
DOM全稱”Document Object Model”,字面上叫做”文檔對象模型”,它是一款主要用于Web Html中的一種獨立語言。Html Dom主要通過定義一套標準的對象通道接口,使得我們能夠輕松訪問并控制Html對象元素,它是一種用于Html和Xml文檔的編程接口。DOM的表現方 法是一種樹狀結構。
有些時候
QTP只對標準控件支持比較好,而對特殊的控件無法識別。DOM是一種罪底層的對象操作模型,使用它來控制對象不但速度快,而且可以訪問很多QTP無法訪問的東西。
1. 修改控件自身接口
QTP本身無法修改控件自身接口屬性,但通過DOM我們可以訪問并修改自身接口屬性
2. DOM對象下CurrentStyle對象應用
CurrentStyle是一個可以與Html對象元素style sheets進行交互的接口,它可以獲取對象元素的字體名,字體大小,顏色,是否可見等,在驗證點時有重要作用。
3. 性能提升
DOM執行速度會比QTP對象庫的執行速度快好幾倍,這是因為DOM是底層對象接口,而QTP首先要把對象封裝,然后在腳本運行時調用對象庫的對象,最后與頁面上的對象進行比對,如果匹配才可控制
測試對象。而DOM是直接找對象進行控制。
下面的例子是IE對象模型里的DOM應用
1. 啟動IE的三種常見方法
在QTP中啟動IE:
SystemUtil.Run “iexplore.exe”
2. 使用WSH啟動IE:
Set oShell = CreateObject(“wscript.shell”)
3. 使用IE COM對象:
Set oIE = CreateObject("InternetExplorer.Application")
oIE.Visible = True
oIE.Navigate http://www.baidu.com
使用第三種方法還可以獲得當前窗口的句柄,并通過QTP來定位瀏覽器:
ieHwnd = oIE.HWND
Browser(“hwnd:=” & ieHwnd).Close
接下來的這個例子就是使用到DOM去操作頁面元素了
Set oIE = CreateObject("InternetExplorer.Application")
oIE.Visible = True
oIE.Navigate "http://www.baidu.com"
'While oIE.Busy
'Wend
oIE.Document.f.wd.value = "sunyu"
我把While oIE.Busy:Wend這兩句話注釋掉了,運行結果如下:
程序運行出錯了,主要是因為我們沒有等待頁面加載完,就進行了下一步的填值操作,QTP會找不到這個對象。如果你點擊Retry再次運行,那么這次會通過,因為頁面已經加載完畢了。所以我們在操作Web對象時,要特別注意需要等待頁面加載完畢。
注:以上這個錯誤我們會經常遇到,有時候你只需要關掉QTP再重新打開后就不會再遇到這個錯誤了。
遍歷所有IE對象:
Function EnumIE()
Set EnumIE = CreateObject("Scripting.Dictionary")
Set winShell = CreateObject("
Shell.Application")
Set allWins = winShell.Windows
For each win in allWins
If instr(1,win.FullName,"iexplore.exe",vbTextCompare) Then
EnumIE.Add win.hwnd,win
End If
Next
End Function
我打開一共兩個IE窗口,但是第一個IE窗口里有四個子窗口,如下圖:
然后調用上面的代碼:
Set allIE = EnumIE()
For each oIE in allIE.Items
oIE.quit
Next
結果QTP報錯了
這是因為在同一個窗口下的四個子窗口使用的是同一個句柄,所以無法加入到Dictionary對象里去。只要對代碼稍加修改就可以了:
Function EnumIE()
Set EnumIE = CreateObject("Scripting.Dictionary")
Set winShell = CreateObject("Shell.Application")
Set allWins = winShell.Windows
For each win in allWins
If instr(1,win.FullName,"iexplore.exe",vbTextCompare) Then
If Not EnumIE.Exists(win.hwnd) Then
EnumIE.Add win.hwnd,win
End If
End If
Next
End Function
調用的時候,我采用了遞歸調用,只要有子窗口沒有關完,就會繼續關。這里用do while的話會多執行一次EnumIE這個函數,大家可以考慮換一種循環方式,我就不多說了。
Set allIE = EnumIE()
Do while allIE.Count>0
For each oIE in allIE.Items
oIE.quit
Next
Set allIE = EnumIE()
Loop
當然了QTP有自己的方法會很快關閉所有的IE窗口:
SystemUtil.CloseProcessByName(“iexplore.exe”)
下面介紹下利用DOM操作測試對象的幾種常用方法,還是用百度主頁做例子,首先將百度主頁加進對象庫。
IE8里會自帶F12開發工具,可以方便你看你需要的DOM屬性
Set oDOM = Browser("百度一下,你就知道").Page("百度一下,你就知道").Object
需要注意的是,此處的Object屬性目前只支持IE,而對其他的瀏覽器目前還沒有加入支持。
1. 通過getElementById方法獲取定位對象,對其進行操作:
oDOM.getElementById("kw").value = "態度決定測試"
oDOM.getElementById("su").click
2. 通過getElementsByName方法獲取定位對象,對其進行操作:
方法一:
Set oEdits = oDOM.getElementsByName("wd")
For each oEdit in oEdits
oEdit.value = "態度決定測試"
Next
oDOM.getElementById("su").click
方法二:
Set oEdits = oDOM.getElementsByName("wd")
oEdits(0).value = "態度決定測試"
oDOM.getElementById("su").click
通過方法名里Element后面的復數形式也大概可以知道這個方法返回的是一個集合,所以需要遍歷集合里的對象獲取這個對象。
3. 通過getElementsByTagName方法獲取定位對象,對其進行操作:
Set oEdits = oDOM.getElementsByTagName("INPUT")
For each oEdit in oEdits
If oEdit.type = "text" Then
oEdit.value = "態度決定測試"
End If
Next
oDOM.getElementById("su").click
用這個方法遍歷之后通常要加判斷,因為一個頁面里可能有很多INPUT標簽。
4. 利用FORM來獲取對象元素,對其進行操作:
oDOM.f.wd.value = "態度決定測試"
oDOM.f.su.click
5. 訪問頁面里的Script腳本變量
通過DOM可以直接訪問到頁面中的JS或者VBS中的變量,還是以百度為例,我們用F12進行探測,可以看到k這個變量: k = d.f.wd
oDOM.parentWindow.k.value = "態度決定測試"
oDOM.getElementById("su").click
從代碼里可以看出,我們只需要通過parentWindow去訪問web頁面中的變量即可。
下面我們來說說利用DOM完成QTP無法完成的任務:
還是百度,假設我們需要驗證一些屬性,此時我們可以使用CurrentStyle來驗證。
Set oDOM = Browser("百度一下,你就知道").Page("百度一下,你就知道").Object
Set p = oDOM.f.CurrentStyle
msgbox p.color
我們可以驗證表單的顏色。
利用DOM還可以提升我們的腳本性能,舉個例子,自己構建一個含有100個文本框的HTML頁面,每個文本框的name屬性都是由text_開頭,之后由1到100遞增。首先將Page對象加到對象庫里去。
效果圖如下:
接下來我們就可以引入保留對象Services的Transaction屬性來驗證性能是否有提高。
QTP描述性編程:
Services.StartTransaction "test"
For i =1 to 100
Browser("Browser").Page("Page").webEdit("name:=text_"+cstr(i)).Set "hello world"
Next
Services.EndTransaction "test"
運行后結果大概用了11.5秒時間填寫完一百個webEdit對象。
DOM操作腳本:
Set oDOM= Browser("Browser").Page("Page").Object
Services.StartTransaction "test"
For i =1 to 100
oDOM.getElementsByName("text_"+cstr(i))(0).value = "hello world"
Next
Services.EndTransaction "test"
結果只用了1.8秒時間,效率驚人。
如果文本框更多的話,那么DOM操作對象的優勢將進一步顯現出來。這對性能的提升會有巨大的幫助。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
關于
Selenium RC的原理,還是Selenium私房菜系列6比較詳細。 雖然我只看懂了組成。
按照上面的步驟,搭建后的工程:
一個簡單的Case,不完整,純粹為了
測試環境是否搭成功。
package com.dhy.selenium.test; import org.openqa.selenium.By; import org.openqa.selenium.WebDriver; import org.openqa.selenium.WebElement; import org.openqa.selenium.firefox.FirefoxDriver; import org.openqa.selenium.remote.RemoteWebDriver; import org.openqa.selenium.remote.DesiredCapabilities; public class Case1 { public static void main(String[] args) throws Exception{ // WebDriver driver = new RemoteWebDriver(new URL("http://localhost:4444/wd/hub"), // DesiredCapabilities.firefox()); WebDriver driver = new FirefoxDriver(); driver.get("http://2j.isurveylink.com/s/183/?test_mode=1"); WebElement element = driver.findElement(By.id("start_btn")); element.click(); try { Thread.sleep(3000); } catch (InterruptedException e) { // TODO Auto-generated catch block e.printStackTrace(); } System.out.println("Page title is : " + driver.getTitle()); driver.quit(); } } |
這里的語法啊、類啊什么的,需要慢慢研究。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
方法一
這個實現其實蠻簡單,只不過官網上的手冊寫得不是很詳細。
首先你在入口文件中定義你生成html頁面的路徑常量HTML_PATH,一般路徑都定義在根目錄,比較直觀。把手冊上寫得代碼copy到你要生成頁面的應用項目的配置文件中,只要寫靜態緩存規則就行。比如你要生成關于我們頁面,你的規則可以這樣寫
'HTML_CACHE_ON' => true, // 開啟靜態緩存 'HTML_CACHE_TIME' => 60, // 全局靜態緩存有效期(秒) 'HTML_FILE_SUFFIX' => '.shtml', // 設置靜態緩存文件后綴 'HTML_CACHE_RULES' => array( // 定義靜態緩存規則 'About' => array('/About/index.html') |
當你訪問關于我們頁面的時候,就會生成這個頁面的純html頁面,當你這個頁面更新數據的時候,隔60秒后,前臺頁面就會自動重新寫入,因為緩存有效期設置的60秒,你也可以設置永久有效,這樣的話不會每隔60秒重新寫入一次,浪費性能。設置永久有效的話,你更新數據前臺是不會更新的,這個時候你只要刪除緩存就行了,緩存就是這個生成的頁面文件,將其刪除。或者你在后臺寫個一鍵更新緩存等都可以,這種緩存訪問頁面速度是非常可觀的。而且還能脫離程序運行,不怕程序發生意外報錯情況。
方法二
ob_start(); //打開緩沖區 $data = ob_get_contents(); //獲取緩沖區的內容 ob_end_clean(); //關閉緩沖 $fp = fopen("/index.html","w"); //將內容寫入文件 if(!$fp) { echo "文件無權限"; exit(); } else { fwrite($fp,$data); fclose($fp); echo "生成成功"; } |
這代碼寫在前臺相應的控制器中,會自動生成html頁面。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
JIRA 使用神奇的JQL查詢數據,很nice啊 !
官網API: https://docs.atlassian.com/jira/REST/latest/#d2e2344
/rest/api/2/search request query parameters parametervaluedescription jql string a JQL query string startAt int the index of the first issue to return (0-based) maxResults int the maximum number of issues to return (defaults to 50). The maximum allowable value is dictated by the JIRA property 'jira.search.views.default.max'. If you specify a value that is higher than this number, your search results will be truncated. validateQuery boolean Default:true whether to validate the JQL query fields string the list of fields to return for each issue. By default, all navigable fields are returned. expand string A comma-separated list of the parameters to expand. |
其中jql 是一個JQL的query string。
測試代碼:
string url = baseURL + "/search?jql=assignee=" +username +" and (status=1 or status=2)"; HttpWebRequest req = WebRequest.Create(url) as HttpWebRequest; try { req.ContentType = "application/json"; req.Headers.Add("Authorization", "Basic " + m_authString); using (HttpWebResponse resp = req.GetResponse() as HttpWebResponse) { StreamReader reader = new StreamReader(resp.GetResponseStream()); response = reader.ReadToEnd(); } } catch (Exception e) { response = e.Message; m_errorMsg = e.Message; return false; } |
也可以直接裝好以后,用url直接回車訪問上述創建的鏈接,會直接得到數據信息到頁面
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
因電腦上裝了兩個系統,導致我的JIRA服務不能和tomcat同時啟動,讓我弄了好久都不知道是啥原因,經過請教,總算得出原來是JIRA的Port和Tomcat的Port沖突。在
server.xml中修改即可。<Server port="8006" shutdown="SHUTDOWN">兩個改成不一樣就好了。裝好后,記得要配置環境變量,這個跟配置tomcat是一樣的。之后記得破解哦。如果要漢化的話,也有相關操作說明。
破解說明:
1.將atlassian-extras-2.2.2.jar 覆蓋至%JIRA_HOME%/atlassian-jira/WEB-INF/lib/atlassian-extras-2.2.2.jar
2.將atlassian-extras-2.2.2.crack 覆蓋至先將這個文件復制到%JIRA_HOME%/atlassian-jira/WEB-INF/classes下,然后把文件中的MaintenanceExpiryDate項修改到你想要的日期
重啟Jira
JIRA漢化
1、用管理員登錄,進入管理頁面;
2、進入插件頁面
3、進入install標簽頁
4、點擊
5、 在彈出的對話框中選擇 中文插件文件(.jar)
6、“中文插件文件.jar”下載地址:
文件名:JIRA-5.0-language-pack-zh_CN.jar
7、系統會自動安裝,并轉換語言為中文。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
我兩年多的
測試生涯到頭了。我想再這里總結一下點點滴滴。以及我也會說明我為什么選擇離開。在中國有著很多很多的
軟件測試,很多迫于環境,迫于leader,迫于很多原因,導致只是一個“執行者”。以下只是我個人的一些經歷。大家可以借鑒,也可吐槽,大家隨意。
首先在測試的時候需要有一些心理暗示,其實未必是暗示,可能是給自己的一些自信。
第一:產品一定是有bug的。
無論你測試什么產品,一定是需要報有這樣的心態。為什么?其實就如一句說的“如果自己都不愛自己,那么就不要奢望別人來愛你”。如果連測試潛意識里面都覺得產品是沒有bug的那么還能有誰認為產品是有bug的呢?
測試的歷史上有兩種驗證方法,一種是測試是用來驗證產品一定是沒有bug的,一種是測試是用來驗證產品是有bug的。無論哪種你都要有一種原則,要有一種信念。就如人生漫漫長路一樣,我們必須堅信自己的夢想,堅信自己是能夠成功的。那么才有可能,才有希望。當碰見挫折的時候,當迷茫的時候,才不會真的被打敗。
一個新的feature,一個剛剛fix的bug,一個用戶反饋,一個不起眼的問題。我們都需要堅信里面有缺陷的。沒有任何一個產品,任何一個細節是完美的。
許多公司從上級到下屬對于產品的質量根本沒有概念,又或者對于質量不重視。在這種情況下,就需要測試產生力量,需要用各種事實依據去告訴公司,告訴大家這樣一個產品質量的真想。國外的公司相對好點,國內有很多公司是需要有這種有責任感的測試存在。
第二,任何的bug都是能夠repro的
無論你面對一個很小的
功能測試,還是很復雜的場景化的測試,又或者說某個用戶很簡單明了的描述了一個問題。我們需要堅定不移的告訴自己,只要是一個bug就是有重現步驟的。
微軟曾經有測試,一個問題的重現步驟長達50步。雖然可能不是最佳的步驟,但是依然對于解決問題起到了決定性的作用。
自然,在實際中很多情況下的確會碰見一下子找不到重現步驟的方法。找不到方法意味著什么?意味著你可以開bug,dev可以fix這個bug。但是誰都不知道到底有沒有真的修復這個問題。還可能因此出現很多regression的bug。所以找到一個bug的repro step可以說是一個測試基本功也是體現價值的地方。
和第一點一樣,只有你自己信念中去相信了,那么你才有可能成功。
第三,只相信自己看到的
在很多情況下,dev或者同事會告訴測試“這個功能很小,沒有bug的”“簡單測一下就好啦”等等的話。我主張還是不要太相信任何一個人。
面對bug,我們需要好好的理清問題的根源邏輯,在進行一個完全的測試之后告訴自己“這個功能基本上不會有很大,或者很block用戶的問題”;面對一個討論,不要聽到別人說什么就是什么,任何的決定都沒有完全正確的。我們需要自己親手去驗證很多決定和設計,小到你可以google,找出各種證據來證明某些事情。大到你可以進行用戶數據搜集,很多企業不會去做。但是如果一個有sense的測試,我相信必須什么事情都親手去實踐去證明!
以上說了這么多,可能很多人覺得,這個還是測試么?ok,我認為真正的一個測試滿足以上三點是遠遠不夠的。以下是我認為一個有sense的測試,記住是有sense的測試需要做到的。
為什么我將這兩個放在一起呢。兩者密不可分。我所在公司是做android產品的。目前中國國內很多企業也是一樣的問題,就是只是在乎自己的產品怎么樣,并不會很關心你的發展。作為測試,必須有探知精神,必須樂于學習。比如你測試A平臺的B產品,如果只是一味的測試,只是一味的報bug。的確你會有進步,做任何一行你都會有進步,行行都能夠出狀元。但是幾年光陰一過去,當別人或者自己問問自己,自己真的知道了多少?可能對于自己公司做的產品很了解之外,一無所知。那么這樣對于自身發展又有什么好處呢?
探知,對于任何一個design,任何一個bug,任何一個細節都需要去探知。這樣無論你做了多久,無論你是否做多少個項目都會依然有進步。時不時的問問自己,對于這個產品feature真的了解很透徹么?對于產品功能邏輯很清楚么?對于這個產品所在平臺了解么?業內是不是主流的tools都清楚了呢?是不是自己已經沒有了進步的余地了。這樣自己會明了很多。
第二:責任
這點可能很多人會說,測試最基本的不就是責任么?沒有責任怎么去做一個測試呢?是的,責任每個人都有,程度是不同的。你作為一個tester,需要保證產品的質量。勿以bug小而不重視,本質上依然是不負責任的表現。
相反的,很多測試對于產品是負責了,對于自己卻是不負責任的。因為他們只是一個傀儡,天天被人操控著。做這個做那個,我覺得這種是更加可悲的。
如果你作為一個tester leader,那么你的責任不是去指揮別人做事情,不是去拍老板馬屁。而是自己不要忘記進一步的學習,不要忘記對于任何的細節去了解。更不要忘記如果出了什么問題,自己勇于承擔這個責任。真正的leader是什么?需要在流程以及技術上面有自己的sense,需要不停的去完善項目流程,從而提高測試team的效率以及項目的效率。
第三:通過各種渠道找到bug repro step
bug會從各個渠道發現。公司內部bug bash的時候,用戶反饋的問題,自己找到的問題。老板發現的問題等等。這個時候能否找到repro step就是體現一個測試的價值所在了。
測試往往碰見的問題是這樣的。突然發現一個問題,欣喜若狂!但是然后問問自己“我剛剛做了什么”,基本上很多人都不知道。有的時候是有log可以取,但是log只是一個告訴開發如何dev去解決bug的。所以找出重現步驟才是王道。并非要時時刻刻保持警惕,可以有兩個做法,一個就是自己在測試的時候留個心眼,養成時不時回憶自己做了哪些操作。一個就是養成一邊測試一邊記錄log的方法,這個方法相對很保險,不過前提是自己需要有完全看得懂log的能力。
另外一類bug是從用戶這里報出。用戶一般是無知的,根本不會懂你產品的邏輯,可能描述出來的錯誤和真正的錯誤根本就是天差地別。這個時候就需要測試去按照經驗以及各種方法去判斷。判斷出用戶說的產品的真正的問題在哪里,然后使用各種方法(automation.etc)去模擬bug產生的環境。這樣一來,bug在修復的情況下能夠在公司內部馬上得到confirm。這樣無論是對于產品,用戶,還是公司都是一種無限大的利益。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
作為一名
測試人員我知道我不可能找到每一個錯誤。但即便如此,當一個問題從你眼前溜過,跑向生產這一本壘時,我經常會問自己,我怎么就漏過了這個問題呢?有什么是我可以做得更好的?我能做些什么來防止未來這種情況的再次發生?
這些都是很好的問題,但更實際的來說,我們需要認識到一點,錯誤往往會偷偷溜過而未被我們發現。有一些方法可以幫助我們減少這些未被發現的bug數量,但我明白沒有任何辦法能夠保證產品完全無缺陷。
當我剛開始做測試時我總是對別人在我測試過的產品的部分發現bug非常敏感。我常聽到辦公室回響著可怕的句子——“誰測試過這個?為什么沒有發現這個錯誤?”那時我還沒有足夠的經驗可以通過合理的方式來爭論,為什么不是任何產品在任意給定時間段中都可以找到所有的bug。
雖然在某些方面,這些經歷幫助我使我的測試方法更完備。
所以,我列出了一些你可以嘗試一下的事情,以限制未被檢測到的bug的數量,我有幾個故事分享給大家,關于那些像夜晚的忍者那樣悄悄溜過而未被我發現的錯誤。這些故事表明,即使最明顯的錯誤(一旦知道就覺得很明顯),可能發生也將發生。
我們怎么會錯過呢?
在一個項目中,一個網站,正在一些關鍵部分,如注冊和產品選擇進行了重新設計并添加了一些額外的功能,我花了大約兩個月進行各種測試活動。在這段時間內熟悉設置的各種變化和改進,我們都知道危險,并試圖減少它們,我們找了一些人來進行用戶支持測試以幫助測試。不幸的是,這些主要覆蓋在驗證bug修復或者專門針對測試網站的某些部分。
在產品環境中啟動網站的第一分鐘,一個問題被確定。這是非常明顯的bug,也產生了一些相當大的混亂,它是怎么能夠被錯過的。這個問題并不是說需要任何除了會拼寫之外的特殊的技能才能找到的。在該網站的首頁(它通常被稱為商店櫥窗),客戶登陸后看到的你的網站的第一頁,在屏幕中間非常大的字體,寫著“BRAODBAND“而不是“BROADBAND”。 “這是一個非常明顯的錯誤拼寫,但不知何故,每個人都錯過了發現它,直到這個網站開始使用,然后由于某種原因,這個錯誤立即被所有人發現了。
它是活的!
我現在受到了“它還活著”,在1931年的老電影科學怪人中那句臺詞的啟發。當產品處于成熟狀態,我用這句話來慢慢的推進我的想法,為了能夠看到那些可能被我錯過的東西。在這種情況下,問題是那么明顯它造成了混亂的奇怪的氛圍,而且可能因為修補程序過于簡單而無從指責。然而,這很清楚地表明了,即使是最公然明顯的錯誤也很容易被很多人錯過。
本應該,早該,早可以。
這些錯誤不一定在測試過程中由于沒有找到他們而被錯過,而是因為測試者沒有考慮如果X事件發生了,在整個開發周期中將會或者可能會發生什么錯誤。當在當天晚些時候發現或者當產品在生產過程中發現這些bug時,常常招來了一句“是啊,我就覺得這可能會發生”或“我就知道會發生這個問題。”
這些方案有時被稱為邊緣情況(極限測試情況下)或邊角情況(非常具體的,很少發生的情況下)。后者常常使我感到驚訝,因為它們可能很早就在項目中被定義為邊角情況,可是后來發現實際上是一些經常發生的情況。這主要是由于不理解系統以及其相互作用夠好才能夠使得最初做出這樣的判斷。
我曾有過此類的經歷,測試一個新的需要處理成千上萬的客戶記錄的應用程序。在測試過程中,我問了一個問題:“是否進行過負載測試?”對此的答復是“哦,這不是問題,它可以輕松地處理高達一百萬條記錄的負載。”然而,當推出了這個改變后,在前幾分鐘有顯著的負載,經過觀察其證明之后會導致嚴重的問題并且對應的代碼會被還原。在那段時間,我并沒有完全理解所涉及的技術,并假定了開發人員比我知道得更清楚,可能已經考慮過這個潛在的問題。從那天起我才知道,當我有直覺某處可能有問題,我不應該認為別人快速而簡單的答案就是真理。我應該從別處尋求可以支持的資料以證實或反駁我的假設。
我的第六感正在提醒!
我把這稱為我的“第六感”啟發,當我對某些東西有一種感覺,比如我不能完全的理解或我所得到的信息看來可疑的情況下,我不愿意就此忽略它并繼續下一步除非我對其有一個合理的認識。在這種情況下,我會讓參與該項目的每個人都知道,我對這部分有所顧慮。這通常會有所幫助因為其他人會開始質疑為什么我會有顧慮;無論是由于我缺乏相關知識使得我的假設是錯誤的,或我的假設是正確的,對我而言都沒關系。重要的是,我明白如果我忽視自己的直覺進行測試,我不認為自己能有效地做好
工作。
容易復制。不容易找到。
通常如果測試需要涵蓋產品或系統的各個方面,其場景數量會高得難以負擔。即使對于看來可以相對簡單的進行測試的系統也可以有數以百萬計的排列。有些辦法可以處理這樣的問題,其中之一被稱為成對(或組合)的測試,我不會在這里來詳述這個方法,但如果你想了解更多,可以看看Michael Bolton所著的對于這個方法的優秀的處理方式。
我對于這一類的問題的經歷是個標準的負面答案,當發現一個問題時,這是100%可復制的。由于只要通過5個簡單的步驟,就次次都可復制,并最終導致“怎么又沒發現這個bug?”的指責。
問題是這樣,基于一個復制系統,該系統有多個文件夾,每一個文件都具有三個不同的使用權限,僅讀取,讀或寫以及拒絕。在每個文件夾中,每個文件都可以有相同的三個文件權限。 我現在更有經驗并愿意挑戰回復其他人提出的意見,如“你為什么沒有發現錯誤?”因此,我設計了一個簡單的場景,說明給定變量的數量有限的測試,測試所有排列所需的時間是巨大的。該方案是這樣的:
三個文件夾的層次結構
每個文件夾包含四個文件
文件夾和文件都可以有不同的權限
覆蓋這個相對簡單情況下所有排列的測試次數為14348907。這是3^15(15個實體與3種狀態)。很明顯,這么大的數字顯示了你是無法在可行的時間內測試完所有排列的。當然,你可以創建一個自動化的測試,以更迅速地完成,但這里的問題是,這種情況甚至不是一個現實世界中真正存在的情況。我僅僅是創建了一個簡單的練習,以顯示要測試這個看似簡單的可復制問題是有多么困難。要知道在現實世界中的客戶會有幾百個文件夾,包含數百或上千個文件的大層次結構。通過交流關于這個簡單的場景很快使我能夠說明為何測試無法發現每一個漏洞,無論在事后它是多么的明顯。
還有什么?
正如已經敘述的這三個真實世界的故事,即使你認為你已經完成了測試而實際你還沒有。有許多原因可以停止測試,但其中并沒有你已完成了所有測試這一理由。我覺得思考我是否錯過了什么是非常寶貴的。有什么是我沒有想到的?有什么是我覺得太明顯了,就對其忽視或認為是不值得考慮?我一般盡量記錄這些問題。有些會得到答案,有些則沒有;但是這并不會阻止我思考具有啟發性的“還有什么?”。
避免令人尷尬的錯誤!
命名您的啟發式方法,讓你可以在未來輕松地回憶起來。
如果你要問如何做,你才可以進行測試,當心——無論是與你的理解還是所給的答案都可能有問題。
創建許多測試的想法。你真的不應該有沒有想法的時候。
想想“假設?”
請注意你的情緒。他們會告訴你一些事情
有新的眼光來看待變化,而不要指示它們要測試的內容。
意識到“沒有人會這么做”的聲明。
與其他測試人員,開發人員,產品經理,市場營銷——所有可用的并有意愿的人合作測試!
在測試中,我們需要大量的實用主義。不管我們使用什么樣的方法來幫助防止檢測失誤,bug總會被漏過。使用啟發方式可以幫助減少總數。
給啟發方式命名或助記符可以幫助您同時記住并利用它們來幫助你早期識別錯誤和防止明顯的錯誤。命名您的啟發方式可以根據自己的個人喜好來完成,因此,如果以上任何一個方法對你有用,請隨意命名并利用它們來幫助你找到那些所謂明顯的錯誤。
作者簡介
Stephen Blower 已經作為測試員在不同的機構工作了18年。目前,身為Ffrees家庭財務的測試經理,他有令人羨慕的位置,能夠從頭開始創建一個測試團隊。他職位的重要部分是激發測試者,而不僅僅是創建流程。Stephen大力鼓勵互動和反饋,并讓測試者獲得控制權,使他們成為發展具有價值的發展團隊的成員。
譯者簡介:大頭,在讀日本九州大學修士,計算機專業,主研究方向為文本挖掘,及自然語言處理。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
代碼測試的立足點是Code,是基于代碼基礎之上的,而傳統的
功能測試和接口測試是基于應用的,必須對應的測試系統是在運行中的。
代碼測試不會特別注重接口測試的可持續性集成。
代碼測試的特點是快捷高效準確的完成測試
工作,快速推進產品的迭代。
(1) 代碼走讀和review
適合場景:邏輯相對簡單,有較多的邊界值。
方法介紹:直接查看和閱讀代碼,檢驗邏輯是否正確。
(2) 代碼debug與代碼運行中測試
適合場景:數據構造比較困難,特殊的場景覆蓋。
方法介紹:1.直接在debug代碼過程中查看數據流走向,校驗邏輯。
2.在debug過程中直接將變量的值或者對象的值直接改成想要的場景
(3) 私有方法測試
適合場景:需要測試的類的復雜邏輯處理是放在一個特定的方法中,而且該方法中沒有使用到其他引用的bean
方法介紹:通過反射的方式調用方法,進行測試。
例子:
假設有一個待測試的類叫MyApp,有一個私有方法叫getSortList, 參數是一個整形List。
/** * Created by yunmu.wgl on 2014/7/16. */ public class MyApp { private List getSortList(List<Integer> srcList){ Collections.sort(srcList); return srcList; } } |
那么測試類的代碼如下:
/** * Created by yunmu.wgl on 2014/7/16. */ public class MyAppTest { @Test public void testMyApp() throws NoSuchMethodException, InvocationTargetException, IllegalAccessException { Class clazz = MyApp.class; Method sortList = clazz.getDeclaredMethod("getSortList",List.class); //獲取待測試的方法 sortList.setAccessible(true); //私有方法這個是關鍵 List<Integer> testList = new ArrayList<Integer>();//構造測試數據 testList.add(1); testList.add(3); testList.add(2); MyApp myApp = new MyApp(); // 新建一個待測試類的對象 sortList.invoke(myApp,testList); //執行測試方法 System.out.println(testList.toString()); //校驗測試結果 } } |
(4) 快速搭建測試腳本環境
適合場景:待測試的方法以hsf提供接口方法,或者需要測試的類引入了其他bean 配置。
方法介紹:直接在開發工程中添加測試依賴,主要是junit,如果是需要測試hsf接口,則加入hsf的依賴,如果需要使用itest的功能,加入itest依賴。
Junit 的依賴一般開發都會加,主要看下junit的版本,最好是4.5 以上
HSF的測試依賴:以前的hsfunit 和hsf.unit 最好都不要使用了。
<dependency>
<groupId>com.taobao.hsf</groupId>
<artifactId>hsf-standalone</artifactId>
<version>2.0.4-SNAPSHOT</version>
</dependency>
Hsf 接口測試代碼示例:
// 啟動HSF容器,第一個參數設置taobao-hsf.sar路徑,第二個參數設置HSF版本
HSFEasyStarter.start("d:/tmp/", "1.4.9.6");
String springResourcePath = "spring-hsf-uic-consumer.xml";
ClassPathXmlApplicationContext ctx = new ClassPathXmlApplicationContext(springResourcePath);
UicReadService uicReadService = (UicReadService) ctx.getBean("uicReadService");
// 等待相關服務的地址推送(等同于sleep幾秒,如果不加,會報找不到地址的錯誤)
ServiceUtil.waitServiceReady(uicReadService);
BaseUserDO user = uicReadService.getBaseUserByUserId(10000L, "detail").getModule();
System.out.println("user[id:10000L] nick:" + user.getNick());
Hsf bean的配置示例:
<beans>
<bean name="uicReadService" class="com.taobao.hsf.app.spring.util.HSFSpringConsumerBean"
init-method="init">
<property name="interfaceName" value="com.taobao.uic.common.service.userinfo.UicReadService" />
<property name="version" value="1.0.0.daily" />
</bean>
</beans>
Itest的依賴:這個版本之前修復了較多的bug。
<dependency>
<groupId>com.taobao.test</groupId>
<artifactId>itest</artifactId>
<version>1.3.2.1-SNAPSHOT</version>
<dependency>
(5) 程序流程圖校驗
適合場景:業務流程的邏輯較為復雜,分支和異常情況很多
方法介紹:根據代碼邏輯畫出業務流程圖,跟實際的業務邏輯進行對比驗證,是否符合預期。
(6) 結對編程
適合場景:代碼改動較小,測試和開發配對比較穩定
方法介紹:開發修改完代碼后,將修改部分的邏輯重復給測試同學,測試同學review 開發同學講述的邏輯是否和代碼的邏輯一致。
3. 具體操作步驟:
(1) checkout代碼,在接手項目和日常后第一件事情是checkout 對應的應用的代碼
(2) 了解數據結構與數據存儲關系:了解應用的數據對象和數據庫的表結構及存儲關系。
(3) 了解代碼結構, 主要搞清楚代碼的調用關系。
(4) 了解業務邏輯和代碼的關系:業務邏輯肯定是在代碼中實現的,找到被測試的業務邏輯對應的代碼,比較常見的是通過url 或者接口名稱等。
如果是webx框架的可以根據http請求找到對應的代碼,如果是其他框架的也可以通過http請求的域名在配置文件中找到對應的代碼。
(5) 閱讀相關代碼,了解數據流轉過程。
(6) Review 代碼,驗證條件,路徑覆蓋。
(7) 復雜邏輯可以選用寫腳本測試或者私有方法測試,或者畫出流程圖。
4. 代碼測試的常見測試場景舉例:
(1) 條件,邊界值,Null 測試:
復雜的多條件,多邊界值如果要手工測試,會測試用例非常多。而且null值的測試往往構造數據比較困難。
例如如下的代碼:
if (mm.getIsRate() == UeModel.IS_RATE_YES) { float r; if (value != null && value.indexOf(‘.’) != -1) { r = currentValue – compareValue; } else { r = compareValue == 0 ? 0 : (currentValue – compareValue) / compareValue; } if (r >= mm.getIncrLowerBound()) { score = mm.getIncrScore(); } else if (r <= mm.getDecrUpperBound()) { score = mm.getDecrScore(); } mr.setIncreaseRate(formatFloat(r)); } else { // 目前停留時間為非比率對比 if (currentValue – compareValue >=mm.getIncrLowerBound()) { score = mm.getIncrScore(); } else if (currentValue – compareValue <= mm.getDecrUpperBound()) { score = mm.getDecrScore(); } } |
(2) 方法測試
某個方法相對比較獨立,但是是復雜的邏輯處理
例如下面的代碼:
private void filtSameItems(List<SHContentDO> contentList) { Set<Integer> sameIdSet = new TreeSet<Integer>(); Set<Integer> hitIdSet = new HashSet<Integer>(); for (int i = 0; i < contentList.size(); i++) { if (sameIdSet.contains(i) || hitIdSet.contains(i)) { continue; } SHContentDO content = contentList.get(i); List<Integer> equals = new ArrayList<Integer>(); equals.add(i); if ("item".equals(content.getSchema())) { for (int j = i + 1; j < contentList.size(); j++) { SHContentDO other = contentList.get(j); if ("item".equals(other.getSchema()) && content.getReferItems().equals(other.getReferItems())) { equals.add(j); } } } if (equals.size() > 1) { Integer hit = equals.get(0); SHContentDO hitContent = contentList.get(hit); for (int k = 1; k < equals.size(); k++) { SHContentDO other = contentList.get(k); if (hitContent.getFinalScore() == other.getFinalScore()) { long hitTime = hitContent.getGmtCreate().getTime(); long otherTime = other.getGmtCreate().getTime(); if (hitTime > otherTime) { hit = equals.get(k); hitContent = other; } } else { if (hitContent.getFinalScore() < other.getFinalScore()) { hit = equals.get(k); hitContent = other; } } } for (Integer tmp : equals) { if (tmp != hit) { sameIdSet.add(tmp); } } hitIdSet.add(hit); } } Integer[] sameIdArray = new Integer[sameIdSet.size()]; sameIdSet.toArray(sameIdArray); for (int i = sameIdArray.length - 1; i >= 0; i--) { contentList.remove((int) sameIdArray[i]); } } |
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
(1)如何進行SQL注入測試?
首先找到帶有參數傳遞的URL頁面,如 搜索頁面,登錄頁面,提交評論頁面等等.
注1:對 于未明顯標識在URL中傳遞參數的,可以通過查看HTML源代碼中的"FORM"標簽來辨別是否還有參數傳遞.在<FORM> 和</FORM>的標簽中間的每一個參數傳遞都有可能被利用.
<form id="form_search" action="/search/" method="get">
<div>
<input type="text" name="q" id="search_q" value="" />
<input name="search" type="image" src="/media/images/site/search_btn.gif" />
<a href="/search/" class="fl">Gamefinder</a>
</div>
</form>
注 2:當你找不到有輸入行為的頁面時,可以嘗試找一些帶有某些參數的特殊的URL,如HTTP://DOMAIN/INDEX.ASP?ID=10
其 次,在URL參數或表單中加入某些特殊的SQL語句或SQL片斷,如在登錄頁面的URL中輸入HTTP://DOMAIN /INDEX.ASP?USERNAME='HI' OR 1=1
注1:根據實際情況,SQL注入請求可以使用以下語句:
' or 1=1- -
" or 1=1- -
or 1=1- -
' or 'a'='a
" or "a"="a
') or ('a'='a
注2:為什么是OR, 以及',――是特殊的字符呢?
例子:在登錄時進行身份驗證時,通常使用如下語句來進行驗證:sql=select * from user where username='username' and pwd='password'
如 輸入http://duck/index.asp?username=admin' or 1='1&pwd=11,SQL語句會變成以下:sql=select * from user where username='admin' or 1='1' and password='11'
' 與admin前面的'組成了一個查詢條件,即username='admin',接下來的語句將按下一個查詢條件來執行.
接 下來是OR查詢條件,OR是一個邏輯運 算符,在判斷多個條件的時候,只要一個成立,則等式就成立,后面的AND就不再時行判斷了,也就是 說我們繞過了密碼驗證,我們只用用戶名就可以登錄.
如 輸入http://duck/index.asp?username=admin'--&pwd=11,SQL語 句會變成以下sql=select * from user where name='admin' --' and pasword='11',
'與admin前面的'組成了一個查 詢條件,即username='admin',接下來的語句將按下一個查詢條件來執行
接下來是"--"查詢條件,“--”是忽略或注釋,上 述通過連接符注釋掉后面的密碼驗證(注:對ACCESS數據庫無 效).
最后,驗證是否能入侵成功或是出錯的信息是否包含關于
數據庫服務器 的相關信息;如果 能說明存在SQL安 全漏洞.
試想,如果網站存在SQL注入的危險,對于有經驗的惡意用戶還可能猜出數據庫表和表結構,并對數據庫表進行增\刪\改的操 作,這樣造成的后果是非常嚴重的.
(2)如何預防SQL注入?
轉義敏感字符及字符串(SQL的敏感字符包括“exec”,”xp_”,”sp_”,”declare”,”Union”,”cmd”,”+”,”//”,”..”,”;”,”‘”,”--”,”%”,”0x”,”><=!-*/()|”,和”空格”).
屏蔽出錯信息:阻止攻擊者知道攻擊的結果
在服務端正式處理之前提交數據的合法性(合法性檢查主要包括三 項:數據類型,數據長度,敏感字符的校驗)進行檢查等。最根本的解決手段,在確認客 戶端的輸入合法之前,服務端拒絕進行關鍵性的處理操作.
從測試人員的角度來講,在程序開發前(即需求階段),我們就應該有意識的將安全性檢查應用到需求測試中,例如對一個表單需求進行檢查時,我們一般檢驗以下幾項安全性問題:
需求中應說明表單中某一FIELD的類型,長度,以及取值范圍(主要作用就是禁止輸入敏感字符)
需求中應說明如果超出表單規定的類型,長度,以及取值范圍的,應用程序應給出不包含任何代碼或數據庫信息的錯誤提示.
當然在執行測試的過程中,我們也需求對上述兩項內容進行測試.
2.Cross-site scritping(XSS):(跨站點腳本攻擊)
(1)如何進行XSS測試?
<!--[if !supportLists]-->首先,找到帶有參數傳遞的URL,如 登錄頁面,搜索頁面,提交評論,發表留言 頁面等等。
<!--[if !supportLists]-->其次,在頁面參數中輸入如下語句(如:Javascrīpt,VB scrīpt, HTML,ActiveX, Flash)來進行測試:
<scrīpt>alert(document.cookie)</scrīpt>
最后,當用戶瀏覽 時便會彈出一個警告框,內容顯示的是瀏覽者當前的cookie串,這就說明該網站存在XSS漏洞。
試想如果我們注入的不是以上這個簡單的測試代碼,而是一段經常精心設計的惡意腳本,當用戶瀏覽此帖時,cookie信息就可能成功的被 攻擊者獲取。此時瀏覽者的帳號就很容易被攻擊者掌控了。
(2)如何預防XSS漏洞?
從應用程序的角度來講,要進行以下幾項預防:
對Javascrīpt,VB scrīpt, HTML,ActiveX, Flash等 語句或腳本進行轉義.
在 服務端正式處理之前提交數據的合法性(合法性檢查主要包括三項:數據類型,數據長度,敏感字符的校驗)進行檢查等。最根本的解決手段,在確認客戶端的輸入合法之前,服務端 拒絕進行關鍵性的處理操作.
從測試人員的角度來講,要從需求檢查和執行測試過程兩個階段來完成XSS檢查:
在需求檢查過程中對各輸入項或輸出項進行類型、長度以及取 值范圍進行驗證,著重驗證是否對HTML或腳本代碼進行了轉義。
執行測試過程中也應對上述項進行檢查。
3.CSRF:(跨站點偽造請求)
CSRF盡管聽起來像跨站腳本(XSS),但它與XSS非常不同,并且攻擊方式幾乎相左。
XSS是利用站點內的信任用戶,而CSRF則通過偽裝來自受信任用戶的請求來利用受信任的網站。
XSS也好,CSRF也好,它的目的在于竊取用戶的信息,如SESSION 和 COOKIES,
(1)如何進行CSRF測試?
目前主要通過安全性測試工具來進行檢查。
(2)如何預防CSRF漏洞?
這個我們在這就不細談了
4.Email Header Injection(郵件標頭注入)
Email Header Injection:如果表單用于發送email,表單中可能包括“subject”輸入項(郵件標題),我們要驗證subject中應能escape掉“\n”標識。
<!--[if !supportLists]--><!--[endif]-->因為“\n”是新行,如果在subject中輸入“hello\ncc:spamvictim@example.com”,可能會形成以下
Subject: hello
cc: spamvictim@example.com
<!--[if !supportLists]--><!--[endif]-->如果允許用戶使用這樣的subject,那他可能會給利用這個缺陷通過我們的平臺給其它用 戶發送垃圾郵件。
5.Directory Traversal(目錄遍歷)
(1)如何進行目錄遍歷測試?
目錄遍歷產生的原因是:程序中沒有過濾用戶輸入的“../”和“./”之類的目錄跳轉符,導致惡意用戶可以通過提交目錄跳轉來遍歷服務器上的任意文件。
測試方法:在URL中輸入一定數量的“../”和“./”,驗證系統是否ESCAPE掉了這些目錄跳轉符。
(2)如何預防目錄遍歷?
限制Web應用在服務器上的運行
進 行嚴格的輸入驗證,控制用戶輸入非法路徑
6.exposed error messages(錯誤信息)
(1)如何進行測試?
首 先找到一些錯誤頁面,比如404,或500頁面。
驗證在調試未開通過的情況下,是否給出了友好的錯誤提示信息比如“你訪問的頁面不存 在”等,而并非曝露一些程序代碼。
(2)如何預防?
測試人員在進行需求檢查時,應該對出錯信息 進行詳細查,比如是否給出了出錯信息,是否給出了正確的出錯信息。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters
簡介
本文主要關注
SQL注入,假設讀者已經了解一般的SQL注入技術,在我之前的
文章中有過介紹,即通過輸入不同的參數,等待服務器的反應,之后通過不同的前綴和后綴(suffix and prefix )注入到
數據庫。本文將更進一步,討論SQL盲注,如果讀者沒有任何相關知識儲備,建議先去wikipedia學習一下。在繼續之前需要提醒一下,如果讀者也想要按本文的步驟進行,需要在NOWASP Mutillidae環境搭建好之后先注冊一個NOWASP Mutillidae帳號。
SQL注入前言
本文演示從
web界面注入SQL命令的方法,但不會直接連接到數據庫,而是想辦法使后端數據庫處理程序將我們的查詢語句當作SQL命令去執行。本文先描述一些注入基礎知識,之后講解盲注的相關內容。
Show Time
這里我以用戶名“jonnybravo”和密碼“momma”登錄,之后進入用戶查看頁面,位于OWASP 2013 > A1 SQL Injection > Extract data > User Info。要查看用戶信息,需要輸入用戶ID與密碼登錄,之后就可以看到當前用戶的信息了。
如我之前的文章所提到的那樣,這個頁面包含SQL注入漏洞,所以我會嘗試各種注入方法來操縱數據庫,需要使用我之前文章提到的后綴(suffix)與前綴(prefix)的混合。這里我使用的注入語句如下:
Username: jonnybravo’ or 1=1; –
該注入語句要做的就是從數據庫查詢用戶jonnybravo,獲取數據后立刻終止查詢(利用單引號),之后緊接著一條OR語句,由于這是一條“if狀態”查詢語句,而且這里給出 “or 1=1”,表示該查詢永遠為真。1=1表示獲取數據庫中的所有記錄,之后的;–表示結束查詢,告訴數據庫當前語句后面沒有其它查詢語句了。
圖1 正常方式查看用戶信息
將payload注入后,服務器泄露了數據庫中的所有用戶信息。如圖2所示:
圖2 注入payload導致數據庫中所有數據泄露
至此,本文向讀者演示了一種基本SQL注入,下面筆者用BackTrack和Samurai 等滲透
測試發行版中自帶的SQLmap工具向讀者演示。要使用SQLmap,只需要打開終端,輸入SQLmap并回車,如下圖所示:
如果讀者首次使用SQLmap,不需要什么預先操作。如果已經使用過該工具,需要使用—purge-output選項將之前的輸出文件刪除,如下圖所示:

圖3 將SQLmap output目錄中的原輸出文件刪除
本文會演示一些比較獨特的操作。通常人們使用SQLmap時會直接指定URL,筆者也是用該工具分析請求,但會先用Burp查看請求并將其保存到一個文本文件中,之后再用SQLmap工具調用該文本文件進行掃描。以上就是一些準備工作,下面首先就是先獲取一個請求,如下所示:
GET /chintan/index.php?page=user-info.php&username=jonnybravo&password=
momma&user-info-php-submit-button=View+Account+Details HTTP/1.1
Host: localhost
User-Agent: Mozilla/5.0 (Windows NT 5.1; rv:27.0) Gecko/20100101 Firefox/27.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Referer: http://localhost/chintan/index.php?page=user-info.php
Cookie: showhints=0; username=jonnybravo; uid=19; PHPSESSID=f01sonmub2j9aushull1bvh8b5
Connection: keep-alive
將該請求保存到一個文本文件中,之后發送到KALI linux中,用如下命令將該請求頭部傳給SQLmap:
SQLmap –r ~/root/Desktop/header.txt
命令中-r選項表示要讀取一個包含請求的文件,~/root/Desktop/header.txt表示文件的位置。如果讀者用VMware,例如在Windows上用虛擬機跑KALI,執行命令時可能產生如下圖所示的錯誤提示:
這里必須在請求頭中指定一個IP地址,使KALI linux能與XP正常通信,修改如下圖所示:
之后命令就能正常執行了,顯示結果如下圖所示:
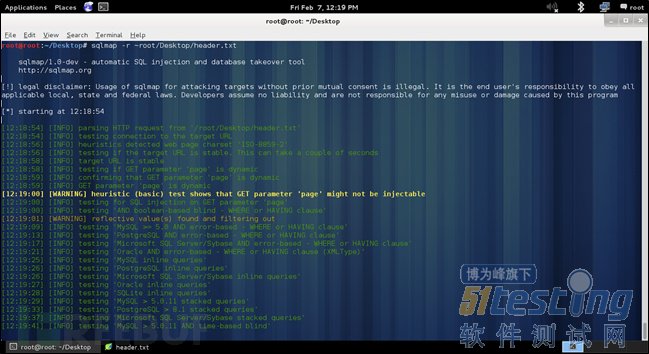
基本上該工具做的就是分析請求并確定請求中的第一個參數,之后對該參數進行各種測試,以確定服務器上運行的數據庫類型。對每個請求,SQLmap都會對請求中的第一個參數進行各種測試。
GET /chintan/index.php?page=user-info.php&username=jonnybravo&password=momma&user-
info-php-submit-button=View+Account+Details HTTP/1.1
SQLmap可以檢測多種數據庫,如MySQL、Oracle SQL、PostgreSQL、Microsoft SQL Server等。
下圖是筆者系統中SQLmap正在對指定的請求進行檢測時顯示的數據庫列表:
首先它會確定給定的參數是否可注入。根據本文演示的情況,我們已經設置OWASP mutillidae的安全性為0,因此這里是可注入的,同時SQLmap也檢測到后臺數據庫DBMS可能為MYSQL。
如上圖所示,工具識別后臺數據庫可能為MYSQL,因此提示用戶是否跳過其它類型數據庫的檢測。
“由于本文在演示之前已經知道被檢測數據庫是MYSQL,因此這里選擇跳過對其它類型數據庫的檢測。”
之后詢問用戶是否引入(include)測試MYSQL相關的所有payload,這里選擇“yes”選項:
測試過一些payloads之后,工具已經識別出GET參數上一個由錯誤引起的注入問題和一個Boolean類型引起的盲注問題。
之后顯示該GET參數username是一個基于MYSQL union(union-based)類型的查詢注入點,因此這里跳過其它測試,深入挖掘已經找出的漏洞。
至此,工具已經識別出應該深入挖掘的可能的注入點:
接下來,我把參數username傳遞給SQLmap工具,以對其進行深入挖掘。通過上文描述的所有注入點和payloads,我們將對username參數使用基于Boolean的SQL盲注技術,通過SQLmap中的–technique選項實現。其中選擇如下列表中不同的選項表示選用不同的技術:
B : 基于Boolean的盲注(Boolean based blind)
Q : 內聯查詢(Inline queries)
T : 基于時間的盲注(time based blind)
U : 基于聯合查詢(Union query based)
E : 基于錯誤(error based)
S : 棧查詢(stack queries)
本例中也給出了參數名“username”,因此最后構造的命令如下:
SQLmap –r ~root/Desktop/header.txt – -technique B – -p username – -current-user
這里-p選項表示要注入的參數,“–current-user“選項表示強制SQLmap查詢并顯示登錄MYSQL數據庫系統的當前用戶。命令得到輸出如下圖所示:
同時也可以看到工具也識別出了操作系統名,DBMS服務器以及程序使用的編程語言。
“”當前我們所做的就是向服務器發送請求并接收來自服務器的響應,類似客戶端-服務器端模式的交互。我們沒有直接與數據庫管理系統DBMS交互,但SQLmap可以仍識別這些后臺信息。
同時本次與之前演示的SQL注入是不同的。在前一次演示SQL注入中,我們使用的是前綴與后綴,本文不再使用這種方法。之前我們往輸入框中輸入內容并等待返回到客戶端的響應,這樣就可以根據這些信息得到切入點。本文我們往輸入框輸入永遠為真的內容,通過它判斷應用程序的響應,當作程序返回給我們的信息。“
結果分析
我們已經給出當前的用戶名,位于本機,下面看看它在后臺做了什么。前文已經說過,后臺是一個if判斷語句,它會分析該if查詢,檢查username為jonnybravo且7333=7333,之后SQLmap用不同的字符串代替7333,新的請求如下:
page=user-info.php?username=’jonnybravo’ AND ‘a’='a’ etc..FALSE
page=user-info.php?username=’jonnybravo’ AND ‘l’='l’ etc..TRUE
page=user-info.php?username=’jonnybravo’ AND ‘s’='s’ etc..TRUE
page=user-info.php?username=’jonnybravo’ AND ‘b’='b’ etc..FALSE
如上所示,第一個和最后一個查詢請求結果為假,另兩個查詢請求結果為真,因為當前的username是root@localhost,包含字母l和s,因此這兩次查詢在查詢字母表時會給出包含這兩個字母的用戶名。
“這就是用來與web服務器驗證的SQL server用戶名,這種情況在任何針對客戶端的攻擊中都不應該出現,但我們讓它發生了。”
去掉了–current-user選項,使用另外兩個選項-U和–password代替。-U用來指定要查詢的用戶名,–password表示讓SQLmap去獲取指定用戶名對應的密碼,得到最后的命令如下:
SQLmap -r ~root/Desktop/header.txt --technique B -p username -U root@localhost --passwords
命令輸出如下圖所示:
Self-Critical Evaluation
有時可能沒有成功獲取到密碼,只得到一個NULL輸出,那是因為系統管理員可能沒有為指定的用戶設定認證信息。如果用戶是在本機測試,默認情況下用戶root@localhost是沒有密碼的,需要使用者自己為該用戶設置密碼,可以在MySQL的user數據表中看到用戶的列表,通過雙擊password區域來為其添加密碼。或者可以直接用下圖所示的命令直接更新指定用戶的密碼:
這里將密碼設置為“sysadmin“,這樣SQLmap就可以獲取到該密碼了,如果不設置的話,得到的就是NULL。
通過以上方法,我們不直接與數據庫服務器通信,通過SQL注入得到了管理員的登錄認證信息。
總結
本文描述的注入方法就是所謂的SQL盲注,這種方法更繁瑣,很多情況下比較難以檢測和利用。相信讀者已經了解傳統SQL注入與SQL盲注的不同。在本文所處的背景下,我們只是輸入參數,看其是否以傳統方式響應,之后憑運氣嘗試注入,與之前演示的注入完全是不同的方式。
English » | | | | | | | | |
Text-to-speech function is limited to 100 characters