3 分配
3.1 鎖堆分配
當所需要的空間大于512字節或者在已有的緩存中無法分配所需的大小,就會發生鎖堆分配,顧名思義,鎖堆分配需要獲取堆上的鎖,所以應該盡量避免。
If size < 512 or enough space in cache
try cacheAlloc
return if OK
HEAP_LOCK
Do
If there is a big enough chunk on freelist
takeit
goto Got it
else
manageAllocFailure
if any error
goto Get out
End Do
Cot it:
Initialise object
Get out:
HEAP_UNLOCK |
圖表 7 鎖堆分配
圖表7即是鎖堆分配的偽代碼,垃圾收集器首先檢測要分配的空間的大小,如果小于512字節或者在當前緩存內有足夠的空間進行分配,則嘗試緩存分配;如果不能進行緩存分配,或者緩存分配失敗,則會發生鎖堆。垃圾收集器開始在空閑鏈表中查詢可用的空間,如果找到滿足條件的空間,則在此空間內進行分配,并且將剩余的空間返回到空閑鏈表中。需要注意的是,如果剩余的空閑空間不足512字節加上頭信息大小(32位架構上12字節,64架構上24字節),那么就不會返回到空閑鏈表中,這些小的存儲空間就被稱為“暗物質”。如果垃圾收集器無法找到滿足條件的空閑空間,就會發生分配失敗,開始進行垃圾收集工作。垃圾收集結束之后,繼續在空閑鏈表中查找滿足需求的空間,如果依然無法找到,就會發生內存溢出的錯誤。無論對象是否分配成功,堆鎖都會被釋放。
3.1.1 小提示
在某些情況下,比如在很大的堆中,空閑鏈表是由大量的空閑存儲空間段組成,或者應用頻繁的申請較大的存儲空間,鎖堆分配策略可能會存在問題。因為每次都需要從空閑鏈表的頭開始查找滿足需求的空閑空間,效率相對較低,所以有了快速空閑鏈表查找算法來解決這個問題。
每次鎖堆分配嘗試查找鏈表時,都會收集以下數據:
· 在找到滿足需求的空間之前已經在空閑鏈表中查找過的存儲段數量
· 在找到滿足需求的空間之前所查找的空閑段中的最大段的大小。也就是不能滿足需求的段的最大大小
當找到滿足需求的空間之后,如果查找計數大于20,表示需要創建一個active hint指向空閑鏈表。然后,根據實際的需求來決定是從空閑鏈表頭開始查找,還是從active hint指向的位置開始查找,一旦在一個段中進行了分配,active hint會被及時更新。
3.2 緩存分配
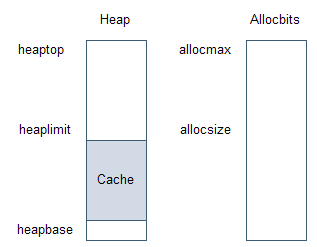
圖表 8 堆中的緩存段
緩存分配是針對小對象設計的高性能分配策略,線程預先從堆中分配一段空間,對象直接在這一段空間內進行分配,無需獲取堆的鎖,所以緩存分配的效率是極高的。如果滿足以下條件,就會進行緩存分配:
· 對象小于512字節,或者
· 線程本地堆中有足夠的空間容納對象
圖表8是堆中緩存段的示意圖。緩存段又叫做線程本地堆(thread local heap,TLH)。當垃圾收集器為一個線程分配線程本地堆時,使用鎖堆分配一段空間給該線程獨享使用。分配集合中對應線程本地堆的比特位不會被設置,直到線程本地堆滿了,或者一輪垃圾收集工作開始的時候,才會被設置。為了提高分配線程本地堆的性能,垃圾收集器總是使用在空閑鏈表中找到的第一個空閑段,并且不大于40KB。
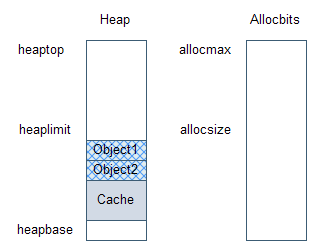
圖表 9 在緩存段中分配的對象
圖表9顯示的是在緩存段中分配的一些對象。在緩存段中,對象總是從段頂開始分配,這樣能夠比從段底分配更加高效。圖表9中還顯示了在分配集合中,并沒有設置緩存段的標識位。直到緩存段滿了,或者一輪垃圾收集工作開始的時候,這些標識位才會被設置。
4 垃圾收集
在鎖堆分配中如果發生了分配失敗,或者有對System.gc()的顯式調用,則會發生垃圾收集。調用System.gc()的線程或者發生分配失敗的線程負責進行垃圾收集。首先,他獲取垃圾收集所需的鎖,然后掛起其他線程,再開始垃圾收集的三個階段的工作:標識、清理以及壓縮階段(非必須的)。IBM JDK的垃圾收集是stop-the-world類型的,因為在垃圾收集過程中,所有的應用線程都被掛起。
在標識階段,所有的活動對象都被標識。因為不可到達對象不太容易定位,所以要明確所有的可到達對象,那么余下的就是垃圾了。這個標識所有可達到對象的過程也被稱作追蹤(tracing)。
被保存的寄存器、線程的執行棧、類中的靜態域、本地或者全局的JNI引用,共同構成了虛擬機的活動狀態。虛擬機自身調用的函數都會生成一個C執行棧上的一個幀。這個幀可能包含一些對象實例,可能是要賦值給本地變量的對象,也可能是來自調用者的調用參數。在追蹤階段,所有這些引用都是被同等對待的。垃圾收集器自頂到底掃描每個線程的棧,4字節為一組(在64位架構上是8字節一組),垃圾收集器假設棧是4字節對齊的(在64位架構上是8字節對齊的),然后檢查棧上每個4字節組是否是指向堆上的一個對象,有可能所指向的不是一個真正的對象,因為可能只是碰巧和一個整數或者浮點數的存儲表示相同。垃圾收集器掃描線程棧,然后保守的處理他所找到的這些指針,只要這個指針指向一個對象地址,那么就假設他真的是一個對象引用,并且在垃圾收集的時候,不能移動這個對象。如果滿足以下3個條件,這個槽位就被認為是指向一個對象的指針:
1. 8字節對齊的
2. 位于堆的地址范圍內
3. 對應的分配比特位已經設置為1
以這種方式被引用的對象就是根對象,根對象的dosed標識位被設置,表示這個對象不能被移動,只有在壓縮階段時,垃圾收集器才會設置dosed標識位。從根對象開始,可以精確的追蹤其他被引用對象,因為垃圾收集器知道這些引用確實是真正指向對象的引用,由于可以修改引用,所以這些被引用的對象在壓縮階段可以被移動。追蹤階段使用一個可以容納4KB條目的棧,所有的引用都被壓棧,同時,設置對應的標識比特位。首先,全部根對象被壓棧,然后再依次出棧,在出棧的過程中繼續追蹤。普通對象(非數組對象)通過mptr訪問類信息塊來追蹤被其引用的其他對象。一旦找到引用,并且被引用對象尚未被標識,那么該對象就被標識并且壓棧。
對于數組對象,垃圾收集器檢查每個條目,如果該對象尚未被標識,則對其進行標識并且壓棧。為了避免標識棧溢出,每次只處理數組的一部分內容。
垃圾收集器重復以上過程,直到標識棧為空。
4.1.1 標識棧溢出
因為標識棧的大小是有限制的,所有有可能發生標識棧溢出的問題。雖然這種問題發生的幾率非常小,但是當發生標識棧溢出時,對于垃圾收集的暫停時間有非常大的影響。
4.1.1.1 溢出集合
垃圾收集器需要一個能夠映射整個堆的比特位數組來記錄堆中未被追蹤的對象,就是FR_bits數組,該數組是為進行增量壓縮(Incremental Compaction, IC)設置的,對于每個可能的引用槽位(在32位架構上是4字節,在64位架構上是8字節),有一個對應的比特位。由于JVMObject頭信息不會包含任何引用信息,所以每個對象對應的FR_bits數組中的前2個比特位是不被IC使用的,因此垃圾收集器使用FR_bits數組中的第1個冗余比特位實現溢出集合。
4.1.1.2 處理非系統堆對象的標識棧溢出
當線程嘗試將一個引用壓棧到標識棧時,如果此時發現標識棧已經滿了,他會向自己的本地標識隊列發布一個任務。如果發布動作失敗了,線程會設置這個引用對象對應的FR_bits數組,以表示發生了標識棧溢出。
然后追蹤工作繼續處理已經設置了FR_bits數組的、無法被壓棧的引用。
一旦線程處理完了標識棧,他就會嘗試接管溢出集合,并且,為了確保溢出集合只被一個線程處理,該線程設置一個是否發生標識棧溢出的全局標識為False。一旦確立了溢出集合的所屬權,這個線程就開始掃描FR_bits數組,查找所有的非零比特位。一旦找到非零的比特位,則將其清零,并且對應的引用被壓棧。到一定量的引用被壓棧之后,他們被發布到本地標識隊列,以便于其他線程輔助處理溢出集合。
在處理溢出集合的同時,有可能發生標識棧溢出。如果發生這種情況,那么一個全局標識會被設置以標識發生了溢出,上面描述的處理過程會重復執行。
4.1.1.3 系統堆溢出機制
在收集根對象時,垃圾收集器會將所有系統堆和ACS堆中的對象引用也壓棧,因此同樣會發生標識棧溢出的問題。但是FR_bits數組只映射了非系統堆,所以無法用來記錄系統堆和ACS堆中未被追蹤的對象。
在垃圾收集的標識階段,已經加載的類的地址是不會被修改的,因此,垃圾收集器需要記錄在發生標識棧溢出前的那一刻,他所到達的追蹤鏈條的位置。所以,引入兩個全局變量“overflowSystemClasses”和“overflowACSClasses”來表示對應在系統堆和ACS堆中的進行位置。當處理溢出集合時,這兩個變量告訴垃圾收集器應該在什么位置停止。
4.1.1.4 處理系統堆對象的標識棧溢出
在并行標識(parallelMark)階段,如果線程已經處理完了標識棧,接下來需要檢查overflowSystemClasses和overflowACSClasses兩個變量是否被設置。如果其中某個變量被設置,那么這個線程就會試圖獲取對應對象列表的控制權,并且將這個變量設置為NULL。一旦線程獲取了控制權,就會將引用壓棧到標識棧,一定量的引用被壓棧之后,向本地標識隊列發布任務,以允許其他線程輔助進行后續工作。
如果在處理的過程中,再次發生了標識棧溢出,線程會記錄在發生溢出之前處理到的位置,然后重復上面的工作。
4.1.2 并行標識
由于優化的按位清理算法和壓縮避免機制的存在,使得一個垃圾收集周期的主要時間消耗在對象標識階段。所以,開發了并行標識技術,該技術使得在單CPU的主機上不降低標識的性能,并且能夠在8路主機上將性能提高4倍左右。
在標識階段的時間主要消耗在一些輔助線程以及協調這些輔助線程共同工作上。一個線程作為主要線程,也就是我們所說的垃圾收集主線程。這個線程負責掃描C堆棧,找到活動的根對象。在一個具有N個CPU的主機上,會創建N-1個輔助線程來輔助完成后續的標識階段工作。輔助線程的數量可以由虛擬機啟動參數
-Xgcthreadsn來重新設定。設置為1表示沒有輔助線程,該參數取值范圍為1到N。
更高層面講,每個標識線程擁有自己的本地棧以及共享的隊列,這兩個變量都包含了那些已經被標識但是尚未被掃描的對象的引用。輔助線程大部分的標識工作都是依賴本地的棧變量來完成的,只有在需要負載均衡的時候才會在共享隊列上進行同步的操作。由于對于標識比特位的操作是原子操作,所以無需獲取鎖。
由于每個線程的棧都可以容納4KB個條目,標識隊列可以容納2KB個條目,所以大大降低了標識棧溢出的發生幾率。
4.1.3 并發標識
并發標識機制保證在堆內存增大的時候,能夠降低垃圾收集的暫停時間。在堆滿之前,開始進行并發標識:垃圾收集器通知每個線程掃描自己的執行棧以查找根對象,然后基于這些根對象開始進行并發的追蹤,追蹤是在進行鎖堆分配的時候,由一個較低優先級的后臺線程以及全部的應用線程一起完成。
由于垃圾收集器在應用運行的同時標識活動對象,所以必須記錄已經追蹤的對象的任何變化。為了達到這個目的,他采用了一種寫隔離(write barrier)的技術,在對象發生變化時被激活。首先將堆分隔成512字節的段,每個段對應卡片表(card table)中的一個字節。當指向一個對象的引用發生變化時,對應這個對象所在段的卡片表中的字節被設置為0x01。使用字節而不是比特位有兩個原因:字節的寫入速度比比特位更快,另外,字節中其他的比特位還可以用作其他用途。
如果發生以下情況,就會開始STW(Stop The World)收集:
· 分配失敗
· System.gc()
· 并發標識階段完成
垃圾收集器開始進行并發標識階段的工作,以試圖在堆耗盡之前完成垃圾收集工作。虛擬機啟動參數可以管理并發標識的時間。
在STW階段,垃圾收集器掃描所有的根對象,并且通過標識卡片來查看需要進一步追蹤的對象,然后按照普通的模式進行清理。這樣能夠保證在并發標識階段開始時的不可到達對象都可以被清理,但是無法保證在并發標識階段進行過程中變成不可到達的對象也被清理。
并發標識策略可以減少垃圾收集的暫停時間,但是會帶來額外消耗,因為應用線程需要在獲取堆鎖的時候進行一些跟蹤工作。具體的性能降低取決于有多少空閑的CPU時間可以給后臺線程使用。另外,寫隔離機制也會有額外的消耗。
開啟并發標識的參數為:
-Xgcpolicy:<optthruput|optavgpause>
設置-Xgcpolicy參數為optthruput禁用并發標識。optthruput是默認設置。如果你的應用中不存在暫停時間帶來的問題,可以使用這個默認選項獲得最好的吞吐能力。
設置-Xgcpolicy參數為optavgpause啟用并發標識。如果應用因為垃圾收集的暫停時間導致響應能力下降,可以使用這個參數來改善情況,但是會降低應用吞吐量。
標識階段結束之后,標識集合中對于堆中每個可到達對象都進行了標識,而且是分配集合的子集。清理階段就是計算分配集合和標識集合的差集,也就是說,找到那些已經被分配但是已經不被引用的對象。
最初,使用按位清理(bitsweep)技術,這種技術檢查標識集合中較長的連續0序列,可能對應的就是空閑空間。一旦找到連續0序列,垃圾收集器檢查這個序列開始位置對應的對象的大小,來計算可以釋放多少空間。如果這個大小大于512字節加上對象頭大小,那么這一段空間就會重新加入到空閑鏈表中去。
未返回到空閑鏈表中的小的空閑空間,就被稱作是“暗物質”,當緊鄰“暗物質”空間的對象被釋放之后,或者壓縮動作執行之后,他就可能再次返回到空閑鏈表中去。垃圾收集器不需要清理空閑段中的每個對象,因為這一段都是可以被清理的對象。在這個過程中,標識集合會整個復制到分配集合中去,這樣分配集合就表示了堆中所有的已分配對象。
4.2.1 并發按位清理技術
并發按位清理技術能夠盡量使用可用的處理器以提高清理階段的執行效率。在并發清理階段,垃圾收集器使用和并發標識階段同樣的輔助線程,所以,默認的參與并發處理的線程數也可以由虛擬機參數-Xgcghreadsn來設置。堆被分割成多個段,段的數量要遠遠大于并發清理線程的數量,計算公式如下:
· 32 * 輔助線程數量 或者
· 堆的最大大小/16MB
中選擇較大的一個。每次一個輔助線程選擇一個段來掃描,然后按位清理,并且保存每個段的清理結果,完成之后,再重新建立空閑鏈表。
在清理階段結束之后,垃圾收集器可以對堆中剩余的活動對象進行壓縮,以移除他們之間的空閑空間。這個壓縮過程是非常復雜的,因為一旦移動了一個對象,那么所有指向這個對象的引用都需要修改。如果是來自棧的引用,那么垃圾收集器還不能確定這就是一個對象引用(有可能碰巧只是一個浮點數),就不能移動這個對象。這樣的對象還會繼續保持在原來的位置,并且dosed標識位會被設置。類似的,JNI操作中引用的對象也是要固化在原來的位置不能被移動的,直到JNI操作結束,不再引用這個對象的時候,才可能被移動。利用mptr的低三位設置為0,垃圾收集器可以在兩個階段內壓縮那些可以移動的對象。其中一位用來標識對象被清理,這個清理標識位出現在兩個地方:size+flags(即OLINK_IsSwapped)以及mptr(即GC_FirstSwapped),這兩種情況中,最低的位(x01)都會被設置。
下圖可以幫助你理解壓縮過程:

圖表 10 壓縮階段工作
圖表10展示了壓縮的效果。假設從A到B是一個走廊,走廊里面有一些家具(藍色的塊),代表對象。空白的區域代表空閑空間或者“暗物質”,有兩個家具被固定在地板上(交叉紋理塊),代表固化的或者不能被移動的對象。壓縮的過程就類似你要把家具從B推到A,盡可能的靠近A端。但是,不幸的是,你不能把家具舉起來越過固定在地板上的家具,所以,他們右側的家具最遠也就推到緊鄰他們的位置。
4.3.1 避免壓縮
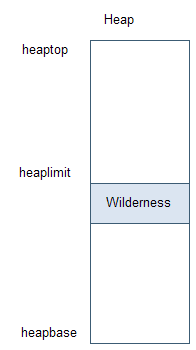
圖表 11 荒地
避免壓縮主要是致力于為對象找到合適的放置位置,以減少或者避免移動對象。避免緊技術中最主要的一個概念叫做荒地預留。荒地預留技術試圖在堆中預留一段空間,然后盡量在其他地方進行對象分配。在堆頂和荒地部分之間,定義一個邊界。如果存在大對象的分配,或者上一次垃圾收集之后尚未滿足分配需求的情況下,就會使用荒地空間。
圖表11是堆中荒地的示意圖。荒地在活動的堆空間的最后進行分配,初始大小是活動堆空間的5%,根據實際需求進行收縮或者擴展。在鎖堆分配失敗的情況下,如果對象大小小于64KB或者上一次垃圾收集的結果取得足夠的進展,那么就再開始一輪垃圾收集工作。足夠的進展的意思是,自從上一次垃圾收集以來,至少有30%的堆空間被占用。30%是默認值,可以通過-Xminf參數設置。如果沒有取得足夠進展,或者對象大于等于64KB,那么會嘗試在荒地中進行分配。這樣就能夠避免垃圾收集和堆壓縮動作。
如果未設置虛擬機參數-Xnocompactgc并且以下幾個條件任何一個為true,那么就會發生堆壓縮動作:
· 設置了虛擬機參數-Xcompactgc
· 清理階段結束之后,還是無法滿足分配需求
· 調用System.gc()并且在最后一次分配失敗發生或者并發標識收集之前發生了壓縮動作
· TLH消耗了至少一半的存儲,并且TLH的平均大小低于1000字節
· 堆的空閑空間小于5%
· 堆的空閑空間小于128KB
4.3.2 增量壓縮
4.3.2.1 介紹
垃圾收集釋放了對象空間之后,在堆中就會產生碎片。那么會引發一種現象,堆中還有足夠的空閑空間,但是由于他們是不連續的,所以無法進行后續的分配。
壓縮動作就是用來整理堆中的碎片,他將堆中分散的已分配的存儲段移動到堆的一端,那么在堆的另一端就會生成一個較大的連續的空閑空間。但是壓縮會增加垃圾收集的暫停時間,對于1GB的堆,如果進行了壓縮動作,垃圾收集的暫停時間可能增加到40秒。對于應用而言,這么長的暫停時間通常是不可接受的。增量壓縮技術就是將壓縮動作分散到多次垃圾收集周期中,以減少暫停時間。
增量壓縮的另一個重要作用是清理暗物質。暗物質就是堆中的很小的(小于512字節)存儲片,這些存儲片不在空閑鏈表中,因此不能被重新利用。暗物質的存在程度直接影響了應用的吞吐能力,因為越多的暗物質就會導致堆中可用的存儲空間越少,可用存儲越少,垃圾收集發生的頻率就會越高,對于應用的性能會產生非常明顯的影響。這些暗物質分散在整個堆中,會占用堆的大部分空間。
4.3.2.2 增量壓縮概覽
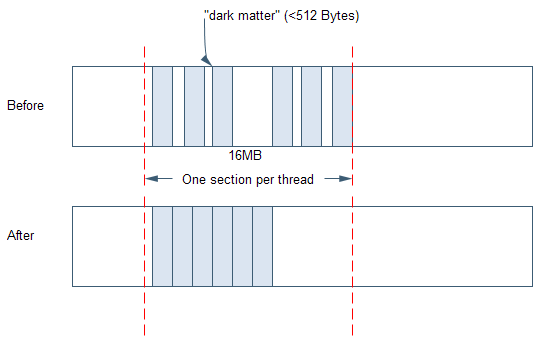
圖表 12 增量壓縮
在圖表12中,涂色的塊表示已經分配的空間,未涂色的塊表示空閑空間。暗物質會分布在空閑空間之間。下半部分表示在增量壓縮之后,對象被移動到段的一側,另一側就整理出了較大的連續空閑空間。
只有在堆大小大于某個值(當前是128MB)時,才會發生增量壓縮。如果堆小于128MB,增量壓縮并不會帶來比完整壓縮更短的暫停時間。
增量壓縮有如下兩步:
1) 記錄和標識指向壓縮區域的所有引用,這個動作在標識階段完成
2) 計算對象的新位置,在區域內進行壓縮,并修改指向被移動對象的引用
增量壓縮在一個周期內進行,一個增量壓縮周期就是指在垃圾收集周期內,一次一個區域的完成整個堆的壓縮動作。壓縮動作會跨越多個垃圾收集周期,因此將壓縮動作的耗時分散到多個垃圾收集周期,減少暫停隨時間。
4.3.2.3 增量壓縮相關的主要參數
默認是啟用增量壓縮的,是否運行增量壓縮取決于一些觸發條件。但是有兩個參數可以由用戶決定是使用增量壓縮還是傳統壓縮:
· -Xpartialcompactgc,表示每次垃圾收集都使用增量壓縮,除非必須進行完整的壓縮動作
· -Xnopartialcompactgc,表示禁用增量壓縮機制
但是,需要提醒的是,-X參數屬于非標準的虛擬機參數,可能在未通知的情況下進行修改。
引用對象能夠使得所有的對象引用都以同樣的方式被操作和處理,因此垃圾收集器在堆上創建兩個獨立的對象:一個是對象本身,一個是引用對象。當對象處于不可到達狀態時,該引用對象可以方便的加入到一個隊列中去。SoftReference,WeakReference以及PhantomReference由用戶創建,不能修改,即,他們只能指向創建時的那個對象,不能指向其他對象。帶有finalizer方法的對象在創建時注冊Finalizer類,因此FinalReference對象指向一個需要finalize的對象,并且關聯到Finalizer隊列。
在垃圾收集階段,引用對象被特殊處理:在標識階段,不會處理引用對象的引用字段,標識階段結束之后,按照如下順序處理引用字段:
1) Soft
2) Weak
3) Final
4) Phantom
對于SoftReference對象的處理稍有特殊,如果他所指向的對象未被標識,ST組件會清理這個SoftReference。如果存儲不足,那么垃圾收集器根據最近最常用的規則來進行清理。使用率根據最后一次被調用get方法來測量。一旦一個引用對象被處理,他所指向的真實對象會被標識,這樣能夠確保如果一個FinalReference也指向同一個對象,他能夠看到這個標識。FinalReferece不會被放到處理隊列中去。因此,在垃圾收集周期可以成功處理引用對象。
指向未標識對象的引用對象最初被放到ReferenceHandler線程的隊列中,ReferenceHandler線程把對象從他的隊列中移除,同時查看這個對象自己的隊列是否存在,如果存在,則這個對象被重新放入ReferenceHandler線程的隊列中去,以進行后續的處理。因此,FinalReference會重新入隊,確保最后finalize方法被finalizer線程執行。
4.4.1 JNI Weak引用
JNI Weak引用對象提供類似WeakReference對象的功能,但是處理機制是不同的。一段JNI代碼可以創建或者刪除JNI Weak引用對象,這個對象指向一個真正的對象。當引用對象指向的對象未被標識,垃圾收集器會清理這個引用對象,但是不同于前一章提到的隊列機制。需要注意的是,如果清理JNI Weak引用對象失敗,可能會引發內存泄漏以及性能方面的問題。對于全局的JNI引用,也是同樣的處理方式。JNI Weak引用對象最后會被引用對象處理線程處理,因此,對于一個已經被finalize的對象,如果存在指向他的phantom引用,他的JNI Weak引用對象也會持續存在。
堆擴展發生在垃圾收集完畢并且所有線程重新啟動之后,但是HEAP_LOCK尚被持有的情況下。如果滿足以下條件之一,堆的活動空間會進行擴展,直到堆的最大限制:
· 垃圾收集無法釋放足夠的空間來滿足分配需求
· 空閑空間低于最小空閑空閑設定,-Xminf參數,默認30%
· 垃圾收集占用了超過13%的時間,并且按照最小擴展量(-Xmine)擴展之后,還是無法滿足堆內最大空閑空間(-Xmaxf)要求的。
每次擴展的量計算規則如下:
· 如果由于無法滿足堆的空閑空間為-Xminf(30%),垃圾收集器計算能夠滿足-Xminf堆空閑的擴展量。如果這個計算結果大于最大擴展量-Xmaxe(默認為0,即沒有最大擴展量限制),那么會采用-Xmaxe設定的數量。如果計算結果小于-Xmine(默認為1MB),那么會按照-Xmine設定進行擴展
· 如果由于垃圾收集之后仍然不能滿足分配需求,并且垃圾收集的時間占用總運行時間的比例不超過13%,則按照實際的分配需求來擴展
· 如果由于其他原因觸發擴展,則垃圾收集器計算能夠滿足17.5%堆空閑的擴展量。類似上面,根據-Xmaxe和-Xmine的設定進行調整
· 最終,如果垃圾收集未能釋放出滿足分配需求的空間,則堆的擴展要保證至少滿足分配需求
所有計算出的擴展量,在32位架構上是64KB的整倍,在64位架構上是4MB的整倍。
堆收縮發生在垃圾收集完畢并且所有線程都處于掛起狀態時。如果滿足以下任何一個條件,就不會發生堆收縮:
· 垃圾收集未能釋放滿足分配需求的空閑空間
· -Xmaxf參數設定為100%(默認是60%)
· 在最近的3次垃圾收集之中發生過堆擴展
· 由于調用System.gc()發生的垃圾收集,并且在收集周期開始之前,堆的空閑空間小于-Xminf(30%)
如果以上條件都不滿足,并且存在大于-Xmaxf的空閑空間,垃圾收集器會計算收縮量,以保證能夠擁有-Xmaxf的空閑空間,并且不小于初始大小(-Xms)。計算出的收縮量在32位架構上是64KB的整倍,在64位架構上是4MB的整倍。
如果滿足以下任何一個條件,會在收縮之前發生壓縮:
· 在本次垃圾收集周期未進行壓縮
· 堆尾沒有空閑存儲片,或者堆尾的空閑存儲片小于需要收縮量的10%
· 在上一次垃圾收集周期中未發生壓縮和收縮
從1.3.0以后,引入了Resettable JVM,該虛擬機只能運行在z/OS平臺。在http://www.s390.ibm.com/Java有詳細的文檔
posted on 2008-04-22 11:29
YODA 閱讀(2191)
評論(0) 編輯 收藏