每秒查詢率QPS是對一個特定的查詢服務(wù)器在規(guī)定時間內(nèi)所處理流量多少的衡量標(biāo)準(zhǔn),在因特網(wǎng)上,作為域名系統(tǒng)服務(wù)器的機器的性能經(jīng)常用每秒查詢率來衡量。
原理:每天80%的訪問集中在20%的時間里,這20%時間叫做峰值時間
公式:( 總PV數(shù) * 80% ) / ( 每天秒數(shù) * 20% ) = 峰值時間每秒請求數(shù)(QPS)
機器:峰值時間每秒QPS / 單臺機器的QPS = 需要的機器
問:每天300w PV 的在單臺機器上,這臺機器需要多少Q(mào)PS?
答:( 3000000 * 0.8 ) / (86400 * 0.2 ) = 139 (QPS)
問:如果一臺機器的QPS是58,需要幾臺機器來支持?
答:139 / 58 = 3
現(xiàn)在敏捷開發(fā)是越來越火了,人人都在談敏捷,人人都在學(xué)習(xí)Scrum和XP...
為了不落后他人,于是我也開始學(xué)習(xí)Scrum,今天主要是對我最近閱讀的相關(guān)資料,根據(jù)自己的理解,用自己的話來講述Scrum中的各個環(huán)節(jié),主要目的有兩個,一個是進(jìn)行知識的總結(jié),另外一個是覺得網(wǎng)上很多學(xué)習(xí)資料的講述方式讓初學(xué)者不太容易理解;所以我決定寫一篇掃盲性的博文,同時試著也與園內(nèi)的朋友一起分享交流一下,希望對初學(xué)者有幫助。
什么是敏捷開發(fā)?
敏捷開發(fā)(Agile Development)是一種以人為核心、迭代、循序漸進(jìn)的開發(fā)方法。
怎么理解呢?首先,我們要理解它不是一門技術(shù),它是一種開發(fā)方法,也就是一種軟件開發(fā)的流程,它會指導(dǎo)我們用規(guī)定的環(huán)節(jié)去一步一步完成項目的開發(fā);而這種開發(fā)方式的主要驅(qū)動核心是人;它采用的是迭代式開發(fā);
為什么說是以人為核心?
我們大部分人都學(xué)過瀑布開發(fā)模型,它是以文檔為驅(qū)動的,為什么呢?因為在瀑布的整個開發(fā)過程中,要寫大量的文檔,把需求文檔寫出來后,開發(fā)人員都是根據(jù)文檔進(jìn)行開發(fā)的,一切以文檔為依據(jù);而敏捷開發(fā)它只寫有必要的文檔,或盡量少寫文檔,敏捷開發(fā)注重的是人與人之間,面對面的交流,所以它強調(diào)以人為核心。
什么是迭代?
迭代是指把一個復(fù)雜且開發(fā)周期很長的開發(fā)任務(wù),分解為很多小周期可完成的任務(wù),這樣的一個周期就是一次迭代的過程;同時每一次迭代都可以生產(chǎn)或開發(fā)出一個可以交付的軟件產(chǎn)品。
關(guān)于Scrum和XP
前面說了敏捷它是一種指導(dǎo)思想或開發(fā)方式,但是它沒有明確告訴我們到底采用什么樣的流程進(jìn)行開發(fā),而Scrum和XP就是敏捷開發(fā)的具體方式了,你可以采用Scrum方式也可以采用XP方式;Scrum和XP的區(qū)別是,Scrum偏重于過程,XP則偏重于實踐,但是實際中,兩者是結(jié)合一起應(yīng)用的,這里我主要講Scrum。
什么是Scrum?
Scrum的英文意思是橄欖球運動的一個專業(yè)術(shù)語,表示“爭球”的動作;把一個開發(fā)流程的名字取名為Scrum,我想你一定能想象出你的開發(fā)團(tuán)隊在開發(fā)一個項目時,大家像打橄欖球一樣迅速、富有戰(zhàn)斗激情、人人你爭我搶地完成它,你一定會感到非常興奮的。
而Scrum就是這樣的一個開發(fā)流程,運用該流程,你就能看到你團(tuán)隊高效的工作。
【Scrum開發(fā)流程中的三大角色】
產(chǎn)品負(fù)責(zé)人(Product Owner)
主要負(fù)責(zé)確定產(chǎn)品的功能和達(dá)到要求的標(biāo)準(zhǔn),指定軟件的發(fā)布日期和交付的內(nèi)容,同時有權(quán)力接受或拒絕開發(fā)團(tuán)隊的工作成果。
流程管理員(Scrum Master)
主要負(fù)責(zé)整個Scrum流程在項目中的順利實施和進(jìn)行,以及清除擋在客戶和開發(fā)工作之間的溝通障礙,使得客戶可以直接驅(qū)動開發(fā)。
開發(fā)團(tuán)隊(Scrum Team)
主要負(fù)責(zé)軟件產(chǎn)品在Scrum規(guī)定流程下進(jìn)行開發(fā)工作,人數(shù)控制在5~10人左右,每個成員可能負(fù)責(zé)不同的技術(shù)方面,但要求每成員必須要有很強的自我管理能力,同時具有一定的表達(dá)能力;成員可以采用任何工作方式,只要能達(dá)到Sprint的目標(biāo)。
Scrum流程圖
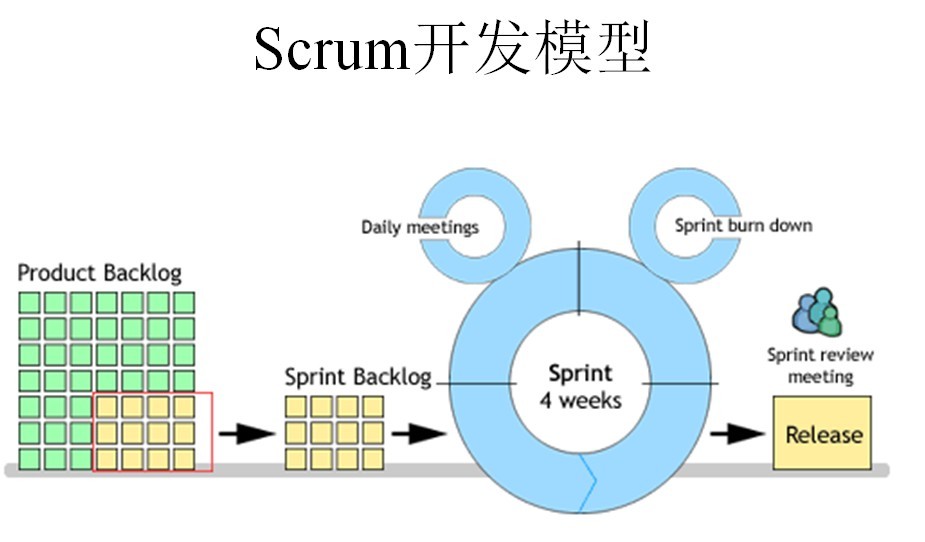
//------------------------
下面,我們開始講具體實施流程,但是在講之前,我還要對一個英文單詞進(jìn)行講解。
什么是Sprint?
Sprint是短距離賽跑的意思,這里面指的是一次迭代,而一次迭代的周期是1個月時間(即4個星期),也就是我們要把一次迭代的開發(fā)內(nèi)容以最快的速度完成它,這個過程我們稱它為Sprint。
如何進(jìn)行Scrum開發(fā)?
1、我們首先需要確定一個Product Backlog(按優(yōu)先順序排列的一個產(chǎn)品需求列表),這個是由Product Owner 負(fù)責(zé)的;
2、Scrum Team根據(jù)Product Backlog列表,做工作量的預(yù)估和安排;
3、有了Product Backlog列表,我們需要通過 Sprint Planning Meeting(Sprint計劃會議) 來從中挑選出一個Story作為本次迭代完成的目標(biāo),這個目標(biāo)的時間周期是1~4個星期,然后把這個Story進(jìn)行細(xì)化,形成一個Sprint Backlog;
4、Sprint Backlog是由Scrum Team去完成的,每個成員根據(jù)Sprint Backlog再細(xì)化成更小的任務(wù)(細(xì)到每個任務(wù)的工作量在2天內(nèi)能完成);
5、在Scrum Team完成計劃會議上選出的Sprint Backlog過程中,需要進(jìn)行 Daily Scrum Meeting(每日站立會議),每次會議控制在15分鐘左右,每個人都必須發(fā)言,并且要向所有成員當(dāng)面匯報你昨天完成了什么,并且向所有成員承諾你今天要完成什么,同時遇到不能解決的問題也可以提出,每個人回答完成后,要走到黑板前更新自己的 Sprint burn down(Sprint燃盡圖);
6、做到每日集成,也就是每天都要有一個可以成功編譯、并且可以演示的版本;很多人可能還沒有用過自動化的每日集成,其實TFS就有這個功能,它可以支持每次有成員進(jìn)行簽入操作的時候,在服務(wù)器上自動獲取最新版本,然后在服務(wù)器中編譯,如果通過則馬上再執(zhí)行單元測試代碼,如果也全部通過,則將該版本發(fā)布,這時一次正式的簽入操作才保存到TFS中,中間有任何失敗,都會用郵件通知項目管理人員;
7、當(dāng)一個Story完成,也就是Sprint Backlog被完成,也就表示一次Sprint完成,這時,我們要進(jìn)行 Srpint Review Meeting(演示會議),也稱為評審會議,產(chǎn)品負(fù)責(zé)人和客戶都要參加(最好本公司老板也參加),每一個Scrum Team的成員都要向他們演示自己完成的軟件產(chǎn)品(這個會議非常重要,一定不能取消);
8、最后就是 Sprint Retrospective Meeting(回顧會議),也稱為總結(jié)會議,以輪流發(fā)言方式進(jìn)行,每個人都要發(fā)言,總結(jié)并討論改進(jìn)的地方,放入下一輪Sprint的產(chǎn)品需求中;
下面是運用Scrum開發(fā)流程中的一些場景圖:
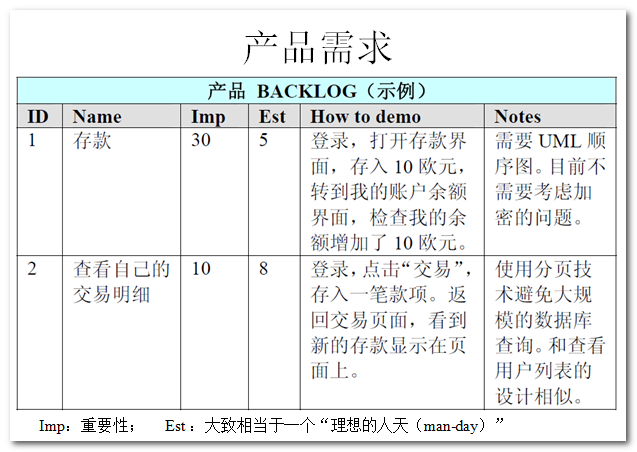
上圖是一個 Product Backlog 的示例。

上圖就是每日的站立會議了,參會人員可以隨意姿勢站立,任務(wù)看板要保證讓每個人看到,當(dāng)每個人發(fā)言完后,要走到任務(wù)版前更新自己的燃盡圖。
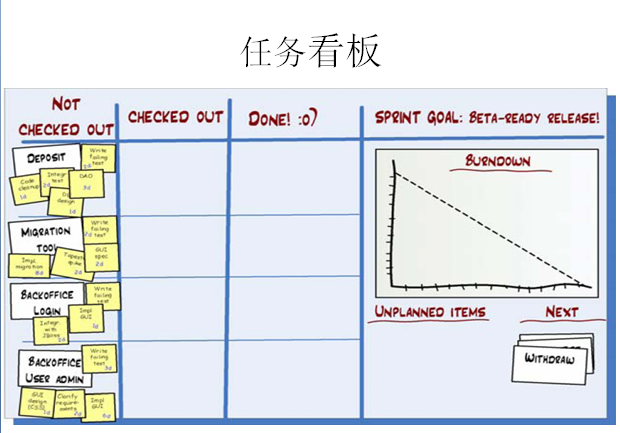
任務(wù)看版包含 未完成、正在做、已完成 的工作狀態(tài),假設(shè)你今天把一個未完成的工作已經(jīng)完成,那么你要把小卡片從未完成區(qū)域貼到已完成區(qū)域。

每個人的工作進(jìn)度和完成情況都是公開的,如果有一個人的工作任務(wù)在某一個位置放了好幾天,大家都能發(fā)現(xiàn)他的工作進(jìn)度出現(xiàn)了什么問題(成員人數(shù)最好是5~7個,這樣每人可以使用一種專用顏色的標(biāo)簽紙,一眼就可以從任務(wù)版看出誰的工作進(jìn)度快,誰的工作進(jìn)度慢)

上圖可不是撲克牌,它是計劃紙牌,它的作用是防止項目在開發(fā)過程中,被某些人所領(lǐng)導(dǎo)。
怎么用的呢?比如A程序員開發(fā)一個功能,需要5個小時,B程序員認(rèn)為只需要半小時,那他們各自取相應(yīng)的牌,藏在手中,最后攤牌,如果時間差距很大,那么A和B就可以討論A為什么要5個小時...
轉(zhuǎn)自:http://www.cnblogs.com/taven/archive/2010/10/17/1853386.html
先申明概念:
1、悲觀鎖,正如其名,它指的是對數(shù)據(jù)被外界(包括本系統(tǒng)當(dāng)前的其他事務(wù),以及來自外部系統(tǒng)的事務(wù)處理)修改持保守態(tài)度,因此,在整個數(shù)據(jù)處理過程中,將數(shù)據(jù)處于鎖定狀態(tài)。悲觀鎖的實現(xiàn),往往依靠數(shù)據(jù)庫提供的鎖機制(也只有數(shù)據(jù)庫層提供的鎖機制才能真正保證數(shù)據(jù)訪問的排他性,否則,即使在本系統(tǒng)中實現(xiàn)了加鎖機制,也無法保證外部系統(tǒng)不會修改數(shù)據(jù))。
2、樂觀鎖( Optimistic Locking )
相對悲觀鎖而言,樂觀鎖機制采取了更加寬松的加鎖機制。悲觀鎖大多數(shù)情況下依靠數(shù)據(jù)庫的鎖機制實現(xiàn),以保證操作最大程度的獨占性。但隨之而來的就是數(shù)據(jù)庫性能的大量開銷,特別是對長事務(wù)而言,這樣的開銷往往無法承受。而樂觀鎖機制在一定程度上解決了這個問題。樂觀鎖,大多是基于數(shù)據(jù)版本( Version )記錄機制實現(xiàn)。何謂數(shù)據(jù)版本?即為數(shù)據(jù)增加一個版本標(biāo)識,在基于數(shù)據(jù)庫表的版本解決方案中,一般是通過為數(shù)據(jù)庫表增加一個 “version” 字段來實現(xiàn)。讀取出數(shù)據(jù)時,將此版本號一同讀出,之后更新時,對此版本號加一。此時,將提交數(shù)據(jù)的版本數(shù)據(jù)與數(shù)據(jù)庫表對應(yīng)記錄的當(dāng)前版本信息進(jìn)行比對,如果提交的數(shù)據(jù)版本號大于數(shù)據(jù)庫表當(dāng)前版本號,則予以更新,否則認(rèn)為是過期數(shù)據(jù)。
所以悲觀鎖和樂觀鎖最大的區(qū)別是是否一直鎖定資源,悲觀鎖在事物的全流程鎖定數(shù)據(jù),樂觀鎖不鎖定數(shù)據(jù)(用讀寫鎖是阻塞事物,而用樂觀鎖則會導(dǎo)致回滾。這個是一種事物沖突后的不同鎖的表象)。樂觀鎖的最大特點是在最后檢查數(shù)據(jù)是否被修改,如果已被別人修改過,則回滾數(shù)據(jù),避免臟數(shù)據(jù)。至于事物是否沖突和加鎖沒有直接聯(lián)系,該沖突的還是會沖突,不管你加悲觀鎖和樂觀鎖都會沖突。
悲觀鎖和樂觀鎖都是為了解決丟失更新問題或者是臟讀。悲觀鎖和樂觀鎖的重點就是是否在讀取記錄的時候直接上鎖。悲觀鎖的缺點很明顯,需要一個持續(xù)的數(shù)據(jù)庫連接,這在web應(yīng)用中已經(jīng)不適合了。
一個比較清楚的場景
下面這個假設(shè)的實際場景可以比較清楚的幫助我們理解這個問題:
a. 假設(shè)當(dāng)當(dāng)網(wǎng)上用戶下單買了本書,這時數(shù)據(jù)庫中有條訂單號為001的訂單,其中有個status字段是’有效’,表示該訂單是有效的;
b. 后臺管理人員查詢到這條001的訂單,并且看到狀態(tài)是有效的
c. 用戶發(fā)現(xiàn)下單的時候下錯了,于是撤銷訂單,假設(shè)運行這樣一條SQL: update order_table set status = ‘取消’ where order_id = 001;
d. 后臺管理人員由于在b這步看到狀態(tài)有效的,這時,雖然用戶在c這步已經(jīng)撤銷了訂單,可是管理人員并未刷新界面,看到的訂單狀態(tài)還是有效的,于是點擊”發(fā)貨”按鈕,將該訂單發(fā)到物流部門,同時運行類似如下SQL,將訂單狀態(tài)改成已發(fā)貨:update order_table set status = ‘已發(fā)貨’ where order_id = 001
觀點1:只有沖突非常嚴(yán)重的系統(tǒng)才需要悲觀鎖;
分析:這是更準(zhǔn)確的說法;
“所有悲觀鎖的做法都適合于狀態(tài)被修改的概率比較高的情況,具體是否合適則需要根據(jù)實際情況判斷。”,表達(dá)的也是這個意思,不過說法不夠準(zhǔn)確;的確,之所以用悲觀鎖就是因為兩個用戶更新同一條數(shù)據(jù)的概率高,也就是沖突比較嚴(yán)重的情況下,所以才用悲觀鎖。
觀點2:最后提交前作一次select for update檢查,然后再提交update也是一種樂觀鎖的做法
分析:這是更準(zhǔn)確的說法;
的確,這符合傳統(tǒng)樂觀鎖的做法,就是到最后再去檢查。但是wiki在解釋悲觀鎖的做法的時候,’It is not appropriate for use in web application development.’, 現(xiàn)在已經(jīng)很少有悲觀鎖的做法了,所以我自己將這種二次檢查的做法也歸為悲觀鎖的變種,因為這在所有樂觀鎖里面,做法和悲觀鎖是最接近的,都是先select for update,然后update
*****除了上面的觀點1和觀點2是更準(zhǔn)確的說法,下面的所有觀點都是錯誤的***********
觀點3:這個問題的原因是因為數(shù)據(jù)庫隔離級別是uncommitted read級別;
分析:這個觀點是錯誤的;
這個過程本身就是在read committed隔離級別下發(fā)生的,從a到d每一步,尤其是d這步,并不是因為讀到了未提交的數(shù)據(jù),僅僅是因為用戶界面沒有刷新[事實上也不可能做自動刷新,這樣相當(dāng)于數(shù)據(jù)庫一發(fā)生改變立刻要刷新了,這需要監(jiān)聽數(shù)據(jù)庫了,顯然這是簡單問題復(fù)雜化了];
觀點4:悲觀鎖是指一個用戶在更新數(shù)據(jù)的時候,其他用戶不能讀取這條記錄;也就是update阻塞讀才叫悲觀鎖;
分析:這個觀點是錯的;
這在db2背景的開發(fā)中尤其常見;因為db2默認(rèn)就是update會阻塞讀;但是這是各個數(shù)據(jù)庫對讀寫的時候上鎖的并發(fā)處理實現(xiàn)不一樣。但這根本不是悲觀鎖樂觀鎖的區(qū)別。Oracle可以做到寫不阻塞讀僅僅是因為做了多版本并發(fā)控制(Multiversion concurrency control), http://en.wikipedia.org/wiki/Multiversion_concurrency_control;但是在Oracle里面,一樣可以做樂觀鎖和悲觀鎖的控制。這本質(zhì)上是應(yīng)用層面的選擇。
觀點5:Oracle實際上用的就是樂觀鎖
分析:這個觀點是錯的;
前面說了,Oracle的確可以做到寫不阻塞讀,但是這不是悲觀鎖和樂觀鎖的問題。這是因為實現(xiàn)了多版本并發(fā)控制。按照wiki的定義,悲觀鎖和樂觀鎖是在應(yīng)用層面選擇的。Oracle的應(yīng)用只要在第二步做了select for update,就是悲觀鎖的做法;況且Oracle在任何隔離級別下,除了分布式事務(wù)兩階段提交的短暫時間,其他所有情況下都不存在寫阻塞讀的情況,如果按照這個觀點的話那Oracle已經(jīng)不能做悲觀鎖了-_-
觀點6:不需要這么麻煩,只需要在d這步,最后提交更新的時候再做一個普通的select檢查一下就可以;[就是double check的做法]
分析:這個觀點是錯的。
這個做法其實在http://www.hetaoblog.com/database-lost-update-pessimistic-lock/,’3. 傳統(tǒng)悲觀鎖做法的變通’這節(jié)已經(jīng)說明了,如果要這么做的話,仍然需要在最后提交更新前double check的時候做一個select for update, 否則select結(jié)束到update提交前的時間仍然有可能記錄被修改;
觀點7:應(yīng)該盡可能使用悲觀鎖;
分析:這個觀點是錯的;
a. 根據(jù)悲觀鎖的概念,用戶在讀的時候(b這步)就會將記錄鎖住,直到更新結(jié)束的時候才會將鎖釋放,所以整個鎖的過程時間比較長;
b. 另外,悲觀鎖需要有一個持續(xù)的數(shù)據(jù)庫連接,這在當(dāng)今的web應(yīng)用中已經(jīng)幾乎不存在;wiki上也說了, 悲觀鎖‘is not appropriate for use in web application development.’
所以,現(xiàn)在大部分應(yīng)用都應(yīng)該是樂觀鎖的;
轉(zhuǎn)自:http://zhidao.baidu.com/link?url=MUOUg59oz7-FKwz-zuUviGryfw9J4V63Pd2iWWErorwUpyeL85rznlmYaGDHXjH_ChywA3R1m9XNpx4k7RCCT3rNofjkCxIBYHdsvwr2bVy
1、常規(guī)網(wǎng)絡(luò)訪問限制:
a、線上運營設(shè)備的SSH端口不允許綁定在公網(wǎng)IP地址上,開發(fā)只能登錄開發(fā)機然后通過內(nèi)網(wǎng)登錄這些服務(wù)器;
b、開發(fā)機、測試機的SSH端口可以綁定在公網(wǎng)IP地址上,SSH端口(22)可以考慮改為非知名端口;
c、線上運營設(shè)備、開發(fā)機、測試機的防火墻配置,公網(wǎng)只做80(HTTP)、8080(HTTP)、443(HTTPS)、SSH端口(僅限開發(fā)機、測試機)對外授權(quán)訪問;
d、線上運營設(shè)備、開發(fā)機、測試機除第c點以外所有服務(wù)端口禁止綁定在公網(wǎng)IP地址上,尤其是3306端口(MySQL);
2、DB保護(hù),
a、DB服務(wù)器不允許配置公網(wǎng)IP(或用防火墻全部禁止公網(wǎng)訪問);
b、DB的root賬戶不用于業(yè)務(wù)訪問,回收集中管理,開放普通賬戶做業(yè)務(wù)邏輯訪問,對不同安全要求的庫表用不同的賬戶密碼訪問;
c、程序不要把DB訪問的賬戶密碼寫到配置文件中,寫入代碼或啟動時遠(yuǎn)程到配置中心拉取(此方法比較重,可暫不考慮)。
d、另:DB備份文件可以考慮做加密處理;
3、系統(tǒng)安全:
a、設(shè)備的root密碼回收集中管理,給開發(fā)提供普通用戶帳號;
b、密碼需要定期修改,有強度要求;
4、業(yè)務(wù)訪問控制:
a、業(yè)務(wù)服務(wù)邏輯和運營平臺,盡量不要提供對用戶表和訂單表的批量訪問接口,如果運營平臺確實有這樣的需求,需要對特定賬戶做授權(quán);
安全的代價是不方便、效率會下降,需要尋找平衡點。