1 . 用Executors構(gòu)造一個新的線程池
 ExecutorService executor = Executors.newCachedThreadPool();
ExecutorService executor = Executors.newCachedThreadPool();
方法 newCachedThreadPool();
創(chuàng)建一個可根據(jù)需要創(chuàng)建新線程的線程池,但是在以前構(gòu)造的線程可用時將重用它們,并在需要時使用提供的 ThreadFactory 創(chuàng)建新線程。
2. 用構(gòu)造的線程池創(chuàng)建ExecutorFilter
ExecutorFilter es= new ExecutorFilter(executor));
在ExecutorFilter內(nèi)部:
只需要將相應(yīng)的事件分發(fā)到到線程池的相應(yīng)線程即可,但是SessionCreated事件只能在主線程中,不能分發(fā)
觸發(fā)方法
1 .
首先構(gòu)造一個IoFilterEvent,這個IoFilterEvent包含1、事件的類型,2、下一個過濾器
然后觸發(fā)該時間的處理方法。

 if (eventTypes.contains(IoEventType.SESSION_OPENED))
if (eventTypes.contains(IoEventType.SESSION_OPENED))  {
{
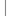 fireEvent(new IoFilterEvent(nextFilter, IoEventType.SESSION_OPENED,
fireEvent(new IoFilterEvent(nextFilter, IoEventType.SESSION_OPENED,
session, null));
 }
}
2 .
從線程池中取出一個線程執(zhí)行事件處理
protected void fireEvent(IoFilterEvent event) {
getExecutor().execute(event);
}
在構(gòu)造ExecutorFilter 時如果沒有傳入IoEventType則默認(rèn)只對如下幾種幾件感興趣
EXCEPTION_CAUGHT
MESSAGE_RECEIVED
MESSAGE_SENT
SESSION_CLOSED
SESSION_IDLE
SESSION_OPENED
當(dāng)然還需要覆蓋相應(yīng)的事件處理方法 如上所示
參數(shù)db_block_size;
這個參數(shù)只能設(shè)置成底層操作系統(tǒng)物理塊大小的整數(shù)倍,最好是2的n次方倍。
如WINDOWS下4KB,8KB,16KB
且該參數(shù)需要在建庫的時候指定,一旦指定不能更改。
雖然在ORACLE9I以上可以指定表空間的數(shù)據(jù)庫大小,允許同時使用包括非默認(rèn)大小在內(nèi)的數(shù)據(jù)庫塊大小。不過需要設(shè)置指定大小數(shù)據(jù)塊的buffer_cache.
小的塊:
小的塊降低塊競爭,因為每個塊中的行較少.
小的塊對于小的行有益.
小的塊對于隨意的訪問較好.如果一個塊不太可能在讀入內(nèi)存后被修改,那么塊的大小越小使用buffer cache越有效率。當(dāng)內(nèi)存資源很珍貴時尤為重要,因為數(shù)據(jù)庫的buffer cache是被限制大小的。
劣勢:
小塊的管理消費相對大.
因為行的大小你可能只在塊中存儲很小數(shù)目的行,這可能導(dǎo)致額外的I/O。
小塊可能導(dǎo)致更多的索引塊被讀取
大的塊
好處:
更少的管理消費和更多存儲數(shù)據(jù)的空間.
大塊對于有順序的讀取較好. 譬如說全表掃描
大塊對很大的行較好
大塊改進(jìn)了索引讀取的性能.大的塊可以在一個塊中容納更多的索引條目,降低了大的索引級的數(shù)量.越少的index level意味著在遍歷索引分支的時候越少的I/O。
劣勢:
大塊不適合在OLTP中用作索引塊,因為它們增加了在索引葉塊上的塊競爭。
如果你是隨意的訪問小的行并有大的塊,buffer cache就被浪費了。例如,8 KB的block size 和50 byte row size,你浪費了7,950
將進(jìn)酒 杯莫停 -------> 亭名: 悲默亭
全球通史
《詩經(jīng)·采薇》
昔我往矣,楊柳依依 今我來思,雨雪霏霏
摘要: <?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance...
閱讀全文
在搜索引擎中,切詞語是一個重要的部分,其中包括專有名詞的提取、詞的分割、詞的格式化等等。
TokenStream 類幾乎是所有這些類的基類
有兩個需要被子類實現(xiàn)的方法Token next() 和 close()
首先來看analysis包,這個包主要是提供一些簡單的詞匯化處理
以Tokenizer結(jié)尾的類是將要處理的字符串進(jìn)行分割成Token流,而根據(jù)分割的依據(jù)的又產(chǎn)生了以下幾個Tokenizer類
首先Tokenizer類是所有以Tokenizer結(jié)尾的類的基類
然后是CharTokenizer,所有的以Tokenizer結(jié)尾的類都是從這個類繼承的
這個類中有一個抽象方法
protected abstract boolean isTokenChar(char c);
另外一個需要被子類覆寫的方法
protected char normalize(char c) {};
是對單個字符進(jìn)行處理的方法譬如說將英文字母全部轉(zhuǎn)化為小寫
還有一個變量
protected Reader input;
這個讀取器是這些類所處理的數(shù)據(jù)的 數(shù)據(jù)源
輸入一個Reader ,產(chǎn)生一個Token流
這個方法是是否進(jìn)行切分的依據(jù),依次讀取char流,然后用這個方法對每個char進(jìn)行檢測,如果返回false則將預(yù)先存儲在
詞匯緩沖區(qū)中的char數(shù)組作為一個Token返回
LetterTokenizer :
protected boolean isTokenChar(char c) {
return Character.isLetter(c);
}
WhitespaceTokenizer:
protected boolean isTokenChar(char c) {
return !Character.isWhitespace(c);
}
LowerCaseTokenizer extends LetterTokenizer:
protected char normalize(char c) {
return Character.toLowerCase(c);
}
在構(gòu)造函數(shù)中調(diào)用super(in);進(jìn)行和 LetterTokenizer同樣的操作,但是在詞匯化之前所有的詞都轉(zhuǎn)化為小寫了
然后是以Filter結(jié)尾的類,這個類簇主要是對已經(jīng)詞匯化的Token流進(jìn)行進(jìn)一步的處理
輸入是Token流 , 輸出仍然是Token流。
TokenFilter extends TokenStream 是所有這些類的父類
protected TokenStream input;
在TokenFilter 中有一個TokenStream 變量,是Filter類簇處理的數(shù)據(jù)源,而Filter類簇又是繼承了TokenStream 類的
有一個public final Token next()方法,這個方法以TokenStream.next()產(chǎn)生的Token流 為處理源,產(chǎn)生的仍然是Token流
只不過中間有一些處理的過程
LowerCaseFilter:將所有的Token流的轉(zhuǎn)化為小寫
t.termText = t.termText.toLowerCase();
StopFilter:過濾掉一些停止詞,這些停止詞由構(gòu)造函數(shù)指定
for (Token token = input.next(); token != null; token = input.next())
if (!stopWords.contains(token.termText))
return token;
比較一下Tokenizer類簇和Filter類簇,可以知道
Tokenizer類簇主要是對輸入的Reader流,實際上是字符流按照一定的規(guī)則進(jìn)行分割,產(chǎn)生出Token流
其輸入是字符串的Reader流形式,輸出是Token流
Filter類簇主要是對輸入的Token流進(jìn)行更進(jìn)一步的處理,如去除停止詞,轉(zhuǎn)化為小寫
主要為一些格式化操作。
由于Filter類簇的輸入輸出相同,所以可以嵌套幾個不同的Filter類,以達(dá)到預(yù)期的處理目的。
前一個Filter類的輸出作為后一個Filter類的輸入
而Tokenizer類簇由于輸入輸出不同,所以不能嵌套
在JAVA JDK1.5以后具有的自動裝箱與拆箱的功能,所謂的自動裝箱
與拆箱也就是把基本的數(shù)據(jù)類型自動的轉(zhuǎn)為封裝類型。
如:自動裝箱,它可以直接把基本類型賦值給封裝類型
Integer num = 10 ;
Double d = 2d ;
自動拆箱,它可以把封裝類型賦值給基本類型
int num = new Integer(10);
double d = new Double(2d);
自動裝箱與拆箱的功能事實上是編譯器來幫您的忙,編譯器在編譯時期依您所編寫的語法,決定是否進(jìn)行裝箱或拆箱動作。在自動裝箱時對于值從-128到127之間的值,它們被裝箱為Integer對象后,會存在內(nèi)存中被重用,所以范例4.6中使用==進(jìn)行比較時,i1 與 i2實際上參考至同一個對象。如果超過了從-128到127之間的值,被裝箱后的Integer對象并不會被重用,即相當(dāng)于每次裝箱時都新建一個Integer對象,所以范例4.7使用==進(jìn)行比較時,i1與i2參考的是不同的對象。所以不要過分依賴自動裝箱與拆箱,您還是必須知道基本數(shù)據(jù)類型與對象的差異。
public void testBoxingUnboxing() {
int i = 10;
Integer inta = i;
inta++;
inta += 1;
int j = inta;
assertTrue(j == inta);結(jié)果是:true//junit里面的方法
assertTrue(j == new Integer(j)); 結(jié)果是:true
assertTrue(10000 == new Integer(10000)); 結(jié)果是:true
}
Integer i = 100.相當(dāng)于編譯器自動為您作以下的語法編譯:
Integer i = new Integer(100).所以自動裝箱與拆箱的功能是所謂的“編譯器蜜糖”(Compiler Sugar),雖然使用這個功能很方便,但在程序運行階段您得了解Java的語義。例如下面的程序是可以通過編譯的:
Integer i = null.int j = i.這樣的語法在編譯時期是合法的,但是在運行時期會有錯誤,因為這種寫法相當(dāng)于:
Integer i = null.int j = i.intValue().null表示i沒有參考至任何的對象實體,它可以合法地指定給對象參考名稱。由于實際上i并沒有參考至任何的對象,所以也就不可能操作intValue()方法,這樣上面的寫法在運行時會出現(xiàn)NullPointerException錯誤。
自動裝箱、拆箱的功能提供了方便性,但隱藏了一些細(xì)節(jié),所以必須小心。再來看范例4.6,您認(rèn)為結(jié)果是什么呢?
Ü. 范例4.6 AutoBoxDemo2.java
public class AutoBoxDemo2 {
public static void main(String[] args) {
Integer i1 = 100;
Integer i2 = 100;
if (i1 == i2)
System.out.println("i1 == i2");
else
System.out.println("i1 != i2").
}
}
從自動裝箱與拆箱的機(jī)制來看,可能會覺得結(jié)果是顯示i1 == i2,您是對的。那么范例4.7的這個程序,您覺得結(jié)果是什么?
Ü. 范例4.7 AutoBoxDemo3.java
public class AutoBoxDemo3 {
public static void main(String[] args) {
Integer i1 = 200;
Integer i2 = 200;
if (i1 == i2)
System.out.println("i1 == i2");
else
System.out.println("i1 != i2");
}
}
結(jié)果是顯示i1 != i2,這有些令人驚訝,兩個范例語法完全一樣,只不過改個數(shù)值而已,結(jié)果卻相反。
其實這與==運算符的比較有關(guān),在第3章中介紹過==是用來比較兩個基本數(shù)據(jù)類型的變量值是否相等,事實上==也用于判斷兩個對象引用名稱是否參考至同一個對象。
在自動裝箱時對于值從–128到127之間的值,它們被裝箱為Integer對象后,會存在內(nèi)存中被重用,所以范例4.6中使用==進(jìn)行比較時,i1 與 i2實際上參考至同一個對象。如果超過了從–128到127之間的值,被裝箱后的Integer對象并不會被重用,即相當(dāng)于每次裝箱時都新建一個Integer對象,所以范例4.7使用==進(jìn)行比較時,i1與i2參考的是不同的對象。
所以不要過分依賴自動裝箱與拆箱,您還是必須知道基本數(shù)據(jù)類型與對象的差異。范例4.7最好還是依正規(guī)的方式來寫,而不是依賴編譯器蜜糖(Compiler Sugar)。例如范例4.7必須改寫為范例4.8才是正確的。
Ü. 范例4.8 AutoBoxDemo4.java
public class AutoBoxDemo4 {
public static void main(String[] args) {
Integer i1 = 200;
Integer i2 = 200;
if (i1.equals(i2))
System.out.println("i1 == i2");
else
System.out.println("i1 != i2");
}
}
結(jié)果這次是顯示i1 == i2。使用這樣的寫法,相信也會比較放心一些,對于這些方便但隱藏細(xì)節(jié)的功能到底要不要用呢?基本上只有一個原則:如果您不確定就不要用。