Apriori算法乃是關聯規則挖掘的經典算法,盡管是94年提出的算法,然而至今也有著旺盛的生命力。在互聯網科學領域,也有著廣泛的應用,因此還是值得大家都對此學習一下。
一、術語
1.支持度:support,所有實例中覆蓋某一項集的實例數。
2.置信度:confidence。對于X→Y這個規則,如果數據庫的包含X的實例數的c%也包含Y,則X→Y的置信度為c%。
3.頻繁項集:也稱large itemsets,指支持度大于minsup(最小支持度)的項集
二、思想
1.Apriori算法思想與其它關聯規則挖掘算法在某些方面是相同的。即首先找出所有的頻繁項集,然后從頻繁項集中抽取出規則,再從規則中將置信度小于最小置信度的規則剃除掉。
2.若項集i為頻繁項集,則其所有子集必為頻繁項集。因此,Apriori算法思想在于從頻繁的k-1項集中合并出k項集,然后剃除掉子集有不是頻繁項集的k項集。
3.先從數據庫中讀出每條實例,對于設定閾值,選出頻繁1項集,然后從頻繁1項集中合并,并剃除掉包含非頻繁1項集子集的2項集……
4.符號說明:
L
k:Set of large(frequent) k-itemsets
C
k:Set of candidate k-itemsets
apriori-gen()函數通過合并k-1的頻繁項集,生成C
k
三、算法描述
1) Apriori基本算法
1
 L1={large 1-itemsets};
L1={large 1-itemsets};
2 for(k=2;Lk-1!=Φ;k++)
for(k=2;Lk-1!=Φ;k++)
3{
4 Ck=apriori-gen(Lk-1);
Ck=apriori-gen(Lk-1);
5 for(all transaction t∈D)
6
 {
{
7 Ct=subset(Ck,t);
8 for(all candidates c∈Ct)
9 c.count++;
10 }
}
11 Lk={c∈Ck|c.count>=minsup}
12 }
}
13Answer=∪k Lk; 2)apriori-gen()函數
這個函數將L
k-1(即所有k-1頻繁項集的集合)作為參數,返回一個L
k的超集(即C
k)
算法如下:
1insert into Ck
2select p.item1, p.item2,  ,p.itemk-1,q.itemk-1
,p.itemk-1,q.itemk-1
3from Lk-1 p, Lk-1 q
4where p.item1=q.item1, p.item2=q.item2, , p.itemk-1<q.itemk-1 然后通過剪枝,剃除掉C
k中某些子集不為頻繁k-1項集的項集,算法如下:
1for(all items c∈C
k)
3)從頻繁項集中生成規則
1 for(all l
for(all l∈Answer)
2 {
{
3 A=set of nonempty-subset(l);
A=set of nonempty-subset(l);
4 for(all a∈A)
5 {
{
6 output a→(l-a);
7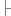 }
}
8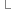 }
} 四、舉例(這里將minsup=1,mincof=0.5)
L3={{1 2 3}{1 2 4}{1 3 4}{1 3 5}{2 3 4}}
在合并步驟時,選取L3中,前兩個項都相同,第三個項不同的項集合并,如{1 2 3}與{1 2 4}合并、{1 3 4}與{1 3 5}合并成{1 2 3 4}和{1 3 4 5}。因此,C4={{1 2 3 4}{1 3 4 5}},但是由于{1 3 4 5}中某子集{3 4 5}并未在L3中出現,因此,將{1 3 4 5}剃除掉,所以L4={{1 2 3 4}}。
然后以L4為例,選取出關聯的規則:
L4中{1 2 3 4}項集中抽取出(這里只列出左邊為3項的情況):
{1 2 3}→4
{1 2 4}→3
{1 3 4}→2
{2 3 4}→1
顯然,因為只有一個4項集,因此,這四條規則的置信度都為100%。因此,全數為關聯規則。
五、Apriori變體
有些Apriori變體為追求時間效率,不是從L
1→C
2→L
2→C
3→....的步驟產生,而是從L
1→C
2→C
3'..產生。
參考文獻:
Agrawal, Rakesh, Srikant, Ramakrishnan. Fast algorithms for mining association rules in large databases. Very Large Data Bases, International Conference Proceedings, p 487, 1994 posted on 2012-02-27 13:08
Seraphi 閱讀(780)
評論(0) 編輯 收藏