
1、
測試人員只能修改缺陷狀態為:new-->open,fixed-->closed,fiexed-->reopen
2、 開發人員只能修改缺陷狀態為:open-->fiexd,open-->rejected
以上狀態轉換,可以根據實際需要進行定制!
本實驗前提:已經設置好相關的組(如項目測試組,組內成員:wyy)
下面以測試人員只能修改的缺陷狀態為例,詳細介紹如何設置。
1. 在IE瀏覽器中輸入:http://<安裝TD的IP地址>/tdbin,回車,打開如圖1所示頁面。
圖1 TestDirector主頁面
2. 在圖1中點“TestDirector”鏈接,打開如圖2所示頁面。
圖2 TestDirector登錄頁面
3.點圖2頁面右上角的“Customize”鏈接,打開如圖3所示的對話框,選擇Domain、Project,輸入User ID、Password。(注意:須用管理員權限登錄)
圖3 TestDirector登錄自定義頁面
4. 在圖3中點“OK”按鈕,進入自定義管理頁面,如圖4所示。
圖4 TestDirector自定義頁面
5. 點圖4中的“Set up Groups”鏈接,打開Set up Groups對話框,如圖5所示。
圖5 Set up Groups對話框
6. 選擇需要設置的組,如:選擇組“項目測試組”,點“Change”,打開“Permission Settings For 項目測試組 Groups ”,如圖6所示。
圖6 Permission Settings For 項目測試組 Groups(一) 7. 點圖6中的“Defects”,并點“Modify Defect”復選框前面的+號展看該項,如圖7所示。
圖7 Permission Settings For 項目測試組 Groups(二)
8. 點圖7中的“Status”項,如圖8所示。
圖8 Permission Settings For 項目測試組 Groups(三)
9. 點圖8中的“Add”、“Edit”、“Delete”按鈕即可添加、編輯、刪除狀態字段的設置。
比如:要設置測試人員可以修改的權限狀態為:new-->open,fixed-->closed,fiexed-->reopen。
先刪除圖8中的fiexed到any,之后點“Add”, 如圖9所示,選擇From中的下面一個單選按鈕,在下拉框中選擇New,再選擇To的下面一個單選按鈕,在下拉框中選擇Open,之后點“OK”即可設置成功。
圖9 添加缺陷狀態轉換規則
10.最后的設置如圖10所示。
圖10 添加缺陷狀態轉換規則示例
11.點圖10中的“OK”即可設置成功,返回到“Set up Groups”對話框界面,點“OK”設置完成,返回到“Customize”頁面,到此設置完成。
公司的Web服務器搭建完成,上線在即。它能夠承載多大的訪問量,響應速度和容錯能力等性能指標是否滿足要求,所有這些都是我最想知道,也最為擔心的。如何才能知曉這一切呢?
通過工具可以有效地測試Web服務器的運行狀態和響應時間等性能指標,從而解決上述問題。下面以Web Application Stress Tool(簡稱WAST)為例,介紹如何進行Web壓力
測試。這是由
微軟的網站測試人員開發的專門用來進行實際網站
壓力測試的一套工具。
測試工具的設置
下載并安裝WAST,過程極其簡單。在對目標Web服務器進行壓力測試之前,首先要對它進行一些必要的設置。
1.設置并行連接數
點擊“Defaults→Settings”打開設置面板。在Concurrent Connections下進行并行連接設置。Stress Level(Threads)是最少線程,Stress Multiplier是最大線程。這里的線程是指定程序在后臺用多少線程進行請求,也就是相當于模擬多少個客戶機的連接,一般填寫500~1000。這個線程數是根據本機的承受力來設置的,如果你對自己的機器配置有足夠信心的話,那么可以設置得更高一些。
2.設置持續時間
在“Test Run Time”中用來指定一次壓力測試需要持續的時間,分為天、小時、分、秒幾個單位級別,比如我們設置為1個小時。
3.其余設置
用Rpquest Delay設置延遲時間,我們設置為100~500。用Suspend設置設定掛起時間,Warmup時間是初始化測試運行時間,Cooldown時間是指定結束階段的測試時間。Bandwith指定帶寬瓶頸,允許模擬從14.4 kbps的Modem連接到T1(1.5 Mbps)的Local Area Network(LAN)連接的網絡帶寬。Redirects設置重定向時間,Throughput用來設置用戶、密碼頁面狀態保存等是否啟用,Name Resolution用來設置是否進行名稱解析。所有以上的選項大家可以根據自己的需要進行設置。
壓力測試的步驟
設置完成后就可以進行壓力測試。測試的步驟如下:
第一步,點擊工具欄上的“New Script”按鈕,在打開的面板中點擊“Nanual”按鈕創建一個新的測試項目。在打開的窗口中對它進行設置,在主選項中的Server中填寫要測試的服務器的IP地址。這里我們填寫192.168.1.20。在下方選擇測試的Web連接方式,這里的方式Verb選擇get。Path選擇要測試的Web頁面路徑,這里填寫/Index.asp即動網的首頁文件,WAST可以設置更多的Path。
第二步,在“Settings”功能設置中將Stress Level (Threads)線程數設置為1000。然后點工具中的灰色三角按鈕即可進行測試。測試過程中我們可以從服務器的任務管理器中看到CPU使用率已經達到100%,損耗率達到最大。在CMD窗口中使用命令netstat -an,可以看到客戶端的IP地址在服務器上的80端口進行了非常多的連接,而且Web網站已經打不開了,提示過多用戶連接。
通過壓力測試,管理員對Web服務器的抗壓能力有了大概了解,可根據實際需要進行服務器硬件擴展,也為系統設置和軟件選擇等提供依據。Web服務器在正式發布前進行壓力測試是非常必要的。
首先,兩者的出發點是一致的,都是保證項目的健壯性、可靠性、正確性而言的。
不同點主要有:
1、時機不一致。
單元測試是在軟件編碼前期進行的,先于集成測試;集成測試,是在系統即將開發完畢,對系統的是否正常運作進行測試。
2、測試目的不一樣。
單元測試是一個高度本地化的東西(個人認為是屬于程序員自身的)。主要是針對每一個package下的Class 的功能進行測試。是程序員的生產力的一個表現方式。
集成測試,將系統當成一個黑盒子,僅關注系統的輸出、輸入。向客戶提供質量保證,不專門對單個程序員進行評估。
3、測試工具不一樣
單元測試:用junit自動測試框架,專人寫測試代碼,周期性的進行測試,保證沒有隱藏bug的出現。
集成測試:則需要更多人的協調,側重點會放到業務的處理上來,性能上也會有所考慮
4、測試粒度不同
單元測試的顆粒度是在單只程序上
集成測試的顆粒度則在整個系統上
最近幾天在公司里寫網絡通訊的代碼比較多,自然就會涉及到IO事件監測方法的問題。我驚奇的發現select輪訓的方法在那里居然還大行其道。我告訴他們現在無論在
Linux系統下,還是windows系統下,select都應該被廢棄不用了,其原因是在兩個平臺上select的系統調用都有一個可以說是致命的坑。
在windows上面單個fd_set中容納的socket handle個數不能超過FD_SETSIZE(在win32 winsock2.h里其定義為64,以VS2010版本為準),并且fd_set結構使用一個數組來容納這些socket handle的,每次FD_SET宏都是向這個數組中放入一個socket handle,并且此過程中是限定了不能超過FD_SETSIZE,具體請自己查看winsock2.h中FD_SET宏的定義。
此處的問題是
若本身fd_set中的socket handle已經達到FD_SETSIZE個,那么后續的FD_SET操作實際上是沒有效果的,對應socket handle的IO事件將被遺漏!!!
而在Linux系統下面,該問題其實也是處在fd_set的結構和FD_SET宏上。此時fd_set結構是使用bit位序列來記錄每一個待檢測IO事件的fd。記錄的方式稍微復雜,如下
/usr/include/sys/select.h中
1 typedef long int __fd_mask; 2 #define __NFDBITS (8 * sizeof (__fd_mask)) 3 #define __FDELT(d) ((d) / __NFDBITS) 4 5 #define __FDMASK(d) ((__fd_mask) 1 << ((d) % __NFDBITS)) 6 7 typedef struct 8 { 9 /* XPG4.2 requires this member name. Otherwise avoid the name 10 from the global namespace. */ 11 #ifdef __USE_XOPEN 12 __fd_mask fds_bits[__FD_SETSIZE / __NFDBITS]; 13 # define __FDS_BITS(set) ((set)->fds_bits) 14 #else 15 __fd_mask __fds_bits[__FD_SETSIZE / __NFDBITS]; 16 # define __FDS_BITS(set) ((set)->__fds_bits) 17 #endif 18 } fd_set; 19 20 #define FD_SET(fd, fdsetp) __FD_SET (fd, fdsetp) |
/usr/include/bits/select.h中
1 # define __FD_SET(d, set) (__FDS_BITS (set)[__FDELT (d)] |= __FDMASK (d))
可以看出,在上面的過程,實際上每個bit在fd_set的bit序列中的位置對應于fd的值。而fd_set結構中bit位個數是__FD_SETSIZE定義的,__FD_SETSIZE在/usr/include/bits/typesize.h(包含關系如下sys/socket.h -> bits/types.h -> bits/typesizes.h)中被定義為1024。
現在的問題是,當fd>=1024時,FD_SET宏實際上會引起內存寫越界。而實際上在man select中對已也有明確的說明,如下
NOTES
An fd_set is a fixed size buffer. Executing FD_CLR() or FD_SET() with a value of fd that is negative or is equal to or
larger than FD_SETSIZE will result in undefined behavior. Moreover, POSIX requires fd to be a valid file descriptor.
這一點包括之前的我,是很多人沒有注意到的,并且云風大神有篇博文《一起 select 引起的崩潰》也描述了這個問題。
可以看出在Linux系統select也是不安全的,若想使用,得小心翼翼的確認fd是否達到1024,但這很難做到,不然還是老老實實的用poll或epoll吧。
扯得有點遠了,但也引出了本片
文章要敘述的主題,就是Linux系統下fd值是怎么分配確定,大家都知道fd是int類型,但其值是怎么增長的,在下面的內容中我對此進行了一點分析,以2.6.30版本的kernel為例,歡迎拍磚。
首先得知道是哪個函數進行fd分配,對此我以pipe為例,它是分配fd的一個典型的syscall,在fs/pipe.c中定義了pipe和pipe2的syscall實現,如下1 SYSCALL_DEFINE2(pipe2, int __user *, fildes, int, flags) 2 { 3 int fd[2]; 4 int error; 5 6 error = do_pipe_flags(fd, flags); 7 if (!error) { 8 if (copy_to_user(fildes, fd, sizeof(fd))) { 9 sys_close(fd[0]); 10 sys_close(fd[1]); 11 error = -EFAULT; 12 } 13 } 14 return error; 15 } 16 17 SYSCALL_DEFINE1(pipe, int __user *, fildes) 18 { 19 return sys_pipe2(fildes, 0); 20 } |
進一步分析do_pipe_flags()實現,發現其使用get_unused_fd_flags(flags)來分配fd的,它是一個宏
#define get_unused_fd_flags(flags) alloc_fd(0, (flags)),位于include/linux/fs.h中
好了咱們找到了主角了,就是alloc_fd(),它就是內核章實際執行fd分配的函數。其位于fs/file.c,實現也很簡單,如下
1 int alloc_fd(unsigned start, unsigned flags) 2 { 3 struct files_struct *files = current->files; 4 unsigned int fd; 5 int error; 6 struct fdtable *fdt; 7 8 spin_lock(&files->file_lock); 9 repeat: 10 fdt = files_fdtable(files); 11 fd = start; 12 if (fd < files->next_fd) 13 fd = files->next_fd; 14 15 if (fd < fdt->max_fds) 16 fd = find_next_zero_bit(fdt->open_fds->fds_bits, 17 fdt->max_fds, fd); 18 19 error = expand_files(files, fd); 20 if (error < 0) 21 goto out; 22 23 /* 24 * If we needed to expand the fs array we 25 * might have blocked - try again. 26 */ 27 if (error) 28 goto repeat; 29 30 if (start <= files->next_fd) 31 files->next_fd = fd + 1; 32 33 FD_SET(fd, fdt->open_fds); 34 if (flags & O_CLOEXEC) 35 FD_SET(fd, fdt->close_on_exec); 36 else 37 FD_CLR(fd, fdt->close_on_exec); 38 error = fd; 39 #if 1 40 /* Sanity check */ 41 if (rcu_dereference(fdt->fd[fd]) != NULL) { 42 printk(KERN_WARNING "alloc_fd: slot %d not NULL!\n", fd); 43 rcu_assign_pointer(fdt->fd[fd], NULL); 44 } 45 #endif 46 47 out: 48 spin_unlock(&files->file_lock); 49 return error; 50 } |
在pipe的系統調用中start值始終為0,而中間比較關鍵的expand_files()函數是根據所給的fd值,判斷是否需要對進程的打開文件表進行擴容,其函數頭注釋如下
/*
* Expand files.
* This function will expand the file structures, if the requested size exceeds
* the current capacity and there is room for expansion.
* Return <0 error code on error; 0 when nothing done; 1 when files were
* expanded and execution may have blocked.
* The files->file_lock should be held on entry, and will be held on exit.
*/
此處對其實現就不做深究了,回到alloc_fd(),現在可以看出,其分配fd的原則是
每次優先分配fd值最小的空閑fd,當分配不成功,即返回EMFILE的錯誤碼,這表示當前進程中fd太多。
到此也印證了在公司寫的服務端程序(kernel是2.6.18)中,每次打印client鏈接對應的fd值得變化規律了,假如給一個新連接分配的fd值為8,那么其關閉之后,緊接著的新的鏈接分配到的fd也是8,再新的鏈接的fd值是逐漸加1的。
為此,我繼續找了一下socket對應fd分配方法,發現最終也是 alloc_fd(0, (flags),調用序列如下
socket(sys_call) -> sock_map_fd() -> sock_alloc_fd() -> get_unused_fd_flags()
open系統調用也是用get_unused_fd_flags(),這里就不列舉了。
現在想回頭說說開篇的select的問題。由于Linux系統fd的分配規則,實際上是已經保證每次的fd值盡量的小,一般非IO頻繁的系統,的確一個進程中fd值達到1024的概率比較小。因而對此到底是否該棄用select,還不能完全地做絕對的結論。如果設計的系統的確有其他措施保證fd值小于1024,那么用select無可厚非。
但在網絡通訊程序這種場合是絕不應該作此假設的,所以還是盡量的不用select吧!!
文章開始之前,我先吐槽一下:現在的應屆畢業生丫,不知大學四年都干了什么,難道時間都花在戀愛上面,就算你想戀也沒得愛可給你戀的,你確實戀了的,我只能認為你在搞基。
雖然我也是從大學四年搞基出來的,至少有些東西還是沒丟給老師。
目錄:
1. 數據類型
2. 存儲引擎
3. 名詞解析
4. 實體 VS 類
5. 關系型 VS 面向對象
文章開始之前,還是先吐槽一下:那些從學校步入社會的人們丫,多上點心,別天天還搞基,傷身又傷心,底子薄沒事,不肯前進就是大事了,不是每個頭頭都這么好心,還一點一點給你們寫培訓文檔。
本文都是Mysql為基礎。
1. 數據類型
1) 整數型
tinyint
int
bigint
當我問起int(20) 和int (12) 有區別嗎?(括號里面是長度)全場沉默了......
2) 數值型
decimal
當我問起decimal 10,當數值長度操過10了,會怎么樣? 萬一是金融行業呢,你該咋辦? 全場沉默了......
3) 字符型
char
varchar
當我問起char(2) 和varchar(2)有區別嗎?(括號里面是長度)全場沉默了......
當char字段和varchar字段使用索引的時候,他們有區別嗎?全場沉默了......
tinytext
text
mediumtext
text最大的大小是多少?text字段可以用索引嗎? 全場沉默了......
4)時間型
datetime
timestamp
datetime跟 timestamp有區別嗎?區別在哪里? 全場繼續沉默了......
5)枚舉型
enum
一位童鞋站起來問到,enum(Y,N) 和 char(1)有區別嗎?
2. 存儲引擎
innodb
myisam
memory
當我問起 innodb、 myisam有什么區別的時候,一位技術牛人,站起來,一棍子打死一群人,說直接用innodb就是了,現在的版本mysql默認都是推薦你使用innodb。
如果真要說起來,就說到鎖了,這又是坑爹的話題。 還是那位技術牛人高....
3. 名詞解析
完整性
冗余
實體
實體的關系
關系型
某位童鞋直接站起來說道:都扔給老師。 真的是佩服那位健忘的童鞋,有健忘癥真好,我這課我也丟給老師了。
4 實體 VS 類
該篇開始,我要說個知識:現在很多公司都是由下往上開發,今天我給你們講的是從上往下開發。
當時有位比較資深的人員就說到,由下往上都是老一輩人喜歡的,因為那段時間里他們的思想沒受到面向對象編程的侵襲。
從上往下是你們這群90后樂意做的事。
由下往上:數據庫關系--->代碼編程---->界面
由上往下:界面--->代碼編程---->數據庫關系
這是要逆天的存在,先不管是否是不是逆天,先看下面的實例:
class Person {
public $name;
public $age;
public $sex;
public $weight;
}
然后找了個童鞋轉了下數據結構
id int name varchar(50) age int sex enum("男","女") weight int
這位童鞋確實給力。
然后我又寫了.
$person1 = new Person();
$person1->name = "張三';
$person2= new Person();
$person2->name = "李四';
這位童鞋又寫出了如下
id int name varchar(50) age int sex enum("男","女") weight int
1 張三
2 李四
我相信當你看到這些,你應該知道發生了什么了吧!
我繼續寫到:
class Person {
public $name;
public $age;
public $orders = array(new Order(),new Order());
}
class Order {
public $money;
public $items = array(
"手把手教你做關鍵詞匹配項目",
"屌絲的坑人表單神器"
);
}
90后的小伙子很快就完成了:
order表:
order_id person_id money
order_item表:
item_id order_id item_name
看了這個我翻然大悟,原來現在的應屆生對類感興趣,對實體和實體與實體之間的聯系免疫了。
我大悟了,不知道那些童鞋了解了沒有,畢竟這個培訓是給那些童鞋的。
5. 關系型 VS 面向對象
面向對象 =>關系型 (90后太厲害了,不提了)
最終總結:課后,他們希望我下節課講解下數據庫如何優化,我只能吐槽下:尼瑪,連tinyint,char,varchar,索引,鎖都搞不懂就來學數據庫如何優化,這是要整哪樣?
當然我也對他們樂于要求感到高興,畢竟有需求就有動力。
官方介紹
HSSF is the POI Project's pure
Java implementation of the Excel '97(-2007) file format. XSSF is the POI Project's pure Java implementation of the Excel 2007 OOXML (.xlsx) file format.
從官方文檔中了解到:POI提供的HSSF包用于操作 Excel '97(-2007)的.xls文件,而XSSF包則用于操作Excel2007之后的.xslx文件。
需要的jar包
POI官網上下載包并解壓獲取java操作excel文件必須的jar包:
其中dom4j-1.6.1.jar和xbean.jar(下載地址:http://mirror.bjtu.edu.cn/apache/xmlbeans/binaries/ 網站:http://xmlbeans.apache.org
并不包含在POI提供的jar包中,需要單獨下載,否則程序會拋出異常:java.lang.ClassNotFoundException:org.apache.xmlbeans.XmlOptions。
具體代碼
在Eclipse中創建一個java project,將上面列出來的jar包都加入到工程的classpath中,否則引用不到jar包會報錯。
直接上代碼(代碼基本框架來自Apache POI官方網站,自行調整部分):
創建excel文件并寫入內容:
public static void createWorkbook() throws IOException { Workbook wb = new HSSFWorkbook(); String safeName1 = WorkbookUtil.createSafeSheetName("[O'sheet1]"); Sheet sheet1 = wb.createSheet(safeName1); CreationHelper createHelper = wb.getCreationHelper(); // Create a row and put some cells in it. Rows are 0 based. Row row = sheet1.createRow((short) 0); // Create a cell and put a value in it. Cell cell = row.createCell(0); cell.setCellValue(1234); // Or do it on one line. row.createCell(2).setCellValue( createHelper.createRichTextString("This is a string")); row.createCell(3).setCellValue(true); // we style the second cell as a date (and time). It is important to // create a new cell style from the workbook otherwise you can end up // modifying the built in style and effecting not only this cell but // other cells. CellStyle cellStyle = wb.createCellStyle(); cellStyle.setDataFormat(createHelper.createDataFormat().getFormat( "m/d/yy h:mm")); cell = row.createCell(1); cell.setCellValue(new Date()); cell.setCellStyle(cellStyle); // you can also set date as java.util.Calendar CellStyle cellStyle1 = wb.createCellStyle(); cellStyle1.setDataFormat(createHelper.createDataFormat().getFormat( "yyyyMMdd HH:mm:ss")); cellStyle1.setBorderBottom(CellStyle.BORDER_THIN); cellStyle1.setBottomBorderColor(IndexedColors.BLACK.getIndex()); cellStyle1.setBorderLeft(CellStyle.BORDER_THIN); cellStyle1.setLeftBorderColor(IndexedColors.GREEN.getIndex()); cellStyle1.setBorderRight(CellStyle.BORDER_THIN); cellStyle1.setRightBorderColor(IndexedColors.BLUE.getIndex()); cellStyle1.setBorderTop(CellStyle.BORDER_MEDIUM_DASHED); cellStyle1.setTopBorderColor(IndexedColors.BLACK.getIndex()); cell = row.createCell(4); cell.setCellValue(Calendar.getInstance()); cell.setCellStyle(cellStyle1); FileOutputStream fileOut = new FileOutputStream("e:/test/workbook.xls"); wb.write(fileOut); fileOut.close(); } |
讀取excel文件的內容:
public static void readExcel() throws InvalidFormatException, IOException { // Use a file Workbook wb1 = WorkbookFactory.create(new File("e:/test/userinfo.xls")); Sheet sheet = wb1.getSheetAt(0); // Decide which rows to process // int rowStart = Math.min(10, sheet.getFirstRowNum()); // int rowEnd = Math.max(40, sheet.getLastRowNum()); int rowStart = sheet.getLastRowNum(); int rowEnd = sheet.getLastRowNum() + 1; logger.info(sheet.getFirstRowNum()); logger.info(sheet.getLastRowNum()); for (int rowNum = rowStart; rowNum < rowEnd; rowNum++) { Row r = sheet.getRow(rowNum); int lastColumn = Math.max(r.getLastCellNum(), 10); logger.info(lastColumn); // To get the contents of a cell, you first need to know what kind // of cell it is (asking a string cell for its numeric contents will // get you a NumberFormatException for example). So, you will want // to switch on the cell's type, and then call the appropriate // getter for that cell. for (int cn = 0; cn < lastColumn; cn++) { // Cell cell = r.getCell(cn, Row.RETURN_BLANK_AS_NULL); Cell cell = r.getCell(cn); switch (cell.getCellType()) { case Cell.CELL_TYPE_STRING: logger.info(cell.getRichStringCellValue().getString()); break; case Cell.CELL_TYPE_NUMERIC: if (DateUtil.isCellDateFormatted(cell)) { logger.info(cell.getDateCellValue()); } else { logger.info(cell.getNumericCellValue()); } break; case Cell.CELL_TYPE_BOOLEAN: logger.info(cell.getBooleanCellValue()); break; case Cell.CELL_TYPE_FORMULA: logger.info(cell.getCellFormula()); break; default: logger.info("empty"); } } } } |
我們的程序要做的事情是:根據第一行標題的順序來讀取每一行文件的內容,實際標題和內容的順序是不確定的,但是我們要求按照給定的順序輸出文件內容。
代碼如下:
public static void readUserInfo() throws InvalidFormatException, IOException { String[] titles = { "收費編號", "收費性質", "姓名", "家庭住址", "工作單位", "電話", "手機", "小區樓號", "單元號", "樓層", "房間號", "建筑面積(㎡)", "面積依據", "A面積", "A超", "A輕體", "B面積", "B超", "B輕體", "用戶編號", "所屬樓前表表號" }; //用來存儲標題和順序的map,key為標題,value為順序號 Map<String, Integer> titleMap = new HashMap<String, Integer>(); //將既定順序寫入map for (int i=0 ; i<titles.length; i++) { titleMap.put(titles[i], i); } Workbook wb = WorkbookFactory.create(new File("e:/test/userinfo.xls")); for (int numSheet = 0; numSheet < wb.getNumberOfSheets(); numSheet++) { Sheet xSheet = wb.getSheetAt(numSheet); if (xSheet == null) { continue; } // 獲取第一行的標題內容 Row tRow = xSheet.getRow(0); //存儲標題順序的數組 Integer[] titleSort = new Integer[tRow.getLastCellNum()]; //循環標題 for (int titleNum = 0; titleNum < tRow.getLastCellNum(); titleNum++) { Cell tCell = tRow.getCell(titleNum); String title = ""; if (tCell == null || "".equals(tCell)) { } else if (tCell.getCellType() == XSSFCell.CELL_TYPE_BOOLEAN) {// 布爾類型處理 // logger.info(xCell.getBooleanCellValue()); } else if (tCell.getCellType() == XSSFCell.CELL_TYPE_NUMERIC) {// 數值類型處理 title = doubleToString(tCell.getNumericCellValue()); } else {// 其他類型處理 title = tCell.getStringCellValue(); } //通過獲取的標題,從map中讀取順訊號,寫入保存標題順序號的數組 Integer ts = titleMap.get(title); if (ts != null) { titleSort[titleNum] = ts; } } // 循環行Row for (int rowNum = 1; rowNum < xSheet.getLastRowNum() + 1; rowNum++) { Row xRow = xSheet.getRow(rowNum); if (xRow == null) { continue; } // 循環列Cell String[] v = new String[titleSort.length]; for (int cellNum = 0; cellNum < titleSort.length; cellNum++) { Cell xCell = xRow.getCell(cellNum); String value = ""; if (xCell == null || "".equals(xCell)) { } else if (xCell.getCellType() == XSSFCell.CELL_TYPE_BOOLEAN) {// 布爾類型處理 logger.info(xCell.getBooleanCellValue()); } else if (xCell.getCellType() == XSSFCell.CELL_TYPE_NUMERIC) {// 數值類型處理 value = doubleToString(xCell.getNumericCellValue()); } else {// 其他類型處理 value = xCell.getStringCellValue(); } //按照標題順序的編號來存儲每一行記錄 v[titleSort[cellNum]] = value; // logger.info("v[" + titleSort[cellNum] + "] = " + v[titleSort[cellNum]]); } //循環結果數組,獲取的與既定順序相同 for (int i = 0; i < v.length; i++) { logger.info(v[i]); } } } } |
上段程序中用到的工具類doubleToString(將excel中的double類型轉為String類型,處理了科學計數法形式的數):
private static String doubleToString(double d) { String str = Double.valueOf(d).toString(); // System.out.println(str); String result = ""; if (str.indexOf("E") > 2) { int index = str.indexOf("E"); int power = Integer.parseInt(str.substring(index + 1)); BigDecimal value = new BigDecimal(str.substring(0, index)); value = value.movePointRight(power); result = value.toString(); } else { if (str.indexOf(".0") > 0) result = str.substring(0, str.indexOf(".0")); else result = str; } return result; } |
目前對于POI的應用只限于此,并沒有再深入,以后寫了新的相關內容會繼續補充,請大大們批評指正!
1、需求分析前的準備
在
軟件開發過程中,需求分析可以說是核心任務之一,就像一支將要遠航的船隊,要在指定時間內到達目錄地,他們需要一條正確的航線,才能到達目的地,如果航線有誤,他們將會誤時到達,或是不回到原位將永遠到達不了,這么重要的東西,但在國內很多團隊中缺少,雖然我也做了一些,但在項目完成的時候,回頭看看,其實我們做了很多不必要的事,浪費了很多時間、人力和物力,為保證在今后的開發中減少這些錯誤的發生,現將一些問題記錄下來。
為了了解系統需求,先可以從概要式的需求著手,再細化需求,需求分析必須擬定文檔,在寫文檔之前我們必須做好尋求分析的范圍,總結為以下幾點:
1.1要做一個什么樣的系統
這個不說,我想做軟件開發的人都知道,擬定這個后,一切才可以擴展開,比如我們要做一個B2C的商城,要賣母嬰用品,知道了這些,我們就可以找現在網站有的B2C網站做參考,分析系統構架,系統功能等。
1.2系統將要在什么樣的環境下進行
我上次經歷的一個系統,就是要用asp.net重新發一個B2C商城,但有一些前提條件,以前公司有網站,是用java+MYSQL開發的,但我們開發的新系統必須兼容以前的數據,如客戶信息,商品信息,還有一些資源信息,并且還要兼容
Google,baidu收錄的地址路徑,還有與原ERP的通訊等條件,這樣讓我們的開發很受限制,這些需求就是這樣,你無法改變,所以在設計新系統的同時你必須考慮,要花時間去了解以前系統的功能,接口等,如果不了解,等你把新系統開發完了才發現系統脫離了公司原有的業務流程,讓公司無法運作,那就代表你開發的系統根本沒有價值,我想這不是我們想要的結果。
1.3要解決哪些問題
開發出來軟件系統就是為了解決客戶需求的,一個B2C網站就是賣商品,主要由客戶、商品、購物車、定單組成,將這些核心的功能定義好,我想其它的意外都不會太影響到整個系統的進程。
1.4將來可能會有哪些變化
面對將來的發展,我們也許不能完全考慮到,但與公司的戰略發展,可以提前考慮些,能想到多少就想多少,多多益善,我們開發一個系統不是只滿足當前的需求,如果眼光只放在眼前,那么你這個系統很快就會被淘汰,功能也許不需要現在實現,但接口總得留下吧,不然想改進都是很困難的事,如果一個稍微的小需求都要動系統構架,我想這個系統會越來越不穩定,作為系統分析師,這塊也是至關重要的。
1.5系統可以維持任務的周期是多少
系統周期與公司戰略發展是緊扣的,一個系統的功能不可能隨著社會的變化,能一直滿足市場需要的,在設計系統的時候,可以了解一下公司的戰略發展,比如公司三年之內要做成什么樣,客戶多少,網站瀏量,可以做下評估,這樣就考慮系統構架的問題,你開始就準備構架一個大胖子,但現在需求簡單,在實際的運行中,速度緩慢,其實你構架越復雜,系統運行就越緩慢,雖說現在很多大系統運行的都很好,但要想想,人家服務器,網絡構架是什么樣的,你不可能讓你的系統一線就有這么好的環境,就算有,那成本也太大了,一般的公司也吃不消。
1.6系統分幾個階段實施
在開發初期,我們不可能將系統所有的功能都能完成的很好,為了加快開進度,為了系統能盡早上線,我們得像建樓一樣,分階段進行,分段實施,如果我們現在只是要在網上賣商品,那我們就得把客戶管理、商品管理、購物車、定單管理這幾大塊實現,把一個系統根基打好,誰都想讓自己的系統變成最強大的系統,但這個想法幾乎是不可能完成的,如果我們把根基打好了,再在上面加以改進,添磚添瓦,根據客戶或市場的需要來完善,我想這個系統就會慢慢變成一個成功的系統,對于B2C網站來說,能完成商業的需要,能讓公司的流程走順,那就是個好系統,沒有最好的系統,只有最適合的系統。
分階段實施,可以有節約成本,也可以加快實施速度,不管是作為公司的管理人員還是開發人員,能盡快看到成果,會提高信心,可以舉個例子,在設計一個B2C商城的時候,我們除了客戶管理、商品管理、購物車、定單管理外,還要加入廣告管理、促銷管理、CPS、統計管理、用戶積分、虛擬幣、禮品、物流、接口等一些功能,如果開發周期只給兩個月,四個人,從系統設計到系統上線,怎么做?怎樣如期完成呢?如果你的團隊都沒接觸過B2C這樣的系統,開發起來是很難度的,在這樣的情況下,我們必須分段實施,抓主干,把核心的東西完成了,系統可以上線,雖然沒有理想的那么強大,但最少它能賺錢,再一個兩個月可以把客戶管理、商品管理、購物車、定單管理這幾塊主要的功能完善,公司業務可以進行,后面的功能雖然很有必要,但也可以分個先后,系統上線了,能給大家看到東西,能用用,建議也會多些,對于系統的優化改進,這個是無止盡的,如果沒有這些基本的東西,天天都會有人在你耳邊叫,你們什么時候上線呀,做了這么久,做的怎么樣了,讓你的團隊心里承受著很大的壓力,就算你在兩個月內把開發任務完成了,那你的
測試通的過嗎,功能越多,問題越多,在后期維護問題越多,最后煩了,沒辦法,重構,那樣不是虧大了。
在一個新的環境中,一個新的團隊,你說要在某一時間段里完成什么樣的系統,你怎樣做到讓領導相信你,讓公司相信你,一個大一點的軟件系統,少則幾個月,再多一點就一年半載,他們能等嗎,再說了他們不懂代碼,不會天天跟你的屁股后面問你,系統怎么樣了,做了哪些,就算這樣,我想你也進了瘋人院了,所以我們做系統要打好第一槍,這樣才會得到更多人的支持和理解,如果你不能理解,可以去看看商殃變法中的《徒木立信》的典故。
至于軟件第一開發第一階段要做哪些事,這個要根據一個系統的核心功能去了解,只有建立好了框架,不要太急于求成,沒什么好處,把根基打好了,再想怎么包裝,都不是件難事。
1.8系統開發團隊由哪些人組成
一個好的團隊,必定是發揮了團隊中每個人的優勢,在開發團隊中,不是你技術能力強,你就是最有價值的人,我相信在開發團隊里沒有一個從頭到尾都能支持的能人,不是不沒,是我是覺得不可能存在,也許我么說有些人不服,其實我這么說也有我的理由,一個人也許有機會經歷團隊中的每個環節,并且都能深入,但絕對不是一個機會,如果有,那就是一個人的開發,一個人的開發我想也不能叫團隊,有時候,一個人什么都能做,多了一個人,什么都做不好,但面對大的項目,不得不進行團隊合作。
我所在的公司,我進去的時候,接到項目任務,我開始還有些心虛,因為有些工作我也沒接觸過,但又不得不去做,但我很意外的時候,我們的團隊中有一位項目助理,她的出現讓我們的團隊協調管理得到了很好的實施,計劃任務,可以做到很好的按排,但跟蹤管理,我能收集分配,但指定到人后,我很難看到進展的情況,因為自身還有很多的工作,開始我部署了項目管理系統的,收集需求和BUG,也指定到人,但反饋往往不及時,因為我有時候隔一天才上去看,后來我將這項目工作交給了項目助理,讓她去管理這些,我發現她做的很好,她每天和我只花幾分鐘的時間做核對,出現意外情況我就出現解決,她的出現把我和團隊中的每個開發人員的工作連接起來,讓項目管理得以順利的實施。
開發團隊具體由哪些人組成,這是要根據公司實力,項目進度和項目大小來定的,現在說幾個工作職則,可來靈活分配一下:
項目經理:對項目的決策性問題進行定位,一個功能做與不做,領導說的算
構架師:控制技術問題,解決技術難題,對分配下來的任務進行分析、評估,反饋給項目經理,再進行確定
項目助理:記錄團隊會議內容,協調工作中的日常事務
開發組長:調配開發組員,輔助組內開發人員并對成員工作進行監管,一般由主程擔任
開發人員:負責編寫代碼,按需求完成任務
測試人員:對功能進行測試
如果這里的每項目工作按排到個人,我想開發團隊的協調管理最好。
1.9系統運行環境是什么樣的
在系統構架時,根據需要定義好,系統構架、程序環境、網絡環境,如考慮分布式存儲,日均訪問量、系統安全、成本預算等。
asp.net的開發成本是要比java的開成本低的。
Sql server的運營成本是要oracle低的,但oracle在大型數據處理上要優于SQL Server,如果是SNS站我覺得上Oracle會好些。
選擇什么樣的環境,在沒有特定要求的情況下,根據團隊的現狀去考慮我覺得就差不多了。
我們有了目的地將要遠航,那么就得需要航海圖、船、船長、舵手、水手、水和食物,雖然這樣我們能保證100%完成任務,因為大海中的意外誰也不會知曉,但我們理想的是我們能安全到達,如果條件不允許,就算我們知道目的地在哪,出了海,我們將面對是一場艱辛冒險旅程。
2、收集需求
需求的收集是個很繁瑣的過程,收集的不夠,開發過程中變化會很多,特別是你上了一個演示版本后,開始別人一點意見都沒,一看你的演示,你就意見一大堆,這樣的問題我想在很多項目中都出現過,所以先在收集需求的時候要和客戶或相關部門一一確認,我們考慮需求要從種兩種角度去考慮,一種是用戶角度,另一種是開發者角度,所以在談需求時,必須邊聊邊記,把所談的話記錄整理,如果怕遺漏,可以錄音,然后將采用文檔的方式表達出來,將提出的需求加以分析,做下技術評估,如果有特別的難題可以提前讓開發人員做技術預研,在做評估后,需要分段實施的,就做好規劃,然后和提需求的人員確認,需求文檔的功能可以多寫點,根據企業的發展,能考慮的都考慮,這樣可以在系統構架時,定位系統的生命周期時,給以更多的參考,在需求定出階段后,我們得把要馬上實施的功能放在當前,加以強化、細化,反復的進行,條件允許的時候應該做些Demo來確認。
1、新建測試項目:
2、生成TestSuite以及LoadTest
以上操作完成以后項目如下:
開始測試:
雙擊LoadTest1,如下圖:
點擊左上角綠色三角形即可開始測試
上圖中參數設置參見:http://blog.sina.com.cn/s/blog_59ee85870101o1nz.html
TestNG的英文為
Test Next Generation, 聽上去好像下一代
測試框架已經無法正常命名了的樣子,哈哈,言歸正傳,啥是TestNG呢,它是一套測試框架,在原來的Junit框架的思想基礎上開發的新一代測試框架,既然這么牛b,那果斷弄來試試。本文主要從安裝步驟-->第一個測試例子-->再多一點例子-->框架分析-->suite文件的書寫-->總結結束。
安裝步驟:
1. 第一步,當然首先是在你的
java sdk, eclipse ide, system environment,都已經配置好了的情況下進行, 這些本人早就搭建好了,為了體現手把手教學,這里附加上本人的開發環境參數:os: win 8, java_version: 1.7, path: (added), eclipse_version: 4.3.1, 好了,其實只要裝好這些就行了,版本么,再說,哈哈,開工
2. 第二步,去官網download一個TestNG插件,這個
工作在eclipse內完成,點擊help->install new software,緊接著填上http://beust.com/eclipse
然后一路next到finish。好了TestNG插件裝上了,為了check一下是否正常工作,新建一個空的工程,然后再新建一個一個TestNG類試一下,如果能夠正常建立,那么就成功了,步驟:file->new->Other,會看到
如果這個看到了,那么okay,恭喜你,可以開工寫測試的case了,至此,環境搭建完成。
第一個測試例子:
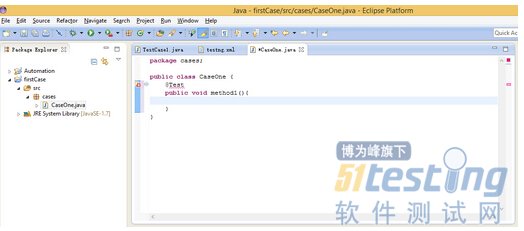
點擊src包上右擊,新建一個類,->new->class,包名就叫cases吧,類名就叫CaseOne吧不要main方法,然后finish
寫第一個TestNG的帶有@Test的方法如圖
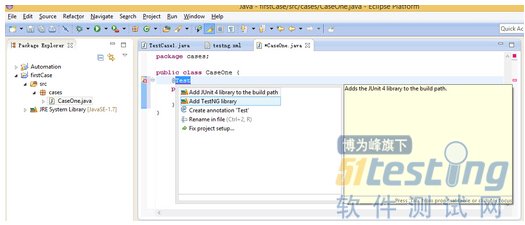
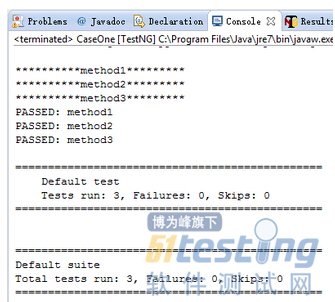
這樣前面的case沒通過,后面的當然也不會過,比如將注釋掉的那句代碼去掉就不會通過執行后面兩case了。
我們還可以對method進行分組,如
@Test(groups={"group1"})
這樣就不用像方法3那樣倚賴寫一大串了,只需要一個group的名字便可以了。
框架分析
再來看看別的annotation吧!上代碼
package cases; import org.testng.annotations.AfterClass; import org.testng.annotations.AfterMethod; import org.testng.annotations.AfterTest; import org.testng.annotations.BeforeClass; import org.testng.annotations.BeforeMethod; import org.testng.annotations.BeforeTest; import org.testng.annotations.Test; public class TestCase2 { @BeforeTest public void setUp(){ System.out.println("*******before********"); } @BeforeMethod public void beforeMethod(){ System.out.println("*******beforeMethod********"); } @AfterMethod public void afterMethod(){ System.out.println("*******aftermethod********"); } @Test public void t1(){ System.out.println("*********t1**********"); } @Test public void t2(){ System.out.println("*********t2**********"); } @BeforeClass public void beforeClass(){ System.out.println("*****beforeClass*****"); } @AfterClass public void afterClass(){ System.out.println("*****afterClass*****"); } @AfterTest public void finish(){ System.out.println("*******finish********"); } } |
運行得到結果如下
*******before******** *****beforeClass***** *******beforeMethod******** *********t1********** *******aftermethod******** *******beforeMethod******** *********t2********** *******aftermethod******** *****afterClass***** *******finish******** PASSED: t1 PASSED: t2 =============================================== Default test Tests run: 2, Failures: 0, Skips: 0 =============================================== |
這樣一來咱們就大概的知道了不同的annotation下的方法的執行順序了。基本上是@BeforeTest->@BeforeClass->(@BeforeMethod->@Test->@AfterTest)->...重復()內內容...->@AfterClass->@AfterTest.好了,框架基本如下,
再多一點例子:
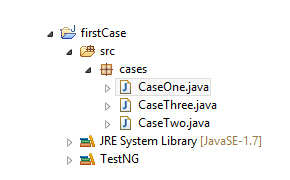
同時建立多個Class,如
如果全部選中,當然會從上當下的執行,但是萬一有些文件我們不想執行呢,比如CaseOne中的method1我們想跳過去,那就得寫一個控制文件了,在TestNG中使用xml來控制,在頂級目錄下建一個build.xml文件,內容如下
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE suite SYSTEM "http://testng.org/testng-1.0.dtd"> <suite name="My Sample Suite"> <test name="First test"> <classes> <class name="cases.CaseOne"></class> </classes> </test> <test name="Second test"> <classes> <class name="cases.CaseTwo"></class> </classes> </test> <test name="Third test"> <classes> <class name="cases.CaseThree"></class> </classes> </test> </suite> 這是按類寫的,當然你可以寫的更詳細,指定方法 <?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE suite SYSTEM "http://testng.org/testng-1.0.dtd"> <suite name="My Sample Suite"> <test name="First test"> <classes> <class name="cases.CaseOne"></class> <methods> <include name="method1"/> <include name="method2"/> </methods> </classes> </test> <test name="Second test"> <classes> <class name="cases.CaseTwo"></class> </classes> </test> <test name="Third test"> <classes> <class name="cases.CaseThree"></class> </classes> </test> </suite> |
這樣類CaseOne中的第三個方法會掠過去不執行。
總結:
在我看來,TestNG是一個非常好用的測試框架,其測試步驟順序很規范,很強大,當然還有很多東西要去探索。筆者水平較淺,不足之處,大家海涵!
通俗的講,Wap是
手機網頁瀏覽器使用的網頁,
web是電腦網頁瀏覽器使用的網頁。(講得不專業,但方便理解)
在手機上顯示的網頁不一定能在電腦上正常顯示,有些web服務器會對瀏覽器版本進行判斷,并返回信息,如下圖是在電腦上打開wap的url提示。
掃描器如果不能正常訪問,是不能正常掃描,需要修改user-agent string。把這個參數改成手機瀏覽器,下圖是從firefox上截圖。參數可以參考這里的值。
HP webinspect 10的參數修改方法,新建一個任務后,會有如下頁面,選擇advanced,進入設置對話框,
在Cookies/Headers中添加一個參數
User-Agent: Mozilla/5.0 (
Windows NT 6.1; WOW64) AppleWebKit/537.31 (KHTML, like Gecko) Chrome/26.0.1410.43 BIDUBrowser/6.x Safari/537.31
設置完后,就可以在HP Webinspect的瀏覽器中顯示手機的網頁,這里拿
百度為例。
http://m.baidu.com/?from=844b&pu=sz%401321_480&wpo=fast