一般情況下,URL 中的參數應使用 url 編碼規則,即把參數字符串中除了 -_. 之外的所有非字母數字字符都將被替換成百分號(%)后跟兩位十六進制數,空格則編碼為加號(+)。但是對于帶有中文的參數來說,這種編碼會使編碼后的字符串變得很長。如果希望有短一點的方式對參數編碼,可以采用 base64 編碼方式對字符串進行編碼,但是 base64 編碼方式不能處理 JavaScript 中的中文,因為 JavaScript 中的中文都是以 UTF-16 方式保存的。而 base64 只能處理單字節字符,所以不能直接用 base64 對帶有中文的 JavaScript 字符串進行編碼。但是可以通過 utf.js 這個程序中提供的 utf16to8 來將 UTF-16 編碼的中文先轉化為 UTF-8 方式,然后再進行 base64 編碼。這樣編碼后的字符串,在傳遞到服務器端后可以直接通過 base64_decode 解碼成 UTF-8 的中文字符串。但是還有個問題需要注意。base64 編碼中使用了加號(+),而 + 在 URL 傳遞時會被當成空格,因此必須要將 base64 編碼后的字符串中的加號替換成 %2B 才能當作 URL 參數進行傳遞。否則在服務器端解碼后就會出錯。
所以我們需要做的就是:
js中:encodeURI(str).replace(/\+/g,'%2B')
java中:str.replaceAll("\\+","%2B")
posted @
2013-12-17 11:03 kelly 閱讀(1542) |
評論 (0) |
編輯 收藏 將mysql數據文件導入到數據庫中:
1.在navicat 中創建一個mysql數據庫鏈接,填寫端口、用戶名、密碼
2.創建數據庫
3.打開數據庫
4.右鍵選擇“運行sql文件”
5.選擇sql文件的地址并執行
用navicat將mysql數據庫中的數據導出的兩種方法:
1.右鍵,轉儲sql文件,直接保存文件,不能設置執行選項。
2.右鍵,數據傳輸;如果只想導出數據庫表結構,不導出數據,可以把“數據傳輸”-》“高級”-》“記錄選項”中的勾去掉,則不會導出記錄。
posted @
2013-12-13 15:12 kelly 閱讀(292) |
評論 (0) |
編輯 收藏Windows 2008 R2默認是禁止Ping的,但是我們在日常中很多情況都需要用到Ping功能,這時候只需要打開Ping功能即可。
在防火期開啟的狀態下,怎樣才能ping呢?
開始-控制面板-管理工具-服務器管理器,如圖
選擇配置-高級安全 Windows 防火墻-入站規則:文件和打印機共享(回顯請求 - ICMPv4-In)(配置文件為域和公用的這條) 啟用該規則即可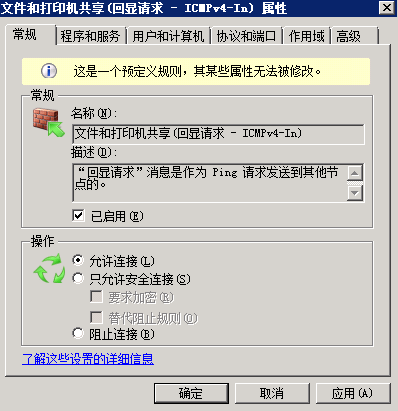 。
。
在本地測試一下:ping ip,已經通了!
posted @
2013-12-13 13:54 kelly 閱讀(281) |
評論 (0) |
編輯 收藏
改變applicationContext.xml中
<bean id="sqlMapClient" class="org.springframework.orm.ibatis.SqlMapClientFactoryBean">
<property name="configLocation">
<value>classpath:SqlMapConfig.xml</value>
</property>
<property name="dataSource">
<ref bean="dataSource"/>
</property>
< /bean>
中的
<value>classpath:SqlMapConfig.xml</value>
然后把SqlMapConfig.xml放到src下面
posted @
2013-12-05 13:39 kelly 閱讀(482) |
評論 (0) |
編輯 收藏全部刪除
如果是刪除某個表的所有數據,并且不需要回滾,使用 TRUNCATE 就ok了。關于Trancate 參見這里http://blog.csdn.net/gnolhh168/archive/2011/05/24/6442561.aspx
SQL> truncate table table_name;
條件刪除
如果刪除數據有條件,如 delete from tablename where col1 = 'lucy';這時除了加索引外, 你可以刪除時加NO LOGGING選項,不寫日志加快刪除速度
引用某人的一句話“幾千萬條記錄的表都不分區,明顯有問題嘛。Oracle的技術支持工程師建議,2,000,000條以上記錄的表,應該考慮分區,你完全可以按照時間為維度來建表,每個月的數據存放在一個分區表中,以后要刪除一個月的數據,直接truncate table即可,不記錄日志,速度很快。”
刪除大量重復記錄
《轉》做項目的時候,一位同事導數據的時候,不小心把一個表中的數據全都搞重了,也就是說,這個表里所有的記錄都有一條重復的。這個表的數據是千萬級的,而且是生產系統。也就是說,不能把所有的記錄都刪除,而且必須快速的把重復記錄刪掉。
對此,總結了一下刪除重復記錄的方法,以及每種方法的優缺點。
為了陳訴方便,假設表名為Tbl,表中有三列col1,col2,col3,其中col1,col2是主鍵,并且,col1,col2上加了索引。
1、通過創建臨時表
可以把數據先導入到一個臨時表中,然后刪除原表的數據,再把數據導回原表,SQL語句如下:
creat table tbl_tmp (select distinct* from tbl);
truncate table tbl; //清空表記錄i
nsert into tbl select * from tbl_tmp;//將臨時表中的數據插回來。
這種方法可以實現需求,但是很明顯,對于一個千萬級記錄的表,這種方法很慢,在生產系統中,這會給系統帶來很大的開銷,不可行。
2、利用rowid
在oracle中,每一條記錄都有一個rowid,rowid在整個數據庫中是唯一的,rowid確定了每條記錄是oracle中的哪一個數據文件、塊、行上。在重復的記錄中,可能所有列的內容都相同,但rowid不會相同。SQL語句如下:
delete from tbl where rowid in (select a.rowid
from tbl a, tbl b
where a.rowid>b.rowid and a.col1=b.col1 and a.col2 = b.col2)
如果已經知道每條記錄只有一條重復的,這個sql語句適用。但是如果每條記錄的重復記錄有N條,這個N是未知的,就要考慮適用下面這種方法了。
3、利用max或min函數
這里也要使用rowid,與上面不同的是結合max或min函數來實現。SQL語句如下
delete from tbl a
where rowid not in (
select max(b.rowid)
from tbl b
where a.col1=b.col1 and a.col2 = b.col2); //這里max使用min也可以
或者用下面的語句
delete from tbl awhere rowid<(
select max(b.rowid)
from tbl b
where a.col1=b.col1 and a.col2 = b.col2); //這里如果把max換成min的話,前面的where子句中需要把"<"改為">"
跟上面的方法思路基本是一樣的,不過使用了group by,減少了顯性的比較條件,提高效率。SQL語句如下:
deletefrom tbl where rowid not in (
select max(rowid)
from tbl tgroup by t.col1, t.col2);
delete from tbl where (col1, col2) in (
select col1,col2
from tblgroup bycol1,col2havingcount(*) >1) and rowidnotin(selectnin(rowid)fromtblgroup bycol1, col2havingcount(*) >1) ----???
還有一種方法,對于表中有重復記錄的記錄比較少的,并且有索引的情況,比較適用。假定col1,col2上有索引,并且tbl表中有重復記錄的記錄比較少,SQL語句如下4、利用group by,提高效率
posted @
2013-12-02 10:49 kelly 閱讀(387) |
評論 (0) |
編輯 收藏