|
|
2008年1月14日
不同的平臺,內存模型是不一樣的,但是jvm的內存模型規范是統一的。其實java的多線程并發問題最終都會反映在java的內存模型上,所謂線程安全無 非是要控制多個線程對某個資源的有序訪問或修改。總結java的內存模型,要解決兩個主要的問題:可見性和有序性。我們都知道計算機有高速緩存的存在,處 理器并不是每次處理數據都是取內存的。JVM定義了自己的內存模型,屏蔽了底層平臺內存管理細節,對于java開發人員,要清楚在jvm內存模型的基礎 上,如果解決多線程的可見性和有序性。
那么,何謂可見性? 多個線程之間是不能互相傳遞數據通信的,它們之間的溝通只能通過共享變量來進行。Java內存模型(JMM)規定了jvm有主內存,主內存是多個線程共享 的。當new一個對象的時候,也是被分配在主內存中,每個線程都有自己的工作內存,工作內存存儲了主存的某些對象的副本,當然線程的工作內存大小是有限制 的。當線程操作某個對象時,執行順序如下:
(1) 從主存復制變量到當前工作內存 (read and load)
(2) 執行代碼,改變共享變量值 (use and assign)
(3) 用工作內存數據刷新主存相關內容 (store and write) JVM規范定義了線程對主存的操作指 令:read,load,use,assign,store,write。當一個共享變量在多個線程的工作內存中都有副本時,如果一個線程修改了這個共享 變量,那么其他線程應該能夠看到這個被修改后的值,這就是多線程的可見性問題。
那么,什么是有序性呢 ?線程在引用變量時不能直接從主內存中引用,如果線程工作內存中沒有該變量,則會從主內存中拷貝一個副本到工作內存中,這個過程為read-load,完 成后線程會引用該副本。當同一線程再度引用該字段時,有可能重新從主存中獲取變量副本(read-load-use),也有可能直接引用原來的副本 (use),也就是說 read,load,use順序可以由JVM實現系統決定。
線程不能直接為主存中中字段賦值,它會將值指定給工作內存中的變量副本(assign),完成后這個變量副本會同步到主存儲區(store- write),至于何時同步過去,根據JVM實現系統決定.有該字段,則會從主內存中將該字段賦值到工作內存中,這個過程為read-load,完成后線 程會引用該變量副本,當同一線程多次重復對字段賦值時,比如:
Java代碼
for(int i=0;i<10;i++)
a++;
線程有可能只對工作內存中的副本進行賦值,只到最后一次賦值后才同步到主存儲區,所以assign,store,weite順序可以由JVM實現系統決 定。假設有一個共享變量x,線程a執行x=x+1。從上面的描述中可以知道x=x+1并不是一個原子操作,它的執行過程如下:
1 從主存中讀取變量x副本到工作內存
2 給x加1
3 將x加1后的值寫回主 存
如果另外一個線程b執行x=x-1,執行過程如下:
1 從主存中讀取變量x副本到工作內存
2 給x減1
3 將x減1后的值寫回主存
那么顯然,最終的x的值是不可靠的。假設x現在為10,線程a加1,線程b減1,從表面上看,似乎最終x還是為10,但是多線程情況下會有這種情況發生:
1:線程a從主存讀取x副本到工作內存,工作內存中x值為10
2:線程b從主存讀取x副本到工作內存,工作內存中x值為10
3:線程a將工作內存中x加1,工作內存中x值為11
4:線程a將x提交主存中,主存中x為11
5:線程b將工作內存中x值減1,工作內存中x值為9
6:線程b將x提交到中主存中,主存中x為 jvm的內存模型之eden區所謂線程的“工作內存”到底是個什么東西?有的人認為是線程的棧,其實這種理解是不正確的。看看JLS(java語言規范)對線程工作 內存的描述,線程的working memory只是cpu的寄存器和高速緩存的抽象描述。 可能 很多人都覺得莫名其妙,說JVM的內存模型,怎么會扯到cpu上去呢?在此,我認為很有必要闡述下,免 得很多人看得不明不白的。先拋開java虛擬機不談,我們都知道,現在的計算機,cpu在計算的時候,并不總是從內存讀取數據,它的數據讀取順序優先級 是:寄存器-高速緩存-內存。線程耗費的是CPU,線程計算的時候,原始的數據來自內存,在計算過程中,有些數據可能被頻繁讀取,這些數據被存儲在寄存器 和高速緩存中,當線程計算完后,這些緩存的數據在適當的時候應該寫回內存。當個多個線程同時讀寫某個內存數據時,就會產生多線程并發問題,涉及到三個特 性:原子性,有序性,可見性。在《線程安全總結》這篇文章中,為了理解方便,我把原子性和有序性統一叫做“多線程執行有序性”。支持多線程的平臺都會面臨 這種問題,運行在多線程平臺上支持多線程的語言應該提供解決該問題的方案。 synchronized, volatile,鎖機制(如同步塊,就緒隊 列,阻塞隊列)等等。這些方案只是語法層面的,但我們要從本質上去理解它,不能僅僅知道一個 synchronized 可以保證同步就完了。 在這里我說的是jvm的內存模型,是動態的,面向多線程并發的,沿襲JSL的“working memory”的說法,只是不想牽扯到太多底層細節,因為 《線程安全總結》這篇文章意在說明怎樣從語法層面去理解java的線程同步,知道各個關鍵字的使用場 景。 說說JVM的eden區吧。JVM的內存,被劃分了很多的區域: 1.程序計數器
每一個Java線程都有一個程序計數器來用于保存程序執行到當前方法的哪一個指令。
2.線程棧
線程的每個方法被執行的時候,都會同時創建一個幀(Frame)用于存儲本地變量表、操作棧、動態鏈接、方法出入口等信息。每一個方法的調用至完成,就意味著一個幀在VM棧中的入棧至出棧的過程。如果線程請求的棧深度大于虛擬機所允許的深度,將拋出StackOverflowError異常;如果VM棧可以動態擴展(VM Spec中允許固定長度的VM棧),當擴展時無法申請到足夠內存則拋出OutOfMemoryError異常。
3.本地方法棧
4.堆
每個線程的棧都是該線程私有的,堆則是所有線程共享的。當我們new一個對象時,該對象就被分配到了堆中。但是堆,并不是一個簡單的概念,堆區又劃分了很多區域,為什么堆劃分成這么多區域,這是為了JVM的內存垃圾收集,似乎越扯越遠了,扯到垃圾收集了,現在的jvm的gc都是按代收集,堆區大致被分為三大塊:新生代,舊生代,持久代(虛擬的);新生代又分為eden區,s0區,s1區。新建一個對象時,基本小的對象,生命周期短的對象都會放在新生代的eden區中,eden區滿時,有一個小范圍的gc(minor gc),整個新生代滿時,會有一個大范圍的gc(major gc),將新生代里的部分對象轉到舊生代里。
5.方法區
其實就是永久代(Permanent Generation),方法區中存放了每個Class的結構信息,包括常量池、字段描述、方法描述等等。VM Space描述中對這個區域的限制非常寬松,除了和Java堆一樣不需要連續的內存,也可以選擇固定大小或者可擴展外,甚至可以選擇不實現垃圾收集。相對來說,垃圾收集行為在這個區域是相對比較少發生的,但并不是某些描述那樣永久代不會發生GC(至 少對當前主流的商業JVM實現來說是如此),這里的GC主要是對常量池的回收和對類的卸載,雖然回收的“成績”一般也比較差強人意,尤其是類卸載,條件相當苛刻。
6.常量池
Class文件中除了有類的版本、字段、方法、接口等描述等信息外,還有一項信息是常量表(constant_pool table),用于存放編譯期已可知的常量,這部分內容將在類加載后進入方法區(永久代)存放。但是Java語言并不要求常量一定只有編譯期預置入Class的常量表的內容才能進入方法區常量池,運行期間也可將新內容放入常量池(最典型的String.intern()方法)。
ArrayList 關于 Java中的transient,volatile和strictfp關鍵字 http://www.iteye.com/topic/52957 (1), ArrayList底層使用Object數據實現, private transient Object[] elementData;且在使用不帶參數的方式實例化時,生成數組默認的長度是10。 (2), add方法實現 public boolean add(E e) {
//ensureCapacityInternal判斷添加新元素是否需要重新擴大數組的長度,需要則擴否則不 ensureCapacityInternal(size + 1); // 此為JDK7調用的方法 JDK5里面使用的ensureCapacity方法 elementData[size++] = e; //把對象插入數組,同時把數組存儲的數據長度size加1 return true; } JDK 7中 ensureCapacityInternal實現 private void ensureCapacityInternal(int minCapacity) { modCount++;修改次數 // overflow-conscious code if (minCapacity - elementData.length > 0) grow(minCapacity);//如果需要擴大數組長度 } /** * The maximum size of array to allocate. --申請新數組最大長度 * Some VMs reserve some header words in an array. * Attempts to allocate larger arrays may result in * OutOfMemoryError: Requested array size exceeds VM limit --如果申請的數組占用的內心大于JVM的限制拋出異常 */ private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;//為什么減去8看注釋第2行 /** * Increases the capacity to ensure that it can hold at least the * number of elements specified by the minimum capacity argument. * * @param minCapacity the desired minimum capacity */ private void grow(int minCapacity) { // overflow-conscious code int oldCapacity = elementData.length; int newCapacity = oldCapacity + (oldCapacity >> 1); //新申請的長度為old的3/2倍同時使用位移運算更高效,JDK5中: (oldCapacity *3)/2+1 if (newCapacity - minCapacity < 0) newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0) //你懂的 newCapacity = hugeCapacity(minCapacity); // minCapacity is usually close to size, so this is a win: elementData = Arrays.copyOf(elementData, newCapacity); } //可以申請的最大長度 private static int hugeCapacity(int minCapacity) { if (minCapacity < 0) // overflow throw new OutOfMemoryError(); return (minCapacity > MAX_ARRAY_SIZE) ? Integer.MAX_VALUE : MAX_ARRAY_SIZE; }
Quicksort
Quicksort is a fast sorting algorithm, which is used not only for educational purposes, but widely applied in practice. On the average, it has O(n log n) complexity, making quicksort suitable for sorting big data volumes. The idea of the algorithm is quite simple and once you realize it, you can write quicksort as fast as bubble sort.
Algorithm
The divide-and-conquer strategy is used in quicksort. Below the recursion step is described:
- Choose a pivot value. We take the value of the middle element as pivot value, but it can be any value, which is in range of sorted values, even if it doesn't present in the array.
- Partition. Rearrange elements in such a way, that all elements which are lesser than the pivot go to the left part of the array and all elements greater than the pivot, go to the right part of the array. Values equal to the pivot can stay in any part of the array. Notice, that array may be divided in non-equal parts.
- Sort both parts. Apply quicksort algorithm recursively to the left and the right parts.
Partition algorithm in detail
There are two indices i and j and at the very beginning of the partition algorithm i points to the first element in the array andj points to the last one. Then algorithm moves i forward, until an element with value greater or equal to the pivot is found. Index j is moved backward, until an element with value lesser or equal to the pivot is found. If i ≤ j then they are swapped and i steps to the next position (i + 1), j steps to the previous one (j - 1). Algorithm stops, when i becomes greater than j.
After partition, all values before i-th element are less or equal than the pivot and all values after j-th element are greater or equal to the pivot.
Example. Sort {1, 12, 5, 26, 7, 14, 3, 7, 2} using quicksort.
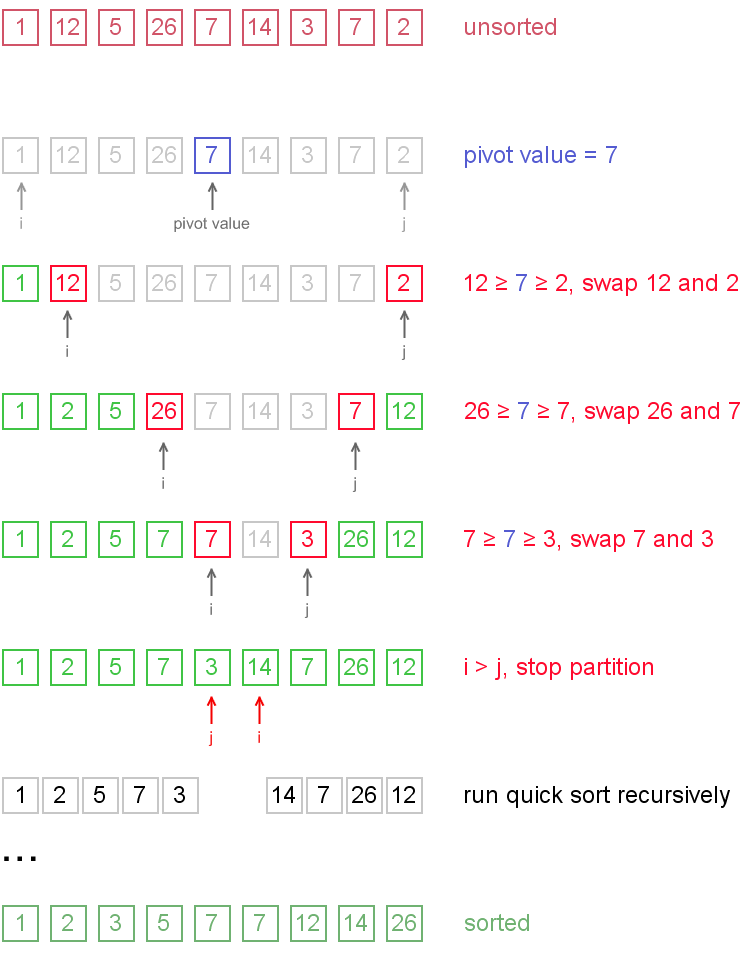
Notice, that we show here only the first recursion step, in order not to make example too long. But, in fact, {1, 2, 5, 7, 3} and {14, 7, 26, 12} are sorted then recursively.
Why does it work?
On the partition step algorithm divides the array into two parts and every element a from the left part is less or equal than every element b from the right part. Also a and b satisfy a ≤ pivot ≤ b inequality. After completion of the recursion calls both of the parts become sorted and, taking into account arguments stated above, the whole array is sorted.
Complexity analysis
On the average quicksort has O(n log n) complexity, but strong proof of this fact is not trivial and not presented here. Still, you can find the proof in [1]. In worst case, quicksort runs O(n2) time, but on the most "practical" data it works just fine and outperforms other O(n log n) sorting algorithms.
Code snippets
Java
int partition(int arr[], int left, int right)
{
int i = left;
int j = right;
int temp;
int pivot = arr[(left+right)>>1];
while(i<=j){
while(arr[i]>=pivot){
i++;
}
while(arr[j]<=pivot){
j--;
}
if(i<=j){
temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
i++;
j--;
}
}
return i
}
void quickSort(int arr[], int left, int right) {
int index = partition(arr, left, right);
if(left<index-1){
quickSort(arr,left,index-1);
}
if(index<right){
quickSort(arr,index,right);
}
}
python
def quickSort(L,left,right) {
i = left
j = right
if right-left <=1:
return L
pivot = L[(left + right) >>1];
/* partition */
while (i <= j) {
while (L[i] < pivot)
i++;
while (L[j] > pivot)
j--;
if (i <= j) {
L[i],L[j] = L[j],L[i]
i++;
j--;
}
};
/* recursion */
if (left < j)
quickSort(L, left, j);
if (i < right)
quickSort(L, i, right);
}
|
Insertion Sort
Insertion sort belongs to the O(n2) sorting algorithms. Unlike many sorting algorithms with quadratic complexity, it is actually applied in practice for sorting small arrays of data. For instance, it is used to improve quicksort routine. Some sources notice, that people use same algorithm ordering items, for example, hand of cards.
Algorithm
Insertion sort algorithm somewhat resembles selection sort. Array is imaginary divided into two parts - sorted one andunsorted one. At the beginning, sorted part contains first element of the array and unsorted one contains the rest. At every step, algorithm takes first element in the unsorted part and inserts it to the right place of the sorted one. Whenunsorted part becomes empty, algorithm stops. Sketchy, insertion sort algorithm step looks like this:
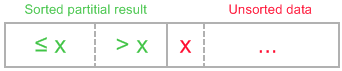
becomes

The idea of the sketch was originaly posted here.
Let us see an example of insertion sort routine to make the idea of algorithm clearer.
Example. Sort {7, -5, 2, 16, 4} using insertion sort.

The ideas of insertion
The main operation of the algorithm is insertion. The task is to insert a value into the sorted part of the array. Let us see the variants of how we can do it.
"Sifting down" using swaps
The simplest way to insert next element into the sorted part is to sift it down, until it occupies correct position. Initially the element stays right after the sorted part. At each step algorithm compares the element with one before it and, if they stay in reversed order, swap them. Let us see an illustration.
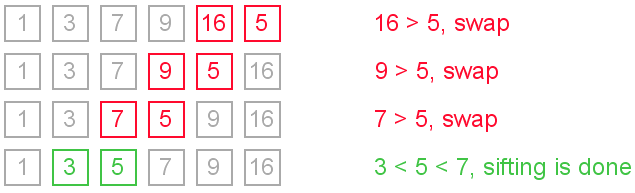
This approach writes sifted element to temporary position many times. Next implementation eliminates those unnecessary writes.
Shifting instead of swapping
We can modify previous algorithm, so it will write sifted element only to the final correct position. Let us see an illustration.
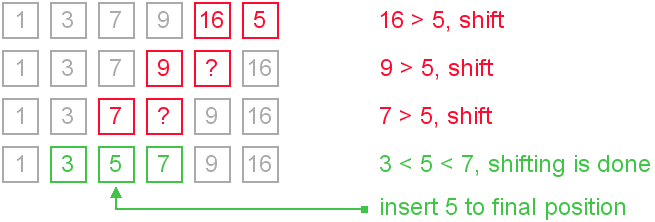
It is the most commonly used modification of the insertion sort.
Using binary search
It is reasonable to use binary search algorithm to find a proper place for insertion. This variant of the insertion sort is calledbinary insertion sort. After position for insertion is found, algorithm shifts the part of the array and inserts the element. This version has lower number of comparisons, but overall average complexity remains O(n2). From a practical point of view this improvement is not very important, because insertion sort is used on quite small data sets.
Complexity analysis
Insertion sort's overall complexity is O(n2) on average, regardless of the method of insertion. On the almost sorted arrays insertion sort shows better performance, up to O(n) in case of applying insertion sort to a sorted array. Number of writes is O(n2) on average, but number of comparisons may vary depending on the insertion algorithm. It is O(n2) when shifting or swapping methods are used and O(n log n) for binary insertion sort.
From the point of view of practical application, an average complexity of the insertion sort is not so important. As it was mentioned above, insertion sort is applied to quite small data sets (from 8 to 12 elements). Therefore, first of all, a "practical performance" should be considered. In practice insertion sort outperforms most of the quadratic sorting algorithms, like selection sort or bubble sort.
Insertion sort properties
- adaptive (performance adapts to the initial order of elements);
- stable (insertion sort retains relative order of the same elements);
- in-place (requires constant amount of additional space);
- online (new elements can be added during the sort).
Code snippets
We show the idea of insertion with shifts in Java implementation and the idea of insertion using python code snippet.
Java implementation
void insertionSort(int[] arr) {
int i,j,newValue;
for(i=1;i<arr.length;i++){
newValue = arr[i];
j=i;
while(j>0&&arr[j-1]>newValue){
arr[j] = arr[j-1];
j--;
}
arr[j] = newValue;
}
Python implementation
void insertionSort(L) {
for i in range(l,len(L)):
j = i
newValue = L[i]
while j > 0 and L[j - 1] >L[j]:
L[j] = L[j - 1]
j = j-1
}
L[j] = newValue
}
}
|
Binary search algorithm
Generally, to find a value in unsorted array, we should look through elements of an array one by one, until searched value is found. In case of searched value is absent from array, we go through all elements. In average, complexity of such an algorithm is proportional to the length of the array.
Situation changes significantly, when array is sorted. If we know it, random access capability can be utilized very efficientlyto find searched value quick. Cost of searching algorithm reduces to binary logarithm of the array length. For reference, log2(1 000 000) ≈ 20. It means, that in worst case, algorithm makes 20 steps to find a value in sorted array of a million elements or to say, that it doesn't present it the array.
Algorithm
Algorithm is quite simple. It can be done either recursively or iteratively:
- get the middle element;
- if the middle element equals to the searched value, the algorithm stops;
- otherwise, two cases are possible:
- searched value is less, than the middle element. In this case, go to the step 1 for the part of the array, before middle element.
- searched value is greater, than the middle element. In this case, go to the step 1 for the part of the array, after middle element.
Now we should define, when iterations should stop. First case is when searched element is found. Second one is when subarray has no elements. In this case, we can conclude, that searched value doesn't present in the array.
Examples
Example 1. Find 6 in {-1, 5, 6, 18, 19, 25, 46, 78, 102, 114}.
Step 1 (middle element is 19 > 6): -1 5 6 18 19 25 46 78 102 114
Step 2 (middle element is 5 < 6): -1 5 6 18 19 25 46 78 102 114
Step 3 (middle element is 6 == 6): -1 5 6 18 19 25 46 78 102 114
Example 2. Find 103 in {-1, 5, 6, 18, 19, 25, 46, 78, 102, 114}.
Step 1 (middle element is 19 < 103): -1 5 6 18 19 25 46 78 102 114
Step 2 (middle element is 78 < 103): -1 5 6 18 19 25 46 78 102 114
Step 3 (middle element is 102 < 103): -1 5 6 18 19 25 46 78 102 114
Step 4 (middle element is 114 > 103): -1 5 6 18 19 25 46 78 102 114
Step 5 (searched value is absent): -1 5 6 18 19 25 46 78 102 114
Complexity analysis
Huge advantage of this algorithm is that it's complexity depends on the array size logarithmically in worst case. In practice it means, that algorithm will do at most log2(n) iterations, which is a very small number even for big arrays. It can be proved very easily. Indeed, on every step the size of the searched part is reduced by half. Algorithm stops, when there are no elements to search in. Therefore, solving following inequality in whole numbers:
n / 2iterations > 0
resulting in
iterations <= log2(n).
It means, that binary search algorithm time complexity is O(log2(n)).
Code snippets.
You can see recursive solution for Java and iterative for python below.
Java
int binarySearch(int[] array, int value, int left, int right) {
if (left > right)
return -1;
int middle = left + (right-left) / 2;
if (array[middle] == value)
return middle;
if (array[middle] > value)
return binarySearch(array, value, left, middle - 1);
else
return binarySearch(array, value, middle + 1, right);
}
Python
def biSearch(L,e,first,last):
if last - first < 2: return L[first] == e or L[last] == e
mid = first + (last-first)/2
if L[mid] ==e: return True
if L[mid]> e :
return biSearch(L,e,first,mid-1)
return biSearch(L,e,mid+1,last)
|
Merge sort is an O(n log n) comparison-based sorting algorithm. Most implementations produce a stable sort, meaning that the implementation preserves the input order of equal elements in the sorted output. It is a divide and conquer algorithm. Merge sort was invented by John von Neumann in 1945. A detailed description and analysis of bottom-up mergesort appeared in a report byGoldstine and Neumann as early as 1948
divide and conquer algorithm: 1, split the problem into several subproblem of the same type. 2,solove independetly. 3 combine those solutions
Python Implement
def mergeSort(L):
if len(L) < 2 :
return L
middle = len(L)/2
left = mergeSort(L[:mddle])
right = mergeSort(L[middle:])
together = merge(left,right)
return together
Algorithm to merge sorted arrays
In the article we present an algorithm for merging two sorted arrays. One can learn how to operate with several arrays and master read/write indices. Also, the algorithm has certain applications in practice, for instance in merge sort.
Merge algorithm
Assume, that both arrays are sorted in ascending order and we want resulting array to maintain the same order. Algorithm to merge two arrays A[0..m-1] and B[0..n-1] into an array C[0..m+n-1] is as following:
- Introduce read-indices i, j to traverse arrays A and B, accordingly. Introduce write-index k to store position of the first free cell in the resulting array. By default i = j = k = 0.
- At each step: if both indices are in range (i < m and j < n), choose minimum of (A[i], B[j]) and write it toC[k]. Otherwise go to step 4.
- Increase k and index of the array, algorithm located minimal value at, by one. Repeat step 2.
- Copy the rest values from the array, which index is still in range, to the resulting array.
Enhancements
Algorithm could be enhanced in many ways. For instance, it is reasonable to check, if A[m - 1] < B[0] orB[n - 1] < A[0]. In any of those cases, there is no need to do more comparisons. Algorithm could just copy source arrays in the resulting one in the right order. More complicated enhancements may include searching for interleaving parts and run merge algorithm for them only. It could save up much time, when sizes of merged arrays differ in scores of times.
Complexity analysis
Merge algorithm's time complexity is O(n + m). Additionally, it requires O(n + m) additional space to store resulting array.
Code snippets
Java implementation
// size of C array must be equal or greater than
// sum of A and B arrays' sizes
public void merge(int[] A, int[] B, int[] C) {
int i,j,k ;
i = 0;
j=0;
k=0;
m = A.length;
n = B.length;
while(i < m && j < n){
if(A[i]<= B[j]){
C[k] = A[i];
i++;
}else{
C[k] = B[j];
j++;
}
k++;
while(i<m){
C[k] = A[i]
i++;
k++;
}
while(j<n){
C[k] = B[j]
j++;
k++;
}
Python implementation
def merege(left,right):
result = []
i,j = 0
while i< len(left) and j < len(right):
if left[i]<= right[j]:
result.append(left[i])
i = i + 1
else:
result.append(right[j])
j = j + 1
while i< len(left):
result.append(left[i])
i = i + 1
while j< len(right):
result.append(right[j])
j = j + 1
return result
MergSort:
import operator
def mergeSort(L, compare = operator.lt):
if len(L) < 2:
return L[:]
else:
middle = int(len(L)/2)
left = mergeSort(L[:middle], compare)
right= mergeSort(L[middle:], compare)
return merge(left, right, compare)
def merge(left, right, compare):
result = []
i, j = 0, 0
while i < len(left) and j < len(right):
if compare(left[i], right[j]):
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
while i < len(left):
result.append(left[i])
i += 1
while j < len(right):
result.append(right[j])
j += 1
return result
|
Selection Sort
Selection sort is one of the O(n2) sorting algorithms, which makes it quite inefficient for sorting large data volumes. Selection sort is notable for its programming simplicity and it can over perform other sorts in certain situations (see complexity analysis for more details).
Algorithm
The idea of algorithm is quite simple. Array is imaginary divided into two parts - sorted one and unsorted one. At the beginning, sorted part is empty, while unsorted one contains whole array. At every step, algorithm finds minimal element in the unsorted part and adds it to the end of the sorted one. When unsorted part becomes empty, algorithmstops.
When algorithm sorts an array, it swaps first element of unsorted part with minimal element and then it is included to the sorted part. This implementation of selection sort in not stable. In case of linked list is sorted, and, instead of swaps, minimal element is linked to the unsorted part, selection sort is stable.
Let us see an example of sorting an array to make the idea of selection sort clearer.
Example. Sort {5, 1, 12, -5, 16, 2, 12, 14} using selection sort.
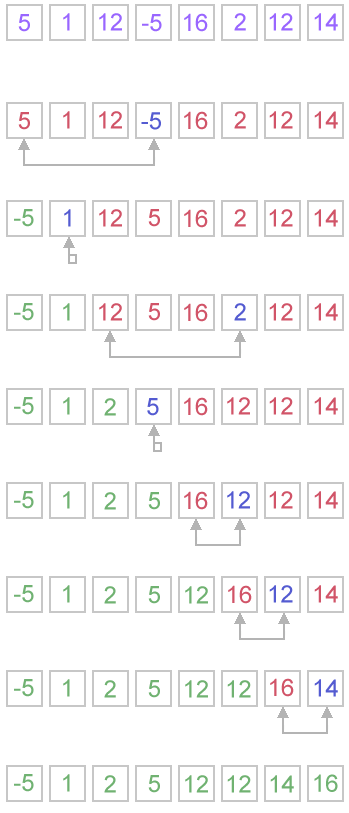
Complexity analysis
Selection sort stops, when unsorted part becomes empty. As we know, on every step number of unsorted elements decreased by one. Therefore, selection sort makes n steps (n is number of elements in array) of outer loop, before stop. Every step of outer loop requires finding minimum in unsorted part. Summing up, n + (n - 1) + (n - 2) + ... + 1, results in O(n2) number of comparisons. Number of swaps may vary from zero (in case of sorted array) to n - 1 (in case array was sorted in reversed order), which results in O(n) number of swaps. Overall algorithm complexity is O(n2).
Fact, that selection sort requires n - 1 number of swaps at most, makes it very efficient in situations, when write operation is significantly more expensive, than read operation.
Code snippets
Java
public void selectionSort(int[] arr) {
int i, j, minIndex, tmp;
int n = arr.length;
for (i = 0; i < n - 1; i++) {
minIndex = i;
for (j = i + 1; j < n; j++)
if (arr[j] < arr[minIndex])
minIndex = j;
if (minIndex != i) {
tmp = arr[i];
arr[i] = arr[minIndex];
arr[minIndex] = tmp;
}
}
}
Python
for i in range(len(L)-1): minIndex = i minValue = L[i] j = i + 1 while j< len(L): if minValue > L[j]: minIndex = j minValue = L[j] j += 1 if minIndex != i: temp = L[i] L[i] = L[minIndex] L[minIndex] = temp
|
Bubble Sort
Bubble sort is a simple and well-known sorting algorithm. It is used in practice once in a blue moon and its main application is to make an introduction to the sorting algorithms. Bubble sort belongs to O(n2) sorting algorithms, which makes it quite inefficient for sorting large data volumes. Bubble sort is stable and adaptive.
Algorithm
- Compare each pair of adjacent elements from the beginning of an array and, if they are in reversed order, swap them.
- If at least one swap has been done, repeat step 1.
You can imagine that on every step big bubbles float to the surface and stay there. At the step, when no bubble moves, sorting stops. Let us see an example of sorting an array to make the idea of bubble sort clearer.
Example. Sort {5, 1, 12, -5, 16} using bubble sort.
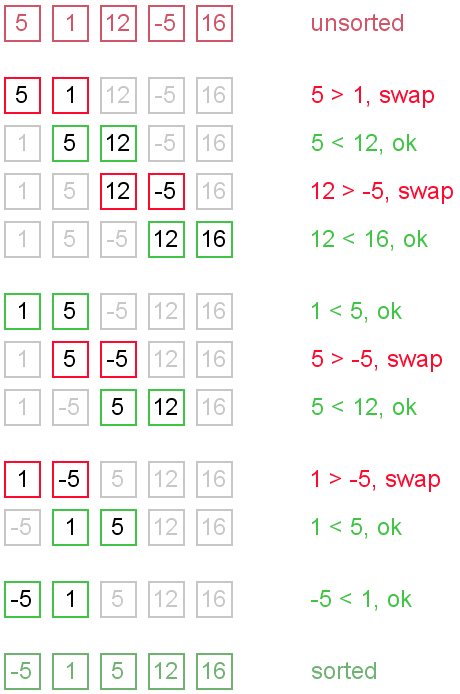
Complexity analysis
Average and worst case complexity of bubble sort is O(n2). Also, it makes O(n2) swaps in the worst case. Bubble sort is adaptive. It means that for almost sorted array it gives O(n) estimation. Avoid implementations, which don't check if the array is already sorted on every step (any swaps made). This check is necessary, in order to preserve adaptive property.
Turtles and rabbits
One more problem of bubble sort is that its running time badly depends on the initial order of the elements. Big elements (rabbits) go up fast, while small ones (turtles) go down very slow. This problem is solved in the Cocktail sort.
Turtle example. Thought, array {2, 3, 4, 5, 1} is almost sorted, it takes O(n2) iterations to sort an array. Element {1} is a turtle.

Rabbit example. Array {6, 1, 2, 3, 4, 5} is almost sorted too, but it takes O(n) iterations to sort it. Element {6} is a rabbit. This example demonstrates adaptive property of the bubble sort.

Code snippets
There are several ways to implement the bubble sort. Notice, that "swaps" check is absolutely necessary, in order to preserve adaptive property.
Java
public void bubbleSort(int[] arr) {
boolean swapped = true;
int j = 0;
int tmp;
while (swapped) {
swapped = false;
j++;
for (int i = 0; i < arr.length - j; i++) {
if (arr[i] > arr[i + 1]) {
tmp = arr[i];
arr[i] = arr[i + 1];
arr[i + 1] = tmp;
swapped = true;
}
}
}
}
Python
def bubbleSort(L) :
swapped = True;
while swapped:
swapped = False
for i in range(len(L)-1):
if L[i]>L[i+1]:
temp = L[i]
L[i] = L[i+1]
L[i+1] = temp
swapped = True
|
摘要: 關于二分查找的原理互聯網上相關的文章很多,我就不重復了,但網絡的文章大部分講述的二分查找都是其中的核心部分,是不完備的和效率其實還可以提高,如取中間索引使用開始索引加上末尾索引的和除以2,這種做法在數字的長度超過整型的范圍的時候就會拋出異常,下面是我的代碼,其中可能有些地方沒考慮到或有什么不足 閱讀全文
JNDI : Java Naming and Directory Interface (JNDI)
JNDI works in concert with other technologies in the Java Platform, Enterprise Edition (Java EE) to organize and locate components in a distributed computing environment.
翻譯:JNDI 在Java平臺企業級開發的分布式計算環境以組織和查找組件方式與其他技術協同工作。
Tomcat 6.0 的數據源配置
給大家我的配置方式:
1,在Tomcat中配置:
tomcat 安裝目錄下的conf的context.xml 的
<Context></Context>中
添加代碼如下:
<Resource name="jdbc/tango"
auth="Container"
type="javax.sql.DataSource"
maxActive="20"
maxIdel="10"
maxWait="1000"
username="root"
password="root"
driverClassName="com.mysql.jdbc.Driver" url="jdbc:mysql://localhost:3306/tango"
>
</Resource>
其中:
name 表示指定的jndi名稱
auth 表示認證方式,一般為Container
type 表示數據源床型,使用標準的javax.sql.DataSource
maxActive 表示連接池當中最大的數據庫連接
maxIdle 表示最大的空閑連接數
maxWait 當池的數據庫連接已經被占用的時候,最大等待時間
username 表示數據庫用戶名
password 表示數據庫用戶的密碼
driverClassName 表示JDBC DRIVER
url 表示數據庫URL地址
同時你需要把你使用的數據驅動jar包放到Tomcat的lib目錄下。
如果你使用其他數據源如DBCP數據源,需要在<Resouce 標簽多添加一個屬性如
factory="org.apache.commons.dbcp.BasicDataSourceFactory"
當然你也要把DBCP相關jar包放在tomcat的lib目錄下。
這樣的好處是,以后的項目需要這些jar包,可以共享適合于項目實施階段。
如果是個人開發階段一個tomcat下部署多個項目,在啟動時消耗時間,同時
可能不同項目用到不用數據源帶來麻煩。所以有配置方法2
2在項目的中配置:
2.1 使用自己的DBCP數據源
在WebRoot下面建文件夾META-INF,里面建一個文件context.xml,
添加內容和 配置1一樣
同時加上<Resouce 標簽多添加一個屬性如
factory="org.apache.commons.dbcp.BasicDataSourceFactory"
這樣做的:可以把配置需要jar包直接放在WEB-INF的lib里面 和web容器(Tomcat)無關
總后一點:提醒大家,有個同學可能說 tomacat的有DBCP的jar包,確實tomcat把它放了
進去,你就認為不用添加DBCP數據源的jar包,也按照上面的配置,100%你要出錯。
因為tomcat重新打包了相應的jar,你應該把
factory="org.apache.tomcat.dbcp.dbcp.BasicDataSourceFactory" 改為
factory="org.apache.commons.dbcp.BasicDataSourceFactory"
同時加上DBCP 所依賴的jar包(commons-dbcp.jar和commons-pool.jar)
你可以到www.apache.org 項目的commons里面找到相關的內容
2.2 使用Tomcat 自帶的DBCP數據源
在WebRoot下面建文件夾META-INF,里面建一個文件context.xml,
添加相應的內容
這是可以不需要添加配置
配置1一樣
factory="org.apache.tomcat.dbcp.dbcp.BasicDataSourceFactory"
也不要想添加額外的jar包
最后,不管使用哪種配置,都需要把數據庫驅動jar包放在目錄tomcat /lib里面
JNDI使用示例代碼:
 Context initContext; Context initContext;
  try try  { {
 Context context=new InitialContext(); Context context=new InitialContext();
DataSource ds=(DataSource) context.lookup("java:/comp/env/jdbc/tango");
// "java:/comp/env/"是固定寫法,后面接的是 context.xml中的Resource中name屬性的值
Connection conn = ds.getConnection();
Statement stmt = conn.createStatement();
ResultSet set = stmt.executeQuery("SELECT id,name,age FROM user_lzy");
  while(set.next()){ while(set.next()){
System.out.println(set.getString("name"));
 } }
//etc.
} catch (NamingException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
 } }
謝謝!
Java處理Excel數據有很多方式,如Apache的POI或JXL等.
我首先給出一個Excele數據的讀入的方式(使用的是jxl.jar包)
 package com.ccniit.readexcel; package com.ccniit.readexcel;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import jxl.Sheet;
import jxl.Workbook;
import jxl.read.biff.BiffException;
  public class ExcelHander { public class ExcelHander {
  public static String[] getColName(String desc) { public static String[] getColName(String desc) {
InputStream is = null;
String[] colNames = null;
try {
is = new FileInputStream(new File(desc));
Workbook wb = Workbook.getWorkbook(is);
Sheet sheet = wb.getSheet(0);
int cols = sheet.getColumns();
colNames = new String[cols];
for (int i = 0; i < cols; i++) {
colNames[i] = sheet.getCell(i, 0).getContents();
// System.out.println("列名: " + colNames[i]);
 } }
is.close();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (BiffException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return colNames;
}
public List<Map<String, Object>> readExcel(String desc) {
List<Map<String, Object>> datas = null;
try {
InputStream is = new FileInputStream(new File(desc));
Workbook wb = Workbook.getWorkbook(is);
if(wb == null){
return null;
}
Sheet sheet = wb.getSheet(0);
int cols = sheet.getColumns();
int rows = sheet.getRows();
datas = new ArrayList<Map<String, Object>>();
for (int i = 1; i < rows; i++) {
Map<String, Object> data = new HashMap<String, Object>();
for (int j = 0; j < cols; j++) {
String key = sheet.getCell(j, 0).getContents();
// System.out.println("key:" + key);
Object value = (Object) sheet.getCell(j, i).getContents();
// System.out.println("value:" + value.toString());
data.put(key, value);
}
datas.add(data);
}
is.close();
wb.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (BiffException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return datas;
}
 } }
再見了我的 2008
謹以此文獻給我們的2008年--
但愿你的點點滴滴永存于我們心間....
再見我的2008--楊天寧
還有一點點的時間
讓我們用來回憶
還有一點點的時間
可以用來哭泣
可以不管得到還是失去
輕輕合上眼睛
緊緊抱著它啊
時間這樣飛逝
我們就這樣長大
我們哭著笑著唱著
在勇敢地成長
想想身邊每個朋友
你們是否不再孤單害怕
聽時間開始倒記
這樣隨音樂大聲唱起
再見我的2008年
好懷念你在我的身邊
當昨天它一點點走遠
我知道我們不能回到從前
再見我的2008年
我記得你的每一個瞬間
無論明天悲喜或是改變
只希望我們都能快樂一點
鐘聲它已走遠...
2008,這一年發生了太多太多的事,或許有些事你已經淡忘,但也有些事會長存于你的心間,難以磨滅.
在2008年即將離我們而去之際,讓我們回首一下自己這一年所經歷過的點點滴滴.在這一年里,我們哭過,笑過,痛苦過,掙扎過,努力過,認真過,也跌到過,爬起過,遺憾過...無論你在這一年里是達到了自己的目標,實現了夢想,還是犯下了不可彌補的錯誤,讓自己身邊的人受到傷害,這一切都將過去,因為 2008年在你生命中只有一次而已,而它正逐漸離我們而去...
年初的南方大雪災(家人因為地滑,摔傷)
手足口病肆虐
藏獨事件
網絡開始流行全民"中國心"頭像
全球華人開展愛國行動 堅決反對西藏獨立
奧運火炬傳遞活動遭藏獨份子阻礙
512汶川大地震 無數人在此災難中痛失親人朋友(學校損失被迫異地復課)
08年8月8日20點 北京奧運會開幕
劉翔因腿傷退出比賽 成為全民討論熱點
毒奶粉事件 使中國奶制品業受重創
起于美國的金融風暴 席卷全球
2008,是屬于中國人的奧運年.從4年前得知我們要舉辦奧運的那一刻起,到后來奧運圣火輾轉傳遞,然后到奧運會順利開幕,選手們展開精彩角逐,最后到奧運圓滿閉幕,這些都在我們心中留下一個個永生難忘的精彩瞬間 那一個個運動健兒揮灑汗水,頑強拼搏的身影也銘刻于我們心底...
2008,也是中國多災多難的一年.一個突如其來的大地震,讓無數的人痛失自己摯愛的親人,朋友,也失去了自己心愛的家園...跌倒了,不要緊,最后我們還是爬起來了.當得知這一噩耗時,我們全國同胞都紛紛伸出自己的援助之手,捐資捐物,幫災民重建家園.這也讓我們看到了中華的希望,我們傳統的互助精神并沒有被遺忘.一個災難的磨練,令世人更加清楚地認識到了這個民族的力量所在.
......
對于我而言,2008也是具有里程碑式意義的一年.因為這一年我告別了自己的大學生涯,開始人生新旅程.不曉得我這個句號劃得完不完美,但是我自己無悔就夠了,畢竟我努力過了,就讓所大學以前的記憶,所有記憶都停在這一年吧,也停留在我的內心深處...
時間推著我們向前 我們是無法停留在原地的 只有把昨天的記憶埋于心底作養料 用現有的來播種 然后期待明天能開出絢爛的花朵...
再見了,2008;再見了,我的大學生活,雖說是再見卻永遠不會再見,但愿我在往后十年里能有所成就,也希望09年以后,世界能繼續朝著繁榮安定的方向邁進,能順利找到工作.....
個人在項目開發中總結的。供大家參考
1.頁面顯示中文時出現的亂碼,通常使用
1 <%@ page contentType="text/html;charset=gb2312"%>
可以達到處理亂碼的效果
2.從請求中獲得數據是出現的中文亂碼處理方法有
(1) get請求有兩種處理方法
方法1:
在tomcat的配置文件(conf)中的server.xml的
1 <Connector port="8080" protocol="HTTP/1.1"
2 connectionTimeout="20000"
3 redirectPort="8443"
4 URIEncoding="gb2312"/>
加入上面第4行代碼即可。
方法2:也就是通常說的再編碼的說法,
1<%
2 String name=request.getParameter("name");
3 byte []b = name.getBytes("GB2312");
4 name=new String(b);
5%>
6也可簡化為:
7<%=new String(request.getParameter().getBytes("GB2312"))
8%>
(2)post請求
在jsp頁面中加入也下代碼
1<%request.setCharacterEncoding("gb2312");%>
需要注意的是這部分代碼要放寫在獲得請求內容以前。
3.以上就是JSP頁面中出現亂碼的方法,最后我想說的就是如何確定發送的
請求是GET 還是POST。
(1)一般表單(Form)提交中有method方法確定。
(2)通過URL鏈接傳遞為GET方法提交
(3)通過地址重寫的為GET方法提交
謝謝閱讀
我是軟件專業現在是大二的學生,我們已經學了1年的Java 知識,現在還沒有開Java Web 我想多
提前和多學點知識,可我有點迷惑。開始應該還先學JSP方面的知識,學JSP 必須要學習HTML方面的知道,
如涉及到CSS,JS.如果想把網站設計更美觀的還需要學習PS。當一切都好的時候,可能考慮學習框架,可現
在Java框架特多,我應該怎么選擇,那些好啊。最后學習J2EE方面東西。我在互聯網上看到,有點人說學習
J2EE可無EJB,這是真的嗎??還有最后問題學了這樣一切,現在流行AJAX。又要學習這個知識。我想了我
應該從哪里開始啊。如果都學一個人精力不能有那么多啊,可要是不學那開發做出來東西在外觀或其他方面
沒有別人好吧。希望那些高手們,幫我出個主意。。謝謝啦。。。
|