究結構部分
* 看代碼示例部分
* 選擇模式參考者的名字, 使它們在應用上下文中有意義
* 定義類
* 定義模式中專用于應用的操作名稱
* 實現執行模式中責任和協作的操作
啥叫模式? Patterns in solutions come from patterns in problems.
針對某一類經常出現的問題所采取的行之有效的解決方案
"A pattern is a solution to a problem in a context."
"Each pattern describes a problem which occurs over and over again in our environment, and then describes the core of the solution to that problem, in such a way that you can use this solution a million times over, without ever doing it the same way twice."(Christopher Alexander -- A Pattern Language)
模式的四個基本要素:
1. 模式名稱pattern name
2. 問題problem
3. 解決方案solution
4. 效果consequences
如何描述設計模式(十大特點)
1. 意圖:描述,別名
2. 動機:場景
3. 適用性: 什么情況下
4. 結構: 類圖, 序列圖
5. 參考者
6. 協作
7. 效果
8. 實現
9. 應用
10. 相關模式
在實踐中學習是最佳的方式, 所以先要掌握每個模式的十大特點,更加重要的是在實際應用中學習, 在水中學會游泳
以迭代器模式為例, Java中有一個Iterator接口
1 public interface Iterator
2 {
3 /**
4 * Tests whether there are elements remaining in the collection. In other
5 * words, calling <code>next()</code> will not throw an exception.
6 *
7 * @return true if there is at least one more element in the collection
8 */
9 boolean hasNext();
10
11 /**
12 * Obtain the next element in the collection.
13 *
14 * @return the next element in the collection
15 * @throws NoSuchElementException if there are no more elements
16 */
17 Object next();
18
19 /**
20 * Remove from the underlying collection the last element returned by next
21 * (optional operation). This method can be called only once after each
22 * call to <code>next()</code>. It does not affect what will be returned
23 * by subsequent calls to next.
24 *
25 * @throws IllegalStateException if next has not yet been called or remove
26 * has already been called since the last call to next.
27 * @throws UnsupportedOperationException if this Iterator does not support
28 * the remove operation.
29 */
30 void remove();
31 }
32
假如你的類中有一些聚集關系, 那么考慮增加一個iterator方法,以實現下面這個接口
public interface Iterable
{
/**
* Returns an iterator for the collection.
*
* @return an iterator.
*/
Iterator iterator ();
}
返回你自己實現的ConcreteIterator類, 這個ConcreteIterator當然是實現了
Iterator接口的
你會發現在遍歷和迭代類中的這個成員的聚集元素時會有不同的感覺, 因為這個Iterator與實現是分離的.
你的類終歸是給自己或別人使用的,在調用者的眼里, 非常簡單, 管你里面是怎么實現的呢,
反正我知道你能給我一個迭代器就夠了, 這里面就體現了面向接口編程的好處. 也就是按契約編程
2008年7月26日
自Java5以來提供的
BlockingQueue是一種特殊的隊列, 它 是支持兩個附加操作的
Queue,這兩個操作是:檢索元素時等待隊列變為非空,以及存儲元素時等待空間變得可用。
以JDK中的例子略加改寫如下
1 import java.util.concurrent.ArrayBlockingQueue;
2 import java.util.concurrent.BlockingQueue;
3
4 class Producer implements Runnable {
5 private final BlockingQueue queue;
6
7 Producer(BlockingQueue q) {
8 queue = q;
9 }
10
11 public void run() {
12 try {
13 while (true) {
14 queue.put(produce());
15 }
16 } catch (InterruptedException ex) {
17 System.out.println("produce interrupted " + ex.getMessage());
18 Thread.currentThread().interrupt();
19 //return;
20 }
21 }
22
23 Object produce() {
24 System.out.println("produce laugh");
25 return "haha";
26 }
27 }
28
29 class Consumer implements Runnable {
30 private final BlockingQueue queue;
31
32 Consumer(BlockingQueue q) {
33 queue = q;
34 }
35
36 public void run() {
37 try {
38 while (true) {
39 consume(queue.take());
40 }
41 } catch (InterruptedException ex) {
42 System.out.println("consume interrupted " + ex.getMessage());
43 Thread.currentThread().interrupt();
44 }
45 }
46
47 void consume(Object x) {
48 System.out.println("consume laugh "+ x);
49 }
50 }
51
52 public class BlockingQueueTest {
53 public static void main(String args[]) {
54 BlockingQueue q = new ArrayBlockingQueue(10);
55 Producer p = new Producer(q);
56 Consumer c1 = new Consumer(q);
57 Consumer c2 = new Consumer(q);
58 Thread pTh = new Thread(p);
59 pTh.start();
60 Thread cTh1 = new Thread(c1);
61 cTh1.start();
62 Thread cTh2 = new Thread(c2);
63 cTh2.start();
64 try {
65 Thread.sleep(3000);
66 }catch (Exception e) {
67 // TODO: handle exception
68 }
69 pTh.interrupt();
70 cTh1.interrupt();
71 cTh2.interrupt();
72 }
73 }
74
2008年7月2日
Debug中的推理:假設,預測,試驗,觀察,結論
1.觀察錯誤
2.大膽假設
3.小心求證
4.假設成立則修正錯誤
假設推翻則重新假設
例如
1.如發現內存泄漏
2.假設A處創建的對象沒有釋放
3.屏蔽掉A處代碼,重新編譯,觀察內存使用情況
4.相同條件下內存已經不再泄漏了, 則添加代碼來釋放A處創建的對象
反之,相同條件下內存還再泄漏,則內存泄漏仍有其他原因,重新假設
(不排除A處有錯誤,只有還存在錯誤)
推理的四種方法
1.演繹(零運行過程)
2.觀察(一次運行過程)
3.歸納(多次運行過程)
4.試驗(多次可控制的運行過程)
假設的依據
1.問題描述
2.程序代碼
3.故障運行過程
4.參照運行過程
5.之前的假設
記錄每一個假設和每一次的試驗,防止遺忘,浪費精力做重復的事
在試驗時注意簡化,不一定要運行整個龐大的應用程序,針對自己的想法,
剝離出一小段代碼單獨運行,偽造假定的輸出,觀察是否有假定的輸出
How to debug a program
# Track the problem
# Reproduce the failure
# Automate and simplify
# Find infection origins
# Focus on likely origins
# Isolate the infection chain
# Correct the defect.
==Links==
*Why program fail
http://books.google.com/books?vid=ISBN1558608664&printsec=frontcover#PPR13,M1
==Summary==
Chp1 How Failure Comes to Be
In general, a failure comes about in the four stages discussed in the following.
1.The programmer creates a defect
2.The defect causes an infection.
3.The infection propagates.
4.The infection causes a failure
Notevery defect results in an infection, and not every infection resultsin a failure. Hence, having no failures does not imply having nodefects. This is the curse of testing, as pointed out by Dijkstra. Testing can only show the presence of defects, but never their absence.
indeed, debugging is largely a search problem.
Chp 2 Tracking Problems
one of the key issues of software configuration management: to be able to recreate any given configuration any time
To separate fixes and features, use a version control system to keep fixes in branches and features in the main trunk.
Unless you have a problem-tracking system that neatly integrates withyour test suite, I recommend keeping test outcomes separate fromproblem reports.
problem-trackingsystems “should be usedexclusively as a place to store feedback whenyou cannot immediately modify the code.” Otherwise, you should create areproducible test case.
Six Stages of Debugging:
1. That can’t happen.
2. That doesn’t happen on my machine.
3. That shouldn’t happen.
4. Why does that happen?
5. Oh, I see.
6. How did that ever work?
Chp 3 Making Program Fail
A program can be typically decomposed into three layers:presentation layer,functionality layer,unit layer
The rule of thumb for testing :the friendlier an interface is to humans, the less friendly it is to automated test.
the big advantage of testing at the functionality layers is that theresults can be easily accessed and evaluated.Of course, this requiresthe program with a clear separation between presentation andfunctionality.
Whereas units are amongthe eldest concepts of programming, the concept of automated testing atthe unit level has seen a burst of interest only in the last few years.
Overall, the general principle of breaking a dependence is known as the dependence inversion principle, which can be summarized as depending on abstractions rather on details.
Test early,Test first, Test often ,Test enough
developers are unsuited to testing their own code
Chp 4 Reproducing the problem
Regarding problem reproduction, data as stored in files and/or databases is seldom an issue.
To make the test reusable, one should at least aim to automate input at the higher level
STRACE basicallyworks by diverting the calls to the operating system to wrapperfunctions that log the incoming and outgoing data.On a Linux system,all system calls use one single functionality—a specific interruptroutine that transfers control from the program to the system kernel.STRACE diverts this interrupt routine to do the logging.
Nondeterminism introduced by thread or process schedules is among the worst problems to face in debugging.
Some languages are more prone to Heisenbugs effect than others (inparticular, languages, where undefined behavior is part of thesemantics, such as C and C++).
Executing on a virtual machine gives the best possibilities for recording and replaying interaction.
Chp 5 Simplifing problem
Oncewe have reproduce a problem, we must simplify it—that is, we must findout which circumstances are not relevant for the problem and can thusbe omitted.
Our aim is to find a minimal set of circumstances to minimize a failure-inducing configuration.
ddmin is an instance of delta debugging—a general approach to isolate failure causes by narrowing down differences (deltas) between runs.
Delta debugging again is an instance of adaptive testing—a series oftests in which each test depends on the results of earlier tests.
Chp 6 Scientic Debugging
Being explicit is an important means toward understanding the problem at hand, starting with the problem statement.
Just stating the problem in whateverway makes you rethink your assumptions—and often reveals the essential clues
to the solution.
The idea of algorithmic debugging (also called declarative debugging) is to have a tool that guides the user along the debugging process interactively.
algorithmic debugging works best for functional and logical programming languages
within each iteration of the scientific method we must come up with a new hypothesis. This is the creative part of debugging: thinking about the many ways a failure could have come to be.
Deductionis reasoning from the general to the particular. It lies at the core ofall reasoning techniques. In program analysis, deduction is used forreasoning from the program code (or other abstractions) to concrete runs
In this book, we call any technique static analysis if it infers findings without executing the program—that is, the technique is based on deduction alone. In contrast, dynamic analysis techniques use actual executions.
As Nethercote (2004) points out, this distinction of whether a programis executed or not may be misleading. In particular, this raises theissue of what exactly is meant by “execution.” Instead, he suggeststhat static techniques
predict approximations of a program’s future; dynamic analysis remembersapproximations of a program’s past. Because in debugging we aretypically concerned about the past, most interesting debuggingtechniques fall into
the “dynamic” categories.
Inductionis reasoning from the particular to the general. In program analysis,induction is used to summarize multiple program runs (e.g.,a test suiteor random testing) to some abstraction that holds for all consideredprogram runs.
Chp 8 Observing Facts
When observing state, do not interfere. Know what and when to observe, and proceed systematically.
The"do . . . while" loop makes the macro body a single statement, forhaving code such as "if (debug) LOG(var);" work the intended way.
Watchpoints areexpensive. Because the debugger must verify the value of the watchedexpression after each instruction, a watchpoint implies a switchbetween the debugged processes and the debugger process for eachinstruction step. This slows down program execution by a factor of1,000 or more.
Chp 9 Tracking Origins
A common issue with observation tools(such as debuggers) is that theyexecute the program forward in time, whereas the programmer must reasonbackward in time.
Rather than accessing the program while itis running, an omniscient debuggerfirst executes the program and records its. Once the run is complete,the omniscient debugger loads the recording and makes it available forobservation
On average, dynamic slices are far more precise than static slices.
Chp 10 Assesrting Expectations
The basic idea of assertions is to have the computer do the observation
Overall,few techniques are as helpful for debugging as assertions, and no other technique has as many additional benefits.
Using the GNU C runtime library (default on Linux systems), one canavoid common errors related to heap use simply by setting anenvironment variable called MALLOC_CHECK_.
VALGRINDis built around an interpreter for x86 machinecode instructions. Itinterprets the machine instructions of the program to be debugged, andkeeps track of the used memory in so-called shadow memory.
an assertion is not the best way of checking critical results, in that an assertion can be turned off
an assertion is not the right way to check external conditions.
the current trend in software development is to trade performance for runtime safety wherever possible.
Chp 11 Detecting anomalies
code that is executed only in failing runs is more likely to contain the defect than code that is always executed.
Anomalies are neither defects nor failure causes but can strongly correlate with either.
2008年6月29日
2008年1月6日
由于工作上的原因,我不得不看大量別人寫的代碼,這是一件很痛苦的事,尤其是看既少文檔注釋,又無良好命名和結構的代碼.
有本書叫Code Reading,中文譯作代碼閱讀方法與實踐, 簡單瀏覽了一遍電子文檔, 感覺還是隔靴搔癢, 對提高代碼閱讀效率并無太大的幫助. 自己感覺還是以下方法有些幫助:
1. 把對代碼閱讀的認識用筆或wiki記下來, 最好根據功能結構分類,可畫些輔助理解的框圖或思維導圖
2. 利用UML工具反向生成些類圖,包圖, 還可自己動手畫一些流程圖,時序圖和協作圖
3. 利用調試工具,通過設斷點,單步調試,設觀察哨等手段看看到底它是怎么運行的
4. 寫一些簡單的測試程序,通過斷言,日志來驗證自己的判斷
5. 如有可能,和代碼的原作者或其他維護者一起做Code Review
附Code Reading目錄, 建議重點閱讀第10章, 希望多多提高自己,積累經驗,將來也可以寫一本關于代碼閱讀的書
第1章 導論
1.1 為什么以及如何閱讀代碼
1.2 如何閱讀本書
進階讀物
第2章 基本編程元素
2.1 一個完整的程序
2.2 函數和全局變量
2.3 while循環、條件和塊
2.4 switch語句
2.5 for循環
2.6 break和continue語句
2.7 字符和布爾型表達式
2.8 goto語句
2.9 小范圍重構
2.10 do循環和整型表達式
2.11 再論控制結構
進階讀物
第3章 高級C數據類型
3.1 指針
3.2 結構
3.3 共用體
3.4 動態內存分配
3.5 typedef聲明
進階讀物
第4章 C數據結構
4.1 向量
4.2 矩陣和表
4.3 棧
4.4 隊列
4.5 映射
4.6 集合
4.7 鏈表
4.8 樹
4.9 圖
進階讀物
第5章 高級控制流程
5.1 遞歸
5.2 異常
5.3 并行處理
5.4 信號
5.5 非局部跳轉
5.6 宏替換
進階讀物
第6章 應對大型項目
6.1 設計與實現技術
6.2 項目的組織
6.3 編譯過程和制作文件
6.4 配置
6.5 修訂控制
6.6 項目的專有工具
6.7 測試
進階讀物
第7章 編碼規范和約定
7.1 文件的命名及組織
7.2 縮進
7.3 編排
7.4 命名約定
7.5 編程實踐
7.6 過程規范
進階讀物
第8章 文檔
8.1 文檔的類型
8.2 閱讀文檔
8.3 文檔存在的問題
8.4 其他文檔來源
8.5 常見的開放源碼文檔格式
進階讀物
第9章 系統構架
9.1 系統的結構
9.2 控制模型
9.3 元素封裝
9.4 構架重用
進階讀物
第10章 代碼閱讀工具
10.1 正規表達式
10.2 用編輯器瀏覽代碼
10.3 用grep搜索代碼
10.4 找出文件的差異
10.5 開發自己的工具
10.6 用編譯器來協助代碼閱讀
10.7 代碼瀏覽器和美化器
10.8 運行期間的工具
10.9 非軟件工具
可用工具和進階讀物
第11章 一個完整的例子
11.1 概況
11.2 攻堅計劃
11.3 代碼重用
11.4 測試與調試
11.5 文檔
11.6 觀察報告
附錄A 代碼概況
附錄B 閱讀代碼的格言