快的打車從2013年年底到2014年下半年,系統訪問量迅速膨脹,很多復雜的問題要在短時間內解決,且不能影響線上業務,這是比較大的挑戰,本文將會闡述快的打車架構演變過程遇到的一些有代表性的問題和解決方案。
LBS的瓶頸和方案
先看看基本的系統模型,如圖1所示。
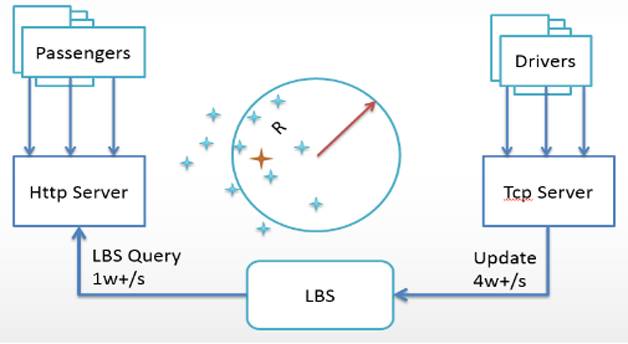 圖1 系統模型示意圖
圖1 系統模型示意圖
司機每隔幾秒鐘上報一次經緯度,存儲在MongoDB里;
乘客發單時,通過MongoDB圈選出附近司機;
將訂單通過長連接服務推送給司機;
司機接單,開始服務。
MongoDB集群是一主多從的復制集方式,讀寫都很密集(4w+/s寫、1w+/s讀)時出現以下問題:
從服務器CPU負載急劇上升;
查詢性能急劇降低(大量查詢耗時超過800毫秒);
查詢吞吐量大幅降低;
主從復制出現較大的延遲。
原因是當時的MongoDB版本(2.6.4)是庫級別的鎖每次寫都會鎖庫,還有每一次LBS查詢會分解成許多單獨的子查詢,增大整個查詢的鎖等待概率。我們最后將全國分為4個大區,部署多個獨立的MongoDB集群,每個大區的用戶存儲在對應的MongoDB集群里。
長連接服務穩定性
我們的長連接服務通過Socket接收客戶端心跳、推送消息給乘客和司機。打車大戰期間,長連接服務非常不穩定。
先說說硬件問題,現象是CPU的第一個核經常使用率100%,其他的核卻非常空閑,系統吞吐量上不去,對業務的影響很大。經過較長時間排查,最終發現這是因為服務器用了單隊列網卡,I/O中斷都被分配到了一個CPU核上,大量數據包到來時,單個CPU核無法全部處理,導致LVS不斷丟包連接中斷。最后解決這個問題其實很簡單,換成多隊列網卡就行。
再看軟件問題,長連接服務當時用Mina實現,Mina本身存在一些問題:內存使用控制粒度不夠細、垃圾回收難以有效控制、空閑連接檢查效率不高、大量連接時周期性CPU使用率飆高。快的打車的長連接服務特點是:大量的廣播、消息推送具有不同的優先級、細粒度的資源監控。最后我們用AIO重寫了這個長連接服務框架,徹底解決了這個問題。主要有以下特性:
針對快的場景定制開發;
資源(主要是ByteBuffer)池化,減少GC造成的影響;
廣播時,一份ByteBuffer復用到多個通道,減少內存拷貝;
使用TimeWheel檢測空閑連接,消除空閑連接檢測造成的CPU尖峰;
支持按優先級發送數據。
其實Netty已經實現了資源池化和TimeWheel方式檢測空閑連接,但無法做到消息優先級區分和細粒度監控,這也算是快的自身的定制特性吧,通用的通信框架確實不好滿足。選用AIO方式僅僅是因為AIO的編程模型比較簡單而已,其實底層的性能并沒有多大差別。
系統分布式改造
快的打車最初只有兩個系統,一個提供HTTP服務的Web系統,一個提供TCP長連接服務的推送系統,所有業務運行在這個Web系統里,代碼量非常龐大,代碼下載和編譯都需要花較長時間。
業務代碼都混在一起,頻繁的日常變更導致并行開發的分支非常多,測試和代碼合并以及發布驗證的效率非常低下,常常一發布就通宵。這種情況下,系統的伸縮性和擴展性非常差,關鍵業務和非關鍵業務混在一起,互相影響。
因此我們Web系統做了拆分,將整個系統從上往下分為3個大的層次:業務層、服務層以及數據層。
我們在拆分的同時,也仔細梳理了系統之間的依賴。對于強依賴場景,用Dubbo實現了RPC和服務治理。對于弱依賴場景,通過RocketMQ實現。Dubbo是阿里開源的框架,在阿里內部和國內大型互聯網公司有廣泛的應用,我們對Dubbo源碼比較了解。RocketMQ也是阿里開源的,在內部得到了非常廣泛的應用,也有很多外部用戶,可簡單將RocketMQ理解為Java版的Kafka,我們同樣也對RocketMQ源碼非常了解,快的打車所有的消息都是通過RocketMQ實現的,這兩個中間件在線上運行得非常穩定。
借著分布式改造的機會,我們對系統全局也做了梳理,建立研發流程、代碼規范、SQL規范,梳理鏈路上的單點和性能瓶頸,建立服務降級機制。
無線開放平臺
當時客戶端與服務端通信面臨以下問題。
每新增一個業務請求,Web工程就要改動發布。
請求和響應格式沒有規范,導致服務端很難對請求做統一處理,而且與第三方集成的方式非常多,維護成本高。
來多少請求就處理多少,根本不考慮后端服務的承受能力,而某些時候需要對后端做保護。
業務邏輯比較分散,有的在Web應用里,有的在Dubbo服務里。提供新功能時,工程師關注的點比較多,增加了系統風險。
業務頻繁變化和快速發展,文檔無法跟上,最后沒人能說清到底有哪些協議,協議里的字段含義。
針對這些問題,我們設計了快的無線開放平臺KOP,以下是一些大的設計原則。
接入權限控制
為接入的客戶端分配標示和密鑰,密鑰由客戶端保管,用來對請求做數字簽名。服務端對客戶端請求做簽名校驗,校驗通過才會執行請求。
流量分配和降級
同樣的API,不同接入端的訪問限制可以不一樣。可按城市、客戶端平臺類型做ABTest。極端情況下,優先保證核心客戶端的流量,同時也會優先保證核心API的服務能力,例如登錄、下單、接單、支付這些核心的API。被訪問被限制時,返回一個限流錯誤碼,客戶端根據不同場景酌情處理。
流量分析
從客戶端、API、IP、用戶多個維度,實時分析當前請求是否惡意請求,惡意的IP和用戶會被凍結一段時間或永久封禁。
實時發布
上線或下線API不需要對KOP進行發布,實時生效。當然,為了安全,會有API的審核機制。
實時監控
能統計每個客戶端對每個API每分鐘的調用總量、成功量、失敗量、平均耗時,能以分鐘為單位查看指定時間段內的數據曲線,并且能對比歷史數據。當響應時間或失敗數量超過閾值時,系統會自動發送報警短信。
實時計算與監控
我們基于Storm和HBase設計了自己的實時監控平臺,分鐘級別實時展現系統運行狀況和業務數據(架構如圖2所示),包含以下幾個主要部分。
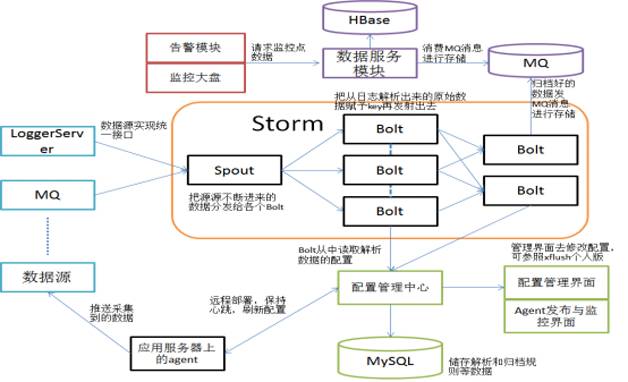 圖2 監控系統架構圖
圖2 監控系統架構圖
核心計算模型
求和、求平均、分組。
基于Storm的實時計算
Storm的邏輯并不復雜,只有兩個Bolt,一個將一條日志解析成KV對,另外一個基于KV和設定的規則進行計算。每隔一分鐘將數據寫入RocketMQ。
基于HBase的數據存儲
只有插入沒有更新,避免了HBase行鎖競爭。rowkey是有序的,因為要根據維度和時間段查詢,這樣會形成HBase Region熱點,導致寫入比較集中,但是沒有性能問題,因為每個維度每隔1分鐘定時插入,平均每秒的插入很少。即使前端應用的日志量突然增加很多,HBase的插入頻度仍然是穩定的。
基于RocketMQ的數據緩沖
收集的日志和Storm計算的結果都先放入MetaQ集群,無論Storm集群還是存儲節點,發生故障時系統仍然是穩定的,不會將故障放大;即使有突然的流量高峰,因為有消息隊列做緩沖,Storm和HBase仍然能以穩定的TPS處理。這些都極大的保證了系統的穩定性。RocketMQ集群自身的健壯性足夠強,都是物理機。SSD存儲盤、高配內存和CPU、Broker全部是M/S結構。可以存儲足夠多的緩沖數據。
某個系統的實時業務指標(關鍵數據被隱藏),見圖3。
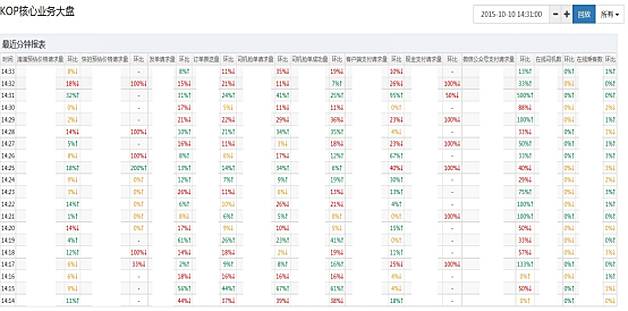 圖3 某個業務系統大盤截圖
圖3 某個業務系統大盤截圖
數據層改造
隨著業務發展,單數據庫單表已經無法滿足性能要求,特別是發券和訂單,我們選擇在客戶端分庫分表,自己做了一個通用框架解決分庫分表的問題。但是還有以下問題:
數據同步
快的原來的數據庫分為前臺庫和后臺庫,前臺庫給應用系統使用,后臺庫只供后臺使用。不管前臺應用有多少庫,后臺庫只有一個,那么前臺的多個庫多個表如何對應到后臺的單庫單表?MySQL的復制無法解決這個問題。
離線計算抽取
還有大數據的場景,大數據同事經常要dump數據做離線計算,都是通過Sqoop到后臺庫抽數據,有的復雜SQL經常會使數據庫變得不穩定。而且,不同業務場景下的Sqoop會造成數據重復抽取,給數據庫添加了更多的負擔。
我們最終實現了一個數據同步平臺,見圖4。
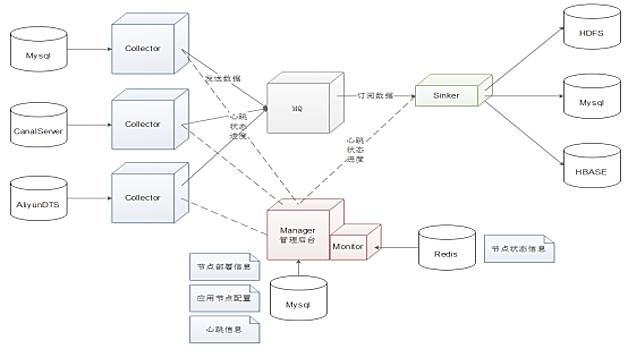 圖4 數據同步平臺架構圖
圖4 數據同步平臺架構圖
數據抽取用開源的canal實現,MySQL binlog改為Row模式,將canal抽取的binlog解析為MQ消息,打包傳輸給MQ;
一份數據,多種消費場景,之前是每種場景都抽取一份數據;
各個消費端不需要關心MySQL,只需要關心MQ的Topic;
支持全局有序,局部有序,并發亂序;
可以指定時間點回放數據;
數據鏈路監控、報警;
通過管理平臺自動部署節點。
分庫分表解決了前臺應用的性能問題,數據同步解決了多庫多表歸一的問題,但是隨著時間推移,后臺單庫的問題越來越嚴重,迫切需要一種方案解決海量數據存儲的問題,同時又要讓現有的上層應用不會有太大改動。因此我們基于HBase和數據同步設計了實時數據中心,如圖5所示。
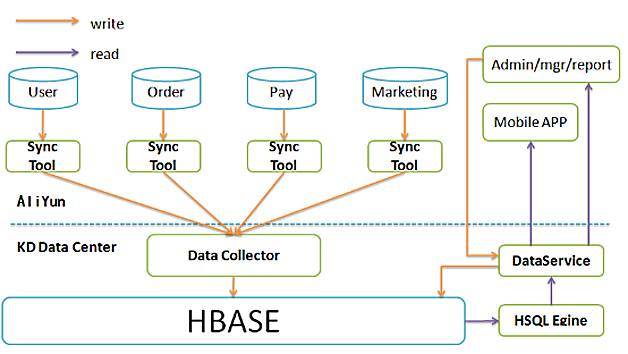 圖5 實時數據中心架構圖
圖5 實時數據中心架構圖
將前臺MySQL多庫多表通過同步平臺,都同步到了HBase;
為減少后臺應用層的改動,設計了一個SQL解析模塊,將SQL查詢轉換為HBase查詢;
支持二級索引。
說說二級索引,HBase并不支持二級索引,對它而言只有一個索引,那就是Rowkey。如果要按其它字段查詢,那就要為這些字段建立與Rowkey的映射關系,這就是所謂的二級索引。HBase二級索引可以通過Coprocessor在數據插入之前執行一段代碼,這段代碼運行在HBase服務端(Region Server),可以讓這段代碼負責插入二級索引。實時數據中心的二級索引是在客戶端負責插入的,并沒有使用Coprocessor,主要原因是Coprocessor不容易實現索引的批量插入,而批量插入,實踐證明,是提升HBase插入性能非常有效的手段。二級索引的應用其實還有些條件,如下:
排序
在HBase中,只有一種排序,就是按Rowkey排序,因此,在建立索引的時候,實際上就定死了將來查詢結果的排序。某個索引字段的reverse屬性為true,則按這個字段倒序排序,否則正序排序。
打散
單調變化的Rowkey讀寫壓力很難均勻分布到多個Region上,而打散將會使讀寫均勻分布到多個Region,因此提升了讀寫性能。但打散也有局限性,主要的是,經過打散的字段將無法支持范圍查詢。而且,hash和reverse這兩個屬性是互斥的,且hash優先級高,就是說一旦設置了hash=true,則會忽略reverse這個屬性。
串聯
另外需要特別強調的是,索引配置也影響到多表歸一,作為“串聯”的字段,必須建立唯一索引,如果串聯字段上沒有建立唯一索引,將無法完成多表歸一。
我們還實現了一套將SQL語句轉換成HBase API的引擎,可以通過SQL語句直接操作HBase。這里需要指出的是HSQL引擎和Hive是不同的,Hive主要用于將SQL語句轉換成Hadoop的Map/Reduce任務,當然也可以轉換成HBase的查詢。但Hive無法利用二級索引(HBase本來就不存在二級索引這個概念),Hive主要面向的是大批量、低頻度、高延遲、順序讀的訪問場景,而HSQL可以有效利用二級索引,它面向的是小批量、高頻度、低延遲、隨機讀的訪問場景。
王小雪,滴滴出行架構師,原快的打車架構師。從無到有組建了快的打車基礎服務團隊,主持研發、引進了眾多基礎框架和服務,推進快的架構升級,從穩定性、可用性、性能、安全、監控多方面體系化的建設了快的高可用架構。對高并發分布式系統架構、實時數據處理、網絡通信和Java中間件有比較深厚的經驗積累。錢曙光,關注架構和算法領域,尋求報道或者投稿請發郵件qianshg@csdn.net,交流探討可加微信qshuguang2008,備注姓名+公司+職位