
下面是stackoverflow中關于數組方法的相關問題中,獲得最多票數的12個數組操作方法。
1. 聲明一個數組
String[] aArray = new String[5];
String[] bArray = {"a","b","c", "d", "e"};
String[] cArray = new String[]{"a","b","c","d","e"};
2. 輸出一個數組
int[] intArray = { 1, 2, 3, 4, 5 };
String intArrayString = Arrays.toString(intArray);
// print directly will print reference value
System.out.println(intArray);
// [I@7150bd4d
System.out.println(intArrayString);
// [1, 2, 3, 4, 5]
3. 從一個數組創建數組列表
String[] stringArray = { "a", "b", "c", "d", "e" };
ArrayList<String> arrayList = new ArrayList<String>(Arrays.asList(stringArray));
System.out.println(arrayList);
// [a, b, c, d, e]
4. 檢查一個數組是否包含某個值
String[] stringArray = { "a", "b", "c", "d", "e" };
boolean b = Arrays.asList(stringArray).contains("a");
System.out.println(b);
// true
5. 連接兩個數組
int[] intArray = { 1, 2, 3, 4, 5 };
int[] intArray2 = { 6, 7, 8, 9, 10 };
// Apache Commons Lang library
int[] combinedIntArray = ArrayUtils.addAll(intArray, intArray2);
6. 聲明一個內聯數組(Array inline)
method(new String[]{"a", "b", "c", "d", "e"});
7. 把提供的數組元素放入一個字符串
// containing the provided list of elements
// Apache common lang
String j = StringUtils.join(new String[] { "a", "b", "c" }, ", ");
System.out.println(j);
// a, b, c
8. 將一個數組列表轉換為數組
String[] stringArray = { "a", "b", "c", "d", "e" };
ArrayList<String> arrayList = new ArrayList<String>(Arrays.asList(stringArray));
String[] stringArr = new String[arrayList.size()];
arrayList.toArray(stringArr);
for (String s : stringArr)
System.out.println(s);
9. 將一個數組轉換為集(set)
Set<String> set = new HashSet<String>(Arrays.asList(stringArray));
System.out.println(set);
//[d, e, b, c, a]
10. 逆向一個數組
int[] intArray = { 1, 2, 3, 4, 5 };
ArrayUtils.reverse(intArray);
System.out.println(Arrays.toString(intArray));
//[5, 4, 3, 2, 1]
11. 移除數組中的元素
int[] intArray = { 1, 2, 3, 4, 5 };
int[] removed = ArrayUtils.removeElement(intArray, 3);//create a new array
System.out.println(Arrays.toString(removed));
12. 將整數轉換為字節數組
byte[] bytes = ByteBuffer.allocate(4).putInt(8).array();
for (byte t : bytes) {
System.out.format("0x%x ", t);
}
前幾天看了一下Spring的部分源碼,發現回調機制被大量使用,覺得有必要把Java回調機制的理解歸納總結一下,以方便在研究類似于Spring源碼這樣的代碼時能更加得心應手。
注:本文不想扯很多拗口的話來充場面,我的目的是希望以最簡明扼要的語言將Java回調的大概機制說清楚。好了,言歸正傳。
一句話,回調是一種雙向調用模式,什么意思呢,就是說,被調用方在被調用時也會調用對方,這就叫回調。“If you call me, i will call back”。
不理解?沒關系,先看看這個可以說比較經典的使用回調的方式:
class A實現接口InA ——背景1
class A中包含一個class B的引用b ——背景2
class B有一個參數為InA的方法
test(InA a) ——背景3
A的對象a調用B的方法傳入自己,test(a) ——這一步相當于you call me
然后b就可以在test方法中調用InA的方法 ——這一步相當于i call you back
是不是清晰一點了?下面再來看一個完全符合這個方式模板的例子
(PS:這個例子來源于網絡,由于這個例子表現的功能極度拉風,令我感覺想想出一個超越它的例子確實比較困難,所以直接搬過來)
//相當于接口InA public interface BoomWTC{ //獲得拉登的決定 public benLaDengDecide(); // 執行轟炸世貿 public void boom(); } //相當于class A public class At$911 implements BoomWTC{//相當于【背景1】 private boolean decide; private TerroristAttack ta;//相當于【背景2】 public At$911(){ Date now=new Date(); SimpleDateFormat myFmt1=new SimpleDateFormat("yy/MM/dd HH:mm"); this.dicede= myFmt.format(dt).equals("01/09/11 09:44"); this.ta=new TerroristAttack(); } //獲得拉登的決定 public boolean benLaDengDecide(){ return decide; } // 執行轟炸世貿 public void boom(){ ta.attack(new At$911);//class A調用class B的方法傳入自己的對象,相當于【you call me】 } } //相當于class B public class TerroristAttack{ public TerroristAttack(){ } public attack(BoomWTC bmw){——這相當于【背景3】 if(bmw.benLaDengDecide()){//class B在方法中回調class A的方法,相當于【i call you back】 //let's go......... } } } |
現在應該對回調有一點概念了吧。
可是問題來了,對于上面這個例子來說,看不出用回調有什么好處,直接在調用方法不就可以了,為什么要使用回調呢?
事實上,很多需要進行回調的操作是比較費時的,被調用者進行費時操作,然后操作完之后將結果回調給調用者。看這樣一個例子:
//模擬Spring中HibernateTemplate回調機制的代碼 interface CallBack{ public void doCRUD(); } public class HibernateTemplate { public void execute(CallBack action){ getConnection(); action.doCRUD(); releaseConnection(); } public void add(){ execute(new CallBack(){ public void doCRUD(){ System.out.println("執行add操作..."); } }); } public void getConnection(){ System.out.println("獲得連接..."); } public void releaseConnection(){ System.out.println("釋放連接..."); } } |
可能上面這個例子你不能一眼看出個所以然來,因為其實這里A是作為一個內部匿名類存在的。好,不要急,讓我們把這個例子來重構一下:
interface CallBack{ //相當于接口InA public void doCRUD(); } public class A implements CallBack{//【背景1】 private B b;//【背景2】 public void doCRUD(){ System.out.println("執行add操作..."); } public void add(){ b.execute(new A());//【you call me】 } } public class B{ public void execute(CallBack action){ //【背景3】 getConnection(); action.doCRUD(); //【i call you back】 releaseConnection(); } public void getConnection(){ System.out.println("獲得連接..."); } public void releaseConnection(){ System.out.println("釋放連接..."); } } |
好了,現在就明白多了吧,完全可以轉化為上面所說的回調使用方式的模板。
現在在來看看為什么要使用回調,取得連接getConnection();是費時操作,A希望由B來進行這個費時的操作,執行完了之后通知A即可(即所謂的i call you back)。這就是這里使用回調的原因。
在網上看到了一個比喻,覺得很形象,這里借用一下:
你有一個復雜的問題解決不了,打電話給你的同學,你的同學說可以解決這個問題,但是需要一些時間,那么你不可能一直拿著電話在那里等,你會把你的電話號碼告訴他,讓他解決之后打電話通知你。回調就是體現在你的同學又反過來撥打你的號碼。
結合到前面所分析的,你打電話給你同學就是【you call me】,你同學解決完之后打電話給你就是【i call you back】。
怎么樣,現在理解了吧?
---------------------------------以下為更新----------------------------------
看了有些朋友的回帖,我又思考了一下,感覺自己之前對回調作用的理解的確存在偏差。
下面把自己整理之后的想法共享一下,如果有錯誤希望指出!多謝!
先說上面這段代碼,本來完全可以用模板模式來進行實現:
public abstract class B{ public void execute(){ getConnection(); doCRUD(); releaseConnection(); } public abstract void doCRUD(); public void getConnection(){ System.out.println("獲得連接..."); } public void releaseConnection(){ System.out.println("釋放連接..."); } } public class A extends B{ public void doCRUD(){ System.out.println("執行add操作..."); } public void add(){ doCRUD(); } } public class C extends B{ public void doCRUD(){ System.out.println("執行delete操作..."); } public void delete(){ doCRUD(); } } 如果改為回調實現是這樣的: interface CallBack{ public void doCRUD(); } public class HibernateTemplate { public void execute(CallBack action){ getConnection(); action.doCRUD(); releaseConnection(); } public void add(){ execute(new CallBack(){ public void doCRUD(){ System.out.println("執行add操作..."); } }); } public void delete(){ execute(new CallBack(){ public void doCRUD(){ System.out.println("執行delete操作..."); } }); } public void getConnection(){ System.out.println("獲得連接..."); } public void releaseConnection(){ System.out.println("釋放連接..."); } } |
可見摒棄了繼承抽象類方式的回調方式更加簡便靈活。不需要為了實現抽象方法而總是繼承抽象類,而是只需要通過回調來增加一個方法即可,更加的直觀簡潔靈活。這算是回調的好處之一。
下面再給出一個關于利用回調配合異步調用的很不錯的例子
回調接口:
public interface CallBack { /** * 執行回調方法 * @param objects 將處理后的結果作為參數返回給回調方法 */ public void execute(Object... objects ); } 消息的發送者: /** * 這個類相當于你自己 */ public class Local implements CallBack,Runnable{ private Remote remote; /** * 發送出去的消息 */ private String message; public Local(Remote remote, String message) { super(); this.remote = remote; this.message = message; } /** * 發送消息 */ public void sendMessage() { /**當前線程的名稱**/ System.out.println(Thread.currentThread().getName()); /**創建一個新的線程發送消息**/ Thread thread = new Thread(this); thread.start(); /**當前線程繼續執行**/ System.out.println("Message has been sent by Local~!"); } /** * 發送消息后的回調函數 */ public void execute(Object... objects ) { /**打印返回的消息**/ System.out.println(objects[0]); /**打印發送消息的線程名稱**/ System.out.println(Thread.currentThread().getName()); /**中斷發送消息的線程**/ Thread.interrupted(); } public static void main(String[] args) { Local local = new Local(new Remote(),"Hello"); local.sendMessage(); } public void run() { remote.executeMessage(message, this); //這相當于給同學打電話,打完電話之后,這個線程就可以去做其他事情了,只不過等到你的同學打回電話給你的時候你要做出響應 } } |
消息的接收者:
/** * 這個類相當于你的同學 */ public class Remote { /** * 處理消息 * @param msg 接收的消息 * @param callBack 回調函數處理類 */ public void executeMessage(String msg,CallBack callBack) { /**模擬遠程類正在處理其他事情,可能需要花費許多時間**/ for(int i=0;i<1000000000;i++) { } /**處理完其他事情,現在來處理消息**/ System.out.println(msg); System.out.println("I hava executed the message by Local"); /**執行回調**/ callBack.execute(new String[]{"Nice to meet you~!"}); //這相當于同學執行完之后打電話給你 } } |
由上面這個例子可見,回調可以作為異步調用的基礎來實現異步調用。
git作為源碼管理工具出于流行趨勢。這里和大家一起分享下我們是如何用git的分支(branch)功能管理不同規模的項目
小型項目
推薦工具:TortoiseGit
開發階段(第一版上線前):2個分支 develop和master
由于是項目參與人員不多,基本上很少會有不同角色的人員出現職責沖突,需求變更也不會很繁冗。這種情況值我們只需要主要功能分支。
其中develop負責開發版本,master相當于預上線版本。
develop過程如果出現代碼沖突,手工merge就好。
開發階段(第一版上線后):3個分支 develop、master、hotfix
多處于來的hotfix用于緊急上線(bug,新需求等)。hotfix基于master,因為develop已經越走越遠,基于develop的hotfix會將帶上一些當前不想上線的新功能。
hotfix完成后hotfix要merge到master上,因為線上不管何種情況都是master版本。qa完成
測試并且上線后要將master版本merge到develop避免hotfix的修改在develop中丟失。
維護階段(停止常規開發):2個分支 master、hotfix。
這個階段就相當于針對上線版本的各種打補丁了。
中型項目
推薦工具: sourcetree
開發階段(第一版上線前):3個分支 feature、develop和master
相對于小型項目多了feature分支的概念。feature分支基于develop分支,當功能開發完成后merge回develop。
這樣做的好處是將develop分支從小型項目中去中心化。舉個例子,因為是中型項目,我們可能有5 6個在并行開發,如果這個過程中客戶說某個功能我們不要了,我們可以很輕松的丟掉某個feature分支而不必污染develop。
但是如果是開發時間很久的feature分支,很可能會因為不定時的merge develop或者需求的不斷變更等導致當前分支的commit比較骯臟。所以對于feature分析的力度要控制好。
如圖所示:
開發階段(第一版上線后):4個分支 feature、develop、master和hotfix
和上面小心項目一樣 hotfix基于master版本。
維護階段(停止常規開發): 和小型項目一樣 大型項目
推薦工具:sourcetree
大型項目相對于中型項目又多了release版本。這個版本的作用只要是控制需求的更新以及當前版本bug的fix處理。
點擊查看大圖:
對于這種情景sourcetree自帶git-flow的功能
并且給出各種引導提示
和中型項目相比,hotfix分支在大型項目中只處理線上的bug問題。對于需求的控制,都會發生在release分支中。一個release版本的生成并不意味著它可以直接提交master,qa的介入在中小型項目中屬于master分支,
但是在這個流程下,qa的介入屬于release分支,包括對于bug的修復操作也是直接在release版本完成。當qa對于release版本確認完成后,release版本merge到master預上線并且merge回develop保持代碼一致性。
2007年8月13日,在剛剛開始我
工作的第七個年頭時,終于順利的進入了M公司,并得到了一個
測試管理方面的職位。雖然之前的六年工作中,我一直在偏技術和偏管理的角色中游移,自信自己在兩個方面都有一些積累,足以勝任技術管理工作。可是在M公司的這一個半月,的確又真的讓我重新開始思考自己的工作。
零零碎碎想到一些東西,先寫下來,以后繼續慢慢補充,也歡迎大家一起討論。另外,雖然我的視角是從 Test Team 的角度出發的,但是也應該可以適用于其他想進一步提升自己價值的Team。
在大多數情況下,Test Team并不是以軟件的直接生產者的身份出現的,而是作為一個附屬的功能團隊承擔開發過程中的一部分職責。這也決定了Test Team 的工作并不不能直接的體現出價值,而是只有當Test Team的工作成果被其他人或Team所使用,為其他人或Team帶來價值時,才能真正的體現出Test Team的價值。
換句話說,當我們的“產品”能夠服務于他人時,我們的工作才有了價值;而當接受或使用我們的“服務”的組織越多時,則我們的Test Team的價值也就越大。
舉個例子。當一個 Test Team 僅僅認為自己的工作只是“盡早的找到bug,并確認每個bug都得到合理的解決(這是對
軟件測試工作的經典定義)”時,一個Test Team產生的價值僅僅作用于某個Develop Team甚至某個Developer。這時,Test Team的大多數工作都屬于Team內部的工作,與其他Team的接口可能僅僅限于一個bug tracking system,所產生交互的工作也僅僅限于對bug的討論和狀態的跟蹤。這種情況下的 Test Team的工作甚至存在的理由都無法被項目之外或部門之外的人或組織所了解。
但是當我們留意到我們可以為整個項目中的多個Team,甚至整個部門的多個項目或者企業中的多個部門提供我們的“服務”時,一切都會變得完全不同了。例如
為項目團隊提供每個版本的bug趨勢分析數據,讓項目中的每個人都了解項目當前的狀態
通過分析bug數據來建立或完善各種Checklist,幫助項目團隊更好的完成需求評審、設計評審以及代碼評審,減少bug出現的機會。同時,可以定期將多個項目的Checklist進行合并,使單個項目的經驗可以通過Test Team快速的流動起來,及時的作用于其他項目
主動為Architect Team提供每個項目的
性能測試數據,幫助他們獲取更多的實際項目信息,減少踏入“陷阱”的幾率
……
我們可以做得事情還可以有很多,而關鍵在于我們是否有積極主動的與其他部門內或部門外的Team進行溝通,去努力了解他們的工作和需求,并開發我們已有的“產品”所能提供的價值。也只有當我們把自己成功的“推銷”出去,并與更多的Team在工作上有了越來越深的融合,我們為別人提供的價值也越來越大時,我們自己的價值也才會變得越來越大,并且逐漸成為組織中無可替代的部分!
git作為源碼管理工具出于流行趨勢。這里和大家一起分享下我們是如何用git的分支(branch)功能管理不同規模的項目
小型項目
推薦工具:TortoiseGit
開發階段(第一版上線前):2個分支 develop和master
由于是項目參與人員不多,基本上很少會有不同角色的人員出現職責沖突,需求變更也不會很繁冗。這種情況值我們只需要主要功能分支。
其中develop負責開發版本,master相當于預上線版本。
develop過程如果出現代碼沖突,手工merge就好。
開發階段(第一版上線后):3個分支 develop、master、hotfix
多處于來的hotfix用于緊急上線(bug,新需求等)。hotfix基于master,因為develop已經越走越遠,基于develop的hotfix會將帶上一些當前不想上線的新功能。
hotfix完成后hotfix要merge到master上,因為線上不管何種情況都是master版本。qa完成
測試并且上線后要將master版本merge到develop避免hotfix的修改在develop中丟失。
維護階段(停止常規開發):2個分支 master、hotfix。
這個階段就相當于針對上線版本的各種打補丁了。
中型項目
推薦工具: sourcetree
開發階段(第一版上線前):3個分支 feature、develop和master
相對于小型項目多了feature分支的概念。feature分支基于develop分支,當功能開發完成后merge回develop。
這樣做的好處是將develop分支從小型項目中去中心化。舉個例子,因為是中型項目,我們可能有5 6個在并行開發,如果這個過程中客戶說某個功能我們不要了,我們可以很輕松的丟掉某個feature分支而不必污染develop。
但是如果是開發時間很久的feature分支,很可能會因為不定時的merge develop或者需求的不斷變更等導致當前分支的commit比較骯臟。所以對于feature分析的力度要控制好。
如圖所示:
開發階段(第一版上線后):4個分支 feature、develop、master和hotfix
和上面小心項目一樣 hotfix基于master版本。
維護階段(停止常規開發): 和小型項目一樣 大型項目
推薦工具:sourcetree
大型項目相對于中型項目又多了release版本。這個版本的作用只要是控制需求的更新以及當前版本bug的fix處理。
點擊查看大圖:
對于這種情景sourcetree自帶git-flow的功能
并且給出各種引導提示
和中型項目相比,hotfix分支在大型項目中只處理線上的bug問題。對于需求的控制,都會發生在release分支中。一個release版本的生成并不意味著它可以直接提交master,qa的介入在中小型項目中屬于master分支,
但是在這個流程下,qa的介入屬于release分支,包括對于bug的修復操作也是直接在release版本完成。當qa對于release版本確認完成后,release版本merge到master預上線并且merge回develop保持代碼一致性。
<pluginRepositories> <pluginRepository> <id>apache.snapshots</id> <url> http://people.apache.org/repo/m2-snapshot-repository/ </url> </pluginRepository> </pluginRepositories> </dependencies> <dependency> <groupId>org.testng</groupId> <artifactId>testng</artifactId> <version>5.5</version> <scope>test</scope> <classifier>jdk15</classifier> </dependency> </dependencies> |
經測試這種方法可以正常運行。
其他幾種方法:
其他的方法沒有測試過,因為現在只是簡單的用例還沒有涉及太多。以后再試。
參考這個吧。http://maven.apache.org/plugins/maven-surefire-plugin/testng.html
多數人知道
SQL注入,也知道SQL參數化查詢可以防止SQL注入,可為什么能防止注入卻并不是很多人都知道的。
首先:我們要了解SQL收到一個指令后所做的事情:
在這里,簡單的表示為: 收到指令 -> 編譯SQL生成執行計劃 ->選擇執行計劃 ->執行執行計劃。
具體可能有點不一樣,但大致的步驟如上所示。
接著我們來分析為什么拼接SQL 字符串會導致SQL注入的風險呢?
首先創建一張表Users:
CREATE TABLE [dbo].[Users]( [Id] [uniqueidentifier] NOT NULL, [UserId] [int] NOT NULL, [UserName] [varchar](50) NULL, [Password] [varchar](50) NOT NULL, CONSTRAINT [PK_Users] PRIMARY KEY CLUSTERED ( [Id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] 3F3ECD42B7A24B139ECA0A7D584CA195 |
插入一些數據:
INSERT INTO [Test].[dbo].[Users]([Id],[UserId],[UserName],[Password])VALUES (NEWID(),1,'name1','pwd1');
INSERT INTO [Test].[dbo].[Users]([Id],[UserId],[UserName],[Password])VALUES (NEWID(),2,'name2','pwd2');
INSERT INTO [Test].[dbo].[Users]([Id],[UserId],[UserName],[Password])VALUES (NEWID(),3,'name3','pwd3');
INSERT INTO [Test].[dbo].[Users]([Id],[UserId],[UserName],[Password])VALUES (NEWID(),4,'name4','pwd4');
INSERT INTO [Test].[dbo].[Users]([Id],[UserId],[UserName],[Password])VALUES (NEWID(),5,'name5','pwd5');
假設我們有個用戶登錄的頁面,代碼如下:
驗證用戶登錄的sql 如下:
select COUNT(*) from Users where Password = 'a' and UserName = 'b'
這段代碼返回Password 和UserName都匹配的用戶數量,如果大于1的話,那么就代表用戶存在。
本文不討論SQL 中的密碼策略,也不討論代碼規范,主要是講為什么能夠防止SQL注入,請一些同學不要糾結與某些代碼,或者和SQL注入無關的主題。
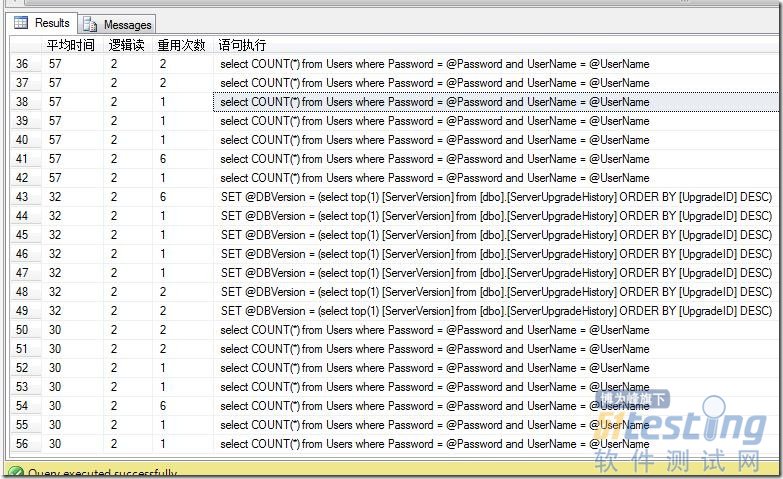
可以看到執行結果:
這個是SQL profile 跟蹤的SQL 語句。
注入的代碼如下:
select COUNT(*) from Users where Password = 'a' and UserName = 'b' or 1=1—'
這里有人將UserName設置為了 “b' or 1=1 –”.
實際執行的SQL就變成了如下:
可以很明顯的看到SQL注入成功了。很多人都知道參數化查詢可以避免上面出現的注入問題,比如下面的代碼:
class Program { private static string connectionString = "Data Source=.;Initial Catalog=Test;Integrated Security=True"; static void Main(string[] args) { Login("b", "a"); Login("b' or 1=1--", "a"); } private static void Login(string userName, string password) { using (SqlConnection conn = new SqlConnection(connectionString)) { conn.Open(); SqlCommand comm = new SqlCommand(); comm.Connection = conn; //為每一條數據添加一個參數 comm.CommandText = "select COUNT(*) from Users where Password = @Password and UserName = @UserName"; comm.Parameters.AddRange( new SqlParameter[] { new SqlParameter("@Password", SqlDbType.VarChar) {Value = password}, new SqlParameter("@UserName", SqlDbType.VarChar) {Value = userName}, }); comm.ExecuteNonQuery(); } } } |
實際執行的SQL 如下所示:
exec sp_executesql N'select COUNT(*) from Users where Password = @Password and UserName = @UserName',N'@Password varchar(1),@UserName varchar(1)',@Password='a',@UserName='b'
exec sp_executesql N'select COUNT(*) from Users where Password = @Password and UserName = @UserName',N'@Password varchar(1),@UserName varchar(11)',@Password='a',@UserName='b'' or 1=1—'
可以看到參數化查詢主要做了這些事情:
1:參數過濾,可以看到 @UserName='b'' or 1=1—'
2:執行計劃重用
因為執行計劃被重用,所以可以防止SQL注入。
首先分析SQL注入的本質,
用戶寫了一段SQL 用來表示查找密碼是a的,用戶名是b的所有用戶的數量。
通過注入SQL,這段SQL現在表示的含義是查找(密碼是a的,并且用戶名是b的) 或者1=1 的所有用戶的數量。
可以看到SQL的語意發生了改變,為什么發生了改變呢?,因為沒有重用以前的執行計劃,因為對注入后的SQL語句重新進行了編譯,因為重新執行了語法解析。所以要保證SQL語義不變,即我想要表達SQL就是我想表達的意思,不是別的注入后的意思,就應該重用執行計劃。
如果不能夠重用執行計劃,那么就有SQL注入的風險,因為SQL的語意有可能會變化,所表達的查詢就可能變化。
在SQL Server 中查詢執行計劃可以使用下面的腳本:
DBCC FreeProccache select total_elapsed_time / execution_count 平均時間,total_logical_reads/execution_count 邏輯讀, usecounts 重用次數,SUBSTRING(d.text, (statement_start_offset/2) + 1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(text) ELSE statement_end_offset END - statement_start_offset)/2) + 1) 語句執行 from sys.dm_exec_cached_plans a cross apply sys.dm_exec_query_plan(a.plan_handle) c ,sys.dm_exec_query_stats b cross apply sys.dm_exec_sql_text(b.sql_handle) d --where a.plan_handle=b.plan_handle and total_logical_reads/execution_count>4000 ORDER BY total_elapsed_time / execution_count DESC; 18EFAED775BF4DB9A36C57B39EC6913D |
在這篇文章中有這么一段:
這里作者有一句話:”不過這種寫法和直接拼SQL執行沒啥實質性的區別”
任何拼接SQL的方式都有SQL注入的風險,所以如果沒有實質性的區別的話,那么使用exec 動態執行SQL是不能防止SQL注入的。
比如下面的代碼:
private static void TestMethod() { using (SqlConnection conn = new SqlConnection(connectionString)) { conn.Open(); SqlCommand comm = new SqlCommand(); comm.Connection = conn; //使用exec動態執行SQL //實際執行的查詢計劃為(@UserID varchar(max))select * from Users(nolock) where UserID in (1,2,3,4) //不是預期的(@UserID varchar(max))exec('select * from Users(nolock) where UserID in ('+@UserID+')') comm.CommandText = "exec('select * from Users(nolock) where UserID in ('+@UserID+')')"; comm.Parameters.Add(new SqlParameter("@UserID", SqlDbType.VarChar, -1) { Value = "1,2,3,4" }); //comm.Parameters.Add(new SqlParameter("@UserID", SqlDbType.VarChar, -1) { Value = "1,2,3,4); delete from Users;--" }); comm.ExecuteNonQuery(); } } |
執行的SQL 如下:
exec sp_executesql N'exec(''select * from Users(nolock) where UserID in (''+@UserID+'')'')',N'@UserID varchar(max) ',@UserID='1,2,3,4'
可以看到SQL語句并沒有參數化查詢。
如果你將UserID設置為”1,2,3,4); delete from Users;—-”,那么執行的SQL就是下面這樣:
exec sp_executesql N'exec(''select * from Users(nolock) where UserID in (''+@UserID+'')'')',N'@UserID varchar(max) ',@UserID='1,2,3,4); delete from Users;--'
不要以為加了個@UserID 就代表能夠防止SQL注入,實際執行的SQL 如下:
任何動態的執行SQL 都有注入的風險,因為動態意味著不重用執行計劃,而如果不重用執行計劃的話,那么就基本上無法保證你寫的SQL所表示的意思就是你要表達的意思。
這就好像小時候的填空題,查找密碼是(____) 并且用戶名是(____)的用戶。
不管你填的是什么值,我所表達的就是這個意思。
最后再總結一句:因為參數化查詢可以重用執行計劃,并且如果重用執行計劃的話,SQL所要表達的語義就不會變化,所以就可以防止SQL注入,如果不能重用執行計劃,就有可能出現SQL注入,存儲過程也是一樣的道理,因為可以重用執行計劃。
本文主要介紹使用
Python語言編寫Socket協議Server及Client的簡單實現方法。
1. Python Socket編程簡介
Socket通常也稱作"套接字",應用程序通常通過"套接字"向網絡發出請求或者應答網絡請求。
三種流行的套接字類型是:stream,datagram和raw。stream和datagram套接字可以直接與TCP協議進行接口,而raw套接字則接口到IP協議。
Python Socket模塊提供了對低層BSD套接字樣式網絡的訪問,使用該模塊建立具有TCP和流套接字的簡單服務器。詳見https://docs.python.org/2/library/socket.html
2. Python Socket Server
實現代碼如下
# -*- coding:utf-8 -*- from socket import * def SocketServer(): try: Colon = ServerUrl.find(':') IP = ServerUrl[0:Colon] Port = int(ServerUrl[Colon+1:]) #建立socket對象 print 'Server start:%s'%ServerUrl sockobj = socket(AF_INET, SOCK_STREAM) sockobj.setsockopt(SOL_SOCKET,SO_REUSEADDR, 1) #綁定IP端口號 sockobj.bind((IP, Port)) #監聽,允許5個連結 sockobj.listen(5) #直到進程結束時才結束循環 while True: #等待client連結 connection, address = sockobj.accept( ) print 'Server connected by client:', address while True: #讀取Client消息包內容 data = connection.recv(1024) #如果沒有data,跳出循環 if not data: break #發送回復至Client RES='200 OK' connection.send(RES) print 'Receive MSG:%s'%data.strip() print 'Send RES:%s\r\n'%RES #關閉Socket connection.close( ) except Exception,ex: print ex ServerUrl = "192.168.16.15:9999" SocketServer() |
注:需要注意的是Socket對象建立后需要加上sockobj.setsockopt(SOL_SOCKET,SO_REUSEADDR, 1),否則會出現Python腳本重啟后Socket Server端口不會立刻關閉,出現端口占用錯誤。
3. Python Socket Client
實現代碼如下
# -*- coding:utf-8 -*- from socket import * def SocketClient(): try: #建立socket對象 s=socket(AF_INET,SOCK_STREAM,0) Colon = ServerUrl.find(':') IP = ServerUrl[0:Colon] Port = ServerUrl[Colon+1:] #建立連接 s.connect((IP,int(Port))) sdata='GET /Test HTTP/1.1\r\n\ Host: %s\r\n\r\n'%ServerUrl print "Request:\r\n%s\r\n"%sdata s.send(sdata) sresult=s.recv(1024) print "Response:\r\n%s\r\n" %sresult #關閉Socket s.close() except Exception,ex: print ex ServerUrl = "192.168.16.15:9999" SocketClient() |
4. 運行結果
Socket Server端運行截圖如下:
Socket-Server
Socket Client端運行截圖如下:
開發環境
1. jdk1.7
2. Eclipse
3. selenium(selenium-java-2.42.2.zip)
將下載下來的 selenium-java-2.42.2.zip 解壓, 解壓后文件目錄:
1. 將上面加壓出來的文件復制到新建的項目目錄下:
2. 添加build path,項目目錄右鍵 >> Build Path >> config build path >> Java Build Path >> Libraries >> Add JARs
把libs文件夾下的jar包全部添加上,再添加selenium-java-2.42.2和selenium-java-2.42.2-srcs
3、添加完之后目錄結構如下圖,多了Referenced Libraries,這里就是上面那一步添加進去的jar包
常用的一些選項有:
問題類型
JIRA系統中用優先級來表示問題的嚴重級別,有以下幾種級別:
優先級 block>critical>major>minor>trivial
狀態
每個問題有一個狀態,用來表明問題所處的階段,問題通過開始于open狀態,然后開始處理/progress,再解決到/resolved,然后關閉/closed.根據情況的不同,可以文具項目來制定問題狀態.
解決
一個問題可以用多種方式解決,系統管理員是可以在JIRA系統中定制解決方式.JIRA系統默認的解決方式如下: