利用Java SE 8流處理數據
-- 結合Stream API的高級操作去表示富數據處理查詢
本文是Java Magazine 201405/06刊中的一篇文章,也是文章系列"利用Java SE 8流處理數據"中的第二篇,它基于flatMap()和collect()介紹了Java流的高級用法(2014.08.15最后更新)在本系列的第一篇文章中,你看到了Java流讓你能夠使用與數據庫操作相似的方法去處理集合。作為一個復習,清單1的例子展示了如何使用Stream API去求得大交易的金額之和。我們組建了一個管道,它由中間操作(filter和map)與最終操作(reduce)構成,圖1形象地展示它。清單1int sumExpensive = transactions.stream() .filter(t -> t.getValue() > 1000) .map(Transaction::getValue) .reduce(0, Integer::sum);圖1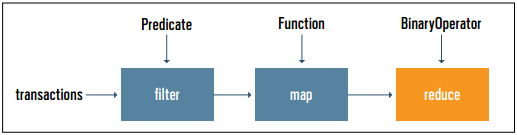 然而在系列的第一部分中,并沒有研究這兩個方法:flatMap:這是一個中間操作,它允許將一個"map"和一個"flatten"操作結合在一起collect:這是一個最終操作,它依據不同的方式,將流中的元素歸集為一個結果。這兩個方法對于表達更為復雜的查詢是十分有用的。例如,你可以將flatMap和collect結合起來,生成代表一個文字流中每個字母出現的次數的Map對象,如清單2所示。如果第一次看到這段代碼覺得很驚奇時,但請不要擔心。本文的目的就是要解釋并探究這兩個方法更多的細節。清單2
然而在系列的第一部分中,并沒有研究這兩個方法:flatMap:這是一個中間操作,它允許將一個"map"和一個"flatten"操作結合在一起collect:這是一個最終操作,它依據不同的方式,將流中的元素歸集為一個結果。這兩個方法對于表達更為復雜的查詢是十分有用的。例如,你可以將flatMap和collect結合起來,生成代表一個文字流中每個字母出現的次數的Map對象,如清單2所示。如果第一次看到這段代碼覺得很驚奇時,但請不要擔心。本文的目的就是要解釋并探究這兩個方法更多的細節。清單2import static java.util.function.Function.identity;
import static java.util.stream.Collectors.*;
Stream<String> words = Stream.of("Java", "Magazine", "is", "the", "best");
Map<String, Long> letterToCount =
words.map(w -> w.split(""))
.flatMap(Arrays::stream)
.collect(groupingBy(identity(), counting()));
清單2中的代碼將會生成如清單3示的結果。棒極了,不是嗎?讓我們開始探究flatMap和collect方法是如何工作的。清單3[a:4, b:1, e:3, g:1, h:1, i:2, ..]
flatMap方法假設你想找出文件中所有獨一唯二的字。你會怎么做呢?你可能認為這很簡單;我們可以Files.lines(),在前面的文章中已見過了這個方法,因為它會返回一個包含文件中所有行的流。然后我們就可以使用map方法將每一行拆分成字,最后再使用distinct方法去除重復的字。第一次嘗試得到的代碼可能如清單4所示。清單4Files.lines(Paths.get("stuff.txt"))
.map(line -> line.split("\\s+")) // Stream<String[]>
.distinct() // Stream<String[]>
.forEach(System.out::println);
不幸的是,這段程序并不十分正確。如果運行它,會得到令人生疑的結果,與下面的輸出有些類似:[Ljava.lang.String;@7cca494b[Ljava.lang.String;@7ba4f24f...我們的第一次嘗試確實打印出了代表幾個流對象的字符串。那發生了什么呢?該方法的問題是,傳給map方法的Lambda表達式返回的是文件中每一行的String數組(String[])。而我們真正想要的是一個表示文字的流的Stream<String>對象。幸運的是,對于該問題有一個解決方案,就是使用flatMap方法。讓我們一步一步地看看如何得到正確的解決方法。首先,我們需要字的流,而不是數組的流。有一個名為Arrays.stream()的方法,它將使用一個數組作為參數,并生成一個流。請看清單5中的例子。清單5String[] arrayOfWords = {"Java", "Magazine"};
Stream<String> streamOfwords = Arrays.stream(arrayOfWords);
讓我們在前面的流管道中使用該方法,看看會發生什么(見清單6)。這個方案依然行不通。那是因為我們最終得到的是一組流的流(準確地說,就是Stream<Stream<String>>)。確切地是,我們首先將每一行轉換為一個字的數組,然后使用方法Arrays.stream()將每一個數組轉換成一個流。清單6Files.lines(Paths.get("stuff.txt"))
.map(line -> line.split("\\s+")) // Stream<String[]>
.map(Arrays::stream) // Stream<Stream<String>>
.distinct() // Stream<Stream<String>>
.forEach(System.out::println);
我們使用flatMap()方法去解決這個問題,如清單7所示。使用flatMap()方法能夠用流中的內容,而不是流去替換每一個生成的數組。換言之,通過map(Arrays::stream)方法生成的全部獨立的流被合并或"扁平化"為一個流。圖2形象地展示了使用flatMap()方法的效果。清單7Files.lines(Paths.get("stuff.txt"))
.map(line -> line.split("\\s+")) // Stream<String[]>
.flatMap(Arrays::stream) // Stream<String>
.distinct() // Stream<String>
.forEach(System.out::println);
本質上,flatMap讓你可以使用其它流去替換另一個流中的每個元素,然后再將所有生成的流連合并為一個流。請注意,flatMap()是一個通用的模式,在使用Optaional或CompletableFuture時,你還會看到它。collect方法現在讓我們看看collect方法的更多細節。在本系列的第一篇文章中你所看到的方法,要么返回另一個流(即,這些方法是中間操作),要么返回一個值,例如一個boolean,一個int,或一個Optional對象(即,這些方法是最終操作)。collect就是一個最終方法,但它有點兒不同,因為你可以用它將一個Stream對象轉為一個List對象。例如,為了得到一個包含有所有高金額交易ID的列表,你可以使用像清單8那樣的代碼。清單8import static java.util.stream.Collectors.*;
List<Integer> expensiveTransactionsIds =
transactions.stream()
.filter(t -> t.getValue() > 1000)
.map(Transaction::getId)
.collect(toList());
傳遞給collect方法的參數就是一個類型為java.util.stream.Collector的對象。這個Collector對象是干什么的?本質上看,它描述了如何按照需要去收集流中的元素,再將它們生成為一個最終結果。之前用到的工廠方法Collector.toList()會返回一個Collector對象,它描述了如何將一個Stream對象歸集為一個List對象。而且,Collctors內建有有許多相似的方法。例如,使用toSet()方法可以將一個Stream對象轉化為一個Set對象,它會刪除所有重復的元素。清單9中的代碼展示了如何生成一個僅僅包含高金額交易所在城市的Set對象。(注意:在后面的例子中,我們假設Collectors類中的工廠方法都已通過語句import static java.util.stream.Collectors.*被靜態引入了)清單9Set<String> cities =
transactions.stream()
.filter(t -> t.getValue() > 1000)
.map(Transaction::getCity)
.collect(toSet());
注意,無法保證會返回何種類型的Set對象。但是,通過使用toCollection(),你可以進行更多的控制。例如,若你想得到一個HashSet,可以傳一個構造器給toCollection方法(見清單10)。清單10Set<String> cities =
transactions.stream()
.filter(t -> t.getValue() > 1000)
.map(Transaction::getCity)
.collect(toCollection(HashSet::new));
然而,這并不是你能用collect和Collector所做的全部事情。實際上,這只是你能用它們所做的事情中的極小部分。下面是一些你所能表達的查詢的例子:將交易按貨幣分類,并計算每種貨幣的交易金額之和(返回一個Map<Currency, Integer>對象)將交易劃分成兩組:高金額交易和非高金額交易(返回一個Map<Boolean, List<Transaction>>對象)創建多層分組,例如先按交易發生的城市分組,再進一步按它們是否為高金額交易進行分組(返回一個Map<String, Map<Boolean, List<Transaction>>>)興奮嗎?很好。讓我們看看,你是如何使用Stream API和Collector來表達上述查詢的。我們首先從一個簡單的例子開始,這個例子要對這個流進行"總結":計算它的平均值,最大值和最小值。然后我們再看看如何表達簡單的分組,最后,再看看如何將Collector組合起來去創建更為強大的查詢,例如多層分組。總結。讓我們用一些簡單的例子來熱身一下。在之前的文章中,你已經看到如何使用reduce方法去計算流中元素的數量,最小值,最大值和平均值,以及如何使用基本數據類型元素的流。有一些預定義的Collector類也能讓你完成那些功能。例如,可以使用counting()方法去計算元素的數量,如清單11所示。清單11long howManyTransactions = transactions.stream().collect(counting());
你可以使用summingDouble(),summingInt()和summingLong()分別對流中元素類型為Double,Int或Long的屬性求和。在清單12中,我們計算出了所有交易的金額之和。清單12int totalValue = transactions.stream().collect(summingInt(Transaction::getValue));
類似的,使用averagingDouble(),averagingInt()和averagingLong()去計算平均值,如清單13所示。清單13double average = transactions.stream().collect(averagingInt(Transaction::getValue));
另外,使用maxBy()和minBy()方法,可以計算出流中值最大和最小的元素。但這里有一個問題:你需要為流中元素定義一個順序,以能夠對它們進行比較。這就是為什么maxBy()和minBy()方法使用使用一個Comparator對象作為參數,圖3表明了這一點。圖3 在清單14的例子中,我們使用了靜態方法comparing(),它將傳入的函數作為參數,從中生成一個Comparator對象。該函數用于從流的元素中解析出用于進行比較的關鍵字。在這個例子中,通過使用交易金額作為比較的關鍵字,我們找到了那筆最高金額的交易。清單14
在清單14的例子中,我們使用了靜態方法comparing(),它將傳入的函數作為參數,從中生成一個Comparator對象。該函數用于從流的元素中解析出用于進行比較的關鍵字。在這個例子中,通過使用交易金額作為比較的關鍵字,我們找到了那筆最高金額的交易。清單14Optional<Transaction> highestTransaction =
transactions.stream()
.collect(maxBy(comparing(Transaction::getValue)));
還有一個reducing()方法,由它產生的Collector對象會把流中的所有元素歸集在一起,對它們重復的應用同一個操作,直到產生結果。該方法與之前看過的reduce()方法在原理上一樣的。例如,清單15展示了使用了基于reducing()方法的另一種方式去計算所有交易的金額之和。清單15int totalValue = transactions.stream().collect(reducing(0, Transaction::getValue, Integer::sum));
reducing()方法使用三個參數:初始值(如果流為空,則返回它);此處,該值為0。應用于流中每個元素的函數對象;此處,該函數會解析出每筆交易的金額。將兩個由解析函數生成的金額合并在一起的方法;此處,我們只是把金額加起來。你可能會說,"等等,使用其它的流方法,如reduce(),max()和min(),我已經可以做到這些了。那么,你為什么還要給我看這些方法呢?"后面,你將會看到我們將Collector結合起來去構建更為復雜的查詢(例如,對加法平均數進行分組),所以,這也能更易于理解這些內建的Collector。分組。這是一個普通的數據庫查詢操作,它使用屬性去數據進行分組。例如,你也許想按幣種對一組交易進行分組。若你使用如清單16所示的代碼,通過顯式的遍歷去表達這個查詢,那會是很痛苦的。清單16Map<Currency, List<Transaction>> transactionsByCurrencies = new HashMap< >();
for(Transaction transaction : transactions) {
Currency currency = transaction.getCurrency();
List<Transaction> transactionsForCurrency =
transactionsByCurrencies.get(currency);
if (transactionsForCurrency == null) {
transactionsForCurrency = new ArrayList<>();
transactionsByCurrencies.put(currency, transactionsForCurrency);
}
transactionsForCurrency.add(transaction);
}
你首先需要創建一個Map對象,它將收集所有的交易記錄。然后,你需要遍歷所有的交易記錄,并解析出每筆交易的幣種。在將交易記錄使用一個值插入Map中之前,需要先檢查一下,這個List是否已經創建過了,等等。真是令人汗顏啊,因為我們想要是"按幣種對交易進行分組"。為什么不得不涉及這么多代碼呢?有好消息:有一個稱為groupingBy()的Collector,它允許我們以簡潔的方式來表達這個例子。我們可以使用清單17中的例子來表達這個相同的查詢,現在代碼的閱讀更接近問題語句了。清單17Map<Currency, List<Transaction>> transactionsByCurrencies =
transactions.stream().collect(groupingBy(Transaction::getCurrency));
工廠方法groupingBy()使用一個函數對象作為參數,該函數會解析出用于分類交易記錄的關鍵字。我們稱為這個函數為分類函數。在此處,為了按幣種對交易進行分組,我們傳入一個方法引用,Transaction::getCurrency。圖4演示了這個分組操作。圖4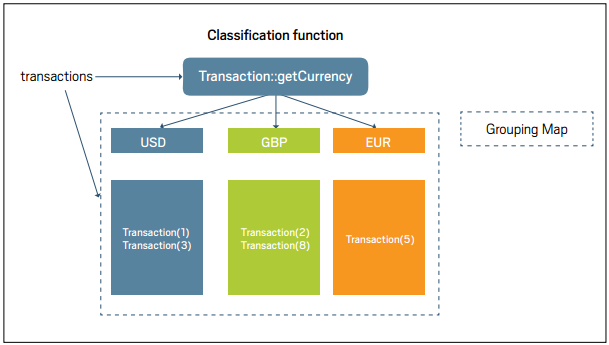 分割。有一個稱為partitioningBy()的工廠方法,它可被視為一種特殊的groupingBy()方法。它使用一個謂語作為參數(該參數返回一個boolean值),然后根據元素是否滿足這個謂語對它們進行分組。換言之,它將組成流的交易分割成了結構Map<Boolean, List<Transaction>>。例如,如若你想將交易分割成兩組--低廉的和昂貴的--你就可以像清單18那樣去使用partitioningBy()產生的Collector。此例中的Lambda表達式,t->t.getValue() > 1000,就是一個將交易分成低廉和昂貴的謂語。清單18
分割。有一個稱為partitioningBy()的工廠方法,它可被視為一種特殊的groupingBy()方法。它使用一個謂語作為參數(該參數返回一個boolean值),然后根據元素是否滿足這個謂語對它們進行分組。換言之,它將組成流的交易分割成了結構Map<Boolean, List<Transaction>>。例如,如若你想將交易分割成兩組--低廉的和昂貴的--你就可以像清單18那樣去使用partitioningBy()產生的Collector。此例中的Lambda表達式,t->t.getValue() > 1000,就是一個將交易分成低廉和昂貴的謂語。清單18Map<Boolean, List<Transaction>> partitionedTransactions =
transactions.stream().collect(partitioningBy(t -> t.getValue() > 1000));
組合Collector。如果你熟悉SQL,你應該知道可以將GROUP BY與函數COUNT()和SUM()一塊兒使用,以按幣種和交易金額之和進行分組。那么,使用Stream API是否也可以實現相似的功能呢?當然可以。確切地說,有一個重載的groupingBy()方法,它使用另一個Collector作為第二個參數。這個額外的Collector對象用于定義在使用由groupingBy()產生的Collector時如何匯集所有與關鍵字相關的元素。好吧,這聽起來有些抽象,那么讓我們看一個簡單的例子。我們想基于每個城市的交易金額之和生成一個城市的Map對象(見清單19)。在此處,我們告訴groupingBy()方法使用getCity()方法作為分類方法。那么,得到的Map結果的Key就為城市。正常地,我們期望對Map中每個鍵所對應的值,即List<Transaction>對象,使用groupingBy()方法。清單19Map<String, Integer> cityToSum =
transactions.stream().collect(groupingBy(Transaction::getCity,
summingInt(Transaction::getValue)));
然后,我們卻是傳入了另一個Collector對象,它由summingInt()方法產生,該方法會將所有與特定城市相關的交易記錄的金額加起來。結果,我們得到了一個Map<String, Integer>對象,它將每個城市與它們對應的所有交易的金額之和進行了映射。酷,不是嗎?想想這個:基本的groupingBy(Transaction:getCity)方法其實就只是groupingBy(Transaction:getCity, toList())的簡寫。讓我們看看另一個例子。如果你想生成這樣一個Map,它對每個城市與它的最大金額的交易記錄進行映射,那要怎么做呢?你可能已經猜到了,我們可以重用前面過的由maxBy()方法產生的Collector,如清單20所示。清單20Map<String, Optional<Transaction>> cityToHighestTransaction =
transactions.stream().collect(groupingBy(Transaction::getCity,
maxBy(comparing(Transaction::getValue))));
你已經看到Stream API很善于表達,我們正在構建的一些十分有趣的查詢都可以寫的簡潔些。你還能想象出回到從前去遍歷地處理一個集合嗎?讓我們看一個更為復雜的例子,以結束這篇文章。你已看到groupingBy()方法可以將一個Collector對象作為參數,再根據進一步的分類規則去收集流中的元素。因為groupingBy()方法本身得到的也是一個Collector對象,那么通過傳入另一個由groupingBy()方法得到的Collector對象,該Collector定義了第二級的分類規范,我們就能夠創建多層次分組。在清單21的代碼中,先按城市對交易記錄進行分組,再進一步對每個城市中的交易記錄按幣種進行分組,以得到每個城市中每個幣種的所有交易記錄的平均金額。圖5就形象地展示了這種機制。清單21Map<String, Map<Currency, Double>> cityByCurrencyToAverage =
transactions.stream().collect(groupingBy(Transaction::getCity,
groupingBy(Transaction::getCurrency,
averagingInt(Transaction::getValue))));
圖5 創建你自己的Collector。到目前為止,我們展示的全部Collector都實現了接口java.util.stream.Collector。這就意味著,你可以實現自己的Collector,以"定制"歸一操作。但是對于這個主題,再寫一篇文章可能更合適一些,所以我們不會在本文中討論這個問題。結論在本文中,我們探討了Stream API中的兩個高級:flatMap和collect。它們是可以加到你的兵器庫中的工具,可以用來表述豐富的數據處理查詢。特別地,你也已經看到了,collect()方法可被用于歸納,分組和分割操作。另外,這些操作還可能被結合在一起,去構建更為豐富的查詢,例如"生產一個兩層Map對象,它代表每個城市中每個幣種的平均交易金額"。然而,本文也沒有查究到所有的內建Collector實現。請你去看看Collectors類,并試試其它的Collector實現,例如由mapping(),joining()和collectingAndThen(),也許你會發現它們也很有用。
創建你自己的Collector。到目前為止,我們展示的全部Collector都實現了接口java.util.stream.Collector。這就意味著,你可以實現自己的Collector,以"定制"歸一操作。但是對于這個主題,再寫一篇文章可能更合適一些,所以我們不會在本文中討論這個問題。結論在本文中,我們探討了Stream API中的兩個高級:flatMap和collect。它們是可以加到你的兵器庫中的工具,可以用來表述豐富的數據處理查詢。特別地,你也已經看到了,collect()方法可被用于歸納,分組和分割操作。另外,這些操作還可能被結合在一起,去構建更為豐富的查詢,例如"生產一個兩層Map對象,它代表每個城市中每個幣種的平均交易金額"。然而,本文也沒有查究到所有的內建Collector實現。請你去看看Collectors類,并試試其它的Collector實現,例如由mapping(),joining()和collectingAndThen(),也許你會發現它們也很有用。