2011年2月12日
#
摘要: 一個完整的自動化測試框架體系包含以下幾個部分:1、自動化測試框架;2、測試腳本以及測試數據管理;3、測試腳本的執行管理系統;4、測試結果的顯示與分析系統。其中最重要的是自動化測試框架部分。
閱讀全文
摘要: JUnit
JUnit是由 Erich Gamma 和 Kent Beck 編寫的一個回歸測試框架(regression testing framework)。Junit測試是程序員測試,即所謂白盒測試,因為程序員知道被測試的軟件如何(How)完成功能和完成什么樣(What)的功能。Junit是一套框架,繼承TestCase類,就可以用Junit進行自動測試了。
更多JUnit信息
閱讀全文
摘要: Have you wondered why certain programs are located under /bin, or /sbin, or /usr/bin, or /usr/sbin?
For example, less command is located under /usr/bin directory. Why not /bin, or /sbin, or /usr/sbin? What is the different between all these directories?
In this article, let us review the Linux filesystem structures and understand the meaning of individual high-level directories
閱讀全文
摘要: 當今互聯網的發展,已不是大魚吃小魚的時代,而是快魚吃慢魚的時代。互聯網產品的制勝原則就是一個字——“快”。在各種形態的產品研發中,我們始終貫徹如一的價值觀之一就是“快”,我們應該如何來理解和詮釋“快”?又會從哪些方面來執行貫徹這個原則呢?
閱讀全文
摘要: 軟件測試的十二個誤區大體總結如下:
1) 測試人員不需要了解軟件開發的知識:
這個很要命的,我們談到軟件測試人員未來的發展方向大致有:自動化測試,性能測試,測試管理,項目經理。這其中自動化測試和性能測試包括項目管理,都會要求對軟件開發有深入的理解,如何能設計一個好的自動化框架,好的性能測試用例,如何管理一個開發團隊,這都需要我們在軟件開發方面有所掌握。不單要掌握,而且要精通。此其一。
其二:如果不了解開發知識,測試人員很容易被開發人員牽著鼻子走,因為開發人員隨便一忽悠,你如果不了解個中奧妙,你一個字也說不上來。(以前我們討論 Cookie和Session,由于GoAhead不支持Session,只能用Cookie來控制,差點別開發人員忽悠了)
閱讀全文
摘要: 寫在前面:寫Android程序有一個很重要的原則,不阻塞UI線程。因此Android提供了5種方法來,讓一些耗時的作業在其它線程中執行,然后把結果返回給UI線程,以免阻塞UI線程。
閱讀全文
探討了軟件測試的可測試性,主要包括Controllability, Observability, Availability,Simplicity, Stability 和 Information.
HeuristicsOfSoftwareTestability.pdf
摘要: android的selector的用法:
首先android的selector是在drawable/xxx.xml中配置的。
先看一下listview中的狀態:
把下面的XML文件保存成你自己命名的.xml文件(比如list_item_bg.xml),在系統使用時根據ListView中的列表項的狀態來使用相應的背景圖片。drawable/list_item_bg.xml
閱讀全文
摘要: The Monkey is a command-line tool that that you can run on any emulator instance or on a device. It sends a pseudo-random stream of user events into the system, which acts as a stress test on the application software you are developing.
The Monkey includes a number of options, but they break down into four primary categories:
Basic configuration options, such as setting the number of events to attempt.
Operational constraints, such as restricting the test to a single packag
閱讀全文
摘要: Programmers can configure logging either by creating loggers, handlers, and formatters explicitly in a main module with the configuration methods listed above (using Python code), or by creating a logging config file. The following code is an example of configuring a very simple logger, a console handler, and a simple formatter in a Python module:
閱讀全文
摘要: Android系統中Looper負責管理線程的消息隊列和消息循環,具體實現請參考Looper的源碼。 可以通過Loop.myLooper()得到當前線程的Looper對象,通過Loop.getMainLooper()可以獲得當前進程的主線程的Looper對象。
閱讀全文
摘要: The list below defines some of the basic terminology of the Android platform.
.apk file
Android application package file. Each Android application is compiled and packaged in a single file that includes all of the application's code (.dex files), resources, assets, and manifest file. The application package file can have any name but must use the .apk extension. For example: myExampleAppname.apk. For convenience, an application package file is often referred to as an ".apk".
Re
閱讀全文
摘要: C.__init__(self[, arg1, ...] )
Constructor (with any optional arguments)
C.__new__(self[, arg1, ...] )[a]
Constructor (with any optional argu ments); usually used for setting up subclassing of immutable data types
C.__del__(self)
Destructor
C.__str__(self)
Printable string representation; str() built-in and print statement
C.__repr__(self)
Evaluatable string representation; repr() built-in and '' operator
閱讀全文
摘要: 本來這是個老生常談的問題,上周自成又分享了一些性能優化的建議,我這里再做一個全面的Tips整理,謹作為查閱型的文檔,不妥之處,還請指正;
如果你已經對yahoo這些優化建議爛熟于心,果斷點這里
閱讀全文
Five test auomation framework are discussed in this paper.
1) The Test Script Modularity Framework
2) The Test Library Architecture Framework
3) The Keyword-Driven or Table-Driven Testing Framework
4) The Data-Driven Testing Framework
5) The Hybrid Test Automation
摘要: 一、ASE(Android Scripting Environment)為Android系統帶來了腳本語言的技術,通過它我們可以編輯和執行腳本,和腳本解釋交互。腳本可以訪問多數Android API,目前有一個開源項目叫做Scripting Layer for Android (SL4A) ,提供了對python,javaScript, Lua等腳本的支持。ASE主要通過兩種方式來訪問 Android API,一種是通過JSON-RPC來訪問,另外一種通過BeanShell(Java語言的動態版本)直接訪問Android API。SL4AL架構如下圖:
閱讀全文
摘要: 2.你需要學習JAVA語言的基礎知識以及它的核心類庫 (collections,serialization,streams,networking, multithreading,reflection,event,handling,NIO,localization,以及其他)。
閱讀全文
1)
http://www.pythonchallenge.com/ 提供了不同level的Python題目,非常有趣的題目。做完一題后,把URL中的pc改為pcc可以看到上一題的答案
2)
http://projecteuler.net/ 里面有200多道題目,不要要求提交代碼,只要最終答案,提供用各種語言來解決問題。這里(
http://dcy.is-programmer.com/posts/8750.html)有部分題目的答案
非常好玩,有興趣的朋友,快來試試吧
看看 project euler 的第一道題:
If we list all the natural numbers below 10 that are multiples of 3 or 5, we get 3, 5, 6 and 9. The sum of these multiples is 23. Find the sum of all the multiples of 3 or 5 below 1000.
用 python 語言寫出來是:
 print sum(i for i in xrange(1, 1000) if i % 3 == 0 or i % 5 == 0)
print sum(i for i in xrange(1, 1000) if i % 3 == 0 or i % 5 == 0)
This is the first edition of what is expected to become a recurring series on InfoQ. The idea behind this minibook is that a number of InfoQ articles and interviews which deal with a particular topic (in this case, REpresentational State Transfer, or REST) are combined together to provide a detailed exploration suitable for both beginners and advanced practitioners.
Read More: http://www.infoq.com/minibooks/emag-03-2010-rest;jsessionid=1E2375E822D980824403DAD46588FAFE
摘要: #Trie Tree的基本特點
1)根節點不包含字符,除根節點外每個節點只包含一個字符
2)從根節點到某一個節點,路徑上經過的字符連接起來,為該節點對應的字符串
3)每個節點的所有子節點包含的字符串不相同
閱讀全文
摘要: The Bloom filter, conceived by Burton Howard Bloom in 1970, is a space-efficient probabilistic data structure that is used to test whether an element is a member of a set.False positivesare possible, but false negatives are not. Elements can be added to the set, but not removed (though this can be addressed with a counting filter). The more elements that are added to the set, the larger the probability of false positives
閱讀全文
摘要: These posts have garnered a number of interesting comments. I want to address two of the negative ones in this post. Both are of the same general opinion that I am abandoning testers and that Google is not a nice place to ply this trade. I am puzzled by these comments because nothing could be further from the truth. One such negative comment I can take as a one-off but two smart people (hey they are reading this blog, right?) having this impression requires a rebuttal. Here are the comments:
閱讀全文
摘要: One of the key ways Google achieves good results with fewer testers than many companies is that we rarely attempt to ship a large set of features at once. In fact, the exact opposite is often the goal: build the core of a product and release it the moment it is useful to as large a crowd as feasible, then get their feedback and iterate. This is what we did with Gmail, a product that kept its beta tag for four years. That tag was our warning to users that it was still being perfected. We removed
閱讀全文
摘要: Lots of questions in the comments to the last two posts. I am not ignoring them. Hopefully many of them will be answered here and in following posts. I am just getting started on this topic.
閱讀全文
摘要: Android applications are, at least on the T-Mobile G1, limited to 16 MB of heap. It's both a lot of memory for a phone and yet very little for what some developers want to achieve. Even if you do not plan on using all of this memory, you should use as little as possible to let other applications run without getting them killed. The more applications Android can keep in memory, the faster it will be for the user to switch between his apps. As part of my job, I ran into memory leaks issues in Andr
閱讀全文
摘要: The Java community is now swamped with discussions about Oracle's patent suit against Google's Android platform. I've been contributing my opinion in several places, but there is one critical topic that needs repeating the same comments everywhere... so, this blog spills the beans once and completely.
閱讀全文
摘要: Activities in the system are managed as an activity stack. When a new activity is started, it is placed on the top of the stack and becomes the running activity -- the previous activity always remains below it in the stack, and will not come to the foreground again until the new activity exits.
閱讀全文
摘要: The one question I get more than any other is "How does Google test?" It's been explained in bits and pieces on this blog but the explanation is due an update
閱讀全文
摘要: Dependency injection asks us to separate the new operators from the application logic. This separation forces your code to have factories which are responsible for wiring your application together. However, better than writing factories, we want to use automatic dependency injection such as GUICE to do the wiring for us. But can DI really save us from all of the new operators?
閱讀全文
摘要: Everyone seems to think that they are writing OO after all they are using OO languages such as Java, Python or Ruby. But if you exam the code it is often procedural in nature
閱讀全文
By James Whittaker
I’ve had a number of questions about the SET role and it seems I have confused folks when I say that the SWE is a tester and the SET is a tester and at the same time the SWE is a developer and the SET is a developer. What could possibly be confusing about that?
Oh, yeah. Right.
My next series of posts are going to detail the role of the SET and all will eventually be clear but some clarification on career path seems worthwhile.
SETs are developers who write test code and automation as their primary task. They are in every sense of the word a developer. When we interview SETs, SWEs are on the interview loop and SWE questions are asked. They are not all of the interview, but they are part of it.
This means that the skill set that our SETs possess makes them perfect candidates for switching to the SWE role. There is neither incentive nor deterrent to do so. SETs and SWEs are on the same pay scale and bonus structure (I have both roles reporting to me so I have real visibility into salary data) and their promotion velocity (again based on actual data) is roughly equivalent. This means that SETs have no outside influences to prompt them one way or the other.
The key factor is really the type of work you are doing. SETs who find themselves involved in SWE work usually convert to SWE. SWEs are also drawn in the opposite direction. Much of this happens through our 20% time work. Any SET interested in SWE work can take on a 20% task doing feature development. Any SWE interested in automation can find a group and sign up for a 20%. Right now I have both SWEs and SETs involved in such cross pollination.
The ideal situation is that the title reflects the actual work that you are involved in. So if an SET starts doing more feature dev work than automation, he or she should convert, same for SWEs doing automation work. In my time here, conversions in both directions have happened, but it is not all that common. The work of both roles is engaging, interesting and intense. Few Googlers are walking around bored.
Bottom line: do the work you are passionate about and capable of and the right job title will find you.
一、概念
靜態分派(Static Dispatch),發生在編譯時期,分派是根據靜態類型信息發生的,方法重載就是靜態分派。
動態分派(Dynamic Dispatch),發生在運行時期,動態分派動態地置換掉某個方法。面向對象的語言用動態分派實現多態性。
Java語言支持靜態多分派和動態的單分派,利用設計模式Java可以實現Double Dispatch,即訪問者模式。
二、Visitor Pattern
目的:封裝一些施加于某種數據結構元素之上的操作。
UML圖:
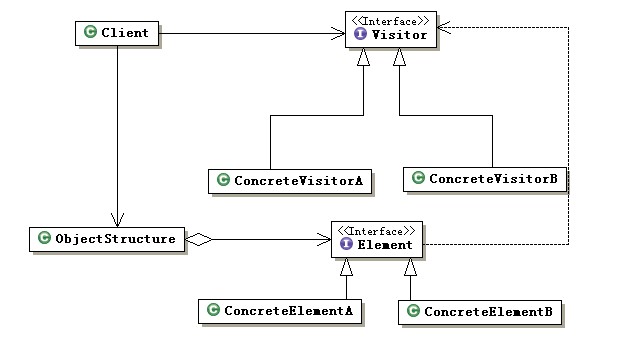
主要原理:“反傳球”,Element來Visitor之間二輪調用,調用過程中用sinlge dispatch確定類型
記錄關于REST的一些技術:
1、REST簡介:http://zh.wikipedia.org/zh/REST
2、InfoQ 深入淺出REST: http://www.infoq.com/cn/articles/rest-introduction
摘要: 要設計良好的架構,必須做到關注點分離,這樣可以產生高內聚、低耦合的系統,這是美麗架構的終極原則
閱讀全文
摘要: A synchronization aid that allows a set of threads to all wait for each other to reach a common barrier point. CyclicBarriers are useful in programs involving a fixed sized party of threads that must occasionally wait for each other. The barrier is called cyclic because it can be re-used after the waiting threads are released.
閱讀全文
摘要: A java.util.concurrent.CountDownLatch is a concurrency construct that allows one or more threads to wait for a given set of operations to complete
閱讀全文
文章描述了實現 Multithreaded Servers的3種方法:
1)單線程,性能性差,請求等待時間長
2)多線程,把接受請求和處理請求的線程分開,接受后交給 worker處理
3)線程池,性能最佳,有效地防止負載過重,重復利用線程,請求多時,讓請求排隊接收處理
4)主要用socket來通信, ServerSocket 和 Socket
具體文章請看:http://tutorials.jenkov.com/java-multithreaded-servers/index.html
摘要: 軟件模塊之間總是存在著一定的接口,從調用方式上,可以把他們分為三類:同步調用、回調和異步調用。
同步調用是一種阻塞式調用,調用方要等待對方執行完畢才返回,它是一種單向調用,如HTTP;
回調是一種雙向調用模式,也就是說,被調用方在接口被調用時也會調用對方的接口;
異步調用是一種類似消息或事件的機制,不過它的調用方向剛好相反,接口的服務在收到某種訊息或發生某種事件時,會主動通知客戶方(即調用客戶方的接口),如JMS;
閱讀全文
摘要: 雖然很少有 Java? 開發人員能夠忽視多線程編程和支持它的 Java 平臺庫,更少有人有時間深入研究線程。相反地,我們臨時學習線程,在需要時向我們的工具箱添加新的技巧和技術。以這種方式構建和運行適當的應用程序是可行的,但是您可以做的不止這些。理解 Java 編譯器的線程處理特性和 JVM 將有助于您編寫更高效、性能更好的 Java 代碼
閱讀全文
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
摘要: This is the text of the Commencement address by Steve Jobs, CEO of Apple Computer and of Pixar Animation Studios, delivered on June 12, 2005.
I am honored to be with you today at your commencement from one of the finest universities in the world. I never graduated from college. Truth be told, this is the closest I’ve ever gotten to a college graduation. Today I want to tell you three stories from my life. That’s it. No big deal. Just three stories.
The first story is about conn
閱讀全文
摘要: 1. 軟件架構概述
1.1 什么是軟件架構
◎ 軟件架構的概念很混亂。如果你問五個不同的人,可能會得到五種不同的答案。
◎ 軟件架構概念主要分為兩大流派:
組成派:軟件架構 = 組件 + 交互。
決策派:軟件架構 = 重要決策集。
◎ 組成派和決策派的概念相輔相成。
閱讀全文
摘要: 所謂第一范式(1NF)是指數據庫表的每一列都是不可分割的基本數據項,同一列中不能有多個值,即實體中的某個屬性不能有多個值或者不能有重復的屬性。如果出現重復的屬性,就可能需要定義一個新的實體,新的實體由重復的屬性構成,新實體與原實體之間為一對多關系。在第一范式(1NF)中表的每一行只包含一個實例的信息。簡而言之,第一范式就是無重復的列。
閱讀全文
OS實時監控工具dstat,整合了vmstat, iostat, ifstat, netstat等常見os監控工具的優點,輸出的結果簡單直觀,并且結果可以保存到csv文件。
dokie@ubuntu:~$ dstat
----total-cpu-usage---- -dsk/total- -net/total- ---paging-- ---system--
usr sys idl wai hiq siq| read writ| recv send| in out | int csw
14 5 78 3 0 0| 553k 109k| 0 0 | 83B 989B| 983 2190
8 2 90 0 0 0| 0 0 |2076B 1383B| 0 0 |1076 1407
9 3 89 0 0 0| 0 72k|7530B 420B| 0 0 | 721 1501
9 4 87 0 0 0| 0 0 |9547B 564B| 0 0 | 750 1474
8 2 89 0 0 0| 0 0 | 12k 672B| 0 0 | 772 1681
9 2 89 0 0 0| 0 0 | 13k 792B| 0 0 | 677 1396
dokie@ubuntu:~$ dstat -h
Usage: dstat [-afv] [options..] [delay [count]]
Versatile tool for generating system resource statistics
Dstat options:
-c, --cpu enable cpu stats
-C 0,3,total include cpu0, cpu3 and total
-d, --disk enable disk stats
-D total,hda include hda and total
-g, --page enable page stats
-i, --int enable interrupt stats
-I 5,eth2 include int5 and interrupt used by eth2
-l, --load enable load stats
-m, --mem enable memory stats
-n, --net enable network stats
-N eth1,total include eth1 and total
-p, --proc enable process stats
-r, --io enable io stats (I/O requests completed)
-s, --swap enable swap stats
-S swap1,total include swap1 and total
-t, --time enable time/date output
-T, --epoch enable time counter (seconds since epoch)
-y, --sys enable system stats
--aio enable aio stats
--fs enable fs stats
--ipc enable ipc stats
--lock enable lock stats
--raw enable raw stats
--socket enable socket stats
--tcp enable tcp stats
--udp enable udp stats
--unix enable unix stats
--vm enable vm stats
-M stat1,stat2 enable external plugins
--mods stat1,stat2
--list list all internal and external plugins
-a, --all equals -cdngy (default)
-f, --full expand -C, -D, -I, -N and -S discovery lists
-v, --vmstat equals -pmgdsc -D total
--integer show integer values
--nocolor disable colors (implies --noupdate)
--noheaders disable repetitive headers
--noupdate disable intermediate updates
--output file write CSV output to file
delay is the delay in seconds between each update
count is the number of updates to display before exiting
The default delay is 1 and count is unspecified (unlimited)
常用的命令:dstat -cdlmnpsy
導出為CVS:
dstat -ta --output osstat.csv
1. 安裝JDK
http://wiki.ubuntu.org.cn/Java%E5%AE%89%E8%A3%85%E9%85%8D%E7%BD%AE
2. 安裝Python
1). apt-get install python
2). PyDev for eclipse:
Name:PyDev,Location:http://pydev.org/updates
Ref:http://www.cnblogs.com/Realh/archive/2010/10/10/1847251.html
3. 安裝dstat--性能監測工具
apt-get install dstat
下面是來自 Taobao QA Team中的安全測試方面的文章,對初學者很有指導意義
安全測試學習筆記系列:
1. http://qa.taobao.com/?p=11352
2.http://qa.taobao.com/?p=11363
3.http://qa.taobao.com/?p=11472
4.http://qa.taobao.com/?p=11479
5.http://qa.taobao.com/?p=11484
------
WEB漏洞攻擊之SQL注入:http://qa.taobao.com/?p=11403
摘要: onabort 當用戶中斷下載圖像時觸發。
onactivate 當對象設置為活動元素時觸發。
onafterprint 對象所關聯的文檔打印或打印預覽后立即在對象上觸發。
onafterupdate 當成功更新數據源對象中的關聯對象后在數據綁定對象上觸發。
onbeforeactivate new 對象要被設置為當前元素前立即觸發。
onbeforecopy 當選中區復制到系統剪貼板之前在源對象觸發。
onbeforecut 當選中區從文檔中刪除之前在源對象觸發。
onbeforedeactivate 在 activeElement 從當前對象變為父文檔其它對象之前立即觸發。
onbeforeeditfocus 在包含于可編輯元素內的對象進入用戶界面激活狀態前或可編輯容器變成控件選中區前觸發。
onbeforepaste 在選中區從系統剪貼板粘貼到文檔前在目標對象上觸發。
閱讀全文
數組類Array是Java中最基本的一個存儲結構。它用于存儲一組連續的對象或基本類型的數據。其中的元素的類型必須相同。
Array是最有效率的一 種:
1、效率高,但容量固定且無法動態改變。 Array還有一個缺點是,無法判斷其中實際存有多少元素,length只是告訴我們Array的容量。
2、Java中有一個Arrays類,專門用來操作Array,提供搜索、排序、復制等靜態方法。 equals():比較兩個Array是否相等,Array擁有相同元素個數,且所有對應元素兩兩相等。 fill():將值填入Array中。 sort():用來對Array進行排序。 binarySearch():在排好序的Array中尋找元素。 System.arraycopy():Array的復制。
Java Collections Framework成員主要包括兩種類型,即:Collection和Map類型。 在Java中提供了Collection和Map接口。其中List和Set繼承了Collection接口;Vector、ArrayList、 LinkedList三個類實現List接口,HashSet、TreeSet實現Set接口,HashTable、HashMap、 TreeMap實現Map接口。由此可見,Java中用8種類型的基本數據結構來實現其Collections Framework;下面分別進行介紹。
Vector:基于Array的List,性能也就不可能超越Array,并且Vector是"sychronized"的,這個也是Vector和ArrayList的唯一的區別。
ArrayList:同Vector一樣是一個基于Array的,但是不同的是ArrayList不是同步的。所以在性能上要比Vector優越一些,但 是當運行到多線程環境中時,可需要自己在管理線程的同步問題。從其命名中可以看出它是一種類似數組的形式進行存儲,因此它的隨機訪問速度極快。
LinkedList:LinkedList不同于前面兩種List,它不是基于Array的,所以不受Array性能的限制。它每一個節點(Node) 都包含兩方面的內容:
1、節點本身的數據(data);
2、下一個節點的信息(nextNode)。所以當對LinkedList做添加,刪除動作的時候 就不用像基于Array的List一樣,必須進行大量的數據移動。只要更改nextNode的相關信息就可以實現了所以它適合于進行頻繁進行插入和刪除操 作。這就是LinkedList的優勢。Iterator只能對容器進行向前遍歷,而 ListIterator則繼承了Iterator的思想,并提供了對List進行雙向遍歷的方法。
List總結:
1、所有的List中只能容納單個不同類型的對象組成的表,而不是Key-Value鍵值對。例如:[ tom,1,c ];
2、所有的List中可以有相同的元素,例如Vector中可以有 [ tom,koo,too,koo ];
3、所有的List中可以有null元素,例如[ tom,null,1 ];
4、基于Array的List(Vector,ArrayList)適合查詢,而LinkedList(鏈表)適合添加,刪除操作。
HashSet:雖然Set同List都實現了Collection接口,但是他們的實現方式卻大不一樣。List基本上都是以Array為基礎。但是 Set則是在HashMap的基礎上來實現的,這個就是Set和List的根本區別。HashSet的存儲方式是把HashMap中的Key作為Set的 對應存儲項,這也是為什么在Set中不能像在List中一樣有重復的項的根本原因,因為HashMap的key是不能有重復的。HashSet能快速定位 一個元素,但是放到HashSet中的對象需要實現hashCode()方法0。
TreeSet則將放入其中的元素按序存放,這就要求你放入其中的對象是可排序的,這就用到了集合框架提供的另外兩個實用類Comparable和 Comparator。一個類是可排序的,它就應該實現Comparable接口。有時多個類具有相同的排序算法,那就不需要重復定義相同的排序算法,只要實現Comparator接口即可。TreeSet是SortedSet的子類,它不同于HashSet的根本就是TreeSet是有序的。它是通過SortedMap來實現的。
Set總結:
1、Set實現的基礎是Map(HashMap);
2、Set中的元素是不能重復的,如果使用add(Object obj)方法添加已經存在的對象,則會覆蓋前面的對象; Set里的元素是不能重復的,那么用什么方法來區分重復與否呢? 是用==還是equals()? 它們有何區別? Set里的元素是不能重復的,即不能包含兩個元素e1、e2(e1.equals(e2))。那么用iterator()方法來區分重復與否。 equals()是判讀兩個Set是否相等。==方法決定引用值(句柄)是否指向同一對象。
HashMap、TreeMap、Hashtable:
1、HashMap也用到了哈希碼的算法,以便快速查找一個鍵,TreeMap則是對鍵按序存放,因此它有一些擴展的方法,比如 firstKey(),lastKey()等。
2、Hashtable:不允許空(null)鍵(key)或值(value),Hashtable的方法是Synchronize的,在多個線程訪問 Hashtable時,不需要自己為它的方法實現同步,而HashMap 就必須為之提供外同步。 Hashtable和HashMap采用的hash/rehash算法都大概一樣,所以性能不會有很大的差異。
3、HashMap和Hashtable的區別:HashMap是Hashtable(線程案例的)的輕量級實現(非線程安全的實現),他們都完成了Map接口。主要區別在于HashMap允許空(null)鍵(key)或值(value),非同步,由于非線程安全,效率上可能高于Hashtable。
Map總結:
是一種把鍵對象和值對象進行關聯的容器,Map有兩種比較常用的實現: HashTable、HashMap和TreeMap。
摘要: 1005:創建表失敗
1006:創建數據庫失敗
1007:數據庫已存在,創建數據庫失敗
1008:數據庫不存在,刪除數據庫失敗
1009:不能刪除數據庫文件導致刪除數據庫失敗
1010:不能刪除數據目錄導致刪除數據庫失敗
1011:刪除數據庫文件失敗
1012:不能讀取系統表中的記錄
1020:記錄已被其他用戶修改
1021:硬盤剩余空間不足,請加大硬盤可用空間...
閱讀全文
摘要: 序言
在擔任公司高管的幾年間,我面試過數以百計的各個層面的員工,其中最讓我感到遺憾的一個現象就是很多人有著非常好的素質,甚至有的還是名校的畢業生,因為不懂得去規劃自己的職業,在工作多年后,依然拿著微薄的薪水,為了一份好一點的工作而奔波。很多這樣的人,他們只要稍微修正一下自己的職業方向,就能夠在職業發展上走得更從容。
有一次一個大連理工大學的研究生,好像是學電子的...
閱讀全文
國外:
BJ Rolison (I.M.Testy) http://blogs.msdn.com/imtesty
BJ是微軟負責EE工作的Test Architecture,也是HWTSaM的作者。他的文章非常有條理,看起來也比較容易,其中的數據也非常豐富,是我喜歡的風格。
Alan Page http://blogs.msdn.com/alanpa/
Alan是微軟負責EE工作的Director,是HWTSaM的主要作者,他的博客是了解微軟測試非常好的一個窗口。最近幾年,他不限于測試技術的推廣,他更多的考慮是測試管理,以及測試氛圍/文化的形成,以及對于測試的影響。我很同意他的一句話“95%的UI自動化測試都是浪費時間”詳情。他的博客文章比較隨意,有時也不知道他在嘮叨些什么,但不時卻有很多精彩的觀點。
Google Test Blog http://googletesting.blogspot.com
這是Google官方的測試博客,信息量很少,除了每年一次的Google Automation Test Conference之外,文章較少。今年6月,James Whittaker離開微軟,加入Google后,才到這里增加不少好文章。
James Bach的博客 http://www.satisfice.com/blog/
James是一個軟件測試的資深人士,90年代曾在Apple和Boland公司???過測試管理工作,后來在其他一些公司負責測試流程和質量管理,2000年自己創辦了satisfice測試咨詢公司,提供軟件質量保證相關的咨詢和培訓. 他和Cem Kaner撰寫了很多Explorary Testing相關的文章和書籍,并且提出了Context-Driven-Testing,這些方法論很適合現在的Agile Testing的特點。
Adam Goucher的博客 http://adam.goucher.ca/
一個多產高質的測試寫作專家,基本上每個月都有10多篇關于測試的文章,有時候一天寫了多篇,真是非常佩服他的寫作能力。他的思想很有深度,對軟件測試各個方面都有全面的理解,他閱讀了幾乎所有新出的測試書籍,并且些了與其相關的評論。這些評論通常非常尖銳。比如說,HWTSaM的評論,他的評論就比較中肯。對James Whittalkes的 Exploratory Testing評論 卻是嗤之以鼻。
軟件測試雜文集:http://blogs.msdn.com/b/cheno/
文章轉自:http://www.cesoo.com/
一、寫在前面
剛開學,趁著有時間把設計模式重新整理一次。學好設計模式是走向架構的第一步,系統架構應該朝著可維護,可擴展,強壯性好的方向去發展。大學的最后一個學期了,時間不多了,3月初就要去騰訊實習了,還有畢設。加油 :)
二、常見的模式分類
|
創建模式
|
結構模式
|
行為模式
|
|
簡單工廠模式
|
適配器模式
|
不變模式
|
|
工廠方法模式
|
缺省適配模式
|
策略模式
|
|
抽象工廠模式
|
合成模式
|
模版方法模式
|
|
單例模式
|
裝飾模式
|
觀察者模式
|
|
多例模式
|
代理模式
|
迭代子模式
|
|
建造模式
|
享元模式
|
責任鏈模式
|
|
原始模型模式
|
門面模式
|
命令模式
|
|
橋梁模式
|
備忘錄模式
|
|
|
狀態模式
|
|
|
訪問者模式
|
|
|
解釋器模式
|
|
|
調停者模式
|
三、主要模式的定義和描述
以下內容來自《head first 設計模式》一書
|
模式
|
定義
|
描述
|
|
裝飾者
|
動態地將責任附加到對象上。若要擴展功能,裝飾者提供了比繼承更有彈性的替代方案
|
包裝一個對象,以提供新的行為
|
|
狀態
|
允許對象在內部狀態改變時改變它的行為,對象看起來好像修改了它的類
|
封裝了基本狀態的行為,并使用委托在行為之間切換
|
|
迭代器
|
提供一種方法順序訪問一個聚合對象中的各個元素,而又不暴露其內部的表示
|
在對象的集合之中游走,而不暴露集合的實現
|
|
外觀(門面)
|
提供一個統一的接口,用來訪問子系統中的一群接口。外觀定義了一個高層接口,讓子系統更多容易使用
|
簡化一群類的接口
|
|
策略
|
定義算法族,分別封裝起來,讓它們之間可以互相替換,此模式讓算法的變化獨立于使用算法的客戶
|
封裝可以互換的行為,并使用委托來決定使用那一種
|
|
代理
|
為另一個對象提供一個替身或點位符以訪問這個對象
|
包裝對象,以控制對此對象的訪問
|
|
工廠方法
|
定義了一個創建對象的接口,但由子類決定要實例化的類是哪一個。工廠方法讓類把實例化推遲到子類
|
由子類決定要創建是具體類是哪一個
|
|
抽象工廠
|
提供一個接口,用于創建相關或依賴對象的家族,而不需要明確指定具體類
|
允許客戶創建對象的家族,而無需指定他們的具體類
|
|
適配器
|
將一個類的接口,轉換成客戶期望另一個接口。適配器讓原來不兼容的類可以合作無間
|
封裝對象,并提供不同的接口
|
|
觀察者
|
在對象之間定義一對多的依賴,這樣一來,當一個對象改變時,依賴它的對象都會收到通知并自動更新
|
讓對象能夠在狀態改變時被通知
|
|
模板方法
|
在一個方法中定義一個算法的骨架,而將一些步驟延遲到子類中。模板方法使得子類可以在不改變算法結構的情況下,重新定義算法中的某些步驟
|
由子類決定如何實現一個算法中的步驟
|
|
組合
|
允許你將對象組成樹結構來表現“整體/部分”的層次結構。組合能讓客戶以一致的方式處理個別對象和對象組合
|
客戶用一致的方式處理對象集合和單個對象
|
|
單件(單體)
|
確保一個類只有一個實例,并提供全局訪問點
|
確保只有一個對象被創建
|
|
命令
|
將請求封裝成對象,這可以讓你使用不同的請求、隊列,或者日志請求來參數化其它對象。命令模式也可以支持撤銷操作
|
封裝請求為對象
|
四、參考資料
IBM社區設計模式方面資料: http://www.ibm.com/developerworks/cn/java/design/
常見OO原則:http://m.tkk7.com/jicheng687/archive/2011/02/13/344174.html
--END--
今天無意中看到InfoQ(http://www.infoq.com/cn/architect)這個網站,里面的內容很不錯,介紹的內容算是國內最先進的的,有興趣的朋友可以看看
一、觀察者模式定義
觀察者模式(Observer): 在對象之間定義一對多的依賴,這樣一來,當一個對象改變狀態,依賴它的對象都會收到通知,并自動更新
二、在JUnit中的體現
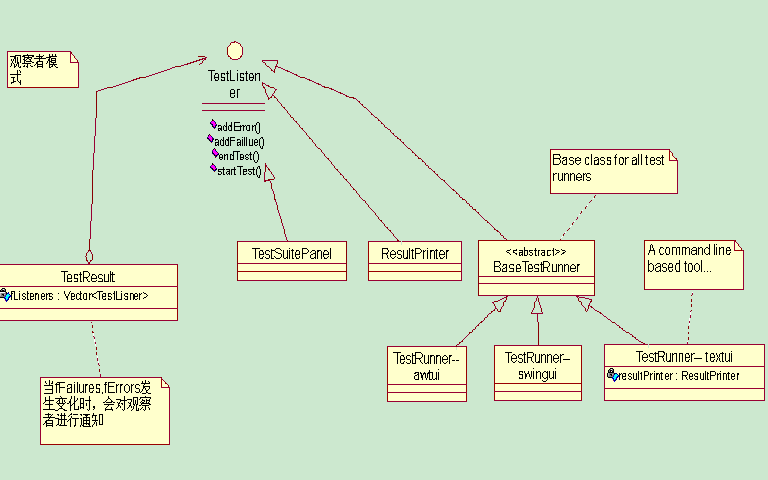
TestResult中用Vector保存各個監聽器(文本界面、圖形界面和Eclipse插件)
protected Vector fListeners; //監聽器集合
在測試運行階段,如果出現Error 或者 Failure,TestResult 則會通知各個監聽器

 public synchronized void addFailure(Test test, AssertionFailedError t)
public synchronized void addFailure(Test test, AssertionFailedError t)  {
{
 fFailures.addElement(new TestFailure(test, t));
fFailures.addElement(new TestFailure(test, t));
//觀察者模式在這里體現出來了,當fFailures有變化時,馬上通知其它Listeners

 for (Enumeration e= cloneListeners().elements(); e.hasMoreElements(); ) {
for (Enumeration e= cloneListeners().elements(); e.hasMoreElements(); ) {
((TestListener)e.nextElement()).addFailure(test, t);
 }
}
 }
}
一、在單元測試領域里,JUnit可以說是王者,它不但精致,而且使用方便。最后有些時間,把JUnit源碼讀讀,順便復習下設計模式 :)
二、參考文章
在深入看代碼之前,先看下面的文章,對JUnit有一個基本的了解后,看代碼會更有目的性。
JUnit官方網站:http://www.junit.org/
分析 JUnit 框架源代碼: http://www.ibm.com/developerworks/cn/java/j-lo-junit-src/
JUnit A cook's tour: http://junit.sourceforge.net/doc/cookstour/cookstour.htm
三、核心架構
我分析的源碼的版本是JUnit 3.8.2,這個版本相對簡略,把核心思想表現出來了,沒有4.X版本那么多附加的功能
JUnit是一個模式密集型的框架,主要用組合模式、模樣方法、觀察者模式、參數收集方法、命令模式、裝飾者模式和適配器模式。其中核心是 前三種
核心類之間的關系
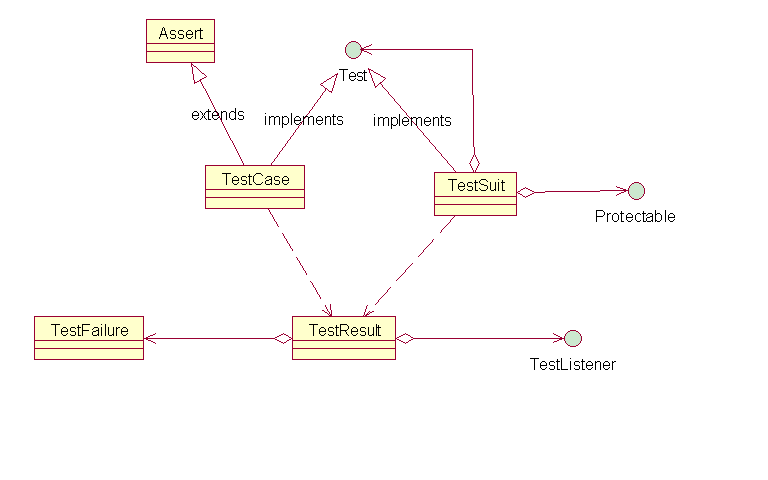
Test、TestCase和TestSuit構成了測試框架的基礎,它們用composite模式組合在一起,使得客戶端可以將對象的集合以及個別的對象(TestCase)一視同仁.TestRusult用來保存測試結果,和TestListner組成observer模式,支持文本界面、圖形界面和 Eclipse 集成組件三種監聽器
和JUnit A cook's tour中提到的模式圖很相似

類與類之間的關系在此就不作解釋了,可以看看參考文章。有興趣的朋友,歡迎一起討論 :)
封裝變化
多用組合,少用繼承
針對接口編程,不針對實現編程
為交互對象之間的松耦合設計而努力
類應該對擴展開放,對修改關閉
只和朋友交談
別找我,我會找你
類應該只有一個改變的理由
38、只針對不正常的條件使用異常
異常只應該被用于不正常的條件,它們永遠不應該被用于不正常的條件
設計API啟示:一個良好的API不應該強迫它的客戶為了正常的控制流而使用異常。對于邊界的判斷常用的有兩種方法:狀態測試方法和可被識別的返回值
40、對于可以恢復的條件使用被檢查的異常,對于程序錯誤使用運行時異常
Thowable(可拋出異常)有三種結構:被檢查的異常(checked exception)、運行時異常(run-time exception)和錯誤(error)
如果期望調用者能夠恢復,那么,對于這樣的條件應該使用被檢查的異常
運行時異常和錯誤,不需要也不應該是被捕獲的拋出物
用運行時異常來指明程序錯誤
對于被檢查的異常,提供一些輔助方法是非常重要的,通過這些方法,調用者可以獲得一些有助于恢復的信息
41、避免不必要地使用被檢查的異常
42、盡量使用標準異常
43、拋出的異常要適合于相應的抽象
高層的實現應該捕獲低層的異常,同時導出一個可以按照高層抽象進行解釋的---異常轉譯
低層的異常對于調試該異常被撥出的情形非常有幫助的話,可以使用異常鏈接。即低層的異常被高層的異常保存起來,并且高層的異常提供一個公有的訪問方法來獲得低層異常
44、每個異常的拋出都必須有文檔
45、在細節消息中包含失敗--捕獲信息
為了捕獲失敗,一個異常的的字符串表示應該包含所有“對異常有貢獻”的參數和域的值
在異常構造函數中以參數形式引入這些信息
46、努力使失敗保持原子性
一個失敗方法調用應該使用對象保持“它在被調用之前的狀態” ---failure atomic
幾種解決方法:在執行操作之前檢查參數的有效性
調整計算機過程,使得任何可能會失敗的計算部分發生在對象狀態被修改之前
編寫一段恢復代碼
在對象上臨時都拷貝一份,當操作完成之后把臨時拷貝中的結果復制給原來的對象。如:Collections.sort
47、不要忽略異常
寫上try catch塊