#
習(xí)慣Spring + Hibernate帶來的方便, 但有時(shí)在應(yīng)用中測試Hibernate的新功能并不是很方便.
實(shí)際上Hibernate的test代碼就有這個功能, 而且不用考慮create table等麻煩事.
在自己的project中使用, 只需繼承org.hibernate.test.TestCase, 改變hand code的路徑, 設(shè)定hibernate.properties文件, 這樣就有了純Hibernate測試環(huán)境
 public abstract class HibernateTestCase extends TestCase
public abstract class HibernateTestCase extends TestCase


 {
{
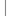 protected HibernateTestCase(String x)
protected HibernateTestCase(String x)

 {
{
super(x);
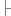 }
}
protected String getBaseForMappings() {
return "com/waterye/test/";
}
/**//**
* true時(shí), 使用auto schema export, hibernate.hbm2ddl.auto create-drop
*/
protected boolean recreateSchema() {
return false;
}
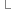 }
}
說明: 以idea為例
1. 將hibernate.properties放到test根目錄下
2. pojo, hbm.xml, Test.java放到同一目錄下(參考hibernate的測試代碼)
3. 在idea中run test method
使用Oracle特有的查詢語法, 可以達(dá)到事半功倍的效果
1. 樹查詢
create table tree (
id number(10) not null primary key,
name varchar2(100) not null,
super number(10) not null // 0 is root
);
-- 從子到父
select * from tree start with id = ? connect by id = prior super
-- 從父到子
select * from tree start with id = ? connect by prior id = suepr
-- 整棵樹
select * from tree start with super = 0 connect by prior id = suepr 2. 分頁查詢
select * from (
select my_table.*, rownum my_rownum from (
select name, birthday from employee order by birthday
) my_table where rownum < 120
) where my_rownum >= 100; 3. 累加查詢, 以scott.emp為例
select empno, ename, sal, sum(sal) over(order by empno) result from emp;
EMPNO ENAME SAL RESULT
---------- ---------- ---------- ----------
7369 SMITH 800 800
7499 ALLEN 1600 2400
7521 WARD 1250 3650
7566 JONES 2975 6625
7654 MARTIN 1250 7875
7698 BLAKE 2850 10725
7782 CLARK 2450 13175
7788 SCOTT 3000 16175
7839 KING 5000 21175
7844 TURNER 1500 22675
7876 ADAMS 1100 23775
7900 JAMES 950 24725
7902 FORD 3000 27725
7934 MILLER 1300 29025 4. 高級group by
select decode(grouping(deptno),1,'all deptno',deptno) deptno,
decode(grouping(job),1,'all job',job) job,
sum(sal) sal
from emp
group by ROLLUP(deptno,job);
DEPTNO JOB SAL
---------------------------------------- --------- ----------
10 CLERK 1300
10 MANAGER 2450
10 PRESIDENT 5000
10 all job 8750
20 CLERK 1900
20 ANALYST 6000
20 MANAGER 2975
20 all job 10875
30 CLERK 950
30 MANAGER 2850
30 SALESMAN 5600
30 all job 9400
all deptno all job 29025 5. use hint
當(dāng)多表連接很慢時(shí),用ORDERED提示試試,也許會快很多
SELECT /**//*+ ORDERED */*
FROM a, b, c, d
WHERE
dbunit: DbUnit is a JUnit extension (also usable with Ant) targeted for database-driven projects
official site, 好久沒更新了, 最新版本2.1還是2004年5月的
1. use ant task
<taskdef classpathref="project.classpath" classname="org.dbunit.ant.DbUnitTask" name="dbunit" />
導(dǎo)出數(shù)據(jù)
<target name="export">
<dbunit password="${database.password}" userid="${database.userid}"
url="${database.url}" driver="${database.driver}" supportbatchstatement="true">
<export format="xml" dest="data/export-data.xml">
<query name="FOO" sql="SELECT COL1, COL2 FROM FOO WHERE COL1=4"/>
<table name="BAR"/>
</export>
</dbunit>
</target>
tip: 不指定query、table, 導(dǎo)出所有的table
導(dǎo)入數(shù)據(jù)
<target name="clean_insert">
<dbunit password="${database.password}" userid="${database.userid}"
url="${database.url}" driver="${database.driver}">
<operation format="xml" src="data/init-data.xml" type="CLEAN_INSERT" />
</dbunit>
</target>
tip:
type: UPDATE, INSERT, DELETE, DELETE_ALL, REFRESH,
MSSQL_INSERT, MSSQL_REFRESH, MSSQL_CLEAN_INSERT.
比較數(shù)據(jù)
<target name="compare">
<dbunit password="${database.password}" userid="${database.userid}"
url="${database.url}" driver="${database.driver}">
<compare format="xml" src="data/init-data.xml" />
</dbunit>
</target>
2. use code
導(dǎo)出數(shù)據(jù)
IDatabaseConnection conn = new DatabaseConnection(jdbcConnection, schema); // oracle指定schema
IDataSet dataSet = conn.createDataSet();
XmlDataSet.write(dataSet, new FileOutputStream("export-data.xml")); // xml file
FlatXmlDataSet.write(dataSet,new FileOutputStream("export-data.xml")); // flat xml file
XlsDataSet.write(dataSet,new FileOutputStream("export-data.xls")); // xls file
FlatDtdDataSet.write(dataSet,new FileOutputStream("export-data.dtd")); // dtd file
CsvDataSetWriter.write(dataSet, new File("export-data-csv")); // csv file
使用DatabaseSequenceFilter, 解決違反外鍵約束的問題
IDatabaseConnection conn = new DatabaseConnection(jdbcConnection);
ITableFilter filter = new DatabaseSequenceFilter(conn);
// ITableFilter filter = new DatabaseSequenceFilter(conn, tableNames);
IDataSet dataset = new FilteredDataSet(filter, conn.createDataSet());
XmlDataSet.write(dataset, new FileOutputStream("export-data.xml"));
導(dǎo)入數(shù)據(jù)
DatabaseOperation.REFRESH.execute(conn, dataSet);
DatabaseOperation.INSERT.execute(conn, dataSet);
刪除數(shù)據(jù)
DatabaseOperation.DELETE.execute(conn, dataSet);
比較數(shù)據(jù)
IDatabaseConnection conn = new DatabaseConnection(jdbcConnection);
Compare compare = new Compare();
compare.setFormat("xml");
compare.setSrc(new File("export-data.xml"));
compare.execute(conn);
tip: 使用assert進(jìn)行比較, 作用不大
code: Assertion.assertEquals(expectedTable, actualTable);
3. QueryDataSet: use sql
QueryDataSet queryDataSet = new QueryDataSet(conn);
queryDataSet.addTable("orders", ordersQuerySQL);
使intellij idea更加強(qiáng)大的plugins
?
1. BackgroudImage
在代碼編輯器顯示背景圖, 個人喜歡透明度為10%
?
2. GenerateToString
為Java Bean生成toString()
?
3. UpperLowerCapitalize
Alt-C (Capitalize), Alt-L (Lowercase), Alt-P (Uppercase)
4. GroovyJ
groovy plugin for idea
?
5. Tomcat Integration
6. CVS Integration
7. JUnit Generator
自動生成test code
?
8.? sql query plugin
新版本功能更強(qiáng)大, 個人主要用于從代碼中抽取出sql語句, 然后到pl/sql developer debug
?
9. IdeaJad
反編譯工具
10. PropertiesEditor
編輯屬性文件
11. ShowEncodingPlugin