==========================================================
概述
JDBC類庫使得Java程序可以訪問多個數據源,但在大多數情況下,這個數據源是關系數據庫,并且通過SQL訪問。然而,實現JDBC技術的驅動也可以基于其它的數據源,包括遺留文件系統和面向對象的系統。JDBC類庫的一個主要目的就是提供一個應用程序訪問多種數據源的標準接口。
這一章介紹JDBC類庫的一些關鍵概念,并描述JDBC應用的兩個通用環境及其中的功能實現。兩層和三層模型都是能被實現在多個物理配置上的邏輯模型。
=================================================
4.1 創建連接
JDBC類庫中的Connection接口代表了底層數據源的一個連接。
在典型場景中,JDBC應用程序使用兩種機制連接到數據源:
1.DriverManager --- 這個類在JDBC 1.0中引入,它使用硬編碼的URL來加載驅動。
2.DataSource --- 這個接口在JDBC 2.0可選包中引入。它優于DriverManager方式,因為它隱藏了數據源的詳細信息。我們通過設置DataSource的屬性來標明它代表的數據源。當getConnection方法被調用時,DataSource對象會返回一個對應的連接。我們可以通過改變DataSource的屬性來使它指向另一個數據源,而不是改變程序代碼。而且,即使DataSource的實現改變了,使用它的應用程序代碼也不需要改變。
JDBC類庫定義了兩個DataSource的擴展來支持企業級應用,如下:
1.ConnectionPoolDataSource --- 支持物理連接的緩存和重用,這樣可以提高應用的性能和可伸縮性。
2.XADataSource --- 提供可以使用在分布式事務中的連接。
=========================================================
4.2 執行SQL語句和操縱結果
連接建立后,我們可以使用JDBC類庫對目標數據源進行查詢和更新。JDBC類庫提供了對大多數SQL2003通用特性的支持。由于各個廠商可能要支持不同的特性,JDBC類庫提供了一個DatabaseMetadata接口。應用可以通過這個接口了解數據源是否支持某個特性。JDBC類庫也定義了轉義語義來支持特定廠商非標準的特性。轉義語義使得我們可以訪問與本地程序相同的SQL特性集,同時保持應用的可移植性。
應用通過使用Connection接口來設置事務屬性和創建Statement, PreparedStatement和CallableStatement. 這些statement被用來執行SQL語句和檢索結果。ResultSet接口封裝了SQL查詢的結果。語句也可以批處理,這樣應用可以通過一次單元執行提交對數據源的多次更新。
RowSet接口擴展了ResultSet接口。它提供了一個比標準結果集功能更多的表數據容器。RowSet對象是Java Beans組件,它可以在中斷數據庫連接的情況下操縱數據。例如,一個RowSet實現可以被序列化從而傳送到網絡上,這對于吞吐量小的客戶端尤為有用,因為這可以省去加載JDBC驅動和建立JDBC連接的開銷。RowSet還可以使用定制的閱讀器(Reader)來訪問表格數據(不僅僅是關系數據庫的數據)。甚者,RowSet對象可以在中斷數據庫連接的情況下更新數據,并在連接正常時通過一個定制的書寫器(Writer)將更新寫入數據源。
4.2.1 對SQL高級數據類型的支持
JDBC類庫定義了SQL數據類型到JDBC數據類型的標準映射。映射也包含了對SQL2003高級數據類型如BLOB,CLOB,ARRAY,REF,STRUCT和DISTINCT的支持。JDBC驅動也可以實現多個用戶自定義類型(UDTs,user-defined types)的映射,在這里,每個UDT映射到Java中的一個類。
JDBC類庫也提供對外部數據的支持,例如數據源外部的一個文件。
========================================
4.3 兩層模型
兩層模型將功能分配到客戶端和服務器端,如圖4-1.
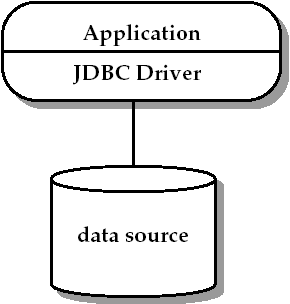
FIGURE 4-1 兩層模型
客戶端包含了應用和一個或多個JDBC驅動,這些應用負責下列內容:
* 表示邏輯
* 業務邏輯
* 對多語句事務(multiple-statement transactions)或分布式事務的管理
* 資源管理
在這個模型中,應用直接跟JDBC驅動打交道,包括建立和管理物理連接,以及處理底層數據源的相關細節。應用可以通過對數據源實現的了解來使用它的非標準特性或者提升性能。
模型的缺點:
* 將表示邏輯、業務邏輯和基礎設施、系統級別的功能混淆在一起,不利于維護。
* 由于被綁定到特定的數據庫,應用很難被移植。需要連接到多個數據庫的應用要注意各個廠商實現的區別。
* 缺少可伸縮性。典型地,應用將從始至終占有一個或多個物理連接,缺少對并發應用的支持。在這個模型中,性能、可伸縮性和可靠性問題都是由JDBC驅動和底層數據源處理的。如果應用要跟多個驅動打交道,它需要注意每個驅動/數據源對是怎么處理這些問題的。
======================================================
4.4 三層模型
三層模型引入了中間層服務器來管理業務邏輯和基礎結構,如圖4-2.

FIGURE 4-2 三層模型
這個架構為企業級應用提供了更好的性能、可伸縮性和可靠性。功能劃分如下:
1.客戶端 --- 只負責表示邏輯,處理人機交互。Java應用程序、網頁瀏覽器和PDA等都是典型的客戶端。客戶端與中間層應用交互,它不需要了解底層的基礎結構和數據源實現。
2.中間層服務器 --- 中間層包含:
* 一些應用程序。這些應用負責跟客戶端打交道和實現業務邏輯。如果應用包含與數據源的交互,它應該使用高層抽象,例如DataSource對象和邏輯連接,而不是底層的驅動程序類庫。
* 一個應用服務器。提供支持大部分應用的基礎結構。這可能包含管理和池化物理連接、管理事務和掩蓋不同JDBC驅動的細節。最后一點使得應用更容易被移植。應用服務器可以使用J2EE服務器。它應該直接和JDBC驅動交互和提供高層應用使用的功能抽象。
* 一個或多個JDBC驅動。提供與底層數據源的連接,每個驅動使用底層數據源支持的特性來實現標準JDBC類庫。驅動層需要掩蓋SQL2003標準和底層數據源語言的不同。如果數據源不是一個關系型數據庫管理系統(DBMS),那么驅動要實現應用服務器使用的關系層。
3.底層數據源 --- 存放數據的層。包含關系型數據庫管理系統(relational DBMS),遺留文件系統,面向對象的DBMS,數據倉庫,報表或者其他包裝和表示數據的方式,只要有對應的支持JDBC類庫的驅動。
===================================================
4.5 J2EE平臺中的JDBC
J2EE組件,例如JSP,Servlets和EJB,經常需要利用JDBC類庫訪問關系型數據。當在J2EE組件里使用JDBC類庫時,容器可能幫你管理事務和數據源(譯者注:Container Managed Persistence,容器管理持久性)。這樣,J2EE組件開發者就不直接使用JDBC類庫的事務和數據源管理功能。詳情請見J2EE平臺規范。