任務(wù)調(diào)度信息存儲
在默認情況下Quartz將任務(wù)調(diào)度的運行信息保存在內(nèi)存中����,這種方法提供了最佳的性能,因為內(nèi)存中數(shù)據(jù)訪問最快。不足之處是缺乏數(shù)據(jù)的持久性����,當程序路途停止或系統(tǒng)崩潰時����,所有運行的信息都會丟失。
比如我們希望安排一個執(zhí)行100次的任務(wù),如果執(zhí)行到50次時系統(tǒng)崩潰了,系統(tǒng)重啟時任務(wù)的執(zhí)行計數(shù)器將從0開始。在大多數(shù)實際的應(yīng)用中,我們往往并不需要保存任務(wù)調(diào)度的現(xiàn)場數(shù)據(jù)����,因為很少需要規(guī)劃一個指定執(zhí)行次數(shù)的任務(wù)。
對于僅執(zhí)行一次的任務(wù)來說����,其執(zhí)行條件信息本身應(yīng)該是已經(jīng)持久化的業(yè)務(wù)數(shù)據(jù)(如鎖定到期解鎖任務(wù)����,解鎖的時間應(yīng)該是業(yè)務(wù)數(shù)據(jù))����,當執(zhí)行完成后,條件信息也會相應(yīng)改變����。當然調(diào)度現(xiàn)場信息不僅僅是記錄運行次數(shù)����,還包括調(diào)度規(guī)則����、JobDataMap中的數(shù)據(jù)等等。
如果確實需要持久化任務(wù)調(diào)度信息����,Quartz允許你通過調(diào)整其屬性文件����,將這些信息保存到數(shù)據(jù)庫中。使用數(shù)據(jù)庫保存任務(wù)調(diào)度信息后����,即使系統(tǒng)崩潰后重新啟動����,任務(wù)的調(diào)度信息將得到恢復(fù)����。如前面所說的例子����,執(zhí)行50次崩潰后重新運行,計數(shù)器將從51開始計數(shù)����。使用了數(shù)據(jù)庫保存信息的任務(wù)稱為持久化任務(wù)����。
通過配置文件調(diào)整任務(wù)調(diào)度信息的保存策略
其實Quartz JAR文件的org.quartz包下就包含了一個quartz.properties屬性配置文件并提供了默認設(shè)置����。如果需要調(diào)整默認配置,可以在類路徑下建立一個新的quartz.properties����,它將自動被Quartz加載并覆蓋默認的設(shè)置����。
先來了解一下Quartz的默認屬性配置文件:
代碼清單5 quartz.properties:默認配置
①集群的配置����,這里不使用集群
org.quartz.scheduler.instanceName = DefaultQuartzScheduler
org.quartz.scheduler.rmi.export = false
org.quartz.scheduler.rmi.proxy = false
org.quartz.scheduler.wrapJobExecutionInUserTransaction = false
②配置調(diào)度器的線程池
org.quartz.threadPool.class = org.quartz.simpl.SimpleThreadPool
org.quartz.threadPool.threadCount = 10
org.quartz.threadPool.threadPriority = 5
org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread = true
③配置任務(wù)調(diào)度現(xiàn)場數(shù)據(jù)保存機制
org.quartz.jobStore.class = org.quartz.simpl.RAMJobStore
Quartz的屬性配置文件主要包括三方面的信息:
1)集群信息;
2)調(diào)度器線程池����;
3)任務(wù)調(diào)度現(xiàn)場數(shù)據(jù)的保存����。
如果任務(wù)數(shù)目很大時����,可以通過增大線程池的大小得到更好的性能����。默認情況下,Quartz采用org.quartz.simpl.RAMJobStore保存任務(wù)的現(xiàn)場數(shù)據(jù)����,顧名思義����,信息保存在RAM內(nèi)存中����,我們可以通過以下設(shè)置將任務(wù)調(diào)度現(xiàn)場數(shù)據(jù)保存到數(shù)據(jù)庫中:
代碼清單6 quartz.properties:使用數(shù)據(jù)庫保存任務(wù)調(diào)度現(xiàn)場數(shù)據(jù)
…
org.quartz.jobStore.class = org.quartz.impl.jdbcjobstore.JobStoreTX
org.quartz.jobStore.tablePrefix = QRTZ_①數(shù)據(jù)表前綴
org.quartz.jobStore.dataSource = qzDS②數(shù)據(jù)源名稱
③定義數(shù)據(jù)源的具體屬性
org.quartz.dataSource.qzDS.driver = oracle.jdbc.driver.OracleDriver
org.quartz.dataSource.qzDS.URL = jdbc:oracle:thin:@localhost:1521:ora9i
org.quartz.dataSource.qzDS.user = stamen
org.quartz.dataSource.qzDS.password = abc
org.quartz.dataSource.qzDS.maxConnections = 10
要將任務(wù)調(diào)度數(shù)據(jù)保存到數(shù)據(jù)庫中,就必須使用org.quartz.impl.jdbcjobstore.JobStoreTX代替原來的org.quartz.simpl.RAMJobStore并提供相應(yīng)的數(shù)據(jù)庫配置信息。首先①處指定了Quartz數(shù)據(jù)庫表的前綴����,在②處定義了一個數(shù)據(jù)源����,在③處具體定義這個數(shù)據(jù)源的連接信息����。
你必須事先在相應(yīng)的數(shù)據(jù)庫中創(chuàng)建Quartz的數(shù)據(jù)表(共8張),在Quartz的完整發(fā)布包的docs/dbTables目錄下?lián)碛袑?yīng)不同數(shù)據(jù)庫的SQL腳本����。
查詢數(shù)據(jù)庫中的運行信息
任務(wù)的現(xiàn)場保存對于上層的Quartz程序來說是完全透明的����,我們在src目錄下編寫一個如代碼清單6所示的quartz.properties文件后����,重新運行代碼清單2或代碼清單3的程序,在數(shù)據(jù)庫表中將可以看到對應(yīng)的持久化信息����。當調(diào)度程序運行過程中途停止后����,任務(wù)調(diào)度的現(xiàn)場數(shù)據(jù)將記錄在數(shù)據(jù)表中����,在系統(tǒng)重啟時就可以在此基礎(chǔ)上繼續(xù)進行任務(wù)的調(diào)度。
代碼清單7 JDBCJobStoreRunner:從數(shù)據(jù)庫中恢復(fù)任務(wù)的調(diào)度
package com.baobaotao.basic.quartz;
import org.quartz.Scheduler;
import org.quartz.SchedulerFactory;
import org.quartz.SimpleTrigger;
import org.quartz.Trigger;
import org.quartz.impl.StdSchedulerFactory;
public class JDBCJobStoreRunner {
public static void main(String args[]) {
try {
SchedulerFactory schedulerFactory = new StdSchedulerFactory();
Scheduler scheduler = schedulerFactory.getScheduler();
// ①獲取調(diào)度器中所有的觸發(fā)器組
String[] triggerGroups = scheduler.getTriggerGroupNames();
// ②重新恢復(fù)在tgroup1組中,名為trigger1_1觸發(fā)器的運行
for (int i = 0; i < triggerGroups.length; i++) {
String[] triggers = scheduler.getTriggerNames(triggerGroups[i]);
for (int j = 0; j < triggers.length; j++) {
Trigger tg = scheduler.getTrigger(triggers[j], triggerGroups[i]);
// ②-1:根據(jù)名稱判斷
if (tg instanceof SimpleTrigger&& tg.getFullName().equals("tgroup1.trigger1_1")) {
// ②-1:恢復(fù)運行
scheduler.rescheduleJob(triggers[j], triggerGroups[i], tg);
}
}
}
scheduler.start();
} catch (Exception e) {
e.printStackTrace();
}
}
}
當代碼清單2中的SimpleTriggerRunner執(zhí)行到一段時間后非正常退出,我們就可以通過這個JDBCJobStoreRunner根據(jù)記錄在數(shù)據(jù)庫中的現(xiàn)場數(shù)據(jù)恢復(fù)任務(wù)的調(diào)度����。Scheduler中的所有Trigger以及JobDetail的運行信息都會保存在數(shù)據(jù)庫中����,這里我們僅恢復(fù)tgroup1組中名稱為trigger1_1的觸發(fā)器����,這可以通過如②-1所示的代碼進行過濾,觸發(fā)器的采用GROUP.TRIGGER_NAME的全名格式����。通過Scheduler#rescheduleJob(String triggerName,String groupName,Trigger newTrigger)即可重新調(diào)度關(guān)聯(lián)某個Trigger的任務(wù)����。
下面我們來觀察一下不同時期qrtz_simple_triggers表的數(shù)據(jù):
1.運行代碼清單2的SimpleTriggerRunner一小段時間后退出:

REPEAT_COUNT表示需要運行的總次數(shù)����,而TIMES_TRIGGER表示已經(jīng)運行的次數(shù)����。
2.運行代碼清單7的JDBCJobStoreRunner恢復(fù)trigger1_1的觸發(fā)器,運行一段時間后退出����,這時qrtz_simple_triggers中的數(shù)據(jù)如下:

首先Quartz會將原REPEAT_COUNT-TIMES_TRIGGER得到新的REPEAT_COUNT值����,并記錄已經(jīng)運行的次數(shù)(重新從0開始計算)����。
3.重新啟動JDBCJobStoreRunner運行后,數(shù)據(jù)又將發(fā)生相應(yīng)的變化:

4.繼續(xù)運行直至完成所有剩余的次數(shù)����,再次查詢qrtz_simple_triggers表:
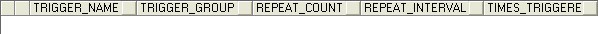
這時����,該表中的記錄已經(jīng)變空����。
值得注意的是,如果你使用JDBC保存任務(wù)調(diào)度數(shù)據(jù)時����,當你運行代碼清單2的SimpleTriggerRunner然后退出����,當再次希望運行SimpleTriggerRunner時����,系統(tǒng)將拋出JobDetail重名的異常:
Unable to store Job with name: 'job1_1' and group: 'jGroup1', because one already exists with this identification.
因為每次調(diào)用Scheduler#scheduleJob()時,Quartz都會將JobDetail和Trigger的信息保存到數(shù)據(jù)庫中����,如果數(shù)據(jù)表中已經(jīng)同名的JobDetail或Trigger����,異常就產(chǎn)生了����。
本文使用quartz 1.6版本,我們發(fā)現(xiàn)當后臺數(shù)據(jù)庫使用MySql時����,數(shù)據(jù)保存不成功����,該錯誤是Quartz的一個Bug����,相信會在高版本中得到修復(fù)。因為HSQLDB不支持SELECT * FROM TABLE_NAME FOR UPDATE的語法,所以不能使用HSQLDB數(shù)據(jù)庫。
小結(jié)
Quartz提供了最為豐富的任務(wù)調(diào)度功能����,不但可以制定周期性運行的任務(wù)調(diào)度方案����,還可以讓你按照日歷相關(guān)的方式進行任務(wù)調(diào)度����。Quartz框架的重要組件包括Job����、JobDetail、Trigger、Scheduler以及輔助性的JobDataMap和SchedulerContext����。
Quartz擁有一個線程池����,通過線程池為任務(wù)提供執(zhí)行線程����,你可以通過配置文件對線程池進行參數(shù)定制。Quartz的另一個重要功能是可將任務(wù)調(diào)度信息持久化到數(shù)據(jù)庫中,以便系統(tǒng)重啟時能夠恢復(fù)已經(jīng)安排的任務(wù)����。此外����,Quartz還擁有完善的事件體系����,允許你注冊各種事件的監(jiān)聽器。