v\:* {behavior:url(#default#VML);} o\:* {behavior:url(#default#VML);} w\:* {behavior:url(#default#VML);} .shape {behavior:url(#default#VML);}
細節優化提升資源利用率
Author: 放翁(文初)
Email: fangweng@taobao.com
Mblog:weibo.com/fangweng
這里通過介紹對于淘寶開放平臺基礎設置之一的TOPAnalyzer的代碼優化,來談一下對于海量數據處理的Java應用可以共享的一些細節設計(一個系統能夠承受的處理量級別往往取決于細節,一個系統能夠支持的業務形態往往取決于設計目標)。
先介紹一下整個TOPAnalyzer的背景,目標和初始設計,為后面的演變做一點鋪墊。
開放平臺從內部開放到正式對外開放,逐步從每天幾千萬的服務調用量發展到了上億到現在的15億,開放的服務也從幾十個到了幾百個,應用接入從幾百個增加到了幾十萬個。此時,對于原始服務訪問數據的分析需求就凸現出來:
<!--[if !supportLists]-->1. <!--[endif]-->應用維度分析(應用的正常業務調用行為和異常調用行為分析)
<!--[if !supportLists]-->2. <!--[endif]-->服務維度分析(服務RT,總量,成功失敗率,業務錯誤及子錯誤等)
<!--[if !supportLists]-->3. <!--[endif]-->平臺維度分析(平臺消耗時間,平臺授權等業務統計分析,平臺錯誤分析,平臺系統健康指標分析等)
<!--[if !supportLists]-->4. <!--[endif]-->業務維度分析(用戶,應用,服務之間關系分析,應用歸類分析,服務歸類分析等)
上面只是一部分,從上面的需求來看需要一個系統能夠靈活的運行期配置分析策略,對海量數據作即時分析,將接過用于告警,監控,業務分析。
下圖是最原始的設計圖,很簡單,但還是有些想法在里面:
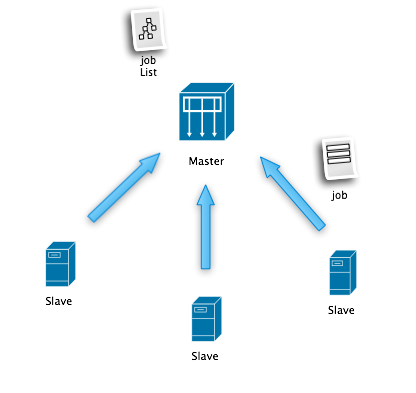
Master:管理任務(分析任務),合并結果(Reduce),輸出結果(全量統計,增量片段統計)
Slave:Require Job + Do Job + Return Result,隨意加入,退出集群。
Job:(Input + Analysis Rule + Output)的定義。
幾個設計點:
<!--[if !supportLists]-->1. <!--[endif]-->后臺系統任務分配:無負載分配算法,采用細化任務+工作者按需自取+粗暴簡單任務重置策略。
<!--[if !supportLists]-->2. <!--[endif]-->Slave與Master采用單向通信,便于容量擴充和縮減。
<!--[if !supportLists]-->3. <!--[endif]-->Job自描述性,從任務數據來源,分析規則,結果輸出都定義在任務中,使得Slave適用與各種分析任務,一個集群分析多種日志,多個集群共享Slave。
<!--[if !supportLists]-->4. <!--[endif]-->數據存儲無業務性(意味著存儲的時候不定義任何業務含義),分析規則包含業務含義(在執行分析的時候告知不同列是什么含義,怎么統計和計算),優勢在于可擴展,劣勢在于全量掃描日志(無預先索引定義)。
<!--[if !supportLists]-->5. <!--[endif]-->透明化整個集群運行狀況,保證簡單粗暴的方式下能夠快速定位出節點問題或者任務問題。(雖然沒有心跳,但是每個節點的工作都會輸出信息,通過外部收集方式快速定位問題,防止集群為了監控耦合不利于擴展)
<!--[if !supportLists]-->6. <!--[endif]-->Master單點采用冷備方式解決。單點不可怕,可怕的是丟失現場和重啟或重選Master周期長。因此采用分析數據和任務信息簡單周期性外部存儲的方式將現場保存與外部(信息盡量少,保證恢復時快速),另一方面采用外部系統通知方式修改Slave集群MasterIP,人工快速切換到冷備。
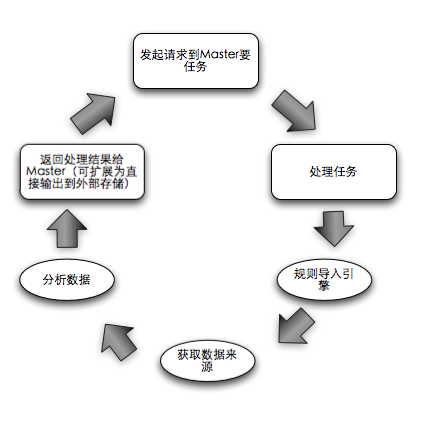
Master的生活軌跡:

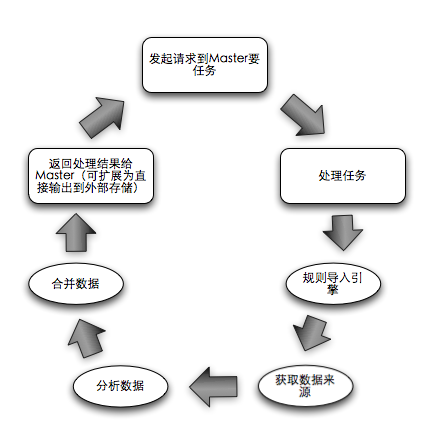
Slave的生活軌跡:
有人會覺得這玩意兒簡單,系統就是簡單+透明才會高效,往往就是因為系統復雜才會帶來更多看似很高深的設計,最終無非是折騰了自己,苦了一線。廢話不多說,背景介紹完了,開始講具體的演變過程。
數據量:2千萬 à 1億 à 8億 à15億。報表輸出結果:10份配置à30份à60份à100份。統計后的數據量:10k à 10M à 9G。統計周期的要求:1天à5分鐘à3分鐘à1分半。
從上面這些數據可以知道從網絡和磁盤IO,到內存,到CPU都會經歷很大的考驗,由于Master是縱向擴展的,因此優化Master成為每個數據跳動的必然要求。由于是用Java寫的,因此內存對于整體分析的影響更加嚴重,GC的停頓直接可以使得系統掛掉(因為數據在不斷流入內存)。
優化過程:
縱向系統的工作的分擔:
從Master的生活軌跡可以看到,它負荷最大的一步就是要去負責Reduce,無論如何都需要交給一個單節點來完成所有的Reduce,但并不表示對于多個Slave的所有的Reduce都需要Master來做。有同學給過建議說讓Master再去分配給不同的Slave去做Slave之間的Reduce,但一旦引入Master對Slave的通信和管理,這就回到了復雜的老路。因此這里用最簡單的方式,一個機器可以部署多個Slave,一個Slave可以一次獲取多個Job,執行完畢后本地合并再匯報給Master。(優勢:Master在Job合并所產生的內存消耗可以減輕,因為這是統計,所以合并后數據量一定大幅下降,此時Master合并越少的Job數量,內存消耗越小),因此Slave的生活軌跡變化了一點:
流程中間數據優化:
這里舉兩個例子來說明對于處理中中間數據優化的意義。
在統計分析中往往會有對分析后的數據做再次處理的需求,例如一個API報表里面會有API訪問總量,API訪問成功數,同時會要有API的成功率,這個數據最早設計的時候和普通的MapReduce字段一樣處理,計算和存儲在每一行數據分析的時候都做,但其實這類數據只有在最后輸出的時候才有統計和存儲價值,因為這些數據都可以通過已有數據計算得到,而中間反復做計算在存儲和計算上都是一種浪費,因此對于這種特殊的Lazy處理字段,中間不計算也不存儲,在周期輸出時做一次分析,降低了計算和存儲的壓力。
對于MapReduce中的Key存儲的壓縮。由于很多統計的Key是很多業務數據的組合,例如APPAPIUser的統計報表,它的Key就是三個字段的串聯:taobao.user.get—12132342—fangweng,這時候大量的Key會占用內存,而Key的目的就是產生這個業務統計中的唯一標識,因此考慮這些API的名稱等等是否可以替換成唯一的短內容就可以減少內存占用。過程中就不多說了,最后在分析器里面實現了兩種策略:
<!--[if !supportLists]-->1. <!--[endif]-->不可逆數字摘要采樣。
有點類似與短連接轉換的方式,對數據做Md5數字摘要,獲得16個byte,然后根據壓縮配置來采樣16個byte部分,用可見字符定義出64進制來標識這些采樣,最后形成較短的字符串。
由于Slave是數據分析者,因此用Slave的CPU來換Master的內存,將中間結果用不可逆的短字符串方式表示。弱點:當最后分析出來的數據量越大,采樣md5后的數據越少,越容易產生沖突,導致統計不準確。
<!--[if !supportLists]-->2. <!--[endif]-->提供需要壓縮的業務數據列表。
業務方提供日志中需要替換的列定義及一組定義內容。簡單來說,當日志某一列可以被枚舉,那么就意味者這一列可以被簡單的替換成短標識。例如配置APIName這列在分析生成key的時候可以被替換,并且提供了500多個api的名稱文件載入到內存中,那么每次api在生成key的時候就會被替換掉名稱組合在key中,大大縮短key。那為什么要提供這些api的名稱呢?首先分析生成key在Slave,是分布式的,如果采用自學習的模式,勢必要引入集中式唯一索引生成器,其次還要做好足夠的并發控制,另一方面也會由并發控制帶來性能損耗。這種模式雖然很原始,但不會影響統計結果的準確性,因此在分析器中被使用,這個列表會隨著任務規則每次發送到Slave中,保證所有節點分析結果的一致性。
特殊化處理特殊的流程:
在Master的生活軌跡中可以看出,影響一輪輸出時間和內存使用的包括分析合并數據結果,導出報表和導出中間結果。在數據上升到1億的時候,Slave和Master之間數據通信以及Master的中間結果磁盤化的過程中都采用了壓縮的方式來減少數據交互對IO緩沖的影響,但一直考慮是否還可以再壓榨一點。首先導出中間結果的時候最初采用簡單的Object序列化導出,從內存使用,外部數據大小,輸出時間上來說都有不少的消耗,仔細看了一下中間結果是Map<String,Map<String,Obj>>,其實最后一個Obj無非只有兩種類型Double和String,既然這樣,序列化完全可以簡單來作,因此直接很簡單的實現了類似Json簡化版的序列化,從序列化速度,內存占用減少上,外部磁盤存儲都有了極大的提高,外部磁盤存儲越小,所消耗的IO和過程中需要的臨時內存都會下降,序列化速度加快,那么內存中的數據就會被盡快釋放。總體上來說就是特殊化處理了可以特殊化對待的流程,提高了資源利用率。(同時中間結果在前期優化階段的作用就是為了備份,因此不需要每個周期都做,當時做成可配置的周期值輸出)
再接著來談一下中間結果合并時候對于內存使用的優化。Master會從多個Slave得到多個Map<Key,Map<Key,Value>>,合并過程就是對多個Map將第一級Key相同的數據做整合,例如第一級Key的一個值是API訪問總量,那么它對應的Map中就是不同的api名稱和總量的統計,而多個Map直接合并就是將一級key(API訪問總量)下的Map數據合并起來(同樣的api總量相加最后保存一份)。最簡單的做法就是多個Map<Key,Map<Key,Value>>遞歸的來合并,但如果要節省內存和計算可以有兩個小改進,首先選擇其中一個作為最終的結果集合(避免申請新空間,也避免輪詢這個Map的數據),其次每一次遞歸時候,將合并后的后面的Map中數據移出(減少后續無用的循環對比,同時也節省空間)。看似小改動,但效果很不錯。
再談一下在輸出結果時候的內存節省。在輸出結果的時候,是基于內存中一份Map<Key,Map<Key,Value>>來構建的。其實將傳統的MapReduce的KV結果如何轉換成為傳統的Report,只需要看看Sql中的Group設計,將多個KV通過Group by key,就可以得到傳統意義上的Key,Value,Value,Value。例如:KV可以是<apiName,apiTotalCount>,<apiName,apiResponse>,<apiName,apiFailCount>,如果Group by apiName,那么就可以得到 apiName,apiTotalCount,apiResponse,apiFailCount的報表行結果。這種歸總的方式可以類似填字游戲,因為我們結果是KV,所以這個填字游戲默認從列開始填寫,遍歷所有的KV以后就可以完整的得到一個大的矩陣并按照行輸出,但代價是KV沒有遍歷完成以前,無法輸出。因此考慮是否可以按照行來填寫,然后每一行填寫完畢之后直接輸出,節省申請內存。按行填寫最大的問題就是如何在對KV中已經處理過的數據打上標識,不要重復處理。(一種方式引入外部存儲來標識這個值已經被處理過,因為這些KV不可以類似合并的時候刪除,后續還會繼續要用,另一種方式就是完全備份一份數據,合并完成后就刪除),但本來就是為了節約內存的,引入更多的存儲,就和目標有悖了。因此做了一個計算換存儲的做法,例如填充時輪訓的順序為:K1V1,K2V2,K3V3,到K2V2遍歷的時候,判斷是否要處理當前這個數據,就只要判斷這個K是否在K1里面出現過,而到K3V3遍歷的時候,判斷是否要處理,就輪詢K1K2是否存在這個K,由于都是Map結構,因此這種查找的消耗很小,由此改為行填寫,逐行輸出。
最后再談一下最重頭的優化,合并調度及磁盤內存互換的優化
從Master的生活軌跡可以看到,原來的主線程負責檢查外部分析數據結果狀態,合并數據結果這個循環,考慮到最終合并后數據只有一個主干,因此采用單線程合并模式來運作,見下圖:
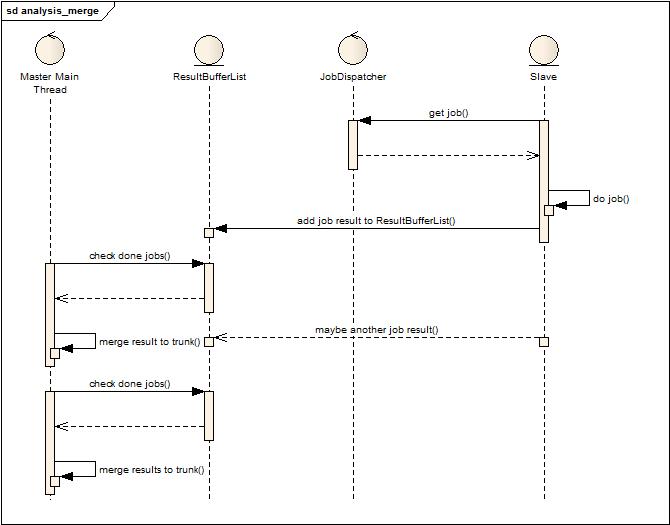
這張圖大致描述了一下處理流程,Slave隨時都會將分析后的結果掛到結果緩沖隊列上,然后主線程負責批量獲取結果并且合并。雖然是批量獲取,但是為了節省內存,也不能等待太久,因為每一點等待就意味著大量沒有合并的數據將會存在與內存中,但合并的太頻繁也會導致在合并過程中,新加入的結果會等待很久,導致內存吃緊。或許這個時候會考慮,為什么不直接用多線程來合并,的確,多線程合并并非不可行,但要考慮如何兼顧到主干合并的并發控制,因為多個線程不可能同時都合并到數據主干上,由此引入了下面的設計實現,半并行模式的合并:
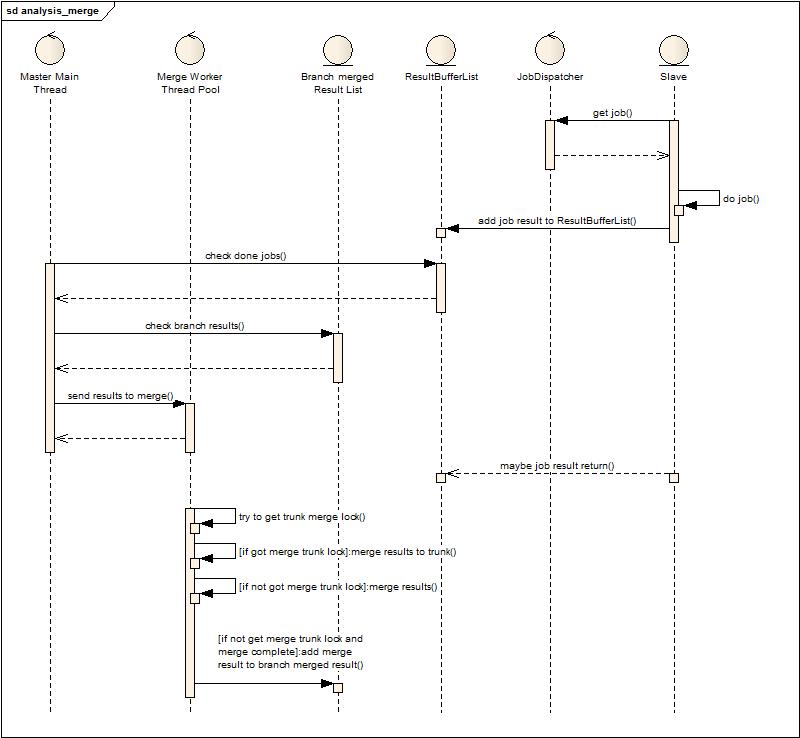
從上圖可以發現增加了兩個角色:Merge Worker Thread Pool和Branch merged ResultList,與上面設計的差別就在于主線程不再負責合并數據,而是批量的獲取數據交給合并線程池來合并,而合并線程池中的工作者在合并的過程中會競爭主干合并鎖,成功獲得的就和主干合并,不成功的就將結果合并后放到分支合并隊列上,等待下次合并時被主干合并或者分支合并獲得再次合并。這樣改進后,發現由于數據掛在隊列沒有得到及時處理產生的內存壓力大大下降,同時也充分利用了多核,多線程榨干了多核的計算能力(線程池大小根據cpu核來設置的小一點,預留一點給GC用)。這種設計中還多了一些小的調優配置,例如是否允許被合并過的數據多次被再次合并(防止無畏的計算消耗),每次并行合并最小結果數是多少,等待堆積到最小結果數的最大時間等等。(有興趣看代碼)
至上面的優化為止,感覺合并這塊已經被榨干了,但分析日志數據的增多,對及時性要求的加強,使得我又要重新審視是否還有能力繼續榨出這個流程的水份。因此有了一個大膽的想法,磁盤換內存。因為在調度合并上已經找不到更多可以優化的點了,但是有一點還可以考慮,就是主干的那點數據是否要貫穿于整個合并周期,而且主干的數據隨著增量分析不斷增大(在最近這次優化的過程中也就是發現GC的頻繁導致合并速度下降,合并速度下降導致內存中臨時數據保存的時間久,反過來又影響GC,最后變成了惡性循環)。盡管覺得靠譜,但不測試不得而知。于是得到了以下的設計和實現:
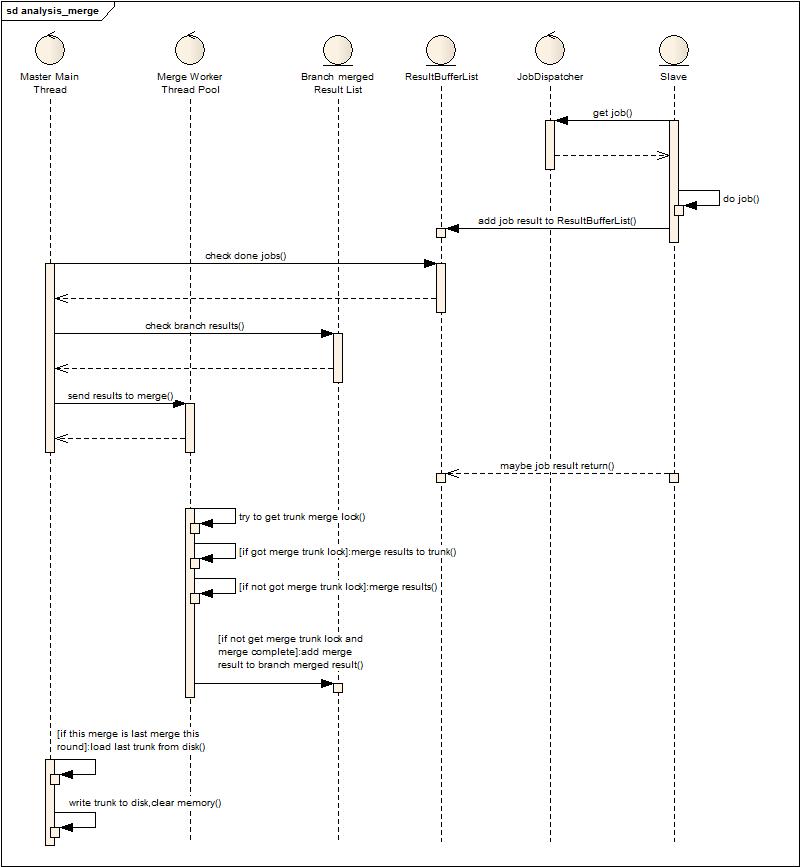
這個流程發現和第二個流程就多了最后兩個步驟,判斷是否是最后的一次合并,如果是載入磁盤數據,然后合并,合并完后將主干輸出到磁盤,清空主干內存。(此時發現導出中間結果原來不是每次必須的,但是這種模式下卻成為每次必須的了)
這個改動的優勢在什么地方?例如一個分析周期是2分鐘,那么在2分鐘內,主干龐大的數據被外置到磁盤,內存大量空閑,極大提高了當前時間片結果合并的效率(GC少了)。缺點是什么?會在每個周期產生兩次磁盤大量的讀寫,但配合上優化過的中間結果載入載出(前面的私有序列化)會適當緩和。
由于線下無法模擬,就嘗試著線上測試,發現GC減少,合并過程加速達到預期,但是每輪的磁盤和內存的換入換出由于也記入在一輪分析時間之內,每輪寫出最大時候70m數據,需要消耗10多秒,甚至20秒,讀入最大需要10s,這個時間如果算在要求一輪兩分鐘內,那也是不可接受的),重新審視是否有疏漏的細節。首先載入是否可以異步,如果可以異步,而不是在最后一輪才載入,那么就不會納入到分析周期中,因此配置了一個可以調整的比例值,當任務完成到達或者超過這個比例值的時候,將開始并行載入數據,最后一輪等到異步載入后開始分析,發現果然可行,因此這個時間被排除在周期之外(雖然也帶來了一點內存消耗)。然后再考慮輸出是否可以異步,以前輸出不可以異步的原因是這份數據是下一輪分析的主干,如果異步輸出,下一輪數據開始處理,很難保證下一輪的第一個任務是否會引發數據修改,導致并發問題,所以一直鎖定主干輸出,直到完成再開始,但現在每次合并都是空主干開始的,因此輸出完全可以異步,主干可以立刻清空,進入下一輪合并,只要在下一個周期開始載入主干前異步導出主干完成即可,這個時間是很長的,完全可以把控,因此輸出也可以變成異步,不納入分析周期。
至此完成了所有的優化,分析器高峰期的指標發生了改變:一輪分析從2分鐘左右降低到了1分10秒,JVM的O區在合并過程中從50-80的占用率下降到20-60的占用率,GC次數明顯大幅減少。
總結:
<!--[if !supportLists]-->1. <!--[endif]-->利用可橫向擴展的系統來分擔縱向擴展系統的工作。
<!--[if !supportLists]-->2. <!--[endif]-->流程中中間數據的優化處理。
<!--[if !supportLists]-->3. <!--[endif]-->特殊化處理可以特殊處理的流程。
<!--[if !supportLists]-->4. <!--[endif]-->從整體流程上考慮不同策略的消耗,提高整體處理能力。
<!--[if !supportLists]-->5. <!--[endif]-->資源的快用快放,提高同一類資源利用率。
<!--[if !supportLists]-->6. <!--[endif]-->不同階段不同資源的互換,提高不同資源的利用率。
其實很多細節也許看了代碼才會有更深的體會,分析器只是一個典型的消耗性案例,每一點改進都是在數據和業務驅動下不斷的考驗。例如縱向的Master也許真的有一天就到了它的極限,那么就交給Slave將數據產出到外部存儲,交由其他系統或者另一個分析集群去做二次分析。對于海量數據的處理來說都需要經歷初次篩選,再次分析,展示關聯幾個階段,Java的應用擺脫不了內存約束帶來對計算的影響,因此就要考慮好自己的頂在什么地方。但優化一定是全局的,例如磁盤換內存,磁盤帶來的消耗在總體上來說還是可以接受的化,那么就可以被采納(當然如果用上SSD效果估計會更好)。
最后還是想說的是,很多事情是簡單做到復雜,復雜再回歸到簡單,對系統提出的挑戰就是如何能夠用最直接的方式簡單的搞定,而不是做一個臃腫依賴龐大的系統,簡單才看的清楚,看的清楚才有機會不斷改進。
@import url(http://m.tkk7.com/CuteSoft_Client/CuteEditor/Load.ashx?type=style&file=SyntaxHighlighter.css);@import url(/css/cuteeditor.css);
java反射機制的實現原理
反射機制:
所謂的反射機制就是java語言在運行時擁有一項自觀的能力。
通過這種能力可以徹底的了解自身的情況為下一步的動作做準備。
下面具體介紹一下java的反射機制。這里你將顛覆原來對java的理解。
Java的反射機制的實現要借助于4個類:class,Constructor,Field,Method;
其中class代表的時類對象,
Constructor-類的構造器對象,
Field-類的屬性對象,
Method-類的方法對象。
通過這四個對象我們可以粗略的看到一個類的各個組 成部分。
Class:程序運行時,java運行時系統會對所有的對象進行運行時類型的處理。
這項信息記錄了每個對象所屬的類,虛擬機通常使用運行時類型信息選擇正 確的方法來執行(摘自:白皮書)。
但是這些信息我們怎么得到啊,就要借助于class類對象了啊。
在Object類中定義了getClass()方法。我 們可以通過這個方法獲得指定對象的類對象。然后我們通過分析這個對象就可以得到我們要的信息了。
比如:ArrayList arrayList;
Class clazz = arrayList.getClass();
然后我來處理這個對象clazz。
當然了Class類具有很多的方法,這里重點將和Constructor,Field,Method類有關系的方法。
Reflection 是 Java 程序開發語言的特征之一,它允許運行中的 Java 程序對自身進行檢查,或者說“自審”,并能直接操作程序的內部屬性。Java 的這一能力在實際應用中也許用得不是很多,但是個人認為要想對java有個更加深入的了解還是應該掌握的。
1.檢測類:
reflection的工作機制
考慮下面這個簡單的例子,讓我們看看 reflection 是如何工作的。
import java.lang.reflect.*;
public class DumpMethods {
public static void main(String args[]) {
try {
//forName("java.lang.String")獲取指定的類的對象
Class c = Class.forName("java.lang.String");
Method m[] = c.getDeclaredMethods();
for (int i = 0; i < m.length; i++)
System.out.println(m[i].toString());
} catch (Throwable e) {
System.err.println(e);
}
}
}
按如下語句執行:
java DumpMethods java.util.ArrayList
這個程序使用 Class.forName 載入指定的類,然后調用 getDeclaredMethods 來獲取這個類中定義了的方法列表。java.lang.reflect.Methods 是用來描述某個類中單個方法的一個類。
Java類反射中的主要方法
對于以下三類組件中的任何一類來說
-- 構造函數、字段和方法
-- java.lang.Class 提供四種獨立的反射調用,以不同的方式來獲得信息。調用都遵循一種標準格式。以下是用于查找構造函數的一組反射調用:
Constructor getConstructor(Class[] params) -- 獲得使用特殊的參數類型的公共構造函數,
Constructor[] getConstructors() -- 獲得類的所有公共構造函數
Constructor getDeclaredConstructor(Class[] params) -- 獲得使用特定參數類型的構造函數(與接入級別無關)
Constructor[] getDeclaredConstructors() -- 獲得類的所有構造函數(與接入級別無關)
獲得字段信息的Class 反射調用不同于那些用于接入構造函數的調用,在參數類型數組中使用了字段名:
Field getField(String name) -- 獲得命名的公共字段
Field[] getFields() -- 獲得類的所有公共字段
Field getDeclaredField(String name) -- 獲得類聲明的命名的字段
Field[] getDeclaredFields() -- 獲得類聲明的所有字段
用于獲得方法信息函數:
Method getMethod(String name, Class[] params) -- 使用特定的參數類型,獲得命名的公共方法
Method[] getMethods() -- 獲得類的所有公共方法
Method getDeclaredMethod(String name, Class[] params) -- 使用特寫的參數類型,獲得類聲明的命名的方法
Method[] getDeclaredMethods() -- 獲得類聲明的所有方法
使用 Reflection:
用于 reflection 的類,如 Method,可以在 java.lang.relfect 包中找到。使用這些類的時候必須要遵循三個步驟:
第一步是獲得你想操作的類的 java.lang.Class 對象。
在運行中的 Java 程序中,用 java.lang.Class 類來描述類和接口等。
下面就是獲得一個 Class 對象的方法之一:
Class c = Class.forName("java.lang.String");
這條語句得到一個 String 類的類對象。還有另一種方法,如下面的語句:
Class c = int.class;
或者
Class c = Integer.TYPE;
它們可獲得基本類型的類信息。其中后一種方法中訪問的是基本類型的封裝類 (如 Intege ) 中預先定義好的 TYPE 字段。
第二步是調用諸如 getDeclaredMethods 的方法,以取得該類中定義的所有方法的列表。
一旦取得這個信息,就可以進行第三步了——使用 reflection API 來操作這些信息,如下面這段代碼:
Class c = Class.forName("java.lang.String");
Method m[] = c.getDeclaredMethods();
System.out.println(m[0].toString());
它將以文本方式打印出 String 中定義的第一個方法的原型。
處理對象:
a.創建一個Class對象
b.通過getField 創建一個Field對象
c.調用Field.getXXX(Object)方法(XXX是Int,Float等,如果是對象就省略;Object是指實例).
例如:
import java.lang.reflect.*;
import java.awt.*;
class SampleGet {
public static void main(String[] args) throws Exception {
Rectangle r = new Rectangle(100, 325);
printHeight(r);
printWidth( r);
}
static void printHeight(Rectangle r)throws Exception {
//Field屬性名
Field heightField;
//Integer屬性值
Integer heightValue;
//創建一個Class對象
Class c = r.getClass();
//.通過getField 創建一個Field對象
heightField = c.getField("height");
//調用Field.getXXX(Object)方法(XXX是Int,Float等,如果是對象就省略;Object是指實例).
heightValue = (Integer) heightField.get(r);
System.out.println("Height: " + heightValue.toString());
}
static void printWidth(Rectangle r) throws Exception{
Field widthField;
Integer widthValue;
Class c = r.getClass();
widthField = c.getField("width");
widthValue = (Integer) widthField.get(r);
System.out.println("Height: " + widthValue.toString());
}
}
安全性和反射:
在處理反射時安全性是一個較復雜的問題。反射經常由框架型代碼使用,由于這一點,我們可能希望框架能夠全面接入代碼,無需考慮常規的接入限制。但是,在其它情況下,不受控制的接入會帶來嚴重的安全性風險,例如當代碼在不值得信任的代碼共享的環境中運行時。
由于這些互相矛盾的需求,Java編程語言定義一種多級別方法來處理反射的安全性。基本模式是對反射實施與應用于源代碼接入相同的限制:
從任意位置到類公共組件的接入
類自身外部無任何到私有組件的接入
受保護和打包(缺省接入)組件的有限接入
不過至少有些時候,圍繞這些限制還有一種簡單的方法。我們可以在我們所寫的類中,擴展一個普通的基本類 java.lang.reflect.AccessibleObject 類。這個類定義了一種setAccessible方法,使我們能夠啟動或關閉對這些類中其中一個類的實例的接入檢測。唯一的問題在于如果使用了安全性管理 器,它將檢測正在關閉接入檢測的代碼是否許可了這樣做。如果未許可,安全性管理器拋出一個例外。
下面是一段程序,在TwoString 類的一個實例上使用反射來顯示安全性正在運行:
public class ReflectSecurity {
public static void main(String[] args) {
try {
TwoString ts = new TwoString("a", "b");
Field field = clas.getDeclaredField("m_s1");
// field.setAccessible(true);
System.out.println("Retrieved value is " +
field.get(inst));
} catch (Exception ex) {
ex.printStackTrace(System.out);
}
}
}
如果我們編譯這一程序時,不使用任何特定參數直接從命令行運行,它將在field .get(inst)調用中拋出一個IllegalAccessException異常。如果我們不注釋 field.setAccessible(true)代碼行,那么重新編譯并重新運行該代碼,它將編譯成功。最后,如果我們在命令行添加了JVM參數 -Djava.security.manager以實現安全性管理器,它仍然將不能通過編譯,除非我們定義了ReflectSecurity類的許可權 限。
反射性能:(轉錄別人的啊)
反射是一種強大的工具,但也存在一些不足。一個主要的缺點是對性能有影響。使用反射基本上是一種解釋操作,我們可以告訴JVM,我們希望做什么并且它滿足我們的要求。這類操作總是慢于只直接執行相同的操作。
下面的程序是字段接入性能測試的一個例子,包括基本的測試方法。每種方法測試字段接入的一種形式 -- accessSame 與同一對象的成員字段協作,accessOther 使用可直接接入的另一對象的字段,accessReflection 使用可通過反射接入的另一對象的字段。在每種情況下,方法執行相同的計算 -- 循環中簡單的加/乘順序。
程序如下:
public int accessSame(int loops) {
m_value = 0;
for (int index = 0; index < loops; index++) {
m_value = (m_value + ADDITIVE_VALUE) *
MULTIPLIER_VALUE;
}
return m_value;
}
public int acces
sReference(int loops) {
TimingClass timing = new TimingClass();
for (int index = 0; index < loops; index++) {
timing.m_value = (timing.m_value + ADDITIVE_VALUE) *
MULTIPLIER_VALUE;
}
return timing.m_value;
}
public int accessReflection(int loops) throws Exception {
TimingClass timing = new TimingClass();
try {
Field field = TimingClass.class.
getDeclaredField("m_value");
for (int index = 0; index < loops; index++) {
int value = (field.getInt(timing) +
ADDITIVE_VALUE) * MULTIPLIER_VALUE;
field.setInt(timing, value);
}
return timing.m_value;
} catch (Exception ex) {
System.out.println("Error using reflection");
throw ex;
}
}
在上面的例子中,測試程序重復調用每種方法,使用一個大循環數,從而平均多次調用的時間衡量結果。平均值中不包括每種方法第一次調用的時間,因此初始化時間不是結果中的一個因素。下面的圖清楚的向我們展示了每種方法字段接入的時間:
圖 1:字段接入時間 :
我們可以看出:在前兩副圖中(Sun JVM),使用反射的執行時間超過使用直接接入的1000倍以上。通過比較,IBM JVM可能稍好一些,但反射方法仍舊需要比其它方法長700倍以上的時間。任何JVM上其它兩種方法之間時間方面無任何顯著差異,但IBM JVM幾乎比Sun JVM快一倍。最有可能的是這種差異反映了Sun Hot Spot JVM的專業優化,它在簡單基準方面表現得很糟糕。反射性能是Sun開發1.4 JVM時關注的一個方面,它在反射方法調用結果中顯示。在這類操作的性能方面,Sun 1.4.1 JVM顯示了比1.3.1版本很大的改進。
如果為為創建使用反射的對象編寫了類似的計時測試程序,我們會發現這種情況下的差異不象字段和方法調用情況下那么顯著。使用newInstance()調 用創建一個簡單的java.lang.Object實例耗用的時間大約是在Sun 1.3.1 JVM上使用new Object()的12倍,是在IBM 1.4.0 JVM的四倍,只是Sun 1.4.1 JVM上的兩部。使用Array.newInstance(type, size)創建一個數組耗用的時間是任何測試的JVM上使用new type[size]的兩倍,隨著數組大小的增加,差異逐步縮小。隨著jdk6.0的推出,反射機制的性能也有了很大的提升。期待中….
總結:
Java語言反射提供一種動態鏈接程序組件的多功能方法。它允許程序創建和控制任何類的對象(根據安全性限制),無需提前硬編碼目標類。這些特性使得反射 特別適用于創建以非常普通的方式與對象協作的庫。例如,反射經常在持續存儲對象為數據庫、XML或其它外部格式的框架中使用。Java reflection 非常有用,它使類和數據結構能按名稱動態檢索相關信息,并允許在運行著的程序中操作這些信息。Java 的這一特性非常強大,并且是其它一些常用語言,如 C、C++、Fortran 或者 Pascal 等都不具備的。
但反射有兩個缺點。第一個是性能問題。用于字段和方法接入時反射要遠慢于直接代碼。性能問題的程度取決于程序中是如何使用反射的。如果它作為程序運行中相 對很少涉及的部分,緩慢的性能將不會是一個問題。即使測試中最壞情況下的計時圖顯示的反射操作只耗用幾微秒。僅反射在性能關鍵的應用的核心邏輯中使用時性 能問題才變得至關重要。
許多應用中更嚴重的一個缺點是使用反射會模糊程序內部實際要發生的事情。程序人員希望在源代碼中看到程序的邏輯,反射等繞過了源代碼的技術會帶來維護問 題。反射代碼比相應的直接代碼更復雜,正如性能比較的代碼實例中看到的一樣。解決這些問題的最佳方案是保守地使用反射——僅在它可以真正增加靈活性的地方 ——記錄其在目標類中的使用。
一下是對應各個部分的例子:
具體的應用:
1、 模仿instanceof 運算符號
class A {}
public class instance1 {
public static void main(String args[])
{
try {
Class cls = Class.forName("A");
boolean b1
= cls.isInstance(new Integer(37));
System.out.println(b1);
boolean b2 = cls.isInstance(new A());
System.out.println(b2);
}
catch (Throwable e) {
System.err.println(e);
}
}
}
2、 在類中尋找指定的方法,同時獲取該方法的參數列表,例外和返回值
import java.lang.reflect.*;
public class method1 {
private int f1(
Object p, int x) throws NullPointerException
{
if (p == null)
throw new NullPointerException();
return x;
}
public static void main(String args[])
{
try {
Class cls = Class.forName("method1");
Method methlist[]
= cls.getDeclaredMethods();
for (int i = 0; i < methlist.length;
i++)
Method m = methlist[i];
System.out.println("name
= " + m.getName());
System.out.println("decl class = " +
m.getDeclaringClass());
Class pvec[] = m.getParameterTypes();
for (int j = 0; j < pvec.length; j++)
System.out.println("
param #" + j + " " + pvec[j]);
Class evec[] = m.getExceptionTypes();
for (int j = 0; j < evec.length; j++)
System.out.println("exc #" + j
+ " " + evec[j]);
System.out.println("return type = " +
m.getReturnType());
System.out.println("-----");
}
}
catch (Throwable e) {
System.err.println(e);
}
}
}
3、 獲取類的構造函數信息,基本上與獲取方法的方式相同
import java.lang.reflect.*;
public class constructor1 {
public constructor1()
{
}
protected constructor1(int i, double d)
{
}
public static void main(String args[])
{
try {
Class cls = Class.forName("constructor1");
Constructor ctorlist[]
= cls.getDeclaredConstructors();
for (int i = 0; i < ctorlist.length; i++) {
Constructor ct = ctorlist[i];
System.out.println("name
= " + ct.getName());
System.out.println("decl class = " +
ct.getDeclaringClass());
Class pvec[] = ct.getParameterTypes();
for (int j = 0; j < pvec.length; j++)
System.out.println("param #"
+ j + " " + pvec[j]);
Class evec[] = ct.getExceptionTypes();
for (int j = 0; j < evec.length; j++)
System.out.println(
"exc #" + j + " " + evec[j]);
System.out.println("-----");
}
}
catch (Throwable e) {
System.err.println(e);
}
}
}
4、 獲取類中的各個數據成員對象,包括名稱。類型和訪問修飾符號
import java.lang.reflect.*;
public class field1 {
private double d;
public static final int i = 37;
String s = "testing";
public static void main(String args[])
{
try {
Class cls = Class.forName("field1");
Field fieldlist[]
= cls.getDeclaredFields();
for (int i
= 0; i < fieldlist.length; i++) {
Field fld = fieldlist[i];
System.out.println("name
= " + fld.getName());
System.out.println("decl class = " +
fld.getDeclaringClass());
System.out.println("type
= " + fld.getType());
int mod = fld.getModifiers();
System.out.println("modifiers = " +
Modifier.toString(mod));
System.out.println("-----");
}
}
catch (Throwable e) {
System.err.println(e);
}
}
}
5、 通過使用方法的名字調用方法
import java.lang.reflect.*;
public class method2 {
public int add(int a, int b)
{
return a + b;
}
public static void main(String args[])
{
try {
Class cls = Class.forName("method2");
Class partypes[] = new Class[2];
partypes[0] = Integer.TYPE;
partypes[1] = Integer.TYPE;
Method meth = cls.getMethod(
"add", partypes);
method2 methobj = new method2();
Object arglist[] = new Object[2];
arglist[0] = new Integer(37);
arglist[1] = new Integer(47);
Object retobj
= meth.invoke(methobj, arglist);
Integer retval = (Integer)retobj;
System.out.println(retval.intValue());
}
catch (Throwable e) {
System.err.println(e);
}
}
}
6、 創建新的對象
import java.lang.reflect.*;
public class constructor2 {
public constructor2()
{
}
public constructor2(int a, int b)
{
System.out.println(
"a = " + a + " b = " + b);
}
public static void main(String args[])
{
try {
Class cls = Class.forName("constructor2");
Class partypes[] = new Class[2];
partypes[0] = Integer.TYPE;
partypes[1] = Integer.TYPE;
Constructor ct
= cls.getConstructor(partypes);
Object arglist[] = new Object[2];
arglist[0] = new Integer(37);
arglist[1] = new Integer(47);
Object retobj = ct.newInstance(arglist);
}
catch (Throwable e) {
System.err.println(e);
}
}
}
7、 變更類實例中的數據的值
import java.lang.reflect.*;
public class field2 {
public double d;
public static void main(String args[])
{
try {
Class cls = Class.forName("field2");
Field fld = cls.getField("d");
field2 f2obj = new field2();
System.out.println("d = " + f2obj.d);
fld.setDouble(f2obj, 12.34);
System.out.println("d = " + f2obj.d);
}
catch (Throwable e) {
System.err.println(e);
}
}
}
使用反射創建可重用代碼:
1、 對象工廠
Object factory(String p) {
Class c;
Object o=null;
try {
c = Class.forName(p);// get class def
o = c.newInstance(); // make a new one
} catch (Exception e) {
System.err.println("Can't make a " + p);
}
return o;
}
public class ObjectFoundry {
public static Object factory(String p)
throws ClassNotFoundException,
InstantiationException,
IllegalAccessException {
Class c = Class.forName(p);
Object o = c.newInstance();
return o;
}
}
2、 動態檢測對象的身份,替代instanceof
public static boolean
isKindOf(Object obj, String type)
throws ClassNotFoundException {
// get the class def for obj and type
Class c = obj.getClass();
Class tClass = Class.forName(type);
while ( c!=null ) {
if ( c==tClass ) return true;
c = c.getSuperclass();
}
return false;
}
打個比方:一個object就像一個大房子,大門永遠打開。房子里有很多房間(也就是方法)。這些房間有上鎖的(synchronized方法),和不上鎖之分(普通方法)。房門口放著一把鑰匙(key),這把鑰匙可以打開所有上鎖的房間。另外我把所有想調用該對象方法的線程比喻成想進入這房子某個房間的人。所有的東西就這么多了,下面我們看看這些東西之間如何作用的。
在此我們先來明確一下我們的前提條件。該對象至少有一個synchronized方法,否則這個key還有啥意義。當然也就不會有我們的這個主題了。
一個人想進入某間上了鎖的房間,他來到房子門口,看見鑰匙在那兒(說明暫時還沒有其他人要使用上鎖的房間)。于是他走上去拿到了鑰匙,并且按照自己的計劃使用那些房間。注意一點,他每次使用完一次上鎖的房間后會馬上把鑰匙還回去。即使他要連續使用兩間上鎖的房間,中間他也要把鑰匙還回去,再取回來。
因此,普通情況下鑰匙的使用原則是:“隨用隨借,用完即還。”
這時其他人可以不受限制的使用那些不上鎖的房間,一個人用一間可以,兩個人用一間也可以,沒限制。但是如果當某個人想要進入上鎖的房間,他就要跑到大門口去看看了。有鑰匙當然拿了就走,沒有的話,就只能等了。
要是很多人在等這把鑰匙,等鑰匙還回來以后,誰會優先得到鑰匙?Not guaranteed。象前面例子里那個想連續使用兩個上鎖房間的家伙,他中間還鑰匙的時候如果還有其他人在等鑰匙,那么沒有任何保證這家伙能再次拿到。(JAVA規范在很多地方都明確說明不保證,象Thread.sleep()休息后多久會返回運行,相同優先權的線程那個首先被執行,當要訪問對象的鎖被釋放后處于等待池的多個線程哪個會優先得到,等等。我想最終的決定權是在JVM,之所以不保證,就是因為JVM在做出上述決定的時候,絕不是簡簡單單根據一個條件來做出判斷,而是根據很多條。而由于判斷條件太多,如果說出來可能會影響JAVA的推廣,也可能是因為知識產權保護的原因吧。SUN給了個不保證就混過去了。無可厚非。但我相信這些不確定,并非完全不確定。因為計算機這東西本身就是按指令運行的。即使看起來很隨機的現象,其實都是有規律可尋。學過計算機的都知道,計算機里隨機數的學名是偽隨機數,是人運用一定的方法寫出來的,看上去隨機罷了。另外,或許是因為要想弄的確定太費事,也沒多大意義,所以不確定就不確定了吧。)
再來看看同步代碼塊。和同步方法有小小的不同。
1.從尺寸上講,同步代碼塊比同步方法小。你可以把同步代碼塊看成是沒上鎖房間里的一塊用帶鎖的屏風隔開的空間。
2.同步代碼塊還可以人為的指定獲得某個其它對象的key。就像是指定用哪一把鑰匙才能開這個屏風的鎖,你可以用本房的鑰匙;你也可以指定用另一個房子的鑰匙才能開,這樣的話,你要跑到另一棟房子那兒把那個鑰匙拿來,并用那個房子的鑰匙來打開這個房子的帶鎖的屏風。
記住你獲得的那另一棟房子的鑰匙,并不影響其他人進入那棟房子沒有鎖的房間。
為什么要使用同步代碼塊呢?我想應該是這樣的:首先對程序來講同步的部分很影響運行效率,而一個方法通常是先創建一些局部變量,再對這些變量做一些操作,如運算,顯示等等;而同步所覆蓋的代碼越多,對效率的影響就越嚴重。因此我們通常盡量縮小其影響范圍。如何做?同步代碼塊。我們只把一個方法中該同步的地方同步,比如運算。
另外,同步代碼塊可以指定鑰匙這一特點有個額外的好處,是可以在一定時期內霸占某個對象的key。還記得前面說過普通情況下鑰匙的使用原則嗎。現在不是普通情況了。你所取得的那把鑰匙不是永遠不還,而是在退出同步代碼塊時才還。
還用前面那個想連續用兩個上鎖房間的家伙打比方。怎樣才能在用完一間以后,繼續使用另一間呢。用同步代碼塊吧。先創建另外一個線程,做一個同步代碼塊,把那個代碼塊的鎖指向這個房子的鑰匙。然后啟動那個線程。只要你能在進入那個代碼塊時抓到這房子的鑰匙,你就可以一直保留到退出那個代碼塊。也就是說你甚至可以對本房內所有上鎖的房間遍歷,甚至再sleep(10*60*1000),而房門口卻還有1000個線程在等這把鑰匙呢。很過癮吧。
在此對sleep()方法和鑰匙的關聯性講一下。一個線程在拿到key后,且沒有完成同步的內容時,如果被強制sleep()了,那key還一直在它那兒。直到它再次運行,做完所有同步內容,才會歸還key。記住,那家伙只是干活干累了,去休息一下,他并沒干完他要干的事。為了避免別人進入那個房間把里面搞的一團糟,即使在睡覺的時候他也要把那唯一的鑰匙戴在身上。
最后,也許有人會問,為什么要一把鑰匙通開,而不是一個鑰匙一個門呢?我想這純粹是因為復雜性問題。一個鑰匙一個門當然更安全,但是會牽扯好多問題。鑰匙的產生,保管,獲得,歸還等等。其復雜性有可能隨同步方法的增加呈幾何級數增加,嚴重影響效率。
這也算是一個權衡的問題吧。為了增加一點點安全性,導致效率大大降低,是多么不可取啊。
摘自:http://www.54bk.com/more.asp?name=czp&id=2097
一、當兩個并發線程訪問同一個對象object中的這個synchronized(this)同步代碼塊時,一個時間內只能有一個線程得到執行。另一個線程必須等待當前線程執行完這個代碼塊以后才能執行該代碼塊。
二、然而,當一個線程訪問object的一個synchronized(this)同步代碼塊時,另一個線程仍然可以訪問該object中的非synchronized(this)同步代碼塊。
三、尤其關鍵的是,當一個線程訪問object的一個synchronized(this)同步代碼塊時,其他線程對object中所有其它synchronized(this)同步代碼塊的訪問將被阻塞。
四、第三個例子同樣適用其它同步代碼塊。也就是說,當一個線程訪問object的一個synchronized(this)同步代碼塊時,它就獲得了這個object的對象鎖。結果,其它線程對該object對象所有同步代碼部分的訪問都被暫時阻塞。
五、以上規則對其它對象鎖同樣適用.
舉例說明:
一、當兩個并發線程訪問同一個對象object中的這個synchronized(this)同步代碼塊時,一個時間內只能有一個線程得到執行。另一個線程必須等待當前線程執行完這個代碼塊以后才能執行該代碼塊。
package ths;
public class Thread1 implements Runnable {
public void run() {
synchronized(this) {
for (int i = 0; i < 5; i++) {
System.out.println(Thread.currentThread().getName() + " synchronized loop " + i);
}
}
}
public static void main(String[] args) {
Thread1 t1 = new Thread1();
Thread ta = new Thread(t1, "A");
Thread tb = new Thread(t1, "B");
ta.start();
tb.start();
}
}
結果:
A synchronized loop 0
A synchronized loop 1
A synchronized loop 2
A synchronized loop 3
A synchronized loop 4
B synchronized loop 0
B synchronized loop 1
B synchronized loop 2
B synchronized loop 3
B synchronized loop 4
二、然而,當一個線程訪問object的一個synchronized(this)同步代碼塊時,另一個線程仍然可以訪問該object中的非synchronized(this)同步代碼塊。
package ths;
public class Thread2 {
public void m4t1() {
synchronized(this) {
int i = 5;
while( i-- > 0) {
System.out.println(Thread.currentThread().getName() + " : " + i);
try {
Thread.sleep(500);
} catch (InterruptedException ie) {
}
}
}
}
public void m4t2() {
int i = 5;
while( i-- > 0) {
System.out.println(Thread.currentThread().getName() + " : " + i);
try {
Thread.sleep(500);
} catch (InterruptedException ie) {
}
}
}
public static void main(String[] args) {
final Thread2 myt2 = new Thread2();
Thread t1 = new Thread(
new Runnable() {
public void run() {
myt2.m4t1();
}
}, "t1"
);
Thread t2 = new Thread(
new Runnable() {
public void run() {
myt2.m4t2();
}
}, "t2"
);
t1.start();
t2.start();
}
}
結果:
t1 : 4
t2 : 4
t1 : 3
t2 : 3
t1 : 2
t2 : 2
t1 : 1
t2 : 1
t1 : 0
t2 : 0
三、尤其關鍵的是,當一個線程訪問object的一個synchronized(this)同步代碼塊時,其他線程對object中所有其它synchronized(this)同步代碼塊的訪問將被阻塞。
//修改Thread2.m4t2()方法:
public void m4t2() {
synchronized(this) {
int i = 5;
while( i-- > 0) {
System.out.println(Thread.currentThread().getName() + " : " + i);
try {
Thread.sleep(500);
} catch (InterruptedException ie) {
}
}
}
}
結果:
t1 : 4
t1 : 3
t1 : 2
t1 : 1
t1 : 0
t2 : 4
t2 : 3
t2 : 2
t2 : 1
t2 : 0
四、第三個例子同樣適用其它同步代碼塊。也就是說,當一個線程訪問object的一個synchronized(this)同步代碼塊時,它就獲得了這個object的對象鎖。結果,其它線程對該object對象所有同步代碼部分的訪問都被暫時阻塞。
//修改Thread2.m4t2()方法如下:
public synchronized void m4t2() {
int i = 5;
while( i-- > 0) {
System.out.println(Thread.currentThread().getName() + " : " + i);
try {
Thread.sleep(500);
} catch (InterruptedException ie) {
}
}
}
結果:
t1 : 4
t1 : 3
t1 : 2
t1 : 1
t1 : 0
t2 : 4
t2 : 3
t2 : 2
t2 : 1
t2 : 0
五、以上規則對其它對象鎖同樣適用:
package ths;
public class Thread3 {
class Inner {
private void m4t1() {
int i = 5;
while(i-- > 0) {
System.out.println(Thread.currentThread().getName() + " : Inner.m4t1()=" + i);
try {
Thread.sleep(500);
} catch(InterruptedException ie) {
}
}
}
private void m4t2() {
int i = 5;
while(i-- > 0) {
System.out.println(Thread.currentThread().getName() + " : Inner.m4t2()=" + i);
try {
Thread.sleep(500);
} catch(InterruptedException ie) {
}
}
}
}
private void m4t1(Inner inner) {
synchronized(inner) { //使用對象鎖
inner.m4t1();
}
}
private void m4t2(Inner inner) {
inner.m4t2();
}
public static void main(String[] args) {
final Thread3 myt3 = new Thread3();
final Inner inner = myt3.new Inner();
Thread t1 = new Thread(
new Runnable() {
public void run() {
myt3.m4t1(inner);
}
}, "t1"
);
Thread t2 = new Thread(
new Runnable() {
public void run() {
myt3.m4t2(inner);
}
}, "t2"
);
t1.start();
t2.start();
}
}
結果:
盡管線程t1獲得了對Inner的對象鎖,但由于線程t2訪問的是同一個Inner中的非同步部分。所以兩個線程互不干擾。
t1 : Inner.m4t1()=4
t2 : Inner.m4t2()=4
t1 : Inner.m4t1()=3
t2 : Inner.m4t2()=3
t1 : Inner.m4t1()=2
t2 : Inner.m4t2()=2
t1 : Inner.m4t1()=1
t2 : Inner.m4t2()=1
t1 : Inner.m4t1()=0
t2 : Inner.m4t2()=0
現在在Inner.m4t2()前面加上synchronized:
private synchronized void m4t2() {
int i = 5;
while(i-- > 0) {
System.out.println(Thread.currentThread().getName() + " : Inner.m4t2()=" + i);
try {
Thread.sleep(500);
} catch(InterruptedException ie) {
}
}
}
結果:
盡管線程t1與t2訪問了同一個Inner對象中兩個毫不相關的部分,但因為t1先獲得了對Inner的對象鎖,所以t2對Inner.m4t2()的訪問也被阻塞,因為m4t2()是Inner中的一個同步方法。
t1 : Inner.m4t1()=4
t1 : Inner.m4t1()=3
t1 : Inner.m4t1()=2
t1 : Inner.m4t1()=1
t1 : Inner.m4t1()=0
t2 : Inner.m4t2()=4
t2 : Inner.m4t2()=3
t2 : Inner.m4t2()=2
t2 : Inner.m4t2()=1
t2 : Inner.m4t2()=0
同步買票問題
public class TicketsSystem {
public static void main(String[] args) {
SellThread st = new SellThread();
Thread th1 = new Thread(st);
th1.start();
Thread th2 = new Thread(st);
th2.start();
Thread th3 = new Thread(st);
th3.start();
}
}
class SellThread implements Runnable {
private int number=10;
String s = new String();
public void run() {
while (number > 0) {
synchronized (s) {
System.out.println("第" + number + "個人在"
+ Thread.currentThread().getName() + "買票");
}
number--;
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
Java線程:線程的同步-同步塊
對于同步,除了同步方法外,還可以使用同步代碼塊,有時候同步代碼塊會帶來比同步方法更好的效果。
追其同步的根本的目的,是控制競爭資源的正確的訪問,因此只要在訪問競爭資源的時候保證同一時刻只能一個線程訪問即可,因此Java引入了同步代碼快的策略,以提高性能。
在上個例子的基礎上,對oper方法做了改動,由同步方法改為同步代碼塊模式,程序的執行邏輯并沒有問題。
/**
* Java線程:線程的同步-同步代碼塊
*
* @author leizhimin 2009-11-4 11:23:32
*/
public class Test {
public static void main(String[] args) {
User u = new User("張三", 100);
MyThread t1 = new MyThread("線程A", u, 20);
MyThread t2 = new MyThread("線程B", u, -60);
MyThread t3 = new MyThread("線程C", u, -80);
MyThread t4 = new MyThread("線程D", u, -30);
MyThread t5 = new MyThread("線程E", u, 32);
MyThread t6 = new MyThread("線程F", u, 21);
t1.start();
t2.start();
t3.start();
t4.start();
t5.start();
t6.start();
}
}
class MyThread extends Thread {
private User u;
private int y = 0;
MyThread(String name, User u, int y) {
super(name);
this.u = u;
this.y = y;
}
public void run() {
u.oper(y);
}
}
class User {
private String code;
private int cash;
User(String code, int cash) {
this.code = code;
this.cash = cash;
}
public String getCode() {
return code;
}
public void setCode(String code) {
this.code = code;
}
/**
* 業務方法
*
* @param x 添加x萬元
*/
public void oper(int x) {
try {
Thread.sleep(10L);
synchronized (this) {
this.cash += x;
System.out.println(Thread.currentThread().getName() + "運行結束,增加“" + x + "”,當前用戶賬戶余額為:" + cash);
}
Thread.sleep(10L);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
@Override
public String toString() {
return "User{" +
"code='" + code + '\'' +
", cash=" + cash +
'}';
}
}
線程E運行結束,增加“32”,當前用戶賬戶余額為:132
線程B運行結束,增加“-60”,當前用戶賬戶余額為:72
線程D運行結束,增加“-30”,當前用戶賬戶余額為:42
線程F運行結束,增加“21”,當前用戶賬戶余額為:63
線程C運行結束,增加“-80”,當前用戶賬戶余額為:-17
線程A運行結束,增加“20”,當前用戶賬戶余額為:3
Process finished with exit code 0
注意:
在使用synchronized關鍵字時候,應該盡可能避免在synchronized方法或synchronized塊中使用sleep或者yield方法,因為synchronized程序塊占有著對象鎖,你休息那么其他的線程只能一邊等著你醒來執行完了才能執行。不但嚴重影響效率,也不合邏輯。
同樣,在同步程序塊內調用yeild方法讓出CPU資源也沒有意義,因為你占用著鎖,其他互斥線程還是無法訪問同步程序塊。當然與同步程序塊無關的線程可以獲得更多的執行時間。