原文:
http://www.rabbitmq.com/memory.html
RabbitMQ服務器在啟動時以及abbitmqctl set_vm_memory_high_watermark fraction 執行時,會檢查計算機的RAM總大小. 默認情況下下, 當 RabbitMQ server 的使用量超過RAM的40% ,它就會發出內存警報,并阻塞所有連接. 一旦內存警報清除 (如,服務器將消息轉存于磁盤,或者將消息投遞給clients),服務又地恢復.
默認內存閥值設置為已安裝RAM的40%. 注意這并不會阻止RabbitMQ server使用內存量超過40%, 它只是為了壓制發布者. Erlang的垃圾回收器最壞情況下,可使用配置內存的2倍(默認情況下t, RAMr的80%). 因此強制建議開啟OS swap或page files .
32位架構傾向于每一個進程有2GB的內存限制. 64位架構的一般實現(i.e. AMD64 和 Intel EM64T) 只允許每個進程為256TB. 64-位 Windows 限制為8TB. 但是,請注意,即使是64位操作系統下,一個32位的過程往往只有一個2GB的最大地址空間。
配置內存閥值
[{rabbit, [{vm_memory_high_watermark, 0.4}]}].
默認值0.4 代表的是已安裝RAM的 40% , 有時候還更小.如:在 32位平臺中,如果你安裝有4GB RAM , 4GB 的40% 是 1.6GB, 但是 32-位 Windows 正常情況下限制進程為2GB,因此實際閥值是2GB的40% (即820MB).
另外, 內存閥值也可以設置為絕對值. 下面的例子將閥值設為了1073741824 字節 (1024 MB):
[{rabbit, [{vm_memory_high_watermark, {absolute, 1073741824}}]}].
同例, 也可使用內存單位:
[{rabbit, [{vm_memory_high_watermark, {absolute, "1024MiB"}}]}].
如果絕對上限大于了安裝的RAM可用的虛擬地址空間, 閥值上限會略小.
當RabbitMQ服務器啟動時,內存限制將追加到RABBITMQ_NODENAME.log 文件中:
=INFO REPORT==== 29-Oct-2009::15:43:27 === Memory limit set to 2048MB.
內存限制也可以使用rabbitmqctl status命令查詢.
其閥值也可以在broker運行時,通過rabbitmqctl set_vm_memory_high_watermark fraction 命令或 rabbitmqctl set_vm_memory_high_watermark absolute memory_limit 命令修改. 內存單位也可以在命令中使用. 此命令會在broker重啟后生效. 當執行此命令時,內存限制可能會改變熱插拔RAM,而不會發生報警,這是因為需要全部數量的系統RAM.
禁止所有發布
其值為0時,會立即觸發報警并禁用所有發布 (當需要禁用全局發布時,這可能是有用的); use rabbitmqctl set_vm_memory_high_watermark 0.
限制的地址空間
當在64位操作系統中運行32位 Erlang VM時,(or a 32 bit OS with PAE), 可用地址內存是受限制的. 服務器探測到后會記錄像下邊的日志消息:
=WARNING REPORT==== 19-Dec-2013::11:27:13 === Only 2048MB of 12037MB memory usable due to limited address space. Crashes due to memory exhaustion are possible - see http://www.rabbitmq.com/memory.html#address-space
內存報警系統是不完美的.雖然停止發布通常會防止任何進一步的內存使用,但可能有其他東西繼續增加內存使用。通常情況下,當這種情況發生時,物理內存耗盡,操作系統將開始交換。但是當運行一個有限的地址空間,超過限制的運行會導致虛擬機崩潰。
因此強制建議在在64位操作系統上運行64位的Erlang VM.
配置分頁閾值
在broker達到最高水位阻塞發布者之前,它會嘗試將隊列內容分頁輸出到磁盤上來釋放內存. 持久化和瞬時消息都會分頁輸出 (已經在磁盤上的持久化消息會被趕出內存).
默認情況下,在達最高水位的50%時,就會發生這種情況. (即,默認最高水位為0.4, 這會在內存使用達到20%時就會發生). 要修改此值,可修改vm_memory_high_watermark_paging_ratio 配置的0.5默認值. 例如:
[{rabbit, [{vm_memory_high_watermark_paging_ratio, 0.75}, {vm_memory_high_watermark, 0.4}]}].
上面的配置表示在內存使用達到30%時,就會啟動,40%的時候會阻塞發布者.
也可以將vm_memory_high_watermark_paging_ratio 值設為大于1.0的值.在這種情況下,隊列不會把它的內容分頁到磁盤上.如果這引起了內存報警關閉,那么生產者會如上面預期的一樣被阻塞.
未確認的平臺
如果RabbitMQ服務器不能識別你的系統,它將在RABBITMQ_NODENAME.log 文件中追加警告.
然后它會假設安裝了超過了1GB的RAM:
=WARNING REPORT==== 29-Oct-2009::17:23:44 === Unknown total memory size for your OS {unix,magic_homebrew_os}. Assuming memory size is 1024MB.
在這種情況下,vm_memory_high_watermark 配置值假設為1GB RAM. 在 vm_memory_high_watermark 默認設為 0.4的情況下, RabbitMQ的內存閥值設為了410MB, 因此當RabbitMQ使用了多于410M內存時,它會阻塞生產者.因此當RabbitMQ不能識別你的平臺時,如果你實際有8GB RAM,并且你想讓RabbitMQ內存使用量超過3GB阻塞生產者,你可以設置vm_memory_high_watermark為3.
posted @
2016-07-30 15:05 胡小軍 閱讀(7961) |
評論 (0) |
編輯 收藏鳥欲高飛先振翅,人求上進先讀書。本文是原書的第9章 線程的監控及其日常工作中如何分析里的9.3.3節常見的內存溢出的三種情況。
3. 常見的內存溢出的三種情況:
1)JVM Heap(堆)溢出:java.lang.OutOfMemoryError: Java heap space
JVM在啟動的時候會自動設置JVM Heap的值, 可以利用JVM提供的-Xmn -Xms -Xmx等選項可進行設置。Heap的大小是Young Generation 和Tenured Generaion 之和。在JVM中如果98%的時間是用于GC,且可用的Heap size 不足2%的時候將拋出此異常信息。
解決方法:手動設置JVM Heap(堆)的大小。
2)PermGen space溢出: java.lang.OutOfMemoryError: PermGen space
PermGen space的全稱是Permanent Generation space,是指內存的永久保存區域。為什么會內存溢出,這是由于這塊內存主要是被JVM存放Class和Meta信息的,Class在被Load的時候被放入PermGen space區域,它和存放Instance的Heap區域不同,sun的 GC不會在主程序運行期對PermGen space進行清理,所以如果你的APP會載入很多CLASS的話,就很可能出現PermGen space溢出。一般發生在程序的啟動階段。
解決方法: 通過-XX:PermSize和-XX:MaxPermSize設置永久代大小即可。
3)棧溢出: java.lang.StackOverflowError : Thread Stack space
棧溢出了,JVM依然是采用棧式的虛擬機,這個和C和Pascal都是一樣的。函數的調用過程都體現在堆棧和退棧上了。調用構造函數的 “層”太多了,以致于把棧區溢出了。 通常來講,一般棧區遠遠小于堆區的,因為函數調用過程往往不會多于上千層,而即便每個函數調用需要 1K的空間(這個大約相當于在一個C函數內聲明了256個int類型的變量),那么棧區也不過是需要1MB的空間。通常棧的大小是1-2MB的。通俗一點講就是單線程的程序需要的內存太大了。 通常遞歸也不要遞歸的層次過多,很容易溢出。
解決方法:1:修改程序。2:通過 -Xss: 來設置每個線程的Stack大小即可。
4. 所以Server容器啟動的時候我們經常關心和設置JVM的幾個參數如下(詳細的JVM參數請參看附錄三):
-Xms:java Heap初始大小, 默認是物理內存的1/64。
-Xmx:ava Heap最大值,不可超過物理內存。
-Xmn:young generation的heap大小,一般設置為Xmx的3、4分之一 。增大年輕代后,將會減小年老代大小,可以根據監控合理設置。
-Xss:每個線程的Stack大小,而最佳值應該是128K,默認值好像是512k。
-XX:PermSize:設定內存的永久保存區初始大小,缺省值為64M。
-XX:MaxPermSize:設定內存的永久保存區最大大小,缺省值為64M。
-XX:SurvivorRatio:Eden區與Survivor區的大小比值,設置為8,則兩個Survivor區與一個Eden區的比值為2:8,一個Survivor區占整個年輕代的1/10
-XX:+UseParallelGC:F年輕代使用并發收集,而年老代仍舊使用串行收集.
-XX:+UseParNewGC:設置年輕代為并行收集,JDK5.0以上,JVM會根據系統配置自行設置,所無需再設置此值。
-XX:ParallelGCThreads:并行收集器的線程數,值最好配置與處理器數目相等 同樣適用于CMS。
-XX:+UseParallelOldGC:年老代垃圾收集方式為并行收集(Parallel Compacting)。
-XX:MaxGCPauseMillis:每次年輕代垃圾回收的最長時間(最大暫停時間),如果無法滿足此時間,JVM會自動調整年輕代大小,以滿足此值。
-XX:+ScavengeBeforeFullGC:Full GC前調用YGC,默認是true。
實例如:JAVA_OPTS=”-Xms4g -Xmx4g -Xmn1024m -XX:PermSize=320M -XX:MaxPermSize=320m -XX:SurvivorRatio=6″
posted @
2016-07-26 23:05 胡小軍 閱讀(334) |
評論 (0) |
編輯 收藏學習如何在你的應用程序中集成WebSockets.
Published April 2013
對于許多基于客戶端-服務器程序來說,老的HTTP 請求-響應模型已經有它的局限性. 信息必須通過多次請求才能將其從服務端傳送到客戶端.
過去許多的黑客使用某些技術來繞過這個問題,例如:長輪詢(long polling)、基于 HTTP 長連接的服務器推技術(Comet).
然而,基于標準的、雙向的、客戶端和服務器之間全雙工的信道需求再不斷增加。
在2011年, IETF發布了標準WebSocket協議-RFC 6455. 從那時起,大多數Web瀏覽器都實現了支持WebSocket協議的客戶端APIs.同時,許多Java 包也開始實現了WebSocket協議.
WebSocket協議利用HTTP升級技術來將HTTP連接升級到WebSocket. 一旦升級后,連接就有了在兩個方向上相互獨立(全雙式)發送消息(數據楨)的能力.
不需要headers 或cookies,這大大降低了所需的帶寬. 通常,WebSockets來周期性地發送小消息 (例如,幾個字節).
額外的headers常常會使開銷大于有效負載(payload)。
JSR 356
JSR 356, WebSocket的Java API, 明確規定了API,當Java開發者需要在應用程序中集成WebSocket時,就可以使用此API—服務端和客戶端均可. 每個聲明兼容JSR 356的WebSocket協議,都必須實現這個API.
因此,開發人員可以自己編寫獨立于底層WebSocket實現的WebSocket應用。這是一個巨大的好處,因為它可以防止供應商鎖定,并允許更多的選擇、自由的庫、應用程序服務器。
JSR 356是即將到來的java EE 7標準的一部分,因此,所有與Java EE 7兼容的應用服務器都有JSR 365標準WebSocket的實現.一旦建立,WebSocket客戶端和服務器節點已經是對稱的了。客戶端API與服務器端API的區別是很小的,JSR 356定義的Java client API只是Java EE7完整API的子集.
客戶段-服務器端程序使用WebSockets,通常會包含一個服務器組件和多個客戶端組件, 如圖1所示:

圖1
在這個例子中,server application 是通過Java編寫的,WebSocket 協議細節是由包含在Java EE 7容器中JSR 356 實現來處理的.
JavaFX 客戶端可依賴任何與JSR 356兼容的客戶端實現來處理WebSocket協議問題.
其它客戶端(如,iOS 客戶端和HTML5客戶端)可使用其它 (非Java)與RFC6455兼容的實現來與server application通信.
編程模型
JSR 356定義的專家小組,希望支持Java EE開發人員常用的模式和技術。因此,JSR 356使用了注釋和注入。
一般來說,支持兩種編程模型:
- 注解驅動(annotation-driven). 通過使用注解POJOs, 開發者可與WebSocket生命周期事件交互.
- 接口驅動(interface-driven). 開發者可實現
Endpoint接口和與生命周期交互的方法.
生命周期事件
典型的WebSocket 交互生命周期如下:
- 一端 (客戶端) 通過發送HTTP握手請求來初始化連接.
- 其它端(服務端) 回復握手響應.
- 建立連接.從現在開始,連接是完全對稱的.
- 兩端都可發送和接收消息.
- 其中一端關閉連接.
大部分WebSocket生命周期事件都與Java方法對應,不管是 annotation-driven 還是interface-driven.
Annotation-Driven 方式
接受WebSocket請求的端點可以是以 @ServerEndpoint 注解的POJO.
此注解告知容器,此類應該被認為是WebSocket端點.
必須的value 元素指定了WebSocket端點的路徑.
考慮下面的代碼片斷:
@ServerEndpoint("/hello") public class MyEndpoint { } 此代碼將會以相對路徑hello來發布一個端點.在后續方法調用中,此路徑可攜帶路徑參數,如: /hello/{userid}是一個有效路徑,在這里{userid} 的值,可在生命周期方法使用@PathParam 注解獲取.
在GlassFish中,如果你的應用程序是用上下文mycontextroot 部署的,且在localhost的8080端口上監聽, WebSocket可通過使用ws://localhost:8080/mycontextroot/hello來訪問.
初始化WebSocket連接的端點可以是以 @ClientEndpoint 注解的POJO.@ClientEndpoint 和 @ServerEndpoint的主要區別是ClientEndpoint 不接受路徑路值元素,因為它監聽進來的請求。
@ClientEndpoint public class MyClientEndpoint {} Java中使用注解驅動POJO方式來初始化WebSocket連接,可通過如下代碼來完成:
javax.websocket.WebSocketContainer container = javax.websocket.ContainerProvider.getWebSocketContainer(); container.conntectToServer(MyClientEndpoint.class, new URI("ws://localhost:8080/tictactoeserver/endpoint")); 此后,以 @ServerEndpoint 或@ClientEndpoint 注解的類都稱為注解端點.
一旦建立了WebSocket連接 ,就會創建 Session,并且會調用注解端點中以@OnOpen注解的方法.
此方法包含了幾個參數:
javax.websocket.Session 參數, 代表創建的SessionEndpointConfig 實例包含了關于端點配置的信息- 0個或多個以
@PathParam注解的字符串參數,指的是端點路徑的path參數
下面的方法實現了當打開WebSocket時,將會打印session的標識符:
@OnOpen public void myOnOpen (Session session) { System.out.println ("WebSocket opened: "+session.getId()); } Session實例只要WebSocket未關閉就會一直有效. Session類中包含了許多有意思的方法,以允許開發者獲取更多關于的信息。
同時,Session 也包含了應用程序特有的數據鉤子,即通過getUserProperties() 方法來返回 Map<String, Object>.
這允許開發者可以使用session-和需要在多個方法調用間共享的應用程序特定信息來填充Session實例.
i當WebSocket端收到消息時,將會調用以@OnMessage注解的方法.以@OnMessage 注解的方法可包含下面的參數:
javax.websocket.Session 參數.- 0個或多個以
@PathParam注解的字符串參數,指的是端點路徑的path參數 - 消息本身. 下面有可能消息類型描述.
當其它端發送了文本消息時,下面的代碼片斷會打印消息內容:
@OnMessage public void myOnMessage (String txt) { System.out.println ("WebSocket received message: "+txt); } 如果以@OnMessage i注解的方法返回值不是void, WebSocket實現會將返回值發送給其它端點.下面的代碼片斷會將收到的文本消息以首字母大寫的形式發回給發送者:
@OnMessage public String myOnMessage (String txt) { return txt.toUpperCase(); } 另一種通過WebSocket連接來發送消息的代碼如下:
RemoteEndpoint.Basic other = session.getBasicRemote(); other.sendText ("Hello, world"); 在這種方式中,我們從Session 對象開始,它可以從生命周期回調方法中獲取(例如,以 @OnOpen注解的方法).session實例上getBasicRemote() 方法返回的是WebSocket其它部分的代表RemoteEndpoint. RemoteEndpoint 實例可用于發送文本或其它類型的消息,后面有描述.
當關閉WebSocket連接時,將會調用@OnClose 注解的方法。此方法接受下面的參數:
javax.websocket.Session 參數. 注意,一旦WebSocket真正關閉了,此參數就不能被使用了,這通常發生在@OnClose 注解方法返回之后.- A
javax.websocket.CloseReason 參數,用于描述關閉WebSocket的原因,如:正常關閉,協議錯誤,服務過載等等. - 0個或多個以
@PathParam注解的字符串參數,指的是端點路徑的path參數
下面的代碼片段打印了WebSocket關閉的原因:
@OnClose public void myOnClose (CloseReason reason) { System.out.prinlnt ("Closing a WebSocket due to "+reason.getReasonPhrase()); } 完整情況下,這里還有一個生命周期注解:如果收到了錯誤,將會調用 @OnError 注解的方法。
Interface-Driven 方式
annotation-driven 方式允許我們注解一個Java類,以及使用生命周期注解來注解方法.
使用interface-driven方式,開發者可繼承javax.websocket.Endpoint 并覆蓋其中的onOpen, onClose, 以及onError 方法:
public class myOwnEndpoint extends javax.websocket.Endpoint { public void onOpen(Session session, EndpointConfig config) {...} public void onClose(Session session, CloseReason closeReason) {...} public void onError (Session session, Throwable throwable) {...} } 為了攔截消息,需要在onOpen實現中注冊一個javax.websocket.MessageHandler:
public void onOpen (Session session, EndpointConfig config) { session.addMessageHandler (new MessageHandler() {...}); } MessageHandler 接口有兩個子接口: MessageHandler.Partial和 MessageHandler.Whole.
MessageHandler.Partial 接口應該用于當開發者想要收到部分消息通知的時候,MessageHandler.Whole的實現應該用于整個消息到達通知。
下面的代碼片斷會監聽進來的文件消息,并將文本信息轉換為大小版本后發回給其它端點:
public void onOpen (Session session, EndpointConfig config) { final RemoteEndpoint.Basic remote = session.getBasicRemote(); session.addMessageHandler (new MessageHandler.Whole<String>() { public void onMessage(String text) { try { remote.sendString(text.toUpperCase()); } catch (IOException ioe) { // handle send failure here } } }); } 消息類型,編碼器,解碼器
WebSocket的JavaAPI非常強大,因為它允許發送任或接收任何對象作為WebSocket消息.
基本上,有三種不同類型的消息:
- 基于文本的消息
- 二進制消息
- Pong 消息,它是WebSocket連接自身
當使用interface-driven模式,每個session最多只能為這三個不同類型的消息注冊一個MessageHandler.
當使用annotation-driven模式,針對不同類型的消息,只允許出現一個@onMessage 注解方法. 在注解方法中,消息內容中允許的參數依賴于消息類型。
Javadoc for the @OnMessage annotation 明確指定了消息類型上允許出現的消息參數:
- "如果方法用于處理文本消息:
- 如果方法用于處理二進制消息:
- 如果方法是用于處理pong消息:
任何Java對象使用編碼器都可以編碼為基于文本或二進制的消息.這種基于文本或二進制的消息將轉輸到其它端點,在其它端點,它可以解碼成Java對象-或者被另外的WebSocket 包解釋.
通常情況下,XML或JSON用于來傳送WebSocket消息, 編碼/解碼然后會將Java對象編組成XML或JSON并在另一端解碼為Java對象.
encoder是以javax.websocket.Encoder 接口的實現來定義,decoder是以javax.websocket.Decoder 接口的實現來定義的.
有時,端點實例必須知道encoders和decoders是什么.使用annotation-driven方式, 可向@ClientEndpoint 和 @ServerEndpoint l注解中的encode和decoder元素傳遞 encoders和decoders的列表。
Listing 1 中的代碼展示了如何注冊一個 MessageEncoder 類(它定義了MyJavaObject實例到文本消息的轉換). MessageDecoder 是以相反的轉換來注冊的.
@ServerEndpoint(value="/endpoint", encoders = MessageEncoder.class, decoders= MessageDecoder.class) public class MyEndpoint { ... } class MessageEncoder implements Encoder.Text<MyJavaObject> { @override public String encode(MyJavaObject obj) throws EncodingException { ... } } class MessageDecoder implements Decoder.Text<MyJavaObject> { @override public MyJavaObject decode (String src) throws DecodeException { ... } @override public boolean willDecode (String src) { // return true if we want to decode this String into a MyJavaObject instance } } Listing 1
Encoder 接口有多個子接口:
Encoder.Text 用于將Java對象轉成文本消息Encoder.TextStream 用于將Java對象添加到字符流中Encoder.Binary 用于將Java對象轉換成二進制消息Encoder.BinaryStream 用于將Java對象添加到二進制流中
類似地,Decoder 接口有四個子接口:
Decoder.Text 用于將文本消息轉換成Java對象Decoder.TextStream 用于從字符流中讀取Java對象Decoder.Binary 用于將二進制消息轉換成Java對象Decoder.BinaryStream 用于從二進制流中讀取Java對象
結論
WebSocket Java API為Java開發者提供了標準API來集成IETF WebSocket標準.通過這樣做,Web 客戶端或本地客戶端可使用任何WebSocket實現來輕易地與Java后端通信。
Java Api是高度可配置的,靈活的,它允許java開發者使用他們喜歡的模式。
也可參考
posted @
2016-07-24 01:35 胡小軍 閱讀(2769) |
評論 (0) |
編輯 收藏
摘要: Servlets定義為JSR 340,可以下載完整規范.servlet是托管于servlet容器中的web組件,并可生成動態內容.web clients可使用請求/響應模式同servlet交互. servlet容器負責處理servlet的生命周期事件,接收請求和發送響應,以及執行其它必要的編碼/解碼部分.WebServlet它是在POJO上使用@WebServlet注...
閱讀全文
posted @
2016-07-24 01:32 胡小軍 閱讀(862) |
評論 (0) |
編輯 收藏在本章中,我們將涵蓋下面的主題:
- 監控RabbitMQ的行為
- 使用RabbitMQ進行故障診斷
- 跟蹤RabbitMQ當前活動
- 調試RabbitMQ的消息
- 當RabbitMQ重啟失敗時該做什么
- 使用Wireshark來調試
介紹
每當我們開發一個應用程序的時候,一種常見的做法是開發一個診斷基礎設施. 這可以基于日志文件,SNMP 轉移以及其它手段.
RabbitMQ提供了標準日志文件和內建消息故障診斷解決方案.
在前面三個食譜中,我們將看到如何來使用這三種特性.
某些時候,會存在一些阻止RabbitMQ啟動的問題.在這種情況下,需要強制解決服務器上的問題并重啟服務器。這一點,我們將在RabbitMQ重啟失敗時該做什么食譜中講解。
然而,調試消息也是應用程序開發的一部分.在這種情況下,我們需要知道RabbitMQ和客戶之間交換的準確信息.可以使用一個內建代理工具(Java client API的一部分) (查看調試RabbitMQ的消息食譜)或者使用高級網絡監視工具來檢查網絡狀況,正如我們將在使用Wireshark來調試食譜中看到的一樣。
監控RabbitMQ行為
為了檢查RabbitMQ的正常行為,有一個監控工具是很有用的,特別是在處理集群的時候.
有許多不同的工具,商業的或免費的, 這有助于讓它們受控于分布式系統如Nagios、Zabbix之下.
在本食譜中,我們將展示如何配置Ganglia RabbitMQ 插件(http://sourceforge.net/apps/trac/ganglia/wiki/ganglia_quick_start).
準備
為了運行此食譜,你需要啟用管理插件來配置RabbitMQ。同時,你也需要安裝和配置Ganglia. 在本食譜中,我們使用的版本是3.6.0.
如何做
為了使用Ganglia監控圖形來查看RabbitMQ統計數據,你需要執行下面的步驟:
1. 在你的Linux發行版上,使用yum或apt-get安裝和配置Ganglia.你需要下面的包:
? ganglia-gmetad
? ganglia-gmond
? ganglia-gmond-python
? ganglia-web
? ganglia
2. 從https://github.com/ganglia/gmond_python_modules/blob/master/rabbit/python_modules/rabbitmq.py拷貝Python Ganglia監控插件到/usr/lib64/ganglia/python_modules.
3. 從https://github.com/ganglia/gmond_python_modules/blob/master/rabbit/conf.d/rabbitmq.pyconf拷貝Python Ganglia 配置文件到/etc/ganglia/conf.d
4. 檢查配置文件中的參數正確性.實際上, 你可能需要通過只留下默認的虛擬主機來解決以下條目:
paramvhost {
value = "/"
}
5.如果它已經運行了,使用下面的命令來重啟gmond:
service gmond restart
如何工作
通過這個食譜, 你可以從Ganglia環境中來監控RabbitMQ.
TIP
對于基本的故障診斷,你可以通過日志文件來進行,默認情況下,日志文件存儲于/var/log/rabbitmq.
一旦它運行起來,你就可以從同一個web界面中,看到系統信息和RabbitMQ節點、隊列的相關信息,如下面的截圖所示:
更多
Ganglia是集群監測一種廣泛的解決方案,但不是唯一的一個。其它的解決方案還包括Nagios (www.nagios.org), Zabbix (www.zabbix.com), 以及Puppet (puppetlabs.com).
通過RabbitMQ排除故障
正如前面食譜提到的, 我們可以通過一種便利的方式,即以日志文件的方式來監控RabbitMQ行為.
也可以使用RabbitMQ自身來訪問同種信息, 通過向AMQP client通知broker的活動.
準備
要運行本食譜,我們需要運行RabbitMQ以及Java client library.
如何做
為了消費日志消息,你可在Consumer.java中執行主方法.你可在Chapter12/Recipe02/Java/src/rmqexample中找到源友. 下面,我們將高亮主要步驟:
1. 創建一個臨時匿名隊列,并將其綁定到AMQP log交換器:
String tmpQueue = channel.queueDeclare().getQueue();
channel.queueBind(tmpQueue,"amq.rabbitmq.log","#");
2. 在消費者回調(ActualConsumer.java)中,可以檢索消息和每個消息的路由鍵,并將它們打印出來:
String routingKey = envelope.getRoutingKey();
String message = new String(body);
System.out.println(routingKey + ": " + message);
3. 此時,你可以在broker上執行任何RabbitMQ操作,并且你會看到日志輸出到標準輸出上。
如何工作
RabbitMQ log交換器amq.rabbitmq.log是一個topic交換器,RabbitMQ自身用來發布其日志消息.
在我們的示例代碼中,我們使用#通配符來消費所有topics的消息.
例如,通過運行另一份代碼,我們可運行同一個broker的兩個連接,然后中斷它,我們將下面的輸出:
info: accepting AMQP connection <0.2737.0> (127.0.0.1:54698 ->127.0.0.1:5672)
info: accepting AMQP connection <0.2753.0> (127.0.0.1:54699 ->127.0.0.1:5672)
warning: closing AMQP connection <0.2737.0> (127.0.0.1:54698 ->127.0.0.1:5672):
connection_closed_abruptly
warning: closing AMQP connection <0.2753.0> (127.0.0.1:54699 ->127.0.0.1:5672):
connection_closed_abruptly
值得注意的是,在這里報告的信息,信息和警告不是自己的一部分,但是我們在每個開始打印的路由鍵消息(前一步驟的步驟2)。
TIP
如果我們只想收到警告和錯誤消息,我們可以訂閱相應的主題.
更多
默認情況下,日志交換器-amq.rabbitmq.log被創建在虛擬主機/中。通過在RabbitMQ配置文件中定義default_vhost從而設置其位置是可能的.
追蹤RabbitMQ當前活動
有時,為了分析和調試未知的應用程序行為,我們需要追蹤RabbitMQ接收和分發的所有消息.
RabbitMQ提供追蹤這些消息的所謂的流水追蹤工具。
追蹤活動可以在運行時啟用和禁用,并且它應該只用于調試,因為它規定了broker活動的開銷.
準備
要運行此食譜,我們需要運行此食譜,我們需要運行RabbitMQ和Java client library.
如何做
RabbitMQ使用與日志消息中同樣的機制來發送追蹤消息;因此,示例代碼與前一個食譜中的非常相似.
為了消費追蹤消息,你可以執行Consumer.java中的主方法,你可在Chapter12/Recipe02/Java/src/rmqexample目錄中找到源碼.這里,我們高亮了主要步驟:
1. 創建一個臨時隊列,并將其綁定到AMQP log交換器上:
String tmpQueue = channel.queueDeclare().getQueue();
channel.queueBind(tmpQueue,"amq.rabbitmq.trace","#");
2.在消費者回調(ActualConsumer.java)中, 可以獲取每個消息,并使用下面的代碼打印出來:
String routingKey = envelope.getRoutingKey();
String message = new String(body);
Map<String,Object> headers = properties.getHeaders();
LongStringexchange_name = (LongString)
headers.get("exchange_name");
LongString node = (LongString) headers.get("node");
...
3. 可從root用戶(Linux)或在RabbitMQ命令控制臺(Windows)來激活firehose,其激活命令如下:
rabbimqctl trace_on
4. 此時,你可以向broker啟動生產和發送消息,然后你們會在標準輸出中看到追蹤信息.
5. 可調用下面的命令來禁用firehose:
rabbimqctl trace_off
如何工作
默認情況下,amq.rabbit.trace topic交換器不會接收任何消息,但一旦激活firehose后(前面步驟的步驟3),所有流經broker的消息將被按下面的規則拷貝:
1.進入broker的消息,它們是通過路由鍵publish.exchange-name發布的, 這里的exchange-name是消息最初發布的交換器名稱.
2.離開broker的消息,它們是通過路由鍵deliver.queuename發布的,這里的queue-name是消息最初被消費的隊列名稱.
3.消息的body是從原始消息中拷貝過來的.
4.原始消息的元數據會插入到拷貝消息的header屬性中. 在步驟2中,我們已經看到了,如何獲取最初分發消息的交換器名稱,但獲取所有原始信息也是可以的,即,找到所有可有字段,并將它們插到消息屬性中.firehose的官方文檔鏈接位于:http://www.rabbitmq.com/firehose.html.
調試RabbitMQ消息
有時,通過在標準輸出中記錄通過broker的消息是有用的.通過RabbitMQ Java客戶端提供的簡單應用程序來追蹤消息,也是可行的.
準備
要運行此食譜,你需要運行的RabbitMQ(運行標準端口 5672),以及RabbitMQ Java client library
如何做
RabbitMQ的Java client library中包含了一個追蹤工具,你可以按下面的步驟來進行實際使用.
1. 從http://www.rabbitmq.com/java-client.html頁面下載最新版本的RabbitMQ Java client library.
2. 將其解壓,并進入其目錄.
3. 通過下面的命令來運行Java tracer:
./runjava.sh com.rabbitmq.tools.Tracer
4. 運行用于調試Java client,并將其連接到5673端口.對于本食譜,我們可以使用包含在Java client包中的另一個Java工具,其調用如下:
./runjava.sh com.rabbitmq.examples.PerfTest -h amqp://localhost:5673 -C 1 -D 1
如何工作
追蹤工具是一個簡單的AMQP代理;默認情況下,它監聽5673端口,并會把所有的請求轉發到默認監聽5672端口的RabbitMQ broker.
所有生產或消費的消息,如同AMQP操作一樣,都會記錄到標準輸出中.
運行前面步驟的步驟4,我們使用了包含在Java client包中另一個用于作RabbitMQ壓力測試的工具.
在這里,我們只是限制了生產一個消息(-C 1) 并消費它(-D 1).
TIP
追蹤工具只在Java client API中可用.
更多
可以使用下面的代碼來為Java追蹤程序傳遞更多的參數:
./runjava.sh com.rabbitmq.tools.Tracer listenPort connectHost connectPort
listenPort指的是追蹤器監聽的端口(默認為5673), connectHost/connectPort (默認為localhost/5672) 是用于連接并轉發收到請求的主機和端口。
使用下面的命令,你可以找到所有PerfTest可用選項:
./runjava.sh com.rabbitmq.examples.PerfTest --help
也可參考
在http://www.rabbitmq.com/java-tools.html中,你可以找到Java追蹤工具以及PerfTest的文檔.
當RabbitMQ重啟失敗時,需要做什么
偶爾情況下, RabbitMQ 可能會重啟失敗。如果broker包含持久化數據時,這是一個嚴重的問題,否則,有足夠的能力重設其持久化狀態。
準備
要運行此食譜,你只需要一個測試RabbitMQ broker.
TIP
我們將銷毀所有之前定義的數據—以避免使用生產實例.
如何做
要清空RabbitMQ, 可執行下面的簡單步驟:
1. 如果RabbitMQ運行的話,停止它.
2. 定位到Mnesia 數據庫目錄.默認是/var/lib/rabbitmq/mnesia (Linux) or %APPDATA%\RabbitMQ\db (Windows).
3. 遞歸刪除其目錄和文件.
4. 重啟RabbitMQ.
如何工作
Mnesia 數據庫包含了所有運行時的RabbitMQ定義信息: 隊列,交換器,用戶等等.
通過刪除Mnesia數據庫 (或者通過重命名,這樣可以在需要的時候恢復某些數據), RabbitMQ會重置到出廠默認狀態,當RabbitMQ啟動時,它會創建一個新的Mnesia數據庫,并使用默認值進行初始化.
更多
如果broker無法在第一時間啟動,有可能是某個系統目錄存在權限問題:即要么是Mnesia數據庫目錄,要么是日志目錄,要么是某些在配置文件中指定的臨時的或自定義的目錄.
你可以在RabbitMQ故障排除頁頁找到詳盡的列表(http://www.rabbitmq.com/troubleshooting.html).
也可參考
在Mnesia API 文檔頁面(http://www.erlang.org/doc/man/mnesia.html),,你可以找到更多關于如何破解Mnesia數據庫的信息.
使用Wireshark調試
在調試RabbitMQ消息食譜中,我們已經了解過了如何來追蹤RabbitMQ的消息.
然而,以下情況并不總是可能的或可取的,即停止正在運行的客戶端(或RabbitMQ服務器),修改它的連接端口,指向一個不同的broker;我們只想監控正在實時傳遞的消息,影響系統的活動應該盡可能的少。
TIP但是,正如在前面食譜(追蹤RabbitMQ當前活動)中看到的一樣,激活firehose是可行的 .
Wireshark是一個免費的有能力解碼AMQP消息的網絡分析工具.
此工具既可用在客戶段,也可以用在服務端,從而無縫監控AMQP交通狀況.
準備
要練習這個食譜,你需要運行的RabbitMQ以及RabbitMQ Java client library.
如何做
在下面的步驟中,我們將看到如何使用Wireshark來追蹤AMQP消息:
1. 如果Wireshark在你的系統中尚不可用,那么需要從http://www.wireshark.org/下載和安裝Wireshark . 如果可能的話,你也可以從你的發行版中進行安裝,如:
yum install wireshark-gnome
2.在Linux系統中,以root用戶來啟動Wireshark.
3.啟動從環回接口中捕獲消息.
4.切換到Java client library路徑下,在終端中運行下面的命令:
./runjava.sh com.rabbitmq.examples.PerfTest -C 1 -D 1
5.停止Wireshark GUI的采集,并分析抓到的AMQP交通狀況.
如何工作
使用Wireshark,可用于檢測AMQP交通的退出或進行一個持有RabbitMQ服務器或客戶端的服務器.
在我們的例子中,我們捕獲了運行在同一臺機器上服務端和客戶端網絡交通狀況,因此連接是localhost中發生的.這也是為什么我們從環回接口中捕獲交通狀況的原因(前面步驟的步驟3).
反之,我們應該從網絡接口中進行捕獲,這種網絡接口通常是eth0或其它相似的網絡接口.
TIP
在Linux上,可以直接捕獲localhost;但同樣的操作不能應用到Windows上.在這種情況下,客戶端和服務端必須位于不同的兩臺機器上, 并且在網絡接口上(要么是物理的,要么是虛擬的)必須激活捕獲, 這樣它們之間才可連接.
所以,為了運行Wireshark的圖形用戶界面,如果RabbitMQ客戶端和服務器運行在同一個節點,你需要選擇環回接口,如圖下面的截圖所示
:
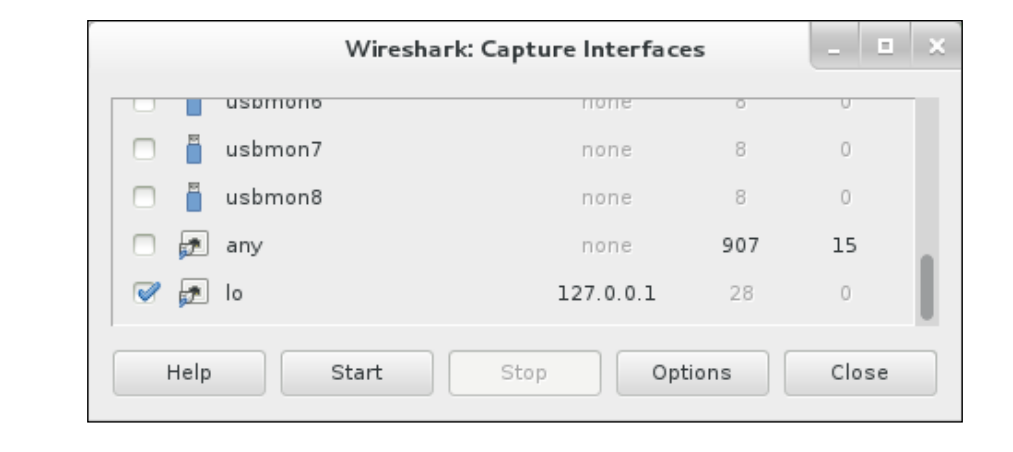
TIP
在Linux上,當你安裝Wireshark軟件包,你通常只會有命令行界面,tshark。要安裝Wireshark的GUI,你必須安裝相應的軟件包. 例如,在Fedora中,你需要安裝wireshark-gnome包.
一旦AMQP交通已穿過環回接口,它已經被Wireshark捕獲。
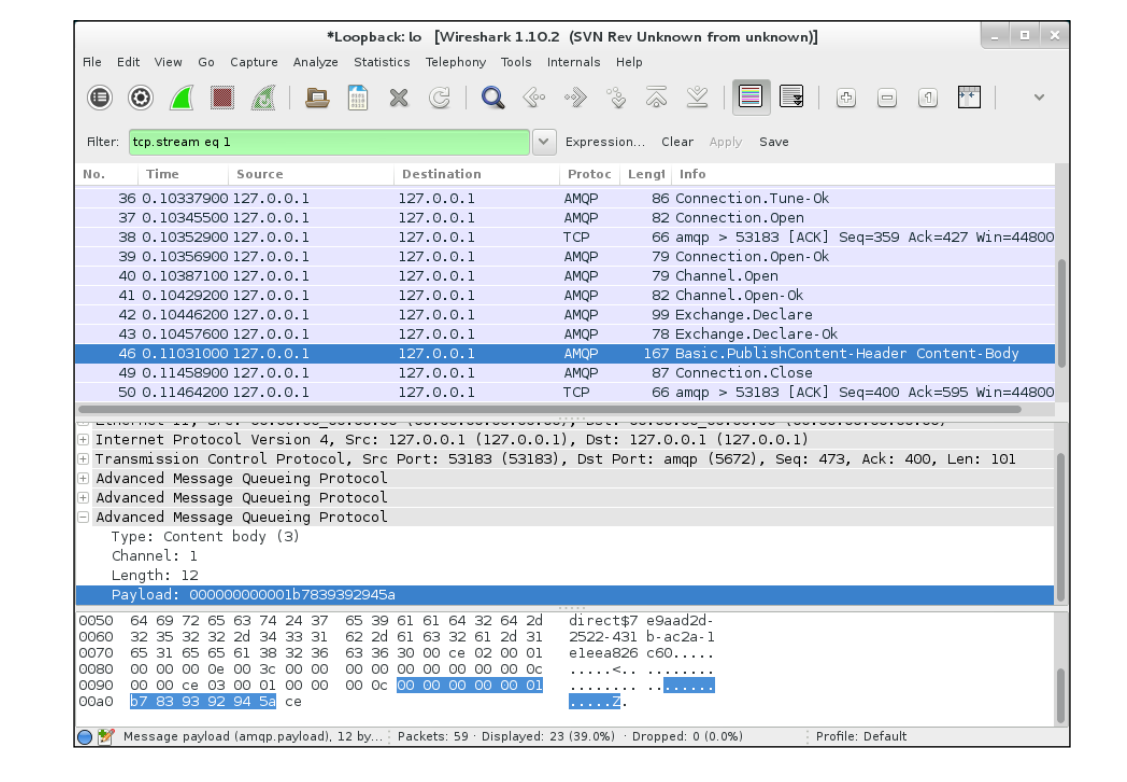
運行在步驟4的實驗實際上在兩個獨立的連接中開啟了一個生產者和一個消費者.
為了高亮顯示,找到一個描述為Basic.PublishContent-Header的包,點擊它,并選擇Follow TCP stream.然后,您可以關閉顯示客戶端和服務器之間有效負載對話的窗口。在主窗口中,您現在可以看到在客戶端和服務器之間交換的網絡數據包,如下面的截圖所示:
用同樣的方式,你可以選擇RabbitMQ server,如下面的截圖所示:
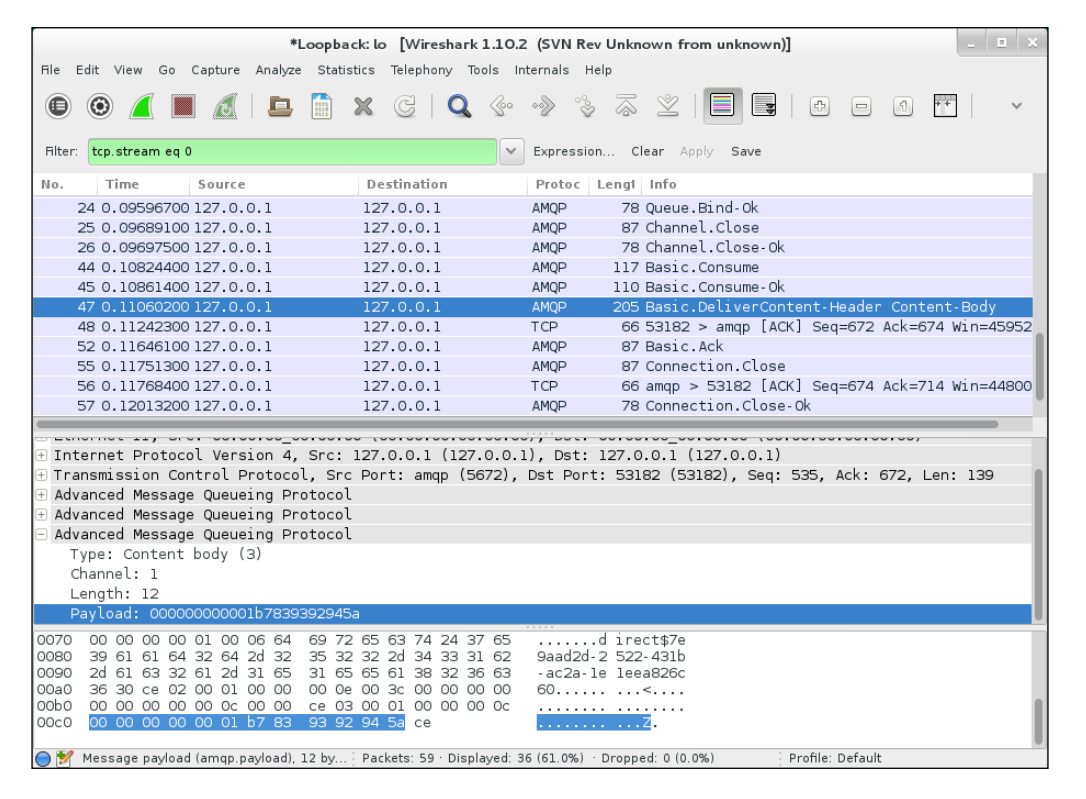
在前面的兩個截圖中,我們已經強調了消息AMQP的有效載荷,但由于Wireshark中包括了一個非常完整的AMQP解剖器,你會發現在AMQP交通的很多細節。
更多如果RabbitMQ配置為使用SSL,并且你想要分析加密流量,在一定條件下,通過在Wireshark配置中合理配置SSL公共/私有密鑰也是可以的。
可在http://wiki.wireshark.org/SSL找到更多信息.
也可參考在http://wiki.wireshark.org/AMQP,你可以找到一些關于Wireshark AMQP 解剖器的一些指南.
posted @
2016-07-20 11:39 胡小軍 閱讀(3965) |
評論 (1) |
編輯 收藏
摘要: 在本章節中,我們將展現一些RabbitMQ中的可用插件.然后,我們將展示如何使用現實世界中的例子來開發新插件.啟用和配置STOMP插件管理RabbitMQ集群監控Shovel狀態開發新插件– 使用ODBC連接關系數據庫介紹多虧了插件設施,使得RabbitMQ成為了一個可擴展平臺.它提供了許多通用插件,其中一些已經在前面的章節中解釋過了.例如, Federation和...
閱讀全文
posted @
2016-07-20 11:30 胡小軍 閱讀(2588) |
評論 (1) |
編輯 收藏
摘要: 在這一章中,我們將涵蓋:多線程和隊列系統調整改善帶寬使用不同分發工具介紹這里沒有標準的RabbitMQ調優指南,因為不同應用程序會采用不同方式優化.通常情況下,應用程序需要在客戶端進行優化:處理器密集型應用程序可以通過為每個處理器內核運行一個線程來進行優化I/O密集型應用程序可以通過在單核上運行多個線程來隱藏隱式延遲在兩種情況下,消息傳遞是完美的結合.為了優化網絡傳輸速率,AMQP標準規定消息按束...
閱讀全文
posted @
2016-07-15 14:53 胡小軍 閱讀(9356) |
評論 (0) |
編輯 收藏
摘要: 在本章中我們將覆蓋涉及:鏡像隊列同步隊列優化鏡像策略在幾個broker之間分發消息創建一個地理位置集群復制過濾和轉發消息將高可用技術結合在一起客戶端高可用性介紹RabbitMQ通過數據復制來達到高可用,當數據完整性、服務連續性是最重要的時候, 這一點與存儲(如:RAID解決方案),數據庫,以及所有IT基礎設施解決方案是相同的。事實上,這些解決方案不僅可以避免數據丟失,也可以避免計劃維護和...
閱讀全文
posted @
2016-07-02 19:11 胡小軍 閱讀(1913) |
評論 (0) |
編輯 收藏名稱
rabbitmq-service.bat — 管理RabbitMQ AMQP service
語法
rabbitmq-service.bat [command]
描述
RabbitMQ是AMQP的實現, 后者是高性能企業消息通信的新興標準. RabbitMQ server是AMQP 中間件的健壯,可擴展實現.
運行rabbitmq-service,可允許RabbitMQ broker在NT/2000/2003/XP/Vista®環境上以服務來運行,這樣就可以通過Windows® services applet來啟動和停止服務.
默認情況下,服務會以本地系統帳戶中認證上下文來運行。因此,有必要將Erlang cookies 和本地系統帳戶進行同步(典型地,C:\WINDOWS\.erlang.cookie和帳戶將用來運行 rabbitmqctl).
命令
- help
顯示使用信息.
- install
安裝service,安裝后,它不會啟動。如果環境變量修改了的話,隨后的調用將更新服務參數.
- remove
刪除service.如果刪除時,service正在運行,則將會自動停止。 它不會刪除任何文件,后續可通過rabbitmq-server 繼續操作。
- start
啟動service. 在此之前,service必須被正確安裝
- stop
停止service.
- disable
禁用service. 這等價于在服務控制面板中,將啟動類型設置為禁用.
- enable
啟用service. 這等價于在服務控制面板中,將啟動類型設置為自動.
環境變量
- RABBITMQ_SERVICENAME
默認為RabbitMQ.
- RABBITMQ_BASE
默認是當前用戶的應用程序數據目錄. 這是日志和數據目錄的位置(C:\Users\Administrator\AppData\Roaming\RabbitMQ).
- RABBITMQ_NODENAME
默認是rabbit. 當你想在一臺機器上運行多個節點時,此配置是相當有用的, RABBITMQ_NODENAME在每個erlang-node和機器的組合中應該唯一。
參考clustering on a single machine guide 來更多細節.
- RABBITMQ_NODE_IP_ADDRESS
默認情況下,RabbitMQ會綁定到所有網絡接口上,如果只想綁定某個網絡接口,可修改此設置。
- RABBITMQ_NODE_PORT
默認為5672.
- ERLANG_SERVICE_MANAGER_PATH
默認為C:\Program Files\erl5.5.5\erts-5.5.5\bin (或64位環境 中為C:\Program Files (x86)\erl5.5.5\erts-5.5.5\bin). 這是Erlang service manager的安裝位置.
- RABBITMQ_CONSOLE_LOG
將此變量設置為new或reuse,以將服務器控制臺的輸出重定向到名為SERVICENAME.debug文件中(位于安裝服務的用戶應用程序數據目錄).在Vista下,其位置在C:\Users\AppData\username\SERVICENAME. 在Windows的前期版本中,位置在C:\Documents and Settings\username\Application Data\SERVICENAME.
如果RABBITMQ_CONSOLE_LOG設置為new,那么每次服務啟動時都會創建一個新文件。
如果RABBITMQ_CONSOLE_LOG設置為reuse,那么每次服務啟動時,文件都會被覆蓋.
當RABBITMQ_CONSOLE_LOG 沒有設置或設置的值不是new或reuse時,默認的行為是丟棄服務器輸出。
posted @
2016-06-24 23:58 胡小軍 閱讀(1541) |
評論 (0) |
編輯 收藏要求
要運行ftp4j library,你需要Java 運行時環境v. 1.4+.
安裝
將ftp4j JAR文件添加到你應用程序的classpath中, 然后你就可以自動啟用ftp4j類的使用了.
Javadocs
可參考ftp4j javadocs.
快速入門
包中的主類是FTPClient (it.sauronsoftware.ftp4j.FTPClient).
創建一個FTPClient 實例:
FTPClient client = new FTPClient();
連接遠程FTP服務:
client.connect("ftp.host.com");如果服務端口不是標準的21端口 (或 FTPS的990端口),需要使用port參數進行指定:
client.connect("ftp.host.com", port);如:
client.connect("ftp.host.com", 8021);然后進行登錄流程:
client.login("carlo", "mypassword");如果沒有拋出任何異常的話,那么你就通過遠程服務器的認證了.否則,如果驗證失敗,你將會收到it.sauronsoftware.ftp4j.FTPException異常.
匿名認證,如果被連接服務認可的話, 可通過發送用戶名"anonymous" 和任意密碼來完成(注意,有些服務器需要e-mail地址來代替密碼):
client.login("anonymous", "ftp4j");使用遠程FTP服務來做任何事情,然后再斷開連接:
client.disconnect(true);
這會向遠程器發送FTP QUIT命令, 以進行一個合法斷開流程.如果你只是想中斷連接而不想向服務器發送任何通知,那么可以使用:
client.disconnect(false);
使用代理進行連接
客戶端通過連接器(一個繼承自it.sauronsoftware.ftp4j.FTPConnector的對象)來連接服務器, 它將返回一個已經打開的連接(一個實現了it.sauronsoftware.ftp4j.FTPConnection 接口的對象).這也是為什么ftp4j 可以支持大量代理的原因.
在連接遠程服務器前,客戶端實例可以使用setConnector() 方法來設置連接器:
client.setConnector(anyConnectorYouWant);
如果沒有設置連接器的話,會使用默認的連接器DirectConnector (it.sauronsoftware.ftp4j.connectors.DirectConnector), 它實現了對遠程服務器的直接連接,且不會使用代理。
如果你只能通過代理來連接遠程服務器, ftp4j包可以讓你在下面的連接器中進行選擇:
- HTTPTunnelConnector (it.sauronsoftware.ftp4j.connectors.HTTPTunnelConnector)
它可以通過HTTP代理來進行連接,并支持CONNECT方法. - FTPProxyConnector (it.sauronsoftware.ftp4j.connectors.FTPProxyConnector)
它可以通過FTP代理進行連接,支持SITE和OPEN命令風格的苛刻遠程主機連接.其它類型的FTP代理,需要username@remotehost 認證,且可以不使用連接器,因為它們對于客戶端來說是透明的。 - SOCKS4Connector (it.sauronsoftware.ftp4j.connectors.SOCKS4Connector)
它可以通過SOCKS 4/4a代理進行連接. - SOCKS5Connector (it.sauronsoftware.ftp4j.connectors.SOCKS5Connector)
它可以通過SOCKS 5代理進行連接.
因為ftp4j的連接器架構設計為可插拔的,因此你可以繼承FTPConnector 抽象類來構建自己的連接器.
FTPS/FTPES 安全連接
ftp4j包支持FTPS (隱式基于 TLS/SSL的FTP) 和FTPES (顯示基于TLS/SSL的FTP).
setSecurity() 方法可用來打開這種特性:
client.setSecurity(FTPClient.SECURITY_FTPS); // 啟用 FTPS
client.setSecurity(FTPClient.SECURITY_FTPES); // 啟用 FTPES
兩個方法都需要在連接遠程服務器前調用.
如果安全協議設置成了SECURITY_FTPS, 則connect() 方法默認使用的端口為990.
默認情況下,客戶端對象商討SSL連接會使用javax.net.ssl.SSLSocketFactory.getDefault()作為其套接字工廠.可通過調用client.setSSLSocketFactory()方法來改變默認套接字工廠. 另外一種SSLSocketFactory, 可用來信任遠程服務器頒發的證書(謹慎使用):
import it.sauronsoftware.ftp4j.FTPClient;
import java.security.KeyManagementException;
import java.security.NoSuchAlgorithmException;
import java.security.SecureRandom;
import java.security.cert.X509Certificate;
import javax.net.ssl.SSLContext;
import javax.net.ssl.SSLSocketFactory;
import javax.net.ssl.TrustManager;
import javax.net.ssl.X509TrustManager;
// ... TrustManager[] trustManager = new TrustManager[] { new X509TrustManager() {
public X509Certificate[] getAcceptedIssuers() { return null;
}
public void checkClientTrusted(X509Certificate[] certs, String authType) { }
public void checkServerTrusted(X509Certificate[] certs, String authType) { } } };
SSLContext sslContext = null;
try { sslContext = SSLContext.getInstance("SSL");
sslContext.init(null, trustManager, new SecureRandom());
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
} catch (KeyManagementException e) {
e.printStackTrace();
}
SSLSocketFactory sslSocketFactory = sslContext.getSocketFactory();
FTPClient client = new FTPClient();
client.setSSLSocketFactory(sslSocketFactory);
client.setSecurity(FTPClient.SECURITY_FTPS);
// or client.setSecurity(FTPClient.SECURITY_FTPES); // ...
瀏覽遠程站點
獲取當前目錄的的絕對路徑(此目錄是FTP服務器的home目錄):
String dir = client.currentDirectory();
改變目錄:
client.changeDirectory(newPath);
你可以使用絕對路徑和相對路徑:
client.changeDirectory("/an/absolute/one");
client.changeDirectory("relative");回到父目錄:
client.changeDirectoryUp();
重命名文件和目錄
要重命名遠程文件或目錄:
client.rename("oldname", "newname");移動文件和文件家
rename() 方法也可以用來從當前位置移動文件或目錄到其它位置.
在這個例子子,假設在當前工作目錄中,你有一個名為"myfile.txt"的文件,然后你想將其移動到子目錄"myfolder"中:
client.rename("myfile.txt", "myfolder/myfile.txt");刪除文件
要刪除遠程文件,需要調用:
client.deleteFile(relativeOrAbsolutePath);
在這個例子中:
client.deleteFile("useless.txt");創建、刪除目錄
如果遠程服務給你機會的話,你可以在遠程站點上創建新目錄:
client.createDirectory("newfolder");你也可以已存在的目錄:
client.deleteDirectory(absoluteOrRelativePath);
在這個例子中:
client.deleteDirectory("oldfolder");請注意,通常情況下,FTP 服務器只允許刪除空目錄.
列出文件、目錄、連接
FTP 協議并不會提供大量支持方法來獲取工作目錄的完整信息.通常LIST命令會給你想知道的東西,但不辛的是,每個服務器會使用不同樣式的響應. 這意味著某些服務器會返回UNIX樣式的目錄,有些服務器會返回DOS樣式的目錄,其它的服務器又會使用別的樣式.
ftp4j 包可以處理許多的LIST響應格式, 并將它們構建成統一目錄內容的結構對象表示.當前ftp4j可以處理:
- UNIX 樣式及其變種(如MAC樣式)
- DOS 樣式
- NetWare 樣式
- EPLF
- MLSD
這可以通過使用可插拔的parsers來完成.包it.sauronsoftware.ftp4j.listparsers包含了用于處理上述樣式的對象.大多數時間,這些已經夠用了。
要列出當前工作目錄下的文件或文件夾,可調用:
FTPFile[] list = client.list();
如果你收到了FTPListParseException (it.sauronsoftware.ftp4j.FTPListParseException) 異常,這就意味著服務器對LIST命令返回了不可理解的樣式,即它不是上述列出的樣式.因此,你可以嘗試使用listNames() 方法, 但它并不如list()方法有優勢.。為了彌補這種缺陷,你可以構建你自己的LIST響應解析器,以支持你遇到的樣式.你可以實現FTPListParser (it.sauronsoftware.ftp4j.FTPListParser) 接口,然后你可以在client的addListParser()方法使用此實現.
FTPFile (it.sauronsoftware.ftp4j.FTPFile) 對象提供了目錄內容的表示,包括文件,子目錄和連接. 根據服務器的響應,FTPFile對象的某些字段可以是null 的或者是無意義的.請檢查javadocs來了解細節.
在list() 方法中你也可以使用文件過濾參數,如:
FTPFile[] list = client.list("*.jpg");如果連接服務器明確支持MLSD命令, ftp4j會用其來代替基本的LIST命令。MLSD的響應事實更為標準,準確,更易解析.不幸的是,不是所有服務器都支持這個命令,并且有些服務器支持得非常糟糕.基于這些理由,開發者可以控制ftp4j是否應該使用MLSD命令,即通過調用FTPClient對象的setMLSDPolicy()方法. 合法的值:
FTPClient.MLSD_IF_SUPPORTED
client只在服務器明確支持MLSD命令時,才使用MLSD命令. 這是ftp4j默認的行為.
FTPClient.MLSD_ALWAYS
client總是會使用MLSD命令, 即便服務器沒有明確表明支持MLSD命令.
FTPClient.MLSD_NEVER
client絕不使用MLSD命令,即便服務器明確表明支持MLSD命令.
例如:
client.setMLSDPolicy(FTPClient.MLSD_NEVER);獲取文件、目錄的最后修改時間
通常情況下FTPFile對象會告訴你條目的最后修改時間, 但正如上面描述的,這依賴于服務器發回的響應.如果你需要最后的修改時間,但你又不能通過list()方法得到,那么可以嘗試這樣做:
java.util.Date md = client.modifiedDate("filename.ext");下載、上傳文件
下載遠程文件最簡單的方式是調用download(String, File) 方法:
client.download("remoteFile.ext", new java.io.File("localFile.ext"));要上傳:
client.upload(new java.io.File("localFile.ext"));要在已有文件中上傳追加內容:
client.append(new java.io.File("localFile.ext"));這些是阻塞式調用:它們會在傳輸完成后(或failed, 或 aborted時)才返回. 此外同步鎖是否由客戶端來實施的,因為在每個時間段內只允許有一個常規的FTP通信.在每個時間段內,你可以處理多個傳輸器,即使用多個FTPClient 對象,每個都與服務器建立一個私有連接.
你可以使用FTPDataTransferListener (it.sauronsoftware.ftp4j.FTPDataTransferListener)對象來監控傳輸.你可以自己實現一個:
import it.sauronsoftware.ftp4j.FTPDataTransferListener;
public class MyTransferListener implements FTPDataTransferListener {
public void started() {
// Transfer started
}
public void transferred(int length) {
// Yet other length bytes has been transferred since the last time this
// method was called
}
public void completed() {
// Transfer completed
}
public void aborted() {
// Transfer aborted
}
public void failed() {
// Transfer failed
}
}
現在像下面這樣來下載或上傳:
client.download("remoteFile.ext", new java.io.File("localFile.ext"), new MyTransferListener());client.upload(new java.io.File("localFile.ext"), new MyTransferListener());client.append(new java.io.File("localFile.ext"), new MyTransferListener());當client處理下載或上傳時,傳輸器可以被同一個FTPClient對象的不同線程通過調用 abortCurrentDataTransfer() 方法aborted. 此方法還需要一個boolean參數:true表示執行合法的abort過程(即向服務器發送ABOR命令), false表示實然關閉傳輸器,而不向服務器發送通知:
client.abortCurrentDataTransfer(true); // Sends ABOR
client.abortCurrentDataTransfer(false); // Breaks abruptly
需要注意的是,list()和listNames() 方法暗中包含了數據傳輸器,因abortCurrentDataTransfer() 方法也可以用來中斷其list過程.
當數據傳輸器在download(), upload(), append(), list() and listNames() 方法中中斷時,將會拋出FTPAbortedException (it.sauronsoftware.ftp4j.FTPAbortedException).
下載和上傳操作可通過restartAt 參數來重新恢復:
client.download("remoteFile.ext", new java.io.File("localFile.ext"), 1056);此操作會文件的第1056個字節處繼續執行下載操作。第一個傳輸的字節將是第1057個.
其它 download(), upload() 和append()方法的變種可以讓你使用流來替代java.io.File對象.因此你可以在數據庫,網絡連接或其它流上來傳輸數據。
Active 、 passive 數據傳輸模式
客戶端和服務器之間的數據傳輸通道是通過單獨的網絡連接來建立的. 在傳輸通道建立期間,服務器可以是active或passive的. 服務器激活數據傳輸時,工作如下:
- client向服務器發送其IP地址和端口號.
- client向服務器發送數據傳輸請求,并在之前發送的端口上啟動監聽.
- 服務器使用客戶端提供的地址和端口來連接客房端.
- 數據傳輸將在新建立的通道中進行.
active模式需要你的client能夠收到來自服務器的連接.如果你的client處于防火墻, 代理或這兩者混合之后,那么大部分時間都會出現問題,因為它不能收到來外界的連接. 下面是passive數據傳輸模式:
- client要求服務器準備好一個passive數據傳輸.
- 服務器使用其IP地址和端口號進行響應.
- client請求傳輸和連接.
- 數據傳輸將在新建立的通道中進行.
在passive模式中,客戶端連接不要求能收到服務器的連接請求.
在ftp4j中,你可以使用下面的調用來切換active、passive模式:
client.setPassive(false); // Active mode
client.setPassive(true); // Passive mode
ftp4j client passive 標志的默認值為true: 如果你沒有調用setPassive(false) ,你的客戶端在每次傳輸前,都會向服務器請求passive模式.
當使用 passive文件傳輸時,服務器會提供一個 IP地址和一個端口號.作為FTP規范的client,需要使用給定的主機號和端口進行連接.在商業環境中,這種行為可能會經常帶來問題,因為NAT配置可能會阻止對IP地址的連接.這就是為什么FTP clients通常會忽略服務器返回的任何IP地址,進而在通信線路中使用同樣的主機來連接服務器.ftp4j的行為依賴于服務器因素:
- 每個FTPConnector 都有其默認行為.大部分連接器都會忽略服務器返回的IP地址。目前,默認使用返回地址的連接器是FTPProxyConnector.
- 連接器的行為可通過定義名為ftp4j.passiveDataTransfer.useSuggestedAddress的系統屬性來覆蓋。如果設置為"true", "yes" 或"1",所有連接器都會使用服務器返回的地址,反之,如果將其設置為"false", "no" or "0", 所有服務器都不會使用返回的地址.
- 最后,連接器的默認行為和全局設置都可以在任何連接器實例中進行覆蓋。你可通過獲取客房端連接器,并調用其setUseSuggestedAddressForDataConnections() 方法來達到目的.
在active傳輸模式中,可以設置下面的系統屬性:
ftp4j.activeDataTransfer.hostAddress
主機地址.當服務器請求執行與客戶端連接時,client會跳轉到給定地址的服務器. 此值應該是一個有效的IPv4地址,如:178.12.34.167. 如果沒有提供此值,客戶端會自動解析系統地址.但如果client運行于LAN中,為了激活數據傳輸,將會使用帶端口轉發的路由器來連接外部服務器,那么自動探測到的地址可能不是正確的. 當系統有多個網絡接口時,也可能發生這種情況.通常使用系統屬性,可以解決這種問題
ftp4j.activeDataTransfer.portRange
連接端口范圍. client會在其中挑選一個來進行數據傳輸.此值 必須是start-stop 形式 ,如6000-7000 表示client只會在給定范圍內挑選一個端口來連接服務器.默認情況下沒有指定端口范圍:這表示client會挑選任何一個可用的端口.
ftp4j.activeDataTransfer.acceptTimeout
以毫秒為單位的連接超時時間. 如果服務器不能在給定超時時間內連接client,傳輸會因FTPDataTransferException異常而中斷.0值表示永不超時。默認值30000 (即30秒).
要設置系統屬性,你可以:
用一個或多個 -Dproperty=value參數來啟動JVM.如:
java -Dftp4j.activeDataTransfer.hostAddress=178.12.34.167 -Dftp4j.activeDataTransfer.portRange=6000-7000 -Dftp4j.activeDataTransfer.acceptTimeout=5000 MyClass
直接在代碼中設置系統屬性,如:
System.setProperty("ftp4j.activeDataTransfer.hostAddress", "178.12.34.167");
System.setProperty("ftp4j.activeDataTransfer.portRange", "6000-7000");
System.setProperty("ftp4j.activeDataTransfer.acceptTimeout", "5000");
二進制和文本數據傳輸類型
數據傳輸的另一個核心概念是binary 和textual 類型.當傳傳輸的文件是二進制文件時,它將視為二進制流,服務器會按原樣存儲。而文本數據傳輸會將傳輸的文件視為字符流,會進行字符集轉換. 假設你的client正運行Windows平臺上,而服務器運行UNIX上,它們的默認字符集通常是不同的. client以文本類型來發送文件時,client會假設文件是按機器標準字符集來編碼的,因此在發送前,它會解碼每個字符并將其編碼為 中間字符集. 服務器收到流后,在存儲前,會解碼中間字符集,并將其編碼為機器默認的字符集.字節雖然被改變了,但內容是相同的。
你可以調用下面的方法選擇你傳輸的類型:
client.setType(FTPClient.TYPE_TEXTUAL);
client.setType(FTPClient.TYPE_BINARY);
client.setType(FTPClient.TYPE_AUTO);
默認的TYPE_AUTO常量 ,會讓client自動來挑選類型:如果文件的擴展名是client能被識別的文本類型標記,那么它會選擇文本傳輸器來執行. 文件擴展名是通過FTPTextualExtensionRecognizer (it.sauronsoftware.ftp4j.FTPTextualExtensionRecognizer) 實例來識別的. 默認擴展識別器是it.sauronsoftware.ftp4j.recognizers.DefaultTextualExtensionRecognizer, 會將下面的視為文本類型:
abc acgi aip asm asp c c cc cc com conf cpp
csh css cxx def el etx f f f77 f90 f90 flx
for for g h h hh hh hlb htc htm html htmls
htt htx idc jav jav java java js ksh list
log lsp lst lsx m m mar mcf p pas php pl pl
pm py rexx rt rt rtf rtx s scm scm sdml sgm
sgm sgml sgml sh shtml shtml spc ssi talk
tcl tcsh text tsv txt uil uni unis uri uris
uu uue vcs wml wmls wsc xml zsh
你可通過實現FTPTextualExtensionRecognizer 接口來實現你自己的識別器,但你可以更喜歡使用 class ParametricTextualExtensionRecognizer(it.sauronsoftware.ftp4j.recognizers.ParametricTextualExtensionRecognizer)便利類.
無論如何,都不要忘記將你的識別器設置在client中:
client.setTextualExtensionRecognizer(myRecognizer);
數據傳輸壓縮
有些服務器支持數據傳輸壓縮特性-MODE Z. 在傳輸大文件時,此特性可以節省帶寬.一旦client連上服務器并通過認證,就可通過調用下面的方法來檢查是否支持壓縮:
boolean compressionSupported = client.isCompressionSupported();如果服務器端支持壓縮,就可通過下面的調用來啟用壓縮:
client.setCompressionEnabled(true);在此調用之后,后續的數據傳輸(下載,上傳,列舉操作)都被將壓縮以節省帶寬.
數據傳輸壓縮可通過下面的調用來禁用:
client.setCompressionEnabled(false);也可以檢查標記值:
boolean compressionEnabled = client.isCompressionEnabled();請注意:壓縮數據傳輸只當壓縮支持且啟用了的情況下才會發生.
默認情況下,壓縮是禁用的,即便是服務器支持壓縮. 如果有需要,可以顯示地打開.
不做任何事(NOOPing the server)
假設你的client什么事情都不做,因為在等待用戶輸入. 通常情況下, FTP服務器會自動斷開非活躍客戶端. 為了避免超時,你可以發送NOOP命令.
此命令不會做任何事情,但它會向服務器說明:客戶端仍然還活著,請重圍超時計數器.調用如下:
client.noop();
當非活躍超時發生時,客戶端也可以自動發送NOOPs. 默認情況下,此特性是禁用的。它可以在 setAutoNoopTimeout() 方法中設置超時時間時啟用,并提供一個毫秒為單位的值.如:
client.setAutoNoopTimeout(30000);
使用此值,client會在30秒后發送一個NOOP命令.
NOOP超時可通過設置小于等于0的值來禁用:
client.setAutoNoopTimeout(0);
網站特殊的自定義命令
你可以像下面這樣來發送站點特殊命令:
FTPReply reply = client.sendSiteCommand("YOUR COMMAND");你也可以發送自定義命令:
FTPReply reply = client.sendCustomCommand("YOUR COMMAND");sendSiteCommand() 和 sendCustomCommand() 都會返回一個FTPReply (it.sauronsoftware.ftp4j.FTPReply)對象.使用此對象,你可以檢查服務器的響應代碼和消息.
FTPCodes (it.sauronsoftware.ftp4j.FTPCodes) 接口報告了一些通用的FTP響應代碼,因此你可以使用這些包中的某個來進行匹配.
異常處理
ftp4j 包定義了五種類型的異常:
- FTPException (it.sauronsoftware.ftp4.FTPException)
依賴于方法,這會報告拋出了一個FTP故障.你可以檢查報告的錯誤碼,使用FTPCodes 常量來獲取故障原因的詳細信息. - FTPIllegalReplyException (it.sauronsoftware.ftp4.FTPIllegalReplyException)
這表示遠程服務器使用非法方式進行了應答, 這與FTP是不兼容的. 這應該是非常罕見的. - FTPListParseException (it.sauronsoftware.ftp4.FTPListParseException)
這通常發生在list()方法,如果服務器發回的響應不能被客戶端包中現有解析器進行的話,就會拋出此種異常 - FTPDataTransferException (it.sauronsoftware.ftp4.FTPDataTransferException)
當數據傳輸 (download, upload, but also list and listNames) 因網絡連接錯誤失敗時,就會拋出此種異常. - FTPAbortedException (it.sauronsoftware.ftp4.FTPAbortedException)
當數據傳輸 (download, upload, but also list and listNames) 因客戶端發出中斷請求失敗時,拋出的異常.
posted @
2016-06-21 22:34 胡小軍 閱讀(5993) |
評論 (0) |
編輯 收藏