文章來自《程序員》
英文原文可以在這里找到http://dev.csdn.net/develop/article/12/12657.shtm
關鍵字:WWW 搜索引擎 網絡爬蟲 PageRank Google
作為一種功能強大的搜索引擎,Googic的背后似乎隱藏著巨大的奧秘,本文是Googic的兩位創始人在1998年國際互聯網大會上發表的論文,通過對Google進行完整地剖析,幫助讀者理解Google的實現過程.
1。為什么要用Google
Web結構的特殊性為信息收集工作帶來了新的挑戰。Web上的信息數量迅速增長的同時,對于Web毫無使用經驗的新用戶也在與日俱增。使用高質量的搜索引擎,無疑可以縮短Web同新用戶之間的距離。大家關心的問題是,搜索質量和效率。
Yahoo曾一度是用戶的最佳選擇。Yahoo的人工維護方式可以有效涵蓋最流行的主題。然而,維護人員的主觀性、高昂的維護代價、較慢的更新速度都是Yahoo的缺陷。更重要的事,這種方式并不能覆蓋所有用戶所關心的話題。所有這些制約了Yahoo的進一步發展。基于關鍵字的搜索引擎隨之出現,但新的問題接踵而來:搜索引擎制造出的大量“垃圾”結果遮住了用戶的視線,也考驗了更多人的耐心。一些廣告商為了吸引用戶的目光,采用一些手段欺騙搜索引擎,這使事情變得更糟。
Google為上述問題提供了新的解決方案。首先,Google是基于關鍵字的,這樣突破了查詢主題的限制;其次,Google利用網頁超級連接的深度和獨創的PageRank算法,為網頁賦予了“級別(Rank)”含義:用戶的檢索結果,是按照網頁的級別(Rank)進行排序的.級別高的網頁鏈接排在前面.
Google這個名字的來歷也很有意思:Google的創建者參考了單詞googol(10100)的拼寫,也許這和作者要建立大規模的搜索引擎的目標不謀而合.
2.設計目標
正如你想到的,GOOGLE的主要目標是提高搜索引擎的搜索質量和易用性.1997年11月的一項調查中,排名前四位的商業化搜索引擎,在執行以它自身的名字作為關鍵字的查詢時,僅有一個搜索引擎在其搜索結果的前10條查詢結果中找到自己.問題已經變得很明顯:用戶關心的不是搜索引擎所能提供的查詢結果,而是在搜索引擎中所能提供的前數十條查詢結果中,能否找到自己的滿意答案.正因為如此,當Web文檔成倍增長時,如何提供一個既易于操作,又能提供準確查詢的新的搜索引擎技術.這成為了關注的焦點.
近幾年的一些相關研究為Google打開了思路.這些研究的主要方向是:如何從頁面的超鏈接文本中獲取對開發人員有用的信息.正是通過對HTML文檔中超文本鏈接的深度分析,Google為自己的精確度算法提供了理論依據.
Google希望通過自己的努力,把原本只屬于商業領域的搜索引擎技術帶到理論研究的范疇,并能讓更多的人參與和完善.Google把自己的系統比喻為一個大的實驗室環境,并歡迎其他領域的研究人員參與其中.正是在千千萬萬如Google這樣的組織的帶動下,Web獲取了它前所未有的發展動力.
3.技術分析
Google之所以能獲取高效率的查詢結果,得益于其兩相重要的技術特性:第一,Google分析整個Web的鏈接結構,然后計算出每一個網頁的級別,并進行綜合評分,這就是Google所采用的PageRank技術;第二,Google充分利用鏈接提供的信息以進一步改善查詢質量.
3.1 PageRank:頁面的排序技術
Google的核心技術稱為PageRank,這是Google的創始人Larry Page和Sergey Brin在斯坦福大學開發出的一套用于網頁評級的系統.作為組織管理工具,PageRank利用了互聯網獨特的明主特性及其巨大的鏈接結構.在浩瀚的鏈接資源中,Google提取出上億個超級鏈接進行分析,制作出一個巨大的網絡地圖(Map).依據此地圖,PageRank技術能夠快速的計算出網頁的級別(Rank).這個級別的依據是:當從網頁A連接到網頁B時,Google就認為"網頁A投了網頁B一票".Google根據網頁的得票數評定其重要性.然而,除了考慮網頁得票數(即鏈接)的純數量之外,Google還要分析投票的網頁。“重要”的網頁所投出的票就會有更高的權重,并且有助于提高其他網頁的“重要性”。
Google以其復雜而全面自動的搜索方法排除了人為因素對搜索結果的影響。所以說,PageRank相對是公平的。在這個意義上,對于基于關鍵字搜索的引擎技術來說,PageRank無疑是一項優秀的技術,Google可以方便、誠實、客觀地幫您在網頁上找到任何有價值的資料。
3.1.1 PageRank算法描述
近些年來,大量的學術研究成果被應用到Web中,主要被用來統計網頁的引用或返回鏈接。這些數據為網頁的重要性和價值分析提供了粗略的依據。基于此, PageRank還進一步統計鏈接在所有網頁中出現的次數。PageRank定義如下所述:
假定頁面A有很多指向他的鏈接,分別定義為頁面T1...Tn。我們再定義阻尼系數d(0〈=d〈=1)。通常指定d=0.85(譯者注:下一節給出實例分析)。函數C(A)表示頁面A中指向其他頁面的鏈接的個數。那么,頁面A的PageRank(PR(A))可以通過下面的公式計算出:
PR(A)=(1-d)+d(PR(T1)/C(T1)+...PR(Tn)/c(Tn))
注意到PageRank的值是通過整個Web計算出來的,所以,所有頁面的PageRank值的和必然為1。
通過簡單的遞歸計算,并參照Web中規范型鏈接矩陣的主特征向量,我們就可以計算出一個頁面的PageRank(PR(A))。假設計算大約26,000,000個頁面的PageRank,使用一臺中等規模的工作站,大約需要數個小時的時間。具體實現的細節已經超出文本的討論范圍,讀者可以參考相關文檔。
3.1.2 PageRank模型
為了更好地理解 PageRank,我們建立以下一個假想的模型。我們假定有一個Web用戶正在隨機瀏覽某個網頁,隨著興趣的變化,他也可能隨機點擊頁面中的另一個鏈接,跳轉到其他頁面(暫且假定該用戶沒有使用返回按鈕)。在這個模型中,吸引用戶點擊指向某個頁面的鏈接的概率就是頁面的PageRank。而由于某些因素導致用戶選擇了其他鏈接的概率就是該頁面的阻尼系數d。有一些極端的情況,如有些頁面可能很少被人訪問,這些頁面就會積累起很高的阻尼系數。所以說,PageRank的技術可以公平有效到避免有些系統為了獲取較高級別而采取一些欺騙搜索引擎的行為。
一般來說。網頁的鏈接指向越多,PageRank的值就會越高。同樣,被一些“重量級”的網站(例如yahoo)引用的次數越多,PageRank的值同樣也會很高。相反,那些設計不佳,或者被鏈接破壞指向的網頁,將逐漸被用戶所遺忘。所有的這些因素都在PageRank技術的綜合考慮之中。
3.2錨文本(anchor text)
在Google中,鏈接文本(text of link )被使用一種特殊的方式進行處理。大多數的搜索引擎都是把鏈接文本和它所在的頁面相關聯,而Google則把鏈接文本和它指向的文檔聯系到一起(想想的確應該如此)。這樣做的優點很多:首先,錨(anchor )一般都會提供它所指向的文檔的準確的描述,而這樣信息,頁面本身往往不能提供;第二,對于那些不能被基于文本的搜索引擎建立索引的文檔,例如圖象,程序以及數據庫等,指向它們的鏈接卻可能存在,這樣就使得那些不能被引擎取回分析的文檔也能作為查詢結果返回。但是,這樣做也可能會引起一些問題,因為這些文檔在返回給用戶之前并未經過搜索引擎的有效性檢查。在這種情況下,搜索引擎就可以簡單地返回查詢結果,甚至不用考慮頁面是否存在,而只管是否有指向它們的超級鏈接存在。也許你會問,這合適嗎?不用擔心,由于查詢結果是經過級別排序輸出的,這種特殊的情況也許根本看不到。
其實,這種使用錨文本技術的思想更早可以追溯到World Wide Web Worm搜索引擎。它使得WWWW可以檢索到非文本信息,甚至擴展到一些可以下載的文檔,Google繼承了這種思路,因為它可以幫助提供更好的搜索結果。然而,使用這種技術需要克服很多的技術難題,首當其沖的就是如何處理如此龐大的數據量。我們來看看一組數據,在Google爬蟲取回的24,000,000個網頁數據中,需要處理的鏈接數高達259,000,000之多。
3.3其它功能
除了PageRank和錨文本技術之外,Google還有一些其它的技術。首先,對于所有命中(hits),Google都記錄了單詞在文檔中的位置信息,這些信息在最終的查詢中可以被用來進行單詞的相似度分析。第二,Google還記錄了頁面中的字體大小、大小寫等視覺信息。有的時候,大號字體和粗體的設置可以用來表示一些重要的信息。第三,在repository數據庫中保存所有頁面的HTML代碼。
(譯注:命中(hit)是Google定義的一個數據結構,有關命中和相似度的描述,詳見下文。)
4.系統剖析
從上文中,我們已經了解Google的一些工作原理。在這一章節中,我們將一起深入探討Google的體系框架,然后具體介紹Google用到的一些數據結構。最后,我們再一起分析Google用到的三個關鍵技術:網頁抓取(crawling)、索引(indexing)以及基于關鍵字的搜索(searching)。
4.1 Google體系框架
本節中,我們共同探討Google體系框架的運行流程,如圖1所示。下面的幾個章節將詳細的介紹所用到的技術和數據結構。考慮到執行效率,Google 中的大部分代碼都是用C/C++語言實現的,并且可以同時運行在Solaris和Linux系統中。
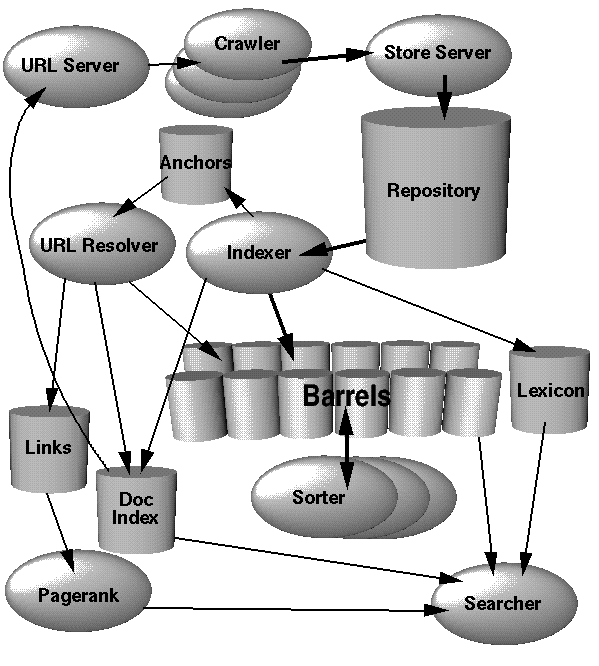 圖1
圖1
在Google的體系框架中,網頁爬行技術(Crawling,指網頁的下載過程)是由若干個分布式的網絡爬蟲(Crawler)軟件實現的。其中,一個叫做URL Server的服務器負責把需要分析的URL地址列表分派給這些網絡爬蟲進行處理。網頁數據如果被取回,將立即被送到Store Server中。Store Server對網頁數據進行壓縮,然后保存到Repository數據庫中。每一個文檔都擁有一個與之相關的唯一的ID編號,Google稱它為docID。每當有一個新的鏈接從頁面中被解析(parse)出來,它所指向的文檔就將自動獲得一個docID。建立索引的任務則交給索引器(Indexer)和排序器(Sorter)來完成。Indexer依次從Repository中取出文檔,對文檔解壓縮,然后對文檔進行解析。隨后文檔被解析為一組命中。在Google中,命中(hit)是一種數據結構,用來記錄單詞在文中每一次出現的信息。在命中結構中,記錄了每個詞(word)、詞在頁面中的位置、大小寫、字體相對大小等信息。這樣,每個詞都有很多不同的命中,這些命中的組合又稱為該詞的命中列表(hit list)。索引器把這些命中再寫入到一組桶(barrel) 中,并建立一個部分排序的前敘索引(foward index)。索引器還同時把網頁中所有的鏈接的重要信息解析出來,并記錄到一個叫做Anchors的文件中。該文件包含了足夠多的信息,從中可以查詢出每一個鏈接的來源、指向以及該鏈接的文本。
(譯注:索引器還把解析出的詞寫入到一個詞典(Lexicon中,這將在下文中提到。)
URL Resolver服務器負責從 Anchors文件中讀取這些鏈接,把相對路徑改為絕對路徑,再轉換為相應的 docID。通過docID的關聯,錨文本的信息也被加入到前序索引的anchor hit結構中。URL Resolver同時創建了一個Links數據庫,用來存放兩兩對應的docID。Links數據庫被用來計算所有文檔的PagePank 。
接著排序器接管過這些桶。如前所述,這些桶已經按照 docID進行了排序。排序器的主要任務是按照WordID重新進行排序,從而為這些桶生成一個倒排索引(inverted index)。這個操作是在每個桶中執行的,所以只需要用到很少的臨時空間。排序器還建立了一個WordID列表,列表中同時記錄了該WordID在倒排索引中的偏移量大小。有一個叫做DumpLexicon的工具,用來把wordID和上文中提到的由索引器產生的詞典(Lexicon)相結合,并產生一個新的詞典。這個新的詞典被用在最終的搜索程序中,連同PageRank和倒排序索引一起,為用戶提供查詢服務。
4.2 數據結構
Google對數據結構進行了很多優化,其目的主要是為了有效的減少在處理大文檔的抓取、索引以及查詢時所需要耗費的成本。雖然這些年來計算機的性能得到了很大的改善,但對于磁盤的檢索仍然需要大約10ms的時間來完成。基于性能的考慮,Google盡可能地避免使用磁盤操作,而這個想法也很大的影響了數據結構的設計思路。
4.2.1 巨型文件(BigFile)
巨型文件(BigFile)被設計成為跨越多文件系統地、64位地址空間的虛擬文件,并能夠在多文件系統中自動進行文件分配。因為操作系統不能為我們提供有用的支持,巨型文件包(BigFile package)被設計用來負責操作文件描述符的創建和銷毀。另外,巨型文件也支持一些初步的壓縮喧響。
4.2.2 數據倉庫(Repository)
數據倉庫(Repository)中保存了每一個網頁完整的HTML代碼。為了節省空間,頁面在存儲前使用zlib技術進行了壓縮。壓縮技術的選擇綜合考慮了速度和壓縮比的因素。盡管bzip技術在壓縮比方面技高一籌(壓縮比達到了4:1),Google還是基于速度的考慮最終選擇了zlib(壓縮比只有3:1)。文檔記錄在數據倉庫中順序排列,并以docID、length、URL等作為文檔記錄的前綴,如圖2所示。數據倉庫的訪問不需要使用任何其他的數據結構,這樣有助于保持數據的完整性,并且使得開發變得更為容易。

圖2
4.2.3 文檔索引(Document Index)
文檔索引(Document Index)用來跟蹤每一個文檔的信息。它是一種定寬的ISAM(Index sequential access mode)類型的索引,并按照文檔的docID進行了排序。索引中的每一項存儲了當前文檔的狀態、指向數據倉庫的指針、文檔校驗和,以及一些統計信息。如果文檔被爬蟲取回,則該索引項還將包含一個指向docinfo文件的指針。docinfo文件包含該文檔的URL和標題;否則,這個指針就被指向一個僅包含一種比較緊湊的數據結構,以及在一次搜索操作中查找一條磁盤記錄的執行效率。
另外,在轉換URLs到docIDs時需要用到一個文件。這個文件其實是一個包含URL校驗和(checksum)和與它對應的docID的列表,并且按照checksum進行排序。通常,我們需要根據URL來查找文檔的docID。這時,首先計算出該URL的校驗和(checksum)進行二進制的檢索,然后根據檢索結果找到其所對應的docID。其實,URL Resolver正是使用這個辦法把URL轉換為docID的。在這里使用批處理模式很有必要,否則對于包含322,000,000各鏈接的數據集來說,要檢索所有的鏈接至少得耗費數月之久。
4.2.4 詞典 (Lexicon)
詞典有好幾種不同的格式.隨著內存成本的下降,現在可以實現把詞典嵌入到內存中運行,這將可以大大提高運行的效率.在一個256M電腦的內存中,可以運行一個包含14,000,000個詞匯的詞典。詞典由兩部分來實現:一個詞列表(彼此之間以Null分隔)和一個包含指針的哈希表.
4.2.5 命中列表(Hit Lists)
命中列表(hit list)對應于某個特定的詞在某個特定的文檔中一次或多次的出現,它主要用來記錄詞在文中出現的位置、字體、大小寫等信息。命中列表在前序索引和倒排索引中都占據了絕大部分的空間。因此,命中列表需要盡可能地以一種高效率的方式來實現。有幾個可以用來參考的編碼方案:一個是簡單編碼方式(三位整數法),第二是壓縮編碼方式(對位的分配進行手工優化),最后一種是有名的霍夫曼編碼方式。Google在權衡了空間的占用量以及對于位操作的復雜性之后,選擇了第二種壓縮編碼方案。命中的實現細節,參見圖3
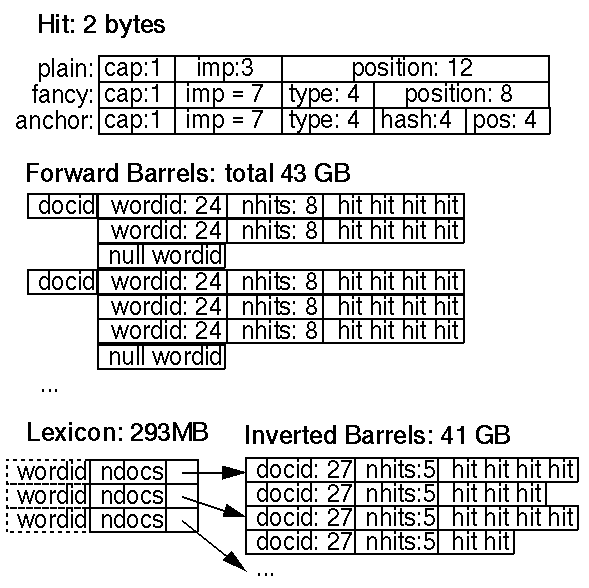 圖3。
圖3。
在這種壓縮編碼中,每個命中占用2個字節的空間。命中又可細分為兩種類型:特殊命中(fancy hit)和普通命中(plain hit)。特殊命中(fancy hit)是指出現在URL、頁面標題、錨文本或者meta標簽中的命中,除此之外的全部命中都是普通命中(plain hit)。普通命中(plain hit)包含標識大小寫的位(1位)、字體大小位、以及12位的為之心系(如果在文檔中的位置大于4095,則一律以4096表示)。字體大小是字體在文檔中的相對大小,用3位來表示。字體大小只使用從000到110這七個數,111被用來單獨表示一個特殊命中(fancy hit)。特殊命中(fancy hit)也包含一個大小寫的位(1位)、字體大小(設為7=111)、4位的類型編碼、以及8位的位置信息。對于出現在錨文本的命中(anchor hit)來說,8位的位置信息又細分為錨中的位置信息(4位)以及錨所在的文檔docID的hash值(4位)。這樣,在針對某些特定的詞進行查詢時,如果找不到足夠的鏈接匹配,就可以從這些anchor hit中找一些來補充。以后,考慮到對于位置信息和docID的哈希值哈還會有更多的解決方案,anchor hit的存儲方式將會有所改變。另外,Google之所以使用字體的相對大小,主要是考慮到在對文檔計算級別時,我們不能僅僅因為A文檔使用了較大的字體就說A文檔比B文檔級別高。
命中列表的長度保存在命中列表的前面。為了節省空間,采用了一些特殊的技巧,從前序索引的worldID自段和后排索引的docID字段中分別壓縮出8位和5位空間,用來存儲該長度值。如果長度值出現溢出,這些位將使用一個溢出符表示,并在緊接著的下兩個字節中包含實際的長度值。
4.2.6 前序索引 (Forward index)
前序索引實際已經經過部分排序。它由許多個桶組成,每個桶中保存一定范圍的wordID。如果某篇文檔中詞對應到某個桶中的wordID,該文檔的wordID也會被記錄到該桶中。每個docID后面緊跟著一個屬于它的wordID列表,而這些列表中每個wordID的后面又緊跟著該word的命中列表。
因為大量重復docID的存在,這種存儲方案也許會帶來更大的空間需求。但是由于索引被分散在許多個桶中,而且這種設計在最后由排序器執行的短語索引操作中可以合理地節省時間上的開銷,并降低了編程的復雜度,所以,空間上的這點浪費是完全可以容忍的。而且,wordID中存儲的實際上是WordID與其所在的桶中的WordID最小值之間計算出來的相對差。這樣,WordID就只需要24位來存儲,余下的8位恰好可以被用來存儲命中列表中的長度(參見上文)。
4.2.7倒排索引(Inverted Index)
和前序索引一樣,到排索引也是由同一組桶所組成,只是這些桶經過了排序器的進一步處理。對于每一個有效的WordID,詞典中都會有一個指向包含該WordID的桶的指針。這個指針指向一個docID的列表(doclist),列表中的每一項都由docID和該WordID的命中列表組成。該WordID所在的所有的文檔的docID都包含在該doclist中.
一個重要的問題是,doclit列表中的docID應該如何排序?一個比較簡單的解決方案是直接根據docID排序。這種方案在對多字詞的復合查詢時,可以實現多個doclist之間的快速歸并(merge)操作。另外一個復雜一點的方案,是按照word在每篇文擋中出現的級別進行排序。
這種放案對于單字詞的查詢作用不大,但對于多字詞的查詢,可以實現把最近的查詢結果排到前面。兩種方案各有自己的不足。首先,歸并操作具有一定的難度;而級別計算函數的每一次改變都可能需要對索引進行重建,著無疑會給開發工作增加新的難度。所以,有必要采取一種折中的方案。在這個方案中,保持兩組排序的桶,其中一組用來包含在標題或錨文本中出現的命中列表,另一組則包含所有的命中列表。首先,查詢第一組桶(short barrel)中進行;如果找不到足夠的匹配,則轉到另一組桶(full barrel)中繼續查找。
4.3 Web爬行技術(Crawling the Web)
事實上,在Web上運行一個網絡爬蟲(crawler)的工作頗具挑戰性。這不僅兼顧棘手的性能和可靠性因素之外,更重要的,還需要考慮一些社會因素。由于需要實時的和成千上萬臺狀態不可控的Web服務器進行交互,Web爬行技術也極容易崩潰。
為了更好的適應Web上數以千億的網頁數量,Google采用了一種分布式的Web爬行系統,由于URL server負責把URL需求提交給若干個爬蟲軟件進行處理。需要說明的是,URLServer以及爬蟲都是用Python語言實現的。每個爬蟲一次可以同時打開大約300個連接線程,這樣,網頁爬行足以保持一個足夠快的進度。假如使用4個crawler,系統就可以實現最快每秒抓取超過100個頁面,也就是大約600k/秒的數據流。性能上的影響主要來自對于DNS(域名服務)的查詢,因此,每個爬蟲都配有一個單獨的DNS高速cache,這樣可以有效的避免影響效率的DNS查詢。爬蟲擁有的線程分為下列幾種狀態:DNS查詢階段,正在連接主機,發送請求階段,以及處理服務器響應過程。依據狀態的不同,線程被分別放在不同的隊列中。當線程的狀態發生改變時,異步IO的方式被用來發出事件通知,同時線程被轉移到另一個相關隊列中。
事實上,由于面對如此巨大的數據處理,總會有一些難以預料的事情發生。舉個例子來說,如果爬蟲試圖處理的鏈接是一個在線游戲,那會出現什么情況?情況的確很糟,自作聰明的爬蟲將取回大量的垃圾頁面,而當你發現問題并試圖處理時,你將面對的是數以千萬計的已經被下載的網頁。看來,有些導致錯誤的因素也許根本是無法預測的。系統必須經過認真的測試。然而,Internet如此之大,測試工作從何開始?這個時候,合理處理用戶的反饋信息顯得尤為重要。
4.4 Web索引技術(Indexing the Web)
解析技術(Parsing)--任何一種為Web設計的解析技術必須能夠有效處理各種各樣可能出現的錯誤,包括HTML標簽的拼寫錯誤,標簽定義中缺少的空格,非ASCII字符,錯誤嵌套的HTML標簽以及形形色色的其它錯誤類型。這些錯誤都在挑戰著設計者的想象力,促使他們拿出創造性的設計方案。考慮到速度的最大化,Google沒有采用由YACC來產生CFG解析器的做法,而使用Flex(一種快速的詞典分析器制作工具)設計了一個具有自己堆棧的詞典分析器。當然,分析器必須同時實現穩定性和高速度的要求。
文檔的哈希索引(Indexing Documents into Barrels)--文檔被解析之后,就會被編碼并放入有許多桶組成的哈希表中。文檔中的每一個詞,通過檢索在內存中運行的詞典哈希表,被映射成其所對應的WordID。詞典中沒有的詞被紀錄到一個日志文件中。當一個word被映射成WordID時,它在當前文檔中的出現信息將被同時構造成相應的命中列表,然后命中列表被紀錄到前序索引相對應的桶中。在這個過程中,詞典必須被共享,所以如何解決索引階段的并發操作問題成為一個難題。有一個方案,可以避免詞典的共享。在這個方案中,使用一個基詞典,其中固定使用大約14,000,000個詞。擴增的詞都寫入到日志中。這樣,多感索引器就可以并發的執行,而把這個包含擴增詞匯的日志文件交給最后剩下的一個索引器處理就夠了。
排序技術(Sorting)--為了建立倒排索引,排序排序器接管過前敘索引中的桶,并按照WordID進行重新排序,從而產生了兩組倒排序的桶:一組是對于標題和錨命中的倒排序索引(short barrle),一組是對于所有命中列表的倒排序索引(full barrle)。由于排序的過程每次僅再一個桶中進行,所以只需要很少的臨時空間。另外,排序的階段被盡可能多的分派到多臺計算機上運行,這樣,多個排序器就可以并行處理多個不同的bucket。因為捅不適合被放入內存中運行,排序器便把它細分為一系列適合放進內存中的bucket,這些bucket是基于WordID和docID的。然后,排序器把每一個bucket加載到內存中,并執行排序,最后把它的內容分別寫入到short barrle和full barrle這兩組倒排的桶中。
4.5 搜索技術(Searching)
能夠高效地提供高質量的搜索結果,是每一個搜索技術的最終目標。很多大型的商業化搜索引擎已經在執行效率方面取得了很大的進步。所以Google就把更多的精力投放到搜索結果的質量研究上來。當然,Google的執行效率同商業化的搜索引擎相比同樣毫不遜色。
Google的搜索過程如下。
1.解析查詢字符串;
2.把word映射成wordID;
3.對每一個word,首先從short barrel中doclist的開頭進行檢索;
4.遍歷整個doclist直到發現有一個文檔能夠匹配所有的搜索項目;
5.為此查詢計算文檔的級別;
6.如果到了short barrel中doclist的結尾,則從full barrel中doclist的開頭繼續進行檢索,并跳轉到步驟4;
7.如果沒有到達doclist的結尾,跳轉到步驟4;
8.對所有通過rank匹配的文檔進行排序,并返回前K個查詢結果。
為了控制響應時間,一旦匹配的文檔數目達到某個指定的值(例如40,000),如圖4所示,搜索器就直接跳轉到第8步。這就意味著可能有一些沒有完全優化的查詢結果被返回。盡管如此,PageRank技術的存在有效地改善了這種狀況。
4.5.1級別審定系統(The Panking System)
與其它的搜索引擎相比,Google利用了更多的Web文檔所提供的信息。每一個命中列表紀錄了詞的位置、字體、大小寫等信息。另外,包含在錨文本中的命中和文黨的PageRank一樣被Google所關注。要把所有這些信息都綜合起來給出一個頁面的級別有點難度,級別判定功能必定被設計成不會受到任何個別因素的影響。
首先考慮一種最簡單的情況--單詞查詢。為了在單詞匯查詢中計算出一個文檔的級別,Google首先分析該詞匯在這個文檔中的命中列表。Google為每一個命中定義了以下幾種不同的類型:標題、錨、URL、普通的大字體文本、普通的小字體文本 ,每一種類型都有自己的類型權重(type-weight).Google把命中的類型權重組合到一起形成一個以類型為索引的向量,接著統計出命中列表中每一種類型的命中所占的數量。每一個計數值又被轉換為一個計數權重(count-weight),計數權重隨計數值呈線性增長,到達某個計數值之后就會趨于停止。最后,把類型權重組成向量和計數權重組成的向量進行點乘得到的矢量積作為該文檔的IR分值。IR分值和PageRank再進行組合從而得出文檔最終的級別。
對于多詞匯的查詢,情況變得更加復雜。多個命中列表需要被同步分析,在文檔中出現位置比較靠近的命中就會比位置離的教遠的命中具有較高的權重。多個命中列表中的命中被綜合到一起一使得鄰近的命中最終被分配到一起。對于每一組經過匹配的命中,他們之間的相似度(proximity)接著被計算出來。相似度基于命中的文檔(或錨)中距離的遠近,并且被劃分為10個不同的值“bins”,這些bins的范圍被定義為從短語匹配(phrase match)到根本不匹配(not even close).除了對每一種類型的命中進行計數之外,同時也對每一種類型和相似度進行計數。每一對類型和相似度的組合稱作一個類型相似度權重(type-prox-weight),命中的計數則被轉換為計數權重。最后,把計數權重組成的向量和類型相似度權重組成的向量進行點乘也得到一個IR分值。在Google的一種特殊的調試模式中,這些數字和矩陣可以隨查詢結果一同顯示,這將為級別審定系統的開發工作帶來很大的幫助。