2014年3月27日
#
今天啟動Tomcat啟動不了,報以下錯: org.apache.catalina.core.StandardContext startInternal SEVERE: Error listenerStart org.apache.catalina.core.StandardContext startInternal SEVERE: Context [/******] startup failed due to previous errors 網上找了N多文章,都沒有切中要害。 后來在國外網站上搜到一個方法 http://grails.1312388.n4.nabble.com/Deployment-problems-td4628710.html。 我試了一下,是可以的。方案如下。 Tomcat報的錯太含糊了,什么錯都沒報出來,只提示了Error listenerStart。為了調試,我們要獲得更詳細的日志。可以在WEB-INF/classes目錄下新建一個文件叫logging.properties,內容如下 Java代碼

- handlers = org.apache.juli.FileHandler, java.util.logging.ConsoleHandler
-
- ############################################################
- # Handler specific properties.
- # Describes specific configuration info for Handlers.
- ############################################################
-
- org.apache.juli.FileHandler.level = FINE
- org.apache.juli.FileHandler.directory = ${catalina.base}/logs
- org.apache.juli.FileHandler.prefix = error-debug.
-
- java.util.logging.ConsoleHandler.level = FINE
- java.util.logging.ConsoleHandler.formatter = java.util.logging.SimpleFormatter
每秒查詢率QPS是對一個特定的查詢服務器在規定時間內所處理流量多少的衡量標準,在因特網上,作為域名系統服務器的機器的性能經常用每秒查詢率來衡量。
原理:每天80%的訪問集中在20%的時間里,這20%時間叫做峰值時間
公式:( 總PV數 * 80% ) / ( 每天秒數 * 20% ) = 峰值時間每秒請求數(QPS)
機器:峰值時間每秒QPS / 單臺機器的QPS = 需要的機器
問:每天300w PV 的在單臺機器上,這臺機器需要多少QPS?
答:( 3000000 * 0.8 ) / (86400 * 0.2 ) = 139 (QPS)
問:如果一臺機器的QPS是58,需要幾臺機器來支持?
答:139 / 58 = 3
現在敏捷開發是越來越火了,人人都在談敏捷,人人都在學習Scrum和XP...
為了不落后他人,于是我也開始學習Scrum,今天主要是對我最近閱讀的相關資料,根據自己的理解,用自己的話來講述Scrum中的各個環節,主要目的有兩個,一個是進行知識的總結,另外一個是覺得網上很多學習資料的講述方式讓初學者不太容易理解;所以我決定寫一篇掃盲性的博文,同時試著也與園內的朋友一起分享交流一下,希望對初學者有幫助。
什么是敏捷開發?
敏捷開發(Agile Development)是一種以人為核心、迭代、循序漸進的開發方法。
怎么理解呢?首先,我們要理解它不是一門技術,它是一種開發方法,也就是一種軟件開發的流程,它會指導我們用規定的環節去一步一步完成項目的開發;而這種開發方式的主要驅動核心是人;它采用的是迭代式開發;
為什么說是以人為核心?
我們大部分人都學過瀑布開發模型,它是以文檔為驅動的,為什么呢?因為在瀑布的整個開發過程中,要寫大量的文檔,把需求文檔寫出來后,開發人員都是根據文檔進行開發的,一切以文檔為依據;而敏捷開發它只寫有必要的文檔,或盡量少寫文檔,敏捷開發注重的是人與人之間,面對面的交流,所以它強調以人為核心。
什么是迭代?
迭代是指把一個復雜且開發周期很長的開發任務,分解為很多小周期可完成的任務,這樣的一個周期就是一次迭代的過程;同時每一次迭代都可以生產或開發出一個可以交付的軟件產品。
關于Scrum和XP
前面說了敏捷它是一種指導思想或開發方式,但是它沒有明確告訴我們到底采用什么樣的流程進行開發,而Scrum和XP就是敏捷開發的具體方式了,你可以采用Scrum方式也可以采用XP方式;Scrum和XP的區別是,Scrum偏重于過程,XP則偏重于實踐,但是實際中,兩者是結合一起應用的,這里我主要講Scrum。
什么是Scrum?
Scrum的英文意思是橄欖球運動的一個專業術語,表示“爭球”的動作;把一個開發流程的名字取名為Scrum,我想你一定能想象出你的開發團隊在開發一個項目時,大家像打橄欖球一樣迅速、富有戰斗激情、人人你爭我搶地完成它,你一定會感到非常興奮的。
而Scrum就是這樣的一個開發流程,運用該流程,你就能看到你團隊高效的工作。
【Scrum開發流程中的三大角色】
產品負責人(Product Owner)
主要負責確定產品的功能和達到要求的標準,指定軟件的發布日期和交付的內容,同時有權力接受或拒絕開發團隊的工作成果。
流程管理員(Scrum Master)
主要負責整個Scrum流程在項目中的順利實施和進行,以及清除擋在客戶和開發工作之間的溝通障礙,使得客戶可以直接驅動開發。
開發團隊(Scrum Team)
主要負責軟件產品在Scrum規定流程下進行開發工作,人數控制在5~10人左右,每個成員可能負責不同的技術方面,但要求每成員必須要有很強的自我管理能力,同時具有一定的表達能力;成員可以采用任何工作方式,只要能達到Sprint的目標。
Scrum流程圖
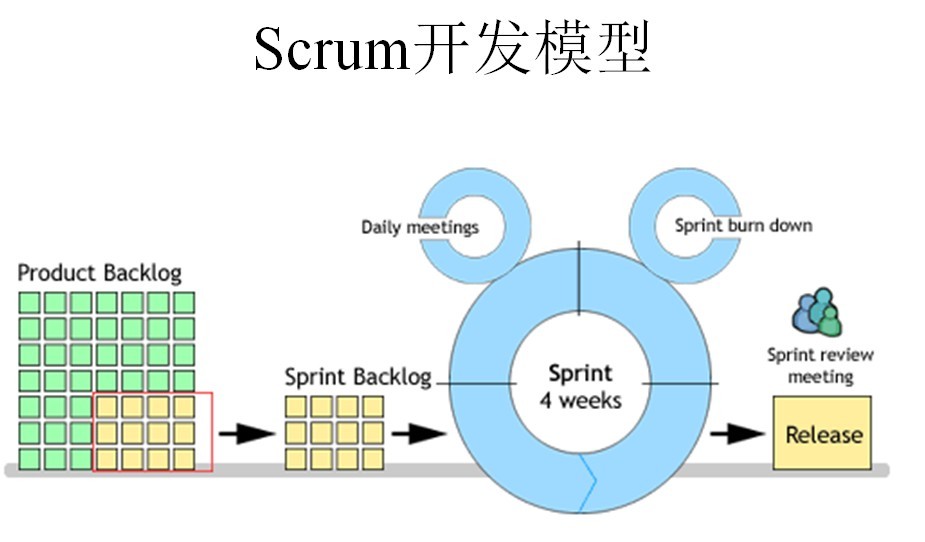
//------------------------
下面,我們開始講具體實施流程,但是在講之前,我還要對一個英文單詞進行講解。
什么是Sprint?
Sprint是短距離賽跑的意思,這里面指的是一次迭代,而一次迭代的周期是1個月時間(即4個星期),也就是我們要把一次迭代的開發內容以最快的速度完成它,這個過程我們稱它為Sprint。
如何進行Scrum開發?
1、我們首先需要確定一個Product Backlog(按優先順序排列的一個產品需求列表),這個是由Product Owner 負責的;
2、Scrum Team根據Product Backlog列表,做工作量的預估和安排;
3、有了Product Backlog列表,我們需要通過 Sprint Planning Meeting(Sprint計劃會議) 來從中挑選出一個Story作為本次迭代完成的目標,這個目標的時間周期是1~4個星期,然后把這個Story進行細化,形成一個Sprint Backlog;
4、Sprint Backlog是由Scrum Team去完成的,每個成員根據Sprint Backlog再細化成更小的任務(細到每個任務的工作量在2天內能完成);
5、在Scrum Team完成計劃會議上選出的Sprint Backlog過程中,需要進行 Daily Scrum Meeting(每日站立會議),每次會議控制在15分鐘左右,每個人都必須發言,并且要向所有成員當面匯報你昨天完成了什么,并且向所有成員承諾你今天要完成什么,同時遇到不能解決的問題也可以提出,每個人回答完成后,要走到黑板前更新自己的 Sprint burn down(Sprint燃盡圖);
6、做到每日集成,也就是每天都要有一個可以成功編譯、并且可以演示的版本;很多人可能還沒有用過自動化的每日集成,其實TFS就有這個功能,它可以支持每次有成員進行簽入操作的時候,在服務器上自動獲取最新版本,然后在服務器中編譯,如果通過則馬上再執行單元測試代碼,如果也全部通過,則將該版本發布,這時一次正式的簽入操作才保存到TFS中,中間有任何失敗,都會用郵件通知項目管理人員;
7、當一個Story完成,也就是Sprint Backlog被完成,也就表示一次Sprint完成,這時,我們要進行 Srpint Review Meeting(演示會議),也稱為評審會議,產品負責人和客戶都要參加(最好本公司老板也參加),每一個Scrum Team的成員都要向他們演示自己完成的軟件產品(這個會議非常重要,一定不能取消);
8、最后就是 Sprint Retrospective Meeting(回顧會議),也稱為總結會議,以輪流發言方式進行,每個人都要發言,總結并討論改進的地方,放入下一輪Sprint的產品需求中;
下面是運用Scrum開發流程中的一些場景圖:
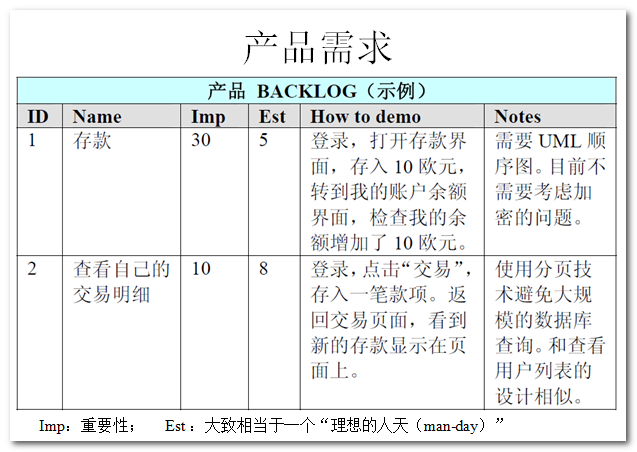
上圖是一個 Product Backlog 的示例。

上圖就是每日的站立會議了,參會人員可以隨意姿勢站立,任務看板要保證讓每個人看到,當每個人發言完后,要走到任務版前更新自己的燃盡圖。
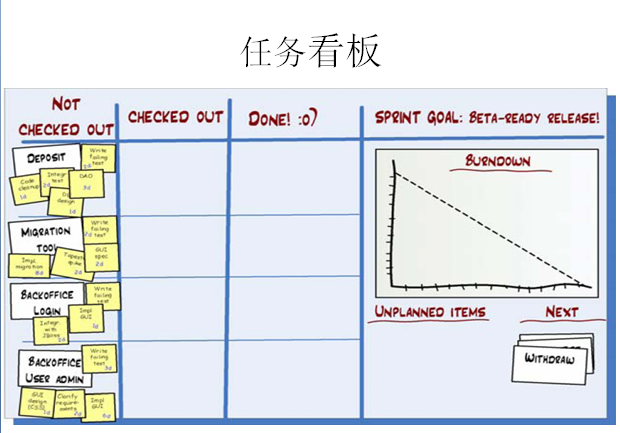
任務看版包含 未完成、正在做、已完成 的工作狀態,假設你今天把一個未完成的工作已經完成,那么你要把小卡片從未完成區域貼到已完成區域。

每個人的工作進度和完成情況都是公開的,如果有一個人的工作任務在某一個位置放了好幾天,大家都能發現他的工作進度出現了什么問題(成員人數最好是5~7個,這樣每人可以使用一種專用顏色的標簽紙,一眼就可以從任務版看出誰的工作進度快,誰的工作進度慢)

上圖可不是撲克牌,它是計劃紙牌,它的作用是防止項目在開發過程中,被某些人所領導。
怎么用的呢?比如A程序員開發一個功能,需要5個小時,B程序員認為只需要半小時,那他們各自取相應的牌,藏在手中,最后攤牌,如果時間差距很大,那么A和B就可以討論A為什么要5個小時...
轉自:http://www.cnblogs.com/taven/archive/2010/10/17/1853386.html
先申明概念:
1、悲觀鎖,正如其名,它指的是對數據被外界(包括本系統當前的其他事務,以及來自外部系統的事務處理)修改持保守態度,因此,在整個數據處理過程中,將數據處于鎖定狀態。悲觀鎖的實現,往往依靠數據庫提供的鎖機制(也只有數據庫層提供的鎖機制才能真正保證數據訪問的排他性,否則,即使在本系統中實現了加鎖機制,也無法保證外部系統不會修改數據)。
2、樂觀鎖( Optimistic Locking )
相對悲觀鎖而言,樂觀鎖機制采取了更加寬松的加鎖機制。悲觀鎖大多數情況下依靠數據庫的鎖機制實現,以保證操作最大程度的獨占性。但隨之而來的就是數據庫性能的大量開銷,特別是對長事務而言,這樣的開銷往往無法承受。而樂觀鎖機制在一定程度上解決了這個問題。樂觀鎖,大多是基于數據版本( Version )記錄機制實現。何謂數據版本?即為數據增加一個版本標識,在基于數據庫表的版本解決方案中,一般是通過為數據庫表增加一個 “version” 字段來實現。讀取出數據時,將此版本號一同讀出,之后更新時,對此版本號加一。此時,將提交數據的版本數據與數據庫表對應記錄的當前版本信息進行比對,如果提交的數據版本號大于數據庫表當前版本號,則予以更新,否則認為是過期數據。
所以悲觀鎖和樂觀鎖最大的區別是是否一直鎖定資源,悲觀鎖在事物的全流程鎖定數據,樂觀鎖不鎖定數據(用讀寫鎖是阻塞事物,而用樂觀鎖則會導致回滾。這個是一種事物沖突后的不同鎖的表象)。樂觀鎖的最大特點是在最后檢查數據是否被修改,如果已被別人修改過,則回滾數據,避免臟數據。至于事物是否沖突和加鎖沒有直接聯系,該沖突的還是會沖突,不管你加悲觀鎖和樂觀鎖都會沖突。
悲觀鎖和樂觀鎖都是為了解決丟失更新問題或者是臟讀。悲觀鎖和樂觀鎖的重點就是是否在讀取記錄的時候直接上鎖。悲觀鎖的缺點很明顯,需要一個持續的數據庫連接,這在web應用中已經不適合了。
一個比較清楚的場景
下面這個假設的實際場景可以比較清楚的幫助我們理解這個問題:
a. 假設當當網上用戶下單買了本書,這時數據庫中有條訂單號為001的訂單,其中有個status字段是’有效’,表示該訂單是有效的;
b. 后臺管理人員查詢到這條001的訂單,并且看到狀態是有效的
c. 用戶發現下單的時候下錯了,于是撤銷訂單,假設運行這樣一條SQL: update order_table set status = ‘取消’ where order_id = 001;
d. 后臺管理人員由于在b這步看到狀態有效的,這時,雖然用戶在c這步已經撤銷了訂單,可是管理人員并未刷新界面,看到的訂單狀態還是有效的,于是點擊”發貨”按鈕,將該訂單發到物流部門,同時運行類似如下SQL,將訂單狀態改成已發貨:update order_table set status = ‘已發貨’ where order_id = 001
觀點1:只有沖突非常嚴重的系統才需要悲觀鎖;
分析:這是更準確的說法;
“所有悲觀鎖的做法都適合于狀態被修改的概率比較高的情況,具體是否合適則需要根據實際情況判斷。”,表達的也是這個意思,不過說法不夠準確;的確,之所以用悲觀鎖就是因為兩個用戶更新同一條數據的概率高,也就是沖突比較嚴重的情況下,所以才用悲觀鎖。
觀點2:最后提交前作一次select for update檢查,然后再提交update也是一種樂觀鎖的做法
分析:這是更準確的說法;
的確,這符合傳統樂觀鎖的做法,就是到最后再去檢查。但是wiki在解釋悲觀鎖的做法的時候,’It is not appropriate for use in web application development.’, 現在已經很少有悲觀鎖的做法了,所以我自己將這種二次檢查的做法也歸為悲觀鎖的變種,因為這在所有樂觀鎖里面,做法和悲觀鎖是最接近的,都是先select for update,然后update
*****除了上面的觀點1和觀點2是更準確的說法,下面的所有觀點都是錯誤的***********
觀點3:這個問題的原因是因為數據庫隔離級別是uncommitted read級別;
分析:這個觀點是錯誤的;
這個過程本身就是在read committed隔離級別下發生的,從a到d每一步,尤其是d這步,并不是因為讀到了未提交的數據,僅僅是因為用戶界面沒有刷新[事實上也不可能做自動刷新,這樣相當于數據庫一發生改變立刻要刷新了,這需要監聽數據庫了,顯然這是簡單問題復雜化了];
觀點4:悲觀鎖是指一個用戶在更新數據的時候,其他用戶不能讀取這條記錄;也就是update阻塞讀才叫悲觀鎖;
分析:這個觀點是錯的;
這在db2背景的開發中尤其常見;因為db2默認就是update會阻塞讀;但是這是各個數據庫對讀寫的時候上鎖的并發處理實現不一樣。但這根本不是悲觀鎖樂觀鎖的區別。Oracle可以做到寫不阻塞讀僅僅是因為做了多版本并發控制(Multiversion concurrency control), http://en.wikipedia.org/wiki/Multiversion_concurrency_control;但是在Oracle里面,一樣可以做樂觀鎖和悲觀鎖的控制。這本質上是應用層面的選擇。
觀點5:Oracle實際上用的就是樂觀鎖
分析:這個觀點是錯的;
前面說了,Oracle的確可以做到寫不阻塞讀,但是這不是悲觀鎖和樂觀鎖的問題。這是因為實現了多版本并發控制。按照wiki的定義,悲觀鎖和樂觀鎖是在應用層面選擇的。Oracle的應用只要在第二步做了select for update,就是悲觀鎖的做法;況且Oracle在任何隔離級別下,除了分布式事務兩階段提交的短暫時間,其他所有情況下都不存在寫阻塞讀的情況,如果按照這個觀點的話那Oracle已經不能做悲觀鎖了-_-
觀點6:不需要這么麻煩,只需要在d這步,最后提交更新的時候再做一個普通的select檢查一下就可以;[就是double check的做法]
分析:這個觀點是錯的。
這個做法其實在http://www.hetaoblog.com/database-lost-update-pessimistic-lock/,’3. 傳統悲觀鎖做法的變通’這節已經說明了,如果要這么做的話,仍然需要在最后提交更新前double check的時候做一個select for update, 否則select結束到update提交前的時間仍然有可能記錄被修改;
觀點7:應該盡可能使用悲觀鎖;
分析:這個觀點是錯的;
a. 根據悲觀鎖的概念,用戶在讀的時候(b這步)就會將記錄鎖住,直到更新結束的時候才會將鎖釋放,所以整個鎖的過程時間比較長;
b. 另外,悲觀鎖需要有一個持續的數據庫連接,這在當今的web應用中已經幾乎不存在;wiki上也說了, 悲觀鎖‘is not appropriate for use in web application development.’
所以,現在大部分應用都應該是樂觀鎖的;
轉自:http://zhidao.baidu.com/link?url=MUOUg59oz7-FKwz-zuUviGryfw9J4V63Pd2iWWErorwUpyeL85rznlmYaGDHXjH_ChywA3R1m9XNpx4k7RCCT3rNofjkCxIBYHdsvwr2bVy
JDK1.5以后,在鎖機制方面引入了新的鎖-Lock,在網上的說法都比較籠統,結合網上的信息和我的理解這里做個總結。 java現有的鎖機制有兩種實現方式,J.DK1.4前是通過synchronized實現,JDK1.5后加入java.util.concurrent.locks包下的各種lock(以下簡稱Lock) 先說說代碼層的區別。 synchronized:在代碼里,synchronized類似“面向對象”,修飾類、方法、對象。 Lock:不作為修飾,類似“面向過程”,在方法中需要鎖的時候lock,在結束的時候unlock(一般都在finally塊里)。 例如代碼: Java代碼

- public void method1() {
- synchronized(this){//舊鎖,無需人工釋放
- System.out.println(1);
- }
- }
-
- public void method2() {
- Lock lock = new ReentrantLock();
- lock.lock();//上鎖
- try{
- System.out.println(2);
- }finally{
- lock.unlock();//解鎖
- }
- }
之所以起這樣一個題目是因為很久以前我曾經寫過一篇介紹TIME_WAIT的文章,不過當時基本屬于淺嘗輒止,并沒深入說明問題的來龍去脈,碰巧這段時間反復被別人問到相關的問題,讓我覺得有必要全面總結一下,以備不時之需。
討論前大家可以拿手頭的服務器摸摸底,記住「ss」比「netstat」快:
shell> ss -ant | awk ' NR>1 {++s[$1]} END {for(k in s) print k,s[k]} '如果你只是想單獨查詢一下TIME_WAIT的數量,那么還可以更簡單一些:
shell> cat /proc/net/sockstat
我猜你一定被巨大無比的TIME_WAIT網絡連接總數嚇到了!以我個人的經驗,對于一臺繁忙的Web服務器來說,如果主要以短連接為主,那么其TIME_WAIT網絡連接總數很可能會達到幾萬,甚至十幾萬。雖然一個TIME_WAIT網絡連接耗費的資源無非就是一個端口、一點內存,但是架不住基數大,所以這始終是一個需要面對的問題。
為什么會存在TIME_WAIT?
TCP在建立連接的時候需要握手,同理,在關閉連接的時候也需要握手。為了更直觀的說明關閉連接時握手的過程,我們引用「The TCP/IP Guide」中的例子:

TCP Close
因為TCP連接是雙向的,所以在關閉連接的時候,兩個方向各自都需要關閉。先發FIN包的一方執行的是主動關閉;后發FIN包的一方執行的是被動關閉。主動關閉的一方會進入TIME_WAIT狀態,并且在此狀態停留兩倍的MSL時長。
穿插一點MSL的知識:MSL指的是報文段的最大生存時間,如果報文段在網絡活動了MSL時間,還沒有被接收,那么會被丟棄。關于MSL的大小,RFC 793協議中給出的建議是兩分鐘,不過實際上不同的操作系統可能有不同的設置,以Linux為例,通常是半分鐘,兩倍的MSL就是一分鐘,也就是60秒,并且這個數值是硬編碼在內核中的,也就是說除非你重新編譯內核,否則沒法修改它:
#define TCP_TIMEWAIT_LEN (60*HZ)
如果每秒的連接數是一千的話,那么一分鐘就可能會產生六萬個TIME_WAIT。
為什么主動關閉的一方不直接進入CLOSED狀態,而是進入TIME_WAIT狀態,并且停留兩倍的MSL時長呢?這是因為TCP是建立在不可靠網絡上的可靠的協議。例子:主動關閉的一方收到被動關閉的一方發出的FIN包后,回應ACK包,同時進入TIME_WAIT狀態,但是因為網絡原因,主動關閉的一方發送的這個ACK包很可能延遲,從而觸發被動連接一方重傳FIN包。極端情況下,這一去一回,就是兩倍的MSL時長。如果主動關閉的一方跳過TIME_WAIT直接進入CLOSED,或者在TIME_WAIT停留的時長不足兩倍的MSL,那么當被動關閉的一方早先發出的延遲包到達后,就可能出現類似下面的問題:
- 舊的TCP連接已經不存在了,系統此時只能返回RST包
- 新的TCP連接被建立起來了,延遲包可能干擾新的連接
不管是哪種情況都會讓TCP不再可靠,所以TIME_WAIT狀態有存在的必要性。
如何控制TIME_WAIT的數量?
從前面的描述我們可以得出這樣的結論:TIME_WAIT這東西沒有的話不行,不過太多可能也是個麻煩事。下面讓我們看看有哪些方法可以控制TIME_WAIT數量,這里只說一些常規方法,另外一些諸如SO_LINGER之類的方法太過偏門,略過不談。
ip_conntrack:顧名思義就是跟蹤連接。一旦激活了此模塊,就能在系統參數里發現很多用來控制網絡連接狀態超時的設置,其中自然也包括TIME_WAIT:
shell> modprobe ip_conntrack shell> sysctl net.ipv4.netfilter.ip_conntrack_tcp_timeout_time_wait
我們可以嘗試縮小它的設置,比如十秒,甚至一秒,具體設置成多少合適取決于網絡情況而定,當然也可以參考相關的案例。不過就我的個人意見來說,ip_conntrack引入的問題比解決的還多,比如性能會大幅下降,所以不建議使用。
tcp_tw_recycle:顧名思義就是回收TIME_WAIT連接。可以說這個內核參數已經變成了大眾處理TIME_WAIT的萬金油,如果你在網絡上搜索TIME_WAIT的解決方案,十有八九會推薦設置它,不過這里隱藏著一個不易察覺的陷阱:
當多個客戶端通過NAT方式聯網并與服務端交互時,服務端看到的是同一個IP,也就是說對服務端而言這些客戶端實際上等同于一個,可惜由于這些客戶端的時間戳可能存在差異,于是乎從服務端的視角看,便可能出現時間戳錯亂的現象,進而直接導致時間戳小的數據包被丟棄。參考:tcp_tw_recycle和tcp_timestamps導致connect失敗問題。
tcp_tw_reuse:顧名思義就是復用TIME_WAIT連接。當創建新連接的時候,如果可能的話會考慮復用相應的TIME_WAIT連接。通常認為「tcp_tw_reuse」比「tcp_tw_recycle」安全一些,這是因為一來TIME_WAIT創建時間必須超過一秒才可能會被復用;二來只有連接的時間戳是遞增的時候才會被復用。官方文檔里是這樣說的:如果從協議視角看它是安全的,那么就可以使用。這簡直就是外交辭令啊!按我的看法,如果網絡比較穩定,比如都是內網連接,那么就可以嘗試使用。
不過需要注意的是在哪里使用,既然我們要復用連接,那么當然應該在連接的發起方使用,而不能在被連接方使用。舉例來說:客戶端向服務端發起HTTP請求,服務端響應后主動關閉連接,于是TIME_WAIT便留在了服務端,此類情況使用「tcp_tw_reuse」是無效的,因為服務端是被連接方,所以不存在復用連接一說。讓我們延伸一點來看,比如說服務端是PHP,它查詢另一個MySQL服務端,然后主動斷開連接,于是TIME_WAIT就落在了PHP一側,此類情況下使用「tcp_tw_reuse」是有效的,因為此時PHP相對于MySQL而言是客戶端,它是連接的發起方,所以可以復用連接。
說明:如果使用tcp_tw_reuse,請激活tcp_timestamps,否則無效。
tcp_max_tw_buckets:顧名思義就是控制TIME_WAIT總數。官網文檔說這個選項只是為了阻止一些簡單的DoS攻擊,平常不要人為的降低它。如果縮小了它,那么系統會將多余的TIME_WAIT刪除掉,日志里會顯示:「TCP: time wait bucket table overflow」。
需要提醒大家的是物極必反,曾經看到有人把「tcp_max_tw_buckets」設置成0,也就是說完全拋棄TIME_WAIT,這就有些冒險了,用一句圍棋諺語來說:入界宜緩。
…
有時候,如果我們換個角度去看問題,往往能得到四兩撥千斤的效果。前面提到的例子:客戶端向服務端發起HTTP請求,服務端響應后主動關閉連接,于是TIME_WAIT便留在了服務端。這里的關鍵在于主動關閉連接的是服務端!在關閉TCP連接的時候,先出手的一方注定逃不開TIME_WAIT的宿命,套用一句歌詞:把我的悲傷留給自己,你的美麗讓你帶走。如果客戶端可控的話,那么在服務端打開KeepAlive,盡可能不讓服務端主動關閉連接,而讓客戶端主動關閉連接,如此一來問題便迎刃而解了。
參考文檔:
- tcp短連接TIME_WAIT問題解決方法大全(1)——高屋建瓴
- tcp短連接TIME_WAIT問題解決方法大全(2)——SO_LINGER
- tcp短連接TIME_WAIT問題解決方法大全(3)——tcp_tw_recycle
- tcp短連接TIME_WAIT問題解決方法大全(4)——tcp_tw_reuse
- tcp短連接TIME_WAIT問題解決方法大全(5)——tcp_max_tw_buckets
1、常規網絡訪問限制:
a、線上運營設備的SSH端口不允許綁定在公網IP地址上,開發只能登錄開發機然后通過內網登錄這些服務器;
b、開發機、測試機的SSH端口可以綁定在公網IP地址上,SSH端口(22)可以考慮改為非知名端口;
c、線上運營設備、開發機、測試機的防火墻配置,公網只做80(HTTP)、8080(HTTP)、443(HTTPS)、SSH端口(僅限開發機、測試機)對外授權訪問;
d、線上運營設備、開發機、測試機除第c點以外所有服務端口禁止綁定在公網IP地址上,尤其是3306端口(MySQL);
2、DB保護,
a、DB服務器不允許配置公網IP(或用防火墻全部禁止公網訪問);
b、DB的root賬戶不用于業務訪問,回收集中管理,開放普通賬戶做業務邏輯訪問,對不同安全要求的庫表用不同的賬戶密碼訪問;
c、程序不要把DB訪問的賬戶密碼寫到配置文件中,寫入代碼或啟動時遠程到配置中心拉取(此方法比較重,可暫不考慮)。
d、另:DB備份文件可以考慮做加密處理;
3、系統安全:
a、設備的root密碼回收集中管理,給開發提供普通用戶帳號;
b、密碼需要定期修改,有強度要求;
4、業務訪問控制:
a、業務服務邏輯和運營平臺,盡量不要提供對用戶表和訂單表的批量訪問接口,如果運營平臺確實有這樣的需求,需要對特定賬戶做授權;
安全的代價是不方便、效率會下降,需要尋找平衡點。
轉自http://www.witwebs.com/aliyun-mount-init/
阿里云的服務器,國內訪問速度,穩定性一直都是不錯的。至少我在使用的過程中,還未碰到什么問題。我將自己在使用主機過程的安裝和環境配置做一個詳細的介紹。僅供新手朋友參考!當我們在購買到阿里云服務器之后,會獲得相應的IP地址和管理密碼。
主要介紹Linux的數據盤的格式化和掛載。
大致步驟是: 登陸Linux > 查看硬盤狀況 > 分區數據盤 > 格式化數據盤 > 掛載新分區
將會用到的命令如下:
df -h 查看已掛載硬盤信息
fdisk -l 查看磁盤信息,未掛載的也會列出來
fdisk /dev/xvdb 對數據盤進行分區,回車之后,繼續 根據提示,依次輸入”n” ,”p”,“1”,兩次回車,“wq”, 分區就開始了,很快就會完成
mkfs .ext3 /dev/xvdb1 命令對新分區進行格式化
echo ‘/dev/xvdb1 /www ext3 defaults 0 0′ >> /etc/fstab 添加分區信息
mount -a 命令掛載新分區
1:通過Linux SSH 登陸軟件登陸你的linux。登陸之后輸入命令:df -lh 的界面如圖:

2:輸入命令: fdisk -l 查看磁盤狀況,可以看到有數據盤: /dev/xvdb 而用df沒有查看到這個磁盤。所以需要另外掛載。

3: 用 fdisk /dev/xvdb 對數據盤進行分區。根據提示,輸入 n, p, 1, 回車,回車, wq。
完成之后,再用 fdisk -l,就可以看到顯示的信息和之前有不同了。

4:格式化磁盤。 mkfs .ext3 /dev/xvdb1 ,格式化磁盤。完成之后,就可以來掛載分區了。

5, 掛載分區,首先建立一個目錄用來掛載分區。比如: mkdir /www
然后把分區信息加入到fstab中:一次執行:
echo ‘/dev/xvdb1 /www ext3 defaults 0 0′ >> /etc/fstab 添加分區信息
mount -a 命令掛載新分區
最后用 df -h 命令查看,將會發現數據盤。

OK,希望能幫到各位。
1、需要先安裝gcc和tcl
yum install gcc
yum install tcl
2、下載并安裝redis
cd /opt
wget http://download.redis.io/releases/redis-3.0.0.tar.gz
tar -zxvf /opt/redis-3.0.0.tar.gz
cd /opt/redis-3.0.0
make
make test
make PREFIX=/opt/redis-3.0.0 install
注:PREFIX一定要大寫,裝好后,會生成/opt/redis-3.0.0/bin目錄,里面有啟動命令之類的文件。
3、啟動與關閉
redis啟動
/opt/redis-3.0.0/bin/redis-server /opt/redis-3.0.0/redis.conf
redis關閉
/opt/redis-3.0.0/bin/redis-cli -h 127.0.0.1 -p 6379 shutdown
客戶端啟動
/opt/redis-3.0.0/bin/redis-cli
set name test
get name
4、參數修改
/opt/redis-3.0.0/redis.conf文件修改
#后臺運行,可以ctrl+c不至于退出
daemonize yes
關于錯誤提示
(1)編輯/etc/sysctl.conf ,最下面加一行vm.overcommit_memory=1,然后sysctl -p 使配置文件生效
(2)sysctl vm.overcommit_memory=1
注:如果使用了云服務器,要記得打開6379端口,否則無法遠程訪問
1、svnadmin create /opt/svn/yiss/app/ios1、apache里的httpd.conf配置如下:
每個庫單獨
<Location /yiss/app/ios>#這個是ios項目url上的訪問上下文,對應http://IP/yiss/app/ios/
DAV svn
SVNPath /opt/svn/yiss/app/ios#這個是svn庫的絕對路徑
AuthType Basic#校驗方式
AuthName "please input username/password"#提示信息
AuthUserFile /opt/svn/passwd#密碼文件絕對路徑
AuthzSVNAccessFile /opt/svn/authz#權限文件絕對路徑
Require valid-user
</Location>
<Location /yiss/app/android>#安卓項目訪問上下文
DAV svn
SVNPath /opt/svn/yiss/app/android
AuthType Basic
AuthName "please input username/password"
AuthUserFile /opt/svn/passwd
AuthzSVNAccessFile /opt/svn/authz
Require valid-user
</Location>
<Location /yiss/web/buildscript>
DAV svn
SVNPath /opt/svn/yiss/web/buildscript
AuthType Basic
AuthName "please input username/password"
AuthUserFile /opt/svn/passwd
AuthzSVNAccessFile /opt/svn/authz
Require valid-user
</Location>
2、首先要創建/opt/svn/yiss/app目錄和/opt/svn/yiss/web
然后用命令創建svn庫
svnadmin create /opt/svn/yiss/app/ios
svnadmin create /opt/svn/yiss/app/android
svnadmin create /opt/svn/yiss/web/buildscript
3、創建apache用戶和密碼,會提示重復輸入2次確認。想改密碼就多次輸入,以最后一次輸入的為準。
htpasswd /opt/svn/passwd wxq
htpasswd /opt/svn/passwd caowei
......
4、配置權限組/opt/svn/authz
[groups]
admin=wxq
web=caowei,luocan,houlei,gengzhuo,huangwei,wuhaiying,leo
app=ssh,golden,shawn,leo
#admin組用戶可以訪問所有目錄
[/]
@admin=rw
#ios,android,srv,doc,buildscript這些都是庫名,這里創建了3個庫
[ios:/]
@app=rw
[android:/]
@app=rw
[buildscript:/]
@admin=rw
5、給目錄及子目錄授權,否則會報403forbidden無權限
chmod 777 /opt/svn -R
6、重啟svn,啟動的時候要以根啟動,如果以某個svn庫啟動,則其他庫無法啟動。
killall svnserve
svnserve -d -r /opt/svn/yiss
7、重啟apache
/opt/apache/bin/apachectl restart
8、瀏覽測試
http://115.231.94.x/yiss/app/ios/
http://115.231.94.x/yiss/app/android/
http://115.231.94.x/yiss/web/buildscript/
LoadModule auth_basic_module modules/mod_auth_basic.so #基本認證模塊
LoadModule auth_digest_module modules/mod_auth_digest.so #使用MD5的用戶驗證模塊
LoadModule authn_file_module modules/mod_authn_file.so #使用文本文件的用戶驗證
LoadModule authn_alias_module modules/mod_authn_alias.so #在原有的驗證方法上提供拓展的驗證
LoadModule authn_anon_module modules/mod_authn_anon.so #允許匿名訪問已驗證的區域
LoadModule authn_dbm_module modules/mod_authn_dbm.so #使用數據庫文件驗證
LoadModule authn_default_module modules/mod_authn_default.so #認證的撤銷模塊
LoadModule authz_host_module modules/mod_authz_host.so #基于主機名(或IP)的組授權
LoadModule authz_user_module modules/mod_authz_user.so #用戶授權
LoadModule authz_owner_module modules/mod_authz_owner.so #依照文件擁有者的授權
LoadModule authz_groupfile_module modules/mod_authz_groupfile.so #使用明文文件的組授權
LoadModule authz_dbm_module modules/mod_authz_dbm.so #使用數據庫的組授權
LoadModule authz_default_module modules/mod_authz_default.so #授權的撤銷模塊
LoadModule ldap_module modules/mod_ldap.so #LDAP提供其它LADP的連接接和緩存服務模塊
LoadModule authnz_ldap_module modules/mod_authnz_ldap.so #允許使用一個LDAP的目錄來存放HTTP基本授權文件
LoadModule include_module modules/mod_include.so #服務器端解析HTML語法的模塊
LoadModule log_config_module modules/mod_log_config.so #記錄服務器請求日志
LoadModule logio_module modules/mod_logio.so #記錄每個請求的I/O字節數
LoadModule env_module modules/mod_env.so #設置傳遞給CGI腳本和SSI頁面的環境?
LoadModule ext_filter_module modules/mod_ext_filter.so #在遞交給客戶端以前通過外部程序發送相應本體
LoadModule mime_magic_module modules/mod_mime_magic.so #通過查看一個文件的一些內容判斷MIME類別
LoadModule expires_module modules/mod_expires.so #根據用戶的特別設定來生成失效和隱藏控制的http頭信息
LoadModule deflate_module modules/mod_deflate.so #傳送給客戶端以前壓縮數據
LoadModule headers_module modules/mod_headers.so #定制響應和回復的HTTP頭的內容
LoadModule usertrack_module modules/mod_usertrack.so #在一個站點上跟蹤用戶的登錄信息
LoadModule setenvif_module modules/mod_setenvif.so #允許經過客戶編碼請求來設定環境變量
LoadModule mime_module modules/mod_mime.so #通過文件的一些屬性判讀MIME類型
LoadModule dav_module modules/mod_dav.so #基于WEB的創作和版本?
LoadModule status_module modules/mod_status.so #提供服務器運行信息
LoadModule autoindex_module modules/mod_autoindex.so #自動列出一個目錄的索引表(類似于UNIX上的ls和DOS下的dir)
LoadModule info_module modules/mod_info.so #提供服務配置的一個綜合概況
LoadModule dav_fs_module modules/mod_dav_fs.so #為mod_dav提供文件系統支持
LoadModule vhost_alias_module modules/mod_vhost_alias.so #為虛擬主機提供動態配置
LoadModule negotiation_module modules/mod_negotiation.so #為內容判斷提供支持
LoadModule dir_module modules/mod_dir.so #為“/”結尾的重定向和目錄文件索引
LoadModule actions_module modules/mod_actions.so #提供了基于請求和媒體類型的CGI腳本執行的支持
LoadModule speling_module modules/mod_speling.so #嘗試糾正用戶輸入錯誤的網址
LoadModule userdir_module modules/mod_userdir.so #用戶特定目錄
LoadModule alias_module modules/mod_alias.so #提供主機文件系統不同部分的文件樹映射為URL
LoadModule rewrite_module modules/mod_rewrite.so #提供在運行中基于規則的地址重寫的支持
LoadModule proxy_module modules/mod_proxy.so #基于HTTP1.1協議的網關或代理服務器
LoadModule proxy_balancer_module modules/mod_proxy_balancer.so #負載均衡的mod_proxy拓展
LoadModule proxy_ftp_module modules/mod_proxy_ftp.so #為mod_proxy提供的ftp支持模塊
LoadModule proxy_http_module modules/mod_proxy_http.so #為mod_proxy提供的http支持模塊
LoadModule proxy_connect_module modules/mod_proxy_connect.so #mod_proxy的連接處理拓展模塊
LoadModule cache_module modules/mod_cache.so #目錄隱藏在URL外?
LoadModule suexec_module modules/mod_suexec.so #允許CGI腳本使用特定的用戶和組運行
LoadModule disk_cache_module modules/mod_disk_cache.so #管理內容隱藏存放來適合URL的工具?
LoadModule file_cache_module modules/mod_file_cache.so #在內存中緩存一個文件列表
LoadModule mem_cache_module modules/mod_mem_cache.so #隱藏內容于URL
LoadModule cgi_module modules/mod_cgi.so #執行CGI腳本
1.安裝apr和apr-util
apr, apr-util: http://apr.apache.org/
tar zxvf apr-1.5.1.tar.gz
cd apr-1.5.1
./configure --prefix=/opt/apr
make && make install
tar zxvf apr-util-1.5.4.tar.gz
cd apr-util-1.5.4
./configure --prefix=/opt/apr-util --with-apr=/opt/apr/
make && make install
2.安裝apache下載地址:http://www.apache.org/dist//httpd/httpd-2.2.27.tar.gz
cd /opt
tar -zxvf httpd-2.4.10.tar.gz
cd /opt/httpd-2.4.10
./configure --prefix=/opt/apache --with-apr=/opt/apr/ --with-apr-util=/opt/apr-util/ --with-pcre=/opt/pcre --enable-so --enable-dav --enable-dav-fs
make && make install
其中,–enable-dav允許Apache提供DAV協議支持;–enable-so允許運行時加載DSO模塊,前兩個參數是必須要加的,–prefix 是安裝的位置。如果configure通過,接著執行
數分鐘后就完事了,通過 /opt/apache/bin/apachectl start 來啟動,在瀏覽器中訪問IP比如本機訪問127.0.0.1,如果出現 It’s Works!,那么說明安裝成功。
目錄授權
chmod 777 /opt/svn
chown -R daemon:daemon /opt/svn
3.安裝sqlite,http://www.sqlite.org/download.html
這里下載的是sqlite-autoconf-3080701.tar.gz,我下載到了/root/install并解壓
tar zxvf sqlite-autoconf-3080701.tar.gz
cd /root/install/sqlite-autoconf-3080701
./configure --prefix=/opt/sqlite
make && make install
4安裝SVN
http://subversion.apache.org/download/下載最新版本,老版本在http://archive.apache.org/dist/subversion/
tar -zxvf subversion-1.8.10.tar.gz
cd /opt/subversion-1.8.10
./configure --prefix=/opt/subversion --with-apr=/opt/apr --with-apr-util=/opt/apr-util --with-apxs=/opt/apache/bin/apxs --with-openssl --with-zlib --enable-maintainer-mode --with-sqlite=/opt/sqlite
有可能需要安裝zlib1:
configure: error: subversion requires zlib
去http://zlib.net/下載,http://zlib.net/zlib-1.2.8.tar.gz,上傳到/opt
cd /opt
tar zxvf zlib-1.2.8.tar.gz
cd zlib-1.2.8
./configure
make && make install
5.修改Apache配置,httpd.conf最下面追加,直接在根目錄下建密碼
cd /opt/apache/conf下載httpd.conf
這幾個是必須的模塊,出了問題檢查一下有沒有加載
LoadModule authn_file_module modules/mod_authn_file.so
LoadModule authz_host_module modules/mod_authz_host.so
LoadModule dav_module modules/mod_dav.so
#下面2個需要從該目錄拷貝過來,并且引入,如果不引入無法和svn協同。
cp /opt/subversion/libexec/mod_authz_svn.so /opt/apache/modules
cp /opt/subversion/libexec/mod_dav_svn.so /opt/apache/modules
LoadModule dav_svn_module modules/mod_dav_svn.so
LoadModule authz_svn_module modules/mod_authz_svn.so
這個加到最下面用來和svn協同
<Location /svn>
DAV svn
SVNListParentPath on //很重要
SVNParentPath /opt/svn
AuthType Basic
AuthName "please input username/password"
AuthUserFile /opt/svn/passwd
AuthzSVNAccessFile /opt/svn/authz
Require valid-user
</Location>
6.svn倉庫的創建和權限配置
mkdir -p /opt/svn/
創建apache賬戶,使通過apache訪問url的時候可以瀏覽該目錄
新建一個文件需要-c,以后就不需要加了,passwd文件一定要用命令,明碼是不行的
htpasswd -c /opt/svn/passwd wxq
htpasswd /opt/svn/passwd caowei
另外需要建一個群組權限文件到/opt/svn/authz, @代表群組,這里聲明了一個admin組,admin組有讀寫權限
[groups]
admin=wxq
[/]
@admin=rw
[home:/]
@admin=rw
創建子倉庫
svnadmin create /opt/svn/home
7.啟動/重啟/關閉apache
/opt/apache/bin/apachectl start
/opt/apache/bin/apachectl restart
/opt/apache/bin/apachectl stop
8.檢測SVN 端口
[root@localhost conf]#netstat -ln |grep 3690
tcp 0 0 0.0.0.0:3690 0.0.0.0:* LISTEN
停止重啟SVN
killall svnserve
svnserve -d -r /opt/svn
如果已經有svn在運行,可以換一個端口運行
svnserve -d -r /opt/svn/ --listen-port 3391
查看版本
svnserve --version
查看是否安裝了svn
rpm -q subversion
查看是否安裝了httpd,可以使用httpd --version檢測是否已經卸載
rpm -q httpd
maven是個項目管理工具,集各種功能于一身,下面介紹maven web項目在eclipse種的配置,并于tomcat集成。配置成功后,可以跟一般的web項目一樣調試。
一、準備條件
1、安裝下載jdk
這里以jdk1.6為例
2、安裝eclipse
到eclipse官網下載 Eclipse IDE for Java EE Developers版本的eclipse
http://www.eclipse.org/
3、安裝tomcat6
4、安裝maven
5、安裝eclipse maven插件
這里以在線安裝的方式,安裝地址為:http://m2eclipse.sonatype.org/sites/m2e
二、配置
1、在eclipse中配置jdk安裝位置,tomcat安裝位置,maven安裝位置,為tomcat指定jdk
在此不詳述
2、在eclipse中新建一個maven項目
2-1、新建一個maven項目,選擇create a simple project ...

2-2、
點擊Next,進入下一個

在此窗口下填寫group id,artifact id,可以隨便寫一個,在Packaging中選擇war類型
點擊下一步,在以下步驟中一直next,直到最后點擊finish
2-3、
右擊項目,選擇properites,打開以下對話框

在此界面右邊導航欄選中 Project Facets,點擊超鏈接Convert Faceted from,進入以下界面
2-4、

在Configuration中選擇custom
在下方的Project Facet的Dynamic Web Module中選擇2.5版本
在java中選擇1.6
注意:這些選擇可能根據tomcat版本變化而變化,就tomcat6來說選擇以上選項是可以的
此步驟非常重要,只有操作了此步驟,右側導航欄才會有Deployment Assembly 鏈接
2-5
接下來點擊右邊面板的Runtime面板

可以看到下方中有tomcat,如果沒有,則點擊下面的new,新建一個,新建后選中復選框,然后apply,ok
2-6、
在項目屬性面板中的作部導航欄選擇Deployment Assembly選項,在右邊Web Deployment Assembly
如果看到以下的圖示,那么配置就完成了

這里解釋一下以上文件夾
src/main/java
該文件夾是存放java源碼的,發布項目時會將該文件夾下的class文件復制到WEB-INF/classes目錄下
src/main/resources
該文件夾一般放置配置文件,如xml,properties文件等,其實也可以放置java文件,只是一種約定罷了,發布項目時
該文件夾的文件也會復制到WEB-INF/class中
至于test,有些類似,只不過這些是測試代碼,用過maven的應該會知道這一點
src/main/webapp
maven中約定是把該文件夾當成是普通web項目中的WebRoot目錄,看看右邊的deploy path,發布項目時
是發布到根目錄/了。該文件夾在建成的maven web項目中,在其內尚沒有WEB-INF/classes,WEB-INF/lib文件夾
需要手工建立
注意:有時候由于某種原因,你打開的以上視圖可能是下面這樣的,

其實,這樣也是可以運行項目,調試項目的,但是,如果你運行該項目的pom.xml文件時就會報錯,為什么呢,
因為maven會把src/main/webapp文件當成是普通web項目中的WebRoot,而該你的配置里面(上圖)卻
沒有配置,故而會報錯。
怎么辦呢,分2步
1、選中 WebContent,remove掉它
2、新建一個,Source文件夾為src/main/webapp,deploy path為 /
點擊apply,ok即可。
最后還必須將maven庫映射到WEB-INF/lib下,具體操作如下,點擊add按鈕,進入下圖

選擇java build path entries,點擊next,進入下圖

選擇Maven Dependencies,點擊finish,最終如下圖

如果不把Maven Dependencies映射到WEB-INF/lib,則在服務端如servlet中用到maven中的庫時,則會提示找不到類(雖然你在編寫代碼時沒有紅xx,但是運行程序時卻會找不到類)
三、運行
在eclipse的server視圖中添加你的項目,右鍵選擇的tomcat服務器,選擇add and remove,添加剛才新建的web工程,效果如下圖

在src/main/java中建立一個servlet,在src/main/webapp中建立一個jsp
啟動tomcat,訪問你的servlet和jsp,在servlet中你可以定斷點,可以調試。
http://zk1878.iteye.com/blog/1222330
在linux下怎么安裝.bin的文件。
或者
第一步: sh ./j2sdk-1_4_2-nb-3_5_1-bin-linux.bin
回答YES
第二步: rpm **** |
如何查看是否開啟慢查:可看到慢查的設定時間,最下幾行
SHOW VARIABLES LIKE '%_query_%';
重新生成慢查詢日志文件,不用重啟
mysqladmin -u root -p flush-logs(網上都說這種,其實不行)
正確的做法:
1、分析慢查日志輸出到digest.log
/usr/local/bin/percona-toolkit-2.2.11/bin/pt-query-digest /data/mysql-slow.log >/data/mysql-digest/digest$(date +%Y-%m-%d-%H:%M).log
2、直接刪除mysql-slow.log
rm -fr /data/mysql-slow.log
3、備份并重新生成日志文件:
touch /data/mysql-slow.log
chmod 777 /data/mysql-slow.log
4、重新開啟日志記錄:
SET GLOBAL slow_query_log = ON;
5、等待就行了,經試驗有效
常用工具集:
1、服務器摘要
2、服務器磁盤監測
3、mysql服務狀態摘要
- pt-mysql-summary -- --user=root --password=root
4、慢查詢日志分析統計
- pt-query-digest /data/logs/mysql/mysql-slow.log
5、表同步工具,和mk-tables-sync功能一樣, 用法上 稍有不一樣 ,--print的結果更詳細
- pt-table-sync --execute --print --no-check-slave --database=world h='127.0.0.1' --user=root --password=123456 h='192.168.0.212' --user=root --password=123456
6、主從狀態監測,提供給它一臺mysql服務器的IP用戶名密碼,就可以分析出整個主從架構中每臺服務器的信息,包括但不限于mysql版本,IP地址,server ID,mysql服務的啟動時間,角色(主/從),Slave Status(落后于主服務器多少秒,有沒有錯誤,slave有沒有在運行)。
- [root@RHCE6 ~]# pt-slave-find --host=localhost --user=rhce6 --password=rhce6
- localhost
- Version 5.5.23-log
- Server ID 1
- Uptime 05:16:10 (started 2012-08-08T09:32:03)
- Replication Is not a slave, has 1 slaves connected, is not read_only
- Filters
- Binary logging STATEMENT
- Slave status
- Slave mode STRICT
- Auto-increment increment 1, offset 1
- InnoDB version 1.1.8
- +- 192.168.0.168
- Version 5.5.23-log
- Server ID 10
- Uptime 38:19 (started 2012-08-08T14:09:54)
- Replication Is a slave, has 0 slaves connected, is not read_only
- Filters
- Binary logging STATEMENT
- Slave status 0 seconds behind, running, no errors
- Slave mode STRICT
- Auto-increment increment 1, offset 1
- InnoDB version 1.1.8
7、mysql死鎖監測
- pt-deadlock-logger h='127.0.0.1' --user=root --password=123456
8.主鍵沖突檢查
- pt-duplicate-key-checker --database=world h='127.0.0.1' --user=root --password=123456
9.監測從庫的復制延遲 ###經過測試 運行這個命令會使從庫上的sql線程異常掛掉
- pt-slave-delay --host 192.168.0.206 --user=root --password=123456
更多介紹參考http://www.zhaokunyao.com/archives/3245,命令的使用可以通過--help獲知
percona-toolkit簡介
percona-toolkit是一組高級命令行工具的集合,用來執行各種通過手工執行非常復雜和麻煩的mysql和系統任務,這些任務包括:
l 檢查master和slave數據的一致性
l 有效地對記錄進行歸檔
l 查找重復的索引
l 對服務器信息進行匯總
l 分析來自日志和tcpdump的查詢
l 當系統出問題的時候收集重要的系統信息
percona-toolkit源自Maatkit 和Aspersa工具,這兩個工具是管理mysql的最有名的工具,現在Maatkit工具已經不維護了,請大家還是使用percona-toolkit吧!這些工具主要包括開發、性能、配置、監控、復制、系統、實用六大類,作為一個優秀的DBA,里面有的工具非常有用,如果能掌握并加以靈活應用,將能極大的提高工作效率。
二、percona-toolkit工具包安裝
0.準備工作,先安裝:
yum install -y perl-CPAN perl-Time-HiRes
1. 軟件包下載
訪問http://www.percona.com/downloads/percona-toolkit/下載最新版本的Percona Toolkit 或者通過如下命令行來獲取最新的版本:
wget percona.com/get/percona-toolkit.tar.gz
wget percona.com/get/percona-toolkit.rpm
我這里選擇直接從網站上找到最新版本下載:
cd /usr/local/bin
wget http://www.percona.com/downloads/percona-toolkit/2.2.11/percona-toolkit-2.2.11.tar.gz
2. 軟件包安裝
percona-toolkit的編譯安裝方式
/usr/local/bin
tar xzvf percona-toolkit-2.2.11.tar.gz
cd percona-toolkit-2.2.11
perl Makefile.PL
make
make test
make install
1、INFO: Maximum number of threads (200) created for connector with address null and port 8091
說明:最大線程數錯誤
解決方案:
使用線程池,用較少的線程處理較多的訪問,可以提高tomcat處理請求的能力。使用方式:
首先。打開/conf/server.xml,增加
- <Executor name="tomcatThreadPool" namePrefix="catalina-exec-"
- maxThreads="500" minSpareThreads="20" maxIdleTime="60000" />
最大線程500(一般服務器足以),最小空閑線程數20,線程最大空閑時間60秒。
然后,修改<Connector ...>節點,增加executor屬性,如:
- <Connector executor="tomcatThreadPool"
- port="80" protocol="HTTP/1.1"
- connectionTimeout="60000"
- keepAliveTimeout="15000"
- maxKeepAliveRequests="1"
- redirectPort="443"
- ....../>
2、java.net.SocketException: Too many open files
當tomcat并發用戶量大的時候,單個jvm進程確實可能打開過多的文件句柄。
使用 #lsof -p 10001|wc -l 查看文件操作數
如下操作:
- (1).ps -ef |grep tomcat 查看tomcat的進程ID,記錄ID號,假設進程ID為10001
- (2).lsof -p 10001|wc -l 查看當前進程id為10001的 文件操作數
- (3).使用命令:ulimit -a 查看每個用戶允許打開的最大文件數
- 默認是1024.
- (4).然后執行:ulimit -n 65536 將允許的最大文件數調整為65536
ngxin需要增加如下配置和tomcat的session復制配合使用
proxy_redirect off;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header Host $host;
tomcat集群配置:
<Cluster className="org.apache.catalina.cluster.tcp.SimpleTcpCluster"
managerClassName="org.apache.catalina.cluster.session.DeltaManager"
expireSessionsOnShutdown="false"
useDirtyFlag="true"
notifyListenersOnReplication="true">
<Membership
className="org.apache.catalina.cluster.mcast.McastService"
mcastAddr="228.0.0.4"
mcastPort="45564"
mcastFrequency="500"
mcastDropTime="3000"/>
<Receiver
className="org.apache.catalina.cluster.tcp.ReplicationListener"
tcpListenAddress="192.168.1.199"http://這里配置局域網IP
tcpListenPort="4001"
tcpSelectorTimeout="100"
tcpThreadCount="6"/>
<Sender
className="org.apache.catalina.cluster.tcp.ReplicationTransmitter"
replicationMode="pooled"
ackTimeout="15000"
waitForAck="true"/>
<Valve className="org.apache.catalina.cluster.tcp.ReplicationValve"
filter=".*\.gif;.*\.js;.*\.jpg;.*\.png;.*\.htm;.*\.html;.*\.css;.*\.txt;"/>
<Deployer className="org.apache.catalina.cluster.deploy.FarmWarDeployer"
tempDir="/tmp/war-temp/"
deployDir="/tmp/war-deploy/"
watchDir="/tmp/war-listen/"
watchEnabled="false"/>
<ClusterListener className="org.apache.catalina.cluster.session.ClusterSessionListener"/>
</Cluster>
web.xml最下面加上這句話
<distributable/>
轉自http://hanqunfeng.iteye.com/blog/1920994
1)ip_hash(不推薦使用)
nginx中的ip_hash技術能夠將某個ip的請求定向到同一臺后端,這樣一來這個ip下的某個客戶端和某個后端就能建立起穩固的session,ip_hash是在upstream配置中定義的:
- upstream backend {
- server 127.0.0.1:8080 ;
- server 127.0.0.1:9090 ;
- ip_hash;
- }
不推薦使用的原因如下:
1/ nginx不是最前端的服務器。
ip_hash要求nginx一定是最前端的服務器,否則nginx得不到正確ip,就不能根據ip作hash。譬如使用的是squid為最前端,那么nginx取ip時只能得到squid的服務器ip地址,用這個地址來作分流是肯定錯亂的。
2/ nginx的后端還有其它方式的負載均衡。
假如nginx后端又有其它負載均衡,將請求又通過另外的方式分流了,那么某個客戶端的請求肯定不能定位到同一臺session應用服務器上。
3/ 多個外網出口。
很多公司上網有多個出口,多個ip地址,用戶訪問互聯網時候自動切換ip。而且這種情況不在少數。使用 ip_hash 的話對這種情況的用戶無效,無法將某個用戶綁定在固定的tomcat上 。
2)nginx_upstream_jvm_route(nginx擴展,推薦使用)
nginx_upstream_jvm_route 是一個nginx的擴展模塊,用來實現基于 Cookie 的 Session Sticky 的功能。
簡單來說,它是基于cookie中的JSESSIONID來決定將請求發送給后端的哪個server,nginx_upstream_jvm_route會在用戶第一次請求后端server時,將響應的server標識綁定到cookie中的JSESSIONID中,從而當用戶發起下一次請求時,nginx會根據JSESSIONID來決定由哪個后端server來處理。
1/ nginx_upstream_jvm_route安裝
下載地址(svn):http://nginx-upstream-jvm-route.googlecode.com/svn/trunk/
假設nginx_upstream_jvm_route下載后的路徑為/usr/local/nginx_upstream_jvm_route,
(1)進入nginx源碼路徑
patch -p0 < /usr/local/nginx_upstream_jvm_route/jvm_route.patch
(2)./configure --with-http_stub_status_module --with-http_ssl_module --prefix=/usr/local/nginx --with-pcre=/usr/local/pcre-8.33 --add-module=/usr/local/nginx_upstream_jvm_route
(3)make & make install
關于nginx的下載與安裝參考:http://hanqunfeng.iteye.com/blog/697696
2/ nginx配置
- upstream tomcats_jvm_route
- {
- # ip_hash;
- server 192.168.33.10:8090 srun_id=tomcat01;
- server 192.168.33.11:8090 srun_id=tomcat02;
- jvm_route $cookie_JSESSIONID|sessionid reverse;
- }
3/ tomcat配置
修改192.168.33.10:8090tomcat的server.xml,
- 將
- <Engine name="Catalina" defaultHost="localhost" >
- 修改為:
- <Engine name="Catalina" defaultHost="localhost" jvmRoute="tomcat01">
同理,在192.168.33.11:8090server.xml中增加jvmRoute="tomcat02"。
4/ 測試
啟動tomcat和nginx,訪問nginx代理,使用Google瀏覽器,F12,查看cookie中的JSESSIONID,
形如:ABCD123456OIUH897SDFSDF.tomcat01 ,刷新也不會變化
今天在安裝的時候出現這樣的錯誤。
src/http/modules -I src/mail \
-o objs/addon/nginx-sticky-module-1.1/ngx_http_sticky_misc.o \ ../nginx-sticky-module-1.1/ngx_http_sticky_misc.c
In file included from ../nginx-sticky-module-1.1/ngx_http_sticky_misc.c:11:0: src/core/ngx_sha1.h:19:17: fatal error: sha.h: No such file or directory compilation terminated. make1?: [objs/addon/nginx-sticky-module-1.1/ngx_http_sticky_misc.o] Error 1 make1?: Leaving directory `/etc/nginx/nginx-1.4.1' make: build? Error 2
我的命令是
./configure --prefix=/opt/nginx --with-file-aio --with-http_stub_status_module --add-module=../nginx-sticky-module-1.1
make
提示信息不實很明確,后來安裝了openssl之后再次安裝就解決了問題。
yum -y install openssl-devel
[root@localhost conf]# /usr/local/nginx/sbin/nginx/usr/local/nginx/sbin/nginx: error while loading shared libraries: libpcre.so.1: cannot open shared object file: No such file or directory
從錯誤看出是缺少lib文件導致
可以看出 libpcre.so.1 => not found 并沒有找到,進入/lib目錄中手動鏈接下[root@localhost lib]# ln -s libpcre.so.0.0.1 libpcre.so.1然后在啟動nginx ok 了[root@localhost lib]# /usr/local/nginx/sbin/nginx[root@localhost lib]# ps -ef |grep nginxroot 9539 1 0 19:06 ? 00:00:00 nginx: master process /usr/local/nginx/sbin/nginxwww 9540 9539 0 19:06 ? 00:00:00 nginx: worker process
安裝pcre
PCRE是perl所用到的正則表達式,目的是讓所裝的軟件支持正則表達式。默認情況下,Nginx只處理靜態的網頁請求,也就是html.如果是來自動態的網頁請求,比如*.php,那么Nginx就要根據正則表達式查詢路徑,然后把*.PHP交給PHP去處理
#rpm -qa | grep pcre //查詢系統中有沒有安裝PCRE,一般裝系統是默認裝有,所以我們要刪掉系統自帶的
#cp /lib/libpcre.so.0 / //在刪除系統自帶的PCRE之前,要先備份一下libpcre.so.0這個文件,因為RPM包的關聯性太強,在刪除后沒libpcre.so.0這個文件時我們裝PCRE是裝不上的
#rpm -e --nodeps pcre-6.6-1.1 //刪除系統自帶的PCRE
# tar zxvf pcre-8.00.tar.gz
#cd pcre-8.00
#cp /libpcre.so.0 /lib/ //把我們刪除系統自帶的PCRE之前備份的libpcre.so.0拷貝到/lib 目錄下
#./configure //配置PCRE,因為PCRE是一個庫,而不是像pache、php、postfix等這樣的程序,所以我們安裝時選擇默認路徑即可,這樣會在后面安裝其它東西時避免一些不必要的麻煩,執行完這部后會顯示出下圖,上面顯示了我們對PCRE的配置
#make && make install
摘要: 轉自http://www.ttlsa.com/nginx/nginx-modules-nginx-sticky-module/在多臺后臺服務器的環境下,我們為了確保一個客戶只和一臺服務器通信,我們勢必使用長連接。使用什么方式來實現這種連接呢,常見的有使用nginx自帶的ip_hash來做,我想這絕對不是一個好的辦法,如果前端是CDN,或者說一個局域網的客戶同時訪問服務器,導致出現服務器分配不均衡,...
閱讀全文