前面已經詳細介紹過WTP語法Document(IStructuredDocument)、WTP語義Document(IDOMDocument或ICSSDocument)和WTP Model(IStructuredModel),在本節中將從總體上再看一下對我們后續基于WTP進行代碼定制很重要的點,同時將補充最核心的一個點:WTP中的模型管理機制。
PS:如果前面的幾節是探微的過程,那邊本節將完成知著的過程,“探微知著”^_^
【語法Document、語義Document、WTP Model】
 (說明:上圖中的實線可以理解為引用關系。)
(說明:上圖中的實線可以理解為引用關系。)
 【從引用關系層面看】
【從引用關系層面看】
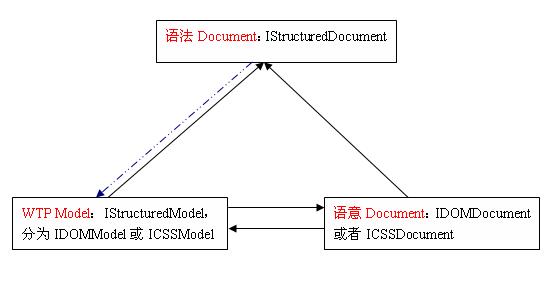
1、從上圖一可以看的出來,IStructuredDocument并不引用IStrcuturedModel或者IDOMDocument(或ICSSDocument),也就是說
IStructuredDocument本身并不關心IStrcuturedModel或者IDOMDocument(或ICSSDocument)的存在
2、結合上圖一和上圖二,可以看的出來IStructuredModel將IStructuredDocument和IDOMDocument(或ICSSDocument)作為其兩個組成部分。換個角度說,
如果已知IStructuredModel存在的情況下,IStructuredModel可以作為三者的門面,對IStructuredModel進行管理也就間接對IStructuredDocument和IDOMDocument(或ICSSDocument)進行管理
3、我們解釋一下上圖一中的那條藍色虛線,我們已經說過
IStructuredDocument本身并不關心IStrcuturedModel或者IDOMDocument(或ICSSDocument)的存在,所以要想以IStructuredDocument獲取對應的IStructuredModel,需要一個第三方的角色,來維護從IStructuredDocument到IStructuredModel的映射關系,這個角色就是后面要說的WTP提供的IModelManager。如果IStructuredDocument通過IModelManager獲取到了對應的IStructuredModel,那么再通過IStructuredModel可以自然獲取到對應的語義Document(IDOMDocument或者ICSSDocument)。這樣三者就完全聯系起來了^_^
我們看一下,以上的引用關系對應的API接口是什么(需要熟練掌握):
1、WTP Model --》 語法Document
IStructuredModel.getStructuredDocument()
2、WTP Model --》 語義Document
IDOMModel.getDocument 返回的語義Document類型為IDOMDocument
ICSSModel.getDocument 返回的語義Document類型為ICSSDocument
3、語義Document --》 WTP Model
IDOMNode.getModel (IDOMDocument本身就是IDOMNode^_^)
ICSSDocument.getModel
4、語法Document --》 WTP Model
前提:對應的IStructuredModel已經被WTP提供的IModelManager托管了,否則是沒有意義的(前面說過,因為IStructuredDocument并不關心IStructuredModel和語義Document是否存在)
IModelManager.getModelForEdit(IStructuredDocument)
IModelManager.getModelForRead(IStructuredDocument)
5、語法Document --》 語義Document
前提:對應的IStructuredModel已經被WTP提供的IModelManager托管了!!!
步驟:語法Document --》 WTP Model --》 語義Document
6、語義Document --》 語法Document
方法一:IDOMNode.getStructuredDocument
方法二:語義Document --》 WTP Model --》 語法Document
PS:通過上面的5和6也可以體會到,WTP Model存在的情況下,完全可以在語法Document和語義Document之前起到一個橋梁的作用
【從依賴關系層面看】
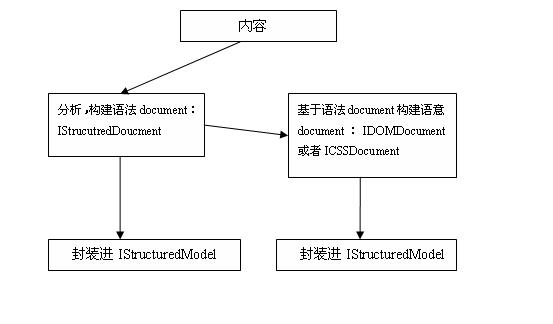
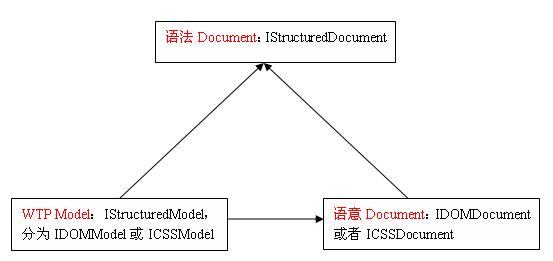
1、通過上圖二IStructuredModel的構造過程就可以看的出來,WTP Model和語義Document(IDOMDocument或者ICSSDocument)都是以IStructuredDocument為基礎,也就是說依賴于它
2、語法Document(IStructuredDocument)不需要關心其他兩者是否存在
3、語義Document(IDOMDocument或者ICSSDocument)依賴于語法Document(IStructuredDocument)
4、一個完整的WTP Model必須有對應的語法Document和語義Document,從這個意義上將,可以理解為WTP Model需要依賴語法Document和語義Document。
由上面四點,我們可以簡要的畫一個三者之間的依賴關系圖:
 (依賴關系圖:上圖中的實線可以理解為依賴關系)
【從動態變化角度看(簡要了解一下就可以了^_^)】
(依賴關系圖:上圖中的實線可以理解為依賴關系)
【從動態變化角度看(簡要了解一下就可以了^_^)】
上面我們講了這么多三者之間的關系,好像總感覺是從靜態的角度出發的,那么如果三者中的一者發生變化了,三者直接又會又什么樣的互動呢?
1、
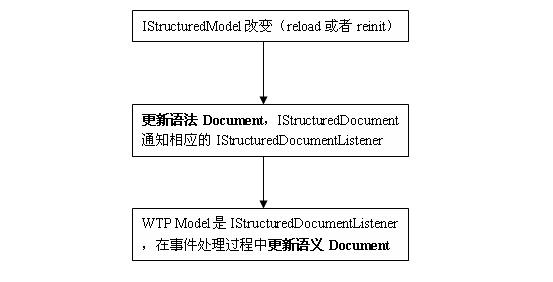
WTP Model作為變化源,變化情況如下:
IStructuredModel引發的變化,通常情況下就是調用了IStructuredModel的reload和reinit的操作。這個操作會修改其持有的IStructuredDocument,引起IStructuredDocument改變事件。IStructuredModel本身又是一個IStructuredDocumentListener,所以會處理這種變化,在變化的處理過程中包含了修改其持有的語義Document。大致過程示意圖如下:
2、
IStructuredDocument作為變化源,變化情況如下(這將是我們最常見的情況):
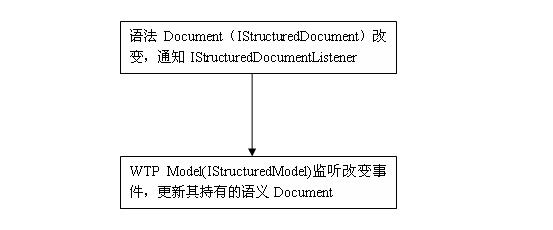
3、
IDOMDocument作為變化源,變化情況如下:
//獲取語義Document
IDOMDocument domDocument = ((IDOMModel)structuredModel).getDocument();
//修改語義Document,例如刪除其第一個節點
Node node = domDocument.getChildNodes().item(0);
domDocument.removeChild(node);
以上代碼會發生如下事情:首先DOM Document被修改,然后會回調DOMModelImpl中對應的更新方法(例如DOMModelImpl.childReplaced),然后會調用一個XMLModelUpdater的角色,在這個XMLModelUpdater會去更新IStructuredDocument(replace text操作),這進而會引發IStructuredDocument改變事件,會進而進入上面已經闡述過的循環。大致示意圖如下:
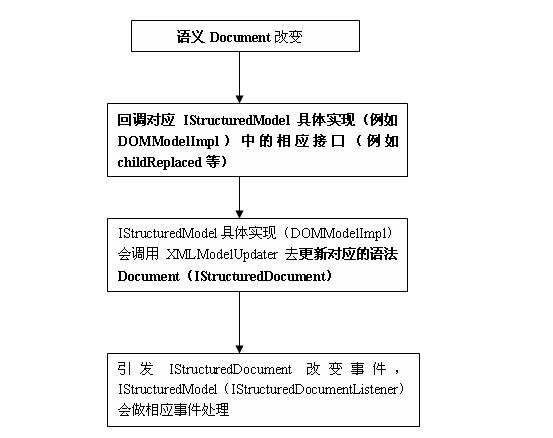
說明:語義Document(IDOMDoucment或者ICSSDocument)持有一個IStructuredModel的引用,所以才有了上圖中的回調。可以看的出來語義Document(IDOMDoucment或者ICSSDocument)并沒有提供對應的listener接口,采用的是直接回調的辦法。
上面三個動態變化需要經常使用這幾個WTP數據模型才能有比較深的印象,考慮到確實有點繁瑣,所以就不做代碼分析了,這里留個大概印象就可以了。
提醒:IStructuredModel對應的三個子類(AbstractStructuredModel、DOMModelImpl和CSSModelImpl)分別都有IStructuredDocumentListener實現,有時間可以看一下這些實現之間的差別,對加深WTP數據模型的認識會有幫助。
【IModelManager!!!】
(
IModelManager:org.eclipse.wst.sse.core.internal.provisional.IModelManager)
【IModelManager為什么存在?】
我們先來考慮幾個問題:
1、 無論是語法Document還是語義Document的實例化過程(可不是new一個實例那么簡單^_^)都十分繁瑣,這個實例化的活是留給客戶調用端還是提供一個負責實例化的中間角色(客戶端通過調用這個中間角色來完成實例化的工作)?
答案:肯定盡量選擇后者。將客戶端和對象的繁瑣實例化過程進行解耦,是一個我們應該盡量遵循的規則。這個封裝了實例化過程的中間角色就是IModelLoader:org.eclipse.wst.sse.core.internal.provisional.IModelLoader)和IDocumentLoader(org.eclipse.wst.sse.core.internal.document.IDocumentLoader),我可以寬泛地將這個中間角色理解為工廠,而且實例化過程可能有變化,所以這個工廠不能是一個簡單靜態工廠,而應該是一個工廠方法應用(為什么不是抽象工廠,因為不是創建相關的系列實例,也談不上什么幾個產品系列^_^)。
2、一個WTP Model同時持有一個重量級的語法Document和語義Document,這個兩個Document無論是在時間占用(解析過程十分耗時),還是在內存占用方法都比較客觀。那么,如果我們對WTP Model實例進行緩存管理,在內存占用可接受的情況下可以大大解決時間占用的性能瓶頸問題,不挺好嗎?
答案:是挺好的^_^。 IModelManager一部分任務就是干這個事情。注意這邊的緩存管理可不簡單就是將對象存儲下來這么簡單,也需要提供用于更新被緩存對象的方法。
3、如果提供能夠將上面兩個角色組合在一起,對一般用戶而且使用起來是不是會更方便一點?
答案:是的。但是有點不太優雅,職責有點混淆,不過問題不是很丑陋^_^。
回答完以上三個問題之后,我們可以猜測出來IModelManager承擔的兩個個核心任務:
1、創建型工廠(IDocumentLoader、IModelLoader)的門面,提供創建接口
2、緩存管理:包含緩存實例的存儲管理和更新維護等任務。
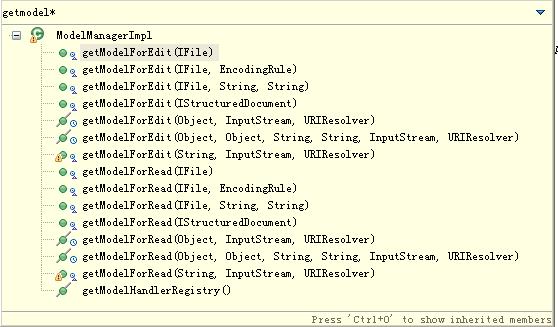
【IModelManager創建職責】

說明:
1、
上圖中包含了創建IStructuredModel、IStructuredDocument的方法,并沒有提供創建語義Document(IDOMDocument或者ICSSDocument)的方法。為什么?我們前面說過IStructuredDocument可以并不關心IStructuredModel或者語義Document是否存在,所以可以允許獨立創建;而語法Document和語義Document是IStructuredModel的兩個必然組成部分,所以提供了IStructuredModel的創建方法,就間接提供了語義Document的創建服務。
2、
以上創建方法返回的實例都是未經托管的,每次都會創建一個新的實例。千萬不要誤認為IModelManager提供的創建方法返回的實例都是緩存的!!!^_^ 前面說過,WTP提供的語法Document和語義Document在時間占用和內存占用方面都是比較可觀的,小心!!!!!!!!!!!!!!
3、注意createStructuredDocumentFor(IFile iFile)和createNewStructuredDocumentFor(IFile iFile)兩個方法的正確用法,前者基于iFile存在,后者基于iFile不存在。
【IModelManager管理職責】
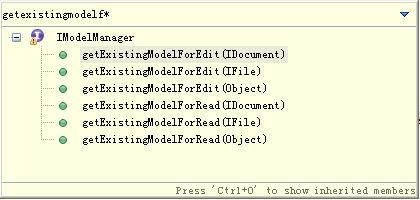
說明:
1、
getModelFor*不假定模型已經被托管,沒有對應的模型情況下會創建一個新的被托管的實例(但是不能以IDocument為參數);getExistingModelFor*假設有對應的被托管模型存在于IModelManager種,否則返回null,不創建新的被托管實例。
2、
getModelFor*和getExistingModelFor*都涉及到引用計數的概念,每次調用都會增加read或者editor計數,使用完畢之后應該調用IStructuredModel.releaseFromEdit或者IStructuredModel.releaseFromRead。
3、IModelManager并沒有提供IStructuredDocument的獲取接口,因為IModelManager管理的目標只是IStructuredModel。IStructuredDocument雖然可以脫離IStructuredModel獨立存在,但是IModelManager不提供管理。
4、使用getModelFor*(IDocument)和getExistingModelFor*(IDocument)的前提必須是有對應的IStructuredModel被托管了。示例代碼:
try {
IFile file = ResourcesPlugin.getWorkspace().getRoot().getFile(new Path("/project/WebContent/Test2.jsp"));
IStructuredDocument document = StructuredModelManager.getModelManager().createStructuredDocumentFor(file);
Object model1 = StructuredModelManager.getModelManager().getModelForRead(document);
Object model2 = StructuredModelManager.getModelManager().getExistingModelForEdit(document);
} catch (Exception e) {
e.printStackTrace();
}
如果上面代碼種的file代表的資源沒有對應的IStructuredModel被托管,則model1和model2的獲取都會引發異常。如果調用getModelFor*(IFile)或 getExistingModelFor*(IFile)則不會出現問題。
PS:IModelManager的其他操作就不一一列舉了,具體可以看一下對應代碼。IModelManager的獲取方式上面代碼中已經體現:org.eclipse.wst.sse.core.StructuredModelManager中提供了getModelManager操作來獲取IModelManager實例。
【使用WTP IModelManager一定要注意的地方】
1、根據你的模型是否需要被緩存托管,判斷該調用什么方法。如果不需要被托管的模型卻被緩存托管了,則會大大增加內存占用。
2、注意維護引用計數平衡
【語法Region VS 語義Region】
語法Document(IStructuredDocument)提供了語法Region(ITextRegion)的概念,語義Document(IDOMDocument或者ICSSDocument)對應的是語義Region(IndexedRegion、IDOMNode、ICSSNode),那我們現在來看一下它們之間的區別和聯系。
【區別】
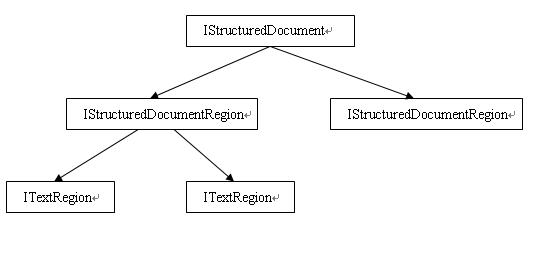
顯而易見,語法Region(ITextRegion)是按照語法進行劃分的,既然是structured region,那么劃分時候一個重要的判斷依據就是特定的文本是否是結構化的。IStructuredDocumentRegion代表的就是一個結構化的region,里面會含有一系列的葉子節點的text region。
IStructuredDocumentRegion之間并不會呈現父子關系,例如父子標簽之間是獨立的IStructuredDocumentRegion,因為這個父子是從語義層面才有意思。
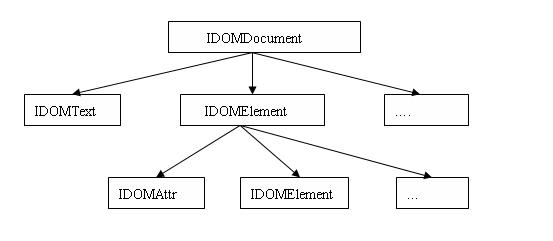
語義Region(IndexedRegion、IDOMNode、ICSSNode)則是按照語義進行劃分的,體現的語義層面的包含關系。例如,子標簽會作為一個child node(IDOMElement)存在于父標簽中(同樣是一個IDOMElement);再例如一個IDOMAttr表示一個屬性,如果切換到語法region視角,則對應于三個ITextRegion:AttributeNameRegion、AttributeEqualsRegion、AttributeValueRegion。
一句話,根據應用場景的不同你可以選擇借助語法region進行分析或者借助語義region進行分析。例如:如果要判斷一個標簽是否在其特定父標簽中,則用語義region進行分析會方便很多^_^。
【聯系】
那我們如何將語法Region和語義Region比較方便的聯系起來呢?
答案:offset(位置信息)!!!
基于語法Document構建語義Document,說白了就是把語法region列表重新組織為語義region列表,語法region本身就持有位置信息,語義region會持有對應的語法region,所以語義region本身也可以提供位置信息了。前面曾經說過,所有的語義region都是IndexedRegion接口的實現,IndexedRegion定義的核心操作也就是獲取位置信息的。
根據offset信息可以定位到對應的語法region或者語義region,涉及到的方法前面已經在講述相關接口的時候講述過,這邊就不再重復了。(這些東西用用就熟悉了^_^)
IndexedRegion IStructuredModel.getIndexedRegion(int offset)
IStructuredDocumentRegion IStructuredDocument.getRegionAtCharacterOffset(int offset)
PS:如果你持有的是一個語義region,則可以直接根據語義region去獲取其引用的語法region。
【后記】
到目前,WTP數據模型相關的東西真的告一段落了,其實這并不是WTP數據模型的全部,后門我們在定義具體功能的時候會順便再講一下其他的數據模型,我們可以把那些模型稱之為元數據模型,很多其實就是再IStructuredModel基礎之上再提供額外的描述信息。
本博客中的所有文章、隨筆除了標題中含有引用或者轉載字樣的,其他均為原創。轉載請注明出處,謝謝!