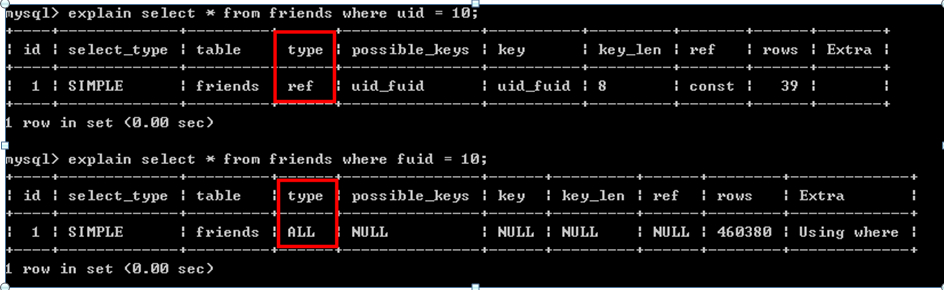
3.關(guān)于索引:
3.1索引可以改善查詢,但會(huì)減慢更新,索引不是越多越好,最好不超過字段數(shù)的20%(在數(shù)據(jù)增、刪、改比較頻繁的表中,索引數(shù)量不應(yīng)超過5個(gè)。
3.2離散程度越小,不適合加索引,例如:不要給性別建索引
test.status取值范圍:0-9,在status列建索引
mysql> select sql_no_cache * from test where status = 3 order by id limit 80000, 2;
+--------+----------------+---------------------+------------+--------+
| id | time1 | time2 | time3 | status |
+--------+----------------+---------------------+------------+--------+
| 795783 | 20110825150959 | 2011-08-25 15:09:00 | 1314256140 | 3 |
| 795789 | 20120829052359 | 2012-08-29 05:23:00 | 1346188980 | 3 |
+--------+----------------+---------------------+------------+--------+
2 rows in set (1.26 sec)
刪除status索引后
mysql> select sql_no_cache * from test where status = 3 order by id limit 80000, 2;
+--------+----------------+---------------------+------------+--------+
| id | time1 | time2 | time3 | status |
+--------+----------------+---------------------+------------+--------+
| 795783 | 20110825150959 | 2011-08-25 15:09:00 | 1314256140 | 3 |
| 795789 | 20120829052359 | 2012-08-29 05:23:00 | 1346188980 | 3 |
+--------+----------------+---------------------+------------+--------+
2 rows in set (0.37 sec)
3.3.避免在空值(Null)很多的字段上建立索引,大量空值會(huì)降低索引效率
3.4.避免在數(shù)據(jù)值分布不均的字段上建立索引,個(gè)別數(shù)據(jù)值占總數(shù)據(jù)量的百分率明顯比其它數(shù)據(jù)值占總數(shù)據(jù)量的百分率高,表明該字段數(shù)據(jù)值分布不均,容易引起數(shù)據(jù)庫選擇錯(cuò)誤索引,生成錯(cuò)誤的查詢執(zhí)行計(jì)劃。
3.5.在數(shù)據(jù)量較少且訪問頻率不高的情況下,如只有一百行記錄以下的表不需要建立索引。因?yàn)樵跀?shù)據(jù)量少的情況下,使用全表掃描效果比走索引更好。
3.6.字符字段必須建前綴索引
單字母區(qū)分度:26
4個(gè)字母區(qū)分度:26*26*26*26=456976
6個(gè)字母區(qū)分度:26*26*26*26*26*26=308915776
CREATE TABLE `test1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`a` char(20) NOT NULL DEFAULT '',
`b` varchar(14) NOT NULL DEFAULT '00000000000000',
`c` varchar(14) DEFAULT '00000000000000',
PRIMARY KEY (`id`),
KEY `a` (`a`(6))
) ENGINE=MyISAM AUTO_INCREMENT=12534199 DEFAULT CHARSET=gbk;
mysql> select sql_no_cache count(*) from test1;
+----------+
| count(*) |
+----------+
| 12534198 |
+----------+
1 row in set (0.00 sec)
mysql> select sql_no_cache count(*) from test1 where a = 'tR6cDjx0frXx45yURG1m';
+----------+
| count(*) |
+----------+
| 1 |
+----------+
1 row in set (0.00 sec)
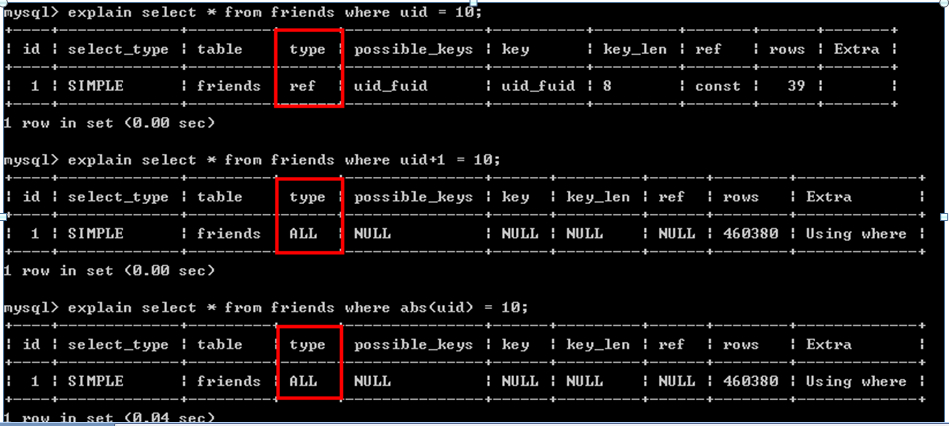
3.7.不在索引列做運(yùn)算,盡量不用外鍵(InnoDB)
3.8.唯一索引:在建立索引的字段所有數(shù)值都具有唯一性特點(diǎn)的情況下,建立唯一索引(unique index)代替普通索引,唯一索引(unique index)查詢效率比普通索引查詢效率更高,可以大幅提升查詢速度。
4.組合索引
4.1.避免建立兩個(gè)或以上功能相同索引。例如已經(jīng)建立字段A、B兩個(gè)字段的索引,應(yīng)該避免再建立字段A的單獨(dú)索引。兩個(gè)索引之間,對(duì)相同的查詢都會(huì)起到相同的作用。建立兩個(gè)功能相同的索引,反而會(huì)容易引起數(shù)據(jù)庫產(chǎn)生錯(cuò)誤的查詢計(jì)劃,降低查詢效率。
4.2.選擇正確的組合索引字段順序,最常用的查詢字段和選擇性、區(qū)分度較高的字段,應(yīng)該作為索引的前導(dǎo)字段使用。
假設(shè)存在組合索引it1c1c2(c1,c2),查詢語句select * from t1 where c1=1 and c2=2能夠使用該索引。查詢語句select * from t1 where c1=1也能夠使用該索引。但是,查詢語句select * from t1 where c2=2不能夠使用該索引,因?yàn)闆]有組合索引的引導(dǎo)列,即,要想使用c2列進(jìn)行查找,必需出現(xiàn)c1等于某值。
4.3.合適的字段數(shù),組合索引的字段數(shù)不適宜較多,較多的組合索引字段數(shù)會(huì)降低索引查詢效率,組合索引字段數(shù)應(yīng)不多于3個(gè),如業(yè)務(wù)特點(diǎn)需要建立多字段的組合主鍵例外。
關(guān)于一個(gè)B-Tree索引的例子:
假設(shè)有如下一個(gè)表:
CREATE TABLE People (
last_name varchar(50) not null,
first_name varchar(50) not null,
dob date not null,
gender enum('m', 'f') not null,
key(last_name, first_name, dob)
);
其索引包含表中每一行的last_name、first_name和dob列。其結(jié)構(gòu)大致如下:
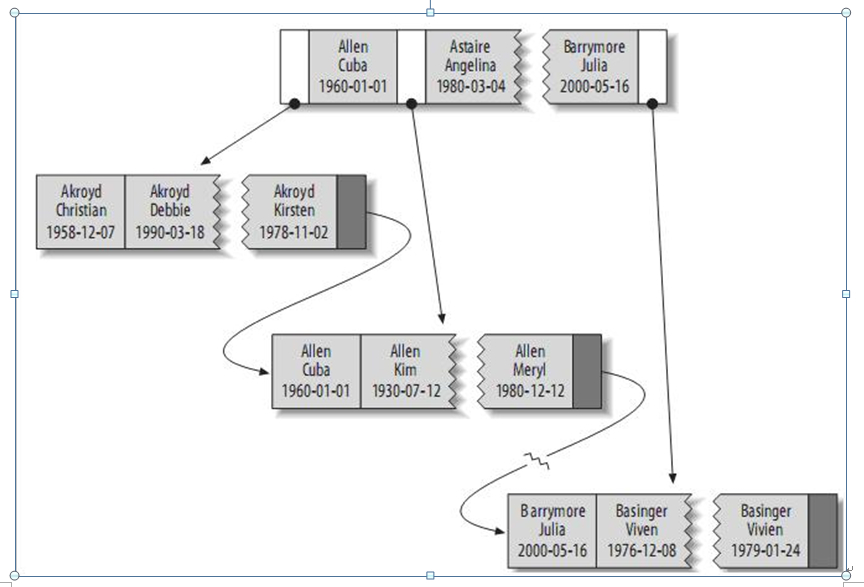
索引存儲(chǔ)的值按索引列中的順序排列。可以利用B-Tree索引進(jìn)行全關(guān)鍵字、關(guān)鍵字范圍和關(guān)鍵字前綴查詢,當(dāng)然,如果想使用索引,你必須保證按索引的最左邊前綴(leftmost prefix of the index)來進(jìn)行查詢。
(1)匹配全值(Match the full value):對(duì)索引中的所有列都指定具體的值。例如,上圖中索引可以幫助你查找出生于1960-01-01的Cuba Allen。
(2)匹配最左前綴(Match a leftmost prefix):你可以利用索引查找last name為Allen的人,僅僅使用索引中的第1列。
(3)匹配列前綴(Match a column prefix):例如,你可以利用索引查找last name以J開始的人,這僅僅使用索引中的第1列。
(4)匹配值的范圍查詢(Match a range of values):可以利用索引查找last name在Allen和Barrymore之間的人,僅僅使用索引中第1列。
(5)匹配部分精確而其它部分進(jìn)行范圍匹配(Match one part exactly and match a range on another part):可以利用索引查找last name為Allen,而first name以字母K開始的人。
(6)僅對(duì)索引進(jìn)行查詢(Index-only queries):如果查詢的列都位于索引中,則不需要讀取元組的值。
由于B-樹中的節(jié)點(diǎn)都是順序存儲(chǔ)的,所以可以利用索引進(jìn)行查找(找某些值),也可以對(duì)查詢結(jié)果進(jìn)行ORDER BY。當(dāng)然,使用B-tree索引有以下一些限制:
(1) 查詢必須從索引的最左邊的列開始。關(guān)于這點(diǎn)已經(jīng)提了很多遍了。例如你不能利用索引查找在某一天出生的人。
(2) 不能跳過某一索引列。例如,你不能利用索引查找last name為Smith且出生于某一天的人。
(3) 存儲(chǔ)引擎不能使用索引中范圍條件右邊的列。例如,如果你的查詢語句為WHERE last_name="Smith" AND first_name LIKE 'J%' AND dob='1976-12-23',則該查詢只會(huì)使用索引中的前兩列,因?yàn)長IKE是范圍查詢。
另一個(gè)例子:
CREATE TABLE `friends` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`uid` bigint(20) unsigned NOT NULL DEFAULT '0',
`fuid` bigint(20) unsigned NOT NULL DEFAULT '0',
`fname` varchar(50) NOT NULL DEFAULT '',
`fpicture` varchar(150) NOT NULL DEFAULT '',
`fsex` tinyint(1) NOT NULL DEFAULT '0',
`status` tinyint(1) NOT NULL DEFAULT '0',
PRIMARY KEY (`id`),
KEY `uid_fuid` (`uid`,`fuid`)
) ENGINE=MyISAM DEFAULT CHARSET=gbk;
下一個(gè)
5.覆蓋索引(Covering Indexes)
如果索引包含滿足查詢的所有數(shù)據(jù),就稱為覆蓋索引。覆蓋索引是一種非常強(qiáng)大的工具,能大大提高查詢性能。只需要讀取索引而不用讀取數(shù)據(jù)有以下一些優(yōu)點(diǎn):
(1)索引項(xiàng)通常比記錄要小,所以MySQL訪問更少的數(shù)據(jù);
(2)索引都按值的大小順序存儲(chǔ),相對(duì)于隨機(jī)訪問記錄,需要更少的I/O;
(3)大多數(shù)據(jù)引擎能更好的緩存索引。比如MyISAM只緩存索引。
(4)覆蓋索引對(duì)于InnoDB表尤其有用,因?yàn)镮nnoDB使用聚集索引組織數(shù)據(jù),如果二級(jí)索引中包含查詢所需的數(shù)據(jù),就不再需要在聚集索引中查找了。
注意:覆蓋索引不能是任何索引,只有B-TREE索引存儲(chǔ)相應(yīng)的值。而且不同的存儲(chǔ)引擎實(shí)現(xiàn)覆蓋索引的方式都不同,并不是所有存儲(chǔ)引擎都支持覆蓋索引(Memory和Falcon就不支持)。
對(duì)于索引覆蓋查詢(index-covered query),使用EXPLAIN時(shí),可以在Extra一列中看到“Using index”
CREATE TABLE `friends` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`uid` bigint(20) unsigned NOT NULL DEFAULT '0',
`fuid` bigint(20) unsigned NOT NULL DEFAULT '0',
`fname` varchar(50) NOT NULL DEFAULT '',
`fpicture` varchar(150) NOT NULL DEFAULT '',
`fsex` tinyint(1) NOT NULL DEFAULT '0',
`status` tinyint(1) NOT NULL DEFAULT '0',
PRIMARY KEY (`id`),
KEY `uid_fuid` (`uid`,`fuid`)
) ENGINE=MyISAM DEFAULT CHARSET=gbk;

6.排序
MySQL中,有兩種方式生成有序結(jié)果集:
a. filesort 糟糕
b. Index排序 好
什么時(shí)候使用Index排序?
當(dāng)索引的順序與ORDER BY中的列順序相同且所有的列是同一方向(全部升序或者全部降序)時(shí),可以使用索引來排序。其它情況都會(huì)使用filesort。
什么時(shí)候使用filesort?
當(dāng)MySQL不能使用Index排序時(shí),就會(huì)利用自己的排序算法(快速排序算法)在內(nèi)存(sort buffer)中對(duì)數(shù)據(jù)進(jìn)行排序,如果內(nèi)存裝載不下,它會(huì)將磁盤上的數(shù)據(jù)進(jìn)行分塊,再對(duì)各個(gè)數(shù)據(jù)塊進(jìn)行排序,然后將各個(gè)塊合并成有序的結(jié)果集(實(shí)際上就是外排序)。
當(dāng)對(duì)連接操作進(jìn)行排序時(shí),如果ORDER BY僅僅引用第一個(gè)表的列,MySQL對(duì)該表進(jìn)行filesort操作,然后進(jìn)行連接處理,此時(shí),EXPLAIN輸出“Using filesort”;
否則,MySQL必須將查詢的結(jié)果集生成一個(gè)臨時(shí)表,在連接完成之后進(jìn)行filesort操作,此時(shí),EXPLAIN輸出“Using temporary;Using filesort”。
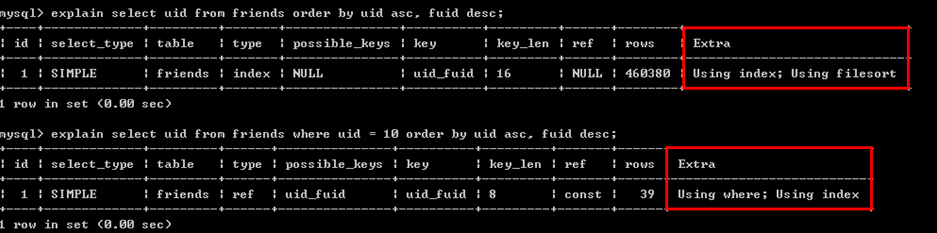
通過索引優(yōu)化來實(shí)現(xiàn)MySQL的ORDER BY語句優(yōu)化例子:
1、ORDER BY的索引優(yōu)化。如果一個(gè)SQL語句形如:
SELECT [column1],[column2],…. FROM [TABLE] ORDER BY [sort];
在[sort]這個(gè)欄位上建立索引就可以實(shí)現(xiàn)利用索引進(jìn)行order by 優(yōu)化。
2、WHERE + ORDER BY的索引優(yōu)化,形如:
SELECT [column1],[column2],…. FROM [TABLE] WHERE [columnX] = [value] ORDER BY [sort];
建立一個(gè)聯(lián)合索引(columnX,sort)來實(shí)現(xiàn)order by 優(yōu)化。
注意:如果columnX對(duì)應(yīng)多個(gè)值,如下面語句就無法利用索引來實(shí)現(xiàn)order by的優(yōu)化
SELECT [column1],[column2],…. FROM [TABLE] WHERE [columnX] IN ([value1],[value2],…) ORDER BY[sort];
3、WHERE+ 多個(gè)字段ORDER BY
SELECT * FROM [table] WHERE uid=1 ORDER x,y LIMIT 0,10;
建立索引(uid,x,y)實(shí)現(xiàn)order by的優(yōu)化,比建立(x,y,uid)索引效果要好得多。
MySQL Order By不能使用索引來優(yōu)化排序的情況:
1、對(duì)不同的索引鍵做 ORDER BY :(key1,key2分別建立索引)
SELECT * FROM t1 ORDER BY key1, key2;

2、用于where語句的索引和ORDER BY 的不是同一個(gè):(key1,key2分別建立索引)
SELECT * FROM t1 WHERE key2=constant ORDER BY key1;

3、同時(shí)使用了 ASC 和 DESC:(key_part1,key_part2建立聯(lián)合索引),通過where語句將order by中索引列轉(zhuǎn)為常量,則除外
SELECT * FROM t1 ORDER BY key_part1 DESC, key_part2 ASC;
4、如果在WHERE或ORDER BY的欄位上應(yīng)用表達(dá)式(函數(shù))時(shí),則無法利用索引來實(shí)現(xiàn)order by的優(yōu)化
SELECT * FROM t1 ORDER BY YEAR(logindate) LIMIT 0,10;

5、檢查的行數(shù)過多,且沒有使用覆蓋索引
6、where語句中使用了條件查詢

7.關(guān)于group by或distinct
7.1.盡量只對(duì)存在索引的字段進(jìn)行g(shù)roup by或distinct。當(dāng)group by 不能使用index 時(shí)mysql有兩種處理方法:臨時(shí)表和filesort。
7.2.在group by 語句中mysql會(huì)自動(dòng)order,如果不需要可使用order by null來禁止自動(dòng)的order。
8.關(guān)于索引失效
8.1.避免對(duì)索引字段計(jì)算
8.2.避免使用索引列值是否可為空的索引,如果索引列值可以是空值,在SQL語句中那些要返回NULL值的操作,將不會(huì)用到索引。
8.3.相同的索引列不能互相比較,這將會(huì)啟用全表掃描,如tab1上存在索引idx_col1_col2(col1,col2),其中col1和col2都是int型。則查詢語句SELECT * FROM tab1 WHERE col1>col2;是不會(huì)使用索引的。
8.4.避免使用存在潛在的數(shù)據(jù)類型轉(zhuǎn)換的索引。潛在的數(shù)據(jù)轉(zhuǎn)換,查詢條件中是指由于等式兩端的數(shù)據(jù)類型不一致。例如索引字段使用的是數(shù)字類型,而條件等式的另一端數(shù)據(jù)類型是字符類型,數(shù)據(jù)庫將會(huì)對(duì)其中一端進(jìn)行數(shù)據(jù)類型轉(zhuǎn)換,數(shù)據(jù)類型的轉(zhuǎn)換會(huì)讓索引的作用失效,令數(shù)據(jù)庫選擇其他的較為低效率的訪問路徑。

8.5.使用索引列作為條件進(jìn)行查詢時(shí),需要避免使用<>或者!=等判斷條件。如確實(shí)業(yè)務(wù)需要,使用到不等于符號(hào),需要在重新評(píng)估索引建立,避免在此字段上建立索引,改由查詢條件中其他索引字段代替。
a)盡量避免負(fù)向查詢:NOT、!=、<>、!<、!>、NOT EXISTS、NOT IN、NOT LIKE,避免%前模糊查詢
b)WHERE條件中的范圍查詢(IN、BETWEEN、<、<=、>、>=)會(huì)導(dǎo)致后面的條件使用不了索引。
8.6.使用索引列作為條件進(jìn)行范圍查詢時(shí),應(yīng)該避免較大范圍取值。
posted on 2014-05-08 19:48
zhangxl 閱讀(2033)
評(píng)論(4) 編輯 收藏 所屬分類:
DB