
2006年8月30日
摘要:
閱讀全文
摘要:
閱讀全文
摘要:
閱讀全文
摘要:
閱讀全文
摘要:
閱讀全文
摘要:
閱讀全文
摘要:
閱讀全文
摘要:
閱讀全文
摘要:
閱讀全文
摘要:
閱讀全文
摘要:
閱讀全文
摘要:
閱讀全文
摘要:
閱讀全文
摘要:
閱讀全文
出處:http://m.tkk7.com/xmatthew/archive/2008/04/14/192450.html
(轉(zhuǎn))設(shè)計(jì)一個(gè)Tomcat訪問(wèn)日志分析工具
常使用web服務(wù)器的朋友大都了解,一般的web server有兩部分日志:
一是運(yùn)行中的日志,它主要記錄運(yùn)行的一些信息,尤其是一些異常錯(cuò)誤日志信息
二是訪問(wèn)日志信息,它記錄的訪問(wèn)的時(shí)間,IP,訪問(wèn)的資料等相關(guān)信息。
現(xiàn)在我來(lái)和大家介紹一下利用tomcat產(chǎn)生的訪問(wèn)日志數(shù)據(jù),我們能做哪些有效的分析數(shù)據(jù)?
首先是配置tomcat訪問(wèn)日志數(shù)據(jù),默認(rèn)情況下訪問(wèn)日志沒(méi)有打開,配置的方式如下:
編輯 ${catalina}/conf/server.xml文件.注:${catalina}是tomcat的安裝目錄
把以下的注釋(<!-- -->)去掉即可。
<!--
<Valve className="org.apache.catalina.valves.AccessLogValve"
directory="logs" prefix="localhost_access_log." suffix=".txt"
pattern="common" resolveHosts="false"/>
-->
其中 directory是產(chǎn)生的目錄 tomcat安裝${catalina}作為當(dāng)前目錄
pattern表示日志生產(chǎn)的格式,common是tomcat提供的一個(gè)標(biāo)準(zhǔn)設(shè)置格式。其具體的表達(dá)式為 %h %l %u %t "%r" %s %b
但本人建議采用以下具體的配置,因?yàn)闃?biāo)準(zhǔn)配置有一些重要的日志數(shù)據(jù)無(wú)法生。
%h %l %u %t "%r" %s %b %T
具體的日志產(chǎn)生樣式說(shuō)明如下(從官方文檔中摘錄):
* %a - Remote IP address
* %A - Local IP address
* %b - Bytes sent, excluding HTTP headers, or '-' if zero
* %B - Bytes sent, excluding HTTP headers
* %h - Remote host name (or IP address if resolveHosts is false)
* %H - Request protocol
* %l - Remote logical username from identd (always returns '-')
* %m - Request method (GET, POST, etc.)
* %p - Local port on which this request was received
* %q - Query string (prepended with a '?' if it exists)
* %r - First line of the request (method and request URI)
* %s - HTTP status code of the response
* %S - User session ID
* %t - Date and time, in Common Log Format
* %u - Remote user that was authenticated (if any), else '-'
* %U - Requested URL path
* %v - Local server name
* %D - Time taken to process the request, in millis
* %T - Time taken to process the request, in seconds
There is also support to write information from the cookie, incoming header, the Session or something else in the ServletRequest. It is modeled after the apache syntax:
* %{xxx}i for incoming headers
* %{xxx}c for a specific cookie
* %{xxx}r xxx is an attribute in the ServletRequest
* %{xxx}s xxx is an attribute in the HttpSession
現(xiàn)在我們回頭再來(lái)看一下下面這個(gè)配置 %h %l %u %t "%r" %s %b %T 生產(chǎn)的訪問(wèn)日志數(shù)據(jù),我們可以做哪些事?
先看一下,我們能得到的數(shù)據(jù)有:
* %h 訪問(wèn)的用戶IP地址
* %l 訪問(wèn)邏輯用戶名,通常返回'-'
* %u 訪問(wèn)驗(yàn)證用戶名,通常返回'-'
* %t 訪問(wèn)日時(shí)
* %r 訪問(wèn)的方式(post或者是get),訪問(wèn)的資源和使用的http協(xié)議版本
* %s 訪問(wèn)返回的http狀態(tài)
* %b 訪問(wèn)資源返回的流量
* %T 訪問(wèn)所使用的時(shí)間
有了這些數(shù)據(jù),我們可以根據(jù)時(shí)間段做以下的分析處理(圖片使用jfreechart工具動(dòng)態(tài)生成):
* 獨(dú)立IP數(shù)統(tǒng)計(jì)
* 訪問(wèn)請(qǐng)求數(shù)統(tǒng)計(jì)
* 訪問(wèn)資料文件數(shù)統(tǒng)計(jì)
* 訪問(wèn)流量統(tǒng)計(jì)
* 訪問(wèn)處理響應(yīng)時(shí)間統(tǒng)計(jì)
* 統(tǒng)計(jì)所有404錯(cuò)誤頁(yè)面
* 統(tǒng)計(jì)所有500錯(cuò)誤的頁(yè)面
* 統(tǒng)計(jì)訪問(wèn)最頻繁頁(yè)面
* 統(tǒng)計(jì)訪問(wèn)處理時(shí)間最久頁(yè)面
* 統(tǒng)計(jì)并發(fā)訪問(wèn)頻率最高的頁(yè)面

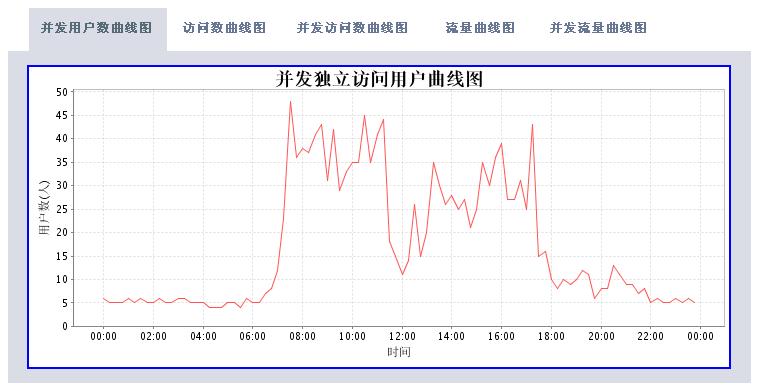




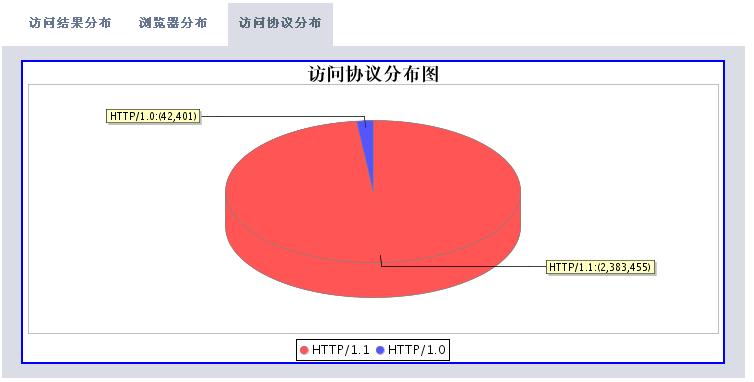

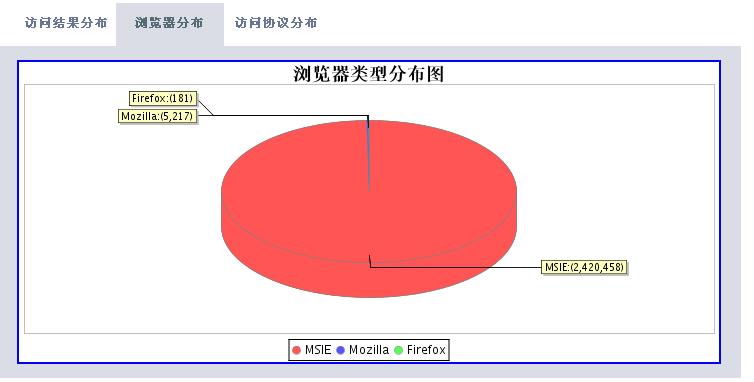


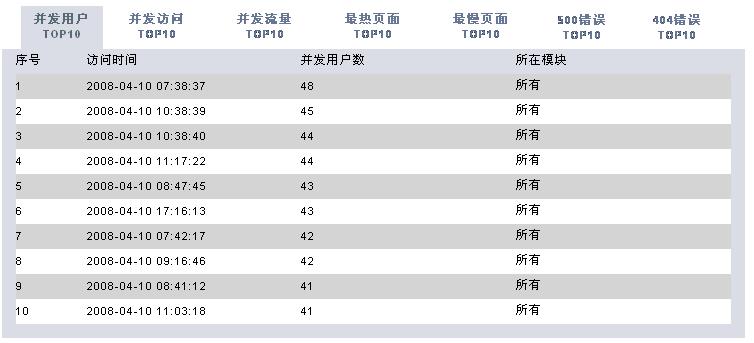

分析工具包括兩大部分,一個(gè)是后臺(tái)解釋程序,每天執(zhí)行一次對(duì)后臺(tái)日志數(shù)據(jù)進(jìn)行解析后保存到數(shù)據(jù)庫(kù)中。
第二個(gè)是顯示程序,從數(shù)據(jù)庫(kù)中查詢數(shù)據(jù)并生成相應(yīng)的圖表信息。
摘要:
閱讀全文
摘要:
閱讀全文
如果你覺(jué)得你的Eclipse在啟動(dòng)的時(shí)候很慢(比如說(shuō)超過(guò)20秒鐘),也許你要調(diào)整一下你的Eclipse啟動(dòng)參數(shù)了,以下是一些``小貼士'':
1. 檢查啟動(dòng)Eclipse的JVM設(shè)置。 在Help\About Eclipse SDK\Configuration Detail里面,你可以看到啟動(dòng)Eclipse的JVM。 這個(gè)JVM和你在Eclipse中設(shè)置的Installed JDK是兩回事情。 如果啟動(dòng)Eclipse的JVM還是JDK 1.4的話,那最好改為JDK 5,因?yàn)镴DK 5的性能比1.4更好。
C:\eclipse\eclipse.exe -vm "C:\Program Files\Java\jdk1.5.0_08\ bin\javaw.exe"
2. 檢查Eclipse所使用的heap的大小。 在C:\eclipse目錄下有一個(gè)配置文件eclipse.ini,其中配置了Eclipse啟動(dòng)的默認(rèn)heap大小
-vmargs
-Xms40M
-Xmx256M
所以你可以把默認(rèn)值改為:
-vmargs
-Xms256M
-Xmx512M
當(dāng)然,也可以這樣做,把堆的大小改為256 - 512。
C:\eclipse\eclipse.exe -vm "C:\Program Files\Java\jdk1.5.0_08\ bin\javaw.exe" -vmargs -Xms256M -Xmx512M
3. 其他的啟動(dòng)參數(shù)。 如果你有一個(gè)雙核的CPU,也許可以嘗試這個(gè)參數(shù):
-XX:+UseParallelGC
讓GC可以更快的執(zhí)行。(只是JDK 5里對(duì)GC新增加的參數(shù))
Java對(duì)多線程的支持與同步機(jī)制深受大家的喜愛(ài),似乎看起來(lái)使用了synchronized關(guān)鍵字就可以輕松地解決多線程共享數(shù)據(jù)同步問(wèn)題。到底如何?――還得對(duì)synchronized關(guān)鍵字的作用進(jìn)行深入了解才可定論。
總的說(shuō)來(lái),synchronized關(guān)鍵字可以作為函數(shù)的修飾符,也可作為函數(shù)內(nèi)的語(yǔ)句,也就是平時(shí)說(shuō)的同步方法和同步語(yǔ)句塊。如果再細(xì)的分類,synchronized可作用于instance變量、object reference(對(duì)象引用)、static函數(shù)和class literals(類名稱字面常量)身上。
在進(jìn)一步闡述之前,我們需要明確幾點(diǎn):
A.無(wú)論synchronized關(guān)鍵字加在方法上還是對(duì)象上,它取得的鎖都是對(duì)象,而不是把一段代碼或函數(shù)當(dāng)作鎖――而且同步方法很可能還會(huì)被其他線程的對(duì)象訪問(wèn)。
B.每個(gè)對(duì)象只有一個(gè)鎖(lock)與之相關(guān)聯(lián)。
C.實(shí)現(xiàn)同步是要很大的系統(tǒng)開銷作為代價(jià)的,甚至可能造成死鎖,所以盡量避免無(wú)謂的同步控制。
接著來(lái)討論synchronized用到不同地方對(duì)代碼產(chǎn)生的影響:
假設(shè)P1、P2是同一個(gè)類的不同對(duì)象,這個(gè)類中定義了以下幾種情況的同步塊或同步方法,P1、P2就都可以調(diào)用它們。
1. 把synchronized當(dāng)作函數(shù)修飾符時(shí),示例代碼如下:
Public synchronized void methodAAA()
{
//….
}
這也就是同步方法,那這時(shí)synchronized鎖定的是哪個(gè)對(duì)象呢?它鎖定的是調(diào)用這個(gè)同步方法對(duì)象。也就是說(shuō),當(dāng)一個(gè)對(duì)象P1在不同的線程中執(zhí)行這個(gè)同步方法時(shí),它們之間會(huì)形成互斥,達(dá)到同步的效果。但是這個(gè)對(duì)象所屬的Class所產(chǎn)生的另一對(duì)象P2卻可以任意調(diào)用這個(gè)被加了synchronized關(guān)鍵字的方法。
上邊的示例代碼等同于如下代碼:
public void methodAAA()
{
synchronized (this) // (1)
{
//…..
}
}
(1)處的this指的是什么呢?它指的就是調(diào)用這個(gè)方法的對(duì)象,如P1。可見(jiàn)同步方法實(shí)質(zhì)是將synchronized作用于object reference。――那個(gè)拿到了P1對(duì)象鎖的線程,才可以調(diào)用P1的同步方法,而對(duì)P2而言,P1這個(gè)鎖與它毫不相干,程序也可能在這種情形下擺脫同步機(jī)制的控制,造成數(shù)據(jù)混亂:(
2.同步塊,示例代碼如下:
public void method3(SomeObject so)
{
synchronized(so)
{
//…..
}
}
這時(shí),鎖就是so這個(gè)對(duì)象,誰(shuí)拿到這個(gè)鎖誰(shuí)就可以運(yùn)行它所控制的那段代碼。當(dāng)有一個(gè)明確的對(duì)象作為鎖時(shí),就可以這樣寫程序,但當(dāng)沒(méi)有明確的對(duì)象作為鎖,只是想讓一段代碼同步時(shí),可以創(chuàng)建一個(gè)特殊的instance變量(它得是一個(gè)對(duì)象)來(lái)充當(dāng)鎖:
class Foo implements Runnable
{
private byte[] lock = new byte[0]; // 特殊的instance變量
Public void methodA()
{
synchronized(lock) { //… }
}
//…..
}
注:零長(zhǎng)度的byte數(shù)組對(duì)象創(chuàng)建起來(lái)將比任何對(duì)象都經(jīng)濟(jì)――查看編譯后的字節(jié)碼:生成零長(zhǎng)度的byte[]對(duì)象只需3條操作碼,而Object lock = new Object()則需要7行操作碼。
3.將synchronized作用于static 函數(shù),示例代碼如下:
Class Foo
{
public synchronized static void methodAAA() // 同步的static 函數(shù)
{
//….
}
public void methodBBB()
{
synchronized(Foo.class) // class literal(類名稱字面常量)
}
}
代碼中的methodBBB()方法是把class literal作為鎖的情況,它和同步的static函數(shù)產(chǎn)生的效果是一樣的,取得的鎖很特別,是當(dāng)前調(diào)用這個(gè)方法的對(duì)象所屬的類(Class,而不再是由這個(gè)Class產(chǎn)生的某個(gè)具體對(duì)象了)。
記得在《Effective Java》一書中看到過(guò)將 Foo.class和 P1.getClass()用于作同步鎖還不一樣,不能用P1.getClass()來(lái)達(dá)到鎖這個(gè)Class的目的。P1指的是由Foo類產(chǎn)生的對(duì)象。
可以推斷:如果一個(gè)類中定義了一個(gè)synchronized的static函數(shù)A,也定義了一個(gè)synchronized 的instance函數(shù)B,那么這個(gè)類的同一對(duì)象Obj在多線程中分別訪問(wèn)A和B兩個(gè)方法時(shí),不會(huì)構(gòu)成同步,因?yàn)樗鼈兊逆i都不一樣。A方法的鎖是Obj這個(gè)對(duì)象,而B的鎖是Obj所屬的那個(gè)Class。
小結(jié)如下:
搞清楚synchronized鎖定的是哪個(gè)對(duì)象,就能幫助我們?cè)O(shè)計(jì)更安全的多線程程序。
還有一些技巧可以讓我們對(duì)共享資源的同步訪問(wèn)更加安全:
1. 定義private 的instance變量+它的 get方法,而不要定義public/protected的instance變量。如果將變量定義為public,對(duì)象在外界可以繞過(guò)同步方法的控制而直接取得它,并改動(dòng)它。這也是JavaBean的標(biāo)準(zhǔn)實(shí)現(xiàn)方式之一。
2. 如果instance變量是一個(gè)對(duì)象,如數(shù)組或ArrayList什么的,那上述方法仍然不安全,因?yàn)楫?dāng)外界對(duì)象通過(guò)get方法拿到這個(gè)instance對(duì)象的引用后,又將其指向另一個(gè)對(duì)象,那么這個(gè)private變量也就變了,豈不是很危險(xiǎn)。這個(gè)時(shí)候就需要將get方法也加上synchronized同步,并且,只返回這個(gè)private對(duì)象的clone()――這樣,調(diào)用端得到的就是對(duì)象副本的引用了。
摘要:
閱讀全文
這幾個(gè)學(xué)習(xí)材料非常短小精悍,可清晰快捷的掌握以下幾個(gè)概念,方便更深入學(xué)習(xí)
XML tutorial:
http://www.w3schools.com/xml/default.asp
SOAP tutorial:
http://www.w3schools.com/soap/default.asp
WSDL tutorial:
http://www.w3schools.com/wsdl/default.asp
WEB Service tutorial:
http://www.w3schools.com/webservices/default.asp
類-->對(duì)象-->實(shí)例
人類是類
某個(gè)人是對(duì)象
你是實(shí)例
實(shí)例本身也是對(duì)象。
表現(xiàn)出來(lái)是這樣的
String 類
String str str是對(duì)象
String str = "abc"; "abc"是實(shí)例,也是對(duì)象.
這樣也能解釋instance of object這種說(shuō)法 str的實(shí)例是"abc"
1.?概述?
本文主要包括以下幾個(gè)方面:編碼基本知識(shí),java,系統(tǒng)軟件,url,工具軟件等。?
在下面的描述中,將以"中文"兩個(gè)字為例,經(jīng)查表可以知道其GB2312編碼是"d6d0?cec4",Unicode編碼為"4e2d?6587",UTF編碼就是"e4b8ad?e69687"。注意,這兩個(gè)字沒(méi)有iso8859-1編碼,但可以用iso8859-1編碼來(lái)"表示"。?
2.?編碼基本知識(shí)?
最早的編碼是iso8859-1,和ascii編碼相似。但為了方便表示各種各樣的語(yǔ)言,逐漸出現(xiàn)了很多標(biāo)準(zhǔn)編碼,重要的有如下幾個(gè)。?
2.1.?iso8859-1?
屬于單字節(jié)編碼,最多能表示的字符范圍是0-255,應(yīng)用于英文系列。比如,字母'a'的編碼為0x61=97。?
很明顯,iso8859-1編碼表示的字符范圍很窄,無(wú)法表示中文字符。但是,由于是單字節(jié)編碼,和計(jì)算機(jī)最基礎(chǔ)的表示單位一致,所以很多時(shí)候,仍舊使用iso8859-1編碼來(lái)表示。而且在很多協(xié)議上,默認(rèn)使用該編碼。比如,雖然"中文"兩個(gè)字不存在iso8859-1編碼,以gb2312編碼為例,應(yīng)該是"d6d0?cec4"兩個(gè)字符,使用iso8859-1編碼的時(shí)候則將它拆開為4個(gè)字節(jié)來(lái)表示:"d6?d0?ce?c4"(事實(shí)上,在進(jìn)行存儲(chǔ)的時(shí)候,也是以字節(jié)為單位處理的)。而如果是UTF編碼,則是6個(gè)字節(jié)"e4?b8?ad?e6?96?87"。很明顯,這種表示方法還需要以另一種編碼為基礎(chǔ)。?
2.2.?GB2312/GBK?
這就是漢子的國(guó)標(biāo)碼,專門用來(lái)表示漢字,是雙字節(jié)編碼,而英文字母和iso8859-1一致(兼容iso8859-1編碼)。其中g(shù)bk編碼能夠用來(lái)同時(shí)表示繁體字和簡(jiǎn)體字,而gb2312只能表示簡(jiǎn)體字,gbk是兼容gb2312編碼的。?
2.3.?unicode?
這是最統(tǒng)一的編碼,可以用來(lái)表示所有語(yǔ)言的字符,而且是定長(zhǎng)雙字節(jié)(也有四字節(jié)的)編碼,包括英文字母在內(nèi)。所以可以說(shuō)它是不兼容iso8859-1編碼的,也不兼容任何編碼。不過(guò),相對(duì)于iso8859-1編碼來(lái)說(shuō),uniocode編碼只是在前面增加了一個(gè)0字節(jié),比如字母'a'為"00?61"。?
需要說(shuō)明的是,定長(zhǎng)編碼便于計(jì)算機(jī)處理(注意GB2312/GBK不是定長(zhǎng)編碼),而unicode又可以用來(lái)表示所有字符,所以在很多軟件內(nèi)部是使用unicode編碼來(lái)處理的,比如java。?
2.4.?UTF?
考慮到unicode編碼不兼容iso8859-1編碼,而且容易占用更多的空間:因?yàn)閷?duì)于英文字母,unicode也需要兩個(gè)字節(jié)來(lái)表示。所以u(píng)nicode不便于傳輸和存儲(chǔ)。因此而產(chǎn)生了utf編碼,utf編碼兼容iso8859-1編碼,同時(shí)也可以用來(lái)表示所有語(yǔ)言的字符,不過(guò),utf編碼是不定長(zhǎng)編碼,每一個(gè)字符的長(zhǎng)度從1-6個(gè)字節(jié)不等。另外,utf編碼自帶簡(jiǎn)單的校驗(yàn)功能。一般來(lái)講,英文字母都是用一個(gè)字節(jié)表示,而漢字使用三個(gè)字節(jié)。?
注意,雖然說(shuō)utf是為了使用更少的空間而使用的,但那只是相對(duì)于unicode編碼來(lái)說(shuō),如果已經(jīng)知道是漢字,則使用GB2312/GBK無(wú)疑是最節(jié)省的。不過(guò)另一方面,值得說(shuō)明的是,雖然utf編碼對(duì)漢字使用3個(gè)字節(jié),但即使對(duì)于漢字網(wǎng)頁(yè),utf編碼也會(huì)比unicode編碼節(jié)省,因?yàn)榫W(wǎng)頁(yè)中包含了很多的英文字符。?
3.?java對(duì)字符的處理?
在java應(yīng)用軟件中,會(huì)有多處涉及到字符集編碼,有些地方需要進(jìn)行正確的設(shè)置,有些地方需要進(jìn)行一定程度的處理。?
3.1.?getBytes(charset)?
這是java字符串處理的一個(gè)標(biāo)準(zhǔn)函數(shù),其作用是將字符串所表示的字符按照charset編碼,并以字節(jié)方式表示。注意字符串在java內(nèi)存中總是按unicode編碼存儲(chǔ)的。比如"中文",正常情況下(即沒(méi)有錯(cuò)誤的時(shí)候)存儲(chǔ)為"4e2d?6587",如果charset為"gbk",則被編碼為"d6d0?cec4",然后返回字節(jié)"d6?d0?ce?c4"。如果charset為"utf8"則最后是"e4?b8?ad?e6?96?87"。如果是"iso8859-1",則由于無(wú)法編碼,最后返回?"3f?3f"(兩個(gè)問(wèn)號(hào))。?
3.2.?new?String(charset)?
這是java字符串處理的另一個(gè)標(biāo)準(zhǔn)函數(shù),和上一個(gè)函數(shù)的作用相反,將字節(jié)數(shù)組按照charset編碼進(jìn)行組合識(shí)別,最后轉(zhuǎn)換為unicode存儲(chǔ)。參考上述getBytes的例子,"gbk"?和"utf8"都可以得出正確的結(jié)果"4e2d?6587",但iso8859-1最后變成了"003f?003f"(兩個(gè)問(wèn)號(hào))。?
因?yàn)閡tf8可以用來(lái)表示/編碼所有字符,所以new?String(?str.getBytes(?"utf8"?),?"utf8"?)?===?str,即完全可逆。?
3.3.?setCharacterEncoding()?
該函數(shù)用來(lái)設(shè)置http請(qǐng)求或者相應(yīng)的編碼。?
對(duì)于request,是指提交內(nèi)容的編碼,指定后可以通過(guò)getParameter()則直接獲得正確的字符串,如果不指定,則默認(rèn)使用iso8859-1編碼,需要進(jìn)一步處理。參見(jiàn)下述"表單輸入"。值得注意的是在執(zhí)行setCharacterEncoding()之前,不能執(zhí)行任何getParameter()。java?doc上說(shuō)明:This?method?must?be?called?prior?to?reading?request?parameters?or?reading?input?using?getReader()。而且,該指定只對(duì)POST方法有效,對(duì)GET方法無(wú)效。分析原因,應(yīng)該是在執(zhí)行第一個(gè)getParameter()的時(shí)候,java將會(huì)按照編碼分析所有的提交內(nèi)容,而后續(xù)的getParameter()不再進(jìn)行分析,所以setCharacterEncoding()無(wú)效。而對(duì)于GET方法提交表單是,提交的內(nèi)容在URL中,一開始就已經(jīng)按照編碼分析所有的提交內(nèi)容,setCharacterEncoding()自然就無(wú)效。?
對(duì)于response,則是指定輸出內(nèi)容的編碼,同時(shí),該設(shè)置會(huì)傳遞給瀏覽器,告訴瀏覽器輸出內(nèi)容所采用的編碼。?
3.4.?處理過(guò)程?
下面分析兩個(gè)有代表性的例子,說(shuō)明java對(duì)編碼有關(guān)問(wèn)題的處理方法。?
3.4.1.?表單輸入?
User?input??*(gbk:d6d0?cec4)??browser??*(gbk:d6d0?cec4)??web?server??iso8859-1(00d6?00d?000ce?00c4)??class,需要在class中進(jìn)行處理:getbytes("iso8859-1")為d6?d0?ce?c4,new?String("gbk")為d6d0?cec4,內(nèi)存中以u(píng)nicode編碼則為4e2d?6587。?
l?用戶輸入的編碼方式和頁(yè)面指定的編碼有關(guān),也和用戶的操作系統(tǒng)有關(guān),所以是不確定的,上例以gbk為例。?
l?從browser到web?server,可以在表單中指定提交內(nèi)容時(shí)使用的字符集,否則會(huì)使用頁(yè)面指定的編碼。而如果在url中直接用?的方式輸入?yún)?shù),則其編碼往往是操作系統(tǒng)本身的編碼,因?yàn)檫@時(shí)和頁(yè)面無(wú)關(guān)。上述仍舊以gbk編碼為例。?
l?Web?server接收到的是字節(jié)流,默認(rèn)時(shí)(getParameter)會(huì)以iso8859-1編碼處理之,結(jié)果是不正確的,所以需要進(jìn)行處理。但如果預(yù)先設(shè)置了編碼(通過(guò)request.?setCharacterEncoding?()),則能夠直接獲取到正確的結(jié)果。?
l?在頁(yè)面中指定編碼是個(gè)好習(xí)慣,否則可能失去控制,無(wú)法指定正確的編碼。?
3.4.2.?文件編譯?
假設(shè)文件是gbk編碼保存的,而編譯有兩種編碼選擇:gbk或者iso8859-1,前者是中文windows的默認(rèn)編碼,后者是linux的默認(rèn)編碼,當(dāng)然也可以在編譯時(shí)指定編碼。?
Jsp??*(gbk:d6d0?cec4)??java?file??*(gbk:d6d0?cec4)??compiler?read??uincode(gbk:?4e2d?6587;?iso8859-1:?00d6?00d?000ce?00c4)??compiler?write??utf(gbk:?e4b8ad?e69687;?iso8859-1:?*)??compiled?file??unicode(gbk:?4e2d?6587;?iso8859-1:?00d6?00d?000ce?00c4)??class。所以用gbk編碼保存,而用iso8859-1編譯的結(jié)果是不正確的。?
class??unicode(4e2d?6587)??system.out?/?jsp.out??gbk(d6d0?cec4)??os?console?/?browser。?
l?文件可以以多種編碼方式保存,中文windows下,默認(rèn)為ansi/gbk。?
l?編譯器讀取文件時(shí),需要得到文件的編碼,如果未指定,則使用系統(tǒng)默認(rèn)編碼。一般class文件,是以系統(tǒng)默認(rèn)編碼保存的,所以編譯不會(huì)出問(wèn)題,但對(duì)于jsp文件,如果在中文windows下編輯保存,而部署在英文linux下運(yùn)行/編譯,則會(huì)出現(xiàn)問(wèn)題。所以需要在jsp文件中用pageEncoding指定編碼。?
l?Java編譯的時(shí)候會(huì)轉(zhuǎn)換成統(tǒng)一的unicode編碼處理,最后保存的時(shí)候再轉(zhuǎn)換為utf編碼。?
l?當(dāng)系統(tǒng)輸出字符的時(shí)候,會(huì)按指定編碼輸出,對(duì)于中文windows下,System.out將使用gbk編碼,而對(duì)于response(瀏覽器),則使用jsp文件頭指定的contentType,或者可以直接為response指定編碼。同時(shí),會(huì)告訴browser網(wǎng)頁(yè)的編碼。如果未指定,則會(huì)使用iso8859-1編碼。對(duì)于中文,應(yīng)該為browser指定輸出字符串的編碼。?
l?browser顯示網(wǎng)頁(yè)的時(shí)候,首先使用response中指定的編碼(jsp文件頭指定的contentType最終也反映在response上),如果未指定,則會(huì)使用網(wǎng)頁(yè)中meta項(xiàng)指定中的contentType。?
3.5.?幾處設(shè)置?
對(duì)于web應(yīng)用程序,和編碼有關(guān)的設(shè)置或者函數(shù)如下。?
3.5.1.?jsp編譯?
指定文件的存儲(chǔ)編碼,很明顯,該設(shè)置應(yīng)該置于文件的開頭。例如:<%@page?pageEncoding="GBK"%>。另外,對(duì)于一般class文件,可以在編譯的時(shí)候指定編碼。?
3.5.2.?jsp輸出?
指定文件輸出到browser是使用的編碼,該設(shè)置也應(yīng)該置于文件的開頭。例如:<%@?page?contentType="text/html;?charset=?GBK"?%>。該設(shè)置和response.setCharacterEncoding("GBK")等效。?
3.5.3.?meta設(shè)置?
指定網(wǎng)頁(yè)使用的編碼,該設(shè)置對(duì)靜態(tài)網(wǎng)頁(yè)尤其有作用。因?yàn)殪o態(tài)網(wǎng)頁(yè)無(wú)法采用jsp的設(shè)置,而且也無(wú)法執(zhí)行response.setCharacterEncoding()。例如:<META?http-equiv="Content-Type"?content="text/html;?charset=GBK"?/>?
如果同時(shí)采用了jsp輸出和meta設(shè)置兩種編碼指定方式,則jsp指定的優(yōu)先。因?yàn)閖sp指定的直接體現(xiàn)在response中。?
需要注意的是,apache有一個(gè)設(shè)置可以給無(wú)編碼指定的網(wǎng)頁(yè)指定編碼,該指定等同于jsp的編碼指定方式,所以會(huì)覆蓋靜態(tài)網(wǎng)頁(yè)中的meta指定。所以有人建議關(guān)閉該設(shè)置。?
3.5.4.?form設(shè)置?
當(dāng)瀏覽器提交表單的時(shí)候,可以指定相應(yīng)的編碼。例如:<form?accept-charset=?"gb2312">。一般不必不使用該設(shè)置,瀏覽器會(huì)直接使用網(wǎng)頁(yè)的編碼。?
4.?系統(tǒng)軟件?
下面討論幾個(gè)相關(guān)的系統(tǒng)軟件。?
4.1.?mysql數(shù)據(jù)庫(kù)?
很明顯,要支持多語(yǔ)言,應(yīng)該將數(shù)據(jù)庫(kù)的編碼設(shè)置成utf或者unicode,而utf更適合與存儲(chǔ)。但是,如果中文數(shù)據(jù)中包含的英文字母很少,其實(shí)unicode更為適合。?
數(shù)據(jù)庫(kù)的編碼可以通過(guò)mysql的配置文件設(shè)置,例如default-character-set=utf8。還可以在數(shù)據(jù)庫(kù)鏈接URL中設(shè)置,例如:?useUnicode=true&characterEncoding=UTF-8。注意這兩者應(yīng)該保持一致,在新的sql版本里,在數(shù)據(jù)庫(kù)鏈接URL里可以不進(jìn)行設(shè)置,但也不能是錯(cuò)誤的設(shè)置。?
4.2.?apache?
appache和編碼有關(guān)的配置在httpd.conf中,例如AddDefaultCharset?UTF-8。如前所述,該功能會(huì)將所有靜態(tài)頁(yè)面的編碼設(shè)置為UTF-8,最好關(guān)閉該功能。?
另外,apache還有單獨(dú)的模塊來(lái)處理網(wǎng)頁(yè)響應(yīng)頭,其中也可能對(duì)編碼進(jìn)行設(shè)置。?
4.3.?linux默認(rèn)編碼?
這里所說(shuō)的linux默認(rèn)編碼,是指運(yùn)行時(shí)的環(huán)境變量。兩個(gè)重要的環(huán)境變量是LC_ALL和LANG,默認(rèn)編碼會(huì)影響到j(luò)ava?URLEncode的行為,下面有描述。?
建議都設(shè)置為"zh_CN.UTF-8"。?
4.4.?其它?
為了支持中文文件名,linux在加載磁盤時(shí)應(yīng)該指定字符集,例如:mount?/dev/hda5?/mnt/hda5/?-t?ntfs?-o?iocharset=gb2312。?
另外,如前所述,使用GET方法提交的信息不支持request.setCharacterEncoding(),但可以通過(guò)tomcat的配置文件指定字符集,在tomcat的server.xml文件中,形如:<Connector?...?URIEncoding="GBK"/>。這種方法將統(tǒng)一設(shè)置所有請(qǐng)求,而不能針對(duì)具體頁(yè)面進(jìn)行設(shè)置,也不一定和browser使用的編碼相同,所以有時(shí)候并不是所期望的。?
5.?URL地址?
URL地址中含有中文字符是很麻煩的,前面描述過(guò)使用GET方法提交表單的情況,使用GET方法時(shí),參數(shù)就是包含在URL中。?
5.1.?URL編碼?
對(duì)于URL中的一些特殊字符,瀏覽器會(huì)自動(dòng)進(jìn)行編碼。這些字符除了"/?&"等外,還包括unicode字符,比如漢子。這時(shí)的編碼比較特殊。?
IE有一個(gè)選項(xiàng)"總是使用UTF-8發(fā)送URL",當(dāng)該選項(xiàng)有效時(shí),IE將會(huì)對(duì)特殊字符進(jìn)行UTF-8編碼,同時(shí)進(jìn)行URL編碼。如果改選項(xiàng)無(wú)效,則使用默認(rèn)編碼"GBK",并且不進(jìn)行URL編碼。但是,對(duì)于URL后面的參數(shù),則總是不進(jìn)行編碼,相當(dāng)于UTF-8選項(xiàng)無(wú)效。比如"中文.html?a=中文",當(dāng)UTF-8選項(xiàng)有效時(shí),將發(fā)送鏈接"%e4%b8%ad%e6%96%87.html?a=\x4e\x2d\x65\x87";而UTF-8選項(xiàng)無(wú)效時(shí),將發(fā)送鏈接"\x4e\x2d\x65\x87.html?a=\x4e\x2d\x65\x87"。注意后者前面的"中文"兩個(gè)字只有4個(gè)字節(jié),而前者卻有18個(gè)字節(jié),這主要時(shí)URL編碼的原因。?
當(dāng)web?server(tomcat)接收到該鏈接時(shí),將會(huì)進(jìn)行URL解碼,即去掉"%",同時(shí)按照ISO8859-1編碼(上面已經(jīng)描述,可以使用URLEncoding來(lái)設(shè)置成其它編碼)識(shí)別。上述例子的結(jié)果分別是"\ue4\ub8\uad\ue6\u96\u87.html?a=\u4e\u2d\u65\u87"和"\u4e\u2d\u65\u87.html?a=\u4e\u2d\u65\u87",注意前者前面的"中文"兩個(gè)字恢復(fù)成了6個(gè)字符。這里用"\u",表示是unicode。?
所以,由于客戶端設(shè)置的不同,相同的鏈接,在服務(wù)器上得到了不同結(jié)果。這個(gè)問(wèn)題不少人都遇到,卻沒(méi)有很好的解決辦法。所以有的網(wǎng)站會(huì)建議用戶嘗試關(guān)閉UTF-8選項(xiàng)。不過(guò),下面會(huì)描述一個(gè)更好的處理辦法。?
5.2.?rewrite?
熟悉的人都知道,apache有一個(gè)功能強(qiáng)大的rewrite模塊,這里不描述其功能。需要說(shuō)明的是該模塊會(huì)自動(dòng)將URL解碼(去除%),即完成上述web?server(tomcat)的部分功能。有相關(guān)文檔介紹說(shuō)可以使用[NE]參數(shù)來(lái)關(guān)閉該功能,但我試驗(yàn)并未成功,可能是因?yàn)榘姹荆ㄎ沂褂玫氖莂pache?2.0.54)問(wèn)題。另外,當(dāng)參數(shù)中含有"?&?"等符號(hào)的時(shí)候,該功能將導(dǎo)致系統(tǒng)得不到正常結(jié)果。?
rewrite本身似乎完全是采用字節(jié)處理的方式,而不考慮字符串的編碼,所以不會(huì)帶來(lái)編碼問(wèn)題。?
5.3.?URLEncode.encode()?
這是Java本身提供對(duì)的URL編碼函數(shù),完成的工作和上述UTF-8選項(xiàng)有效時(shí)瀏覽器所做的工作相似。值得說(shuō)明的是,java已經(jīng)不贊成不指定編碼來(lái)使用該方法(deprecated)。應(yīng)該在使用的時(shí)候增加編碼指定。?
當(dāng)不指定編碼的時(shí)候,該方法使用系統(tǒng)默認(rèn)編碼,這會(huì)導(dǎo)致軟件運(yùn)行結(jié)果得不確定。比如對(duì)于"中文",當(dāng)系統(tǒng)默認(rèn)編碼為"gb2312"時(shí),結(jié)果是"%4e%2d%65%87",而默認(rèn)編碼為"UTF-8",結(jié)果卻是"%e4%b8%ad%e6%96%87",后續(xù)程序?qū)㈦y以處理。另外,這兒說(shuō)的系統(tǒng)默認(rèn)編碼是由運(yùn)行tomcat時(shí)的環(huán)境變量LC_ALL和LANG等決定的,曾經(jīng)出現(xiàn)過(guò)tomcat重啟后就出現(xiàn)亂碼的問(wèn)題,最后才郁悶的發(fā)現(xiàn)是因?yàn)樾薷男薷牧诉@兩個(gè)環(huán)境變量。?
建議統(tǒng)一指定為"UTF-8"編碼,可能需要修改相應(yīng)的程序。?
5.4.?一個(gè)解決方案?
上面說(shuō)起過(guò),因?yàn)闉g覽器設(shè)置的不同,對(duì)于同一個(gè)鏈接,web?server收到的是不同內(nèi)容,而軟件系統(tǒng)有無(wú)法知道這中間的區(qū)別,所以這一協(xié)議目前還存在缺陷。?
針對(duì)具體問(wèn)題,不應(yīng)該僥幸認(rèn)為所有客戶的IE設(shè)置都是UTF-8有效的,也不應(yīng)該粗暴的建議用戶修改IE設(shè)置,要知道,用戶不可能去記住每一個(gè)web?server的設(shè)置。所以,接下來(lái)的解決辦法就只能是讓自己的程序多一點(diǎn)智能:根據(jù)內(nèi)容來(lái)分析編碼是否UTF-8。?
比較幸運(yùn)的是UTF-8編碼相當(dāng)有規(guī)律,所以可以通過(guò)分析傳輸過(guò)來(lái)的鏈接內(nèi)容,來(lái)判斷是否是正確的UTF-8字符,如果是,則以UTF-8處理之,如果不是,則使用客戶默認(rèn)編碼(比如"GBK"),下面是一個(gè)判斷是否UTF-8的例子,如果你了解相應(yīng)規(guī)律,就容易理解。?
public?static?boolean?isValidUtf8(byte[]?b,int?aMaxCount){?
???????int?lLen=b.length,lCharCount=0;?
???????for(int?i=0;i<lLen?&&?lCharCount<aMaxCount;++lCharCount){?
??????????????byte?lByte=b[i++];//to?fast?operation,?++?now,?ready?for?the?following?for(;;)?
??????????????if(lByte>=0)?continue;//>=0?is?normal?ascii?
??????????????if(lByte<(byte)0xc0?||?lByte>(byte)0xfd)?return?false;?
??????????????int?lCount=lByte>(byte)0xfc?5:lByte>(byte)0xf8?4?
?????????????????????:lByte>(byte)0xf0?3:lByte>(byte)0xe0?2:1;?
??????????????if(i+lCount>lLen)?return?false;?
??????????????for(int?j=0;j<lCount;++j,++i)?if(b[i]>=(byte)0xc0)?return?false;?
???????}?
???????return?true;?
}?
相應(yīng)地,一個(gè)使用上述方法的例子如下:?
public?static?String?getUrlParam(String?aStr,String?aDefaultCharset)?
throws?UnsupportedEncodingException{?
???????if(aStr==null)?return?null;?
???????byte[]?lBytes=aStr.getBytes("ISO-8859-1");?
???????return?new?String(lBytes,StringUtil.isValidUtf8(lBytes)?"utf8":aDefaultCharset);?
}?
不過(guò),該方法也存在缺陷,如下兩方面:?
l?沒(méi)有包括對(duì)用戶默認(rèn)編碼的識(shí)別,這可以根據(jù)請(qǐng)求信息的語(yǔ)言來(lái)判斷,但不一定正確,因?yàn)槲覀冇袝r(shí)候也會(huì)輸入一些韓文,或者其他文字。?
l?可能會(huì)錯(cuò)誤判斷UTF-8字符,一個(gè)例子是"學(xué)習(xí)"兩個(gè)字,其GBK編碼是"?\xd1\xa7\xcf\xb0",如果使用上述isValidUtf8方法判斷,將返回true。可以考慮使用更嚴(yán)格的判斷方法,不過(guò)估計(jì)效果不大。?
有一個(gè)例子可以證明google也遇到了上述問(wèn)題,而且也采用了和上述相似的處理方法,比如,如果在地址欄中輸入"http://www.google.com/search?hl=zh-CN&newwindow=1&q=學(xué)習(xí)",google將無(wú)法正確識(shí)別,而其他漢字一般能夠正常識(shí)別。?
最后,應(yīng)該補(bǔ)充說(shuō)明一下,如果不使用rewrite規(guī)則,或者通過(guò)表單提交數(shù)據(jù),其實(shí)并不一定會(huì)遇到上述問(wèn)題,因?yàn)檫@時(shí)可以在提交數(shù)據(jù)時(shí)指定希望的編碼。另外,中文文件名確實(shí)會(huì)帶來(lái)問(wèn)題,應(yīng)該謹(jǐn)慎使用。?
6.?其它?
下面描述一些和編碼有關(guān)的其他問(wèn)題。?
6.1.?SecureCRT?
除了瀏覽器和控制臺(tái)與編碼有關(guān)外,一些客戶端也很有關(guān)系。比如在使用SecureCRT連接linux時(shí),應(yīng)該讓SecureCRT的顯示編碼(不同的session,可以有不同的編碼設(shè)置)和linux的編碼環(huán)境變量保持一致。否則看到的一些幫助信息,就可能是亂碼。?
另外,mysql有自己的編碼設(shè)置,也應(yīng)該保持和SecureCRT的顯示編碼一致。否則通過(guò)SecureCRT執(zhí)行sql語(yǔ)句的時(shí)候,可能無(wú)法處理中文字符,查詢結(jié)果也會(huì)出現(xiàn)亂碼。?
對(duì)于Utf-8文件,很多編輯器(比如記事本)會(huì)在文件開頭增加三個(gè)不可見(jiàn)的標(biāo)志字節(jié),如果作為mysql的輸入文件,則必須要去掉這三個(gè)字符。(用linux的vi保存可以去掉這三個(gè)字符)。一個(gè)有趣的現(xiàn)象是,在中文windows下,創(chuàng)建一個(gè)新txt文件,用記事本打開,輸入"連通"兩個(gè)字,保存,再打開,你會(huì)發(fā)現(xiàn)兩個(gè)字沒(méi)了,只留下一個(gè)小黑點(diǎn)。?
6.2.?過(guò)濾器?
如果需要統(tǒng)一設(shè)置編碼,則通過(guò)filter進(jìn)行設(shè)置是個(gè)不錯(cuò)的選擇。在filter?class中,可以統(tǒng)一為需要的請(qǐng)求或者回應(yīng)設(shè)置編碼。參加上述setCharacterEncoding()。這個(gè)類apache已經(jīng)給出了可以直接使用的例子SetCharacterEncodingFilter。?
6.3.?POST和GET?
很明顯,以POST提交信息時(shí),URL有更好的可讀性,而且可以方便的使用setCharacterEncoding()來(lái)處理字符集問(wèn)題。但GET方法形成的URL能夠更容易表達(dá)網(wǎng)頁(yè)的實(shí)際內(nèi)容,也能夠用于收藏。?
從統(tǒng)一的角度考慮問(wèn)題,建議采用GET方法,這要求在程序中獲得參數(shù)是進(jìn)行特殊處理,而無(wú)法使用setCharacterEncoding()的便利,如果不考慮rewrite,就不存在IE的UTF-8問(wèn)題,可以考慮通過(guò)設(shè)置URIEncoding來(lái)方便獲取URL中的參數(shù)。?
6.4.?簡(jiǎn)繁體編碼轉(zhuǎn)換?
GBK同時(shí)包含簡(jiǎn)體和繁體編碼,也就是說(shuō)同一個(gè)字,由于編碼不同,在GBK編碼下屬于兩個(gè)字。有時(shí)候,為了正確取得完整的結(jié)果,應(yīng)該將繁體和簡(jiǎn)體進(jìn)行統(tǒng)一。可以考慮將UTF、GBK中的所有繁體字,轉(zhuǎn)換為相應(yīng)的簡(jiǎn)體字,BIG5編碼的數(shù)據(jù),也應(yīng)該轉(zhuǎn)化成相應(yīng)的簡(jiǎn)體字。當(dāng)然,仍舊以UTF編碼存儲(chǔ)。?
例如,對(duì)于"語(yǔ)言??言",用UTF表示為"\xE8\xAF\xAD\xE8\xA8\x80?\xE8\xAA\x9E\xE8\xA8\x80",進(jìn)行簡(jiǎn)繁體編碼轉(zhuǎn)換后應(yīng)該是兩個(gè)相同的?"\xE8\xAF\xAD\xE8\xA8\x80>"。?
?