在完成ASF集成REST以后,接到的任務就是要完成一個日志分析應用。需求沒有很明確,只是要有這么一個東西能夠滿足分析收集后的日志,將分析后的原始數據入庫,作為后期分析和統計使用。
在動手做之前,我還是給這個應用作了最基本的需求定義:靈活配置(輸入源,輸出目標,分析器的實現等),高效(并行任務分解)。就這兩點能夠做到,那么將來需求如何變化都可以適應。Tiger的Concurrent包是滿足后面那項最好的實現,因此打算好好的實踐一把,也就這部分Tiger的特性還沒有充分使用過,里面的線程池,異步服務調用,并發控制都能夠極好的完成并行任務分解的工作。也就是在這個過程中,看到了IBM開發者論壇上的一片文章,講關于《應用fork-join框架》,談到了在J2SE 7 的Concurrent包中將會增加fork-join風格的并行分解庫,其實這個是更細粒度的任務分解,同時能夠在當前多CPU的情況下提高執行效率,充分利用CPU的一種實現。無關的話不多說了,就寫一下整個設計和實現的過程以及中間的一些細節知識。
背景:
由于服務路由應用訪問量十分大,即時的將訪問記錄入庫對于路由應用本身以及數據庫來說無疑都會產生很大的壓力和影響。因此考慮首先將訪問信息通過log4j記錄在本地(當然自己需要定制一下Log4j的Appender和Filter),然后通過服務器的定時任務腳本來將日志集中到日志分析應用所在的機器上(這里通過配置可以決定日志是根據什么時間間隔來產生新文件)。日志分析應用就比較單純的讀取日志,分析日志,輸出分析結果(包括寫入數據庫或者是將即時統計信息存入到集中式緩存Memcached中)。網絡結構圖如下:
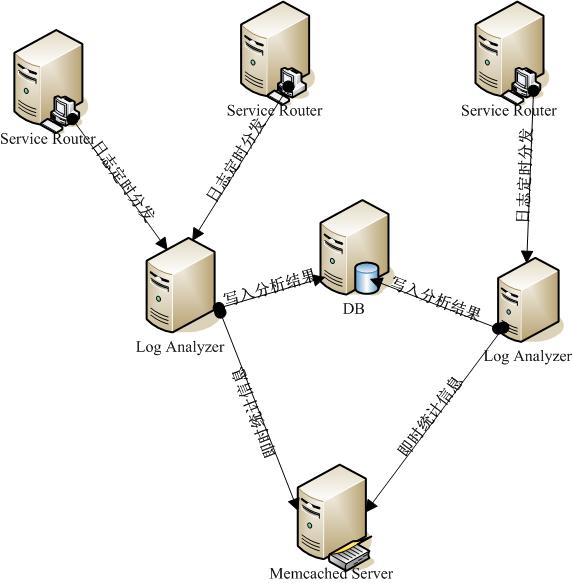
圖1 網絡結構圖
Concurrent概述:
Tiger出來也有些年頭了,但是每一個新的特性是否都在實際的工作中使用過,起碼我自己是沒有作到的,包括對于Concurrent包也只是看過,寫了幾個Test case玩一下,但具體使用到實際開發中還是比較少的。在這個工作之前,如果考慮要使用對象池或者線程池,那么一定會去采用apache的common pool,不過在現在jdk日益“強大”的基礎下,能夠通過jdk自己搞定的,就盡量不再引入第三方包了。看Java 的Doc很容易就理解了Concurrent,這里我只是大致的說一下幾個自己在應用中使用的接口:
BlockingQueue<E>:看看名字就知道了,阻塞式隊列,可以設置大小。適合于生產者和消費者模式,生產者在隊列滿時阻塞,消費者在隊列空時阻塞。在日志分析應用開發中被用于分析任務(生產者)和輸出任務(消費者)之間的分析結果存儲通道。
Callable<V>:任何需要執行的任務都可以定義成Callable,類似于線程的Runnable接口,可以被Service Executor指派給內部的線程異步執行,并且返回對象或者拋出異常。在日志分析應用開發中,非定時性的任務都定義成為此類型。
ConcurrentMap<K,V>:這個以前常常使用,因為效率要遠遠高于Collections.synchronizedCollection和synchronized。后面還會提到實踐中的幾個實用的技巧來防止在高并發的情況下出現問題。在日志分析應用中,此類型的Map作為保存日志文件分析狀態的緩存(日志文件分為兩種狀態:分析中,分析結束。如果不存在于Map中就認為尚未分析,那么將其納入Map然后啟動分析處理線程工作,如果存在于Map中標示為分析中,那么將不會再分析此文件,如果分析結束并且被輸出,將會標示此文件分析結束,異步清理線程將會定時根據策略刪除或移動文件)。
ExecutorService:內置線程池,異步執行指派任務,并可以根據返回的Future來跟蹤執行情況。在日志分析應用開發中,被用于非定時性任務執行。
ScheduledExecutorService:內置線程池,定時異步執行指派任務,并可以根據返回的Future來跟蹤執行情況。在日志分析應用開發中,被用于定時性任務執行。
以上就是被使用到的接口,具體實現策略配置就不在此贅述了。
整體結構設計:
整體設計還是基于開始設定的兩個原則:靈活配置,高效性(任務分解,并行流水線執行)。說到任務分解又會想起讀書時候的離散數學中關鍵路徑等等。任務分解還是要根據具體情況來分析和設計,不然并行不但不會提高效率,反而還降低了處理效率。
就日志分析來看,主要的處理過程可以分成這么幾個任務:
1. 檢查日志來源目錄,鎖定需要分析的文件。(執行需要時間很短,可通過定時間隔執行)。
2. 分析已經被鎖定的日志文件,產生分析結果。(執行需要時間根據日志文件大小來決定,因此需要線程異步執行,結果根據設定拆分成細粒度包,降低輸出線程等待時間)。
3. 檢查分析結果隊列。(執行需要時間很短,當前是配置了SingleThreadExecutor來執行檢查阻塞隊列的工作,同時獲取到分析結果包以后立刻創建線程來執行輸出任務)
4. 輸出分析結果,如果輸出成功,將分析過的日志文件在日志文件狀態緩存中的狀態更新為已分析。(執行時間根據輸出情況來定,當前實現的是批量輸出到數據庫中,根據配置來批量提交入庫,后續還會考慮實時統計到集中式Cache作為監控使用)。
5. 清理分析日志文件。(執行時間較短,設定了定時線程池執行清理任務,根據策略配置來執行清理和移動文件任務,并且清除在日志文件狀態緩存中的信息)
根據上面的分解可以看到,其實在單線程工作的過程中,容易造成阻塞而影響性能的主要是讀取,分析和寫出這三個過程的協調,一個一個讀取分析和寫出,性能一定低于讀取和分析并行工作,而分析完畢才寫出,性能一定低于分析部分,寫出部分。
同時由于細分各個任務,因此任務與任務之間的耦合度降低,可以運行期獲取具體的任務實現配置,達到靈活配置的目的。
下面就具體的看看整個流程,以及其中的一些細節的說明,這里根據下圖中的序號來逐一描述:
1. 配置了Schedule Executor來檢查日志所屬目錄中的日志文件,Executor的線程池大小以及檢查時間間隔都根據配置來設定。
Tip:定時任務可以設置delay時間,那么可以根據你的任務數量以及時間間隔來設定每一個任務的delay時間,均勻的將這些任務分布,提高效率。
2. 當Read Schedule被執行時,將會去檢查Analysis Log File State Concurrent Cache(也就是上面提到的ConcurrentMap)中是否存在此文件,如果不存在證明尚未分析,需要將其置入Cache,如果已經存在就去查詢其他文件。Tip:這里用了一點小技巧,通常我們對于此類操作應該做兩部分工作,get然后再put,但是這樣可能就會在高并發的情況下出現問題,因為這兩個操作不是一個原子操作。ConcurrentMap提供了putIfAbsent操作,這個操作意思就是說如果需要put的key沒有存在于Map中,那么將會把key,value存入,并且返回null,如果已經存在了key那么就返回key在map已經對應的值。通過if (resources.putIfAbsent(filename, Constants.FILE_STATUS_ANALYSISING) == null)就可以把兩個操作合并成為一個操作。
3. 日志讀取的工作線程完成鎖定文件以后,就將后續的工作交給Log Analysis Service Executor來創建分析任務異步執行分析操作,日志讀取工作線程任務就此完成。
4. Log Analysis Schedule是運行期裝載具體的接口實現類(采用的就是類似于JAXP等框架使用的META-INF/services來讀取工廠類,載入接口實現)。Analysis Schedule執行的主要任務就是分析文件,并且根據配置將分析結果拆分并串行的置入到Block Queue中,提供給輸出線程使用。
5. Receiver主要工作就是守候著Block Queue,當有數據結果產生就創建Write Schedule來異步執行輸出。
6. Log Writer Service Executor根據配置來決定內置線程池大小,同時在Receiver獲取到數據包時產生Write Schedule來異步執行輸出工作。
7. Write Schedule和Analysis Schedule一樣可以運行期裝載接口實現類,這樣提供了靈活的輸出策略配置。
Tips:在數據庫輸出的時候需要配置批量提交記錄最大數,分批提交提高性能,也防止過大結果集批量提交問題。
8. 寫出完成以后需要更新鎖定文件的狀態,標示成為已經分析成功。這里還遺留一點問題,在一個日志文件分包的過程中每一個包都回記錄隸屬于哪一個分析文件,文件的最后一個數據包將會被標示。在輸出成功以后會去檢查哪些包是文件最后數據包,更新此文件為已分析成功,如果出現異常,那么將會把這些文件狀態清除,接受下一次的重新分析。這里一個文件部分包提交暫時沒有做到事務一致,如果出現部分成功可能會重復分析和記錄。
9. 最后就是Clean Schedule被定時執行,根據策略來刪除或者移動已經被分析過的文件。
Tips:
ScheduledExecutorService內部可以配置線程池,當執行定時任務比較耗時,線程池中的線程都被占用的情況下,定時任務將不會準確的按時執行,因此設計過程中需要注意的是,定時任務一般是簡短的工作任務,如果比較耗時,那么應該結合ScheduledExecutorService和ExecutorService,定時任務完成必要工作以后將耗時工作轉交給ExecutorService創建的即時執行異步線程去處理,保證Schedule Executor正常工作。

圖2 流程結構設計
類圖:
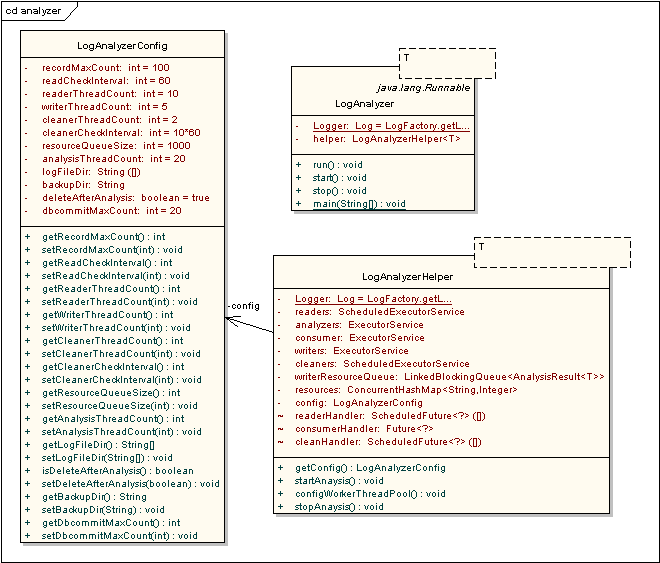
圖3 類圖1
上面的類圖中主要描述的就是日志分析應用的三個主類:類似于控制臺的LogAnalyzer,具體內部資源管理類,配置類。(T表示采用泛型)

圖 4 類圖2
類圖2主要就是描述了在整個應用中所有的被分解可并行的任務定義。ClearSchedule是用來在控制臺輸入stop停止日志分析的時候,做后續資源回收工作的任務。CleanSchedule是用來清除被分析后的日志文件任務。ConsumerSchedule是阻塞隊列消費者任務。
其他還有一些輔助工具類以及工廠類和定義類就不畫了。
后話:
做這個設計和開發的過程中又好好的實踐了一些編程細節方面的內容,作為架構設計來說,需要多一些全局觀和業務觀,作為一個良好的開發者來說需要多實踐,多了解一些細節,在不斷學習和掌握各種大方向技術框架的同時,適當的了解一些細節也是一種很好的補充,同時也可以衍生思考。
REST風格的服務結合云計算的思想,會被使用的更為廣泛,而云計算其實就是一個問題分解和組合處理的過程,可以說是一種宏觀的問題解決策略。高效解決問題,提供服務,通過組合體現業務最大價值,就是互聯服務的最重要目的。
更多文章請訪問:http://blog.csdn.net/cenwenchu79/