
與網絡相關的文件:
1) /etc/sysconfig/network 設置主機名稱及能否啟動Network
2) /etc/sysconfig/network-scripts/ifcfg-eth0 設置網卡參數的文件
3) /etc/modprobe.conf 開機時用來設置加載內核模塊的文件
4) /etc/resolv.conf 設置DNS IP(解析服務器)的文件
5) /etc/hosts 記錄計算機IP對應的主機名稱或主機別名
6) /etc/protocols 定義IP數據包協議的相關數據,包括ICMP、TCP方面的數據包協議的定義等
與網絡相關的啟動指令:
1)/etc/init.d/network restart 可以重啟整個網絡的參數
2)ifup eth0(ifdown eth0) 啟動或是關閉某個網絡接口,可以通過簡單的script來處理,這兩個script會主動到/etc/sysconfig/network-scripts/目錄下
·ifconfig 查詢、設置網卡與IP網段等相關參數
·ifup/ifdown 啟動/關閉網絡接口
配置IP的三種方法:
1、使用命令設置:
只是暫時修改網絡接口,立即生效,但不永久有效
#ifconfig ethX ip/netmask
# ifconfig eth0 192.168.100.1 設置eth0的IP
# ifconfig eth0 192.168.100.1 netmask 255.255.255.0 > mtu 8000 設置網絡接口值,同時設置MTU的值
2、 圖形界面設置:
system-config-network-gui
system-config-network-tui
輸入setup命令,進入圖形界面(配置設備IP等相關屬性信息、system-config中的服務集中在這一面板中),有時進入圖形設置網絡接口的界面時會出現亂碼,這時的解決方法是:退出此圖形界面,輸入當命令“export LANG=en”,再進入圖形界面,亂碼便會得到改善。
進入圖形界面,選擇“Network configuration”
修改后網絡接口之后,“Ok”、“Save”、“Save&Quit”、“Quit”退出,網絡接口修改完成。網絡接口不會立即生效,一旦生效,便會永久有效,讓IP生效的解決方法是:
1. #ifdown eth1 && ifup eth1 先禁用,再啟用
2. #service network restart 網絡服務重啟
3. #/etc/init.d/network restart 也可以重啟網絡接口
3、直接編輯配置文件:
#vim /etc/sysconfig/network-scripts/ifcfg-ethX
修改網絡接口的配置文件,配置文件中的常用的屬性有:
DEVICE=ethX 設備名
BOOTPROTO=(none | static(手動指定地址) | dhcp(動態獲取) | bootp)
ONBOOT={yes | no} 系統啟動時,網絡設備是否被激活
HWADDR= 物理地址,不可隨便改動
IPADDR= IP地址,必須
NETMASK= 子網掩碼,必須
TYPE=Ethernet 默認的,一般不要改,此項可以不存在
常用屬性還有:
GATEWAY= 網關
USERCTL={yes | no} 是否允許普通用戶啟用和禁用網絡設備
PEERDNS={yes | no} 若使用dhcp獲取地址,服務器分配一個IP地址,是否修改服務器DNS的默認指向(默認值為yes)
網絡接口不會立即生效,一旦生效,便會永久有效,讓IP生效的解決方法和第二種方法一樣:
1. #ifdown eth1 && ifup eth1 先禁用,再啟用
2. #service network restart 網絡服務重啟
3. #/etc/init.d/network restart 也可以重啟網絡接口
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
無論是
操作系統 (Unix 或者
Windows),還是應用程序 (Web 服務,
數據庫系統等等) ,通常都有自身的日志機制,以便故障時追溯現場及原因。Windows Event Log和
SQL Server Error Log就是這樣的日志, PS: SQL Server 中的錯誤日志 (Error Log) 類似于
Oracle中的alert 文件。
一. 錯誤日志簡介
1. Windows事件日志與SQL Server 錯誤日志
Windows事件日志中,應用程序里的SQL Server和SQL Server Agent服務,分別對應來源自MSSQLSERVER和SQLSERVERAGENT的日志信息;
SQL Server錯誤日志中信息,與Windows事件日志里來源自MSSQLSERVER的日志信息基本一致,不同的是,Windows事件日志里信息為應用程序級,較為簡潔些,而SQL Server錯誤日志里通常有具體的數據庫錯誤信息。比如:
Windows事件日志中錯誤信息:
Login failed for user 'sa'. Reason: Password did not match that for the login provided. [CLIENT: 10.213.20.8]
SQL Server錯誤日志中錯誤信息:
Login failed for user 'sa'. Reason: Password did not match that for the login provided. [CLIENT: 10.213.20.8]
Error: 18456, Severity: 14, State: 8.
2. 如何理解SQL Server的Error message?
以上面的Error: 18456, Severity: 14, State: 8.為例:
(1) Error,錯誤編號,可以在系統表里查到對應的文本信息;
select * From sys.messages where message_id = 18456
(2) Severity,錯誤級別,表明這個錯誤的嚴重性,一共有25個等級,級別越高,就越需要我們去注意處理,20~25級別的錯誤會直接報錯并跳出執行,用SQL語句的TRY…CATCH是捕獲不到的;
(3) State,錯誤狀態,比如18456錯誤,幫助文檔記載了如下狀態,不同狀態代表不同錯誤原因:
1. Error information is not available. This state usually means you do not have permission to receive the error details. Contact your SQL Server administrator for more information.
2. User ID is not valid.
5. User ID is not valid.
6. An attempt was made to use a Windows login name with SQL Server Authentication.
7. Login is disabled, and the password is incorrect.
8. The password is incorrect.
9. Password is not valid.
11. Login is valid, but server access failed.
12. Login is valid login, but server access failed.
18. Password must be changed.
還有文檔未記載的State: 10, State: 16,通常是SQL Server啟動帳號權限問題,或者重啟SQL Server服務就好了。
3. SQL Server 錯誤日志包含哪些信息
SQL Server錯誤日志中包含SQL Server開啟、運行、終止整個過程的:運行環境信息、重要操作、級別比較高的錯誤等:
(1) SQL Server/Windows基本信息,如:版本、進程號、IP/主機名、端口、CPU個數等;
(2) SQL Server啟動參數及認證模式、內存分配;
(3) SQL Server實例下每個數據打開狀態(包括系統和用戶數據庫);
(4) 數據庫或服務器配置選項變更,KILL操作,開關DBCC跟蹤,登錄失敗等等
(5) 數據庫備份/還原的記錄;
(6) 內存相關的錯誤和警告,可能會DUMP很多信息在錯誤日志里;
(7) SQL Server調度異常警告、IO操作延遲警告、內部訪問越界 (也就是下面說到的Error 0);
(8) 數據庫損壞的相關錯誤,以及DBCC CHECKDB的結果;
(9) 實例關閉時間;
另外,可以手動開關一些跟蹤標記(trace flags),來自定義錯誤日志的內容,比如:記錄如用戶登入登出記錄(login auditing),查詢的編譯執行等信息,比較常用的可能是用于檢查死鎖時的1204/1222 跟蹤標記。
通常錯誤日志不會記錄SQL語句的性能問題,如:阻塞、超時的信息,也不會記錄Windows層面的異常(這會在windows事件日志中記載)。
SQL Server Agent錯誤日志中同樣也包括:信息/警告/錯誤這幾類日志,但要簡單很多。
4. SQL Server 錯誤日志存放在哪里
假設SQL Server被安裝在X:\Program Files\Microsoft SQL Server,則SQL Server 與SQL Server Agent的錯誤日志文件默認被放在:
X:\Program Files\Microsoft SQL Server\MSSQL.n\MSSQL\LOG\ ERRORLOG ~ ERRORLOG.n
X:\Program Files\Microsoft SQL Server\MSSQL.n\MSSQL\LOG\SQLAGENT.n and SQLAGENT.out.
如果錯誤日志路徑被管理員修改,可以通過以下某種方式找到:
(1) 操作系統的應用程序日志里,SQL Server啟動時會留下錯誤日志文件的路徑;
(2) 通過SSMS/管理/錯誤日志,SQL Server啟動時會留下錯誤日志文件的路徑;
(3) SQL Server配置管理器里,點擊SQL Server實例/屬性/高級/啟動參數 (Startup parameters) ;
(4) 通過一個未記載的SQL語句 (在SQL Server 2000中測試無效,2005及以后可以):
SELECT SERVERPROPERTY('ErrorLogFileName')
5. SQL Server 錯誤日志目錄下的其他文件
在錯誤日志目錄下除了SQL Server和SQL Server Agent的日志,可能還會有以下文件:
(1) 維護計劃產生的report文件 (SQL Server 2000的時候,后來的維護計劃log記錄在msdb);
(2) 默認跟蹤(default trace) 生成的trace文件,PS: 審計(Audit) 產生的trace文件在\MSSQL\DATA下;
(3) 全文索引的錯誤、日志文件;
(4) SQLDUMP文件,比如:exception.log/SQLDump0001.txt/SQLDump0001.mdmp,大多是發生Error 0時DUMP出來的,同時在錯誤日志里通常會有類似如下記錄:
Error: 0, Severity: 19, State: 0
SqlDumpExceptionHandler: Process 232 generated fatal exception c0000005 EXCEPTION_ACCESS_VIOLATION. SQL Server is terminating this process.
順便說下ERROR 0 的解釋:
You've hit a bug of some kind - an access violation is an unexpected condition. You need to contact Product Support (http://support.microsoft.com/sql) to help figure out what happened and whether there's a fix available.
Is your server up to date with service packs? If not, you might try updating to the latest build. This error is an internal error in sql server. If you are up to date, you should report it to MS.
二. 錯誤日志維護
1. 錯誤日志文件個數
1.1 SQL Server錯誤日志
SQL Server錯誤日志文件數量默認為7個:1個正在用的(ERRORLOG)和6個歸檔的(ERRORLOG.1 – ERRORLOG.6),可以配置以保留更多(最多99個);
(1) 打開到SSMS/管理/SQL Server Logs文件夾/右擊/配置;
(2) 通過未記載的擴展存儲過程,直接讀寫注冊表也行:
USE [master]
GO
EXEC xp_instance_regwrite N'HKEY_LOCAL_MACHINE', N'Software\Microsoft\MSSQLServer\MSSQLServer', N'NumErrorLogs', REG_DWORD, 50
GO
--Check current errorlog amout
USE [master]
GO
DECLARE @i int
EXEC xp_instance_regread N'HKEY_LOCAL_MACHINE', N'Software\Microsoft\MSSQLServer\MSSQLServer', N'NumErrorLogs', @i OUTPUT
SELECT @i
SQL Server作為一個Windows下的應用程序,很多信息是寫在注冊表里的,自然也可以手動打開注冊表編輯器或寫SHELL去修改注冊表來作配置。
最后,可以通過 如下SQL語句查看已存在的錯誤日志編號、起止時間、當前大小。
EXEC master..xp_enumerrorlogs
1.2 SQL Server Agent錯誤日志
SQL Server Agent錯誤日志文件數量共為10個:1個正在用的(SQLAGENT.OUT),9個歸檔的(SQLAGENT.1 - SQLAGENT.9),個數不可以修改,但可以配置日志所記載的信息類型:信息、警告、錯誤。
(1) 打開到SSMS/SQL Server Agent/Error Logs文件夾/右擊/配置;
(2) 未記載的擴展存儲過程:
USE [msdb]
GO
EXEC msdb.dbo.sp_set_sqlagent_properties @errorlogging_level=7
GO
至于@errorlogging_level各個值的意思,由于沒有文檔記載,需要自己測試并推算下。
2. 錯誤日志文件歸檔
2.1 為什么要歸檔錯誤日志?
假設SQL Server實例從來沒被重啟過,也沒有手動歸檔過錯誤日志,那么錯誤日志文件可能會變得很大,尤其是有內部錯誤時會DUMP很多信息,一來占空間,更重要的是:想要查看分析也會不太方便。
SQL Server/SQL Server Agent 錯誤日志有2種歸檔方式,即:創建一個新的日志文件,并將最老的日志刪除。
(1) 自動歸檔:在SQL Server/ SQL Server Agent服務重啟時;
(2) 手動歸檔:定期運行如下系統存儲過程
EXEC master..sp_cycle_errorlog; --DBCC ERRORLOG 亦可
EXEC msdb.dbo.sp_cycle_agent_errorlog;--SQL Agent 服務需在啟動狀態下才有效
2.2 可不可以根據文件大小來歸檔?
可能有人會覺得,雖然很久沒歸檔,但是錯誤日志確實不大,沒必要定期歸檔,最好可以根據文件大小來判斷。有以下幾種方法:
(1) 有些監控工具,比如:SQL Diagnostic manager,就有檢測錯誤日志文件大小,并根據大小來決定是否歸檔的功能;
(2) 自定義腳本也可以,比如:powershell, xp_enumerrorlogs 都可以檢查錯誤日志大小;
(3) SQL Server 2012支持一個注冊表選項,以下語句限制每個錯誤日志文件為5M,到了5M就會自動歸檔,在2008/2008 R2測試無效:
USE [master]
GO
EXEC xp_instance_regwrite N'HKEY_LOCAL_MACHINE', N'Software\Microsoft\MSSQLServer\MSSQLServer', N'ErrorLogSizeInKb', REG_DWORD, 5120;
三. 錯誤日志查看及告警
錯誤日志以文本方式記錄,記事本就可以查看,如果錯誤日志很大,可以選擇Gvim/UltraEdit /DOS窗口type errorlog等,這些方式都會“分頁”加載,不會卡住。
1. 錯誤日志查看
SQL Server提供了以下2種方式查看:
(1) 日志查看器 (log viewer),除了可以查看SQL Server 與SQL Server Agent的錯誤日志,還可以查看操作系統日志、數據庫郵件日志。不過當日志文件太大時,圖形界面非常慢;
(2) 未記載的擴展存儲過程xp_readerrorlog,另外還有一個名為sp_readerrorlog的存儲過程,它是對xp_readerrorlog的簡單封裝,并且只提供了4個參數,直接使用xp_readerrorlog即可:
在SQL Server 2000里,僅支持一個參數,即錯誤日志號,默認為0~6:
exec dbo.xp_readerrorlog --寫0或null都會報錯,直接運行即可 exec dbo.xp_readerrorlog 1 exec dbo.xp_readerrorlog 6 --sql server 2000 read error log if OBJECT_ID('tempdb..#tmp_error_log_all') is not null drop table #tmp_error_log_all create table #tmp_error_log_all ( info varchar(8000),--datetime + processinfo + text num int ) insert into #tmp_error_log_all exec dbo.xp_readerrorlog --split error text if OBJECT_ID('tempdb..#tmp_error_log_split') is not null drop table #tmp_error_log_split create table #tmp_error_log_split ( logdate datetime,--datetime processinfo varchar(100),--processinfo info varchar(7900)--text ) insert into #tmp_error_log_split select CONVERT(DATETIME,LEFT(info,22),120), LEFT(STUFF(info,1,23,''),CHARINDEX(' ',STUFF(info,1,23,'')) - 1), LTRIM(STUFF(info,1,23 + CHARINDEX(' ',STUFF(info,1,23,'')),'')) from #tmp_error_log_all where ISNUMERIC(LEFT(info,4)) = 1 and info <> '.' and substring(info,11,1) = ' ' select * from #tmp_error_log_split where info like '%18456%' |
在SQL Server 2005及以后版本里,支持多達7個參數,說明如下:
exec dbo.xp_readerrorlog 1,1,N'string1',N'string2',null,null,N'desc'
參數1.日志文件號: 0 = 當前, 1 = Archive #1, 2 = Archive #2, etc...
參數2.日志文件類型: 1 or NULL = SQL Server 錯誤日志, 2 = SQL Agent 錯誤日志
參數3.檢索字符串1: 用來檢索的字符串
參數4.檢索字符串2: 在檢索字符串1的返回結果之上再做過濾
參數5.日志開始時間
參數6.日志結束時間
參數7.結果排序: N'asc' = 升序, N'desc' = 降序
--sql server 2005 read error log if OBJECT_ID('tempdb..#tmp_error_log') is not null drop table #tmp_error_log create table #tmp_error_log ( logdate datetime, processinfo varchar(100), info varchar(8000) ) insert into #tmp_error_log exec dbo.xp_readerrorlog select * from #tmp_error_log where info like '%18456%' |
2. 錯誤日志告警
可以通過對某些關鍵字做檢索:錯誤(Error),警告(Warn),失敗(Fail),停止(Stop),而進行告警 (database mail),以下腳本檢索24小時內的錯誤日志:
declare @start_time datetime ,@end_time datetime set @start_time = CONVERT(char(10),GETDATE() - 1,120) set @end_time = GETDATE() if OBJECT_ID('tempdb..#tmp_error_log') is not null drop table #tmp_error_log create table #tmp_error_log ( logdate datetime, processinfo varchar(100), info varchar(8000) ) insert into #tmp_error_log exec dbo.xp_readerrorlog 0,1,NULL,NULL,@start_time,@end_time,N'desc' select COUNT(1) as num, MAX(logdate) as logdate,info from #tmp_error_log where (info like '%ERROR%' or info like '%WARN%' or info like '%FAIL%' or info like '%STOP%') and info not like '%CHECKDB%' and info not like '%Registry startup parameters%' and info not like '%Logging SQL Server messages in file%' and info not like '%previous log for older entries%' group by info |
當然,還可以添加更多關鍵字:kill, dead, victim, cannot, could, not, terminate, bypass, roll, truncate, upgrade, recover, IO requests taking longer than,但當中有個例外,就是DBCC CHECKDB,它的運行結果中必然包括Error字樣,如下:
DBCC CHECKDB (xxxx) executed by sqladmin found 0 errors and repaired 0 errors.
所以對0 errors要跳過,只有在發現非0 errors時才作告警。
小結
如果沒有監控工具,那么可選擇擴展存儲過程,結合數據庫郵件的方式,作自動檢查及告警,并定期歸檔錯誤日志文件以避免文件太大。大致步驟如下 :
(1) 部署數據庫郵件;
(2) 部署作業:定時檢查日志文件,如檢索到關鍵字,發郵件告警;
(3) 部署作業:定期歸檔錯誤日志,可與步驟(2) 合并作為兩個step放在一個作業里。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
vmstat一直以來就是linux/unix中進行性能監控的利器,相比top來說它的監控更加系統級,更側重于系統整體的情況。
今天在學習vmstat的時候,突然想看看
數據庫中的并行對于系統級的影響到底有多緊密,自己簡單
測試了一下。
首先來看看vmstat的命令的解釋。
可能大家并不陌生,如果需要每隔2秒,生成3次報告,可以使用vmstat 2 3
對于命令的輸出解釋如下:
r代表等待cpu事件的進程數
b代表處于不可中斷休眠中的進程數,
swpd表示使用的虛擬內存的總量,單位是M
free代表空閑的物理內存總量,單位是M
buffer代表用作緩沖區的內存總量
cache代表用做高速緩存的內存總量
si代表從磁盤交換進來的內存總量
so代表交換到磁盤的內存總量
bi代表從塊設備收到的塊數,單位是1024bytes
bo代表發送到塊設備的塊數
in代表每秒的cpu中斷次數
cs代表每秒的cpu上下文切換次數
us代表用戶執行非內核代碼的cpu時間所占的百分比
sy代表用于執行那個內核代碼的cpu時間所占的百分比
id代表處于空閑狀態的cpu時間所占的百分比
wa代表等待io的cpu時間所占的百分比
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 0 296716 399588 904276 0 0 0 16 639 1285 0 0 100 0 0 0 0 0 296576 399588 904276 0 0 43 11 809 1484 1 1 98 0 0 0 0 0 296576 399592 904276 0 0 53 25 764 1538 0 0 99 0 0 0 0 0 296584 399592 904276 0 0 0 11 716 1502 0 0 100 0 0 0 0 0 296584 399600 904276 0 0 21 16 756 1534 0 0 100 0 0 |
零零總總說了一大堆,我們舉幾個例子,一個是文件的拷貝,這個最直接的io操作。看看在vmstat的監控下會有什么樣的數據變化。
黃色部分代表開始運行cp命令時vmstat的變化,我們拷貝的文件是200M,可以看到空閑內存立馬騰出了將近200M的內存空間,buffer空間基本沒有變化,這部分空間都放入了cache,同時從設備收到的塊數也是急劇增加,cpu上下文的切換次數也是從930瞬間達到了1918,然后慢慢下降,cpu的使用率也是瞬間上升,最后基本控制在20%~30%。
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 0 296716 399588 904276 0 0 0 16 639 1285 0 0 100 0 0 0 0 0 296576 399588 904276 0 0 43 11 809 1484 1 1 98 0 0 0 0 0 296576 399592 904276 0 0 53 25 764 1538 0 0 99 0 0 0 0 0 296584 399592 904276 0 0 0 11 716 1502 0 0 100 0 0 0 0 0 296584 399600 904276 0 0 21 16 756 1534 0 0 100 0 0 0 0 0 296584 399600 904276 0 0 0 11 930 1625 1 1 98 0 0 1 1 0 93960 399608 1104528 0 0 33427 24 1918 2094 0 23 71 7 0 1 0 0 66440 399592 1131832 0 0 7573 12 1513 1323 0 25 74 2 0 5 0 0 74988 399588 1123188 0 0 2859 33 887 594 0 24 75 1 0 11 0 0 74280 399572 1114952 0 0 1963 15 770 738 3 44 53 0 0 2 0 0 74492 399568 1125008 0 0 3776 16 1014 812 0 20 73 6 0 2 0 0 72640 399560 1126696 0 0 2411 23 975 619 1 21 78 0 0 1 0 0 70532 399556 1128936 0 0 2389 16 1018 732 0 22 77 0 0 2 0 0 75396 399532 1116288 0 0 2795 15 831 673 2 47 51 0 0 2 0 0 79576 399536 1121416 0 0 2901 20 850 688 1 24 63 12 0 0 3 0 67052 399536 1130252 0 0 1493 43708 701 644 0 29 24 47 0 1 0 0 74244 399540 1125600 0 0 1323 19 842 624 0 10 65 25 0 3 0 0 70788 399532 1127728 0 0 2539 21152 936 624 0 18 58 24 0 5 0 0 73164 399532 1120352 0 0 1109 27 458 447 4 71 17 9 0 0 0 0 76120 399532 1125684 0 0 1859 15 957 1182 0 19 80 1 0 0 0 0 76128 399532 1125688 0 0 21 19 679 1399 0 0 98 1 0 --拷貝 工作完成系統的負載又逐步恢復了原值。 |
對于文件的操作有了一個基本認識,來看看數據庫級的操作吧。
首先看看全表掃描的情況。
我們對于一個170萬數據的表進行查詢。可以看到
從設備收到的塊數是急劇增加,效果跟文件的拷貝有些類似,但是buffer,cache基本沒有變化。我想這也就是數據庫級別的操作和系統級別的根本區別吧。數據庫的buffer_cache應該就是起這個作用的。
SQL> select count(*)from test where object_id<>1; COUNT(*) ---------- 1732096 [ora11g@rac1 arch]$ vmstat 3 procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 1 0 0 166520 399680 1023292 0 0 17 20 6 5 1 1 98 1 0 0 0 0 175800 399680 1023292 0 0 53 11 680 1308 0 0 100 0 0 1 0 0 175800 399680 1023292 0 0 18021 24 1451 1826 2 7 66 25 0 0 0 0 175800 399680 1023292 0 0 53 53 812 1577 0 0 98 2 0 0 0 0 166256 399680 1023292 0 0 0 16 881 1614 1 1 98 0 0 1 0 0 175908 399680 1023292 0 0 21 11 866 1605 0 0 99 0 0 |
接著來做一個更為消耗資源的操作,這個sql不建議在正式環境測試,因為很耗費資源
對一個170多萬的表進行低效的連接。vmstat的情況如下。運行了較長的時間,過了好一段時間都沒有結束,可以看到cpu的使用率已經達到了40~50%,在開始的時候,從設備中得到的塊數急劇增加,然后基本趨于一個平均值,buffer,cache基本沒有變化。
SQL> select count(*)from test t1,test t2 where t1.object_id=t2.object_id; procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 0 176024 399688 1023292 0 0 43 11 655 1284 0 0 99 1 0 1 0 0 171420 399688 1023292 0 0 0 16 671 1302 1 1 98 0 0 0 0 0 176164 399688 1023292 0 0 0 11 735 1331 0 1 99 0 0 0 0 0 176164 399688 1023292 0 0 21 25 678 1291 0 0 99 0 0 1 0 0 173452 399688 1023292 0 0 15643 5256 1835 2178 6 12 76 6 0 2 0 0 163048 399688 1023292 0 0 15179 5748 2166 2271 7 12 67 14 0 1 0 0 172072 399688 1023292 0 0 5541 2432 2226 1860 32 6 59 3 0 1 0 0 169964 399688 1023292 0 0 656 24 2322 1656 46 1 50 4 0 1 0 0 169848 399688 1023292 0 0 485 11 2335 1637 48 1 50 2 0 1 0 0 159576 399692 1023288 0 0 448 115 2442 1738 49 1 48 2 0 1 0 0 169344 399692 1023292 0 0 712 11 2351 1701 47 1 50 3 0 1 0 0 169352 399696 1023288 0 0 619 24 2332 1649 48 1 49 2 0 1 0 0 169360 399696 1023292 0 0 467 11 2339 1623 47 1 50 2 0 1 0 0 159848 399700 1023288 0 0 693 16 2318 1673 48 1 48 3 0 1 0 0 169368 399700 1023292 0 0 467 11 2309 1660 47 1 50 3 0 2 0 0 169368 399700 1023292 0 0 467 28 2329 1624 48 1 50 2 0 |
來看看并行的效果。最后返回的條數有近億條,這也就是這個連接低效的原因所在,但是在vmstat得到的信息來看和普通的數據查詢還是有很大的差別。
首先是急劇消耗io,同時從內存中也取出了一塊內存空間。然后io基本趨于穩定,開始急劇消耗cpu資源。可以看到cpu的使用率達到了90%以上。
SQL> select count(*)from test t1,test t2 where t1.object_id=t2.object_id; COUNT(*) ---------- 221708288 procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 0 175048 399748 1023292 0 0 0 20 665 1274 0 0 100 0 0 0 0 0 175048 399748 1023292 0 0 21 11 657 1286 0 0 100 0 0 0 0 0 165644 399748 1023292 0 0 0 16 715 1310 1 1 98 0 0 0 0 0 175056 399748 1023292 0 0 0 11 664 1284 0 0 99 0 0 0 0 0 175056 399748 1023292 0 0 21 24 640 1289 0 0 99 0 0 0 4 0 142364 399748 1025408 0 0 5957 988 1407 1869 10 8 64 18 0 0 0 0 132092 399748 1025444 0 0 12520 4939 1903 2556 14 11 32 43 0 0 2 0 140248 399748 1025444 0 0 10477 3973 1728 2427 11 7 29 53 0 2 0 0 136776 399748 1025444 0 0 7987 4125 1536 2248 11 6 24 60 0 2 0 0 136776 399748 1025444 0 0 971 20 2427 1663 98 1 0 1 0 2 0 0 121404 399748 1025456 0 0 1160 11 2422 1730 96 3 0 1 0 2 0 0 134528 399748 1025460 0 0 1195 17 2399 1695 97 2 0 2 0 3 0 0 134520 399748 1025460 0 0 1325 19 2443 1693 96 1 0 3 0 2 0 0 134536 399748 1025460 0 0 1176 16 2405 1674 99 1 0 0 0 2 0 0 125108 399748 1025460 0 0 1139 11 2418 1647 97 2 0 1 0 2 0 0 134628 399752 1025460 0 0 1235 16 2391 1653 98 1 0 1 0 3 0 0 134644 399752 1025460 0 0 1197 21 2392 1640 97 2 0 1 0 2 0 0 134652 399756 1025460 0 0 1400 16 2433 1670 97 1 0 3 0 2 0 0 125116 399756 1025460 0 0 1008 11 2199 1564 97 2 0 1 0 |
看來并行的實現還是有很多的細節,相比普通的查詢來說更加復雜,而且消耗的資源更多,這個也就是在使用并行的時候需要權衡的一個原因。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
一 磁盤物理結構
(1) 盤片:硬盤的盤體由多個盤片疊在一起構成。
在硬盤出廠時,由硬盤生產商完成了低級格式化(物理格式化),作用是將空白的盤片(Platter)劃分為一個個同圓心、不同半徑的磁道(Track),還將磁道劃分為若干個扇區(Sector),每個扇區可存儲128×2的N次方(N=0.1.2.3)字節信息,默認每個扇區的大小為512字節。通常使用者無需再進行低級格式化操作。
(2) 磁頭:每張盤片的正反兩面各有一個磁頭。
(3) 主軸:所有盤片都由主軸電機帶動旋轉。
(4) 控制集成電路板:復雜!上面還有ROM(內有軟件系統)、Cache等。
二 磁盤如何完成單次IO操作
(1) 尋道
當控制器對磁盤發出一個IO操作命令的時候,磁盤的驅動臂(Actuator Arm)帶動磁頭(Head)離開著陸區(Landing Zone,位于內圈沒有數據的區域),
移動到要操作的初始數據塊所在的磁道(Track)的正上方,這個過程被稱為尋道(Seeking),對應消耗的時間被稱為尋道時間(Seek Time);
(2) 旋轉延遲
找到對應磁道還不能馬上讀取數據,這時候磁頭要等到磁盤盤片(Platter)旋轉到初始數據塊所在的扇區(Sector)落在讀寫磁頭正下方之后才能開始讀取數據,在這個等待盤片旋轉到可操作扇區的過程中消耗的時間稱為旋轉延時(Rotational Latency);
(3) 數據傳送
接下來就隨著盤片的旋轉,磁頭不斷的讀/寫相應的數據塊,直到完成這次IO所需要操作的全部數據,這個過程稱為數據傳送(Data Transfer),對應的時間稱為傳送時間(Transfer Time)。完成這三個步驟之后單次IO操作也就完成了。
根據磁盤單次IO操作的過程,可以發現:
單次IO時間 = 尋道時間 + 旋轉延遲 + 傳送時間
進而推算IOPS(IO per second)的公式為:
IOPS = 1000ms/單次IO時間
三 磁盤IOPS計算
不同磁盤,它的尋道時間,旋轉延遲,數據傳送所需的時間各是多少?
1. 尋道時間
考慮到被讀寫的數據可能在磁盤的任意一個磁道,既有可能在磁盤的最內圈(尋道時間最短),也可能在磁盤的最外圈(尋道時間最長),所以在計算中我們只考慮平均尋道時間。
在購買磁盤時,該參數都有標明,目前的SATA/SAS磁盤,按轉速不同,尋道時間不同,不過通常都在10ms以下:
2. 旋轉延時
和尋道一樣,當磁頭定位到磁道之后有可能正好在要讀寫扇區之上,這時候是不需要額外的延時就可以立刻讀寫到數據,但是最壞的情況確實要磁盤旋轉整整一圈之后磁頭才能讀取到數據,所以這里也考慮的是平均旋轉延時,對于15000rpm的磁盤就是(60s/15000)*(1/2) = 2ms。
3. 傳送時間
(1) 磁盤傳輸速率
磁盤傳輸速率分兩種:內部傳輸速率(Internal Transfer Rate),外部傳輸速率(External Transfer Rate)。
內部傳輸速率(Internal Transfer Rate),是指磁頭與硬盤緩存之間的數據傳輸速率,簡單的說就是硬盤磁頭將數據從盤片上讀取出來,然后存儲在緩存內的速度。
理想的內部傳輸速率不存在尋道,旋轉延時,就一直在同一個磁道上讀數據并傳到緩存,顯然這是不可能的,因為單個磁道的存儲空間是有限的;
實際的內部傳輸速率包含了尋道和旋轉延時,目前家用磁盤,穩定的內部傳輸速率一般在30MB/s到45MB/s之間(服務器磁盤,應該會更高)。
外部傳輸速率(External Transfer Rate),是指硬盤緩存和系統總線之間的數據傳輸速率,也就是計算機通過硬盤接口從緩存中將數據讀出交給相應的硬盤控制器的速率。
硬盤廠商在硬盤參數中,通常也會給出一個最大傳輸速率,比如現在SATA3.0的6Gbit/s,換算一下就是6*1024/8,768MB/s,通常指的是硬盤接口對外的最大傳輸速率,當然實際使用中是達不到這個值的。
這里計算IOPS,保守選擇實際內部傳輸速率,以40M/s為例。
(2) 單次IO操作的大小
有了傳送速率,還要知道單次IO操作的大小(IO Chunk Size),才可以算出單次IO的傳送時間。那么磁盤單次IO的大小是多少?答案是:不確定。
操作系統為了提高 IO的性能而引入了文件系統緩存(File System Cache),系統會根據請求數據的情況將多個來自IO的請求先放在緩存里面,然后再一次性的提交給磁盤,也就是說對于數據庫發出的多個8K數據塊的讀操作有可能放在一個磁盤讀IO里就處理了。
還有,有些存儲系統也是提供了緩存(Cache),接收到操作系統的IO請求之后也是會將多個操作系統的 IO請求合并成一個來處理。
不管是操作系統層面的緩存,還是磁盤控制器層面的緩存,目的都只有一個,提高數據讀寫的效率。因此每次單獨的IO操作大小都是不一樣的,它主要取決于系統對于數據讀寫效率的判斷。這里以SQL Server數據庫的數據頁大小為例:8K。
(3) 傳送時間
傳送時間 = IO Chunk Size/Internal Transfer Rate = 8k/40M/s = 0.2ms
可以發現:
(3.1) 如果IO Chunk Size大的話,傳送時間會變長,單次IO時間就也變長,從而導致IOPS變小;
(3.2) 機械磁盤的主要讀寫成本,都花在了尋址時間上,即:尋道時間 + 旋轉延遲,也就是磁盤臂的擺動,和磁盤的旋轉延遲。
(3.3) 如果粗略的計算IOPS,可以忽略傳送時間,1000ms/(尋道時間 + 旋轉延遲)即可。
4. IOPS計算示例
以15000rpm為例:
(1) 單次IO時間
單次IO時間 = 尋道時間 + 旋轉延遲 + 傳送時間 = 3ms + 2ms + 0.2 ms = 5.2 ms
(2) IOPS
IOPS = 1000ms/單次IO時間 = 1000ms/5.2ms = 192 (次)
這里計算的是單塊磁盤的隨機訪問IOPS。
考慮一種極端的情況,如果磁盤全部為順序訪問,那么就可以忽略:尋道時間 + 旋轉延遲 的時長,IOPS的計算公式就變為:IOPS = 1000ms/傳送時間
IOPS = 1000ms/傳送時間= 1000ms/0.2ms = 5000 (次)
顯然這種極端的情況太過理想,畢竟每個磁道的空間是有限的,尋道時間 + 旋轉延遲 時長確實可以減少,不過是無法完全避免的。
四 數據庫中的磁盤讀寫
1. 隨機訪問和連續訪問
(1) 隨機訪問(Random Access)
指的是本次IO所給出的扇區地址和上次IO給出扇區地址相差比較大,這樣的話磁頭在兩次IO操作之間需要作比較大的移動動作才能重新開始讀/寫數據。
(2) 連續訪問(Sequential Access)
相反的,如果當次IO給出的扇區地址與上次IO結束的扇區地址一致或者是接近的話,那磁頭就能很快的開始這次IO操作,這樣的多個IO操作稱為連續訪問。
(3) 以SQL Server數據庫為例
數據文件,SQL Server統一區上的對象,是以extent(8*8k)為單位進行空間分配的,數據存放是很隨機的,哪個數據頁有空間,就寫在哪里,除非通過文件組給每個表預分配足夠大的、單獨使用的文件,否則不能保證數據的連續性,通常為隨機訪問。
另外哪怕聚集索引表,也只是邏輯上的連續,并不是物理上。
日志文件,由于有VLF的存在,日志的讀寫理論上為連續訪問,但如果日志文件設置為自動增長,且增量不大,VLF就會很多很小,那么就也并不是嚴格的連續訪問了。
2. 順序IO和并發IO
(1) 順序IO模式(Queue Mode)
磁盤控制器可能會一次對磁盤組發出一連串的IO命令,如果磁盤組一次只能執行一個IO命令,稱為順序IO;
(2) 并發IO模式(Burst Mode)
當磁盤組能同時執行多個IO命令時,稱為并發IO。并發IO只能發生在由多個磁盤組成的磁盤組上,單塊磁盤只能一次處理一個IO命令。
(3) 以SQL Server數據庫為例
有的時候,盡管磁盤的IOPS(Disk Transfers/sec)還沒有太大,但是發現數據庫出現IO等待,為什么?通常是因為有了磁盤請求隊列,有過多的IO請求堆積。
磁盤的請求隊列和繁忙程度,通過以下性能計數器查看:
LogicalDisk/Avg.Disk Queue Length
LogicalDisk/Current Disk Queue Length
LogicalDisk/%Disk Time
這種情況下,可以做的是:
(1) 簡化業務邏輯,減少IO請求數;
(2) 同一個實例下的多個用戶數據庫,遷移到不同實例下;
(3) 同一個數據庫的日志、數據文件,分離到不同的存儲單元;
(4) 借助HA策略,做讀寫操作的分離。
3. IOPS和吞吐量(throughput)
(1) IOPS
IOPS即每秒進行讀寫(I/O)操作的次數。在計算傳送時間時,有提到:如果IO Chunk Size大的話,那么IOPS會變小,假設以100M為單位讀寫數據,那么IOPS就會很小。
(2) 吞吐量(throughput)
吞吐量指每秒可以讀寫的字節數。同樣假設以100M為單位讀寫數據,盡管IOPS很小,但是每秒讀寫了N*100M的數據,吞吐量并不小。
(3) 以SQL Server數據庫為例
對于OLTP的系統,經常讀寫小塊數據,多為隨機訪問,用IOPS來衡量讀寫性能;
對于數據倉庫,日志文件,經常讀寫大塊數據,多為順序訪問,用吞吐量來衡量讀寫性能。
磁盤當前的IOPS,通過以下性能計數器查看:
LogicalDisk/Disk Transfers/sec
LogicalDisk/Disk Reads/sec
LogicalDisk/Disk Writes/sec
磁盤當前的吞吐量,通過以下性能計數器查看:
LogicalDisk/Disk Bytes/sec
LogicalDisk/Disk Read Bytes/sec
LogicalDisk/Disk Write Bytes/sec
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
============問題描述============
在
數據庫中存放用戶發帖的信息,利用下面的程序得到該用戶發帖的數量。可是UserUtils的值一直是1,這是怎么回事?
ResultSet res = sqlConn .executeQuery("select count(*) from" + username + "_message"); while (res.next()) { UserUtils.flag = res.getInt(1); System.out.println("userUtils = " + UserUtils.flag); } |
============解決方案1============
from這后面加個空格吧
============解決方案2============
select count(*) from后面少了一個空格樣。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
數據庫的備份是極其重要的事情。如果沒有備份,遇到下列情況就會抓狂:
UPDATE or DELETE whitout where…
table was DROPPed accidentally…
INNODB was corrupt…
entire datacenter loses power…
從數據安全的角度來說,服務器磁盤都會做raid,
MySQL本身也有主從、drbd等容災機制,但它們都無法完全取代備份。容災和高可用能幫我們有效的應對物理的、硬件的、機械的故障,而對我們犯下的邏輯錯誤卻無能為力。每一種邏輯錯誤發生的概率都極低,但是當多種可能性疊加的時候,小概率事件就放大成很大的安全隱患,這時候備份的必要性就凸顯了。那么在眾多的MySQL備份方式中,哪一種才是適合我們的呢?
常見的備份方式
MySQL本身為我們提供了mysqldump、mysqlbinlog遠程備份工具,percona也為我們提供了強大的Xtrabackup,加上開源的mydumper,還有基于主從同步的延遲備份、從庫冷備等方式,以及基于文件系統快照的備份,其實選擇已經多到眼花繚亂。而備份本身是為了恢復,所以能夠讓我們在出現故障后迅速、準確恢復的備份方式,就是最適合我們的,當然,同時能夠省錢、省事,那就非常完美。下面就我理解的幾種備份工具進行一些比較,探討下它們各自的適用場景。
1. mysqldump & mydumper
mysqldump是最簡單的邏輯備份方式。在備份myisam表的時候,如果要得到一致的數據,就需要鎖表,簡單而粗暴。而在備份innodb表的時候,加上–master-data=1 –single-transaction 選項,在事務開始時刻,記錄下binlog pos點,然后利用mvcc來獲取一致的數據,由于是一個長事務,在寫入和更新量很大的數據庫上,將產生非常多的undo,顯著影響性能,所以要慎用。
優點:簡單,可針對單表備份,在全量導出表結構的時候尤其有用。
缺點:簡單粗暴,單線程,備份慢而且恢復慢,跨IDC有可能遇到時區問題。
mydumper是mysqldump的加強版。相比mysqldump:
內置支持壓縮,可以節省2-4倍的存儲空間。
支持并行備份和恢復,因此速度比mysqldump快很多,但是由于是邏輯備份,仍不是很快。
2. 基于文件系統的快照
基于文件系統的快照,是物理備份的一種。在備份前需要進行一些復雜的設置,在備份開始時刻獲得快照并記錄下binlog pos點,然后采用類似copy-on-write的方式,把快照進行轉儲。轉儲快照本身會消耗一定的IO資源,而且在寫入壓力較大的實例上,保存被更改數據塊的前印象也會消耗IO,最終表現為整體性能的下降。而且服務器還要為copy-on-write快照預留較多的磁盤空間,這本身對資源也是一種浪費。因此這種備份方式我們使用的不多。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
Hibernate 與數據庫中的觸發器協同工作時, 會造成兩類問題 1、觸發器使 Session 的緩存中的持久化對象與數據庫中對應的數據不一致:觸發器運行在數據庫中, 它執行的操作對 Session 是透明的 Session 的
解決方案: 在執行完 Session 的相關操作后, 立即調用 Session 的 flush() 和 refresh() 方法, 迫使 Session 的緩存與數據庫同步(refresh() 方法重新從數據庫中加載對
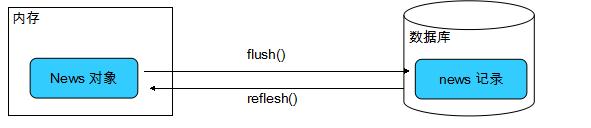
象)
2、update() 方法盲目地激發觸發器: 無論游離對象的屬性是否發生變化, 都會執行 update 語句, 而 update 語句會激發數據庫中相應的觸發器
解決方案:在映射文件的的 <class> 元素中設置 select-before-update 屬性: 當 Session 的 update 或 saveOrUpdate() 方法更新一個游離對象時, 會先執行 Select 語句, 獲得當前游離對象在數據庫中的最新數據, 只有在不一致的情況下才會執行 update 語句(沒有用到觸發器的時候一般的情況下最好不要設置,因為會降低效率的)
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
Java應用中拋出的空指針異常是解決空指針的最好方式,也是寫出能順利
工作的健壯程序的關鍵。俗話說“預防勝于治療”,對于這么令人討厭的空指針異常,這句話也是成立的。值得慶幸的是運用一些防御性的編碼技巧,跟蹤應用中多個部分之間的聯系,你可以將Java中的空指針異常控制在一個很好的水平上。順便說一句,這是Javarevisited上的第二個空指針異常的帖子。在上個帖子中我們討論了Java中導致空指針異常的常見原因,而在本教程中我們將會
學習一些Java的編程技巧和最佳實踐。這些技巧可以幫助你避免Java中的空指針異常。遵從這些技巧同樣可以減少Java代碼中到處都有的非空檢查的數量。作為一個有經驗的Java程序員,你可能已經知道其中的一部分技巧并且應用在你的項目中。但對于新手和中級開發人員來說,這將是很值得學習的。順便說一句,如果你知道其它的避免空指針異常和減少空指針檢查的Java技巧,請和我們分享。
這些都是簡單的技巧,很容易應用,但是對代碼質量和健壯性有顯著影響。根據我的經驗,只有第一個技巧可以顯著改善代碼質量。如我之前所講,如果你知道任何避免空指針異常和減少空指針檢查的Java技巧,你可以通過評論本文來和分享。
1) 從已知的String對象中調用equals()和equalsIgnoreCase()方法,而非未知對象。
總是從已知的非空String對象中調用equals()方法。因為equals()方法是對稱的,調用a.equals(b)和調用b.equals(a)是完全相同的,這也是為什么程序員對于對象a和b這么不上心。如果調用者是空指針,這種調用可能導致一個空指針異常
Object unknownObject = null; //錯誤方式 – 可能導致 NullPointerException if(unknownObject.equals("knownObject")){ System.err.println("This may result in NullPointerException if unknownObject is null"); } //正確方式 - 即便 unknownObject是null也能避免NullPointerException if("knownObject".equals(unknownObject)){ System.err.println("better coding avoided NullPointerException"); } |
這是避免空指針異常最簡單的Java技巧,但能夠導致巨大的改進,因為equals()是一個常見方法。
2) 當valueOf()和toString()返回相同的結果時,寧愿使用前者。
因為調用null對象的toString()會拋出空指針異常,如果我們能夠使用valueOf()獲得相同的值,那寧愿使用valueOf(),傳遞一個null給valueOf()將會返回“null”,尤其是在那些包裝類,像Integer、Float、Double和BigDecimal。
BigDecimal bd = getPrice();
System.out.println(String.valueOf(bd)); //不會拋出空指針異常
System.out.println(bd.toString()); //拋出 "Exception in thread "main" java.lang.NullPointerException"
3) 使用null安全的方法和庫 有很多開源庫已經為您做了繁重的空指針檢查工作。其中最常用的一個的是Apache commons 中的StringUtils。你可以使用StringUtils.isBlank(),isNumeric(),isWhiteSpace()以及其他的工具方法而不用擔心空指針異常。
//StringUtils方法是空指針安全的,他們不會拋出空指針異常 System.out.println(StringUtils.isEmpty(null)); System.out.println(StringUtils.isBlank(null)); System.out.println(StringUtils.isNumeric(null)); System.out.println(StringUtils.isAllUpperCase(null)); Output: true true false false |
但是在做出結論之前,不要忘記閱讀空指針方法的類的文檔。這是另一個不需要下大功夫就能得到很大改進的Java最佳實踐。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
最近做程序,時不時需要自己去手動將sql語句直接寫入到
Java代碼中,寫入sql語句時,需要注意幾個小問題。
先看我之前寫的幾句簡單的sql語句,自以為沒有問題,但是編譯直接報錯。
String str = "insert into XXX(a,b,c) values ('"a.getA()"','"a.getB()"','"a.getC()"');";
研究了半天發現應該是連接字符串問題,第一次修改過后將賦值字段前后加“+”號來完成sql語句。改正后代碼如下
String str = "insert into XXX(a,b,c) values ('"+a.getA()+"','"+a.getB()+"','"+a.getC()+"');";
原來在
數據庫中給字段動態賦值需要以‘“+···+”’的方式來完成。好的,編譯后成功,將運行的str的結果值放入sql數據庫中
測試,沒有問題,自以為一切ok了,結果運行時再次報錯。這把自己困擾住了,反復測試,在數據庫中用sql語句來對比,沒有問題啊,現將我最后成功的代碼放上來,大家看看有沒有什么不同。
String str = "insert into XXX(a,b,c) values ('"+a.getA()+"','"+a.getB()+"','"+a.getC()+"')";
沒錯,就是最后的分號,原來在java語句中不能講分號加入到普通的sql語句中,雖然在數據庫中沒有報錯,但是在java中一定還是要注意這種小問題的。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
今天在優化一個功能的時候遇到了instr與substr函數,之前沒有接觸過這兩個函數,但是今天無意中用到,一查才發現,真是實用的一對兄弟啊。
先來說說substr函數,這個函數返回的是字符串的一部分。
substr(string,start,length)
其中string參數為必須參數,要截取的字符串內容。
start為必須參數,為起始的位置,可以為正數也可以為負數,正數的話代表從在字符串的指定位置開始;負數代表從字符串結尾的指定位置開始;0代表在字符串中的第一個字符處開始。
length不是必須參數,為截取的長度,正數代表從 start 參數所在的位置向后返回字符個數;負數代表從字符串末端指定位置向前返回字符個數。
舉個例子:
substr("Hello World!",2,1)返回的是e
substr("Hello World!",2)返回的是ello World!
substr("Hello World!",-2,1)返回的是d
substr("Hello World!",-2,-1)返回的是d!
instr( string1, string2, start_position,nth_appearance ) 函數返回要截取的字符串在源字符串中的位置。
string1源字符串,要在此字符串中查找。
string2要在string1中查找的字符串 。
start_position代表開始的位置。
nth_appearance代表要查找第幾次出現的string2. 此參數可選,如果省略,默認為 1.如果為負數系統會報錯。
舉個例子:
instr("Hello World!","o")返回的是5
instr("Hello World!","o",1,2)返回的是8。解釋一下,這句話代表"o"從字符串第一個位置開始查詢,第二個“o”出現的位置。
很有用的兩個函數呢
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters