最近看到一篇文章,其中講述了各種Javadoc生成chm的方法及工具。
其實(shí)我一直以來都是使用自己寫的一個(gè)工具來生成的,不過這個(gè)工具只是生成了.hhp、.hhc和.hhk文件,最后還需要使用FAR進(jìn)行簡單的編輯和壓縮。不過我的工具可以配置并識(shí)別目錄中包含多個(gè)API目錄的情況,并能夠?qū)⒎茿PI的部分生成TOC文件(之所以要使用FAR進(jìn)行簡單的編輯,也是因?yàn)榉茿PI的TOC部分需要根據(jù)情況自己修改或增減)。
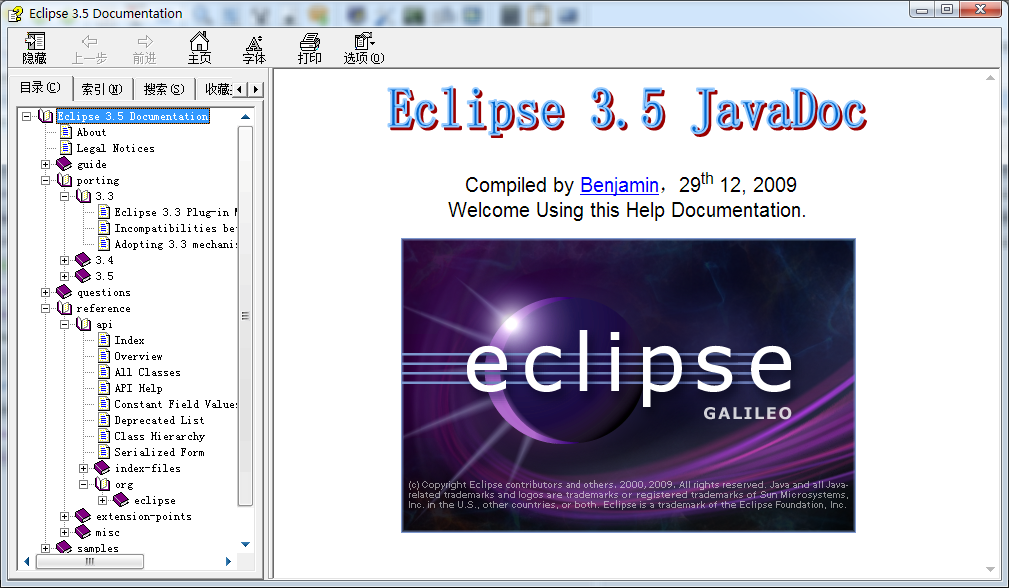
上圖是我是用這個(gè)工具生成的Eclipse 3.5的chm文檔。
其實(shí)這個(gè)過程很簡單,我們只需要構(gòu)造自己的文檔解析器,并按照hhp、hhc和hhk格式規(guī)范生成相應(yīng)的文件就行了。其中文檔解析器我使用了Java的正則表達(dá)式來解析,其解析式的核心如下:
1 public static final String _INDEX_PATTERN = "<DT><A HREF=\"([\\p{Graph}|\\p{Blank}]*?)\"(\\p{Space}\\p{Alpha}+?=\".*?\")?+><B>(.*?)</B></A>(.*?)\\p{Space}-";
2 public static final String _CONTEXT_PATTERN = "<TD><CODE><B><A HREF=\"((\\p{Graph}*?)#(\\p{Graph}*?))\">(.*?)</A></B>(.*?)</CODE>" ;
3 public static final String _TITLE_PATTERN = "<title>(.*?)</title>";
其中第一行是索引文件條目的表達(dá)式,這里我是使用了index-files來生成索引的,當(dāng)然在沒有index-files的時(shí)候是使用TOC解析出來的條目構(gòu)建。
第二行是TOC條目的表達(dá)式,第三行是提取文件title時(shí)使用的表達(dá)式。
當(dāng)然這里表達(dá)式是有缺陷的,比如不能解析不嚴(yán)格的HTML標(biāo)簽等等,不過對(duì)于我自己而言已經(jīng)足夠應(yīng)付絕大多數(shù)Javadoc了。
無人分享的快樂不是真快樂,沒人分擔(dān)的痛苦是真痛苦。
posted on 2010-01-12 14:22
Feenn 閱讀(1204)
評(píng)論(4) 編輯 收藏