每秒查詢率QPS是對一個特定的查詢服務器在規定時間內所處理流量多少的衡量標準,在因特網上,作為域名系統服務器的機器的性能經常用每秒查詢率來衡量。
原理:每天80%的訪問集中在20%的時間里,這20%時間叫做峰值時間
公式:( 總PV數 * 80% ) / ( 每天秒數 * 20% ) = 峰值時間每秒請求數(QPS)
機器:峰值時間每秒QPS / 單臺機器的QPS = 需要的機器
問:每天300w PV 的在單臺機器上,這臺機器需要多少QPS?
答:( 3000000 * 0.8 ) / (86400 * 0.2 ) = 139 (QPS)
問:如果一臺機器的QPS是58,需要幾臺機器來支持?
答:139 / 58 = 3
現在敏捷開發是越來越火了,人人都在談敏捷,人人都在學習Scrum和XP...
為了不落后他人,于是我也開始學習Scrum,今天主要是對我最近閱讀的相關資料,根據自己的理解,用自己的話來講述Scrum中的各個環節,主要目的有兩個,一個是進行知識的總結,另外一個是覺得網上很多學習資料的講述方式讓初學者不太容易理解;所以我決定寫一篇掃盲性的博文,同時試著也與園內的朋友一起分享交流一下,希望對初學者有幫助。
什么是敏捷開發?
敏捷開發(Agile Development)是一種以人為核心、迭代、循序漸進的開發方法。
怎么理解呢?首先,我們要理解它不是一門技術,它是一種開發方法,也就是一種軟件開發的流程,它會指導我們用規定的環節去一步一步完成項目的開發;而這種開發方式的主要驅動核心是人;它采用的是迭代式開發;
為什么說是以人為核心?
我們大部分人都學過瀑布開發模型,它是以文檔為驅動的,為什么呢?因為在瀑布的整個開發過程中,要寫大量的文檔,把需求文檔寫出來后,開發人員都是根據文檔進行開發的,一切以文檔為依據;而敏捷開發它只寫有必要的文檔,或盡量少寫文檔,敏捷開發注重的是人與人之間,面對面的交流,所以它強調以人為核心。
什么是迭代?
迭代是指把一個復雜且開發周期很長的開發任務,分解為很多小周期可完成的任務,這樣的一個周期就是一次迭代的過程;同時每一次迭代都可以生產或開發出一個可以交付的軟件產品。
關于Scrum和XP
前面說了敏捷它是一種指導思想或開發方式,但是它沒有明確告訴我們到底采用什么樣的流程進行開發,而Scrum和XP就是敏捷開發的具體方式了,你可以采用Scrum方式也可以采用XP方式;Scrum和XP的區別是,Scrum偏重于過程,XP則偏重于實踐,但是實際中,兩者是結合一起應用的,這里我主要講Scrum。
什么是Scrum?
Scrum的英文意思是橄欖球運動的一個專業術語,表示“爭球”的動作;把一個開發流程的名字取名為Scrum,我想你一定能想象出你的開發團隊在開發一個項目時,大家像打橄欖球一樣迅速、富有戰斗激情、人人你爭我搶地完成它,你一定會感到非常興奮的。
而Scrum就是這樣的一個開發流程,運用該流程,你就能看到你團隊高效的工作。
【Scrum開發流程中的三大角色】
產品負責人(Product Owner)
主要負責確定產品的功能和達到要求的標準,指定軟件的發布日期和交付的內容,同時有權力接受或拒絕開發團隊的工作成果。
流程管理員(Scrum Master)
主要負責整個Scrum流程在項目中的順利實施和進行,以及清除擋在客戶和開發工作之間的溝通障礙,使得客戶可以直接驅動開發。
開發團隊(Scrum Team)
主要負責軟件產品在Scrum規定流程下進行開發工作,人數控制在5~10人左右,每個成員可能負責不同的技術方面,但要求每成員必須要有很強的自我管理能力,同時具有一定的表達能力;成員可以采用任何工作方式,只要能達到Sprint的目標。
Scrum流程圖
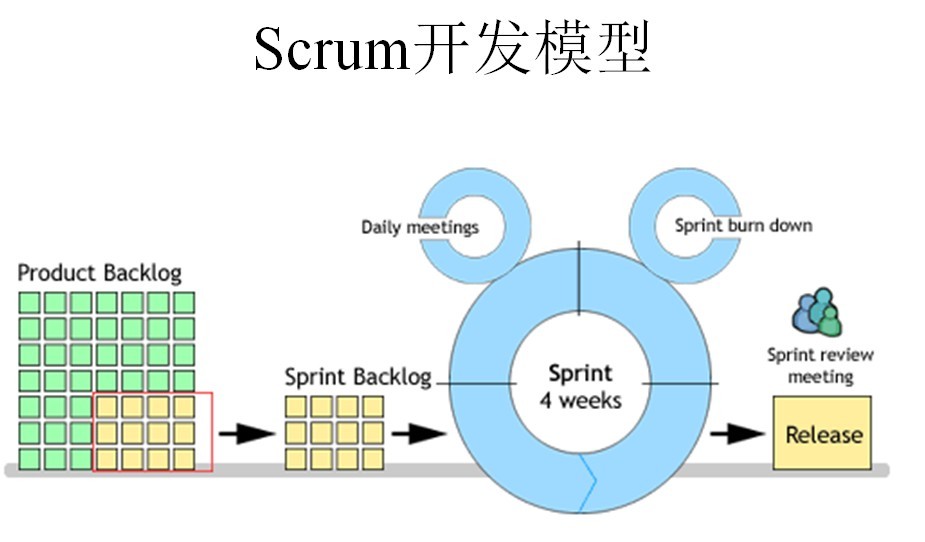
//------------------------
下面,我們開始講具體實施流程,但是在講之前,我還要對一個英文單詞進行講解。
什么是Sprint?
Sprint是短距離賽跑的意思,這里面指的是一次迭代,而一次迭代的周期是1個月時間(即4個星期),也就是我們要把一次迭代的開發內容以最快的速度完成它,這個過程我們稱它為Sprint。
如何進行Scrum開發?
1、我們首先需要確定一個Product Backlog(按優先順序排列的一個產品需求列表),這個是由Product Owner 負責的;
2、Scrum Team根據Product Backlog列表,做工作量的預估和安排;
3、有了Product Backlog列表,我們需要通過 Sprint Planning Meeting(Sprint計劃會議) 來從中挑選出一個Story作為本次迭代完成的目標,這個目標的時間周期是1~4個星期,然后把這個Story進行細化,形成一個Sprint Backlog;
4、Sprint Backlog是由Scrum Team去完成的,每個成員根據Sprint Backlog再細化成更小的任務(細到每個任務的工作量在2天內能完成);
5、在Scrum Team完成計劃會議上選出的Sprint Backlog過程中,需要進行 Daily Scrum Meeting(每日站立會議),每次會議控制在15分鐘左右,每個人都必須發言,并且要向所有成員當面匯報你昨天完成了什么,并且向所有成員承諾你今天要完成什么,同時遇到不能解決的問題也可以提出,每個人回答完成后,要走到黑板前更新自己的 Sprint burn down(Sprint燃盡圖);
6、做到每日集成,也就是每天都要有一個可以成功編譯、并且可以演示的版本;很多人可能還沒有用過自動化的每日集成,其實TFS就有這個功能,它可以支持每次有成員進行簽入操作的時候,在服務器上自動獲取最新版本,然后在服務器中編譯,如果通過則馬上再執行單元測試代碼,如果也全部通過,則將該版本發布,這時一次正式的簽入操作才保存到TFS中,中間有任何失敗,都會用郵件通知項目管理人員;
7、當一個Story完成,也就是Sprint Backlog被完成,也就表示一次Sprint完成,這時,我們要進行 Srpint Review Meeting(演示會議),也稱為評審會議,產品負責人和客戶都要參加(最好本公司老板也參加),每一個Scrum Team的成員都要向他們演示自己完成的軟件產品(這個會議非常重要,一定不能取消);
8、最后就是 Sprint Retrospective Meeting(回顧會議),也稱為總結會議,以輪流發言方式進行,每個人都要發言,總結并討論改進的地方,放入下一輪Sprint的產品需求中;
下面是運用Scrum開發流程中的一些場景圖:
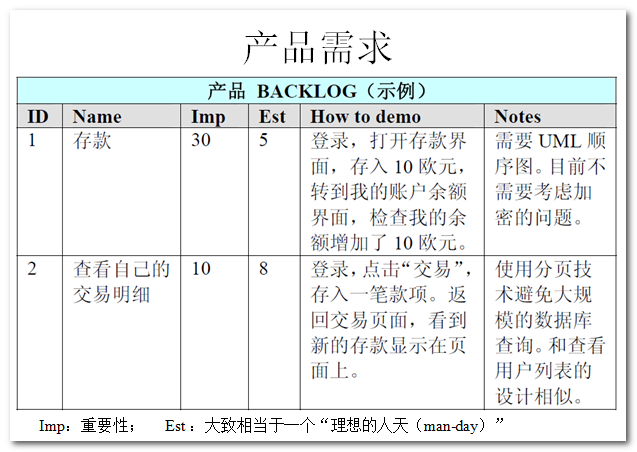
上圖是一個 Product Backlog 的示例。

上圖就是每日的站立會議了,參會人員可以隨意姿勢站立,任務看板要保證讓每個人看到,當每個人發言完后,要走到任務版前更新自己的燃盡圖。
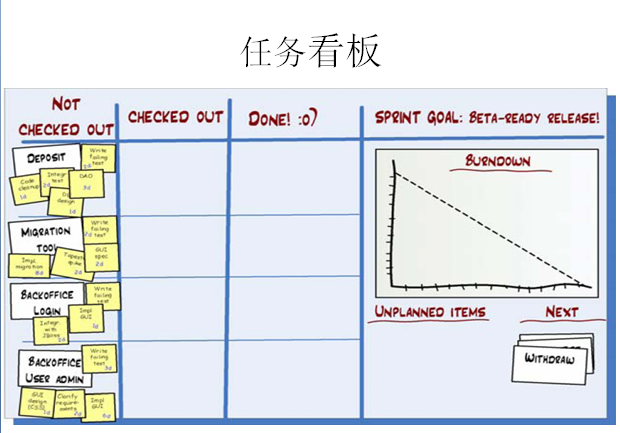
任務看版包含 未完成、正在做、已完成 的工作狀態,假設你今天把一個未完成的工作已經完成,那么你要把小卡片從未完成區域貼到已完成區域。

每個人的工作進度和完成情況都是公開的,如果有一個人的工作任務在某一個位置放了好幾天,大家都能發現他的工作進度出現了什么問題(成員人數最好是5~7個,這樣每人可以使用一種專用顏色的標簽紙,一眼就可以從任務版看出誰的工作進度快,誰的工作進度慢)

上圖可不是撲克牌,它是計劃紙牌,它的作用是防止項目在開發過程中,被某些人所領導。
怎么用的呢?比如A程序員開發一個功能,需要5個小時,B程序員認為只需要半小時,那他們各自取相應的牌,藏在手中,最后攤牌,如果時間差距很大,那么A和B就可以討論A為什么要5個小時...
轉自:http://www.cnblogs.com/taven/archive/2010/10/17/1853386.html
先申明概念:
1、悲觀鎖,正如其名,它指的是對數據被外界(包括本系統當前的其他事務,以及來自外部系統的事務處理)修改持保守態度,因此,在整個數據處理過程中,將數據處于鎖定狀態。悲觀鎖的實現,往往依靠數據庫提供的鎖機制(也只有數據庫層提供的鎖機制才能真正保證數據訪問的排他性,否則,即使在本系統中實現了加鎖機制,也無法保證外部系統不會修改數據)。
2、樂觀鎖( Optimistic Locking )
相對悲觀鎖而言,樂觀鎖機制采取了更加寬松的加鎖機制。悲觀鎖大多數情況下依靠數據庫的鎖機制實現,以保證操作最大程度的獨占性。但隨之而來的就是數據庫性能的大量開銷,特別是對長事務而言,這樣的開銷往往無法承受。而樂觀鎖機制在一定程度上解決了這個問題。樂觀鎖,大多是基于數據版本( Version )記錄機制實現。何謂數據版本?即為數據增加一個版本標識,在基于數據庫表的版本解決方案中,一般是通過為數據庫表增加一個 “version” 字段來實現。讀取出數據時,將此版本號一同讀出,之后更新時,對此版本號加一。此時,將提交數據的版本數據與數據庫表對應記錄的當前版本信息進行比對,如果提交的數據版本號大于數據庫表當前版本號,則予以更新,否則認為是過期數據。
所以悲觀鎖和樂觀鎖最大的區別是是否一直鎖定資源,悲觀鎖在事物的全流程鎖定數據,樂觀鎖不鎖定數據(用讀寫鎖是阻塞事物,而用樂觀鎖則會導致回滾。這個是一種事物沖突后的不同鎖的表象)。樂觀鎖的最大特點是在最后檢查數據是否被修改,如果已被別人修改過,則回滾數據,避免臟數據。至于事物是否沖突和加鎖沒有直接聯系,該沖突的還是會沖突,不管你加悲觀鎖和樂觀鎖都會沖突。
悲觀鎖和樂觀鎖都是為了解決丟失更新問題或者是臟讀。悲觀鎖和樂觀鎖的重點就是是否在讀取記錄的時候直接上鎖。悲觀鎖的缺點很明顯,需要一個持續的數據庫連接,這在web應用中已經不適合了。
一個比較清楚的場景
下面這個假設的實際場景可以比較清楚的幫助我們理解這個問題:
a. 假設當當網上用戶下單買了本書,這時數據庫中有條訂單號為001的訂單,其中有個status字段是’有效’,表示該訂單是有效的;
b. 后臺管理人員查詢到這條001的訂單,并且看到狀態是有效的
c. 用戶發現下單的時候下錯了,于是撤銷訂單,假設運行這樣一條SQL: update order_table set status = ‘取消’ where order_id = 001;
d. 后臺管理人員由于在b這步看到狀態有效的,這時,雖然用戶在c這步已經撤銷了訂單,可是管理人員并未刷新界面,看到的訂單狀態還是有效的,于是點擊”發貨”按鈕,將該訂單發到物流部門,同時運行類似如下SQL,將訂單狀態改成已發貨:update order_table set status = ‘已發貨’ where order_id = 001
觀點1:只有沖突非常嚴重的系統才需要悲觀鎖;
分析:這是更準確的說法;
“所有悲觀鎖的做法都適合于狀態被修改的概率比較高的情況,具體是否合適則需要根據實際情況判斷。”,表達的也是這個意思,不過說法不夠準確;的確,之所以用悲觀鎖就是因為兩個用戶更新同一條數據的概率高,也就是沖突比較嚴重的情況下,所以才用悲觀鎖。
觀點2:最后提交前作一次select for update檢查,然后再提交update也是一種樂觀鎖的做法
分析:這是更準確的說法;
的確,這符合傳統樂觀鎖的做法,就是到最后再去檢查。但是wiki在解釋悲觀鎖的做法的時候,’It is not appropriate for use in web application development.’, 現在已經很少有悲觀鎖的做法了,所以我自己將這種二次檢查的做法也歸為悲觀鎖的變種,因為這在所有樂觀鎖里面,做法和悲觀鎖是最接近的,都是先select for update,然后update
*****除了上面的觀點1和觀點2是更準確的說法,下面的所有觀點都是錯誤的***********
觀點3:這個問題的原因是因為數據庫隔離級別是uncommitted read級別;
分析:這個觀點是錯誤的;
這個過程本身就是在read committed隔離級別下發生的,從a到d每一步,尤其是d這步,并不是因為讀到了未提交的數據,僅僅是因為用戶界面沒有刷新[事實上也不可能做自動刷新,這樣相當于數據庫一發生改變立刻要刷新了,這需要監聽數據庫了,顯然這是簡單問題復雜化了];
觀點4:悲觀鎖是指一個用戶在更新數據的時候,其他用戶不能讀取這條記錄;也就是update阻塞讀才叫悲觀鎖;
分析:這個觀點是錯的;
這在db2背景的開發中尤其常見;因為db2默認就是update會阻塞讀;但是這是各個數據庫對讀寫的時候上鎖的并發處理實現不一樣。但這根本不是悲觀鎖樂觀鎖的區別。Oracle可以做到寫不阻塞讀僅僅是因為做了多版本并發控制(Multiversion concurrency control), http://en.wikipedia.org/wiki/Multiversion_concurrency_control;但是在Oracle里面,一樣可以做樂觀鎖和悲觀鎖的控制。這本質上是應用層面的選擇。
觀點5:Oracle實際上用的就是樂觀鎖
分析:這個觀點是錯的;
前面說了,Oracle的確可以做到寫不阻塞讀,但是這不是悲觀鎖和樂觀鎖的問題。這是因為實現了多版本并發控制。按照wiki的定義,悲觀鎖和樂觀鎖是在應用層面選擇的。Oracle的應用只要在第二步做了select for update,就是悲觀鎖的做法;況且Oracle在任何隔離級別下,除了分布式事務兩階段提交的短暫時間,其他所有情況下都不存在寫阻塞讀的情況,如果按照這個觀點的話那Oracle已經不能做悲觀鎖了-_-
觀點6:不需要這么麻煩,只需要在d這步,最后提交更新的時候再做一個普通的select檢查一下就可以;[就是double check的做法]
分析:這個觀點是錯的。
這個做法其實在http://www.hetaoblog.com/database-lost-update-pessimistic-lock/,’3. 傳統悲觀鎖做法的變通’這節已經說明了,如果要這么做的話,仍然需要在最后提交更新前double check的時候做一個select for update, 否則select結束到update提交前的時間仍然有可能記錄被修改;
觀點7:應該盡可能使用悲觀鎖;
分析:這個觀點是錯的;
a. 根據悲觀鎖的概念,用戶在讀的時候(b這步)就會將記錄鎖住,直到更新結束的時候才會將鎖釋放,所以整個鎖的過程時間比較長;
b. 另外,悲觀鎖需要有一個持續的數據庫連接,這在當今的web應用中已經幾乎不存在;wiki上也說了, 悲觀鎖‘is not appropriate for use in web application development.’
所以,現在大部分應用都應該是樂觀鎖的;
轉自:http://zhidao.baidu.com/link?url=MUOUg59oz7-FKwz-zuUviGryfw9J4V63Pd2iWWErorwUpyeL85rznlmYaGDHXjH_ChywA3R1m9XNpx4k7RCCT3rNofjkCxIBYHdsvwr2bVy
1、常規網絡訪問限制:
a、線上運營設備的SSH端口不允許綁定在公網IP地址上,開發只能登錄開發機然后通過內網登錄這些服務器;
b、開發機、測試機的SSH端口可以綁定在公網IP地址上,SSH端口(22)可以考慮改為非知名端口;
c、線上運營設備、開發機、測試機的防火墻配置,公網只做80(HTTP)、8080(HTTP)、443(HTTPS)、SSH端口(僅限開發機、測試機)對外授權訪問;
d、線上運營設備、開發機、測試機除第c點以外所有服務端口禁止綁定在公網IP地址上,尤其是3306端口(MySQL);
2、DB保護,
a、DB服務器不允許配置公網IP(或用防火墻全部禁止公網訪問);
b、DB的root賬戶不用于業務訪問,回收集中管理,開放普通賬戶做業務邏輯訪問,對不同安全要求的庫表用不同的賬戶密碼訪問;
c、程序不要把DB訪問的賬戶密碼寫到配置文件中,寫入代碼或啟動時遠程到配置中心拉取(此方法比較重,可暫不考慮)。
d、另:DB備份文件可以考慮做加密處理;
3、系統安全:
a、設備的root密碼回收集中管理,給開發提供普通用戶帳號;
b、密碼需要定期修改,有強度要求;
4、業務訪問控制:
a、業務服務邏輯和運營平臺,盡量不要提供對用戶表和訂單表的批量訪問接口,如果運營平臺確實有這樣的需求,需要對特定賬戶做授權;
安全的代價是不方便、效率會下降,需要尋找平衡點。
轉自http://www.witwebs.com/aliyun-mount-init/
阿里云的服務器,國內訪問速度,穩定性一直都是不錯的。至少我在使用的過程中,還未碰到什么問題。我將自己在使用主機過程的安裝和環境配置做一個詳細的介紹。僅供新手朋友參考!當我們在購買到阿里云服務器之后,會獲得相應的IP地址和管理密碼。
主要介紹Linux的數據盤的格式化和掛載。
大致步驟是: 登陸Linux > 查看硬盤狀況 > 分區數據盤 > 格式化數據盤 > 掛載新分區
將會用到的命令如下:
df -h 查看已掛載硬盤信息
fdisk -l 查看磁盤信息,未掛載的也會列出來
fdisk /dev/xvdb 對數據盤進行分區,回車之后,繼續 根據提示,依次輸入”n” ,”p”,“1”,兩次回車,“wq”, 分區就開始了,很快就會完成
mkfs .ext3 /dev/xvdb1 命令對新分區進行格式化
echo ‘/dev/xvdb1 /www ext3 defaults 0 0′ >> /etc/fstab 添加分區信息
mount -a 命令掛載新分區
1:通過Linux SSH 登陸軟件登陸你的linux。登陸之后輸入命令:df -lh 的界面如圖:

2:輸入命令: fdisk -l 查看磁盤狀況,可以看到有數據盤: /dev/xvdb 而用df沒有查看到這個磁盤。所以需要另外掛載。

3: 用 fdisk /dev/xvdb 對數據盤進行分區。根據提示,輸入 n, p, 1, 回車,回車, wq。
完成之后,再用 fdisk -l,就可以看到顯示的信息和之前有不同了。

4:格式化磁盤。 mkfs .ext3 /dev/xvdb1 ,格式化磁盤。完成之后,就可以來掛載分區了。

5, 掛載分區,首先建立一個目錄用來掛載分區。比如: mkdir /www
然后把分區信息加入到fstab中:一次執行:
echo ‘/dev/xvdb1 /www ext3 defaults 0 0′ >> /etc/fstab 添加分區信息
mount -a 命令掛載新分區
最后用 df -h 命令查看,將會發現數據盤。

OK,希望能幫到各位。
1、需要先安裝gcc和tcl
yum install gcc
yum install tcl
2、下載并安裝redis
cd /opt
wget http://download.redis.io/releases/redis-3.0.0.tar.gz
tar -zxvf /opt/redis-3.0.0.tar.gz
cd /opt/redis-3.0.0
make
make test
make PREFIX=/opt/redis-3.0.0 install
注:PREFIX一定要大寫,裝好后,會生成/opt/redis-3.0.0/bin目錄,里面有啟動命令之類的文件。
3、啟動與關閉
redis啟動
/opt/redis-3.0.0/bin/redis-server /opt/redis-3.0.0/redis.conf
redis關閉
/opt/redis-3.0.0/bin/redis-cli -h 127.0.0.1 -p 6379 shutdown
客戶端啟動
/opt/redis-3.0.0/bin/redis-cli
set name test
get name
4、參數修改
/opt/redis-3.0.0/redis.conf文件修改
#后臺運行,可以ctrl+c不至于退出
daemonize yes
關于錯誤提示
(1)編輯/etc/sysctl.conf ,最下面加一行vm.overcommit_memory=1,然后sysctl -p 使配置文件生效
(2)sysctl vm.overcommit_memory=1
注:如果使用了云服務器,要記得打開6379端口,否則無法遠程訪問
1、svnadmin create /opt/svn/yiss/app/ios1、apache里的httpd.conf配置如下:
每個庫單獨
<Location /yiss/app/ios>#這個是ios項目url上的訪問上下文,對應http://IP/yiss/app/ios/
DAV svn
SVNPath /opt/svn/yiss/app/ios#這個是svn庫的絕對路徑
AuthType Basic#校驗方式
AuthName "please input username/password"#提示信息
AuthUserFile /opt/svn/passwd#密碼文件絕對路徑
AuthzSVNAccessFile /opt/svn/authz#權限文件絕對路徑
Require valid-user
</Location>
<Location /yiss/app/android>#安卓項目訪問上下文
DAV svn
SVNPath /opt/svn/yiss/app/android
AuthType Basic
AuthName "please input username/password"
AuthUserFile /opt/svn/passwd
AuthzSVNAccessFile /opt/svn/authz
Require valid-user
</Location>
<Location /yiss/web/buildscript>
DAV svn
SVNPath /opt/svn/yiss/web/buildscript
AuthType Basic
AuthName "please input username/password"
AuthUserFile /opt/svn/passwd
AuthzSVNAccessFile /opt/svn/authz
Require valid-user
</Location>
2、首先要創建/opt/svn/yiss/app目錄和/opt/svn/yiss/web
然后用命令創建svn庫
svnadmin create /opt/svn/yiss/app/ios
svnadmin create /opt/svn/yiss/app/android
svnadmin create /opt/svn/yiss/web/buildscript
3、創建apache用戶和密碼,會提示重復輸入2次確認。想改密碼就多次輸入,以最后一次輸入的為準。
htpasswd /opt/svn/passwd wxq
htpasswd /opt/svn/passwd caowei
......
4、配置權限組/opt/svn/authz
[groups]
admin=wxq
web=caowei,luocan,houlei,gengzhuo,huangwei,wuhaiying,leo
app=ssh,golden,shawn,leo
#admin組用戶可以訪問所有目錄
[/]
@admin=rw
#ios,android,srv,doc,buildscript這些都是庫名,這里創建了3個庫
[ios:/]
@app=rw
[android:/]
@app=rw
[buildscript:/]
@admin=rw
5、給目錄及子目錄授權,否則會報403forbidden無權限
chmod 777 /opt/svn -R
6、重啟svn,啟動的時候要以根啟動,如果以某個svn庫啟動,則其他庫無法啟動。
killall svnserve
svnserve -d -r /opt/svn/yiss
7、重啟apache
/opt/apache/bin/apachectl restart
8、瀏覽測試
http://115.231.94.x/yiss/app/ios/
http://115.231.94.x/yiss/app/android/
http://115.231.94.x/yiss/web/buildscript/