0. 引子
傳說:“聚類是人類最原始的精神活動��,用于處理他們每天接收到的大量信息”��。為方便廣大同學學習使用��,將我學習聚類時的筆記整理發(fā)布共享。
1. 聚類定義
“聚類是把相似的對象通過靜態(tài)分類的方法分成不同的組別或者更多的子集(subset),這樣讓在同一個子集中的成員對象都有相似的一些屬性��。” ——wikipedia
“聚類分析指將物理或抽象對象的集合分組成為由類似的對象組成的多個類的分析過程��。它是一種重要的人類行為�����。聚類是將數據分類到不同的類或者簇這樣的一個過程,所以同一個簇中的對象有很大的相似性��,而不同簇間的對象有很大的相異性�����。” ——百度百科
說白了��,聚類(clustering)是完全可以按字面意思來理解的——將相同、相似���、相近、相關的對象實例聚成一類的過程���。簡單理解,如果一個數據集合包含N個實例��,根據某種準則可以將這N個實例劃分為m個類別�����,每個類別中的實例都是相關的���,而不同類別之間是區(qū)別的也就是不相關的,這個過程就叫聚類了�����。
形式化一點���,令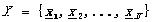 ��,其中的x都是向量�����,一個X的m聚類R將X分割為m個集合C1, C2,…,Cm,使其滿足下面三個條件:
��,其中的x都是向量�����,一個X的m聚類R將X分割為m個集合C1, C2,…,Cm,使其滿足下面三個條件:
(1)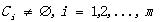
(2)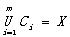
(3)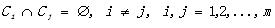
滿足上述條件的同時,在聚類Ci中的向量彼此相似���,而與其他類中的向量不相似。
但是這種定義也只是定義了確定性的聚類,也叫做硬聚類(hard clustering)�����,每個實例x都確定的屬于某個聚類�����。而不確定性聚類�����,也需要定義�����,這就引出了模糊聚類(fuzzy clustering)的概念了。模糊聚類中,每個實例向量x以一定的隸屬度屬于某個聚類��。同上面的設置���,X的模糊聚類是將X分成m個類���,由m個函數uj表示�����,其中滿足:
(1)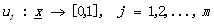
(2)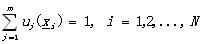
(3)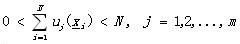
其中這個隸屬度函數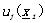 越接近1,說明xi越可能屬于Ci,反之如果越接近0,則說明越不可能屬于Ci�����。
越接近1,說明xi越可能屬于Ci,反之如果越接近0,則說明越不可能屬于Ci�����。
2. 聚類過程
當我們知道聚類是什么時��,我們下一步想知道的應該是怎么進行聚類�����。這一點,教材上做了詳細介紹���,補充一點自己理解:
1)特征選擇(feature selection):就像其他分類任務一樣,特征往往是一切活動的基礎�����,如何選取特征來盡可能的表達需要分類的信息是一個重要問題�����。表達性強的特征將很影響聚類效果���。這點在以后的實驗中我會展示。
2)近鄰測度(proximity measure):當選定了實例向量的特征表達后���,如何判斷兩個實例向量相似呢?這個問題是非常關鍵的一個問題���,在聚類過程中也有著決定性的意義,因為聚類本質在區(qū)分相似與不相似���,而近鄰測度就是對這種相似性的一種定義。
3)聚類準則(clustering criterion):定義了相似性還不夠���,結合近鄰測度,如何判斷相似才是關鍵��。直觀理解聚類準則這個概念就是何時聚類��,何時不聚類的聚類條件��。當我們使用聚類算法進行計算時,如何聚類是算法關心的��,而聚與否需要一個標準���,聚類準則就是這個標準��。(話說標準這東西一拿出來��,夠嚇人了吧^_^)
4)聚類算法(clustering algorithm):這個東西不用細說了吧,整個學習的重中之重��,核心的東西這里不講��,以后會細說��,簡單開個頭——利用近鄰測度和聚類準則開始聚類的過程。
5)結果驗證(validation of the results):其實對于PR的作者提出這個過程也放到聚類任務流程中,我覺得有點冗余�����,因為對于驗證算法的正確性這事應該放到算法層面吧�����,可以把4)和5)結合至一層��。因為算法正確和有窮的驗證本身就是算法的特性嘛。(誰設計了一個算法不得證明?�。?/span>
6)(interpretation of the results):中文版的PR上翻譯為結果判定�����,而我感覺字面意思就是結果解釋�����。(聚類最終會將數據集分成若干個類,做事前要有原則��,做事后要有解釋���,這個就是解釋了���。自圓其說可能是比較好的了^_^)
整個聚類任務詳細的東西會在以后詳細介紹�����,這里先細說一下聚類準則(雖然我感覺在上面我說的已經夠細了)��。舉例吧,比如,有這樣一個數據集X�����,包含了四名同學的基本信息和數學成績���。
|
姓名
|
年級
|
班級
|
數學成績
|
|
張三
|
1
|
2
|
99
|
|
李四
|
2
|
2
|
95
|
|
張飛
|
3
|
1
|
59
|
|
趙云
|
2
|
1
|
90
|
聚類準則就是一個分類標準���,對于示例中這樣一個數據集合��,如何聚類呢。當然聚類的可能情況有很多。比如��,如果我們按照年級是否為大于1來分類��,那么數據集X分為兩類:{張三}���,{李四��,張飛,趙云}��;如果按照班級不同來分���,分為兩類:{張三��,李四}���,{張飛��,趙云};如果按照成績是否及格來分(假設及格為60分)��,分兩類:{張三��,李四�����,趙云},{張飛}。當然聚類準則的設計往往是復雜的�����,就看你想怎么劃分了�����。按照對分類思想的幾何理解���,數據集相當于樣本空間��,數據實例的特征數(本例共有4個特征[姓名,年級�����,班級���,數學成績])相當于空間維度��,而實例向量對應到空間中的一個點�����。那么聚類準則就應該是那些神奇的超平面(對應有數學函數表達式,我個人認為這些函數就等同于聚類準則),這些超平面將數據“完美的”分離開了�����。
3. 聚類特征類型
聚類時用到的特征如何區(qū)分呢��,有什么類型要求��?聚類的特征按照域劃分,可以分為連續(xù)的特征和離散特征��。其中連續(xù)特征對應的定義域是數據空間R的連續(xù)子空間���,而離散特征對應的是離散子集���,另外如果離散特征只包含兩個特征值�����,那么這個離散特征又叫二值特征�����。
根據特征取值的相對意義又可以將特征分為以下四種:標量的(Nominal),順序的(Ordinal)��,區(qū)間尺度的(Interval-scaled)以及比率尺度的(Ratio-scaled)���。其中��,標量特征用于編碼一類特征的可能狀態(tài)�����,比如人的性別,編碼為男和女��;天氣狀況編碼為陰���、晴和雨等�����。順序特征同標量特征類似,同樣是一系列狀態(tài)的編碼,只是對這些編碼稍加約束�����,即編碼順序是有意義的���,比如對一道菜��,它的特征有{很難吃�����,難吃��,一般,好吃,美味}幾個值來定義狀態(tài)��,但是這些狀態(tài)是有順序意義的�����。這類特征我認為就是標量特征的一個特定子集��,或者是一個加約束的標量特征。區(qū)間尺度特征表示該特征數值之間的區(qū)間有意義而數值的比率無意義���,經典例子就是溫度,A地的溫度(20℃)比B地(15℃)高5度��,這里的區(qū)間差值是有意義的��,但你不能說A地比B地熱1/3�����,這是無意義的。比率特征與此相反,其比率是有意義的���,經典例子是重量��,C重100g���,D重50g���,那么C比D重2倍���,這是有意義的���。(當然說C比D重50g也是可以的���,因此可以認為區(qū)間尺度是比率尺度的一個真子集)���。
在常見應用中��,包括我們平日關心的編程實現中,一般只定義nominal特征和numeric特征,其中nominal可以用string來表示���,而numeric可以用number來表示。(weka中的attribute的特征類型就是這么定義的)
4. 聚類分析的應用
說了這么多基本概念���,最實際的話題莫過于應用了。就像為聚類做廣告一樣�����,到底我們可以在哪里應用它呢��。就像引言里我提到的傳說一樣�����,分類作為人類識別對象的一個基本活動大概與人類的意識共同存在著�����,也可以說人類智能認識的本質活動之一就是分類���。而研究者對分類的研究又將分類劃分為有監(jiān)督與無監(jiān)督�����,其中聚類就是無監(jiān)督分類的最常用方法也是絕對代表性方法。設想一下���,對于一組數據���,或者一堆信息��,計算機可以自動地將其分為若干類,那這對于輔助人類智能來說絕對是必要的也是有意義的���。所以聚類的一個核心應用就是數據挖掘與模式識別。另外各個科學領域只要涉及到分類的任務�����,大家無不聯想到聚類~~~(話說我第一次正式地解除聚類�����,還是在23教學樓聽一個貌似是自動化的教授講的信息化課程)�����。而學者比較權威的分類將聚類的應用分為四個基本的方向:1)數據去冗�����,即將海量數據中的冗余信息去除��。2)假說生成���,為了推導出數據的某些性質��,我們可以對數據進行聚類分析�����。3)假說檢驗,其實就是通過聚類分析來驗證某個決策的風險程度��。4)基于分組的預測��,同所有預測任務一樣����,將已有的數據都聚類分類后�,新的未來數據可以用同樣的規(guī)則進行識別預測其所屬分類。
聚類的應用非常廣泛����,如果按科目枚舉�,我是懶得羅列了��。只要知道了其原理和目標����,其應用領域也就自然理解了��。
5. 小結
聚類的基本概念就是這么些了,關于聚類的學習和研究已經歷經幾十年��,可以慶幸的一點是這里的學習我們可以站在很多巨人的肩膀上�,而如何去改進創(chuàng)新擴展應用,那就是我們未來的目的�,“工欲善其事��,必先利其器”,這里聚類就是我們的“器”了。
6. 參考文獻及推薦閱讀
[1]Pattern Recognition Third Edition, Sergios Theodoridis, Konstantinos Koutroumbas
[2] http://baike.baidu.com/view/903740.htm?fr=ala0_1_1
[3] http://zh.wikipedia.org/zh-cn/%E6%95%B0%E6%8D%AE%E8%81%9A%E7%B1%BB
[4]數據挖掘概念與技術(Data mining concepts and techniques) Jiawei Han, Micheline Kamber著范明, 孟小峰譯
[5]模式識別第三版, Sergios Theodoridis, Konstantinos Koutroumbas著, 李晶皎, 王愛俠, 張廣源等譯
[6]數據挖掘導論(Introduction to data mining) Pang-Ning Tan, Michael Steinbach, Vipin Kumar著范明, 范宏建等譯
[7]數據挖掘實用機器學習技術 (Data mining practical machine learning tools and techniques) Ian H.Witten, Eibe Frank著董琳等譯
文章轉載請標明~~~