去年底做了一個Android應用的項目,代碼總計2萬多行,測試周期4個月,項目雖小,但涉及到手機終端適配、網絡環境兼容等多個方面。項目階段一結束后,我們簡單總結了一下測試方法有效性的問題。發出來與大家共享。
這個Android應用的主要功能很簡單,附加功能較多,基本都屬于錦上添花類。測試的實際情況如下:
1、資源投入:持續時長4個月,人力6人+,測試機型30款+
2、測試執行:23輪功能測試,7輪系統測試,8輪健全測試,3輪機型兼容測試,3輪性能測試,1輪MTBF測試,1輪PD/UI驗證測試。
但是這其中有很多不足之處,較明顯的如下:
1、前期功能測試和健全測試一天一輪,頻度太快且測試費時,效果不好。
2、初期的測試用例設計全面,但未精確定義編寫粒度,描述過程過細,后期因需求變更導致維護成本較高。
3、因項目流程和過程控制影響,無法明確劃分測試階段,且初期沒有找到最佳敏捷測試方法,測試流程冗余僵化,導致大量重復性的工作,靈活性偏低。
在測試進程中我們已發現測試策略的問題,并及時調整,在階段二開始使用新策略——使用兩階段測試模型:
1、階段一<自由測試>:按照探索性測試(Exploratory Testing)模式,布置有針對性有重點的自由測試,以“把軟件使用壞掉”為目的,盡可能多發現bug。
2、階段二<覆蓋測試>:執行各項測試用例,以“全面測試”為目的
具體的時間安排如下:
1、先期產品開發階段,即Alpha release之前,做功能測試、健全測試、缺陷驗證+自由測試。
2、項目中期,Alpha ~ Beta之間,執行全面的系統測試、兼容性測試、性能測試,并開展自動化腳本開發、環境搭建等工作。
3、Beta release之后,在產品發布前的2~3周,就開始確定穩定版本Release Candidate,在此版本基礎上做最后一輪全面測試、重點子模塊的健全測試、缺陷主導的ET等,完成最終報告并交由項目組領導、QA審核發布。
本次測試有效性總結我們引入了兩個質量來衡量:軟件質量指標和測試過程質量指標。
軟件質量指標包括:
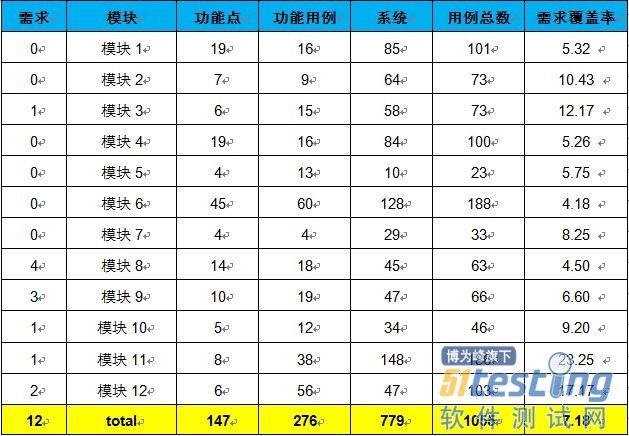
(一)需求功能點覆蓋率:
計算測試用例總數之和除以與之一一對應的功能點數之和,主要查看是否有功能點遺漏測試的情況。用例覆蓋需求矩陣,一個需求對應多個功能點。
需求覆蓋率=∑測試用例數(個)/∑功能點(個)=1055/147=7.18
(二)用例執行覆蓋率:
計算測試用例執行總數除以與之一一對應的測試數之和,主要查看是否有測試用例執行遺漏或有效的情況。
用例執行覆蓋率=∑執行的測試用例個數(個)/∑測試用例個數(個)*100%
功能測試276條,系統測試779條,用例執行覆蓋率達到99%。
測試過程質量指標包括:
(一)缺陷探測率:
計算內部發現的缺陷數除以內部發現的缺陷數與用戶發現的缺陷數之和,主要查看內部發現缺陷的能力。說明:缺陷探測率越高,即內部發現的bug數越多,發布后客戶發現的bug數就越少,質量成本就越低。
缺陷探測率=內部發現的缺陷數(個)/(內部發現的缺陷數(個)+用戶發現的缺陷數(個))*100%
缺陷數=636(有效),用戶發現缺陷數=1(當前)
缺陷探測率=636/637=99.84%
(二)有效缺陷率:
計算被開發人員確認的BUG數總和除于本人上報BUG的總和,可用于查看測試人員的個人測試質量,也可用于查看整個測試組的測試質量。
無效BUG狀態包括:問題重復、不是問題、不可復現狀態。這項指標用于考察測試人員發現的、被確認為缺陷的缺陷數高低或者百分比,數和比率越高測試質量越高。
注意:由于系統框架根本性的、初始化參數設置錯誤引發的、錯誤數據、錯誤環境等而開發人員因無法修正、可以通過改變環境而無需修改程序、重新導入數據、再次發布而解決的BUG為有效BUG
有效缺陷率=測試人員發現的有效缺陷數(個)/測試人員發現的總缺陷數(個)*100%=636/689=92.31%
(三)用例執行效率:
計算測試人員執行的用例數除以執行測試的時間,主要查看測試人員執行測試的效率
說明:此指標的統計需要有一定的前提條件:用例的執行步驟相對來說分布較均勻,執行時間在一個較長的時間段內
用例執行效率=∑測試人員執行的用例數(個)/∑執行用例的時間(小時)
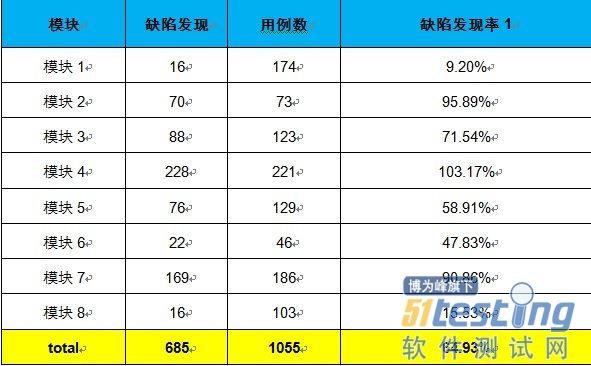
(四)缺陷發現率:
計算測試人員各自發現的缺陷數總和除于各自所花費的測試時間總和。
缺陷發現率=∑提交缺陷數(個)/∑執行測試的有效時間(小時)
以第18輪功能測試為例:
用例執行效率=10.17
缺陷發現率=36.67%
(五)缺陷覆蓋率:
計算缺陷與測試用例的比率,用來衡量測試用例覆蓋缺陷的能力。
缺陷覆蓋率=∑缺陷個數/∑測試用例條數
版權聲明:本文出自 cmriqa 的51Testing軟件測試博客:http://www.51testing.com/?489136
原創作品,轉載時請務必以超鏈接形式標明本文原始出處、作者信息和本聲明,否則將追究法律責任。