附注說明:上圖中刪完尾節(jié)點之后,新鏈表的尾節(jié)點下標(biāo)應(yīng)為n-1。不過由于作圖時只做了尾節(jié)點,故用圖中的n2節(jié)點代替。
刪除尾節(jié)點的代碼如下:
- if(p->next == NULL)
- {
- q->next = NULL;
- }
③. 刪除非頭尾節(jié)點,如圖

刪除非頭尾節(jié)點的代碼如下:
4.查詢節(jié)點:在鏈表中找到你想要找的那個節(jié)點。此操作是根據(jù)數(shù)據(jù)域的內(nèi)容來完成的。查詢只能從表頭開始,當(dāng)要找的節(jié)點的數(shù)據(jù)域內(nèi)容與當(dāng)前不相符時,只需讓當(dāng)前節(jié)點指向下一結(jié)點即可,如此這樣,直到找到那個節(jié)點。
附注:此操作就不在這用圖和代碼說明了。
5.修改節(jié)點:修改某個節(jié)點數(shù)據(jù)域的內(nèi)容。首先查詢到這個節(jié)點,然后對這個節(jié)點數(shù)據(jù)域的內(nèi)容進(jìn)行修改。
附注:同上
ok,鏈表的幾種操作介紹完了,接下來我們來總結(jié)一下鏈表的幾個特點。
鏈?zhǔn)酱鎯Y(jié)構(gòu)的特點:
1.易插入,易刪除。不用移動節(jié)點,只需改變節(jié)點中指針的指向。
2.查詢速度慢:每進(jìn)行一次查詢,都要從表頭開始,速度慢,效率低。
擴(kuò)展閱讀
鏈表:http://public.whut.edu.cn/comptsci/web/data/512.htm
第二節(jié) 樹形存儲結(jié)構(gòu)
所謂樹形存儲結(jié)構(gòu),就是數(shù)據(jù)元素與元素之間存在著一對多關(guān)系的數(shù)據(jù)結(jié)構(gòu)。在樹形存儲結(jié)構(gòu)中,樹的根節(jié)點沒有前驅(qū)結(jié)點,其余的每個節(jié)點有且只有一個前驅(qū)結(jié)點,除葉子結(jié)點沒有后續(xù)節(jié)點外,其他節(jié)點的后續(xù)節(jié)點可以有一個或者多個。
如下圖就是一棵簡單的樹形結(jié)構(gòu):
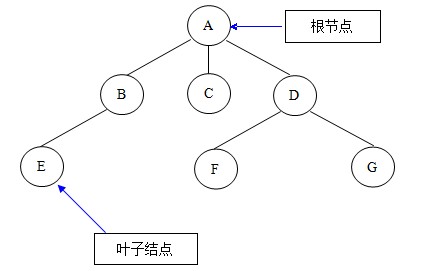
說到樹形結(jié)構(gòu),我們最先想到的就是二叉樹。我們常常利用二叉樹這種結(jié)構(gòu)來解決一些算法方面的問題,比如堆排序、二分檢索等。所以在樹形結(jié)構(gòu)這節(jié)我只重點詳解二叉樹結(jié)構(gòu)。那么二叉樹到底是怎樣的呢?如下圖就是一顆簡單的二叉樹:
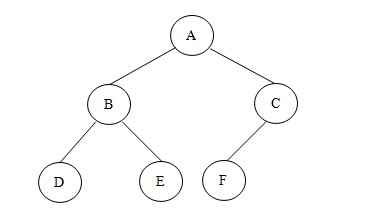
附注:有關(guān)樹的概念以及一些性質(zhì)在此不做解釋,有意者請到百科一覽。
二叉樹的類型描述如下:
- typedef struct tree
- {
- char data;
- struct tree * lchild, * rchild;
- }tree;
二叉樹的操作:創(chuàng)建節(jié)二叉樹,創(chuàng)建節(jié)點,遍歷二叉樹,求二叉樹的深度。
1.創(chuàng)建二叉樹:聲明一棵樹并為其申請存儲空間。
- struct tree * T = NULL;
- T = (struct tree *)malloc(sizeof(struct tree));
2.創(chuàng)建節(jié)點:除根節(jié)點之外,二叉樹的節(jié)點有左右節(jié)點之分。

創(chuàng)建節(jié)點的代碼如下:
- struct tree * createTree()
- {
- char NodeData;
- scanf(" %c", &NodeData);
- if(NodeData == '#')
- return NULL;
- else
- {
- struct tree * T = NULL;
- T = (struct tree *)malloc(sizeof(struct tree));
- T->data = NodeData;
- T->lchild = createTree();
- T->rchild = createTree();
- return T;
- }
- }
3.遍歷二叉樹:分為先序遍歷、中序遍歷、后續(xù)遍歷。
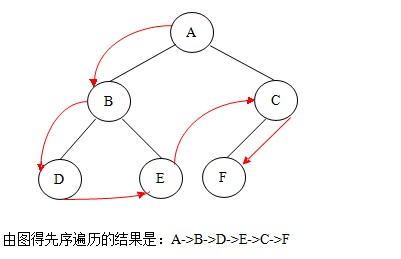
①.先序遍歷:若二叉樹非空,則依次執(zhí)行如下操作:
(1) 訪問根結(jié)點;
(2) 遍歷左子樹;
(3) 遍歷右子樹。
如圖:
先序遍歷的代碼如下:
- void PreTravser(struct tree * T)
- {
- if(T == NULL)
- return;
- else
- {
- printf("%c",T->data);
- PreTravser(T->lchild);
- PreTravser(T->rchild);
- }
- }
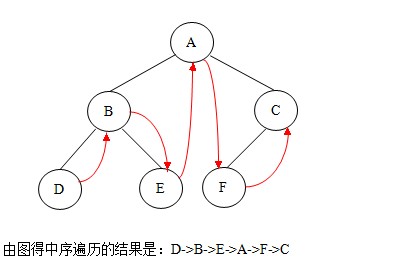
②.中序遍歷:若二叉樹非空,則依次執(zhí)行如下操作:
(1)遍歷左子樹;
(2)訪問根結(jié)點;
(3)遍歷右子樹。
如圖:
中序遍歷的代碼如下:
- void MidTravser(struct tree * T)
- {
- if(!T)
- {
- return;
- }
- else
- {
- MidTravser(T->lchild);
- printf("%c",T->data);
- MidTravser(T->rchild);
- }
- }
③.后續(xù)遍歷:若二叉樹非空,則依次執(zhí)行如下操作:
(1)遍歷左子樹;
(2)遍歷右子樹;
(3)訪問根結(jié)點。
如圖:

后續(xù)遍歷的代碼如下:
- void PostTravser(struct tree * T)
- {
- if(!T)
- return;
- else
- {
- PostTravser(T->lchild);
- PostTravser(T->rchild);
- printf("%c->",T->data);
- }
- }
4.求二叉樹的深度:樹中所有結(jié)點層次的最大值,也稱高度。
二叉樹的深度表示如下圖:
求二叉樹深度的代碼如下:
- int treeDeepth(struct tree * T)
- {
- int i, j;
- if(!T)
- return 0;
- else
- {
- if(T->lchild)
- i = treeDeepth(T->lchild);
- else
- i = 0;
-
- if(T->rchild)
- j = treeDeepth(T->rchild);
- else
- j = 0;
- }
- return i > j? i+1:j+1;
- }
好了,二叉樹的幾種操作介紹完了。
拓展閱讀
二叉樹:http://student.zjzk.cn/course_ware/data_structure/web/DOWNLOAD/%CA%FD%BE%DD%BD%E1%B9%B9%D3%EB%CB%E3%B7%A82.htm
赫夫曼編碼:http://blog.csdn.net/fengchaokobe/article/details/6969217
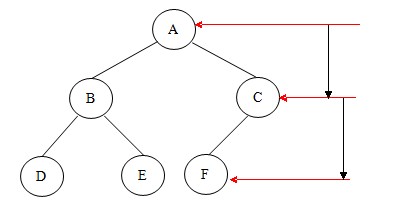
第三節(jié) 圖型存儲結(jié)構(gòu)
所謂圖形結(jié)構(gòu),就是數(shù)據(jù)元素與元素之間的關(guān)系是任意的,任意兩個元素之間均可相關(guān),即每個節(jié)點可能有多個前驅(qū)結(jié)點和多個后繼結(jié)點,因此圖形結(jié)構(gòu)的存儲一般是采用鏈接的方式。圖分為有向圖和無向圖兩種結(jié)構(gòu),如下圖
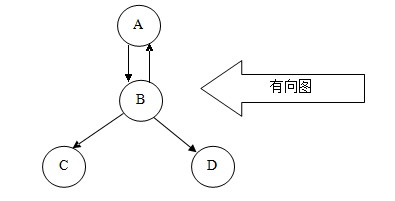
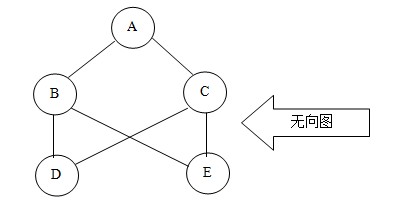
通過圖,我們可以判斷兩個點之間是不是具有連通性;通過圖,我們還可以計算兩個點之間的最小距離是多少;通過圖,我們還可以根據(jù)不同的要求,尋找不同的合適路徑。
1.圖的結(jié)構(gòu)有好幾種,在實際應(yīng)用中需根據(jù)具體的情況選擇合適的結(jié)點結(jié)構(gòu)和表結(jié)構(gòu)。常用的有數(shù)組結(jié)構(gòu)、鄰接表。
①.數(shù)組結(jié)構(gòu)
數(shù)組結(jié)構(gòu)的類型描述如下:
- typedef char VertexType;
- typedef int EdgeType;
- #define maxvex 100 /***頂點的最大個數(shù)***/
-
- typedef struct
- {
- VertexType vexs[maxvex];
- EdgeType arc[maxvex][maxvex];
- }Mgraph;
附注:當(dāng)前圖為無向圖時,圖中某兩個頂點VA和VB構(gòu)成一條邊時,其權(quán)值可表示為EdgeType arc[VA][VB];當(dāng)前圖為有向圖時,圖中某兩個頂點VA和VB構(gòu)成一條邊時,并且是由VA指向VB,其權(quán)值可表示為EdgeType arc[VA][VB],如果是由VB指向VA,其權(quán)值可表示為EdgeType arc[VB][VA]。
②.鄰接表
鄰接表的類型描述如下:
- typedef char VertexType;
- typedef int EdgeType;
-
- typedef struct EdgeNode
- {
- int adjvex;
- EdgeType weight;
- struct EdgeNode *next;
- }EdgeNode;
-
- typedef struct VertexNode
- {
- VertexType data;
- EdgeNode * firstedge;
- }VertexNode,AdjList[MAXVEX];
-
- typedef struct
- {
- AdjList adjList;
- int numVertexes,numEdges;
- }GraphAdjList;
2.圖的遍歷:從圖中的某一節(jié)點出發(fā)訪問圖中的其余節(jié)點,且使每一節(jié)點僅被訪問一次。圖的遍歷算法是求解圖的連通性問題、拓?fù)渑判蚝颓舐窂降人惴ǖ幕A(chǔ)。圖的遍歷分為深度優(yōu)先遍歷和廣度優(yōu)先遍歷,且它們對無向圖和有向圖均適用。
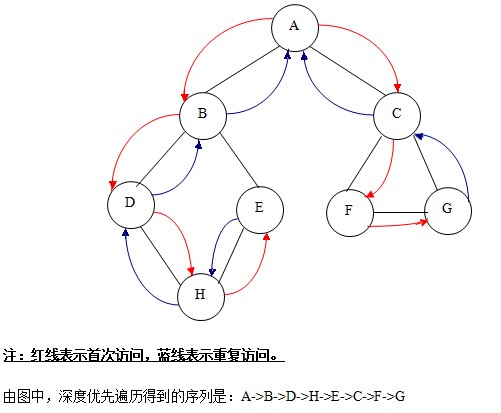
①. 深度優(yōu)先遍歷
定義說明:假設(shè)給定圖G的初態(tài)是所有頂點均未曾訪問過。在G中任選一頂點V為初始出發(fā)點,則深度優(yōu)先遍歷可定義如下:首先訪問出發(fā)點V,并將其標(biāo)記為已訪問過;然后依次從V出發(fā)搜索v的每個鄰接點W。若W未曾訪問過,則以W為新的出發(fā)點繼續(xù)進(jìn)行深度優(yōu)先遍歷,直至圖中所有和源點V有路徑相通的頂點(亦稱為從源點可達(dá)的頂點)均已被訪問為止。若此時圖中仍有未訪問的頂點,則另選一個尚未訪問的頂點作為新的源點重復(fù)上述過程,直至圖中所有頂點均已被訪問為止。
深度遍歷過程如下圖:
②. 廣度優(yōu)先遍歷
定義說明:假設(shè)從圖中某頂點V出發(fā),在訪問了V之后一次訪問V的各個未曾訪問過的鄰接點,然后分別從這些鄰接點出發(fā)依次訪問它們的鄰接點,并使“先被訪問的頂點的鄰接點”先于“后被訪問的頂點的鄰接點”被訪問,直至圖中所有已被訪問的頂點的鄰接點都被訪問到。若此時圖中還有頂點未被訪問,則另選圖中一個未曾被訪問的頂點作為起始點,重復(fù)上述過程,直至圖中所有頂點都被訪問到為止。換句話說,廣度優(yōu)先遍歷圖的過程是以V為起點,由近至遠(yuǎn),依次訪問和V有路徑相同且路徑長度為1,2,...的頂點。
廣度遍歷過程如下圖: