2006年4月24日
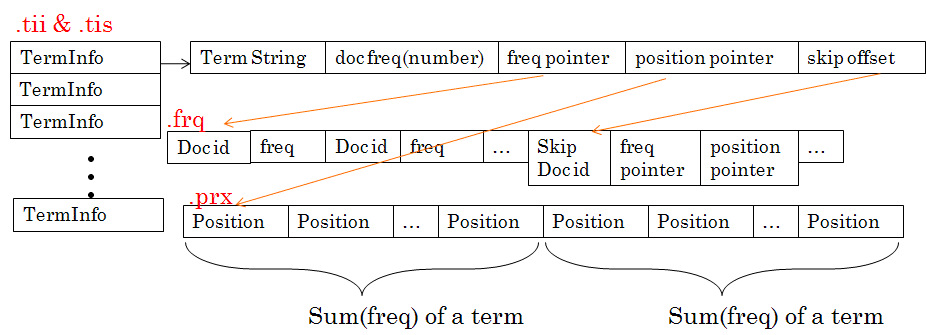
反向索引:
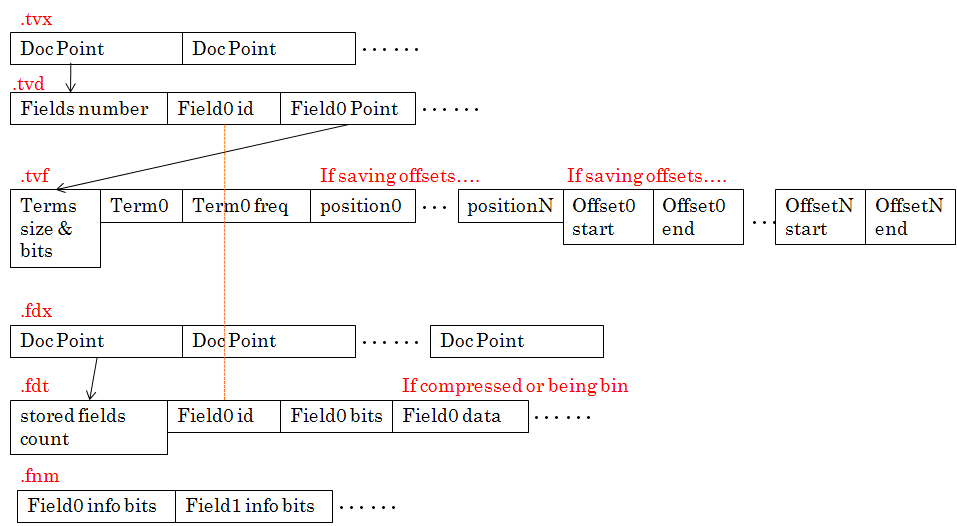
正向索引(草稿,不完全,因?yàn)槭盏絝ield info的影響,不同的field存儲(chǔ)內(nèi)容不同,且fieldInfo的有些信息,TOKENIZED BINARY COMPRESSED也是保存在.fdt的每個(gè)document相關(guān)段的bits中,而不是.fnm中):
Lucene在1.9版本的時(shí)候就已經(jīng)加入了對(duì)GCJ的支持,利用GCJ編譯Lucene,并且使用新的GCJIndexInput.java讀寫(xiě)文件系統(tǒng),
直接調(diào)用操作系統(tǒng)級(jí)別的native方法,相信讀寫(xiě)性能能夠極大得提高啊。
具體代碼可見(jiàn)Lucene的gcj目錄,編譯使用ant gcj
說(shuō)明見(jiàn)Similarity.java的javadoc信息:
算法請(qǐng)參考javadoc的,它使用的是Vector Space Model (VSM) of Information Retrieval。
針對(duì)一條查詢語(yǔ)句q(query),一個(gè)d(document)的得分公式
其中,
tf(t in d) 表示某個(gè)term的出現(xiàn)頻率,定義了term t出現(xiàn)在當(dāng)前地document d的次數(shù)。 那些query中給定地term,如果出現(xiàn)越多次的,得分越高 。它在默認(rèn)實(shí)現(xiàn)DefaultSimilarity的公式為
idf(t) 表示反向文檔頻率。這個(gè)參數(shù)表示docFreq(term t一共在多少個(gè)文檔中出現(xiàn))的反向影響值。它意味著在越少文檔中出現(xiàn)的terms貢獻(xiàn)越高地分?jǐn)?shù)。它在默認(rèn)實(shí)現(xiàn)DefaultSimilarity的公式為:
idf(t) = |
1 + log ( |
| numDocs |
| ––––––––– |
| docFreq+1 |
|
) |
coord(q,d) 是一個(gè)基于在該文檔中出現(xiàn)了多少個(gè)query中的terms的得分 因素。文檔中出現(xiàn)的query中的terms數(shù)量/query總共多少個(gè)query數(shù)量。典型的,一個(gè)文檔包含越多地query中的terms會(huì)得到更高地分。This is a search time factor computed in coord(q,d) by the Similarity in effect at search time.
queryNorm(q) 是一個(gè)標(biāo)準(zhǔn)化參數(shù),它是用來(lái)區(qū)分比較不同queries時(shí)的因素,這個(gè)因素不影響document ranking (因?yàn)樗械膔anked document都會(huì)乘以相同的值),但是不同地queries(或這不同地indexes中)它會(huì)得到不同的可用于比較的值。This is a search time factor computed by the Similarity in effect at search time. 它在默認(rèn)實(shí)現(xiàn)DefaultSimilarity的公式為:
其中的sumOfSquaredWeights(of the query terms)是根據(jù)the query Weight object計(jì)算出來(lái)的. For example, a boolean query computes this value as:
t.getBoost() 是一個(gè)term t在query q中的search time boost, 它是在the query text (see query syntax)中指定的, 或者被應(yīng)用程序直接調(diào)用 setBoost()設(shè)置的. 注意,這兒沒(méi)有直接的API去訪問(wèn)在 a multi term query的一個(gè)term的boost值,但是multi terms會(huì)以multi TermQuery objects在一個(gè)query中被表示,因此the boost of a term in the query可以使用子query的 getBoost()反問(wèn)到.
norm(t,d) 封裝(encapsulates)了一些(indexing time)的boost和length factors: ???這個(gè)參數(shù)之和field中tokens的數(shù)量有關(guān),和term本身無(wú)關(guān)???
Document boost - set by calling doc.setBoost() before adding the document to the index.
Field boost - set by calling field.setBoost() before adding the field to a document.
lengthNorm(field) -。當(dāng)文檔被加入到索引時(shí)計(jì)算,,和document的field 中的tokens的數(shù)量有關(guān),因此,一個(gè)比較短的fields貢獻(xiàn)更高的分?jǐn)?shù)。LengthNorm is computed by the Similarity class in effect at indexing. DefaultSimilarity中的實(shí)現(xiàn)為(float)(1.0 / Math.sqrt(numTerms));
當(dāng)一個(gè)文檔被加入索引時(shí),上述因素會(huì)被相乘。如果文檔有多個(gè)fields同名,他們的boosts數(shù)值會(huì)被多次相乘。
但是 ,計(jì)算出的norm數(shù)值在存儲(chǔ)時(shí)是使用一個(gè)a single byte編碼的。search時(shí),這個(gè)norm byte從index directory讀取,并且被解碼回float。這個(gè)編碼/解碼算法會(huì)產(chǎn)生精度丟失。 - it is not guaranteed that decode(encode(x)) = x. For instance, decode(encode(0.89)) = 0.75. Also notice that search time is too late to modify this norm part of scoring, e.g. by using a different Similarity for search.
Lucene的索引文件,會(huì)包含很多個(gè)segments文件,每個(gè)segment中包含多個(gè)documents文件,一個(gè)segment中會(huì)有完整的正向索引和反向索引。
在搜索時(shí),Lucene會(huì)遍歷這些segments,以segments為基本單位獨(dú)立搜索每個(gè)segments文件,而后再把搜索結(jié)果合并。
建立索引文件的過(guò)程,實(shí)際就是把documents文件一個(gè)個(gè)加入索引中,Lucene的做法是最開(kāi)始為每個(gè)新加入的document獨(dú)立生成一個(gè)segment,放在內(nèi)存中。而后,當(dāng)內(nèi)存中segments數(shù)量到達(dá)一個(gè)闕值時(shí),合并這些segments,新生成一個(gè)segment加入文件系統(tǒng)的segments列表中。
而當(dāng)文件系統(tǒng)的segments數(shù)量過(guò)多時(shí),勢(shì)必影響搜索效率,因此需要不斷合并這些segments文件。
那么Lucene的合并策略是什么?如何保證合適的segments數(shù)量呢?
其實(shí)Lucene有兩套基本的策略:
第一種策略實(shí)現(xiàn)代碼位于IndexWriter#optimize()函數(shù),其實(shí)就是把所有segments文件合并成一個(gè)文件。合并的算法是遞歸合并列表最后的mergeFactor個(gè)segments文件直到合并成一個(gè)文件。這兒mergeFactor是Lucene的一個(gè)參數(shù)。
btw: 從算法細(xì)節(jié)上看,其實(shí)我不是喜歡這段實(shí)現(xiàn),因?yàn)榱斜淼淖詈髆ergeFactor個(gè)文件內(nèi)容實(shí)際被掃描了segmens_count/mergeFactor次。如果分段歸納合并的方式不知道是否更好,每個(gè)segment文件內(nèi)容都將被掃描 ceil(Log_mergeFactor(segmens_count)) 或ceil(Log_mergeFactor(segmens_count)) +1次,是否更好?
第二種策略實(shí)現(xiàn)代碼位于IndexWriter#maybeMergeSegments()函數(shù)中,這個(gè)代碼就復(fù)雜了,它的基本策略就是要求確保合并后兩個(gè)公式的成立:
假定segments是個(gè)有序列表,B表示maxBufferedDocs,f(n)=ceil(log_M(ceil(n/B))),M表示mergeFactor,這兒maxBufferedDocs和mergeFactor是兩個(gè)參數(shù)
1. 如果第i個(gè)segment的documents數(shù)量為x,第i+1個(gè)segment的documents數(shù)量為y,那么f(x)>f(y)一定成立
2. f(n)值相同的segments的數(shù)量不得超過(guò)M。
那么maybeMergeSegments()函數(shù)是如何確保這兩個(gè)公式成立的呢?
1.首先,從代碼:
protected final void maybeFlushRamSegments() throws IOException {
// A flush is triggered if enough new documents are buffered or
// if enough delete terms are buffered
if (ramSegmentInfos.size() >= minMergeDocs
|| numBufferedDeleteTerms >= maxBufferedDeleteTerms) {
flushRamSegments();
}
}
這兒minMergeDocs=maxBufferedDocs, 因此可以看出,當(dāng)內(nèi)存中緩存的segments被合并寫(xiě)回磁盤(pán)時(shí)生成的segment的document count等于或小于maxBufferedDocs(即minMergeDocs)。
補(bǔ)充:因?yàn)閙aybeMergeSegments()運(yùn)行在同步代碼中,因此只要ramSegmentInfos.size==minMergerDocs(即maxBufferedDocs)就會(huì)寫(xiě)回磁盤(pán),因此應(yīng)該不存在ramSegmentInfos.size>maxBufferedDocs才寫(xiě)回的情況。而且,但如果是這種情況,因?yàn)楹喜⒑蟮膕egment文件的document count過(guò)大,后面的maybeMergeSegments()將不做合并處理直接退出,上述公式就可能不成立,那么算法將有錯(cuò)。
----
2.
2.1 因此maybeMergeSegments()第一次執(zhí)行時(shí),所有segments的document count都小于等于maxBufferedDocs。此時(shí),從i=0開(kāi)始,合并i~i+mergeFactor-1個(gè)文件,如果合并后的doc count>maxBufferedDocs時(shí),保留第i個(gè)segment,否則繼續(xù)合并改變后的i~i+mergeFactor-1,直到doc count>maxBufferedDocs或所有segments文件個(gè)數(shù)已經(jīng)<mergeFactor了。經(jīng)過(guò)這樣一輪的合并,除了最后<mergeFactor個(gè)的doc counts<=maxBufferedDocs文件外,其它文件的doc counts一定都>maxBufferedDocs并<maxBufferedDocs*mergeFactor了。
2.2 這時(shí),不理會(huì)最后<mergeFactor個(gè)doc count<maxBufferedDocs的文件,而后按2.1的同理規(guī)則,合并之前的文件,讓這些文件的最后<mergerFactor個(gè)segment符合 maxBufferedDocs<doc counts<=maxBufferedDocs*mergeFactor,之前的segment文件都符合maxBufferedDocs*mergeFactor<doc counts<=maxBufferedDocs*mergeFactor^2
2.3 重復(fù)2.2,最后得到的列表就會(huì)滿足上述兩等式的成立
---
3
之后,每次從內(nèi)存緩存中flush出一個(gè)新的segment時(shí),也就是往這個(gè)segments列表的最后增加一個(gè)doc_count<=maxBufferedDocs的文件,同樣執(zhí)行上述步驟2進(jìn)行合并,能夠始終保證上述兩公式的成立。
----
4
4.1
IndexWriter#addIndexesNoOptimize同樣借鑒使用了maybeMergeSegments()算法,區(qū)別此時(shí),實(shí)際是已有一個(gè)符合兩公式的segments序列T,在T之后追加上隨意順序的segments序列S。這時(shí),我們先找到S中doc count值最大的那個(gè)segment,計(jì)算出它屬于的區(qū)間f(x),使得maxBufferedDocs*mergeFactor^x<doc counts<=maxBufferedDocs*mergeFactor^(x+1),而后按2.2的算法合并出除了最后<mergerFactor個(gè)segments外, 之前所有segments都符合 a. doc count>maxBufferedDocs*mergeFactor^(x+1) b.符合上述2等式。
btw: 因?yàn)檫@兒調(diào)用IndexWriter#addIndexesNoOptimize傳入的參數(shù)是maxBufferedDocs*mergeFactor^(x+1),因?yàn)镾所有segment的doc count都一定小于maxBufferedDocs*mergeFactor^(x+1),因此S的所有元素都會(huì)參與收縮合并。
4.2 將最后<mergerFactor個(gè)doc count<maxBufferedDocs*mergeFactor^(x+1)的segments合并,如果合并后的segment的doc count大于maxBufferedDocs*mergeFactor^(x+1),就繼續(xù)2.2步驟,使得整個(gè)隊(duì)列符合上述兩公式
-----
上述兩種策略,最終確保了Lucene中的segments不會(huì)太多,確保效率。
BTW:實(shí)際上,如果documents太多時(shí),Lucene還支持把docuements分成幾個(gè)組,每個(gè)組用獨(dú)立的進(jìn)程或電腦進(jìn)行索引,而后再多個(gè)目錄的索引合并起來(lái),具體可參考IndexWriter#addIndexesNoOptimize和IndexWriter#addIndexes函數(shù)
FieldSelectorResult:枚舉,分別為
LOAD Document#getFieldable和Document#getField不會(huì)返回null
LAZY_LOAD :Lazy的Field意味著在搜索結(jié)果里這個(gè)Field的值缺省是不讀取的,只有當(dāng)你真正對(duì)這個(gè)Field取值的時(shí)候才會(huì)去取。所以如果你要對(duì)它取值,你得保證IndexReader還沒(méi)有close。 Document#getField不能使用,只能使用Document#getFieldable
NO_LOAD Document#getField和Document#getFieldable都返回null,Document#add不被調(diào)用。
LOAD_AND_BREAK 類似LOAD,Document#getField和Document#getFieldable都可用,但返回后就結(jié)束,Document可能沒(méi)有完整的field的Set,參考LoadFirstFieldSelector 。
LOAD_FOR_MERGE 類似LOAD,但不壓縮任何數(shù)據(jù)。只被SegmentMerger的一個(gè)FieldSelector匿名內(nèi)嵌實(shí)現(xiàn)類使用。Document#getField和Document#getFieldable可返回null.
SIZE 返回Field的size而不是value. Size表示存儲(chǔ)這個(gè)field需要的bytes數(shù),string數(shù)值使用2*chars。size被存儲(chǔ)為a binary value,表現(xiàn)為as an int in a byte[],with the higher order byte first in [0]。
SIZE_AND_BREAK 類似SIZE,但立刻break from the field loading loop, i.e. stop loading further fields, after the size is loaded
======================================
Field中三大enum: Store Index和TermVector:
------------------------------------
Store.COMPRESS Store the original field value in the index in a compressed form. This is useful for long documents and for binary valued fields.壓縮存儲(chǔ);
Store.YES Store the original field value in the index. This is useful for short texts like a document's title which should be displayed with the results. The value is stored in its original form, i.e. no analyzer is used before it is stored. 索引文件本來(lái)只存儲(chǔ)索引數(shù)據(jù), 此設(shè)計(jì)將原文內(nèi)容直接也存儲(chǔ)在索引文件中,如文檔的標(biāo)題。
Store.NO Do not store the field value in the index. 原文不存儲(chǔ)在索引文件中,搜索結(jié)果命中后,再根據(jù)其他附加屬性如文件的Path,數(shù)據(jù)庫(kù)的主鍵等,重新連接打開(kāi)原文,適合原文內(nèi)容較大的情況。
決定了Field對(duì)象的 this.isStored 和 this.isCompressed
------------------------------------
Index.NO Do not index the field value. This field can thus not be searched, but one can still access its contents provided it is Field.Store stored. 不進(jìn)行索引,存放不能被搜索的內(nèi)容如文檔的一些附加屬性如文檔類型, URL等。
Index.TOKENIZED Index the field's value so it can be searched. An Analyzer will be used to tokenize and possibly further normalize the text before its terms will be stored in the index. This is useful for common text. 分詞索引
Index.UN_TOKENIZED Index the field's value without using an Analyzer, so it can be searched. As no analyzer is used the value will be stored as a single term. This is useful for unique Ids like product numbers. 不分詞進(jìn)行索引,如作者名,日期等,Rod Johnson本身為一單詞,不再需要分詞。
Index.NO_NORMS 不分詞,建索引。norms是什么???字段值???。但是Field的值不像通常那樣被保存,而是只取一個(gè)byte,這樣節(jié)約存儲(chǔ)空間???? Index the field's value without an Analyzer, and disable the storing of norms. No norms means that index-time boosting and field length normalization will be disabled. The benefit is less memory usage as norms take up one byte per indexed field for every document in the index.Note that once you index a given field <i>with</i> norms enabled, disabling norms will have no effect. In other words, for NO_NORMS to have the above described effect on a field, all instances of that field must be indexed with NO_NORMS from the beginning.
決定了Field對(duì)象的 this.isIndexed this.isTokenized this.omitNorms
------------------------------------
Lucene 1.4.3新增的:
TermVector.NO Do not store term vectors. 不保存term vectors
TermVector.YES Store the term vectors of each document. A term vector is a list of the document's terms and their number of occurences in that document. 保存term vectors。
TermVector.WITH_POSITIONS Store the term vector + token position information 保存term vectors。(保存值和token位置信息)
TermVector.WITH_OFFSETS Store the term vector + Token offset information
TermVector.WITH_POSITIONS_OFFSETS Store the term vector + Token position and offset information 保存term vectors。(保存值和Token的offset)
決定了Field對(duì)象的this.storeTermVector this.storePositionWithTermVector this.storeOffsetWithTermVector
以下內(nèi)容均為轉(zhuǎn)載,url見(jiàn)具體鏈接:
最常見(jiàn)的四個(gè)Analyzer,說(shuō)明: http://windshowzbf.bokee.com/3016397.html
WhitespaceAnalyzer 僅僅是去除空格,對(duì)字符沒(méi)有l(wèi)owcase化,不支持中文
SimpleAnalyzer :功能強(qiáng)于WhitespaceAnalyzer,將除去letter之外的符號(hào)全部過(guò)濾掉,并且將所有的字符lowcase化,不支持中文
StopAnalyzer: StopAnalyzer的功能超越了SimpleAnalyzer,在SimpleAnalyzer的基礎(chǔ)上.增加了去除StopWords的功能,不支持中文.類中使用一個(gè)static數(shù)組保存了ENGLISH_STOP_WORDS, 太常見(jiàn)不index的words
StandardAnalyzer: 用Javacc定義的一套EBNF,嚴(yán)禁的語(yǔ)法。有人說(shuō)英文的處理能力同于StopAnalyzer.支持中文采用的方法為單字切分。未仔細(xì)比較,不敢確定。
其他的擴(kuò)展:
ChineseAnalyzer:來(lái)自于Lucene的sand box.性能類似于StandardAnalyzer,缺點(diǎn)是不支持中英文混和分詞.
CJKAnalyzer:chedong寫(xiě)的CJKAnalyzer的功能在英文處理上的功能和StandardAnalyzer相同.但是在漢語(yǔ)的分詞上,不能過(guò)濾掉標(biāo)點(diǎn)符號(hào),即使用二元切分
TjuChineseAnalyzer: http://windshowzbf.bokee.com/3016397.html寫(xiě)的,功能最為強(qiáng)大.TjuChineseAnlyzer的功能相當(dāng)強(qiáng)大,在中文分詞方面由于其調(diào)用的為ICTCLAS的java接口.所以其在中文方面性能上同與ICTCLAS.其在英文分詞上采用了Lucene的StopAnalyzer,可以去除 stopWords,而且可以不區(qū)分大小寫(xiě),過(guò)濾掉各類標(biāo)點(diǎn)符號(hào).
例子:
http://www.langtech.org.cn/index.php/uid-5080-action-viewspace-itemid-68, 還有簡(jiǎn)單的代碼分析
Analyzing "The quick brown fox jumped over the lazy dogs"
WhitespaceAnalyzer:
[The] [quick] [brown] [fox] [jumped] [over] [the] [lazy] [dogs]
SimpleAnalyzer:
[the] [quick] [brown] [fox] [jumped] [over] [the] [lazy] [dogs]
StopAnalyzer:
[quick] [brown] [fox] [jumped] [over] [lazy] [dogs]
StandardAnalyzer:
[quick] [brown] [fox] [jumped] [over] [lazy] [dogs]
Analyzing "XY&Z Corporation - xyz@example.com"
WhitespaceAnalyzer:
[XY&Z] [Corporation] [-] [xyz@example.com]
SimpleAnalyzer:
[xy] [z] [corporation] [xyz] [example] [com]
StopAnalyzer:
[xy] [z] [corporation] [xyz] [example] [com]
StandardAnalyzer:
[xy&z] [corporation] [xyz@example.com]
參考連接:
http://macrochen.blogdriver.com/macrochen/1167942.html
http://macrochen.blogdriver.com/macrochen/1153507.html
http://my.dmresearch.net/bbs/viewthread.php?tid=8318
http://windshowzbf.bokee.com/3016397.html
推薦
http://gceclub.sun.com.cn/developer/technicalArticles/Intl/Supplementary/index_zh_CN.html
http://www.linuxpk.com/3821.html
=======================================
BMP的解釋:
http://zh.wikipedia.org/w/index.php?title=%E5%9F%BA%E6%9C%AC%E5%A4%9A%E6%96%87%E7%A8%AE%E5%B9%B3%E9%9D%A2&variant=zh-cn
http://zh.wikipedia.org/w/index.php?title=%E8%BE%85%E5%8A%A9%E5%B9%B3%E9%9D%A2&variant=zh-cn#.E7.AC.AC.E4.B8.80.E8.BC.94.E5.8A.A9.E5.B9.B3.E9.9D.A2
1個(gè)BMP和16個(gè)輔助plane,需要21個(gè)bits.
======================================
ISO-10646與Unicode關(guān)系
http://zh.wikipedia.org/wiki/%E9%80%9A%E7%94%A8%E5%AD%97%E7%AC%A6%E9%9B%86
ISO-10646術(shù)語(yǔ)
|
Unicode術(shù)語(yǔ)
|
| UCS-2 |
BMP UTF-16 |
| UCS-4 |
UTF-32 |
|
|
注意:UTF-16可看成是UCS-2的 父集。在沒(méi)有輔助平面字符前,UTF-16與UCS-2所指的是同一的意思。但當(dāng)引入輔助平面字符後,就只稱為UTF-16了,因?yàn)槲覀儠?huì)使用2個(gè)UTF-16,也就似乎4bytes保存一個(gè)輔助平面字符。現(xiàn)在若有軟件聲稱自己支援UCS-2編碼,那其實(shí)是暗指它不能支援輔助平面字符的委婉語(yǔ)。
======================================
UTF-8要完整表達(dá)unicode需要4bytes,表達(dá)BMP需要3bytes,見(jiàn) http://en.wikipedia.org/wiki/UTF-8,注意“The range D800-DFFF is disallowed by Unicode. The encoding scheme reliably transforms values in that range, but they are not valid scalar values in Unicode. See Table 3-7 in the Unicode 5.0 standard. ”
======================================
BOM Byte Order Mark,在UCS編碼中有一個(gè)叫做"ZERO WIDTH NO-BREAK SPACE"的字符,它的編碼是FEFF。而FFFE在UCS中是不存在的字符,所以不應(yīng)該出現(xiàn)在實(shí)際傳輸中。UCS規(guī)范建議我們?cè)趥鬏斪止?jié)流前,先傳輸字符"ZERO WIDTH NO-BREAK SPACE"。
這樣如果接收者收到FEFF,就表明這個(gè)字節(jié)流是Big-Endian的;如果收到FFFE,就表明這個(gè)字節(jié)流是Little-Endian的。
字符"ZERO WIDTH NO-BREAK SPACE"又被稱作BOM。UTF-8不需要BOM來(lái)表明字節(jié)順序,但可以用BOM來(lái)表明編碼方式。字符"ZERO WIDTH NO-BREAK SPACE"(也就是U+FEFF)的UTF-8編碼是EF BB BF(就是11101111,10111011,10111111)。所以如果接收者收到以EF BB BF開(kāi)頭的字節(jié)流,就知道這是UTF-8編碼了。
Windows就是使用BOM來(lái)標(biāo)記文本文件的編碼方式的。
除了FEFF,英文wiki http://en.wikipedia.org/wiki/UTF-8還解釋說(shuō)明了一些目前不會(huì)出現(xiàn)在utf-8字節(jié)流中的byte值。
=========================================
Java
http://www.jorendorff.com/articles/unicode/java.html
http://gceclub.sun.com.cn/developer/technicalArticles/Intl/Supplementary/index_zh_CN.html 完美解釋java中的unicode。另外提到j(luò)ava中utf-8其實(shí)有兩種格式,分別是標(biāo)準(zhǔn)utf-8和改良utf-8。對(duì)于文本輸入, Java 2 SDK 提供用于接受“\Uxxxxxx”格式字符串的代碼點(diǎn)輸入方法,這里大寫(xiě)的“U”表示轉(zhuǎn)義序列包含六個(gè)十六進(jìn)制數(shù)字,因此允許使用增補(bǔ)字符。小寫(xiě)的“u”表示轉(zhuǎn)義序列“\uxxxx”的原始格式。
http://dlog.cn/html/diary/showlog.vm?sid=2&cat_id=-1&log_id=557 介紹了String的JDK5新增方法
http://blog.csdn.net/qinysong/archive/2006/09/05/1179480.aspx 連著三篇用實(shí)例說(shuō)明,語(yǔ)言比較亂,說(shuō)的也不盡正確,但他用了做試驗(yàn)的java代碼有點(diǎn)意思,能幫助思考代碼中一些tricky的現(xiàn)象。
http://topic.csdn.net/u/20070928/22/5207088c-c47d-43ed-8416-26f850631cff.html 有一些回答,
http://topic.csdn.net/u/20070515/14/57af3319-28de-4851-b4cf-db65b2ead01c.html 有些試驗(yàn)代碼,價(jià)值不大
http://www.w3china.org/blog/more.asp?name=hongrui&id=24817 有些java實(shí)例代碼,沒(méi)細(xì)看。
另:
Java 1.0 supports Unicode version 1.1.
Java 1.1 onwards supports Unicode version 2.0.
J2SE 1.4中的字符處理是基于Unicode 3.0標(biāo)準(zhǔn)的。
J2SE v 1.5 supports Unicode 4.0 character set.
而:
Unicode 3.0:1999年九月;涵蓋了來(lái)自ISO 10646-1的十六位元通用字元集(UCS)基本多文種平面(Basic Multilingual Plane)
Unicode 3.1:2001年三月;新增從ISO 10646-2定義的輔助平面(Supplementary Planes)
所以:
代碼點(diǎn)在U+0000到U+FFFF之間的就用\u0000到\uffff表示
U+10000到U+1FFFF之間的用 \ud800到\udbff中的作為第一個(gè)單元, 用\udc00到\udfff作為第二單元,組合起來(lái)表示
char這個(gè)概念就是指\u0000到\uffff,這是占兩個(gè)字節(jié)
其余的用code point這個(gè)概念
JDK 1.5 以上支持 Unicode 4.0,也就是 Unicode 的范圍是 U+0000~U+10FFFF,
超過(guò) U+FFFF 的字符采用代碼點(diǎn)(也就是 int 類型的數(shù)據(jù))來(lái)表示,具體的可以
參考一下下面這個(gè)鏈接的文章《Java 平臺(tái)中的增補(bǔ)字符》,對(duì)此作了很詳細(xì)的介
紹。 http://gceclub.sun.com.cn/developer/technicalArticles/Intl/Supplementary/index_zh_CN.html
================================
http://m.tkk7.com/tim-wu/archive/2007/09/12/144550.html
================================
| U-00000000 - U-0000007F: |
0xxxxxxx |
| U-00000080 - U-000007FF: |
110xxxxx 10xxxxxx |
| U-00000800 - U-0000FFFF: |
1110xxxx 10xxxxxx 10xxxxxx |
| U-00010000 - U-001FFFFF: |
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
| U-00200000 - U-03FFFFFF: |
111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
| U-04000000 - U-7FFFFFFF: |
1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
但目前ISO和Unicode組織都不會(huì)規(guī)定10FFFF以上的字符
代碼範(fàn)圍
十六進(jìn)制 |
標(biāo)量值(scalar value
二進(jìn)制 |
UTF-8
二進(jìn)制 / 十六進(jìn)制 |
註釋 |
000000 - 00007F
128個(gè)代碼 |
00000000 00000000 0zzzzzzz |
0zzzzzzz(00-7F) |
ASCII等值範(fàn)圍,位元組由零開(kāi)始 |
| 七個(gè)z |
七個(gè)z |
000080 - 0007FF
1920個(gè)代碼 |
00000000 00000yyy yyzzzzzz |
110yyyyy(C2-DF) 10zzzzzz(80-BF) |
第一個(gè)位元組由110開(kāi)始,接著的位元組由10開(kāi)始 |
| 三個(gè)y;二個(gè)y;六個(gè)z |
五個(gè)y;六個(gè)z |
000800 - 00FFFF
63488個(gè)代碼 |
00000000 xxxxyyyy yyzzzzzz |
1110xxxx(E0-EF) 10yyyyyy 10zzzzzz |
第一個(gè)位元組由1110開(kāi)始,接著的位元組由10開(kāi)始 |
| 四個(gè)x;四個(gè)y;二個(gè)y;六個(gè)z |
四個(gè)x;六個(gè)y;六個(gè)z |
010000 - 10FFFF
1048576個(gè)代碼 |
000wwwxx xxxxyyyy yyzzzzzz |
11110www(F0-F4) 10xxxxxx 10yyyyyy 10zzzzzz |
由11110開(kāi)始,接著的位元組由10開(kāi)始 |
| 三個(gè)w;二個(gè)x;四個(gè)x;四個(gè)y;二個(gè)y;六個(gè)z |
三個(gè)w;六個(gè)x;六個(gè)y;六個(gè)z |
================================
參考:http://blog.csdn.net/qinysong/archive/2006/09/05/1179480.aspx,但該文對(duì)unicode版本說(shuō)明有誤,說(shuō)明見(jiàn)上
在大約 1993 年之后開(kāi)發(fā)的大多數(shù)現(xiàn)代編程語(yǔ)言都有一個(gè)特別的數(shù)據(jù)類型, 叫做 Unicode/ISO 10646-1 字符. 在 Ada95 中叫 Wide_Character, 在 Java 中叫 char.
ISO C 也詳細(xì)說(shuō)明了處理多字節(jié)編碼和寬字符 (wide characters) 的機(jī)制, 1994 年 9 月 Amendment 1 to ISO C 發(fā)表時(shí)又加入了更多. 這些機(jī)制主要是為各類東亞編碼而設(shè)計(jì)的, 它們比處理 UCS 所需的要健壯得多. UTF-8 是 ISO C 標(biāo)準(zhǔn)調(diào)用多字節(jié)字符串的編碼的一個(gè)例子, wchar_t 類型可以用來(lái)存放 Unicode 字符.
代碼為QueryParser.jj,語(yǔ)法為JavaCC實(shí)現(xiàn)的LL():
完整文檔:http://lucene.apache.org/java/2_0_0/queryparsersyntax.html
和正則一樣:
?表示0個(gè)或1個(gè)
+表示一個(gè)或多個(gè)
*表示0個(gè)或多個(gè)
以下是Token部分:
_NUM_CHAR::=["0"-"9"] //數(shù)字
_ESCAPED_CHAR::= "\\" [ "\\", "+", "-", "!", "(", ")", ":", "^", "[", "]", "\"", "{", "}", "~", "*", "?" ] > //特殊字符,
_TERM_START_CHAR ::=( ~[ " ", "\t", "\n", "\r", "+", "-", "!", "(", ")", ":", "^","[", "]", "\"", "{", "}", "~", "*", "?" ] //TERM的起始字符,除了列出的其它字符都可以
_TERM_CHAR::=( <_TERM_START_CHAR> | <_ESCAPED_CHAR> | "-" | "+" ) > //TERM可使用字符
_WHITESPACE::= ( " " | "\t" | "\n" | "\r") //空格和回車,
<DEFAULT> TOKEN:
AND::=("AND" | "&&")
OR::=("OR" | "||")
NOT::=("NOT" | "!")
PLUS::="+"
MINUS::="-"
LPAREN::="("
RPAREN::=")"
COLON::=":"
STAR::="*"
CARAT::="^" //后接Boost,原文<CARAT: "^" > : Boost,后面Boost說(shuō)明什么沒(méi)明白
QUOTED::="\"" (~["\""] | "\\\"")+ "\"" // 表示用"包起來(lái)的字符串,字符"開(kāi)始,中間由不是"的符號(hào)或者連著的這兩個(gè)符號(hào)\"組成,字符"結(jié)束,
TERM::=<_TERM_START_CHAR> (<_TERM_CHAR>)*
FUZZY_SLOP::="~" ( (<_NUM_CHAR>)+ ( "." (<_NUM_CHAR>)+ )? )? //字符~開(kāi)始,而后是數(shù)字.Lucene支持模糊查詢,例如"roam~"或"roam~0.8",The value is between 0 and 1,算法為the Levenshtein Distance, or Edit Distance algorithm
PREFIXTERM::=(<_TERM_START_CHAR> | "*") (<_TERM_CHAR>)* "*" > //模糊查找,表示以某某開(kāi)頭的查詢, 字符表示為"something*",前綴允許模糊符號(hào)*,中間可有字符也可沒(méi)有, 結(jié)尾必須是*
WILDTERM::=(<_TERM_START_CHAR> | [ "*", "?" ]) (<_TERM_CHAR> | ( [ "*", "?" ] ))* > //類似上面,但同時(shí)支持?字符,結(jié)尾可以是字符也可以是* ?。使用[]表示or關(guān)系時(shí),不需要使用|,只要,號(hào)分割即可
RANGEIN_START::="[" //在RangeQuery中,[或{表示了是否包含邊界條件本身, 用字符表示為"[begin TO end]" 或者"{begin TO end}",后接RangeIn
RANGEEX_START::="{" //同上,后接RangeEx
<Boost> TOKEN:
NUMBER::=(<_NUM_CHAR>)+ ( "." (<_NUM_CHAR>)+ )? //后接DEFAULT, 整數(shù)或小數(shù)
<RangeIn> TOKEN:
RANGEIN_TO::="TO"
RANGEIN_END::="]" //后接DEFAULT, RangIn的結(jié)束
RANGEIN_QUOTED::= "\"" (~["\""] | "\\\"")+ "\"" //同上述QUOTED,表示用"包起來(lái)的字符串,
RANGEIN_GOOP::= (~[ " ", "]" ])+ //1個(gè)或多個(gè)不是空格和]的符號(hào),這樣就能提取出[]中的內(nèi)容
<RangeEx> TOKEN :
RANGEEX_TO::="TO">
RANGEEX_END::="}" //后接DEFAULT, RangeEx的結(jié)束
RANGEEX_QUOTED::="\"" (~["\""] | "\\\"")+ "\"" //同上述QUOTED,表示用"包起來(lái)的字符串,
RANGEEX_GOOP::=(~[ " ", "}" ])+ //1個(gè)或多個(gè)不是空格和]的符號(hào),這樣就能提取出[]中的內(nèi)容
<DEFAULT, RangeIn, RangeEx> SKIP : {
< <_WHITESPACE>>
} //所有空格和回車被忽略
以下為解析部分
Conjunction::=[ <AND> { ret = CONJ_AND; } | <OR> { ret = CONJ_OR; } ] //連接
Modifiers::=[ <PLUS> { ret = MOD_REQ; } | <MINUS> { ret = MOD_NOT; } | <NOT> { ret = MOD_NOT; } ] //+ - !符號(hào)
Query::=Modifiers Clause (Conjunction Modifiers Clause)*
Clause::=[(<TERM> <COLON>|<STAR> <COLON>)] //btw:代碼中LOOKAHEAD[2]表示使用LL(2)
(Term|<LPAREN> Query <RPAREN> (<CARAT> <NUMBER>)?) //子句. ???????這兒語(yǔ)法有點(diǎn),仿佛允許 *:(*:dog)這樣的語(yǔ)法,很奇怪
Term::=(
(<TERM>|<STAR>|<PREFIXTERM>|<WILDTERM>|<NUMBER>) [<FUZZY_SLOP>] [<CARAT><NUMBER>[<FUZZY_SLOP>]}
| ( <RANGEIN_START> (<RANGEIN_GOOP>|<RANGEIN_QUOTED>) [ <RANGEIN_TO> ] (<RANGEIN_GOOP>|<RANGEIN_QUOTED> <RANGEIN_END> ) [ <CARAT> boost=<NUMBER> ] //這兒看出range必須同時(shí)有兩端,不能只有有一端
| ( <RANGEEX_START> <RANGEEX_GOOP>|<RANGEEX_QUOTED> [ <RANGEEX_TO> ] <RANGEEX_GOOP>|<RANGEEX_QUOTED> <RANGEEX_END> )[ <CARAT> boost=<NUMBER> ] //在RangeQuery中,[或{表示了是否包含邊界條件本身, 用字符表示為"[begin TO end]" 或者"{begin TO end}",后接RangeIn
| <QUOTED> [ <FUZZY_SLOP> ] [ <CARAT> boost=<NUMBER> ] //被""包含的內(nèi)容
btw: 猜測(cè): javacc中,如果使用[],則允許出現(xiàn)0次或1次
今天讀了lucent中的PriorityQueue.java, 一個(gè)很巧妙的復(fù)雜度為log(n)的排序堆棧.
始終確保數(shù)組A[1...n]中:
A[i]<A[2*i] & A[i] < A[2*i +1]
很容易推論出A[1]一定是最小數(shù)值, 并且每次put()和pop()至多移動(dòng)log(n)個(gè)數(shù)值
真是好久沒(méi)接觸算法了:)
ruby.exe提供了一個(gè)參數(shù)-r, 允許ruby在允許之前加載你指定的庫(kù)
1 如果你安裝了gem,那么環(huán)境變量RUBYOPT將為-rubygems,這個(gè)參數(shù)說(shuō)明了ruby將提前加載ubygem.rb(注意,沒(méi)有r,不是rubygem.rb,而是ubygem:)
2 這時(shí),如果你運(yùn)行 ruby -e "puts $:",可以查看到ruby查詢lib庫(kù)的目錄順序,其中第一個(gè)就是類似"..\ruby\site_ruby\1.8"目錄
3 因此,ubygem.rb將在ruby\site_ruby\1.8\ubygems.rb位置中被ruby定位到,而ubygem.rb只有一句話require 'rubygems',這次才真正調(diào)用了rubygems.rb
4 接著rubygems.rb的最后一句require 'rubygems/custom_require'將加載custom_require.rb
5 最后custom_require.rb中替換了原先的require()函數(shù)的實(shí)現(xiàn),這之后,庫(kù)的加載,將遵循gem的目錄約定。
記得上學(xué)時(shí)學(xué)數(shù)據(jù)庫(kù),書(shū)中說(shuō)過(guò):“數(shù)據(jù)庫(kù)建模一般實(shí)現(xiàn)到3NF和BCNF,4NF 5NF基本沒(méi)用”,造成多年對(duì)4NF和5NF置之不理。
離開(kāi)學(xué)校7年后的今天,無(wú)事有把數(shù)據(jù)庫(kù)的范式定義拿起來(lái)翻翻,發(fā)覺(jué)好象我對(duì)4NF和5NF的理解一直有誤?
在做業(yè)務(wù)建模時(shí),不少情況我們會(huì)盡可能地完全反映顯示業(yè)務(wù)關(guān)系,以 廠 采購(gòu)員 和 訂單 為例:
如果業(yè)務(wù)認(rèn)為訂單不屬于特定采購(gòu)員,也即關(guān)系如下:
廠和訂單為1:n的關(guān)系;
廠和采購(gòu)員也為1:n的關(guān)系;
采購(gòu)員與訂單無(wú)關(guān)。
此時(shí),那么我們肯定ORM簡(jiǎn)單得處理為兩個(gè)關(guān)聯(lián)表,這時(shí),不正是符合了4NF么?(如果只建立一個(gè)關(guān)聯(lián)表,表中三個(gè)字段廠id,訂單id,采購(gòu)員id,而后三個(gè)id組成聯(lián)合主鍵,那就是符合了BCNF但不符合4NF了)
而如果關(guān)系更復(fù)雜,一個(gè)訂單可以被多個(gè)采購(gòu)員處理,一個(gè)訂單還可以同屬于多個(gè)廠共享,那么我們一定是建立三個(gè)關(guān)聯(lián)表,獨(dú)立記錄三者間互相的關(guān)系,這不就是遵循了5NF么?
今天注冊(cè)了個(gè)Google Code的項(xiàng)目,還是google code爽啊,夠簡(jiǎn)單,
http://code.google.com/hosting/createProject 注冊(cè)一下就成功,不用得著什么審核
svn速度爆快,相比sf.net就是個(gè)牛車。
其它沒(méi)試,不評(píng)論,這兩點(diǎn)就足夠了。
不知道rubyforge怎么樣。
  final byte[] addBuffer(int size) final byte[] addBuffer(int size)  { {
 byte[] buffer = new byte[size]; byte[] buffer = new byte[size];
if (directory!=null)
  synchronized (directory) { // Ensure addition of buffer and adjustment to directory size are atomic wrt directory synchronized (directory) { // Ensure addition of buffer and adjustment to directory size are atomic wrt directory
buffers.add(buffer);
directory.sizeInBytes += size;
sizeInBytes += size;
 } }
else
buffers.add(buffer);
return buffer;
 } }
今天讀了 http://infolab.stanford.edu/~backrub/google.html 一文,發(fā)現(xiàn)我畢業(yè)那年(2000年)google已有如此成果。
PageRank or PR(A) can be calculated using a simple iterative algorithm, and corresponds to the principal eigenvector of the normalized link matrix of the web. Also, a PageRank for 26 million web pages can be computed in a few hours on a medium size workstation.
最酷的就是這句話了,真酷的algorithm啊,我想破頭想不出頭緒來(lái)達(dá)到這個(gè)效率。
呵呵,從wikipedia開(kāi)始,發(fā)現(xiàn)很有意思的文章越來(lái)越多:)
http://en.wikipedia.org/wiki/HITS_algorithm
今天翻了util包,發(fā)現(xiàn)自己對(duì)float的匱乏知識(shí),好在有偉大的wiki百科:
http://en.wikipedia.org/wiki/IEEE_754
很清楚得解釋了IEEE 754規(guī)范
可惜看不懂lucene對(duì)small float的結(jié)構(gòu)定義。
如果按我的理解,似乎類SmallFloat的函數(shù)byteToFloat()和byte315ToFloat()有bug,通過(guò)編寫(xiě)測(cè)試代碼:
SmallFloat.byte315ToFloat(Byte.parseByte("01111000", 2)得到的float值為0.5f,
但按照byte315ToFloat()函數(shù)的說(shuō)明,"01111000"的mantissaBits尾數(shù)長(zhǎng)度為3, zeroExponent為15,無(wú)負(fù)數(shù),
而01111按IEEE 754規(guī)范,應(yīng)該理解為1,所以01111000表達(dá)的數(shù)值應(yīng)該為1.0×2^0=1,而不是0.5f
非常之tricky。
通過(guò)讀byte315ToFloat()函數(shù)實(shí)現(xiàn),發(fā)現(xiàn)"01111000"轉(zhuǎn)換為32位值0,01111110,00000000000000000000000,
該值按IEEE 754規(guī)范的確為0.5f, 其中正負(fù)位為1位,指數(shù)(exponent)位為8位,尾數(shù)(mantissa)位為23位。
而在byteToFloat()和byte315ToFloat()的實(shí)現(xiàn)中,我們可以常看到作者將尾數(shù)位偏移24-mantissa位,
也就是說(shuō),他理解的IEEE 754規(guī)范中尾數(shù)位不是23位而是24位。
以上僅為我的猜測(cè),因?yàn)檫€沒(méi)有看到byteToFloat()的具體使用環(huán)境。
而且通過(guò)測(cè)試代碼,發(fā)現(xiàn)byte和float對(duì)應(yīng)關(guān)系:
10000,000==2.0f= 1*2^1
10001,000==8.0f=1*2^3
10010,000==32.0f=1*2^5
01111,000 = 0.5f = 1*2^-1
01110,000==0.125f= 1* 2^-3
完全看不出合理的small float的結(jié)構(gòu),tricky!!!
因?yàn)楣ぷ餍枰裉扉_(kāi)始學(xué)習(xí)lucene,
因?yàn)橛锌赡芤院笠钊胙芯縡ull text的搜索,決定暫時(shí)不看in action,
采用最愚笨的方法,直接爬代碼。憑借以前的門外漢理解一步一步爬吧,
不知道還能衍生出多少知識(shí)。
swt中,默認(rèn)只有用戶線程被允許訪問(wèn)UI圖形控件和一些圖形API,其他非用戶線程如果直接訪問(wèn)這類資源時(shí),SWTException直接被拋出。
如果真有這種需求,必須使用*.widget.Display類中的兩個(gè)線程同步方法:syncExec(Runnable)和asyncExec(Runnable)。方法syncExec()和asyncExec()的區(qū)別在于前者要在指定的線程執(zhí)行結(jié)束后才返回,而后者則無(wú)論指定的線程是否執(zhí)行都會(huì)立即返回到當(dāng)前線程。
例子:
Display.getCurrent().asyncExec(new Runnable() {
public void run() {
butt.setText("Push");
}
});
以下載自某論壇(sorry,忘記了出處),關(guān)于內(nèi)存釋放:
Rule 1: If you created it, you dispose it.
Rule 2: Disposing the parent disposes the children.
(from http://www.eclipse.org/articles/swt-design-2/swt-design-2.html)
當(dāng)使用構(gòu)造函數(shù)來(lái)創(chuàng)建小窗口或圖形對(duì)象時(shí),使用完時(shí)必須用手工來(lái)除掉它。
如果沒(méi)有使用構(gòu)造函數(shù)就獲取小窗口或圖形對(duì)象,則一定不能用手工來(lái)除掉它,因?yàn)槟捶峙渌?
如果將對(duì)小窗口或圖形對(duì)象的引用傳送至另一個(gè)對(duì)象,則一定要小心,仍在使用它時(shí)一定不要除掉它。與在使用圖像的插件模式中所描述的規(guī)則相似。)
當(dāng)用戶關(guān)閉Shell時(shí),將遞歸地銷毀 shell 及其所有子代小窗口。在此情況下,不需要除掉小窗口本身。然而,必須釋放與那些小窗口一起分配的所有圖形資源。
如果創(chuàng)建圖形對(duì)象以便在其中一個(gè)小窗口的生命周期內(nèi)使用它,則在除掉小窗口時(shí)必須除掉圖形對(duì)象。這可以通過(guò)向小窗口注冊(cè)銷毀偵聽(tīng)器,并在接收到銷毀事件時(shí)釋放圖形對(duì)象來(lái)實(shí)現(xiàn)。
這些規(guī)則有一個(gè)例外。簡(jiǎn)單的數(shù)據(jù)對(duì)象(例如,矩形和點(diǎn))不使用操作系統(tǒng)資源。它們沒(méi)有 dispose() 方法,您也不需要釋放它們。如果有疑問(wèn),則檢查特定類的 javadoc。
?
第一種方式,zkjbeyond的文章中有很詳細(xì)的說(shuō)明http://m.tkk7.com/zkjbeyond/archive/2006/05/05/44676.html
簡(jiǎn)單說(shuō),就是利用Ajax讀取包的.js文件后,直接使用eval()運(yùn)行代碼。
除此外,dojo還有另一種加載方式,用在調(diào)試階段(例如使用firebug活Venkman調(diào)試dojo時(shí)都需要用到,不過(guò)我沒(méi)試過(guò)使用MSE7或Visual Studio時(shí)是否需要使用這種加載方式)。
你在加載包前,將djConfig.debugAtAllCosts設(shè)置為true,那么包的加載方式會(huì)有所變化,采用第二種方式。例如:
djConfig.debugAtAllCosts=true;
dojo.require("dojo.widget.TimBar");
dojo.hostenv.writeIncludes();
此時(shí),dojo會(huì)使用加載brower_debug.js文件,
brower_debug.js重載了函數(shù)dojo.hostenv.loadUri,這兒,不再直接使用eval()運(yùn)行,而只是把需要的包push到dojo.hostenv.loadedUris數(shù)組中。實(shí)現(xiàn)代碼:
var text = this.getText(uri, null, true);
var requires = dojo.hostenv.getRequiresAndProvides(text);
eval(requires.join(";"));
dojo.hostenv.loadedUris.push(uri); dojo.hostenv.loadedUris[uri] = true;
var delayRequires = dojo.hostenv.getDelayRequiresAndProvides(text);
eval(delayRequires.join(";"));
從代碼可以看出,dojo為了保證加載的順序,使用dojo.hostenv.getRequiresAndProvides函數(shù)將提前依賴的包摳出來(lái),用遞歸提前push到dojo.hostenv.loadedUris中。
而后,在代碼最后,我們只要主動(dòng)使用dojo.hostenv.writeIncludes();函數(shù),就可一次性將被依賴的包利用document.write包含進(jìn)來(lái)。
btw:
當(dāng)然,這種方法有不少缺陷:
1、使用document.write方式加載包,會(huì)有延遲效應(yīng),會(huì)等待本頁(yè)面中代碼都執(zhí)行完才執(zhí)行包中的代碼,自己編碼時(shí)有點(diǎn)繞,影響可讀性;
2、從上面代碼中看出,dojo會(huì)有更多的IO操作,第一dojo已經(jīng)完整讀取了包代碼,但是不馬上執(zhí)行,只是用來(lái)分析依賴關(guān)系;之后,瀏覽器又要加載一次包代碼。
3、包絕對(duì)不允許循環(huán)引用。當(dāng)然,從OO角度,不循環(huán)引用是好的方式
所以,這種方式只能用在調(diào)試期間
摘要: 常規(guī)循環(huán)引用內(nèi)存泄漏和Closure內(nèi)存泄漏
要了解javascript的內(nèi)存泄漏問(wèn)題,首先要了解的就是javascript的GC原理。
我記得原來(lái)在犀牛書(shū)《JavaScript: The Definitive
Guide》中看到過(guò),IE使用的GC算法是計(jì)數(shù)器,因此只碰到循環(huán) 引用就會(huì)造成memory
leakage。后來(lái)一直覺(jué)得和觀察到的現(xiàn)象很不一致,直到看到Eric的文... 閱讀全文
今天發(fā)現(xiàn)偶的MapEasy的demo中有個(gè)bug,查了半天發(fā)現(xiàn)了一個(gè)在IE 6下特別古怪的問(wèn)題:
使用IE6,這個(gè)頁(yè)面無(wú)法正確顯示
http://mapeasy.sourceforge.net/demo/mapapi0.4alpha20060510/demo2_google_amuse.html
而這個(gè)可以
http://mapeasy.sourceforge.net/demo/mapapi0.4alpha20060510/demo2_google.html
而這兩個(gè)頁(yè)面的唯一區(qū)別就是:第一個(gè)頁(yè)面中有一個(gè)函數(shù)定義的第一行注釋中,帶上了"層"這個(gè)字。
如果去了“層”這個(gè)字,則一切ok。
另外,這兩個(gè)頁(yè)面的編碼均使用utf8
hoho,IE的bug真是多而古怪了,以后函數(shù)的第一行,偶再也不敢寫(xiě)注釋了..............
偷懶了一個(gè)月,今天終于重新修改了mapeasy中的球平算法應(yīng)用。
以前的mapeasy中使用 google map data的例子不能正確使用經(jīng)緯度,現(xiàn)在終于可以了。 google map api中有個(gè)很有用的接口:GProjection,官方對(duì)這個(gè)接口的解釋是: ??? This is the interface for map projections. A map
projection instance is passed to the constructor of
GMapType. This interface is implemented by the
class GMercatorProjection, which is used by all
predefined map types. You can implement this interface if you want
to define map types with different map projections. ??? 這個(gè)接口最大的作用,就是允許你使用自己的球平算法去投影地圖,其中的fromPixelToLatLng()和fromPixelToLatLng()非常重要,他們表示了從經(jīng)緯度和pixel之間的轉(zhuǎn)換算法。 ?? ?? google做了一個(gè)默認(rèn)的實(shí)現(xiàn) GMercatorProjection,使用的是麥卡托算法,google map提供的地圖數(shù)據(jù),就是根據(jù)這個(gè)算法投影轉(zhuǎn)換而來(lái)的。 ?? 如果你需要使用自己的投影地圖,記得一定要自己實(shí)現(xiàn)GProjection接口。 ?? ?? google使用的麥卡托算法很有意思,它并沒(méi)有把整個(gè)地球都投影出來(lái),只能投影緯度在85度內(nèi)的地圖。也就是說(shuō),最北極和最南極的那部分(緯度85以上),在google地圖中是找不到的:) ??? ??? 你可以運(yùn)行一下這句代碼: alert(map.getCurrentMapType().getProjection().fromLatLngToPixel(new?GLatLng(85,0),map.getZoom())); ?? 你會(huì)發(fā)現(xiàn),對(duì)應(yīng)的Y坐標(biāo)就是0了:) ??? 如果運(yùn)行: alert(map.getCurrentMapType().getProjection().fromLatLngToPixel(new?GLatLng(90,0),map.getZoom())); ??? 那么,Y坐標(biāo)將為負(fù)數(shù):) ??? 如果你只是希望使用google實(shí)現(xiàn)好的麥卡托算法,你還可以直接繞過(guò)GMap類,直接使用GMercatorProjection類: ??? var zoom=17;
??? var latLan=new? GLatLng(85,180);
??? var?gm=new?GMercatorProjection(zoom+1);?
????var?x=gm.fromLatLngToPixel(latLan,zoom).x;
????var?y=gm.fromLatLngToPixel(latLan,zoom).y; ?? 而后,你就可以把得到的x,y轉(zhuǎn)換成自己應(yīng)用的坐標(biāo)系中的坐標(biāo)。例如,在我的mapeasy中,坐標(biāo)系范圍是x:[-180,180], y:[-90,90],因此我使用如下的代碼進(jìn)行坐標(biāo)轉(zhuǎn)換: /**
?*?@param?lat?經(jīng)度
?*?@param?lan?緯度
?*?@param?zoom?放大比例
??*/
function?GoogleMapLatLan(lat,lan,zoom){
????this.lat=lat;
????this.lan=lan;
????this.zoom=zoom;
}
GoogleMapLatLan.prototype.fromLatLngToMapEasyPoint=function(){
???var?latLan=new?GLatLng(this.lat,this.lan);
?????var?zoom=this.zoom;
????var?gm=new?GMercatorProjection(zoom+1);?
????//merX,merY:根據(jù)google提供的Mercator算法算出來(lái)的Pixel的
????var?merX=gm.fromLatLngToPixel(latLan,zoom).x;
????var?merY=gm.fromLatLngToPixel(latLan,zoom).y;
???//google使用的麥卡托投影法,并沒(méi)有把整個(gè)地球投影出來(lái),只是投影出緯度在85度以內(nèi)的地球,也就是說(shuō),北緯85度的點(diǎn),就是最北邊的點(diǎn)。而最北極和最南極的那部分地圖(緯度85以上),在google提供的地圖中是找不到的:)
???????//在zome=0時(shí),如果地圖的左上角的點(diǎn)對(duì)應(yīng)的緯經(jīng)度為:(85,-180),右下角對(duì)應(yīng)的緯經(jīng)度為(-85,180),此時(shí),使用google提供的Mercator算法算出來(lái)的對(duì)應(yīng)的坐標(biāo)系?范圍為:x[0,256],y[0,256],
????//坐標(biāo)系的放大倍數(shù)
????var?scale=Math.pow(2,zoom);
????
????var?merXMin=0;
????var?merXMax=256*scale;
???? var?merYCenter=128*scale;
????//meX,meY:MapEasyPoint中的x,y
????//MapEasy默認(rèn)的坐標(biāo)系范圍為x:[-180,180],y:[-90,90],因此需要進(jìn)行轉(zhuǎn)換
????var?meX=((merX-merXMin)-(merXMax-merXMin)/2)*180/((merXMax-merXMin)/2);
????var?meY=(merYCenter-merY)*90/merYCenter;
????return?new?Point(meX,meY);
};
GoogleMapLatLan.prototype.getPoint=function(){
????return?this.fromLatLngToMapEasyPoint();
} ??? 這次寫(xiě)這段代碼,才發(fā)現(xiàn)google中GLatLan類的distanceFrom( other)函數(shù),實(shí)現(xiàn)了計(jì)算兩個(gè)經(jīng)緯坐標(biāo)間距離(米為單位)的算法,簡(jiǎn)單試用了一下,還8錯(cuò)。 ???? 忘了交代 了,我參考的google map api的版本是maps2.48.api.js ?btw: ??? 今天還是偷懶,沒(méi)有仔細(xì)研究GMercatorProjection的實(shí)現(xiàn)代碼,留給team中有空的伙伴去研究吧。 ??? 這兒有個(gè)Mercator不錯(cuò)的說(shuō)明: http://en.wikipedia.org/wiki/Mercator_projection?? 有興趣的朋友可以來(lái)逛逛 http://mapeasy.sf.net。項(xiàng)目問(wèn)題還好多,包括javascript的memory leakage至今也還沒(méi)去解決。項(xiàng)目組的成員最近都好忙,也不知道有沒(méi)有朋友有興趣加入的。
最近有些朋友一直問(wèn)起prototye是什么,偶一直不怎么做javascript開(kāi)發(fā),只能簡(jiǎn)單說(shuō)說(shuō)自己的理解。
javascript其實(shí)不是嚴(yán)格意義的OO語(yǔ)言,至少他沒(méi)有很好地實(shí)現(xiàn)封裝和繼承,甚至javascript使用的是function式對(duì)象。
因此,javascript有一個(gè)奇怪的東西就是prototype,javascript中約定了每個(gè)對(duì)象都可以包含一個(gè)prototype對(duì)象的引用(屬性),
這個(gè)prototype對(duì)象在運(yùn)行時(shí)是不可見(jiàn)的,也就是說(shuō),定義了之后,你無(wú)法直接使用prototype對(duì)象。
那么,prototype對(duì)象有什么用呢?它的作用,就是當(dāng)你去調(diào)用一個(gè)對(duì)象的函數(shù)或?qū)傩詴r(shí),javascript首先會(huì)在這個(gè)對(duì)象的定義中查找,如果找不到,
他就會(huì)去找這個(gè)對(duì)象的prototype對(duì)象有沒(méi)有這個(gè)定義,如果還找不到,他又會(huì)去找prototype對(duì)象的prototype,一直到對(duì)象沒(méi)有prototype定義為止。
是不是和函數(shù)繼承的目的很象?這就是javascript的原型繼承特性。
但是我們也看出了,這種查找方式,效率非常之低,尤其在prototype鏈很長(zhǎng)的情況下。javascript 2.0會(huì)對(duì)此有所改進(jìn)。
另外,prototype的定義方式也很奇怪,他必須以一個(gè)對(duì)象實(shí)例(而不是類)的形式,綁定到其他類上。記得嗎?prototype是定義時(shí)的,同時(shí)又是對(duì)象。
例子:
?? ?o1 = function(){};
?? ?o2 = function(){};
??? o2.prototype = new o1;??
如果嫌直接使用prototype挺麻煩,你可以去下載一個(gè)prototype.js來(lái)用,這個(gè)封裝真的挺不錯(cuò):)
|
|
|
| | 日 | 一 | 二 | 三 | 四 | 五 | 六 |
|---|
| 26 | 27 | 28 | 29 | 30 | 31 | 1 | | 2 | 3 | 4 | 5 | 6 | 7 | 8 | | 9 | 10 | 11 | 12 | 13 | 14 | 15 | | 16 | 17 | 18 | 19 | 20 | 21 | 22 | | 23 | 24 | 25 | 26 | 27 | 28 | 29 | | 30 | 1 | 2 | 3 | 4 | 5 | 6 |
|
導(dǎo)航
統(tǒng)計(jì)
- 隨筆: 28
- 文章: 0
- 評(píng)論: 38
- 引用: 1
常用鏈接
留言簿(4)
我參與的團(tuán)隊(duì)
隨筆檔案
搜索
最新評(píng)論

閱讀排行榜
評(píng)論排行榜
|
|