memcached本身是集中式的緩存系統,要搞多節點分布,只能通過客戶端實現。memcached的分布算法一般有兩種選擇:
1、根據hash(key)的結果,模連接數的余數決定存儲到哪個節點,也就是hash(key)% sessions.size(),這個算法簡單快速,表現良好。然而這個算法有個缺點,就是在memcached節點增加或者刪除的時候,原有的緩存數據將大規模失效,命中率大受影響,如果節點數多,緩存數據多,重建緩存的代價太高,因此有了第二個算法。
2、Consistent Hashing,一致性哈希算法,他的查找節點過程如下:
首先求出memcached服務器(節點)的哈希值,并將其配置到0~2
32的圓(continuum)上。然后用同樣的方法求出存儲數據的鍵的哈希值,并映射到圓上。然后從數據映射到的位置開始順時針查找,將數據保存到找到的第一個服務器上。如果超過2
32仍然找不到服務器,就會保存到第一臺memcached服務器上。
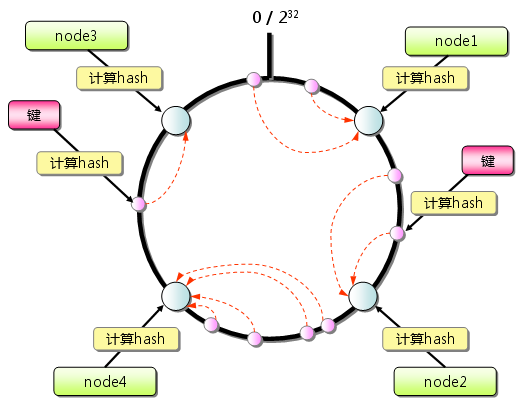
一致性哈希算法來源于P2P網絡的路由算法,更多的信息可以讀
這里。
spymemcached和xmemcached都實現了一致性算法(其實我是照抄的),這里要測試下在使用一致性哈希的情況下,增加節點,看不同
散列函數下命中率和數據分布的變化情況,這個測試結果對于spymemcached和xmemcached是一樣的,測試場景:
從一篇英文小說(《黃金羅盤》前三章)進行單詞統計,并將最后的統計結果存儲到memcached,以單詞為key,以次數為value。單詞個數為3061,memcached原來節點數為10,運行在局域網內同一臺服務器上的不同端口,在存儲統計結果后,增加兩個memcached節點(也就是從10個節點增加到12個節點),統計此時的緩存命中率并查看數據的分布情況。
結果如下表格,命中率一行表示增加節點后的命中率情況(增加前為100%),后續的行表示各個節點存儲的單詞數,CRC32_HASH表示采用CRC32散列函數,KETAMA_HASH是基于md5的散列函數也是默認情況下一致性哈希的推薦算法,FNV1_32_HASH就是FNV 32位散列函數,NATIVE_HASH就是java.lang.String.hashCode()方法返回的long取32位的結果,MYSQL_HASH是xmemcached添加的傳說來自于mysql源碼中的哈希函數。
| |
CRC32_HASH |
KETAMA_HASH |
FNV1_32_HASH |
NATIVE_HASH |
MYSQL_HASH |
命中率
|
78.5% |
83.3% |
78.2% |
99.89% |
86.9% |
| 節點1 |
319 |
366 |
546 |
3596 |
271 |
| 節點2 |
399 |
350 |
191 |
1 |
233 |
| 節點3 |
413 |
362 |
491 |
0 |
665 |
| 節點4 |
393 |
364 |
214 |
1 |
42 |
| 節點5 |
464 |
403 |
427 |
1 |
421 |
| 節點6 |
472 |
306 |
299 |
0 |
285 |
| 節點7 |
283 |
347 |
123 |
0 |
635 |
| 節點8 |
382 |
387 |
257 |
2 |
408 |
| 節點9 |
238 |
341 |
297 |
0 |
55 |
| 節點10 |
239 |
375 |
756 |
0 |
586 |
| 范圍 |
200~500 |
300~400
|
150~750 |
0~3600 |
50~650 |
結果分析:
1、命中率最高看起來是NATIVE_HASH,然而NATIVE_HASH情況下數據集中存儲在第一個節點,顯然沒有實際使用價值。為什么會集中存儲在第一個節點呢?這是由于在查找存儲的節點的過程中,會比較hash(key)和hash(節點IP地址),而在采用了NATIVE_HASH的情況下,所有連接的hash值會呈現一個遞增狀況(因為String.hashCode是乘法散列函數),如:
192.168.0.100:12000 736402923
192.168.0.100:12001 736402924
192.168.0.100:12002 736402925
192.168.0.100:12003 736402926
如果這些值很大的會,那么單詞的hashCode()會通常小于這些值的第一個,那么查找就經常只找到第一個節點并存儲數據,當然,這里有測試的局限性,因為memcached都跑在一個臺機器上只是端口不同造成了hash(節點IP地址)的連續遞增,將分布不均勻的問題放大了。
2、從結果上看,KETAMA_HASH維持了一個最佳平衡,在增加兩個節點后還能訪問到83.3%的單詞,并且數據分布在各個節點上的數目也相對平均,難怪作為默認散列算法。
3、最后,單純比較下散列函數的計算效率:
CRC32_HASH:3266
KETAMA_HASH:7500
FNV1_32_HASH:375
NATIVE_HASH:187
MYSQL_HASH:500
NATIVE_HASH > FNV1_32_HASH > MYSQL_HASH > CRC32_HASH > KETAMA_HASH