DOM解析
在DOM接口規(guī)范中,有四個(gè)基本的接口:Document,Node,NodeList以及NamedNodeMap。在這四個(gè)基本接口中,Document接口是對(duì)文檔進(jìn)行操作的入口,它是從Node接口繼承過來(lái)的。Node接口是其他大多數(shù)接口的父類,象Document,Element,Attribute,Text,Comment等接口都是從Node接口繼承過來(lái)的。NodeList接口是一個(gè)節(jié)點(diǎn)的集合,它包含了某個(gè)節(jié)點(diǎn)中的所有子節(jié)點(diǎn)。NamedNodeMap接口也是一個(gè)節(jié)點(diǎn)的集合,通過該接口,可以建立節(jié)點(diǎn)名和節(jié)點(diǎn)之間的一一映射關(guān)系,從而利用節(jié)點(diǎn)名可以直接訪問特定的節(jié)點(diǎn)。
1.Document
Document接口代表了整個(gè)XML/HTML文檔,因此,它是整棵文檔樹的根,提供了對(duì)文檔中的數(shù)據(jù)進(jìn)行訪問和操作的入口。
2.NodeList
NodeList接口提供了對(duì)節(jié)點(diǎn)集合的抽象定義,它并不包含如何實(shí)現(xiàn)這個(gè)節(jié)點(diǎn)集的定義。NodeList用于表示有順序關(guān)系的一組節(jié)點(diǎn),比如某個(gè)節(jié)點(diǎn)的子節(jié)點(diǎn)序列。另外,它還出現(xiàn)在一些方法的返回值中,例如getElementsByTagName。
在DOM中,NodeList的對(duì)象是"live"的,換句話說(shuō),對(duì)文檔的改變,會(huì)直接反映到相關(guān)的NodeList對(duì)象中。例如,如果通過DOM獲得一個(gè)NodeList對(duì)象,該對(duì)象中包含了某個(gè)Element節(jié)點(diǎn)的所有子節(jié)點(diǎn)的集合,那么,當(dāng)再通過DOM對(duì)Element節(jié)點(diǎn)進(jìn)行操作(添加、刪除、改動(dòng)節(jié)點(diǎn)中的子節(jié)點(diǎn))時(shí),這些改變將會(huì)自動(dòng)地反映到NodeList對(duì)象中,而不需DOM應(yīng)用程序再做其他額外的操作。
NodeList中的每個(gè)item都可以通過一個(gè)索引來(lái)訪問,該索引值從0開始。
3.NamedNodeMap
實(shí)現(xiàn)了NamedNodeMap接口的對(duì)象中包含了可以通過名字來(lái)訪問的一組節(jié)點(diǎn)的集合。不過注意,NamedNodeMap并不是從NodeList繼承過來(lái)的,它所包含的節(jié)點(diǎn)集中的節(jié)點(diǎn)是無(wú)序的。盡管這些節(jié)點(diǎn)也可以通過索引來(lái)進(jìn)行訪問,但這只是提供了枚舉NamedNodeMap中所包含節(jié)點(diǎn)的一種簡(jiǎn)單方法,并不表明在DOM規(guī)范中為NamedNodeMap中的節(jié)點(diǎn)規(guī)定了一種排列順序。
NamedNodeMap表示的是一組節(jié)點(diǎn)和其唯一名字的一一對(duì)應(yīng)關(guān)系,這個(gè)接口主要用在屬性節(jié)點(diǎn)的表示上。 與NodeList相同,在DOM中,NamedNodeMap對(duì)象也是"live"的。
4.Dom對(duì)象
一切都是節(jié)點(diǎn)(對(duì)象)
.Node對(duì)象:DOM結(jié)構(gòu)中最為基本的對(duì)象
?Document對(duì)象:代表整個(gè)XML的文檔
?NodeList對(duì)象:包含一個(gè)或者多個(gè)Node的列表
?Element對(duì)象:代表XML文檔中的標(biāo)簽元素
5.dom解析xml步驟

import javax.xml.parsers.*;
import org.w3c.dom.*;
public class dom {
public static void main(String args[]){
try{
//建立解析器工廠
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
//獲得解析器
DocumentBuilder builder=factory.newDocumentBuilder();
Document doc=builder.parse("candidate.xml");
NodeList nl =doc.getElementsByTagName("PERSON");
for (int i=0;i<nl.getLength();i++){
Element node=(Element) nl.item(i);
System.out.print("NAME: ");
System.out.println (node.getElementsByTagName("NAME").item(0).getFirstChild().getNodeValue());
……
System.out.println();
}
}catch(Exception e){e.printStackTrace();}
}
}
程序詳解:
1)DocumentBuilderFactory dbf=DocumentBuilderFactory.newInstance();
?我們?cè)谶@里使用DocumentBuilderFacotry的目的是為了創(chuàng)建與具體解析器無(wú)關(guān)的程序,當(dāng)DocumentBuilderFactory 類的靜態(tài)方法newInstance()被調(diào)用時(shí),它根據(jù)一個(gè)系統(tǒng)變量來(lái)決定具體使用哪一個(gè)解析器。又因?yàn)樗械慕馕銎鞫挤挠贘AXP所定義的接口,所 以無(wú)論具體使用哪一個(gè)解析器,代碼都是一樣的。所以當(dāng)在不同的解析器之間進(jìn)行切換時(shí),只需要更改系統(tǒng)變量的值,而不用更改任何代碼。這就是工廠所帶來(lái)的好處。
2)?DocumentBuilder db = dbf.newDocumentBuilder();
?當(dāng)獲得一個(gè)工廠對(duì)象后,使用它的靜態(tài)方法newDocumentBuilder()方法可以獲得一個(gè)DocumentBuilder對(duì)象,這個(gè)對(duì)象代表了具體的DOM解析器。但具體是哪一種解析器,微軟的或者IBM的,對(duì)于程序而言并不重要
3)然后,我們就可以利用這個(gè)解析器來(lái)對(duì)XML文檔進(jìn)行解析了
?Document doc = db.parse("c:/xml/message.xml");
?DocumentBuilder的parse()方法接受一個(gè)XML文檔名作為輸入?yún)?shù),返回一個(gè)Document對(duì)象,這個(gè)Document對(duì)象就代表了一個(gè)XML文檔的樹模型。以后所有的對(duì)XML文檔的操作,都與解析器無(wú)關(guān),直接在這個(gè)Document對(duì)象上進(jìn)行操作就可以了。而具體對(duì)Document操作的方法,就是由DOM所定義的了
4).從上面得到的Document對(duì)象開始,我們就可以開始我們的DOM解析了。使用Document對(duì)象的getElementsByTagName()方法,我們可以得到一個(gè)NodeList對(duì)象,一個(gè)Node對(duì)象代表了一個(gè)XML文檔中的一個(gè)標(biāo)簽元素,而NodeList對(duì)象,所代表的是一個(gè)Node對(duì)象的列表
NodeList nl = doc.getElementsByTagName("message"); ?我們通過這樣一條語(yǔ)句所得到的是XML文檔中所有<message>標(biāo)簽對(duì)應(yīng)的Node對(duì)象的一個(gè)列表。然后,我們可以使用NodeList對(duì)象的item()方法來(lái)得到列表中的每一個(gè)Node對(duì)象
?Node my_node = nl.item(0);
5).當(dāng)一個(gè)Node對(duì)象被建立之后,保存在XML文檔中的數(shù)據(jù)就被提取出來(lái)并封裝在這個(gè)Node中了。在這個(gè)例子中,要提取Message標(biāo)簽內(nèi)的內(nèi)容,我們通常會(huì)使用Node對(duì)象的getNodeValue()方法
?Stringmessage
=my_node.getFirstChild().getNodeValue();
注意:請(qǐng)注意,這里還使用了一個(gè)getFirstChild()方法來(lái)獲得message下面的第一個(gè)子Node對(duì)象。雖然在message標(biāo)簽下面除了文本外并沒有其它子標(biāo)簽或者屬性,但是我們堅(jiān)持在這里使用getFirstChild()方法,這主要和W3C對(duì)DOM的定義有關(guān)。W3C把標(biāo)簽內(nèi)的文本部分也定義成一個(gè)Node,所以先要得到代表文本的那個(gè)Node,我們才能夠使用getNodeValue()來(lái)獲取文本的內(nèi)容
6.dom基本對(duì)象詳解
DOM的基本對(duì)象有5個(gè):Document,Node,NodeList,Element和Attr
Document對(duì)象代表了整個(gè)XML的文檔,所有其它的Node,都以一定的順序包含在Document對(duì)象之內(nèi),排列成一個(gè)樹形的結(jié)構(gòu),程序員可以通過遍歷這顆樹來(lái)得到XML文檔的所有的內(nèi)容,這也是對(duì)XML文檔操作的起點(diǎn)。我們總是先通過解析XML源文件而得到一個(gè)Document對(duì)象,然后再來(lái)執(zhí)行后續(xù)的操作。此外,Document還包含了創(chuàng)建其它節(jié)點(diǎn)的方法,比如createAttribute()用來(lái)創(chuàng)建一個(gè)Attr對(duì)象。它所包含的主要的方法有
1).createAttribute(String):用給定的屬性名創(chuàng)建一個(gè)Attr對(duì)象,并可在其后使用setAttributeNode方法來(lái)放置在某一個(gè)Element對(duì)象上面。
?2)createElement(String):用給定的標(biāo)簽名創(chuàng)建一個(gè)Element對(duì)象,代表XML文檔中的一個(gè)標(biāo)簽,然后就可以在這個(gè)Element對(duì)象上添加屬性或進(jìn)行其它的操作。
?3)createTextNode(String):用給定的字符串創(chuàng)建一個(gè)Text對(duì)象,Text對(duì)象代表了標(biāo)簽或者屬性中所包含的純文本字符串。如果在一個(gè)標(biāo)簽內(nèi)沒有其它的標(biāo)簽,那么標(biāo)簽內(nèi)的文本所代表的Text對(duì)象是這個(gè)Element對(duì)象的唯一子對(duì)象。
4)getElementsByTagName(String):返回一個(gè)NodeList對(duì)象,它包含了所有給定標(biāo)簽名字的標(biāo)簽。
5)getDocumentElement():返回一個(gè)代表這個(gè)DOM樹的根元素節(jié)點(diǎn)的Element對(duì)象,也就是代表XML文檔根元素的那個(gè)對(duì)象。
7.Node對(duì)象所包含的主要的方法有
?appendChild(org.w3c.dom.Node):為這個(gè)節(jié)點(diǎn)添加一個(gè)子節(jié)點(diǎn),并放在所有子節(jié)點(diǎn)的最后,如果這個(gè)子節(jié)點(diǎn)已經(jīng)存在,則先把它刪掉再添加進(jìn)去。
?getFirstChild():如果節(jié)點(diǎn)存在子節(jié)點(diǎn),則返回第一個(gè)子節(jié)點(diǎn),對(duì)等的,還有g(shù)etLastChild()方法返回最后一個(gè)子節(jié)點(diǎn)。
?getNextSibling():返回在DOM樹中這個(gè)節(jié)點(diǎn)的下一個(gè)兄弟節(jié)點(diǎn),對(duì)等的,還有g(shù)etPreviousSibling()方法返回其前一個(gè)兄弟節(jié)點(diǎn)。
?getNodeName():根據(jù)節(jié)點(diǎn)的類型返回節(jié)點(diǎn)的名稱。
?getNodeType():返回節(jié)點(diǎn)的類型
.getNodeValue():返回節(jié)點(diǎn)的值。
?hasChildNodes():判斷是不是存在有子節(jié)點(diǎn)。
?hasAttributes():判斷這個(gè)節(jié)點(diǎn)是否存在有屬性。
?getOwnerDocument():返回節(jié)點(diǎn)所處的Document對(duì)象。
?insertBefore(org.w3c.dom.Node new,org.w3c.dom.Node ref):在給定的一個(gè)子對(duì)象前再插入一個(gè)子對(duì)象。
?removeChild(org.w3c.dom.Node):刪除給定的子節(jié)點(diǎn)對(duì)象
.replaceChild(org.w3c.dom.Node new,org.w3c.dom.Node old):用一個(gè)新的Node對(duì)象代替給定的子節(jié)點(diǎn)對(duì)象。
?NodeList對(duì)象,顧名思義,就是代表了一個(gè)包含了一個(gè)或者多個(gè)Node的列表。可以簡(jiǎn)單的把它看成一個(gè)Node的數(shù)組,我們可以通過方法來(lái)獲得列表中的元素:
?getLength():返回列表的長(zhǎng)度。
?item(int):返回指定位置的Node對(duì)象
8 Element對(duì)象代表的是XML文檔中的標(biāo)簽元素,繼承于Node,亦是Node的最主要的子對(duì)象。在標(biāo)簽中可以包含有屬性,因而Element對(duì)象中有存取其屬性的方法,而任何Node中定義的方法,也可以用在Element對(duì)象上面。
?getElementsByTagName(String):返回一個(gè)NodeList對(duì)象,它包含了在這個(gè)標(biāo)簽中其下的子孫節(jié)點(diǎn)中具有給定標(biāo)簽名字的標(biāo)簽。
?getTagName():返回一個(gè)代表這個(gè)標(biāo)簽名字的字符串。
?getAttribute(String):返回標(biāo)簽中給定屬性名稱的屬性的值。在這兒需要注意的是,因?yàn)閄ML文檔中允許有實(shí)體屬性出現(xiàn),而這個(gè)方法對(duì)這些實(shí)體屬性并不適用。這時(shí)候需要用到getAttributeNode()方法來(lái)得到一個(gè)Attr對(duì)象來(lái)進(jìn)行進(jìn)一步的操作
?getAttributeNode(String):返回一個(gè)代表給定屬性名稱的Attr對(duì)象。
9.Attr對(duì)象代表了某個(gè)標(biāo)簽中的屬性。Attr繼承于Node,但是因?yàn)锳ttr實(shí)際上是包含在Element中的,它并不能被看作是Element的子對(duì)象,因而在DOM中Attr并不是DOM樹的一部分,所以Node中的getparentNode(),getpreviousSibling()和getnextSibling()返回的都將是null。也就是說(shuō),Attr其實(shí)是被看作包含它的Element對(duì)象的一部分,它并不作為DOM樹中單獨(dú)的一個(gè)節(jié)點(diǎn)出現(xiàn)。這一點(diǎn)在使用的時(shí)候要同其它的Node子對(duì)象相區(qū)別
SAX解析
SAX的全稱是Simple APIs for XML,SAX提供的訪問模式是一種順序模式,這是一種快速讀寫XML數(shù)據(jù)的方式。當(dāng)使用SAX分析器對(duì)XML文檔進(jìn)行分析時(shí),會(huì)觸發(fā)一系列事件,并激活相應(yīng)的事件處理函數(shù),應(yīng)用程序通過這些事件處理函數(shù)實(shí)現(xiàn)對(duì)XML文檔的訪問,因而SAX接口也被稱作事件驅(qū)動(dòng)接口。由于SAX分析器實(shí)現(xiàn)簡(jiǎn)單,對(duì)內(nèi)存要求比較低,因此實(shí)現(xiàn)效率比較高,對(duì)于那些只需要訪問XML文檔中的數(shù)據(jù)而不對(duì)文檔進(jìn)行更改的應(yīng)用程序來(lái)說(shuō),SAX分析器更為合適。
SAX(Simple APIs for XML),面向XML的簡(jiǎn)單APIs。使用DOM解析XML時(shí),首先將XML文檔加載到內(nèi)存當(dāng)中,然后可以通過隨機(jī)的方式訪問內(nèi)存中的DOM樹;SAX是基于事件而且是順序執(zhí)行的,一旦經(jīng)過了某個(gè)元素,我們就沒有辦法再去訪問它了,SAX不必事先將整個(gè)XML文檔加載到內(nèi)存當(dāng)中,因此它占據(jù)內(nèi)存要比DOM小,對(duì)于大型的XML文檔來(lái)說(shuō),通常會(huì)使用SAX而不是DOM進(jìn)行解析。
SAX也是使用的觀察者模式(類似于GUI中的事件)
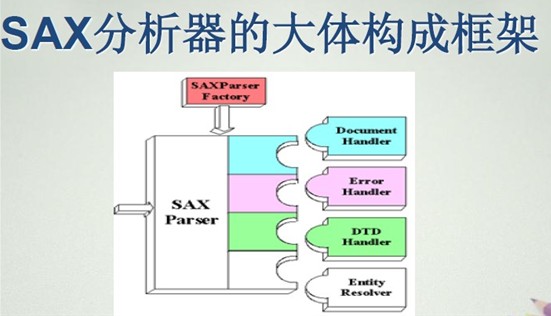
圖中最上方的SAXParserFactory用來(lái)生成一個(gè)分析器實(shí)例。XML文檔是從左側(cè)箭頭所示處讀入,當(dāng)分析器對(duì)文檔進(jìn)行分析時(shí),就會(huì)觸發(fā)在DocumentHandler,ErrorHandler,DTDHandler以及EntityResolver接口中定義的回調(diào)方法。
4.SAX是事件驅(qū)動(dòng)的,文檔的讀入過程就是SAX的解析過程。在讀入的過程中,遇到不同的項(xiàng)目,解析器會(huì)調(diào)用不同的處理方法。
5.org.xml.sax.helpers.DefaultHandler類的方法
|
項(xiàng)目
|
處理方法
|
|
文檔開始
|
startDocument()
|
|
<PEOPLE>
|
startElement()
|
|
“Tony Blair”
|
characters()
|
|
</PEOPLE>
|
endElement()
|
|
文檔結(jié)束
|
endDocument()
|
6.SAX方式提取XML文檔內(nèi)容信息示例
package com.shengsiyuan.xml.sax;
import java.io.File;
import java.util.Stack;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class SaxTest2
{
public static void main(String[] args) throws Exception
{
//step1: 獲得SAX解析器工廠實(shí)例
SAXParserFactory factory = SAXParserFactory.newInstance();
//step2: 獲得SAX解析器實(shí)例
SAXParser parser = factory.newSAXParser();
//step3: 開始進(jìn)行解析
parser.parse(new File("student.xml"), new MyHandler2());
}
}
class MyHandler2 extends DefaultHandler
{
private Stack<String> stack = new Stack<String>();
private String name;
private String gender;
private String age;
@Override
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException
{
stack.push(qName);
for(int i = 0; i < attributes.getLength(); i++)
{
String attrName = attributes.getQName(i);
String attrValue = attributes.getValue(i);
System.out.println(attrName + "=" + attrValue);
}
}
@Override
public void characters(char[] ch, int start, int length)
throws SAXException
{
String tag = stack.peek();
if("姓名".equals(tag))
{
name = new String(ch, start,length);
}
else if("性別".equals(tag))
{
gender = new String(ch, start, length);
}
else if("年齡".equals(tag))
{
age = new String(ch, start, length);
}
}
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException
{
stack.pop(); //表示該元素已經(jīng)解析完畢,需要從棧中彈出
if("學(xué)生".equals(qName))
{
System.out.println("姓名:" + name);
System.out.println("性別:" + gender);
System.out.println("年齡:" + age);
System.out.println();
}
}
}