3.關于索引:
3.1索引可以改善查詢,但會減慢更新,索引不是越多越好,最好不超過字段數的20%(在數據增、刪、改比較頻繁的表中,索引數量不應超過5個。
3.2離散程度越小,不適合加索引,例如:不要給性別建索引
test.status取值范圍:0-9,在status列建索引
mysql> select sql_no_cache * from test where status = 3 order by id limit 80000, 2;
+--------+----------------+---------------------+------------+--------+
| id | time1 | time2 | time3 | status |
+--------+----------------+---------------------+------------+--------+
| 795783 | 20110825150959 | 2011-08-25 15:09:00 | 1314256140 | 3 |
| 795789 | 20120829052359 | 2012-08-29 05:23:00 | 1346188980 | 3 |
+--------+----------------+---------------------+------------+--------+
2 rows in set (1.26 sec)
刪除status索引后
mysql> select sql_no_cache * from test where status = 3 order by id limit 80000, 2;
+--------+----------------+---------------------+------------+--------+
| id | time1 | time2 | time3 | status |
+--------+----------------+---------------------+------------+--------+
| 795783 | 20110825150959 | 2011-08-25 15:09:00 | 1314256140 | 3 |
| 795789 | 20120829052359 | 2012-08-29 05:23:00 | 1346188980 | 3 |
+--------+----------------+---------------------+------------+--------+
2 rows in set (0.37 sec)
3.3.避免在空值(Null)很多的字段上建立索引,大量空值會降低索引效率
3.4.避免在數據值分布不均的字段上建立索引,個別數據值占總數據量的百分率明顯比其它數據值占總數據量的百分率高,表明該字段數據值分布不均,容易引起數據庫選擇錯誤索引,生成錯誤的查詢執行計劃。
3.5.在數據量較少且訪問頻率不高的情況下,如只有一百行記錄以下的表不需要建立索引。因為在數據量少的情況下,使用全表掃描效果比走索引更好。
3.6.字符字段必須建前綴索引
單字母區分度:26
4個字母區分度:26*26*26*26=456976
6個字母區分度:26*26*26*26*26*26=308915776
CREATE TABLE `test1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`a` char(20) NOT NULL DEFAULT '',
`b` varchar(14) NOT NULL DEFAULT '00000000000000',
`c` varchar(14) DEFAULT '00000000000000',
PRIMARY KEY (`id`),
KEY `a` (`a`(6))
) ENGINE=MyISAM AUTO_INCREMENT=12534199 DEFAULT CHARSET=gbk;
mysql> select sql_no_cache count(*) from test1;
+----------+
| count(*) |
+----------+
| 12534198 |
+----------+
1 row in set (0.00 sec)
mysql> select sql_no_cache count(*) from test1 where a = 'tR6cDjx0frXx45yURG1m';
+----------+
| count(*) |
+----------+
| 1 |
+----------+
1 row in set (0.00 sec)
3.7.不在索引列做運算,盡量不用外鍵(InnoDB)
3.8.唯一索引:在建立索引的字段所有數值都具有唯一性特點的情況下,建立唯一索引(unique index)代替普通索引,唯一索引(unique index)查詢效率比普通索引查詢效率更高,可以大幅提升查詢速度。
4.組合索引
4.1.避免建立兩個或以上功能相同索引。例如已經建立字段A、B兩個字段的索引,應該避免再建立字段A的單獨索引。兩個索引之間,對相同的查詢都會起到相同的作用。建立兩個功能相同的索引,反而會容易引起數據庫產生錯誤的查詢計劃,降低查詢效率。
4.2.選擇正確的組合索引字段順序,最常用的查詢字段和選擇性、區分度較高的字段,應該作為索引的前導字段使用。
假設存在組合索引it1c1c2(c1,c2),查詢語句select * from t1 where c1=1 and c2=2能夠使用該索引。查詢語句select * from t1 where c1=1也能夠使用該索引。但是,查詢語句select * from t1 where c2=2不能夠使用該索引,因為沒有組合索引的引導列,即,要想使用c2列進行查找,必需出現c1等于某值。
4.3.合適的字段數,組合索引的字段數不適宜較多,較多的組合索引字段數會降低索引查詢效率,組合索引字段數應不多于3個,如業務特點需要建立多字段的組合主鍵例外。
關于一個B-Tree索引的例子:
假設有如下一個表:
CREATE TABLE People (
last_name varchar(50) not null,
first_name varchar(50) not null,
dob date not null,
gender enum('m', 'f') not null,
key(last_name, first_name, dob)
);
其索引包含表中每一行的last_name、first_name和dob列。其結構大致如下:
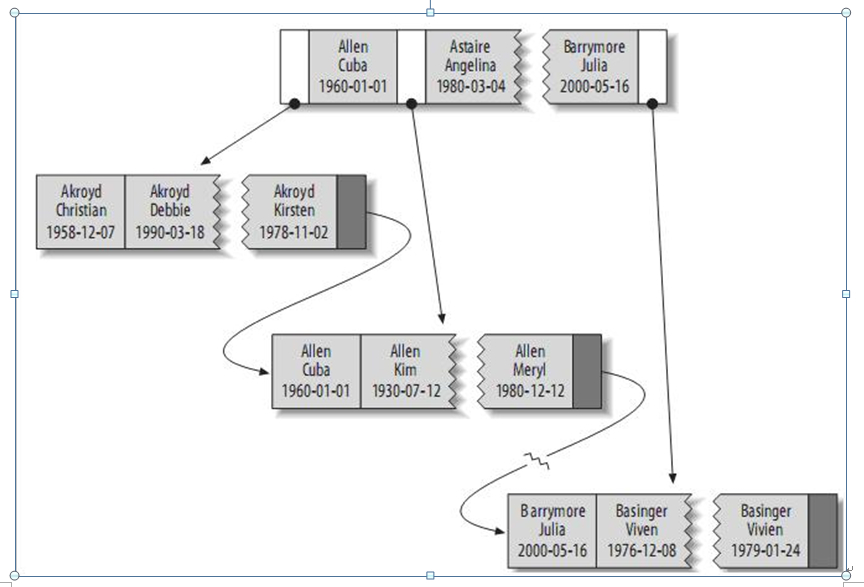
索引存儲的值按索引列中的順序排列。可以利用B-Tree索引進行全關鍵字、關鍵字范圍和關鍵字前綴查詢,當然,如果想使用索引,你必須保證按索引的最左邊前綴(leftmost prefix of the index)來進行查詢。
(1)匹配全值(Match the full value):對索引中的所有列都指定具體的值。例如,上圖中索引可以幫助你查找出生于1960-01-01的Cuba Allen。
(2)匹配最左前綴(Match a leftmost prefix):你可以利用索引查找last name為Allen的人,僅僅使用索引中的第1列。
(3)匹配列前綴(Match a column prefix):例如,你可以利用索引查找last name以J開始的人,這僅僅使用索引中的第1列。
(4)匹配值的范圍查詢(Match a range of values):可以利用索引查找last name在Allen和Barrymore之間的人,僅僅使用索引中第1列。
(5)匹配部分精確而其它部分進行范圍匹配(Match one part exactly and match a range on another part):可以利用索引查找last name為Allen,而first name以字母K開始的人。
(6)僅對索引進行查詢(Index-only queries):如果查詢的列都位于索引中,則不需要讀取元組的值。
由于B-樹中的節點都是順序存儲的,所以可以利用索引進行查找(找某些值),也可以對查詢結果進行ORDER BY。當然,使用B-tree索引有以下一些限制:
(1) 查詢必須從索引的最左邊的列開始。關于這點已經提了很多遍了。例如你不能利用索引查找在某一天出生的人。
(2) 不能跳過某一索引列。例如,你不能利用索引查找last name為Smith且出生于某一天的人。
(3) 存儲引擎不能使用索引中范圍條件右邊的列。例如,如果你的查詢語句為WHERE last_name="Smith" AND first_name LIKE 'J%' AND dob='1976-12-23',則該查詢只會使用索引中的前兩列,因為LIKE是范圍查詢。
另一個例子:
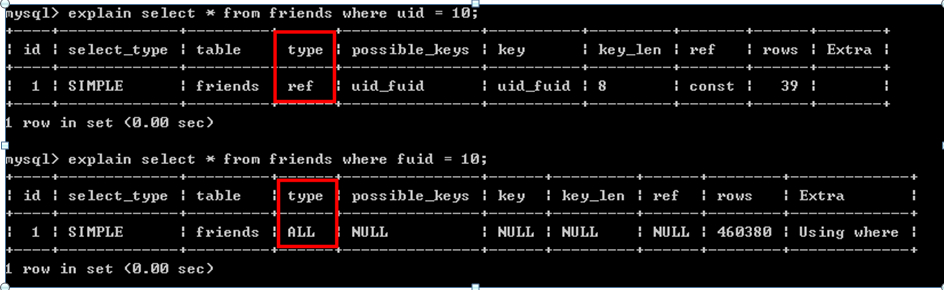
CREATE TABLE `friends` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`uid` bigint(20) unsigned NOT NULL DEFAULT '0',
`fuid` bigint(20) unsigned NOT NULL DEFAULT '0',
`fname` varchar(50) NOT NULL DEFAULT '',
`fpicture` varchar(150) NOT NULL DEFAULT '',
`fsex` tinyint(1) NOT NULL DEFAULT '0',
`status` tinyint(1) NOT NULL DEFAULT '0',
PRIMARY KEY (`id`),
KEY `uid_fuid` (`uid`,`fuid`)
) ENGINE=MyISAM DEFAULT CHARSET=gbk;
下一個
5.覆蓋索引(Covering Indexes)
如果索引包含滿足查詢的所有數據,就稱為覆蓋索引。覆蓋索引是一種非常強大的工具,能大大提高查詢性能。只需要讀取索引而不用讀取數據有以下一些優點:
(1)索引項通常比記錄要小,所以MySQL訪問更少的數據;
(2)索引都按值的大小順序存儲,相對于隨機訪問記錄,需要更少的I/O;
(3)大多數據引擎能更好的緩存索引。比如MyISAM只緩存索引。
(4)覆蓋索引對于InnoDB表尤其有用,因為InnoDB使用聚集索引組織數據,如果二級索引中包含查詢所需的數據,就不再需要在聚集索引中查找了。
注意:覆蓋索引不能是任何索引,只有B-TREE索引存儲相應的值。而且不同的存儲引擎實現覆蓋索引的方式都不同,并不是所有存儲引擎都支持覆蓋索引(Memory和Falcon就不支持)。
對于索引覆蓋查詢(index-covered query),使用EXPLAIN時,可以在Extra一列中看到“Using index”
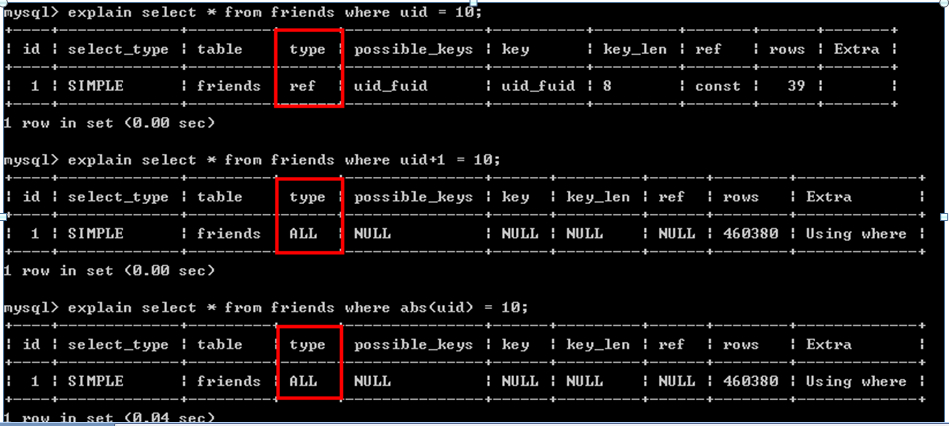
CREATE TABLE `friends` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`uid` bigint(20) unsigned NOT NULL DEFAULT '0',
`fuid` bigint(20) unsigned NOT NULL DEFAULT '0',
`fname` varchar(50) NOT NULL DEFAULT '',
`fpicture` varchar(150) NOT NULL DEFAULT '',
`fsex` tinyint(1) NOT NULL DEFAULT '0',
`status` tinyint(1) NOT NULL DEFAULT '0',
PRIMARY KEY (`id`),
KEY `uid_fuid` (`uid`,`fuid`)
) ENGINE=MyISAM DEFAULT CHARSET=gbk;

6.排序
MySQL中,有兩種方式生成有序結果集:
a. filesort 糟糕
b. Index排序 好
什么時候使用Index排序?
當索引的順序與ORDER BY中的列順序相同且所有的列是同一方向(全部升序或者全部降序)時,可以使用索引來排序。其它情況都會使用filesort。
什么時候使用filesort?
當MySQL不能使用Index排序時,就會利用自己的排序算法(快速排序算法)在內存(sort buffer)中對數據進行排序,如果內存裝載不下,它會將磁盤上的數據進行分塊,再對各個數據塊進行排序,然后將各個塊合并成有序的結果集(實際上就是外排序)。
當對連接操作進行排序時,如果ORDER BY僅僅引用第一個表的列,MySQL對該表進行filesort操作,然后進行連接處理,此時,EXPLAIN輸出“Using filesort”;
否則,MySQL必須將查詢的結果集生成一個臨時表,在連接完成之后進行filesort操作,此時,EXPLAIN輸出“Using temporary;Using filesort”。
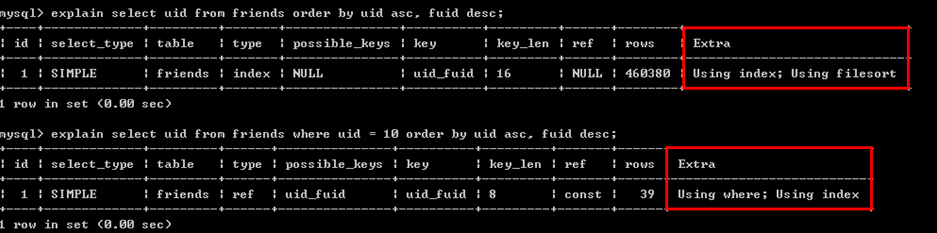
通過索引優化來實現MySQL的ORDER BY語句優化例子:
1、ORDER BY的索引優化。如果一個SQL語句形如:
SELECT [column1],[column2],…. FROM [TABLE] ORDER BY [sort];
在[sort]這個欄位上建立索引就可以實現利用索引進行order by 優化。
2、WHERE + ORDER BY的索引優化,形如:
SELECT [column1],[column2],…. FROM [TABLE] WHERE [columnX] = [value] ORDER BY [sort];
建立一個聯合索引(columnX,sort)來實現order by 優化。
注意:如果columnX對應多個值,如下面語句就無法利用索引來實現order by的優化
SELECT [column1],[column2],…. FROM [TABLE] WHERE [columnX] IN ([value1],[value2],…) ORDER BY[sort];
3、WHERE+ 多個字段ORDER BY
SELECT * FROM [table] WHERE uid=1 ORDER x,y LIMIT 0,10;
建立索引(uid,x,y)實現order by的優化,比建立(x,y,uid)索引效果要好得多。
MySQL Order By不能使用索引來優化排序的情況:
1、對不同的索引鍵做 ORDER BY :(key1,key2分別建立索引)
SELECT * FROM t1 ORDER BY key1, key2;

2、用于where語句的索引和ORDER BY 的不是同一個:(key1,key2分別建立索引)
SELECT * FROM t1 WHERE key2=constant ORDER BY key1;

3、同時使用了 ASC 和 DESC:(key_part1,key_part2建立聯合索引),通過where語句將order by中索引列轉為常量,則除外
SELECT * FROM t1 ORDER BY key_part1 DESC, key_part2 ASC;
4、如果在WHERE或ORDER BY的欄位上應用表達式(函數)時,則無法利用索引來實現order by的優化
SELECT * FROM t1 ORDER BY YEAR(logindate) LIMIT 0,10;

5、檢查的行數過多,且沒有使用覆蓋索引
6、where語句中使用了條件查詢

7.關于group by或distinct
7.1.盡量只對存在索引的字段進行group by或distinct。當group by 不能使用index 時mysql有兩種處理方法:臨時表和filesort。
7.2.在group by 語句中mysql會自動order,如果不需要可使用order by null來禁止自動的order。
8.關于索引失效
8.1.避免對索引字段計算
8.2.避免使用索引列值是否可為空的索引,如果索引列值可以是空值,在SQL語句中那些要返回NULL值的操作,將不會用到索引。
8.3.相同的索引列不能互相比較,這將會啟用全表掃描,如tab1上存在索引idx_col1_col2(col1,col2),其中col1和col2都是int型。則查詢語句SELECT * FROM tab1 WHERE col1>col2;是不會使用索引的。
8.4.避免使用存在潛在的數據類型轉換的索引。潛在的數據轉換,查詢條件中是指由于等式兩端的數據類型不一致。例如索引字段使用的是數字類型,而條件等式的另一端數據類型是字符類型,數據庫將會對其中一端進行數據類型轉換,數據類型的轉換會讓索引的作用失效,令數據庫選擇其他的較為低效率的訪問路徑。

8.5.使用索引列作為條件進行查詢時,需要避免使用<>或者!=等判斷條件。如確實業務需要,使用到不等于符號,需要在重新評估索引建立,避免在此字段上建立索引,改由查詢條件中其他索引字段代替。
a)盡量避免負向查詢:NOT、!=、<>、!<、!>、NOT EXISTS、NOT IN、NOT LIKE,避免%前模糊查詢
b)WHERE條件中的范圍查詢(IN、BETWEEN、<、<=、>、>=)會導致后面的條件使用不了索引。
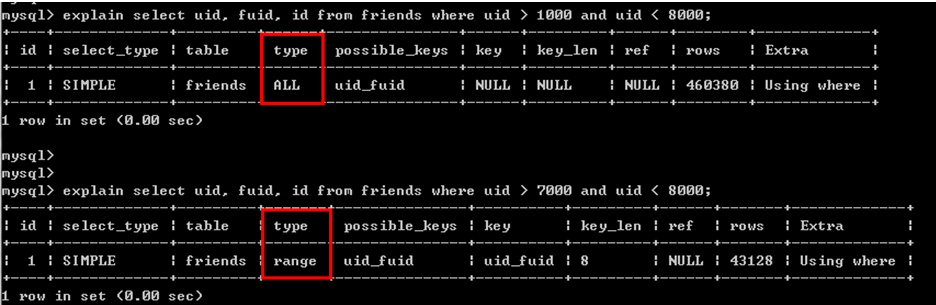
8.6.使用索引列作為條件進行范圍查詢時,應該避免較大范圍取值。
posted on 2014-05-08 19:48
zhangxl 閱讀(2032)
評論(4) 編輯 收藏 所屬分類:
DB