本文為原創,如需轉載,請注明作者和出處,謝謝!
一、Java編碼是怎么回事?
對于使用中文以及其他非拉丁語系語言的開發人員來說,經常會遇到字符集編碼問題。對于Java語言來說,在其內部使用的是UCS2編碼(2個字節的Unicode編碼)。這種編碼并不屬于某個語系的語言編碼,它實際上是一種編碼格式的世界語。在這個世界上所有可以在計算機中使用的語言都有對應的UCS2編碼。
正是因為Java采用了UCS2,因此,在Java中可以使用世界上任何國家的語言來為變量名、方法名、類起名,如下面代碼如下:
class 中國
{
public String 雄起()
{
return "中國雄起";
}
}
中國 祖國 = new 中國();
System.out.println(祖國.雄起());
哈哈,是不是有點象“中文編程”。實際上,也可以使用其他的語言來編程,如下面用韓文和日文來定義個類:
class ???
{
public void スーパーマン() {  }
}
}
實際上,由于Java內部使用的是UCS2編碼格式,因為,Java并不關心所使用的是哪種語言,而只要這種語言在UCS2中有定義就可以。
在UCS2編碼中為不同國家的語言進行了分頁,這個分頁也叫“代碼頁”或“編碼頁”。中文根據包含中文字符的多少,分了很多代碼頁,如cp935、cp936等,然而,這些都是在UCS2中的代碼頁名,而對于操作系統來說,如微軟的windows,一開始的中文編碼為GB2312,后來擴展成了GBK。其實GBK和cp936是完全等效的,用它們哪個都行。
二、Java編碼轉換
上面說了這么多,在這一部分我們做一些編碼轉換,看看會發生什么事情。
先定義一個字符串變量:
String gbk = "中國"; // “中國”在Java內部是以UCS2格式保存的
用下面的語言輸出一定會輸出中文:
System.out.println(gbk);
實現上,當我們從IDE輸入“中國”時,用的是java源代碼文件保存的格式,一般是GBK,有時也可是utf-8,而在Java編譯程序時,會不由分說地將所有的編碼格式轉換成utf-8編碼,讀者可以用UltraEdit或其他的二進制編輯器打開上面的“中國.class”,看看所生成的二進制是否有utf-8的編碼(utf-8和ucs2之間的轉換非常容易,因為utf-8和ucs2之間是用公式進行轉換的,而不是到代碼頁去查,這就相當于將二進制轉成16進制一樣,4個字節一組)。如“中國”的utf-8編碼按著GBK解析就是“涓 浗”。如下圖所示。
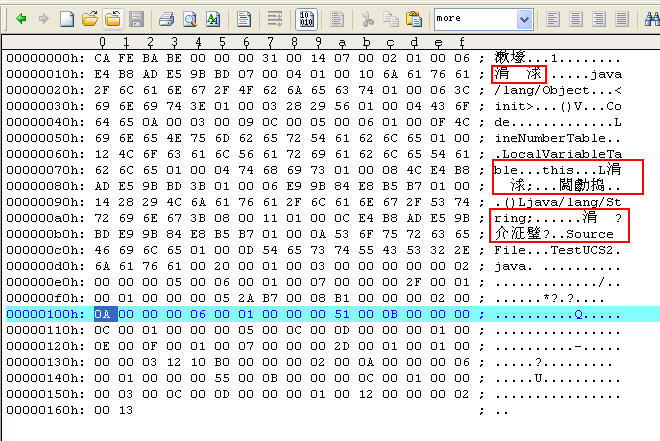
如果使用下面的語言可以獲得“中國”的utf-8字節,結果是6(一個漢字由3個字節組成)
System.out.println(gbk.getBytes("utf-8").length);
下面的代碼將輸出“涓 浗”。
System.out.println(new String(gbk.getBytes("utf-8"),
"gbk"));
由于將“中國“的utf-8編碼格式按著gbk解析,所以會出現亂碼。
如果要返回中文的UCS2編碼,可以使用下面的代碼:
System.out.println(gbk.getBytes("unicode")[2]);
System.out.println(gbk.getBytes("unicode")[3]);
前兩個字節是標識位,要從第3個字節開始。還有就是其他的語言使用的編碼的字節順序可能不同,如在C#中可以使用下面的代碼獲得“中國“的UCS2編碼:
String s = "中";
MessageBox.Show(ASCIIEncoding.Unicode.GetBytes(s)[0].ToString());
MessageBox.Show(ASCIIEncoding.Unicode.GetBytes(s)[1].ToString());
使用上面的java代碼獲得的“中“的16進制UCS2編碼為4E2D,而使用C#獲得的相應的ucs2編碼為2D4E,這只是C#和Java編碼內部使用的問題,并沒有什么關系。但在C#和Java互操作時要注意這一點。
如果使用下面的java編碼將獲得16進制的“中”的GBK編碼:
System.out.println(Integer.toHexString(0xff
& xyz.getBytes("gbk")[0]));
System.out.println(Integer.toHexString(0xff
& xyz.getBytes("gbk")[1]));
“中”的ucs2編碼為2D4E,GBK編碼為D6D0
讀者可訪問如下的url自行查驗:
http://unicode.org/Public/MAPPINGS/VENDORS/MICSFT/WINDOWS/CP936.TXT
當然,感興趣的讀者也可以試試其他語言的編碼,如“人類”的韓語是“???”,如下面的代碼將輸出“???”的cp949和ucs2編碼,其中cp949是韓語的代碼頁。
String korean = "???"; // 共三個韓文字符,我們只測試第一個“?”
System.out.println(Integer.toHexString(0xff & korean.getBytes("unicode")[2]));
System.out.println(Integer.toHexString(0xff & korean.getBytes("unicode")[3]));
System.out.println(Integer.toHexString(0xff & korean.getBytes("Cp949")[0]));
System.out.println(Integer.toHexString(0xff & korean.getBytes("Cp949")[1]));
上面代碼的輸出結果如下:
c7
78
c0
ce
也就是說“?”的ucs2編碼為C778,cp949的編碼為C0CE,要注意的是,在cp949中,ucs2編碼也有C0CE,不要弄混了。讀者可以訪問下面的url來驗證:
http://unicode.org/Public/MAPPINGS/VENDORS/MICSFT/WINDOWS/CP949.TXT
Java支持的編碼格式
三、屬性文件
Java中的屬性文件只支持iso-8859-1編碼格式,因此,要想在屬性文件中保存中文,就必須使用UCS2編碼格式("uxxxx),因此,出現了很多將這種編碼轉換成可視編碼和工具,如Eclipse中的一些屬性文件編輯插件。
實際上,"uxxxx編碼格式在java和C#中都可以使用,如下面的語句所示:
String name= ""u7528"u6237"u540d"u4e0d"u80fd"u4e3a"u7a7a"
;
System.out.println(name);
上面代碼將輸出“用戶名不能為空”的信息。將"uxxxx格式顯示成中文非常簡單,那么如何將中文還原成"uxxxxx格式呢?下面的代碼完成了這個工作:
String ss = "用戶名不能為空";
byte[] uncode = ss.getBytes("Unicode");
int x = 0xff;
String result ="";
for(int i= 2; i < uncode.length; i++)
{
if(i % 2 == 0) result += "\\u";
String abc = Integer.toHexString(x & uncode[i]);
result += abc.format("%2s", abc).replaceAll(" ", "0");
}
System.out.println(result);
上面的代碼將輸出如下結果:
\u7528\u6237\u540d\u4e0d\u80fd\u4e3a\u7a7a
好了,現在可以利用這個技術來實現一個屬性文件編輯器了。
四、Web中的編碼問題
大家碰到最多的編碼問題就是在Web應用中。先讓我們看看下面的程序:
<!-- main.jsp -->
<%@ page language="java" pageEncoding="utf-8"%>
<html>
<head>
</head>
<body>
<form action="servlet/MyPost" method="post">
<input type="text" name="user" />
<p/>
<input type="submit" value="提交"/>
</form>
</body>
</html>
下面是個Servlet:
package servlet;
import java.io.IOException;
import java.io.PrintWriter;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
public class MyPost extends HttpServlet
{
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException
{
String user = request.getParameter("user");
System.out.println(user);
}
}
如果中main.jsp中輸入中文后,向MyPost提交,在控制臺中會輸出“ä¸å?½”,一看就是亂碼。如果將IE的當前編碼設成其他的,如由utf-8改為gbk,仍然會出現亂碼,只是亂得不一樣而已。這是因為客戶端提交數據時是根據瀏覽器當前的編碼格式來提交的,如瀏覽器當前為gbk編碼,就以gbk編碼格式來提交。 這本身是不會出現亂碼的,問題就出在Web服務器接收數據的時候,HttpServletRequest在將客戶端傳來的數據轉成ucs2碼上出了問題。在默認情況下,是按著iso-8859-1編碼格式來轉的,而這種編碼格式并不支持中文,所以也就無法正常顯示中文了,解決這個問題的方法是用和客戶端瀏覽器當前編碼格式一致的編碼來轉換,如果是utf-8,則在doPost方法中應該用以下的語句來處理:
request.setCharacterEncoding("utf-8");
為了對每一個Servlet都起作用,可以將上面的語句加到filter里。
另外,我們一般使用象MyEclipse一樣的IDE來編寫jsp文件,這樣的工具會根據pageEncoding屬性將jsp文件保存成相應的編碼格式,但如果要使用象記事本一樣的簡單的編輯器來編寫jsp文件,如果pageEncoding是utf-8,而在默認時,記事本會將文件保存成iso-8859-1(ascii)格式,但在myeclipse里,如果文件中有中文,它是不允許我們保存成不支持中文的編碼格式的,但記事本并不認識jsp,因此,這時在ie中就無法正確顯示出中文了。除非用記事本將其保存在utf-8格式。如下圖:

新浪微博:http://t.sina.com.cn/androidguy 昵稱:李寧_Lining