經(jīng)常可以從開發(fā)人員口中聽到“面向?qū)ο?#8221;這個詞:
場景1、
A:我今天開始用面向?qū)ο蟮姆椒ㄔO計程序了!
B:你怎么做的?
A:我把保存文件、加載文件封裝成了一個類,以后只要調(diào)用這個類就可以實現(xiàn)文件操作了。
場景2、
A:我開始學習Java了,面向?qū)ο蟮恼Z言,你不要再學VB了,好土呀!
B:VB怎么了?
A:VB是面向過程的,已經(jīng)過時了,Java中都是類,很時髦!
B:VB中也有類呀!
A:(無語)
場景3、
A:面向?qū)ο笏枷刖褪呛醚剑艺娴碾x不開Java了!
B:你又用什么高超技術了?
A:我今天從一個操縱數(shù)據(jù)庫的類繼承了一個子類,然后重寫了它的保存到數(shù)據(jù)庫的方法,然后把數(shù)據(jù)通過Socket發(fā)送到了遠程客戶端了,而調(diào)用者根本不知道,哈哈!
場景4、
A:我推薦你用的Java不錯吧?
B:真是不錯,面向?qū)ο缶褪呛茫琂DK里邊也有好多好多的類可以用,不用像在VB里邊那樣要去查API文檔了。
A:但是我聽說現(xiàn)在又出了個面向方面編程,咱們看來又落伍了呀,看來做編程真的不是長久之計。
寫幾個類就是面向?qū)ο罅藛幔坷^承父類就是為了重用父類的代碼嗎?覆蓋父類的方法就可以瞞天過海了嗎?VB中也有類,它是面向?qū)ο髥幔?
1.1
類與對象
“類”和“對象”是面向?qū)ο缶幊讨凶罨镜母拍睿瑥恼Z言的角度來講,“類”是用戶自定義的具有一定行為的數(shù)據(jù)類型,“對象”則是“類”這種數(shù)據(jù)類型的變量。通俗的講,“類”是具有相同或相似行為的事物的抽象,“對象”是“類”的實例,是是一組具有相關性的代碼和數(shù)據(jù)的組合體,是有一定責任的實體。
類本身還可以進一步抽象為類型,類型是一種更高層次上的抽象,它只用來描述接口,比如抽象類和接口就是一種類型。當一個類型的接口包含另外一個類型的接口時,我們就可以說它是此類型的子類型。類型是用來標識特定接口的,如果一個對象接受某個接口定義的所有行為,那么我們就可以說該對象具有該類型。一個對象同時擁有多種類型。
面向?qū)ο缶幊痰奶匦?
面向?qū)ο缶幊逃腥齻€特性:封裝,繼承,多態(tài)。這三個特性從低級到高級描述了面向?qū)ο蟮奶卣鳌R环N語言只有同時具備這三種特性才能被稱為面向?qū)ο蟮恼Z言。VB中也有類,它的類也支持封裝和簡單的繼承,但是它不支持所有的繼承語義和多態(tài),因此VB只能被稱為基于對象的語言。
封裝是所有抽象數(shù)據(jù)類型(ADT)的特性,很多剛剛接觸面向?qū)ο蟮娜苏J為封裝就是就是面向?qū)ο蟆⒊绦虬凑找欢ǖ倪壿嫹殖啥鄠€互相協(xié)作的部分,并將對外界有用的穩(wěn)定的部分暴露出來,而將會發(fā)生的改變隱藏起來,外界只能通過暴露的部分向這個對象發(fā)送操作請求從而享受對象提供的服務,而不必管對象內(nèi)部是如何運行的,這就是封裝。理解封裝是理解面向?qū)ο蟮牡谝粋€步驟,40%的程序員對面向?qū)ο蟮睦斫鈨H停留在封裝這個層次。
繼承也稱為派生,繼承關系中,被繼承的稱為基類,從基類繼承而得的被稱為派生類或者子類。繼承是保持對象差異性的同時共享對象相似性的復用。能夠被繼承的類總是含有并只含有它所抽象的那一類事務的共同特點。繼承提供了實現(xiàn)復用,只要從一個類繼承,我們就擁有了這個類的所有行為。理解繼承是理解面向?qū)ο蟮牡诙€步驟,50%的程序員對面向?qū)ο蟮睦斫鈨H停留在繼承這個層次。語義上的“繼承”表示“是一種(is-a)”的關系。很多人體會到了繼承在代碼重用方面的優(yōu)點,而忽視了繼承的語義特征。于是很多濫用繼承的情況就發(fā)生了,關于這一點我們將會在后邊介紹。
多態(tài)是“允許用戶將父對象設置成為一個或更多的它的子對象相等的技術,賦值后,基類對象就可以根據(jù)當前賦值給它的派生類對象的特性以不同的方式運作”(Charlie Calvert)。多態(tài)擴大了對象的適應性,改變了對象單一繼承的關系。多態(tài)是行為的抽象,它使得同名方法可以有不同的響應方式,我們可以通過名字調(diào)用某一方法而無需知道哪種實現(xiàn)將被執(zhí)行,甚至無需知道執(zhí)行這個實現(xiàn)的對象類型。多態(tài)是面向?qū)ο缶幊痰暮诵母拍睿挥欣斫饬硕鄳B(tài),才能明白什么是真正的面向?qū)ο螅拍苷嬲l(fā)揮面向?qū)ο蟮淖畲竽芰Α2贿^可惜的是,只有極少數(shù)程序員能真正理解多態(tài)。
對象之間的關系
對象之間有兩種最基本的關系:繼承關系,組合關系。
繼承關系
繼承關系可以分為兩種:一種是類對接口的繼承,被稱為接口繼承;另一種是類對類的繼承,被稱為實現(xiàn)繼承。繼承關系是一種“泛化/特化”關系,基類代表一般,而派生類代表特殊。
組合關系。
組合是由已有的對象組合而成新對象的行為,組合只是重復運用既有程序的功能,而非重用其形式。組合與繼承的不同點在于它表示了整體和部分的關系。比如電腦是由CPU、內(nèi)存、顯示器、硬盤等組成的,這些部件使得電腦有了計算、存儲、顯示圖形的能力,但是不能說電腦是由CPU繼承而來的。
1.2
對象之間有兩種最基本的關系:繼承關系,組合關系。通過這兩種關系的不斷迭代組合最終組成了可用的程序。但是需要注意的就是要合理使用這兩種關系。
派生類是基類的一個特殊種類,而不是基類的一個角色。語義上的“繼承”表示“is-a”(是一種)的關系,派生類“is-a”基類,這是使用繼承關系的最基本前提。如果類A是類B的基類,那么類B應該可以在任何A出現(xiàn)的地方取代A,這就是“Liskov代換法則(LSP)”。如果類B不能在類A出現(xiàn)的地方取代類A的話,就不要把類B設計為類A的派生類。
舉例來說,“蘋果”是“水果”的派生類,所以“水果是植物的果實”這句話中的“水果”可以用“蘋果”來代替:“蘋果是植物的果實”;而“蘋果”不是“香蕉”的派生類,因為“香蕉是一種種子退化的了的植物果實”不能被“蘋果”替換為“蘋果是一種種子退化的了的植物果實”。
舉這個例子好像有點多余,不過現(xiàn)實的開發(fā)中卻經(jīng)常發(fā)生“蘋果”從“香蕉”繼承的事情。
某企業(yè)中有一套信息系統(tǒng),其中有一個“客戶(Customer)”基礎資料,里邊記錄了客戶的名稱、地址、email等信息。后來系統(tǒng)要進行升級,增加一個“供應商(Supplier)”基礎資料,開發(fā)人員發(fā)現(xiàn)“供應商”中有“客戶”中的所有屬性,只是多了一個“銀行帳號”屬性,所以就把“供應商”設置成“客戶”客戶的子類。
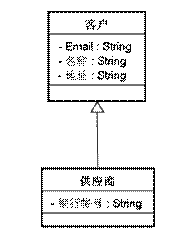
圖 2.1
到了年終,老板要求給所有的客戶通過Email發(fā)送新年祝福,由于“供應商”是一種(is-a)“客戶”,所以系統(tǒng)就給“供應商”和“客戶”都發(fā)送了新年祝福。第二天很多供應商都感動流涕的給老板打電話“謝謝老板呀,我們供應商每次都是求著貴公司買我們的東西,到了年終你們還忘不了我們,真是太感謝了!”。老板很茫然,找來開發(fā)人員,開發(fā)人員這才意識到問題,于是在發(fā)送Email的程序里做了判斷“如果是供應商則不發(fā)送,否則發(fā)送”,一切ok了。到了年初,老板要求給所有很長時間沒有購買他們產(chǎn)品的“客戶”,打電話進行問候和意見征集。由于“供應商”是一種(is-a)“客戶”,所以第二天電話里不斷出現(xiàn)這樣的回答:“你們搞錯了吧,我們是你們的供應商呀!”。老板大發(fā)雷霆,開發(fā)人員這才意識到問題的嚴重性,所以在系統(tǒng)的所有涉及到客戶的地方都加了判斷“如果是供應商則……”,一共修改了60多處,當然由于疏忽遺漏了兩處,所以后來又出了一次類似的事故。
我們可以看到錯誤使用繼承的害處了。其實更好的解決方案應該是,從“客戶”和“供應商”中抽取一個共同的基類“外部公司”出來:

圖 2.2
這樣就將“客戶”和“供應商”之間的繼承關系去除了。
派生類不應大量覆蓋基類的行為。派生類具有擴展基類的責任,而不是具有覆蓋(override)基類的責任。如果派生類需要大量的覆蓋或者替換掉基類的行為,那么就不應該在兩個類之間建立繼承關系。
讓我們再來看一個案例:
一個開發(fā)人員要設計一個入庫單、一張出庫單和一張盤點單,并且這三張單都有登帳的功能,通過閱讀客戶需求,開發(fā)人員發(fā)現(xiàn)三張單的登帳邏輯都相同:遍歷單據(jù)中的所有物品記錄,然后逐筆登到臺帳上去。所以他就設計出了如下的程序:
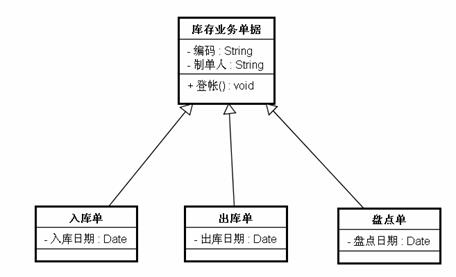
圖 2.3
把登帳邏輯都寫到了“庫存業(yè)務單據(jù)”這個抽象類中,三張單據(jù)從這個類繼承即可。過了三個月,用戶提出了新的需求:盤點單在盤點過程中,如果發(fā)現(xiàn)某個貨物的盤虧量大于50則停止登帳,并向操作人員報警。所以開發(fā)人員在盤點單中重寫了“庫存業(yè)務單據(jù)”的“登帳”方法,實現(xiàn)了客戶要求的邏輯。又過了半個月,客戶要求出庫登帳的時候不僅要進行原先的登帳,還要以便登帳一邊計算出庫成本。所以開發(fā)人員在出庫單中重寫了“庫存業(yè)務單據(jù)”的“登帳”方法,實現(xiàn)了客戶要求的邏輯。到了現(xiàn)在“庫存業(yè)務單據(jù)”的“登帳”方法的邏輯只是對“入庫單”有用了,因為其他兩張單據(jù)都“另立門戶”了。
這時候就是該我們重新梳理系統(tǒng)設計的時候了,我們把“庫存業(yè)務單據(jù)”的“登帳”方法設置成抽象方法,具體的實現(xiàn)代碼由具體子類自己決定:
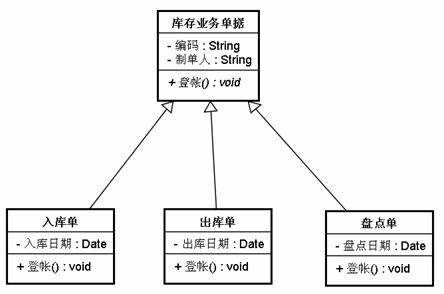
圖 2.4
注意此處的“庫存業(yè)務單據(jù)”中的“登帳”方法是斜體,在UML中表示此方法是一個抽象方法。這個不難理解,每張單據(jù)都肯定有登帳行為,但是每張單據(jù)的登帳行為都有差異,因此在抽象類中定義類的“登帳”方法為抽象方法以延遲到子類中去實現(xiàn)。
繼承具有如下優(yōu)點:實現(xiàn)新的類非常容易,因為基類的大部分功能都可以通過繼承關系自動賦予派生類;修改或者擴展繼承來的實現(xiàn)非常容易;只要修改父類,派生的類的行為就同時被修改了。
初學面向?qū)ο缶幊痰娜藭J為繼承真是一個好東西,是實現(xiàn)復用的最好手段。但是隨著應用的深入就會發(fā)現(xiàn)繼承有很多缺點:繼承破壞封裝性。基類的很多內(nèi)部細節(jié)都是對派生類可見的,因此這種復用是“白箱復用”;如果基類的實現(xiàn)發(fā)生改變,那么派生類的實現(xiàn)也將隨之改變。這樣就導致了子類行為的不可預知性;從基類繼承來的實現(xiàn)是無法在運行期動態(tài)改變的,因此降低了應用的靈活性。
繼承關系有很多缺點,如果合理使用組合則可以有效的避免這些缺點,使用組合關系將系統(tǒng)對變化的適應力從靜態(tài)提升到動態(tài),而且由于組合將已有對象組合到了新對象中,因此新對象可以調(diào)用已有對象的功能。由于組合關系中各個各個對象的內(nèi)部實現(xiàn)是隱藏的,我們只能通過接口調(diào)用,因此我們完全可以在運行期用實現(xiàn)了同樣接口的另外一個對象來代替原對象,從而靈活實現(xiàn)運行期的行為控制。而且使用合成關系有助于保持每個類的職責的單一性,這樣類的層次體系以及類的規(guī)模都不太可能增長為不可控制的龐然大物。因此我們優(yōu)先使用組合而不是繼承。
當然這并不是說繼承是不好的,我們可用的類總是不夠豐富,而使用繼承復用來創(chuàng)建一些實用的類將會不組合來的更快,因此在系統(tǒng)中合理的搭配使用繼承和組合將會使你的系統(tǒng)強大而又牢固。
1.3
接口的概念
接口是一種類型,它定義了能被其他類實現(xiàn)的方法,接口不能被實例化,也不能自己實現(xiàn)其中的方法,只能被支持該接口的其他類來提供實現(xiàn)。接口只是一個標識,標識了對象能做什么,至于怎么做則不在其控制之內(nèi),它更像一個契約。
任何一個類都可以實現(xiàn)一個接口,這樣這個類的實例就可以在任何需要這個接口的地方起作用,這樣系統(tǒng)的靈活性就大大增強了。
接口編程的實例
SQL語句在各個不同的數(shù)據(jù)庫之間移植最大的麻煩就是各個數(shù)據(jù)庫支持的語法不盡相同,比如取出表的前10行數(shù)據(jù)在不同數(shù)據(jù)庫中就有不同的實現(xiàn)。
MSSQLServer:Select top 10 * from T_Table
MySQL:select * from T_Table limit 0,10
Oracle:select * from T_Table where ROWNUM <=10
我們先來看一下最樸素的做法是怎樣的:
首先定義一個SQL語句翻譯器類:
public class Test1SQLTranslator
{
private int dbType;
public Test1SQLTranslator(int dbType)
{
super();
this.dbType = dbType;
}
public String translateSelectTop(String tableName, int count)
{
switch (dbType) {
case 0:
return "select top " + count + " * from " + tableName;
case 1:
return "select * from " + tableName + " limit 0," + count;
case 2:
return "select * from " + tableName + " where ROWNUM<=" + count;
default:
return null;
}
}
}
然后如下調(diào)用
public static void main(String[] args)
{
String tableName = "T_Table";
int count = 10;
int dbType = 0;
Test1SQLTranslator translator = new Test1SQLTranslator(dbType);
String sql = translator.translateSelectTop(tableName,count);
System.out.println(sql);
}
如果要增加對新的數(shù)據(jù)庫的支持,比如DB2,那么就必須修改Test1SQLTranslator類,增加一個對DB2的case語句,這種增加只能是在編輯源碼的時候進行添加,無法在運行時動態(tài)添加。再來看一下如果用基于接口的編程方式是如何實現(xiàn)的。
首先,定義接口ISQLTranslator,這個接口定義了所有SQL翻譯器的方法,目前只有一個翻譯Select top的方法:
public interface ISQLTranslator
{
public String translateSelectTop(String tableName, int count);
}
接著我們?yōu)楦鱾€數(shù)據(jù)庫寫不同的翻譯器類,這些翻譯器類都實現(xiàn)了ISQLTranslator接口:
public class MSSQLServerTranslator implements ISQLTranslator
{
public String translateSelectTop(String tableName, int count)
{
return "select top " + count + " * from " + tableName;
}
}
public class MySQLTranslator implements ISQLTranslator
{
public String translateSelectTop(String tableName, int count)
{
return "select * from " + tableName +" limit 0,"+count;
}
}
public class OracleSQLTranslator implements ISQLTranslator
{
public String translateSelectTop(String tableName, int count)
{
return "select * from " + tableName+" where ROWNUM<="+count;
}
}
如下調(diào)用:
public static void main(String[] args)
{
String tableName = "T_Table";
int count = 10;
ISQLTranslator translator = new MSSQLServerTranslator();
String sql = translator.translateSelectTop(tableName, count);
System.out.println(sql);
}
運行以后,打印出了:
select top 10 from T_Table
可以看到,不同的數(shù)據(jù)庫翻譯實現(xiàn)由不同的類來承擔,這樣最大的好處就是可擴展性極強,比如也許某一天出現(xiàn)了了支持中文語法的數(shù)據(jù)庫,我要為它做翻譯器只需再增加一個類:
public class SinoServerTranslator implements ISQLTranslator
{
public String translateSelectTop(String tableName, int count)
{
return "讀取表"+tableName+"的前"+count+"行";
}
}
修改調(diào)用代碼:
public static void main(String[] args)
{
String tableName = "T_Table";
int count = 10;
ISQLTranslator translator = new SinoServerTranslator();
String sql = translator.translateSelectTop(tableName, count);
System.out.println(sql);
}
運行后控制臺打印出:
讀取表T_Table的前10行
這里的translator 可以隨意實例化,只要實例化的類實現(xiàn)了ISQLTranslator 就可以了,這個類也可以通過配置文件讀取,甚至是其他類傳遞過來的,這都無所謂,只要是實現(xiàn)了ISQLTranslator 接口它就能正常工作。
如果要給SQL語句加上驗證功能,也就是翻譯的時候首先驗證一下翻譯的結(jié)果是否能在數(shù)據(jù)庫中執(zhí)行,我們就可以采用偷天換日的方式來進行。
首先創(chuàng)建一個VerifyTranslator類:
public class VerifyTranslator implements ISQLTranslator
{
private ISQLTranslator translator;
private Connection connection;
public VerifyTranslator(ISQLTranslator translator, Connection connection)
{
super();
this.translator = translator;
this.connection = connection;
}
public String translateSelectTop(String tableName, int count)
{
String sql = translator.translateSelectTop(tableName, count);
PreparedStatement ps = null;
try
{
ps = connection.prepareStatement(sql);
ps.execute();
} catch (SQLException e)
{
DbUtils.close(ps);
return "wrong sql";
}
return sql;
}
}
這個類接受一個實現(xiàn)了ISQLTranslator 接口的變量和數(shù)據(jù)庫連接做為構(gòu)造參數(shù),最重要的是這個類本身也實現(xiàn)了ISQLTranslator 接口,這樣它就完全能“偽裝”成SQL翻譯器來行使翻譯的責任了,不過它沒有真正執(zhí)行翻譯,它把翻譯的任務轉(zhuǎn)發(fā)給了通過構(gòu)造函數(shù)傳遞來的那個翻譯器變量:
String sql = translator.translateSelectTop(tableName, count);
它自己的真正任務則是進行SQL語句的驗證:
ps = connection.prepareStatement(sql);
再次修改調(diào)用代碼:
public static void main(String[] args)
{
String tableName = "T_Table";
int count = 10;
ISQLTranslator translator = new VerifyTranslator(
new SinoServerTranslator(), getConnection());
String sql = translator.translateSelectTop(tableName, count);
System.out.println(sql);
}
運行后控制臺打印出:
wrong sql
下面這段代碼看上去是不是很眼熟呢?
ISQLTranslator translator = new VerifyTranslator(new SinoServerTranslator(), getConnection());
這段代碼和我們經(jīng)常寫的流操作非常類似:
InputStream is = new DataInputStream(new FileInputStream(new File(“c:/boot.ini”)));
這就是設計模式中經(jīng)常提到的“裝飾者模式”。
針對接口編程
從上面的例子我們可以看出,當代碼寫到:
String sql = translator.translateSelectTop(tableName, count);
的時候,代碼編寫者根本不關心translator這個變量到底是哪個類的實例,它只知道它調(diào)用了接口約定支持的translateSelectTop方法。
當一個對象需要與其他對象協(xié)作完成一項任務時,它就需要知道那個對象,這樣才能調(diào)用那個對象的方法來獲得服務,這種對象對另一個協(xié)作對象的依賴就叫做關聯(lián)。如果一個關聯(lián)不是針對具體類,而是針對接口的時候,任何實現(xiàn)這個接口的類都可以滿足要求,因為調(diào)用者僅僅關心被依賴的對象是不是實現(xiàn)了特定接口。
當發(fā)送的請求和具體的請求響應者之間的關系在運行的時候才能確定的時候,我們就稱之為動態(tài)綁定。動態(tài)綁定允許在運行期用具有相同接口的對象進行替換,從而實現(xiàn)多態(tài)。多態(tài)使得對象間彼此獨立,所有的交互操作都通過接口進行,并可以在運行時改變它們之間的依賴關系。
針對接口編程,而不是針對實現(xiàn)編程是面向?qū)ο箝_發(fā)中的一個非常重要的原則,也是設計模式的精髓!
針對接口編程有數(shù)不清的例子,比如在Hibernate中,集合屬性必須聲明為Set、Map、List等接口類型,而不能聲明為HashSet、HashMap、ArrayList等具體的類型,這是因為Hibernate在為了實現(xiàn)LazyLoad,自己開發(fā)了能實現(xiàn)LazyLoad功能的實現(xiàn)了Set、Map、List等接口的類,因為我們的屬性的類型只聲明為這些屬性為這些接口的類型,因此Hibernate才敢放心大膽的返回這些特定的實現(xiàn)類。
現(xiàn)實的開發(fā)過程中有如下一些違反針對接口編程原則的陋習:
陋習1
ArrayList list = new ArrayList();
for(int i=0;i<10;i++)
{
list.add(……);
}
這里使用的是ArrayList的add方法,而add方法是定義在List接口中的,因此沒有必要聲明list變量為ArrayList類型,修改如下:
List list = new ArrayList();
for(int i=0;i<10;i++)
{
list.add(……);
}
陋習2
public void fooBar(HashMap map)
{
Object obj = map.get(“something”);
……
}
在這個方法中只是調(diào)用Map接口的get方法來取數(shù)據(jù),所以就不能要求調(diào)用者一定要傳遞一個HashMap類型的變量進來。修改如下:
public void fooBar(Map map)
{
Object obj = map.get(“something”);
……
}
這樣修改以后用戶為了防止傳遞給fooBar方法的Map被修改,用戶就可以這樣調(diào)用了:
Map unModMap = Collections.unmodifiableMap(map);
obj.fooBar(unModMap);
Collections.unmodifiableMap是JDK提供的一個工具類,可以返回一個對map的包裝,返回的map是不可修改的,這也是裝飾者模式的典型應用。
試想如果我們把接口聲明為public void fooBar(HashMap map)用戶還能這么調(diào)用嗎?
1.4 抽象類
抽象類的主要作用就是為它的派生類定義公共接口,抽象類把它的部分操作的實現(xiàn)延遲到派生類中來,派生類也能覆蓋抽象基類的方法,這樣可以很容易的定義新類。抽象類提供了一個繼承的出發(fā)點,我們經(jīng)常定義一個頂層的抽象類,然后將某些位置的實現(xiàn)定義為抽象的,也就是我們僅僅定義了實現(xiàn)的接口,而沒有定義實現(xiàn)的細節(jié)。
一個抽象類應該盡可能多的擁有共同的代碼,但是不能把只有特定子類才需要的方法移動到抽象類中。Eclipse的某些實現(xiàn)方式在這一點上就做的不是很好,Eclipse的一些界面類中提供了諸如CreateEmailField之類的方法來創(chuàng)建界面對象,這些方法并不是所有子類都用得到的,應該把它們抽取到一個工具類中更好。同樣的錯誤在我們的案例的JCownewDialog中也是存在的,這個類中就提供了CreateOKBtn、CreateCanceBtn兩個方法用來創(chuàng)建確定、取消按鈕。
在設計模式中,最能體現(xiàn)抽象類優(yōu)點的就是模版方法模式。模版方法模式定義了一個算法的骨架,而具體的實現(xiàn)步驟則由具體的子類類來實現(xiàn)。JDK中的InputStream類是模版方法的典型代表,它對skip等方法給出了實現(xiàn),而將read等方法定義為抽象方法等待子類去實現(xiàn)。后邊案例中的PISAbstractAction等類也是模版方法的一個應用。
在實際開發(fā)中接口和抽象類從兩個方向?qū)ο到y(tǒng)的復用做出了貢獻,接口定義了系統(tǒng)的服務契約,而抽象類則為這些服務定義了公共的實現(xiàn),子類完全可以從這些抽象類繼承,這樣就不用自己實現(xiàn)自己所不關心的方法,如果抽象類提供的服務實現(xiàn)不滿足自己的要求,那么就可以自己從頭實現(xiàn)接口的服務契約。
歡迎來訪!^.^!
本BLOG僅用于個人學習交流!
目的在于記錄個人成長.
所有文字均屬于個人理解.
如有錯誤,望多多指教!不勝感激!