在Java并發(fā)編程方面,計(jì)算密集型與IO密集型是兩個(gè)非常典型的例子,這次大象就來講講自己在這方面的內(nèi)容,本篇比較基礎(chǔ),只適合剛?cè)腴T的童鞋,請(qǐng)各種牛人不喜勿噴。
計(jì)算密集型
計(jì)算密集型,顧名思義就是應(yīng)用需要非常多的CPU計(jì)算資源,在多核CPU時(shí)代,我們要讓每一個(gè)CPU核心都參與計(jì)算,將CPU的性能充分利用起來,這樣才算是沒有浪費(fèi)服務(wù)器配置,如果在非常好的服務(wù)器配置上還運(yùn)行著單線程程序那將是多么重大的浪費(fèi)。對(duì)于計(jì)算密集型的應(yīng)用,完全是靠CPU的核數(shù)來工作,所以為了讓它的優(yōu)勢完全發(fā)揮出來,避免過多的線程上下文切換,比較理想方案是:
線程數(shù) = CPU核數(shù)+1
也可以設(shè)置成CPU核數(shù)*2,這還是要看JDK的使用版本,以及CPU配置(服務(wù)器的CPU有超線程)。對(duì)于JDK1.8來說,里面增加了一個(gè)并行計(jì)算,計(jì)算密集型的較理想線程數(shù) = CPU內(nèi)核線程數(shù)*2計(jì)算文件夾大小算是一個(gè)比較典型的例子,代碼很簡單,我就不多解釋了。
import java.io.File;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
import java.util.concurrent.TimeUnit;
/**
* 計(jì)算文件夾大小
* @author 菠蘿大象
*/
public class FileSizeCalc {
static class SubDirsAndSize {
public final long size;
public final List<File> subDirs;
public SubDirsAndSize(long size, List<File> subDirs) {
this.size = size;
this.subDirs = Collections.unmodifiableList(subDirs);
}
}
private SubDirsAndSize getSubDirsAndSize(File file) {
long total = 0;
List<File> subDirs = new ArrayList<File>();
if (file.isDirectory()) {
File[] children = file.listFiles();
if (children != null) {
for (File child : children) {
if (child.isFile())
total += child.length();
else
subDirs.add(child);
}
}
}
return new SubDirsAndSize(total, subDirs);
}
private long getFileSize(File file) throws Exception{
final int cpuCore = Runtime.getRuntime().availableProcessors();
final int poolSize = cpuCore+1;
ExecutorService service = Executors.newFixedThreadPool(poolSize);
long total = 0;
List<File> directories = new ArrayList<File>();
directories.add(file);
SubDirsAndSize subDirsAndSize = null;
try{
while(!directories.isEmpty()){
List<Future<SubDirsAndSize>> partialResults= new ArrayList<Future<SubDirsAndSize>>();
for(final File directory : directories){
partialResults.add(service.submit(new Callable<SubDirsAndSize>(){
@Override
public SubDirsAndSize call() throws Exception {
return getSubDirsAndSize(directory);
}
}));
}
directories.clear();
for(Future<SubDirsAndSize> partialResultFuture : partialResults){
subDirsAndSize = partialResultFuture.get(100,TimeUnit.SECONDS);
total += subDirsAndSize.size;
directories.addAll(subDirsAndSize.subDirs);
}
}
return total;
} finally {
service.shutdown();
}
}
public static void main(String[] args) throws Exception {
for(int i=0;i<10;i++){
final long start = System.currentTimeMillis();
long total = new FileSizeCalc().getFileSize(new File("e:/m2"));
final long end = System.currentTimeMillis();
System.out.format("文件夾大小: %dMB%n" , total/(1024*1024));
System.out.format("所用時(shí)間: %.3fs%n" , (end - start)/1.0e3);
}
}
}
執(zhí)行10次后結(jié)果如下:
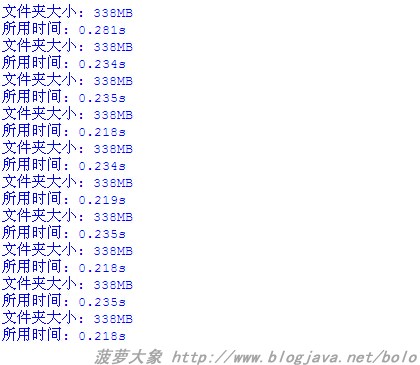
在上面的例子中,線程池設(shè)置為CPU核心數(shù)+1個(gè),這個(gè)運(yùn)行結(jié)果是大象在工作電腦(CPU:G630 內(nèi)存:4G JDK1.7.0_51)上跑出來的。如果在這里把線程池加大,比如調(diào)到100,你會(huì)發(fā)現(xiàn)所用時(shí)間變多了,大象這里最多的消耗時(shí)間是0.297秒,與之前最少的一次0.218之間相差0.079秒,也即79毫秒。當(dāng)然這多出來的時(shí)間在我們看來好像不算什么,只有零點(diǎn)零幾秒,但是對(duì)于CPU來說可是相當(dāng)長的,因?yàn)?/span>CPU里面是以納秒為計(jì)算單位,1毫秒=1000000納秒。所以加大線程池會(huì)增加CPU上下文的切換成本,有時(shí)程序的優(yōu)化就是從這些微小的地方積累起來的。
IO密集型
對(duì)于IO密集型的應(yīng)用,就很好理解了,我們現(xiàn)在做的開發(fā)大部分都是WEB應(yīng)用,涉及到大量的網(wǎng)絡(luò)傳輸,不僅如此,與數(shù)據(jù)庫,與緩存間的交互也涉及到IO,一旦發(fā)生IO,線程就會(huì)處于等待狀態(tài),當(dāng)IO結(jié)束,數(shù)據(jù)準(zhǔn)備好后,線程才會(huì)繼續(xù)執(zhí)行。因此從這里可以發(fā)現(xiàn),對(duì)于IO密集型的應(yīng)用,我們可以多設(shè)置一些線程池中線程的數(shù)量,這樣就能讓在等待IO的這段時(shí)間內(nèi),線程可以去做其它事,提高并發(fā)處理效率。
那么這個(gè)線程池的數(shù)據(jù)量是不是可以隨便設(shè)置呢?當(dāng)然不是的,請(qǐng)一定要記得,線程上下文切換是有代價(jià)的。目前總結(jié)了一套公式,對(duì)于IO密集型應(yīng)用:
線程數(shù) = CPU核心數(shù)/(1-阻塞系數(shù))
這個(gè)阻塞系數(shù)一般為0.8~0.9之間,也可以取0.8或者0.9。套用公式,對(duì)于雙核CPU來說,它比較理想的線程數(shù)就是20,當(dāng)然這都不是絕對(duì)的,需要根據(jù)實(shí)際情況以及實(shí)際業(yè)務(wù)來調(diào)整。
final int poolSize = (int)(cpuCore/(1-0.9))
本篇大象簡單談了下并發(fā)類型,旨在拋磚引玉,讓初學(xué)并發(fā)編程的朋友能夠有一些了解,說的不對(duì)的地方,還請(qǐng)各位指出來。
嘮叨完上面這些,再嘮叨下JDK的版本,每次Java的版本升級(jí),就意味著虛擬機(jī)以及GC的性能都有一定程度的提升,所以JDK1.7比JDK1.6在并發(fā)處理速度上要更快一些,注意對(duì)多線程程度請(qǐng)加上-server參數(shù),并發(fā)效果更好一些。現(xiàn)在JDK1.8都出來這么久了,你的JDK是不是應(yīng)該升級(jí)下了呢?
本文為菠蘿大象原創(chuàng),如要轉(zhuǎn)載請(qǐng)注明出處。http://m.tkk7.com/bolo
posted on 2015-01-20 15:08
菠蘿大象 閱讀(19504)
評(píng)論(6) 編輯 收藏 所屬分類:
Concurrency