前言
這是
《深入HBase架構解析(一)》的續,不多廢話,繼續。。。。
HBase讀的實現
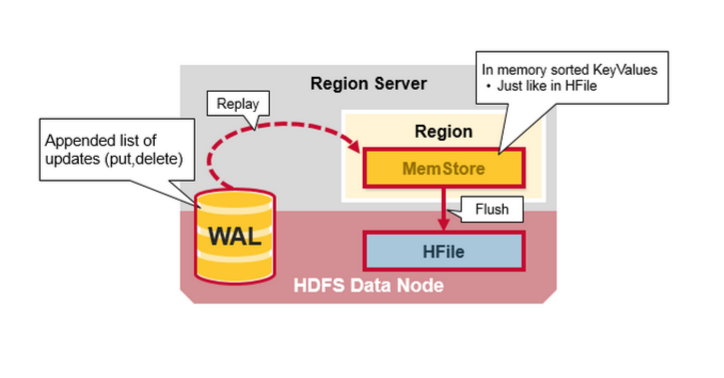
通過前文的描述,我們知道在HBase寫時,相同Cell(RowKey/ColumnFamily/Column相同)并不保證在一起,甚至刪除一個Cell也只是寫入一個新的Cell,它含有Delete標記,而不一定將一個Cell真正刪除了,因而這就引起了一個問題,如何實現讀的問題?要解決這個問題,我們先來分析一下相同的Cell可能存在的位置:首先對新寫入的Cell,它會存在于MemStore中;然后對之前已經Flush到HDFS中的Cell,它會存在于某個或某些StoreFile(HFile)中;最后,對剛讀取過的Cell,它可能存在于BlockCache中。既然相同的Cell可能存儲在三個地方,在讀取的時候只需要掃瞄這三個地方,然后將結果合并即可(Merge Read),在HBase中掃瞄的順序依次是:BlockCache、MemStore、StoreFile(HFile)。其中StoreFile的掃瞄先會使用Bloom Filter過濾那些不可能符合條件的HFile,然后使用Block Index快速定位Cell,并將其加載到BlockCache中,然后從BlockCache中讀取。我們知道一個HStore可能存在多個StoreFile(HFile),此時需要掃瞄多個HFile,如果HFile過多又是會引起性能問題。
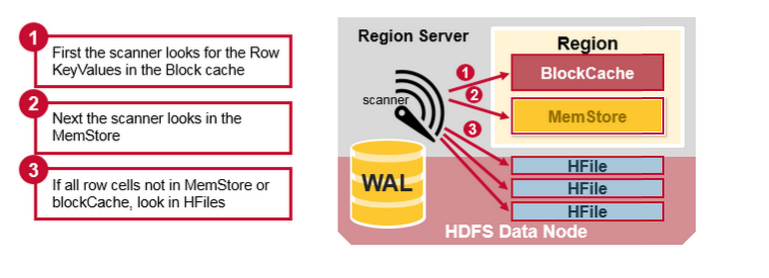
Compaction
MemStore每次Flush會創建新的HFile,而過多的HFile會引起讀的性能問題,那么如何解決這個問題呢?HBase采用Compaction機制來解決這個問題,有點類似Java中的GC機制,起初Java不停的申請內存而不釋放,增加性能,然而天下沒有免費的午餐,最終我們還是要在某個條件下去收集垃圾,很多時候需要Stop-The-World,這種Stop-The-World有些時候也會引起很大的問題,比如參考本人寫的
這篇文章,因而設計是一種權衡,沒有完美的。還是類似Java中的GC,在HBase中Compaction分為兩種:Minor Compaction和Major Compaction。
- Minor Compaction是指選取一些小的、相鄰的StoreFile將他們合并成一個更大的StoreFile,在這個過程中不會處理已經Deleted或Expired的Cell。一次Minor Compaction的結果是更少并且更大的StoreFile。(這個是對的嗎?BigTable中是這樣描述Minor Compaction的:As write operations execute, the size of the memtable in-
creases. When the memtable size reaches a threshold, the
memtable is frozen, a new memtable is created, and the
frozen memtable is converted to an SSTable and written
to GFS. This minor compaction process has two goals:
it shrinks the memory usage of the tablet server, and it
reduces the amount of data that has to be read from the
commit log during recovery if this server dies. Incom-
ing read and write operations can continue while com-
pactions occur. 也就是說它將memtable的數據flush的一個HFile/SSTable稱為一次Minor Compaction)
- Major Compaction是指將所有的StoreFile合并成一個StoreFile,在這個過程中,標記為Deleted的Cell會被刪除,而那些已經Expired的Cell會被丟棄,那些已經超過最多版本數的Cell會被丟棄。一次Major Compaction的結果是一個HStore只有一個StoreFile存在。Major Compaction可以手動或自動觸發,然而由于它會引起很多的IO操作而引起性能問題,因而它一般會被安排在周末、凌晨等集群比較閑的時間。
更形象一點,如下面兩張圖分別表示Minor Compaction和Major Compaction。
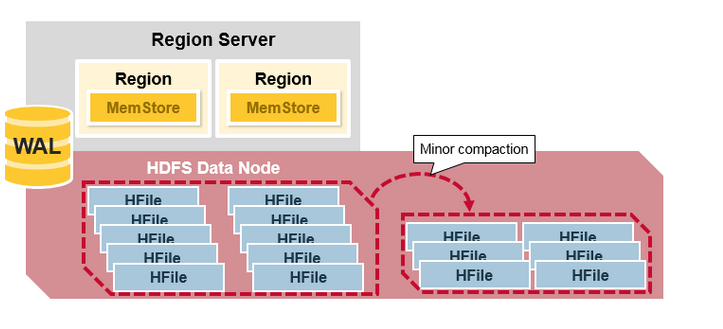
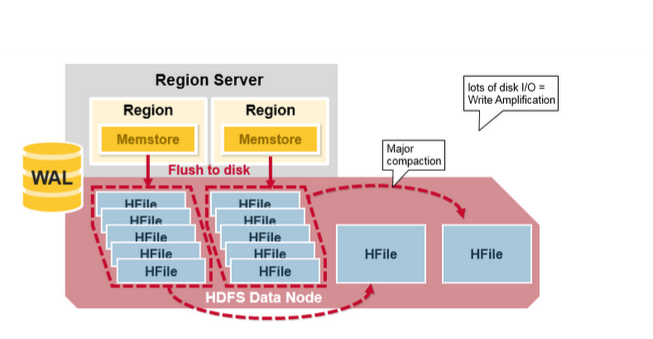
HRegion Split
最初,一個Table只有一個HRegion,隨著數據寫入增加,如果一個HRegion到達一定的大小,就需要Split成兩個HRegion,這個大小由hbase.hregion.max.filesize指定,默認為10GB。當split時,兩個新的HRegion會在同一個HRegionServer中創建,它們各自包含父HRegion一半的數據,當Split完成后,父HRegion會下線,而新的兩個子HRegion會向HMaster注冊上線,處于負載均衡的考慮,這兩個新的HRegion可能會被HMaster分配到其他的HRegionServer中。關于Split的詳細信息,可以參考這篇文章:
《Apache HBase Region Splitting and Merging》。
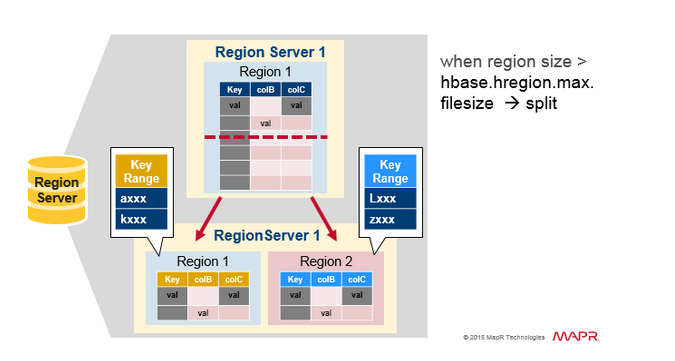
HRegion負載均衡
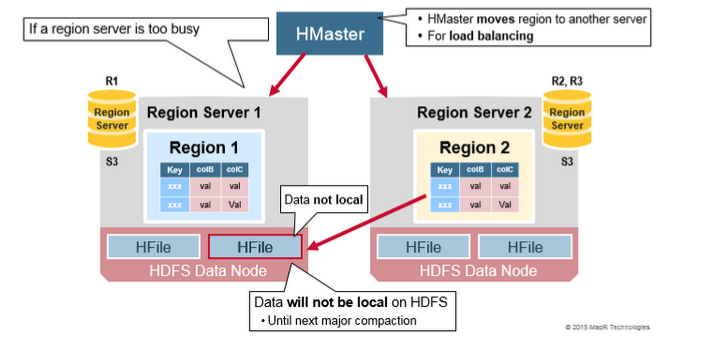
在HRegion Split后,兩個新的HRegion最初會和之前的父HRegion在相同的HRegionServer上,出于負載均衡的考慮,HMaster可能會將其中的一個甚至兩個重新分配的其他的HRegionServer中,此時會引起有些HRegionServer處理的數據在其他節點上,直到下一次Major Compaction將數據從遠端的節點移動到本地節點。
HRegionServer Recovery
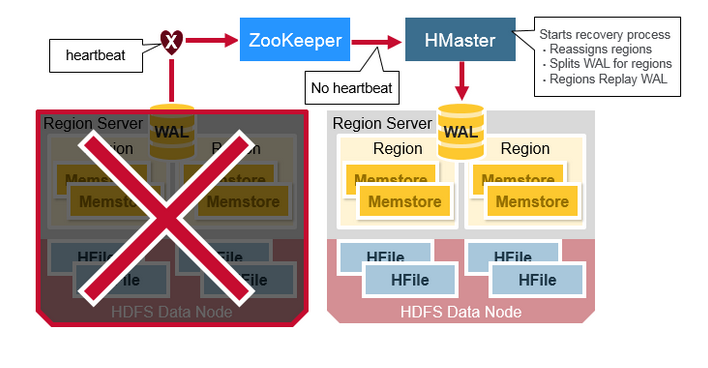
當一臺HRegionServer宕機時,由于它不再發送Heartbeat給ZooKeeper而被監測到,此時ZooKeeper會通知HMaster,HMaster會檢測到哪臺HRegionServer宕機,它將宕機的HRegionServer中的HRegion重新分配給其他的HRegionServer,同時HMaster會把宕機的HRegionServer相關的WAL拆分分配給相應的HRegionServer(將拆分出的WAL文件寫入對應的目的HRegionServer的WAL目錄中,并并寫入對應的DataNode中),從而這些HRegionServer可以Replay分到的WAL來重建MemStore。
HBase架構簡單總結
在NoSQL中,存在著名的CAP理論,即Consistency、Availability、Partition Tolerance不可全得,目前市場上基本上的NoSQL都采用Partition Tolerance以實現數據得水平擴展,來處理Relational DataBase遇到的無法處理數據量太大的問題,或引起的性能問題。因而只有剩下C和A可以選擇。HBase在兩者之間選擇了Consistency,然后使用多個HMaster以及支持HRegionServer的failure監控、ZooKeeper引入作為協調者等各種手段來解決Availability問題,然而當網絡的Split-Brain(Network Partition)發生時,它還是無法完全解決Availability的問題。從這個角度上,Cassandra選擇了A,即它在網絡Split-Brain時還是能正常寫,而使用其他技術來解決Consistency的問題,如讀的時候觸發Consistency判斷和處理。這是設計上的限制。
從實現上的優點:
- HBase采用強一致性模型,在一個寫返回后,保證所有的讀都讀到相同的數據。
- 通過HRegion動態Split和Merge實現自動擴展,并使用HDFS提供的多個數據備份功能,實現高可用性。
- 采用HRegionServer和DataNode運行在相同的服務器上實現數據的本地化,提升讀寫性能,并減少網絡壓力。
- 內建HRegionServer的宕機自動恢復。采用WAL來Replay還未持久化到HDFS的數據。
- 可以無縫的和Hadoop/MapReduce集成。
實現上的缺點:
- WAL的Replay過程可能會很慢。
- 災難恢復比較復雜,也會比較慢。
- Major Compaction會引起IO Storm。
- 。。。。
參考:
https://www.mapr.com/blog/in-depth-look-hbase-architecture#.VdNSN6Yp3qx
http://jimbojw.com/wiki/index.php?title=Understanding_Hbase_and_BigTable
http://hbase.apache.org/book.html
http://www.searchtb.com/2011/01/understanding-hbase.html
http://research.google.com/archive/bigtable-osdi06.pdf
posted on 2015-08-22 19:40
DLevin 閱讀(9141)
評論(0) 編輯 收藏 所屬分類:
HBase 、
Architecture