本文目的
本文的主要目的是討論企業應用實現高可用性的方案�����。即如何在保證性能的同時����,使得應用保持
24
小時的可用性��。
為實現此目的����,災難恢復和性能問題的解決是必不可少的��。本文僅就程序和應用服務器兩方面進行討論�����,不討論數據庫等相關的問題。
1.
??
災難恢復
所謂災難恢復(僅對
Web
應用而言),是指在某個應用失去響應能力后(比如重啟)����,客戶端能立即透明的切換到冗余應用����。這一切換對客戶端來講應該是感覺不到的����。從技術上來講,就是客戶端在與服務器端進行交互的過程中����,客戶端在服務器端保存的狀態能立即切換到新的服務器上����。在
web
應用中��,這些狀態一般保存在
http session
里�����。所以所謂狀態復制,一般來講就是
http session
復制。
目前能提供災難的方案之一是集群����。對于
Weblogic
��,集群的實現方式為
Paired servers replication
:
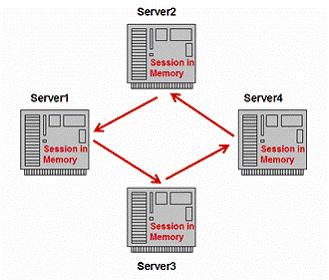
(圖片引自
http://www.theserverside.com/articles/article.tss?l=J2EEClustering
)
在這種實現方式里,
session
只在相鄰的或者指定的兩個
server
之間進行復制,當某一個
server
down
掉后��,需要
servers
前端的
load balancer
知道哪一臺
server
是這個
Server1
的
paired backup server
����,并將原來指向
Server1
的請求轉發給這臺
paired backup server
。應該說這種復制策略是相當高效的��,但是對集群前端的路由要求比較高�����。
2.
??
性能
企業應用一般會跑在多臺服務器上��。就性能而言,我們的期望自然是:總體性能
=
單臺服務器性能
X
服務器臺數。不過從上邊的說明就能看出,集群中的每一臺
server
都會有一部分性能耗費在
session
復制上��。耗費的性能取決于
session
的大小�����。如果應用中
session
保留了大量的數據�����,或者用戶數量很多�����,損耗的性能也將相當可觀����。
(有一種提升性能的方案是使用分布式的對象��,例如
EJB
��,根據對象耗費性能的不同對其所在服務器進行調整。不過這種方案早已充滿了極大的爭論�����。流行的觀點認為��,對于業務邏輯不是很復雜的應用��,使用分布式對象只會讓性能下降。因此下邊將不再討論�����。)
3.
??
維護
從維護的角度上看��,如果我們能不重啟應用就能給應用添加新的功能�����,或者修改已有的
bug
,那顯然相當
8
錯����。
分析
根據上邊的說明,我們可以初步得出幾個結論:
1、?
要使用Weblogic集群所帶來的災難恢復的好處����,就必須忍受同時帶來的性能損失��。
2��、?
在使用weblogic集群的同時,我們必須擁有高性能的
Server
路由設備����。
3�����、?
使用weblogic集群,在重新部署應用時����,由于不能重新部署
(redeploy)
集群下單臺
server
的應用����,導致幾臺
server
需要同時停掉應用����。當所有的
server
全都陷入災難中,災難恢復也就失去了意義��。
?
那么�����,如何在實現災難恢復和高性能的同時�����,又能避免或者減少上邊列舉的損失呢����?
初步的思路可以有:
?
1、?
如果我們能忍受某一臺
server down
機后客戶狀態丟失的后果,那么最簡單的方案就是停用集群,前端
load balancer
把相同
IP
的請求轉到相同的服務器。在重新部署應用時,分批重起不同
server
上的應用����。
2����、?
全部采用無
session
策略�����。將客戶狀態保留在客戶端��。這樣沒有Weblogic集群也就無所謂了。我們只需要一個普通的(分發器+失敗檢測)將請求均勻的分發到可用的服務器上。
?