看文檔:
Returns an estimated number of bytes that can be read or skipped without blocking for more input.
Note that this method provides such a weak guarantee that it is not very useful in practice.
Firstly, the guarantee is "without blocking for more input" rather than "without blocking": a read may still block waiting for I/O to complete — the guarantee is merely that it won't have to wait indefinitely for data to be written. The result of this method should not be used as a license to do I/O on a thread that shouldn't be blocked.
Secondly, the result is a conservative estimate and may be significantly smaller than the actual number of bytes available. In particular, an implementation that always returns 0 would be correct. In general, callers should only use this method if they'd be satisfied with treating the result as a boolean yes or no answer to the question "is there definitely data ready?".
Thirdly, the fact that a given number of bytes is "available" does not guarantee that a read or skip will actually read or skip that many bytes: they may read or skip fewer.
It is particularly important to realize that you must not use this method to size a container and assume that you can read the entirety of the stream without needing to resize the container. Such callers should probably write everything they read to a ByteArrayOutputStream and convert that to a byte array. Alternatively, if you're reading from a file, length() returns the current length of the file (though assuming the file's length can't change may be incorrect, reading a file is inherently racy).
The default implementation of this method in InputStream always returns 0. Subclasses should override this method if they are able to indicate the number of bytes available.
]]>
1 使用==運算符來判斷是否引用同一個對象。
2 使用instance of操作符來判斷參數是否是正確的類型。
3 將實參cast成正確的類型。
4 對于每個關鍵屬性,進行比較:
對于非float或double的primitive類型,使用==判斷等價性;
對于floa類型,先使用Float.floatToIntBits轉換成int類型,然后使用==比較int類型的值;
對于double類型,先使用Double.doubleToLongBits轉換成long類型,然后使用==比較long類型;
對于對象引用,遞歸的調用equals方法。
對于數組類型,對其中的元素進行上述的操作,或者使用Arrays.equals方法(version 1.5)。
為了避免NPE,可以使用
field == null ? o.field == null : fleld.equals(o.field);
重寫hashCode方法如下:
1 把某個非零常數值,例如17,保存在int變量result中;
2 對于對象中每一個關鍵域f(指equals方法中考慮的每一個域),計算散列碼c:
2.1 boolean型,計算(f ? 0 : 1);
2.2 byte,char,short型,計算(int);
2.3 long型,計算(int) (f ^ (f>>>32));
2.4 float型,計算Float.floatToIntBits(f);
2.5 double型,計算Double.doubleToLongBits(f)得到一個long,再執行[2.3];
2.6 對象引用,遞歸調用它的hashCode方法;
2.7 數組域,對其中每個元素按照上面的規則計算hash code。
3 將上面計算得到的散列碼保存到int變量c,然后執行 result=37*result+c;
4 返回result。
]]>
?2?
?3?public?class?SigTest?{
?4?
?5?????public?static?final?String?name?=?null;
?6?
?7?????public?int?getName(int[]?data,long?index)?{
?8?????????return?0;
?9?????}
10?}
11?
[calvin@calvin-desktop /tmp 15:59:50 ]
$ javac SigTest.java
[calvin@calvin-desktop /tmp 15:59:57 ]
$ javap -s -p -classpath . SigTest
Compiled from "SigTest.java"
public class com.demo.SigTest extends java.lang.Object{
public static final java.lang.String name;
? Signature: Ljava/lang/String;
public com.demo.SigTest();
? Signature: ()V
public int getName(int[], long);
? Signature: ([IJ)I
static {};
? Signature: ()V
}
-s表示打印簽名信息
-p表示打印所有函數和成員的簽名信息,默認只打印public的簽名信息。
注意:
粗體部分是.class文件的文件名,不要.class后綴,否則提示
ERROR:Could not find SigTest.class.
]]>
2?????????for(String?apple:appleList){
3?????????????//blabla
4?????????}
編譯器 complains:Type mismatch: cannot convert from element type Object to String
http://www.infoq.com/cn/articles/cf-java-generics
]]>
參見
http://java.sun.com/docs/codeconv/html/CodeConventions.doc2.html#1852
]]>
]]>
但是如果線程被阻塞了,它就不可能去主動去檢查變量了,這時要使用thread.interrupt來中斷線程嗎?
謹慎使用thread.interrupt方法!
因此,如果線程被上述幾種方法阻塞,正確的停止線程方式時設置共享變量,并調用interrupt()(注意變量應該先設置)。如果線程沒有被阻塞,這時調用interrupt()將不起作用;否則,線程就將得到異常(該線程必須事先預備好處理此狀況),接著逃離阻塞狀態。在任何一種情況中,線程最后都將檢查共享變量然后再停止。
中斷標志必須是volatile的,以便run方法能夠看到它,否則的話,這個值很有可能在本地有緩存。
線程代碼為:
2 while(running) {
4 try {
5 // do something may block...
9 } catch (InterruptedException e) {
10 running = false;
12 }
13
14 } //while
15 //
 .
. 16 }
需要停止線程時,調用:
2 thread.interrupt();
注意,一定要先設置標志位后再調用interrupt!
如果線程因為其他原因阻塞,例如socket.accept(),這時,調用interrupt不會拋出異常,又該如何處理?
這些情況下,需要分別處理,例如在socket上調用close方法,它將拋出一個SocketException,這與拋出InterruptException類似。
參考:
1、http://blog.csdn.net/nihaozhangchao/archive/2010/01/07/5147803.aspx
2、http://blog.chenlb.com/2009/07/incorrect-use-thread-interrupt-cause-not-exit.html
]]>
線程:是指進程中的一個執行流程。
線程與進程的區別:每個進程都需要操作系統為其分配獨立的內存地址空間,而同一進程中的所有線程在同一塊地址空間中工作,這些線程可以共享同一塊內存和系統資源。
如何創建一個線程?
創建線程有兩種方式,如下:
1、 擴展java.lang.Thread類
2、 實現Runnable接口
Thread類代表線程類,它的兩個最主要的方法是:
run()——包含線程運行時所執行的代碼
Start()——用于啟動線程
一個線程被創建后只能被啟動一次。第二次啟動時將會拋出java.lang.IllegalThreadExcetpion異常
線程間狀態的轉換
新建狀態:用new語句創建的線程對象處于新建狀態,此時它和其它的java對象一樣,僅僅在堆中被分配了內存
就緒狀態:當一個線程創建了以后,其他的線程調用了它的start()方法,該線程就進入了就緒狀態。處于這個狀態的線程位于可運行池中,等待獲得CPU的使用權
運行狀態:處于這個狀態的線程占用CPU,執行程序的代碼
阻塞狀態:當線程處于阻塞狀態時,java虛擬機不會給線程分配CPU,直到線程重新進入就緒狀態,它才有機會轉到運行狀態。
阻塞狀態分為三種情況:
1、 位于對象等待池中的阻塞狀態:當線程運行時,如果執行了某個對象的wait()方法,java虛擬機就回把線程放到這個對象的等待池中
2、 位于對象鎖中的阻塞狀態,當線程處于運行狀態時,試圖獲得某個對象的同步鎖時,如果該對象的同步鎖已經被其他的線程占用,JVM就會把這個線程放到這個對象的瑣池中。
3、 其它的阻塞狀態:
- 當前線程執行了sleep()方法
- 調用了其它線程的join()方法
- 發出了I/O請求時
或者正常退出
或者遇到異常退出
Thread類的isAlive()方法判斷一個線程是否活著,當線程處于死亡狀態或者新建狀態時,該方法返回false,在其余的狀態下,該方法返回true.
線程調度
線程調度模型:分時調度模型和搶占式調度模型
JVM采用搶占式調度模型。
所謂的多線程的并發運行,其實是指宏觀上看,各個線程輪流獲得CPU的使用權,分別執行各自的任務。
(線程的調度不是跨平臺,它不僅取決于java虛擬機,它還依賴于操作系統)
如果希望明確地讓一個線程給另外一個線程運行的機會,可以采取以下的辦法之一
1、 調整各個線程的優先級
2、 讓處于運行狀態的線程調用Thread.sleep()方法
3、 讓處于運行狀態的線程調用Thread.yield()方法
4、 讓處于運行狀態的線程調用另一個線程的join()方法
調整各個線程的優先級
Thread類的setPriority(int)和getPriority()方法分別用來設置優先級和讀取優先級。
如果希望程序能夠移值到各個操作系統中,應該確保在設置線程的優先級時,只使用MAX_PRIORITY、NORM_PRIORITY、MIN_PRIORITY這3個優先級。
線程睡眠:當線程在運行中執行了sleep()方法時,它就會放棄CPU,轉到阻塞狀態。
線程讓步:當線程在運行中執行了Thread類的yield()靜態方法時,如果此時具有相同優先級的其它線程處于就緒狀態,那么yield()方法將把當前運行的線程放到運行池中并使另一個線程運行。如果沒有相同優先級的可運行線程,則yield()方法什么也不做。
Sleep()方法和yield()方法都是Thread類的靜態方法,都會使當前處于運行狀態的線程放棄CPU,把運行機會讓給別的線程,兩者的區別在于:
1、sleep()方法會給其他線程運行的機會,而不考慮其他線程的優先級,因此會給較低線程一個運行的機會;yield()方法只會給相同優先級或者更高優先級的線程一個運行的機會。
2、當線程執行了sleep(long millis)方法后,將轉到阻塞狀態,參數millis指定睡眠時間;當線程執行了yield()方法后,將轉到就緒狀態。
3、sleep()方法聲明拋出InterruptedException異常,而yield()方法沒有聲明拋出任何異常
4、sleep()方法比yield()方法具有更好的移植性
等待其它線程的結束:join()
當前運行的線程可以調用另一個線程的 join()方法,當前運行的線程將轉到阻塞狀態,直到另一個線程運行結束,它才恢復運行。
定時器Timer:在JDK的java.util包中提供了一個實用類Timer, 它能夠定時執行特定的任務。
線程的同步
原子操作:根據Java規范,對于基本類型的賦值或者返回值操作,是原子操作。但這里的基本數據類型不包括long和double, 因為JVM看到的基本存儲單位是32位,而long 和double都要用64位來表示。所以無法在一個時鐘周期內完成。
自增操作(++)不是原子操作,因為它涉及到一次讀和一次寫。
原子操作:由一組相關的操作完成,這些操作可能會操縱與其它的線程共享的資源,為了保證得到正確的運算結果,一個線程在執行原子操作其間,應該采取其他的措施使得其他的線程不能操縱共享資源。
同步代碼塊:為了保證每個線程能夠正常執行原子操作,Java引入了同步機制,具體的做法是在代表原子操作的程序代碼前加上synchronized標記,這樣的代碼被稱為同步代碼塊。
同步鎖:每個JAVA對象都有且只有一個同步鎖,在任何時刻,最多只允許一個線程擁有這把鎖。
當一個線程試圖訪問帶有synchronized(this)標記的代碼塊時,必須獲得 this關鍵字引用的對象的鎖,在以下的兩種情況下,本線程有著不同的命運。
1、 假如這個鎖已經被其它的線程占用,JVM就會把這個線程放到本對象的鎖池中。本線程進入阻塞狀態。鎖池中可能有很多的線程,等到其他的線程釋放了鎖,JVM就會從鎖池中隨機取出一個線程,使這個線程擁有鎖,并且轉到就緒狀態。
2、 假如這個鎖沒有被其他線程占用,本線程會獲得這把鎖,開始執行同步代碼塊。
(一般情況下在執行同步代碼塊時不會釋放同步鎖,但也有特殊情況會釋放對象鎖
如在執行同步代碼塊時,遇到異常而導致線程終止,鎖會被釋放;在執行代碼塊時,執行了鎖所屬對象的wait()方法,這個線程會釋放對象鎖,進入對象的等待池中)
線程同步的特征:
1、 如果一個同步代碼塊和非同步代碼塊同時操作共享資源,仍然會造成對共享資源的競爭。因為當一個線程執行一個對象的同步代碼塊時,其他的線程仍然可以執行對 象的非同步代碼塊。(所謂的線程之間保持同步,是指不同的線程在執行同一個對象的同步代碼塊時,因為要獲得對象的同步鎖而互相牽制)
2、 每個對象都有唯一的同步鎖
3、 在靜態方法前面可以使用synchronized修飾符。
4、 當一個線程開始執行同步代碼塊時,并不意味著必須以不間斷的方式運行,進入同步代碼塊的線程可以執行Thread.sleep()或者執行Thread.yield()方法,此時它并不釋放對象鎖,只是把運行的機會讓給其他的線程。
5、 Synchronized聲明不會被繼承,如果一個用synchronized修飾的方法被子類覆蓋,那么子類中這個方法不在保持同步,除非用synchronized修飾。
線程安全的類:
1、 這個類的對象可以同時被多個線程安全的訪問。
2、 每個線程都能正常的執行原子操作,得到正確的結果。
3、 在每個線程的原子操作都完成后,對象處于邏輯上合理的狀態。
釋放對象的鎖:
1、 執行完同步代碼塊就會釋放對象的鎖
2、 在執行同步代碼塊的過程中,遇到異常而導致線程終止,鎖也會被釋放
3、 在執行同步代碼塊的過程中,執行了鎖所屬對象的wait()方法,這個線程會釋放對象鎖,進入對象的等待池。
死鎖
當一個線程等待由另一個線程持有的鎖,而后者正在等待已被第一個線程持有的鎖時,就會發生死鎖。JVM不監測也不試圖避免這種情況,因此保證不發生死鎖就成了程序員的責任。
如何避免死鎖
一個通用的經驗法則是:當幾個線程都要訪問共享資源A、B、C 時,保證每個線程都按照同樣的順序去訪問他們。
線程通信
Java.lang.Object類中提供了兩個用于線程通信的方法
1、 wait():執行了該方法的線程釋放對象的鎖,JVM會把該線程放到對象的等待池中。該線程等待其它線程喚醒
2、 notify():執行該方法的線程喚醒在對象的等待池中等待的一個線程,JVM從對象的等待池中隨機選擇一個線程,把它轉到對象的鎖池中。
]]>
]]>
]]>
]]>
]]>
]]>
]]>
]]>
]]>
]]>
]]>
]]>
]]>
]]>
]]>
]]>
可能大家都聽說過 Unicode、UCS-2、UTF-8 等等詞匯,但它們具體是什么意思, 是什么原理,之間有什么關系,恐怕就很少有人明白了。 下面就分別介紹一下它們。
基本知識
字節和字符的區別
Big Endian和Little Endian
UCS-2和UCS-4
UTF-16和UTF-32
UTF-16
UTF-32
UTF-8
基本知識
介紹Unicode之前,首先要講解一些基礎知識。雖然跟Unicode沒有直接的關系, 但想弄明白Unicode,沒這些還真不行。
字節和字符的區別
咦,字節和字符能有什么區別啊?不都是一樣的嗎?完全正確,但只是在古老的DOS時代。 當Unicode出現后,字節和字符就不一樣了。
字節(octet)是一個八位的存儲單元,取值范圍一定是0~255。而字符(character,或者word) 為語言意義上的符號,范圍就不一定了。例如在UCS-2中定義的字符范圍為0~65535, 它的一個字符占用兩個字節。
Big Endian和Little Endian
上面提到了一個字符可能占用多個字節,那么這多個字節在計算機中如何存儲呢? 比如字符0xabcd,它的存儲格式到底是 AB CD,還是 CD AB 呢?
實際上兩者都有可能,并分別有不同的名字。如果存儲為 AB CD,則稱為Big Endian; 如果存儲為 CD AB,則稱為Little Endian。
具體來說,以下這種存儲格式為Big Endian,因為值(0xabcd)的高位(0xab)存儲在前面:地址 值
0x00000000 AB
0x00000001 CD
相反,以下這種存儲格式為Little Endian:地址 值
0x00000000 CD
0x00000001 AB
UCS-2和UCS-4
Unicode是為整合全世界的所有語言文字而誕生的。任何文字在Unicode中都對應一個值, 這個值稱為代碼點(code point,參見Java核心技術的相關章節!)。代碼點的值通常寫成 U+ABCD 的格式。 而文字和代碼點之間的對應關系就是UCS-2(Universal Character Set coded in 2 octets)。 顧名思義,UCS-2是用兩個字節來表示代碼點,其取值范圍為 U+0000~U+FFFF。
為了能表示更多的文字,人們又提出了UCS-4,即用四個字節表示代碼點。 它的范圍為 U+00000000~U+7FFFFFFF,其中 U+00000000~U+0000FFFF和UCS-2是一樣的。
要注意,UCS-2和UCS-4只規定了代碼點和文字之間的對應關系,并沒有規定代碼點在計算機中如何存儲。 規定存儲方式的稱為UTF(Unicode Transformation Format),其中應用較多的就是UTF-16和UTF-8了。
UTF-16和UTF-32
UTF-16
UTF-16由RFC2781規定,它使用兩個字節來表示一個代碼點。
不難猜到,UTF-16是完全對應于UCS-2的,即把UCS-2規定的代碼點通過Big Endian或Little Endian方式 直接保存下來。UTF-16包括三種:UTF-16,UTF-16BE(Big Endian),UTF-16LE(Little Endian)。
UTF-16BE和UTF-16LE不難理解,而UTF-16就需要通過在文件開頭以名為BOM(Byte Order Mark)的字符 來表明文件是Big Endian還是Little Endian。BOM為U+FEFF這個字符。
其實BOM是個小聰明的想法。由于UCS-2沒有定義U+FFFE, 因此只要出現 FF FE 或者 FE FF 這樣的字節序列,就可以認為它是U+FEFF, 并且可以判斷出是Big Endian還是Little Endian。
舉個例子。“ABC”這三個字符用各種方式編碼后的結果如下:UTF-16BE 00 41 00 42 00 43
UTF-16LE 41 00 42 00 43 00
UTF-16(Big Endian) FE FF 00 41 00 42 00 43
UTF-16(Little Endian) FF FE 41 00 42 00 43 00
UTF-16(不帶BOM) 00 41 00 42 00 43
Windows平臺下默認的Unicode編碼為Little Endian的UTF-16(即上述的 FF FE 41 00 42 00 43 00)。 你可以打開記事本,寫上ABC,然后保存,再用二進制編輯器看看它的編碼結果。
另外,UTF-16還能表示一部分的UCS-4代碼點——U+10000~U+10FFFF。 表示算法比較復雜,簡單說明如下:
從代碼點U中減去0x10000,得到U'。這樣U+10000~U+10FFFF就變成了 0x00000~0xFFFFF。
用20位二進制數表示U'。 U'=yyyyyyyyyyxxxxxxxxxx
將前10位和后10位用W1和W2表示,W1=110110yyyyyyyyyy,W2=110111xxxxxxxxxx,則 W1 = D800~DBFF,W2 = DC00~DFFF。
例如,U+12345表示為 D8 08 DF 45(UTF-16BE),或者08 D8 45 DF(UTF-16LE)。
但是由于這種算法的存在,造成UCS-2中的 U+D800~U+DFFF 變成了無定義的字符。
UTF-32
UTF-32用四個字節表示代碼點,這樣就可以完全表示UCS-4的所有代碼點,而無需像UTF-16那樣使用復雜的算法。 與UTF-16類似,UTF-32也包括UTF-32、UTF-32BE、UTF-32LE三種編碼,UTF-32也同樣需要BOM字符。 僅用'ABC'舉例:UTF-32BE 00 00 00 41 00 00 00 42 00 00 00 43
UTF-32LE 41 00 00 00 42 00 00 00 43 00 00 00
UTF-32(Big Endian) 00 00 FE FF 00 00 00 41 00 00 00 42 00 00 00 43
UTF-32(Little Endian) FF FE 00 00 41 00 00 00 42 00 00 00 43 00 00 00
UTF-32(不帶BOM) 00 00 00 41 00 00 00 42 00 00 00 43
UTF-8
UTF-16和UTF-32的一個缺點就是它們固定使用兩個或四個字節, 這樣在表示純ASCII文件時會有很多00字節,造成浪費。 而RFC3629定義的UTF-8則解決了這個問題。
UTF-8用1~4個字節來表示代碼點。表示方式如下:UCS-2 (UCS-4) 位序列 第一字節 第二字節 第三字節 第四字節
U+0000 .. U+007F 00000000-0xxxxxxx 0xxxxxxx
U+0080 .. U+07FF 00000xxx-xxyyyyyy 110xxxxx 10yyyyyy
U+0800 .. U+FFFF xxxxyyyy-yyzzzzzz 1110xxxx 10yyyyyy 10zzzzzz
U+10000..U+10FFFF 00000000-000wwwxx-
xxxxyyyy-yyzzzzzzz 11110www 10xxxxxx 10yyyyyy 10zzzzzz
可見,ASCII字符(U+0000~U+007F)部分完全使用一個字節,避免了存儲空間的浪費。 而且UTF-8不再需要BOM字節。
另外,從上表中可以看出,單字節編碼的第一字節為[00-7F],雙字節編碼的第一字節為[C2-DF], 三字節編碼的第一字節為[E0-EF]。這樣只要看到第一個字節的范圍就可以知道編碼的字節數。 這樣也可以大大簡化算法。
]]>
]]>
概述
我們知道Spring通過各種DAO模板類降低了開發者使用各種數據持久技術的難度。這些模板類都是線程安全的,也就是說,多個DAO可以復用同一個模板實例而不會發生沖突。
我們使用模板類訪問底層數據,根據持久化技術的不同,模板類需要綁定數據連接或會話的資源。但這些資源本身是非線程安全的,也就是說它們不能在同一時刻被多個線程共享。
雖然模板類通過資源池獲取數據連接或會話,但資源池本身解決的是數據連接或會話的緩存問題,并非數據連接或會話的線程安全問題。
按照傳統經驗,如果某個對象是非線程安全的,在多線程環境下,對對象的訪問必須采用synchronized進行線程同步。但Spring的DAO模板類并未采用線程同步機制,因為線程同步限制了并發訪問,會帶來很大的性能損失。
此外,通過代碼同步解決性能安全問題挑戰性很大,可能會增強好幾倍的實現難度。那模板類究竟仰丈何種魔法神功,可以在無需同步的情況下就化解線程安全的難題呢?答案就是ThreadLocal!
ThreadLocal在Spring中發揮著重要的作用,在管理request作用域的Bean、事務管理、任務調度、AOP等模塊都出現了它們的身影,起著舉足輕重的作用。要想了解Spring事務管理的底層技術,ThreadLocal是必須攻克的山頭堡壘。
ThreadLocal是什么
早在JDK 1.2的版本中就提供java.lang.ThreadLocal,ThreadLocal為解決多線程程序的并發問題提供了一種新的思路。使用這個工具類可以很簡潔地編寫出優美的多線程程序。
ThreadLocal很容易讓人望文生義,想當然地認為是一個“本地線程”。其實,ThreadLocal并不是一個Thread,而是Thread的局部變量,也許把它命名為ThreadLocalVariable更容易讓人理解一些。
當使用ThreadLocal維護變量時,ThreadLocal為每個使用該變量的線程提供獨立的變量副本,所以每一個線程都可以獨立地改變自己的副本,而不會影響其它線程所對應的副本。
從線程的角度看,目標變量就象是線程的本地變量,這也是類名中“Local”所要表達的意思。
線程局部變量并不是Java的新發明,很多語言(如IBM IBM XL FORTRAN)在語法層面就提供線程局部變量。在Java中沒有提供在語言級支持,而是變相地通過ThreadLocal的類提供支持。
所以,在Java中編寫線程局部變量的代碼相對來說要笨拙一些,因此造成線程局部變量沒有在Java開發者中得到很好的普及。
ThreadLocal的接口方法
ThreadLocal類接口很簡單,只有4個方法,我們先來了解一下:
void set(Object value)
設置當前線程的線程局部變量的值。
public Object get()
該方法返回當前線程所對應的線程局部變量。
public void remove()
將當前線程局部變量的值刪除,目的是為了減少內存的占用,該方法是JDK 5.0新增的方法。需要指出的是,當線程結束后,對應該線程的局部變量將自動被垃圾回收,所以顯式調用該方法清除線程的局部變量并不是必須的操作,但它可以加快內存回收的速度。
protected Object initialValue()
返回該線程局部變量的初始值,該方法是一個protected的方法,顯然是為了讓子類覆蓋而設計的。這個方法是一個延遲調用方法,在線程第1次調用get()或set(Object)時才執行,并且僅執行1次。ThreadLocal中的缺省實現直接返回一個null。
值得一提的是,在JDK5.0中,ThreadLocal已經支持泛型,該類的類名已經變為ThreadLocal<T>。API方法也相應進行了調整,新版本的API方法分別是void set(T value)、T get()以及T initialValue()。
ThreadLocal是如何做到為每一個線程維護變量的副本的呢?其實實現的思路很簡單:在ThreadLocal類中有一個Map,用于存儲每一個線程的變量副本,Map中元素的鍵為線程對象,而值對應線程的變量副本。我們自己就可以提供一個簡單的實現版本:
代碼清單1 SimpleThreadLocal
public class SimpleThreadLocal {
private Map valueMap = Collections.synchronizedMap(new HashMap());
public void set(Object newValue) {
valueMap.put(Thread.currentThread(), newValue);①鍵為線程對象,值為本線程的變量副本
}
public Object get() {
Thread currentThread = Thread.currentThread();
Object o = valueMap.get(currentThread);②返回本線程對應的變量
if (o == null && !valueMap.containsKey(currentThread)) {③如果在Map中不存在,放到Map
中保存起來。
o = initialValue();
valueMap.put(currentThread, o);
}
return o;
}
public void remove() {
valueMap.remove(Thread.currentThread());
}
public Object initialValue() {
return null;
}
}
雖然代碼清單9?3這個ThreadLocal實現版本顯得比較幼稚,但它和JDK所提供的ThreadLocal類在實現思路上是相近的。
一個TheadLocal實例
下面,我們通過一個具體的實例了解一下ThreadLocal的具體使用方法。
代碼清單2 SequenceNumber
package com.baobaotao.basic;
public class SequenceNumber {
①通過匿名內部類覆蓋ThreadLocal的initialValue()方法,指定初始值
private static ThreadLocal<Integer> seqNum = new ThreadLocal<Integer>(){
public Integer initialValue(){
return 0;
}
};
②獲取下一個序列值
public int getNextNum(){
seqNum.set(seqNum.get()+1);
return seqNum.get();
}
public static void main(String[] args)
{
SequenceNumber sn = new SequenceNumber();
③ 3個線程共享sn,各自產生序列號
TestClient t1 = new TestClient(sn);
TestClient t2 = new TestClient(sn);
TestClient t3 = new TestClient(sn);
t1.start();
t2.start();
t3.start();
}
private static class TestClient extends Thread
{
private SequenceNumber sn;
public TestClient(SequenceNumber sn) {
this.sn = sn;
}
public void run()
{
for (int i = 0; i < 3; i++) {④每個線程打出3個序列值
System.out.println("thread["+Thread.currentThread().getName()+
"] sn["+sn.getNextNum()+"]");
}
}
}
}
通常我們通過匿名內部類的方式定義ThreadLocal的子類,提供初始的變量值,如例子中①處所示。TestClient線程產生一組序列號,在③處,我們生成3個TestClient,它們共享同一個SequenceNumber實例。運行以上代碼,在控制臺上輸出以下的結果:
thread[Thread-2] sn[1]
thread[Thread-0] sn[1]
thread[Thread-1] sn[1]
thread[Thread-2] sn[2]
thread[Thread-0] sn[2]
thread[Thread-1] sn[2]
thread[Thread-2] sn[3]
thread[Thread-0] sn[3]
thread[Thread-1] sn[3]
考察輸出的結果信息,我們發現每個線程所產生的序號雖然都共享同一個SequenceNumber實例,但它們并沒有發生相互干擾的情況,而是各自產生獨立的序列號,這是因為我們通過ThreadLocal為每一個線程提供了單獨的副本。
Thread同步機制的比較
ThreadLocal和線程同步機制相比有什么優勢呢?ThreadLocal和線程同步機制都是為了解決多線程中相同變量的訪問沖突問題。
在同步機制中,通過對象的鎖機制保證同一時間只有一個線程訪問變量。這時該變量是多個線程共享的,使用同步機制要求程序慎密地分析什么時候對變量進行讀寫,什么時候需要鎖定某個對象,什么時候釋放對象鎖等繁雜的問題,程序設計和編寫難度相對較大。
而ThreadLocal則從另一個角度來解決多線程的并發訪問。ThreadLocal會為每一個線程提供一個獨立的變量副本,從而隔離了多個線程對數據的訪問沖突。因為每一個線程都擁有自己的變量副本,從而也就沒有必要對該變量進行同步了。ThreadLocal提供了線程安全的共享對象,在編寫多線程代碼時,可以把不安全的變量封裝進ThreadLocal。
由于ThreadLocal中可以持有任何類型的對象,低版本JDK所提供的get()返回的是Object對象,需要強制類型轉換。但JDK 5.0通過泛型很好的解決了這個問題,在一定程度地簡化ThreadLocal的使用,代碼清單 9 2就使用了JDK 5.0新的ThreadLocal<T>版本。
概括起來說,對于多線程資源共享的問題,同步機制采用了“以時間換空間”的方式,而ThreadLocal采用了“以空間換時間”的方式。前者僅提供一份變量,讓不同的線程排隊訪問,而后者為每一個線程都提供了一份變量,因此可以同時訪問而互不影響。
Spring使用ThreadLocal解決線程安全問題
我們知道在一般情況下,只有無狀態的Bean才可以在多線程環境下共享,在Spring中,絕大部分Bean都可以聲明為singleton作用域。就是因為Spring對一些Bean(如RequestContextHolder、TransactionSynchronizationManager、LocaleContextHolder等)中非線程安全狀態采用ThreadLocal進行處理,讓它們也成為線程安全的狀態,因為有狀態的Bean就可以在多線程中共享了。
一般的Web應用劃分為展現層、服務層和持久層三個層次,在不同的層中編寫對應的邏輯,下層通過接口向上層開放功能調用。在一般情況下,從接收請求到返回響應所經過的所有程序調用都同屬于一個線程,如圖9?2所示:

圖1同一線程貫通三層
這樣你就可以根據需要,將一些非線程安全的變量以ThreadLocal存放,在同一次請求響應的調用線程中,所有關聯的對象引用到的都是同一個變量。
下面的實例能夠體現Spring對有狀態Bean的改造思路:
代碼清單3 TopicDao:非線程安全
public class TopicDao {
private Connection conn;①一個非線程安全的變量
public void addTopic(){
Statement stat = conn.createStatement();②引用非線程安全變量
…
}
}
由于①處的conn是成員變量,因為addTopic()方法是非線程安全的,必須在使用時創建一個新TopicDao實例(非singleton)。下面使用ThreadLocal對conn這個非線程安全的“狀態”進行改造:
代碼清單4 TopicDao:線程安全
import java.sql.Connection;
import java.sql.Statement;
public class TopicDao {
①使用ThreadLocal保存Connection變量
private static ThreadLocal<Connection> connThreadLocal = new ThreadLocal<Connection>();
public static Connection getConnection(){
②如果connThreadLocal沒有本線程對應的Connection創建一個新的Connection,
并將其保存到線程本地變量中。
if (connThreadLocal.get() == null) {
Connection conn = ConnectionManager.getConnection();
connThreadLocal.set(conn);
return conn;
}else{
return connThreadLocal.get();③直接返回線程本地變量
}
}
public void addTopic() {
④從ThreadLocal中獲取線程對應的Connection
Statement stat = getConnection().createStatement();
}
}
不同的線程在使用TopicDao時,先判斷connThreadLocal.get()是否是null,如果是null,則說明當前線程還沒有對應的Connection對象,這時創建一個Connection對象并添加到本地線程變量中;如果不為null,則說明當前的線程已經擁有了Connection對象,直接使用就可以了。這樣,就保證了不同的線程使用線程相關的Connection,而不會使用其它線程的Connection。因此,這個TopicDao就可以做到singleton共享了。
當然,這個例子本身很粗糙,將Connection的ThreadLocal直接放在DAO只能做到本DAO的多個方法共享Connection時不發生線程安全問題,但無法和其它DAO共用同一個Connection,要做到同一事務多DAO共享同一Connection,必須在一個共同的外部類使用ThreadLocal保存Connection。但這個實例基本上說明了Spring對有狀態類線程安全化的解決思路。
小結
ThreadLocal是解決線程安全問題一個很好的思路,它通過為每個線程提供一個獨立的變量副本解決了變量并發訪問的沖突問題。在很多情況下,ThreadLocal比直接使用synchronized同步機制解決線程安全問題更簡單,更方便,且結果程序擁有更高的并發性。
原文出處:http://www.builder.com.cn/2007/0529/404698.shtml
]]>
log4j.addivity.org.apache=true
# 應用于控制臺
log4j.appender.CONSOLE=org.apache.log4j.ConsoleAppender
log4j.appender.CONSOLE.Threshold=INFO
log4j.appender.CONSOLE.Target=System.out
log4j.appender.CONSOLE.Encoding=GBK
log4j.appender.CONSOLE.layout=org.apache.log4j.PatternLayout
log4j.appender.CONSOLE.layout.ConversionPattern=[framework] %d - %c -%-4r [%t] %-5p %c %x - %m%n
# 用于數據庫
#log4j.appender.DATABASE=org.apache.log4j.jdbc.JDBCAppender
#log4j.appender.DATABASE.URL=jdbc:mysql://localhost:3306/ww
#log4j.appender.DATABASE.driver=com.mysql.jdbc.Driver
#log4j.appender.DATABASE.user=root
#log4j.appender.DATABASE.password=123
#log4j.appender.CONSOLE.Threshold=WARN
#log4j.appender.DATABASE.sql=INSERT INTO LOG(stamp,thread, infolevel,class,messages) VALUES ('%d{yyyy-MM-dd HH:mm:ss}', '%t', '%p', '%l', '%m')
# INSERT INTO LOG4J (Message) VALUES ('[framework] %d - %c -%-4r [%t] %-5p %c %x - %m%n')
# 寫入數據庫中的表LOG的Message字段中,內容%d(日期)%c: 日志信息所在地(類名)%p: 日志信息級別%m: 產生的日志具體信息 %n: 輸出日志信息換行
#log4j.appender.DATABASE.layout=org.apache.log4j.PatternLayout
#log4j.appender.DATABASE.layout.ConversionPattern=[framework] %d - %c -%-4r [%t] %-5p %c %x - %m%n
# 每天新建日志
log4j.appender.A1=org.apache.log4j.DailyRollingFileAppender
log4j.appender.A1.File=C:/log4j/log
log4j.appender.A1.Encoding=GBK
log4j.appender.A1.Threshold=DEBUG
log4j.appender.A1.DatePattern='.'yyyy-MM-dd
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%d{ABSOLUTE} %5p %c{1}:%L : %m%n
#應用于文件
log4j.appender.FILE=org.apache.log4j.FileAppender
log4j.appender.FILE.File=C:/log4j/file.log
log4j.appender.FILE.Append=false
log4j.appender.FILE.Encoding=GBK
log4j.appender.FILE.layout=org.apache.log4j.PatternLayout
log4j.appender.FILE.layout.ConversionPattern=[framework] %d - %c -%-4r [%t] %-5p %c %x - %m%n
# 應用于文件回滾
log4j.appender.ROLLING_FILE=org.apache.log4j.RollingFileAppender
log4j.appender.ROLLING_FILE.Threshold=ERROR
log4j.appender.ROLLING_FILE.File=rolling.log
log4j.appender.ROLLING_FILE.Append=true
log4j.appender.CONSOLE_FILE.Encoding=GBK
log4j.appender.ROLLING_FILE.MaxFileSize=10KB
log4j.appender.ROLLING_FILE.MaxBackupIndex=1
log4j.appender.ROLLING_FILE.layout=org.apache.log4j.PatternLayout
log4j.appender.ROLLING_FILE.layout.ConversionPattern=[framework] %d - %c -%-4r [%t] %-5p %c %x - %m%n
#自定義Appender
log4j.appender.im = net.cybercorlin.util.logger.appender.IMAppender
log4j.appender.im.host = mail.cybercorlin.net
log4j.appender.im.username = username
log4j.appender.im.password = password
log4j.appender.im.recipient = corlin@cybercorlin.net
log4j.appender.im.layout=org.apache.log4j.PatternLayout
log4j.appender.im.layout.ConversionPattern =[framework] %d - %c -%-4r [%t] %-5p %c %x - %m%n
#應用于socket
log4j.appender.SOCKET=org.apache.log4j.RollingFileAppender
log4j.appender.SOCKET.RemoteHost=localhost
log4j.appender.SOCKET.Port=5001
log4j.appender.SOCKET.LocationInfo=true
# Set up for Log Facter 5
log4j.appender.SOCKET.layout=org.apache.log4j.PatternLayout
log4j.appender.SOCET.layout.ConversionPattern=[start]%d{DATE}[DATE]%n%p[PRIORITY]%n%x[NDC]%n%t[THREAD]%n%c[CATEGORY]%n%m[MESSAGE]%n%n
# Log Factor 5 Appender
log4j.appender.LF5_APPENDER=org.apache.log4j.lf5.LF5Appender
log4j.appender.LF5_APPENDER.MaxNumberOfRecords=2000
# 發送日志給郵件
log4j.appender.MAIL=org.apache.log4j.net.SMTPAppender
log4j.appender.MAIL.Threshold=FATAL
log4j.appender.MAIL.BufferSize=10
log4j.appender.MAIL.From=user@abc.com
log4j.appender.MAIL.SMTPHost=www.abc.com
log4j.appender.MAIL.Subject=Log4J Message
log4j.appender.MAIL.To=user@abc.com
log4j.appender.MAIL.layout=org.apache.log4j.PatternLayout
log4j.appender.MAIL.layout.ConversionPattern=[framework] %d - %c -%-4r [%t] %-5p %c %x - %m%n
參考資料:
log4j詳解與實戰
]]>
1.理解DOM——很詳盡的DOM入門資料
https://www6.software.ibm.com/developerworks/cn/education/xml/x-udom/section2.html
http://www.cnblogs.com/huangyu/articles/33572.html
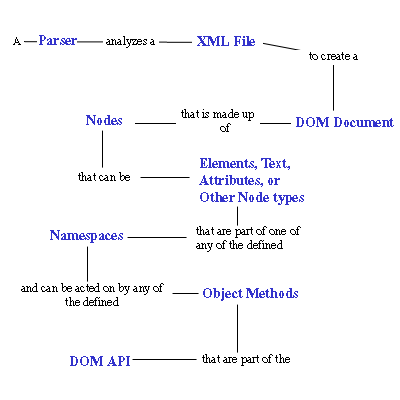
DOM路標圖
2.理解SAX
https://www6.software.ibm.com/developerworks/cn/education/xml/x-usax/index.html
http://www.cnblogs.com/huangyu/archive/2004/08/16/33934.html
SAX 是什么?
用于讀取和操作 XML 文件的標準是文檔對象模型(Document Object Model,DOM)。遺憾的是,DOM 方法涉及讀取整個文件并將該文件存儲在一個樹結構中,而這樣可能是低效的、緩慢的,并且很消耗資源。
一種替代技術就是 Simple API for XML,或稱為 SAX。SAX 允許您在讀取文檔時處理它,從而不必等待整個文檔被存儲之后才采取操作。
SAX 是由 XML-DEV 郵件列表的成員開發的,現在對應的 Java 版本是 SourceForge 項目(請參閱 參考資料)。該項目的目的是為 XML 的使用提供一種更自然的手段 —— 換句話說,也就是不涉及 DOM 所必需的開銷和概念跳躍。
項目的成果是一個基于事件 的 API。解析器向一個事件處理程序發送事件,比如元素的開始和結束,而事件處理程序則處理該信息。然后應用程序才能夠處理該數據。原始的文檔仍然保持原樣,但是 SAX 提供了操作數據的手段,因此數據可以用于另一個進程或文檔。
SAX 沒有官方的標準機構,由萬維網聯盟(Wide Web Consortium,W3C)或其他官方機構維護,但它是 XML 社區事實上的標準。
SAX 處理涉及以下步驟:
- 創建一個事件處理程序。
- 創建 SAX 解析器。
- 向解析器分配事件處理程序。
- 解析文檔,同時向事件處理程序發送每個事件。
這種處理的優點非常類似于流媒體的優點。分析能夠立即開始,而不是等待所有的數據被處理。而且,由于應用程序只是在讀取數據時檢查數據,因此不需要將數據存儲在內存中。這對于大型文檔來說是個巨大的優點。事實上,應用程序甚至不必解析整個文檔;它可以在某個條件得到滿足時停止解析。一般來說,SAX 還比它的替代者 DOM 快許多。
另一方面,由于應用程序沒有以任何方式存儲數據,使用 SAX 來更改數據或在數據流中往后移是不可能的。
SAX 和 DOM 不是相互排斥的,記住這點很重要。您可以使用 DOM 來創建 SAX 事件流,也可以使用 SAX 來創建 DOM 樹。事實上,用于創建 DOM 樹的大多數解析器實際上都使用 SAX 來完成這個任務!
3.DW上的相關資源
http://www.ibm.com/developerworks/cn/xml/
4.使用Xpath提高基于DOM的XML處理效率
http://www.ibm.com/developerworks/cn/xml/x-domjava/index.shtml
]]>
這陣子正打算用Rails做個東東,所以開始系統地學習起了Rails。巧合的是,大概兩周前,dlee邀請我加入Fielding博士關于REST的那篇論文的翻譯團隊。可以說Rails和REST這兩個最熱門的詞匯幾乎同時擠入了我的生活。隨著我對Rails的學習和對[Fielding]的翻譯,我也開始對REST產生了一些不太成熟的想法,寫在這里與大家分享,同時也起到拋磚引玉的作用,歡迎大家討論。
先復習一下REST的基本思想。[Fielding]把REST形式化地定義為一種架構風格(architecture style),它有架構元素(element)和架構約束(constraint)組成。這些概念比較晦澀難懂,而且我們做工程的往往并不需要形而上的理解。我們只知道,REST是一種針對網絡應用的設計和開發方式,可以降低開發的復雜性,提高系統的可伸縮性。REST提出了一些設計概念和準則:
網絡上的所有事物都被抽象為資源(resource);
每個資源對應一個唯一的資源標識(resource identifier);
通過通用的連接器接口(generic connector interface)對資源進行操作;
對資源的各種操作不會改變資源標識;
所有的操作都是無狀態的(stateless)。
對于當今最常見的網絡應用來說,resource identifier是url,generic connector interface是HTTP,第4條準則就是我們常說的url不變性。這些概念中的resouce最容易使人產生誤解。resouce所指的并不是數據,而是數據+特定的表現形式(representation),這也是為什么REST的全名是Representational State Transfer的原因。舉個例子來說,“本月賣得最好的10本書”和“你最喜歡的10本書”在數據上可能有重疊(有一本書即賣得好,你又喜歡),甚至完全相同。但是它們的representation不同,因此是不同的resource。
REST之所以能夠簡化開發,是因為其引入的架構約束,比如Rails 1.2中對REST的實現默認把controller中的方法限制在7個:index、show、new、edit、create、update和destory,這實際上就是對CURD的實現。更進一步講,Rails(也是當今大部分網絡應用)使用HTTP作為generic connector interface,HTTP則把對一個url的操作限制在了4個之內:GET、POST、PUT和DELETE。
REST之所以能夠提高系統的可伸縮性,是因為它強制所有操作都是stateless的,這樣就沒有context的約束,如果要做分布式、做集群,就不需要考慮context的問題了。同時,它令系統可以有效地使用pool。REST對性能的另一個提升來自其對client和server任務的分配:server只負責提供resource以及操作resource的服務,而client要根據resource中的data和representation自己做render。這就減少了服務器的開銷。
既然REST有這樣的好處,那我們應該義無反顧地擁抱它啊!目前一些大牛(像DHH)都已經開始投入到了REST的世界,那我們這些人應該做什么或者說思考寫什么你呢?我覺得我們應該思考兩個問題:
如何使用REST;
REST和MVC的關系。
第一個問題假設REST是我們應該采用的架構,然后討論如何使用;第二個問題則要說明REST和當前最普遍應用的MVC是什么關系,互補還是取代?
我們先來談談第一個問題,如何使用REST。我感覺,REST除了給我們帶來了一個嶄新的架構以外,還有一個重要的貢獻是在開發系統過程中的一種新的思維方式:通過url來設計系統的結構。根據REST,每個url都代表一個resource,而整個系統就是由這些resource組成的。因此,如果url是設計良好的,那么系統的結構就也應該是設計良好的。對于非高手級的開發人員來說,考慮一個系統如何架構總是一個很抽象的問題。敏捷開發所提倡的Test Driven Development,其好處之一(我覺得是最大的好處)就是可以通過testcase直觀地設計系統的接口。比如在還沒有創建一個class的時候就編寫一個testcase,雖然設置不能通過編譯,但是testcase中的方法調用可以很好地從class使用者的角度反映出需要的接口,從而為class的設計提供了直觀的表現。這與在REST架構中通過url設計系統結構非常類似。雖然我們連一個功能都沒有實現,但是我們可以先設計出我們認為合理的url,這些url甚至不能連接到任何page或action,但是它們直觀地告訴我們:系統對用戶的訪問接口就應該是這樣。根據這些url,我們可以很方便地設計系統的結構。
讓我在這里重申一遍:REST允許我們通過url設計系統,就像Test Driven Development允許我們使用testcase設計class接口一樣。
OK,既然url有這樣的好處,那我們就著重討論一下如何設計url。網絡應用通常都是有hierarchy的,像棵大樹。我們通常希望url也能反映出資源的層次性。比如對于一個blog應用:/articles表示所有的文章,/articles/1表示id為1的文章,這都比較直觀。遺憾的是,網絡應用的資源結構永遠不會如此簡單。因此人們常常會問這樣一個問題:RESTful的url能覆蓋所有的用戶請求嗎?比如,login如何RESTful?search如何RESTful?
從REST的概念上來看,所有可以被抽象為資源的東東都可以使用RESTful的url。因此對于上面的兩個問題,如果login和search可以被抽象為資源,那么就可以使用RESTful的url。search比較簡單,因為它會返回搜索結果,因此可以被抽象為資源,并且只實現index方法就可以了(只需要顯示搜索結果,沒有create、destory之類的東西)。然而這里面也有一個問題:search的關鍵字如何傳給server?index方法顯然應該使用HTTP GET,這會把關鍵字加到url后面,當然不符合REST的風格。要解決這個問題,可以把每次search看作一個資源,因此要創建create和index方法,create用來在用戶點擊“搜索”按鈕是通過HTTP POST把關鍵字傳給server,然后index則用來顯示搜索結果。這樣一來,我們還可以記錄用戶的搜索歷史。使用同樣的方法,我們也可以對login應用REST,即每次login動作是一個資源。
現在,我們來復雜一些的東東。如何用url表達“category為ruby的article”?一開始可能想到的是/category/ruby/articles,這種想法很直觀。但是我覺得里面的category是不需要的,我們可以直接把“/ruby”理解為“category是ruby”,也就是說“ruby”出現的位置說明了它指的就是category。OK,/ruby/articles,單單從這個url上看,我們能獲得多少關于category的信息呢?顯然category隱藏在了url后面,這樣做到底好不好,應該是仁者見仁,智者見智了。對于如何表達category這樣的東西,我還沒想出很好的方式,大家有什么好idea,可以一起討論。
另外還有一種url形式,它對應到程序中的繼承關系。比如product是一個父類,book和computer是其子類。那么所有產品的url應該是/products,所有書籍的url應該是/books,所有電腦的url應該是/computers。這一想法就比較直觀了,而且再次驗證了url可以幫助我們進行設計的論點。
讓我再說明一下我的想法:如果每個用戶需求都可以抽象為資源,那么就可以完全使用REST。
由此看來,使用REST的關鍵是如何抽象資源,抽象得越精確,對REST的應用就越好。因此,如何改變我們目前根深蒂固的基于action的思想是最重要的。
有了對第一個問題的討論,第二個問題就容易討論多了。REST會取代MVC嗎?還是彼此是互補關系(就像AOP對于OOP)?答案是It depends!如果我們可以把所有的用戶需求都可以抽象為資源,那么MVC就可以推出歷史的舞臺了。如果情況相反,那么我們就需要混合使用REST和MVC。
當然,這是非常理想的論斷。可能我們無法找到一種方法可以把所有的用戶需求都抽象為資源,因為保證這種抽象的完整性(即真的是所有需求都可以)需要形式化的證明。而且即使被證明出來了,由于開發人員的能力和喜好不同,MVC肯定也會成為不少人的首選。但是對于希望擁抱REST的人來說,這些都沒有關系。只要你開發的系統所設計的問題域可以被合理地抽象為資源,那么REST就會成為你的開發利器。
所以,所有希望擁抱REST的朋友們,趕快訓練自己如何帶上資源的眼鏡看世界吧,這才是REST的核心所在。
轉載自javaeye論壇 作者:AllenYoung
原文地址:http://www.javaeye.com/topic/70113
資源: http://www.ibm.com/developerworks/cn/web/wa-ajaxarch/
]]>
]]>