Author:放翁(文初)
Email:fangweng@taobao.com
Mblog:
weibo.com/fangweng
Blog: http://blog.csdn.net/cenwenchu79/
Beatles: https://github.com/cenwenchu/beatles
讀前先看:
這篇文章主要講述的是beatles流式數(shù)據(jù)分析框架中對于master的橫向擴(kuò)展真實(shí)的設(shè)計演進(jìn),是beatles框架介紹的第三篇,看第三部分的時候如果看過前兩篇文章,這篇文章的遞進(jìn)應(yīng)該比較容易理解(如果看過前面的代碼,那么會更深入的理解其中的細(xì)節(jié),文字圖片描述一分鐘,代碼寫寫1個周)。如果沒有看過前兩篇,那前提你要理解hadoop等常用的分布式分析系統(tǒng)再看,否則最后可能交流起來就有些空對空了,因為真的寫了和用了就會有體會細(xì)節(jié)的差別。
廢話不多說,看完后如果不看代碼其實(shí)也很難體會細(xì)節(jié),因此建議看完后看看代碼,跑一下測試用例子(MasterSlaveIntegrationTest_SocketVersion是socket集成測試版本)。
下面文章中的mr表示MapReduce的意思。
Master的橫向擴(kuò)展:
盡管Beatles這種松散模式下Slave可以隨時隨地的加入集群,但由于最終數(shù)據(jù)還要匯總到Master,Master本身承擔(dān)著類似于Hadoop中Reduce的角色,所以Master在版本迭代的過程中不斷的對本身做著各種優(yōu)化:并行模式下多線程的數(shù)據(jù)合并,主干數(shù)據(jù)分析周期的磁盤換入換出,支持Slave多任務(wù)合并后返回,數(shù)據(jù)導(dǎo)出廣度遍歷column存儲結(jié)構(gòu)等等(詳細(xì)的參看第二篇文章)。當(dāng)數(shù)據(jù)base真的非常大的時候(例如:對于用戶緯度的統(tǒng)計,統(tǒng)計后結(jié)果還是非常多,無法hold在內(nèi)存),開放平臺分析系統(tǒng)給數(shù)據(jù)需求方提供的解決方案是片段性輸出,交由外部再次合并這些片段。(這是基于當(dāng)時間片段足夠小的時候,數(shù)據(jù)片內(nèi)容可以被承受)但結(jié)果是讓外部數(shù)據(jù)使用者利用數(shù)據(jù)庫去對這些結(jié)果做二次歸并。這不僅給數(shù)據(jù)結(jié)果使用者帶來了問題,也使得Master隨時會被最后一根稻草壓倒(如果時間片數(shù)據(jù)依然無法被hold)。
下面看看老的結(jié)構(gòu)圖:
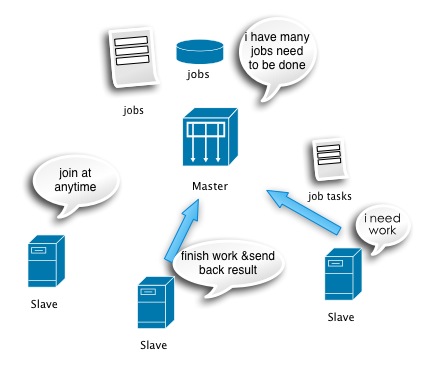
圖1
Master橫向擴(kuò)展前結(jié)構(gòu)圖
1.
master從不同的jobs來源構(gòu)建需要處理的分析任務(wù),并拆分為多個task是。
2.
slave請求任務(wù)(一個或者多個)去做分析處理。
3.
slave獲得任務(wù)后從任務(wù)描述中獲得數(shù)據(jù)來源,分析規(guī)則,輸出,開始從數(shù)據(jù)來源增量獲取數(shù)據(jù)進(jìn)行分析。
4.
slave根據(jù)任務(wù)定義判斷多個任務(wù)結(jié)果是否可以合并,并將合并后的結(jié)果發(fā)回給master。至此slave的一輪業(yè)務(wù)生命周期結(jié)束,再從步驟3開始重復(fù)。
5.
master收到各個slave的數(shù)據(jù),開始多線程并行合并job結(jié)果,最終判斷某一個job的task是否都已經(jīng)完成,如果完成開始導(dǎo)出數(shù)據(jù)和臨時文件,重置job開始下一輪的job執(zhí)行。
思考:
是否增加一個角色:reducer來替代掉master的工作?
其實(shí)slave一次能夠獲取多個jobtask,然后自我合并,就是一種比較弱的reduce的做法。
否定了新增一個reducer的原因:新增角色增加了管理的復(fù)雜度和集群擴(kuò)展性。(Hadoop就直接用slave作為reduce)
如果用slave來完全承擔(dān)所有的reduce工作?
1.
破壞了原來master不管理slave集群的基本原則,slave動態(tài)擴(kuò)展非常麻煩,同時需要增加心跳管理和各種調(diào)度算法,任務(wù)管理來完成結(jié)果的合并。(最后就是一個hadoop的設(shè)計)
2.
不考慮用文件作為數(shù)據(jù)交互的方式(因為流式分析的特點(diǎn):片段性數(shù)據(jù)量不大,及時性要求高,所以最好直接是內(nèi)存),因此hadoop最亮眼的hdfs沒有用到,hadoop設(shè)計將會大打折扣。
如果用master繼續(xù)做reduce,是否可以考慮橫向擴(kuò)展master?
Master的職責(zé):
1.
從任務(wù)源(可能是本地配置文件或者db或者是http服務(wù))獲得jobs定義構(gòu)建任務(wù)池。
2.
被動分配多個job的tasks。
3.
管理job狀態(tài)以及jobtask的狀態(tài)。
4.
根據(jù)jobtask狀態(tài)合并slave返回結(jié)果到job各個主干上。
5.
根據(jù)job狀態(tài)導(dǎo)出job每一輪的中間結(jié)果和統(tǒng)計結(jié)果。
6.
根據(jù)job狀態(tài)判斷是否重置job。
會發(fā)現(xiàn)其實(shí)master歸根到底就是對job的管理以及對job中數(shù)據(jù)結(jié)果的合并和導(dǎo)出,而最為消耗的就是類似與reducer的4,5兩個步驟。
先介紹一下job和jobtask的概念,利于對后面的拆分有更好的理解:
job包含了一組jobtask,job本身定義了一組mr規(guī)則(類似有很多mr處理實(shí)現(xiàn)),定義了要處理的數(shù)據(jù)來源(其他信息參看代碼)。
Jobtask是將job的多個數(shù)據(jù)來源拆分后得到的一個子任務(wù),也就是每一個數(shù)據(jù)來源和同一組mr成為了一個任務(wù),在slave獲得一個或者多個task的時候,可以自己通過數(shù)據(jù)來源去獲取數(shù)據(jù),然后根據(jù)一組規(guī)則直接對流式數(shù)據(jù)做大量的mr(這也是和最早hadoop自己寫mr的差別,其實(shí)數(shù)據(jù)的多次移動和讀入才是計算集群的最大成本),但最終所有的jobtask都要合并到job的結(jié)果主干上,最后導(dǎo)出臨時結(jié)果和報表數(shù)據(jù)。
a.
如果等價部署多個master,所有slave連接一組master,來做master橫向擴(kuò)展會如何?
a)
任務(wù)管理就需要多節(jié)點(diǎn)之間做并發(fā)控制,當(dāng)前可以看看master內(nèi)的代碼是一個進(jìn)程內(nèi)做并發(fā)控制。這種方式過于復(fù)雜,帶來的消耗遠(yuǎn)大于收益
b.
如果等價部署多個master,所有slave連接一組master,但是將job或者jobtask按照業(yè)務(wù)(上面說過job就是定義了多個mr的實(shí)現(xiàn),要拆分也只能將mr分組放到不同的master上來減輕mr產(chǎn)生的<k,v>對存儲帶來的壓力)分?jǐn)偟蕉鄠€master上,即不用對任務(wù)管理做并發(fā)控制,又可以分擔(dān)reduce的工作。
a)
slave主動請求任務(wù),如何判斷應(yīng)該優(yōu)先向誰請求任務(wù)?任務(wù)負(fù)載均衡如何做?最后可能還是單獨(dú)部署多套集群來的靠譜。
b)
將不同的mr放在多個master可行,但結(jié)果就和hadoop獨(dú)立的寫mr帶來的結(jié)果一樣,對同一份數(shù)據(jù)來源處理,卻因為mr的分組數(shù)據(jù)被反復(fù)讀入和移動。
c.
和Zookeeper類似,master建立group,但是只有一臺負(fù)責(zé)1,2,3,6的工作,而4,5則可以擴(kuò)展到多個master上。需要對原來系統(tǒng)的改造為:
a)
多個master job池構(gòu)建來源保持一致,構(gòu)建完畢增加mr與master的對應(yīng)關(guān)系(根據(jù)算法實(shí)現(xiàn)平均分配,后面介紹關(guān)于分配的算法,注意只有主的那臺master接受任務(wù)分發(fā)請求,負(fù)責(zé)將mr與master建立對應(yīng)關(guān)系在task中傳遞給slave)
b)
slave從一臺master上獲取任務(wù),分析后將結(jié)果按照mr分組(執(zhí)行的Task中帶有,所有設(shè)計都是這樣,slave不保留任何帶有業(yè)務(wù)性或者集群管理性的配置,保證slave隨時離場,隨時加入),將分組后的mr結(jié)果并行的發(fā)送到多個master上。
c)
master在合并和輸出結(jié)果的時候判斷自己所負(fù)責(zé)的mr部分,按需合并和存儲(雖然在slave中已經(jīng)有做業(yè)務(wù)數(shù)據(jù)分組)。
會發(fā)現(xiàn)多個master好像多臺流水線一樣,保持著相同的動作和周期性,從同一個slave獲取到了不同原始材料以后,開始制作零件,然后以匹配的速度來將不同零件丟到一個筐子里交給后續(xù)處理者。
當(dāng)然你會考慮到還有容錯,master集群動態(tài)擴(kuò)展,速度不匹配等問題,后續(xù)細(xì)節(jié)慢慢介紹。
基于上面所描述的情況,結(jié)構(gòu)演變成如下:
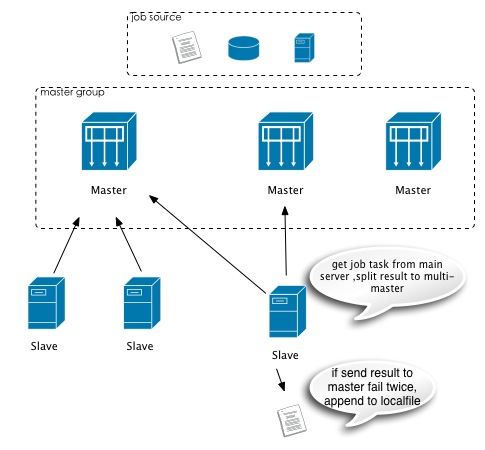
圖2 橫向擴(kuò)展后的結(jié)構(gòu)圖
可以看到Slave現(xiàn)在獲取任務(wù)還是集中在一臺,但是返回任務(wù)結(jié)果會支持分散到多臺master,解決master瓶頸最大的問題。同時master組的jobs來源保持一致,作為橫向擴(kuò)展的基礎(chǔ)(主master分組mr簡化master的協(xié)同,其他master沒有獲得數(shù)據(jù)就沒有結(jié)果輸出)
細(xì)節(jié):
1.
master group之間不需要通信。(主要是業(yè)務(wù)分拆信息,可以通過冪等算法,也可以通過單機(jī)分配,分析結(jié)果過濾投遞的方式),當(dāng)前主要是用分析結(jié)果過濾投遞來保證。
2.
平均分配算法。
首先master有權(quán)重(有實(shí)體機(jī)器,也有虛擬機(jī),處理能力不同),其次mr的權(quán)重也不同(有對app做簡單統(tǒng)計的,有對用戶做統(tǒng)計的,數(shù)據(jù)量相差非常大)。當(dāng)前考慮一個mr一臺虛擬機(jī)抗不論多少數(shù)據(jù)都能抗的住,如果扛不住后續(xù)可以再根據(jù)mr產(chǎn)生的結(jié)果分(這會增加分流數(shù)據(jù)的消耗),其實(shí)可以看作現(xiàn)在是分庫,以后就是分表。分配算法其實(shí)就是在兩邊都有權(quán)重的情況下做任務(wù)分配,且任務(wù)不可切割。
采用了兩個排序隊列,然后按照簡單的饑餓+權(quán)重方式來分配,處理者根據(jù)當(dāng)前獲得的饑餓感排序,越饑餓的放在越前面(饑餓感=已分配任務(wù)/自身權(quán)重),當(dāng)已分配任務(wù)為0的時候饑餓感=1/自身權(quán)重(保證能力最強(qiáng)的優(yōu)先獲得最大的任務(wù))。任務(wù)按照權(quán)重排序,高權(quán)重的排在最前面。分配過程如下:
1.
獲的當(dāng)前任務(wù)隊列最前面的任務(wù)(權(quán)重最高的任務(wù))
2.
將任務(wù)分配給處理者隊列中饑餓感最強(qiáng)的節(jié)點(diǎn)。
3.
節(jié)點(diǎn)吃了任務(wù)以后會再次按照處理者隊列排序。
4.
循環(huán)到1再次分配任務(wù),直到任務(wù)分配結(jié)束。
能看到的就是其實(shí)就是有一個評判餓的標(biāo)準(zhǔn),按照資源權(quán)重高低來分配,最后平均分配資源。(也許各位會有更好的建議和算法)
這個算法在保證兩個隊列構(gòu)建時始終一致性的情況下,能夠變成等冪分配算法,其實(shí)也就是當(dāng)兩個隊列中如果遇到評判標(biāo)準(zhǔn)相等的時候排序是否會有前后變化,如果沒有,那么任何一個master都會產(chǎn)出相同的分配結(jié)果。(具體可以參看代碼,在ReportUtil中)
3.
Master的容災(zāi)。由于master其實(shí)不是等價集群的模式,因此master的不可靠會導(dǎo)致數(shù)據(jù)丟失。
a)
Slave如果發(fā)送錯誤,則會嘗試再發(fā)送一次,如果兩次錯誤,則將master和對應(yīng)的job作為文件名保存這次隸屬于這個job的tasks結(jié)果到文件中(append 進(jìn)文件)。
b)
Master如果恢復(fù)的話,可以通過腳本將這些文件復(fù)制到master的目錄下,master后臺線程載入數(shù)據(jù)合并到主干。
c)
過程中如果master恢復(fù),后續(xù)的消息將會投遞到master,因此不會再寫這個文件,因此文件不會需要有一個增量拷貝的過程,同時master也可以在后臺線程慢慢恢復(fù)合并,最后使得數(shù)據(jù)保持一致性。
d)
當(dāng)前還是處于半自動模式,后續(xù)可以考慮讓slave后臺線程將數(shù)據(jù)發(fā)送到恢復(fù)了的master上。
e)
中間可能損失部分時間片數(shù)據(jù)。
4.
mr的動態(tài)增加或者減少(隨時隨地可以針對流式數(shù)據(jù)產(chǎn)出新的統(tǒng)計分析結(jié)果)。原來的集群就支持mr的動態(tài)增加,因為都是配置文件修改,重新載入翻譯一下即可(統(tǒng)計模型被抽象后mr就可以窮舉了,具體參看前面的文檔)。當(dāng)前因為master是多個,同時開始的時候就做好了mr與master的對應(yīng)關(guān)系,因此增加或者減少如果從新做mr與master的分配會產(chǎn)生數(shù)據(jù)遷移的需求,因此對于mr的增加只是將變化部分再對master group做一次分配(假設(shè)原來那些mr分配是均勻的,現(xiàn)在歸零master再分配,大志結(jié)果也是均勻的),對于mr的減少,只是消除掉task中的定義,mr與master對應(yīng)關(guān)系不消除,避免后面要恢復(fù)帶來的數(shù)據(jù)遷移。
5.
master的動態(tài)增加和減少。這個不可避免的要做數(shù)據(jù)遷移,當(dāng)前做法是每天是所有job重置的周期,增加和減少master將在那個時候?qū)φ麄€集群做停機(jī),然后啟動集群做重新編譯,從今天起點(diǎn)開始分析,追趕數(shù)據(jù)。以后可以考慮如何做到不停機(jī)擴(kuò)容master。(主要就是數(shù)據(jù)遷移)
6.
后續(xù)考慮做master與mr的冗余分配,既可以保證數(shù)據(jù)可靠性(多份數(shù)據(jù)分析存儲),又可以方便擴(kuò)容(數(shù)據(jù)遷移成本可以間接降低)
一些感受
最后master的簡單橫向擴(kuò)展模式,使得數(shù)據(jù)分片,一定程度上得到了數(shù)據(jù)安全性的保證,同時對于非常消耗cpu和memory的reduce被簡單的拆分開來,為業(yè)務(wù)發(fā)展提供了突破,最重要的是系統(tǒng)依然保持最初的設(shè)計原則和目的。
任何系統(tǒng)都有自己的適用場景,不要因為要做一個大而全的系統(tǒng),而喪失了自己設(shè)計的原則,我們很難做一個hadoop,但是我們要的也并不是一個通用的hadoop,找到業(yè)務(wù)場景的特點(diǎn),才能夠用最簡單高效的設(shè)計方式來完成業(yè)務(wù)不斷增長帶來的技術(shù)挑戰(zhàn)。
另,在設(shè)計過程中時不時有同學(xué)問我要不要引入zookeeper,過程中曾考慮過,但最后還是覺得要解決了根本問題以后再引入,因為它只是一個工具,便于管理的工具。就像我們要求代碼能夠做單元測試一樣,如果沒有zookeeper是否你的系統(tǒng)就無法run,小到模塊,大到系統(tǒng),接口化設(shè)計就是要屏蔽實(shí)現(xiàn)對系統(tǒng)設(shè)計后期可擴(kuò)展,穩(wěn)定性的影響,所有系統(tǒng)最后都能夠退化為文件交換方式的處理模式,因此如果能夠用文件交換可以實(shí)現(xiàn)的了的話,你的系統(tǒng)就是最ok的了。(你可以發(fā)現(xiàn)linux這么偉大的操作系統(tǒng)就是如此,一切文件化,一切接口化,簡單就是美,這個美需要不斷的堅持自己的原則)
@import url(http://m.tkk7.com/CuteSoft_Client/CuteEditor/Load.ashx?type=style&file=SyntaxHighlighter.css);@import url(/css/cuteeditor.css);