這里分享的是一個分布式分析系統的Master內存消耗狀況的優化,有些比較特定的優化未必適用于其他系統,但是從這一系列優化過程中,應該能帶給其他系統在做設計時提前考慮一點優化點。
下面先描述一下背景,看了背景可以對后續的優化點可以比較清楚一些,注意,部分設計僅適用于大量計算中,會犧牲可維護性來換取性能提升。最后一點優化應該是比較有通用性意義的。
背景:
開放平臺每天產生大量的調用日志,希望能夠從海量日志中即時的去分析業務指標和系統運行狀況。當前實現的是類似MapReduce的設計,不過Master與Slave之間是松耦合的關系,比傳統的MapReduce更利于擴展和即時分析(當然和Hadoop的目標是不一致的,規模量及作用也不同,主要用于統計規則易變,需要即時分析,數據量在T以內),同時內嵌了統計規則引擎,使得統計邏輯只需要通過配置即可實現分析定義。具體的部署圖和流程圖如下:
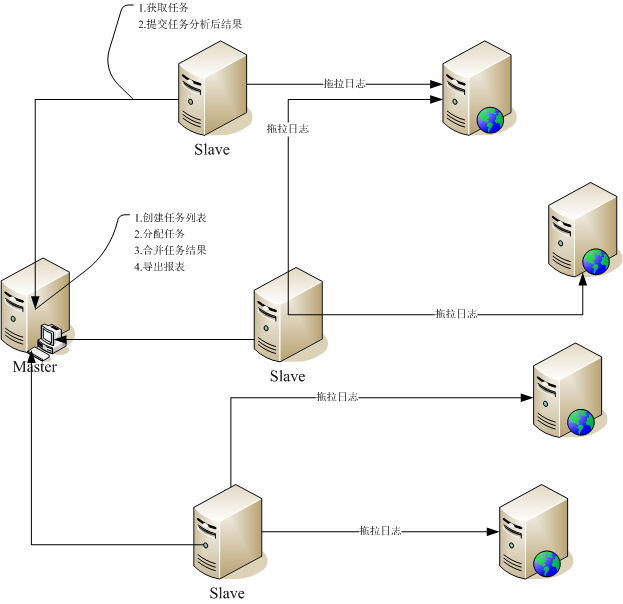
流程如下:
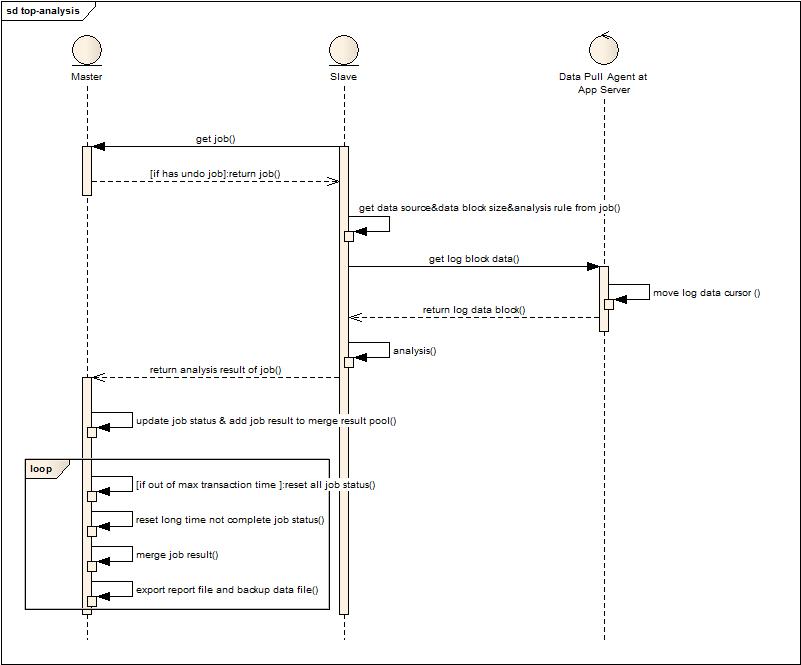
Master與Slave之間沒有注冊和管理的關系,Slave連接到Master請求任務,從任務中獲取數據來源,分析規則配置,獲取數據塊大小的信息,然后將數據塊拉下來分析,最后返回結果給Master。至此,Master與Slave的交互完成。
Master自身主要負責:
1. 任務列表創建和重置(根據配置信息創建任務列表,由于是增量對應用服務器分析,則定期將任務全部重置,可以讓Slave增量的對應用服務器去拖取數據分析)。
2. 重置一些分配出去但是較久都沒有執行的任務,防止Slave任務執行失敗沒有反饋而出現死等的現象。
3. 合并Slave傳遞過來已完成的任務結果集到主干結果集上。
4. 將主干結果集定時輸出提供給第三方使用(告警,圖形化等),導出中間結果,提供給Master異常重啟后回復現場使用。
問題:
由于報表配置增多,單報表的結果數據量大,Master合并多個結果集內存吃緊,不斷的GC,最后導致惡性循環。因此優化原先認為任務不重的Master迫在眉睫。
優化過程:
1. 合并過程中,主干結果和Slave結果都比較大,在操作后是否可以通過主動clear和set null來更快的清理釋放資源。(基本沒有效果,GC已經做了很多優化)
2. 分析器是基于定義去分析出<key,value>結果集合,然后根據配置將key相同的結果串聯成為key,value1,value2,value3(這就是傳統的報表結果)。發現有一些配置的<key,value>規則在實際輸出報表的時候沒有被使用,因此在構建分析規則的時候直接過濾這部分配置。(也就是在實現很多系統的時候,有些結果是中間結果,中間結果是否需要如果在系統啟動時就能判斷,就將這些中間結果計算的邏輯過濾掉,節省計算資源和內存資源,同時可以有一些提示,可能是系統配置中的錯誤導致這部分數據沒有被用)
3. 系統中很多地方都用到Calendar來處理一些日期相關的內容,比如說想獲取年月日時分秒的數據來做Action,比如通過格式化內容然后作為輸出歸類。由于Calendar是線程不安全的,因此不得不大規模的去構造和使用,其實內存消耗較大。
改造方式:能夠用long的時候全部用long來處理,System.currentTimeMillis有消耗,但很小。如果要計算年月日時分秒可以用除法取余來做(注意計算天的時候要考慮中國時差8個小時)。同時如果是中間結果然后后續也要輸出,由于輸出需要便于用戶查看,所以希望格式化,建議系統內部還是保持數字型,直到輸出時做一次格式化處理。(不過這點取決于場景中是中間結果被輸出和內部使用的頻率,如果內部使用較少,有大量多次復用輸出,則可以內部處理好,避免多次格式化)
4. 觀察了一段時間,發現Slave處理結果在高峰期每次返回還有5-6M甚至更高,這樣對于Master在并發處理多個Slave時開銷很大(接收緩存區隨著Slave的增多和內容返回的增多而不斷地增大),因此出于優化網絡和接收發送緩存,都要求將Map后的數據作壓縮。
改造方式:考慮使用QuickLZ這個簡單的開源類來做壓縮,但是由于用到了對象的Outputstream,則直接使用了Output的管道化方式,后來比較了一下,壓縮效果兩者不相上下,速度到沒有再去比較,因為Output管道化效果較好,代碼如下:
ByteArrayOutputStream bout = new ByteArrayOutputStream();
Deflater def = new Deflater(Deflater.BEST_COMPRESSION,false);
DeflaterOutputStream deflaterOutputStream = new DeflaterOutputStream(bout,def);
ObjectOutputStream objOutputStream = new ObjectOutputStream(deflaterOutputStream);
最后的ByteArrayOutputStream將會成為ByteBuffer的數據源。(壓縮后,網絡傳輸和接收緩沖消耗將降低,但當時沒有是考慮一來數據原來不大,二來壓縮消耗CPU,但現在的場景發生變化,因此不得不消耗CPU來節省內存。所以大家根據不同場景來優化,得失自己權衡)
5. 下面是一段NIO接收業務數據后的代碼,平時看來很干凈正規,但是在高并發大量數據的情況下就是一段惡魔代碼。
byte[] content = new byte[receivePacket.getByteBuffer().remaining()];
receivePacket.getByteBuffer().get(content);
log.error("package content size :" + content.length);
ByteArrayInputStream bin = new ByteArrayInputStream(content);
修改后:
ByteArrayInputStream bin = new ByteArrayInputStream(
receivePacket.getByteBuffer().array(),receivePacket.getByteBuffer().position()
,receivePacket.getByteBuffer().remaining());
讓輸入流直接基于ByteBuffer來處理數據,而不是重新申請內存來拷貝出數據。其實在NIO的Buffer和Channel出來以后,由于和Steam的操作沒有橋接的方式,因此很多時候都傾向于自己申請內存去讀取然后再作為Stream的輸入輸出。(Buffer內部的很多方法是支持做鏡像,子集等操作來最大限度復用內部數據流,因此需要仔細的去權衡是否可以復用,但是要注意的是復用的模式需要考慮仔細,否則讀取和寫入數據的游標就會相互影響)
6. Merge(Reduce)的壓力分散。當前如果有50個Job,那么50個job的所有結果都需要Master來合并,其壓力和內存消耗肯定很大,如果可以將多個job的結果在Slave上合并,那么就可以緩解Master的壓力。因此給每個Slave配置了一個系統級參數,每次請求Master分配的最大Job個數。修改了Master與Slave直接的獲取任務協議,可以申請要求多個job,Master根據任務完成情況返回小于等于請求個數的任務。Slave這邊并行執行然后合并結果的機制其實一早就有,只是從當年分析大文件轉向基于Http數據流增量分析后,沒有充分利用Slave的并行處理能力。(這種設計很多,其實在SD會議上我說了幾個簡單的場景,TOP需要將業務返回的對象在格式化為標準的xml或者json方式,一種是TOP自身包攬處理,一種是將部分業務邏輯外移,將計算和內存消耗分擔到更多的應用節點上,帶來的問題是,升級外移的邏輯成本較高。集中處理的好處在于邏輯維護方便,一次處理多次使用。分擔處理的好處在于充分利用更多資源來解決規模化問題)
7. 通過jstat的gcutil觀察,發現Heap增長除了merge以外在報表輸出時也有不小的波動,發現為了保證系統異常退出時能夠在再次啟動繼續增量統計,每次重置任務列表并輸出報表時就會導出內存數據對象,便于下次載入。現在每隔3分鐘是任務重置期,也就是每隔3分鐘都會導出中間結果一次,這個頻率過高,因此將導出動作設置擴大,畢竟異常退出不是經常發生,同時支持命令主動導出。另一方面也采用壓縮的方式對輸出內容作處理,減少內存消耗和導出時間。(很多時候,我們會設計一些異常保護的策略和檢查,但是不要讓這樣的工作成為系統的負擔,通過放大尺度和接受主動即時處理,可以得到一樣的效果)
8. 這點優化看起來很傻,但是效果卻是明顯的,其實說明了一樣問題,就是一點細節可以讓你的程序有很大的改觀。
當前Map后的結果集格式為:Map<EntryId,Map<key,value>>,Entry就代表了一個<key,value>計算的定義。那多個結果集合并的處理方式為(下面是偽代碼)
Map<EntryId,Map<key,value>>[] needMergeResult;//這是外部傳入的需要合并的結果數組
Map<EntryId,Map<key,value>> result = new Map<EntryId,Map<key,value>>;//構建一個合并后的結果集
for ( j = 0 ; j < needMergeResult.size; j++) //遍歷所有的結果集
{
Map<EntryId,Map<key,value>> node = needMergeResult[j];
Loop:遍歷node所有的EntryId
{
Loop:遍歷EntryId對應的Map
{
根據規則將key對應的value與needMergeResult[j+1].get(EntryId).get(key)到needMergeResult[needMergeResult.size-1].get(EntryId).get(key)的value做合并計算,然后移除needMergeResult[j+1].get(EntryId).get(key)到needMergeResult[needMergeResult.size-1].get(EntryId).get(key)對應的數據,避免后續外部循環重復計算
}
}
}
寫了一大堆,其實沒有優化算法(大家覺得合并算法如果有更好的可以告知我),做的優化就是紅色那句被去掉了,也就是原來是構建一個新的結果集作為基礎結果集,現在的做法是合并前先選擇Base最大的結果集作為基礎結果集,然后后續處理同樣,這樣其實省略了內存申請,合理的利用了已有的內存空間,同時這步也為最后的并行合并結果作了優化。
9. 除了線上運行期GC的觀察以外,本地數據量小,但是也跑了master和slave用jprofiler觀察了一下,發現程序中有大量的對ConcurrentMap size的檢查,來做保護,來做一些行為判斷,對于一個長期高并發處理的系統來說,也是有不少損耗的(ConcurrentMap內部為了提高效率是分片存儲的,因此size不是一個簡單的計數器),因此采用Atomic類型的原子計數器來替代,代價是程序復雜度增加。(這點優化其實也是依據場景而定,如果程序在這方面操作不頻繁,簡單的使用size方法更靠譜。需要說明的就是Java很多并發組件的內部實現并不是簡單的處理,因此如果調用次數很多很頻繁,可以考慮其他方式去實現)
10. Master的主線程阻塞式合并結果集的改變。從最上面的設計圖中可以看出,起始的設計我就考慮用單線程阻塞模式來處理結果集的合并,原因很簡單,所有的結果最終都是要合并到“主干”,因此無論如何合并的動作都會加鎖,也就是串行化,與其這樣,還不如簡單的用單線程阻塞式處理。
現象:Slave處理并合并后的多個結果會不定期的到來,由于Slave分析后的數據量呈幾個數量級的增長,原先的Master阻塞式合并時間也變長,此時掛在合并列表上的結果集也會增多(中間結果的生命周期增加,直接導致內存消耗增加),需要做的就是盡可能的減少由于處理滿導致內存堆積消耗,提高Master內存利用率。
下面是考慮優化的過程:
1. 主線程只負責需要合并結果的分發,執行合并的為外部線程池。(帶來的問題:多個線程如何并發的去合并到主干?采用鎖的方式那么依然只有一個線程可以執行合并,依然是串行化操作)
2. 設計采用兩類合并的設計。設計如下圖:
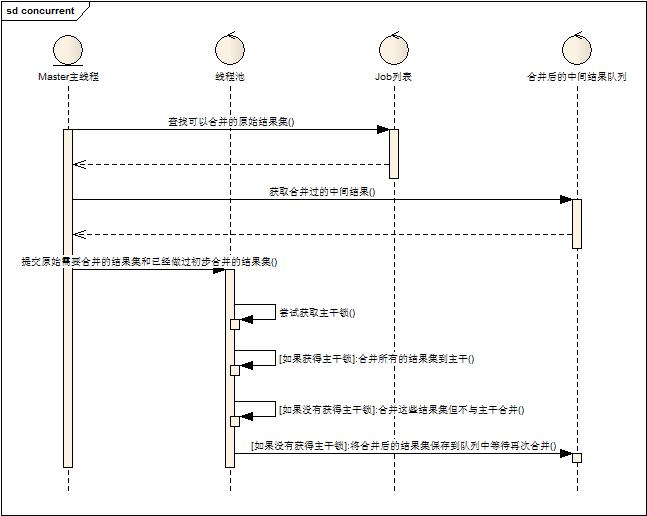
1. Master主線程負責獲取需要合并的結果集(包括原始Slave提交的結果集和后面會提到的被合并過的結果集)
2. Master主線程分發合并任務給線程池。
3. 線程池的執行線程執行前嘗試獲取主干鎖。
4. 如果獲得主干鎖,則將所有結果集合并到主干結果集上。
5. 如果沒有獲得主干鎖,則將結果集內部合并,并且將合并后的結果集放到隊列中,等待再次合并。
首先,依托于上面談起過的合并方式是基于某一個被合并的結果集來做,因此多組合并在資源消耗上可以接受(只是在計算的時候有所消耗),大量原始結果的并存可以被少量中間結果并存替代。其次,任何一次合并都不在等待與主干合并,可以實現并行化,與主干合并的動作沒有做太多特殊處理,工作線程邏輯統一,無差別對待,提升線程池利用率。
帶來的問題:由于Slave原始結果很難預期到來時間,Master的頻繁小規模合并反而會帶來負面效果,同時也出現了中間結果被反復的多次合并,浪費計算資源。
3. 根據2提出的問題,做了一些改進。首先給Master增加了兩個系統參數,任務批量執行的最小數目和任務堆積等待最大時間,當在任務堆積最大等待時間之內,必須達到批量執行最小數目才可以提交線程池執行。(當發現當前的合并結果集+已經合并的結果集=所有結果總數,此條件無效)。其次,中間結果不參與到非主干合并的計算中,除非中間結果是最后需要合并的結果。修改后的流程圖如下:
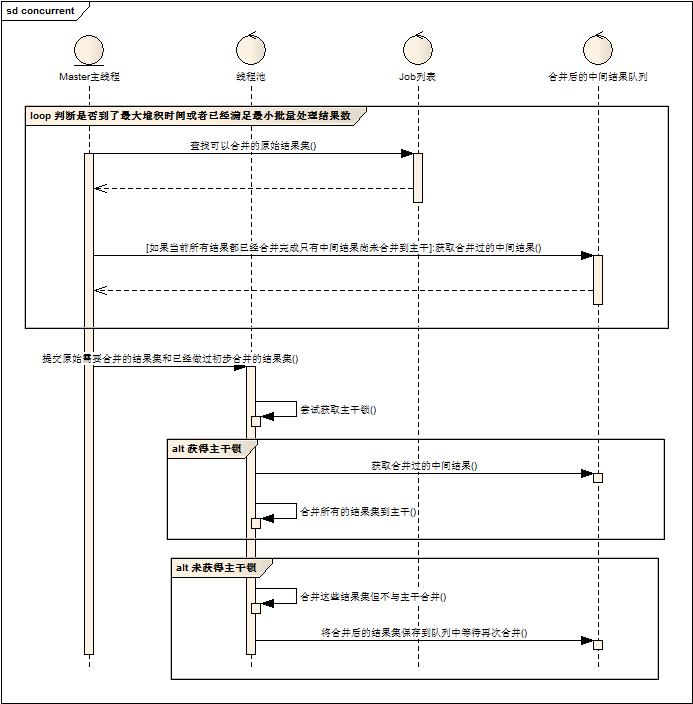
線上做了初步配置測試后,效果明顯,內存利用率提高,釋放速度加快,整體執行時間縮短。
其實這個優化點總結一下背后的實質性特點:當所有操作最后還是需要鎖在一個瓶頸點上來做串行化操作時,最簡單的方式就是串行化處理。(簡單即高效)但是,某些場景下可以做部分優化:
1. 節省資源。如果在串行化操作前,并行處理能夠減少資源消耗,那么在整體事務處理時間不變的情況下,資源可以得到充分利用(反向資源充足時也許可以提速系統處理能力,間接幫助提高事務處理時間)。
2. 節省預處理計算時間。簡單來說就是磨刀不誤砍材功。在前一陣寫著關于任務切割,然后事件驅動的模式里面說到,任務切割后,最大的好處就是可以加速不同階段消耗的資源釋放,即并行化可以并行的操作。如果有10本電話簿,1個電話廳,那么打電話的人可以在電話亭外面先查好電話,然后進入電話亭直接打電話,因為查電話簿是可以小規模并行的,可以提升串行化處理的效率。
補充最后一點,在并行計算中很重要,在分析器的Slave設計中,在多線程處理任務中,盡量讓工作者的邏輯無差別話,任務都自包含描述,工作者邏輯是通用邏輯引擎,這樣對于與線程池或者不同機器進程來說,任務調度將是很簡單也是容易擴展的。
優化其實看似都是很簡單的內容,但是如何去觀察問題,分析問題,解決問題,總結問題都是有很多技巧的,也只有會做好這幾步,才可能去做優化,否則就是空談。