#
獲取表單的引用
在開始對表單進行編程前,必須先獲取表單<form>的引用.有以下方法可以來完成這一操作。
1)采用典型的DOM樹中的定位元素的方法getElementById(),只要傳入表單的id即可獲得表單的引用:
var vform=document.getElementById(“form1”);
2)還可以用document的forms集合,并通過表單在form集合中的位置或者表單的name特性來進行引用:
var oform=document.forms[0];
var oform=document.forms[“formZ”];
訪問表單字段
每個表單字段,不論它是按鈕,文本框還是其它內容,均包含在表單的elements集合中.可以用它們的name特性或者它們在集合中的位置來訪問不同的字段:
Var oFirstField=oForm.elements[0];
Var oTextBox1=oForm.elements[“textBox1”];
此外還可以通過名字來直接訪問字段,如:
Var oTextBox1=oForm.textbox1;
如果名字中有標記,則可以使用方括號標記:
Var oTextBox1=oForm[“text box 1”];
最常見的訪問表單字段的方法
最簡單常用的訪問表單元素的方法自然是document.getElementById(),舉例如下:
<input type="text" name="count"
value="" />
在JS中取得此元素內容的代碼為:
var name=document.getElementById("name").value
這種方法無論表單元素處于那個表單中甚至是不在表單中都能湊效,一般情況下是我們用JS訪問表單元素的首選.
鑒于document.getElementById比較長,你可以用如下函數代替它:
function $(id){
return document.getElementById(id);
}
把這個函數放在共有JS庫中,在jsp頁面通過如下方法引用它:
<head>
<title>"記賬系統"添加資源頁面</title>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<script src="web/js/check.js" type="text/javascript"></script>
<link rel="stylesheet" rev="stylesheet" href="web/css/style.css"
type="text/css" />
</head>
此后你就可以直接使用$訪問表單元素中的內容:
var name=$("name").value;
表單字段的共性
以下是所有表單字段(除了隱藏字段)
Disabled可以用來獲取或設置表單控件是否被禁用.
Form特性用來指向字段所在的表單.
Blur()方法使表單字段失去焦點.
Focus()方法使表單字段獲得焦點.
當字段失去焦點是,發生blur事件,執行onblur事件處理程序.
當字段獲取焦點時,發生focus事件,執行onfocus事件處理函數.
當頁面載入時將焦點放在第一個字段
在body代碼中如此書寫:
<body onload=“focusOnFirstElm()”>
JS函數如下書寫:
Fucntion focusOnFirstElm(){
document.forms[0].elements[0].focus();
}
如果第一個字段不是隱藏字段此方法就是湊效的,如果是的話把elements的下標改成非隱藏字段的下標即可.
控制表單只被提交一次
由于Web的響應問題,用戶有可能會點擊多次提交按鈕從而創建重復數據或是導致錯誤,我們可以使用JS對提交按鈕進行設置以讓表單只被提交一次。
<input type=“submit” value=“提交” onclick=“this.disabled=true;this.form.submit()”/>
這里在點擊提交按鈕時執行了兩句JS代碼,一次是this.disabled=true;這是讓提交按鈕被禁用;一次是this.form.submit()這是提交這個按鈕所在的表單。
檢查用戶在表單元素中的按鍵
為控件添加 onkeydown事件處理,然后在函數查看keyCode,就能知道用戶的按鍵,代碼如下:
<input type="text" name="test"
value="" onkeydown="testkey(this,event)"/>
JS代碼如下:
function testkey(obj,event){
alert(event.keyCode);
}
這種技巧在改善用戶體驗如按回車鍵提交表單時很常用。
Servlet與JSP綜合講述
Servlet和JSP的概念
Servlet是Sun推出的用于實現CGI(通用網關接口)的java語言版本,它不但具有跨平臺的特性,而且還以多線程的方式為用戶提供服務而不必為每個請求都啟動一個線程,因此其效率要比傳統的CGI程序要高很多.
JSP和MS的ASP類似,它把JSP標簽嵌入到HTML格式的網頁中,這樣對程序員和網頁編輯人員都很方便,JSP天生就是為表現層設計的.
實際上,Servlet只是繼承了HttpRequest的Java類,而JSP最終也會被Servlet引擎翻譯成Servlet并編譯執行,JSP的存在主要是為了方便表現層.
Servlet與JSP之間的區別,決定了Servlet與JSP在MVC構架模式中的不同角色.Servlet一般作為MVC中的控制器,JSP一般作為MVC中的視圖.
Servlet的生命周期
Servlet有三個生命周期:初始化,執行和結束,它們分別對應Servlet接口中的init,service和destroy三個函數.
初始化時期:當servlet被servlet容器(如tomcat)載入后,servlet的init函數就會被調用,在這個函數可以做一些初始化工作.init函數只會在servlet容器載入servlet執行一次,以后無論有多少客戶端訪問這個Servlet,init函數都不會被執行.
執行期:servlet采用多線程方式向客戶提供服務,當有客戶請求來到時, service會被用來處理它.每個客戶都有自己的service方法,這些方法接受客戶端請求,并且發揮相應的響應.程序員在實現具體的Servlet時,一般不重載service方法,服務器容器會調用service方法以決定doGet,doPost,doPut,doDelete中的一種或幾種,因此應該重載這些方法來處理客戶端請求.]
結束期:該時期服務器會卸載servlet,它將調用destroy函數釋放占用的資源,注意Web服務器是有可能崩潰的,destroy方法不一定會被執行.
如何開發和部署一個Servlet
1)從java.servlet.http.HttpServlet繼承自己的servlet類.
2)重載doGet或doPost方法來處理客戶請求(一般是doPost,其安全性較好),如果要在加載Servlet時被加載時進行初始化操作,可以重載init方法.
3)在web.xml中配置這個servlet.其中servlet-class用來制定這個servlet的類全名,servlet-name用來標識這個servlet,它可以是任意的字符串,不一定要和類文件名一致.url-pattern用來表示servlet被映射到的url模式.
<!– Servlet在Web.xml中的配置示例 -->
<servlet>
<servlet-name>ShowPageServlet</servlet-name>
<servlet-class>
com.sitinspring.action.ShowPageServlet
</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>ShowPageServlet</servlet-name>
<url-pattern>/ShowPage</url-pattern>
</servlet-mapping>
開發一個啟動時就被執行的Servlet
一般的Servlet都是在有來自客戶端請求時才會執行,要讓它在啟動時就執行需要在配置中進行一些特殊設置,如右.
右邊的代碼中, load-on-startup說明了服務器一啟動就加載并初始化它,0代表了加載它的優先級,注意它必須是一個正數,而且值小的要比值大的先加載.debug制定輸出調試信息的級別,0為最低.
這樣的servlet在用于讀取WebApp的一些初始化參數很有用處,如取得配置文件的地址,設置log4j和得到WebApp的物理路徑等.右邊配置的servlet就是用來初始化log4j的.
<!-- InitServlet -->
<servlet>
<servlet-name>log4j-init</servlet-name>
<servlet-class>
com.sitinspring.action.Log4jInit
</servlet-class>
<init-param>
<param-name>log4j</param-name>
<param-value>WEB-INF/classes/log4j.properties</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
Serlet中出現的線程不安全的問題
Servlet是運行在多線程的服務器上的,它對每個用戶的請求創建的是線程而不是進程,因此在高效的同時也帶來了數據同步和一致性的問題.
服務器值實例化一個Servlet/JSP實例,然后在多個處理線程中調用該實例的相關方法來處理請求,因此servlet的成員變量可能會被多個線程調用該實例的相關方法改變,將有可能帶來問題.這也是大家在眾多的Servlet中很少看到成員變量的原因.
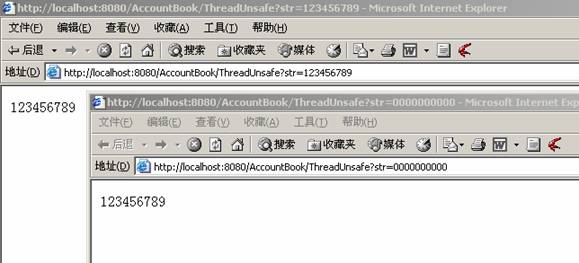
public class ThreadUnsafeServlet extends HttpServlet {
private String unsafeString="";
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, java.io.IOException {
request.setCharacterEncoding("UTF-8");
unsafeString=request.getParameter("str");
try{
Thread.sleep(5000);
}
catch(Exception ex){
ex.printStackTrace();
}
PrintWriter out=response.getWriter();
out.println(unsafeString);
}
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, java.io.IOException {
doPost(request, response);
}
}
關于重定向的兩種方法
在servlet中,重定向一般是通過HttpResponse的sendRedirect()方法或RequestDispatcher的forward方法來實現的.
sendRedirect的參數可以是相對或絕對地址,如果以/開頭容器將認為相對于當前Web引用的根.這種請求將導致客戶端瀏覽器請求URL跳轉,而且從Browser的地址欄中可以看到新的Url地址.另外使用這個方法時,前一個頁面的狀態不會被帶到下一個頁面,通過request.getAttribute(“XXXX”)方法將得到空值.
RequestDispatcher是一個Web資源的包裝器,可以用來把當前請求傳遞到該資源,而且客戶端瀏覽器的地址欄也不會顯示為轉向后的地址.另外此方法還可以將請求發送到任意一個服務器資源.
如果兩種方法都能達到要求,最好使用forward方法,它比sendRedirect安全而高效.
獲取當前絕對路徑
Servlet/JSP有時需要對擁有的資源進行操作,這就要求得到它們所在的絕對路徑.此時可以使用ServletContext接口提供的方法來得到當前應用所在的絕對路徑,代碼如下:
ServletContext sct = getServletContext();
String realPath=sct.getRealPath("/");
注: ServletContext 用于Servlet和Servlet容器交換信息.
XML的由來
XML是eXtensible Markup Language的縮寫。擴展標記語言XML是一種簡單的數據存儲語言,使用一系列簡單的標記描述數據,而這些標記可以用方便的方式建立,雖然XML占用的空間比二進制數據要占用更多的空間,但XML極其簡單易于掌握和使用
XML是現代程序中一個必不可少的組成部分,也是世界上發展最快的技術之一。它的主要目的是以結構化的方式來表示數據,在某些方面,XML也類似于數據庫,提供數據的結構化視圖。
XML(可擴展標記語言)是從稱為SGML(標準通用標記語言)發展而來的,SGML的主要目的是定義使用標簽來表示數據的標記語言的語法。基于SGML的重要語言之一就是著名的HTML.
標簽由包圍在一個小于號<和一個大于號>之間的文本組成,起始標簽(tag)表示一個特定區域的開始,例如<start>;結束標簽定義了一個區域的結束,除了在小于號之后緊跟一個斜線外和起始標簽一致,例如</end>.舉例說明標簽如下:
<member id=“007”>邦德</member>中,左邊的<member id=“007”>是起始標簽,邦德是標簽中的文字,007是屬性Attribute, </member >是結束標簽.
XML的發展
由于SGML中存在特殊而隨意的語法(如標簽的非嵌套使用),使得建立一個SGML語言的解析器成了一項艱巨的任務,這些困難導致了SGML一直停步不前.
XML通過相對嚴格的語法規定使得建立一個XML解析器要容易得多,這些語法包括:
1)任何起始標簽都必須有一個結束標簽。
2)可以采用另一種簡化語法,可以在一個標簽中同時表示起始和結束標簽。這種語法是在大于符號前緊跟一個斜線/.如<tag />等同于<tag></tag>.
3)標簽必須按照合適的順序進行嵌套,在沒有關閉內部節點之前不能關閉外部節點。
4)所有的特性都必須有值,特性的值周圍應該加上雙引號。
XML文檔示例
<?xml version="1.0" encoding="GBK"?>
<members>
<member name="Andy">
<age>25</age>
<title>JSE</title>
</member>
<member name="Bill">
<age>35</age>
<title>SSE</title>
</member>
<member name="Cindy">
<age>45</age>
<title>PM</title>
</member>
<member name="Douglas">
<age>45</age>
<title>GM</title>
</member>
</members>
<?xml version=“1.0” encoding=“GBK”?>是XML序言,這一行代碼告訴解析器文件將按XML規則進行解析, GBK制定了此文件的編碼方式。
<members>是文檔的根節點,一個XML中有且只有一個根節點,否則會造成解析失敗。
<member name=“Andy”>。。。</member>是根節點下面的子節點,name是其特性,特性的值為Andy。這個子節點下面有age和title兩個子節點。
XML的用途
以文本的形式存儲數據,這樣的形式適于機器閱讀,對于人閱讀也相對方便.
作為程序的配置文件使用,如著名的web.xml,struts-config.xml
Ajax程序傳遞數據的載體.
WebService,SOAP的基礎.
針對XML的API
將XML定義為一種語言之后,就出現了使用常見的編程語言(如Java)來同時表現和處理XML代碼的需求。
首先出現的是Java上的SAX(Simple API for XML)項目。SAX提供了一個基于事件的XML解析的API。從其本質上來說,SAX解析器從文件的開頭出發,從前向后解析,每當遇到起始標簽或者結束標簽、特性、文本或者其他的XML語法時,就會觸發一個事件。然后,當事件發生時,具體要怎么做就由開發人員決定。
因為SAX解析器僅僅按照文本的方式來解析它們,所以SAX更輕量、更快速。而它們的主要缺點是在解析中無法停止、后退或者不從文件開始,直接訪問XML結構中的指定部分。
DOM是針對XML的基于樹的API。它關注的不僅僅是解析XML代碼,而是使用一系列互相關聯的對象來表示這些代碼,而這些對象可以被修改且無需重新解析代碼就能直接訪問它們。
使用DOM,只需解析代碼一次來創建一個樹的模型;某些時候會使用SAX解析器來完成它。在這個初始解析過程之后,XML已經完全通過DOM模型來表現出來,同時也不再需要原始的代碼。盡管DOM比SAX慢很多,而且,因為創建了相當多的對象而需要更多的開銷,但由于它使用上的簡便,因而成為Web瀏覽器和JavaScript最喜歡的方法。
最方便的XML解析利器-dom4j
Dom4j是一個易用的、開源的庫,用于XML,XPath和XSLT。它應用于Java平臺,采用了Java集合框架并完全支持DOM,SAX和JAXP.
sax和dom本身的api都比較復雜,不易使用,而開源包dom4j卻綜合了二者的優點,屏蔽了晦澀的細節,封裝了一系列類和接口以方便用戶使用它來讀寫XML.
Dom4j下載
要使用dom4j讀寫XML文檔,需要先下載dom4j包,dom4j官方網站在 http://www.dom4j.org/ 目前最新dom4j包下載地址:http://nchc.dl.sourceforge.net/sourceforge/dom4j/dom4j-1.6.1.zip
解開后有兩個包,僅操作XML文檔的話把dom4j-1.6.1.jar加入工程就可以了,如果需要使用XPath的話還需要加入包jaxen-1.1-beta-7.jar.
使用dom4j讀寫xml的一些常用對象
1.Document:文檔對象,它代表著整篇xml文檔.
2.Element:節點元素,它代表著xml文檔中的一個節點元素,如前面的<age>25</age>就是一個Element.其值(文本值)為25.
3.Attribute:節點屬性,如前面的節點元素<member name=“Andy”>…< /member >中, name就是節點元素的一個屬性,其值(文本值)為Andy.
與Document對象相關的API
1.讀取XML文件,獲得document對象.
SAXReader reader = new SAXReader();
Document document = reader.read(new File("input.xml"));
2.解析XML形式的文本,得到document對象.
String text = "<members></members>";
Document document = DocumentHelper.parseText(text);
3.主動創建document對象.
Document document = DocumentHelper.createDocument();
Element root = document.addElement("members");// 創建根節點
與Element有關的API
1.獲取文檔的根節點.
Element rootElm = document.getRootElement();
2.取得某節點的單個子節點.
Element memberElm=root.element(“member”);// “member”是節點名
3.取得節點的文字
String text=memberElm.getText();
也可以用:
String text=root.elementText("name");這個是取得根節點下的name字節點的文字.
4.取得某節點下名為"member"的所有字節點并進行遍歷.
List nodes = rootElm.elements("member");
for (Iterator it = nodes.iterator(); it.hasNext();) {
Element elm = (Element) it.next();
// do something
}
5.對某節點下的所有子節點進行遍歷.
for(Iterator it=root.elementIterator();it.hasNext();){
Element element = (Element) it.next();
// do something
}
6.在某節點下添加子節點.
Element ageElm = newMemberElm.addElement("age");
7.設置節點文字.
ageElm.setText("29");
8.刪除某節點.
parentElm.remove(childElm);// childElm是待刪除的節點,parentElm是其父節點
與Attribute相關的API
1.取得某節點下的某屬性
Element root=document.getRootElement();
Attribute attribute=root.attribute("size");// 屬性名name
2.取得屬性的文字
String text=attribute.getText();
也可以用:
String text2=root.element("name").attributeValue("firstname");這個是取得根節點下name字節點的屬性firstname的值.
3.遍歷某節點的所有屬性
Element root=document.getRootElement();
for(Iterator it=root.attributeIterator();it.hasNext();){
Attribute attribute = (Attribute) it.next();
String text=attribute.getText();
System.out.println(text);
}
4.設置某節點的屬性和文字.
newMemberElm.addAttribute("name", "sitinspring");
5.設置屬性的文字
Attribute attribute=root.attribute("name");
attribute.setText("sitinspring");
6.刪除某屬性
Attribute attribute=root.attribute("size");// 屬性名name
root.remove(attribute);
將document的內容寫入XML文件
1.文檔中全為英文,不設置編碼,直接寫入的形式.
XMLWriter writer = new XMLWriter(new FileWriter("output.xml"));
writer.write(document);
writer.close();
2.文檔中含有中文,設置編碼格式寫入的形式.
OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("GBK"); // 指定XML編碼
XMLWriter writer = new XMLWriter(new FileWriter("output.xml"),format);
writer.write(document);
writer.close();
字符串與XML的轉換
1.將字符串轉化為XML
String text = "<members> <member>sitinspring</member> </members>";
Document document = DocumentHelper.parseText(text);
2.將文檔或節點的XML轉化為字符串.
SAXReader reader = new SAXReader();
Document document = reader.read(new File("input.xml"));
Element root=document.getRootElement();
String docXmlText=document.asXML();
String rootXmlText=root.asXML();
Element memberElm=root.element("member");
String memberXmlText=memberElm.asXML();
使用XPath快速找到節點.
讀取的XML文檔示例
<?xml version="1.0" encoding="UTF-8"?>
<projectDescription>
<name>MemberManagement</name>
<comment></comment>
<projects>
<project>PRJ1</project>
<project>PRJ2</project>
<project>PRJ3</project>
<project>PRJ4</project>
</projects>
<buildSpec>
<buildCommand>
<name>org.eclipse.jdt.core.javabuilder</name>
<arguments>
</arguments>
</buildCommand>
</buildSpec>
<natures>
<nature>org.eclipse.jdt.core.javanature</nature>
</natures>
</projectDescription>
使用XPath快速找到節點project.
public static void main(String[] args){
SAXReader reader = new SAXReader();
try{
Document doc = reader.read(new File("sample.xml"));
List projects=doc.selectNodes("/projectDescription/projects/project");
Iterator it=projects.iterator();
while(it.hasNext()){
Element elm=(Element)it.next();
System.out.println(elm.getText());
}
}
catch(Exception ex){
ex.printStackTrace();
}
}
本文內容
Socket概述
Socket的重要API
一個Socket通信的例子
Socket是什么?
Socket通常也稱作“套接字”,用于描述IP地址和端口,是一個通信鏈的句柄。應用程序通常通過“套接字”向網絡發出請求或者應答網絡請求。
在java中,Socket和ServerSocket類庫位于java.net包中。ServerSocket用于服務器端,Socket是建立網絡連接時使用的。在連接成功時,應用程序兩端都會產生一個Socket實例,操作這個實例,完成所需的會話。
對于一個網絡連接來說,套接字是平等的,并沒有差別,不因為在服務器端或在客戶端而產生不同級別。
Socket的直觀描述
Socket的英文原義是“孔”或“插座”。在這里作為進程通信機制,取后一種意義。socket非常類似于電話插座。以一個國家級電話網為例。電話的通話雙方相當于相互通信的2個進程,區號是它的網絡地址;區內一個單位的交換機相當于一臺主機,主機分配給每個用戶的局內號碼相當于socket號。任何用戶在通話之前,首先要占有一部電話機,相當于申請一個socket;同時要知道對方的號碼,相當于對方有一個固定的socket。然后向對方撥號呼叫,相當于發出連接請求(假如對方不在同一區內,還要撥對方區號,相當于給出網絡地址)。對方假如在場并空閑(相當于通信的另一主機開機且可以接受連接請求),拿起電話話筒,雙方就可以正式通話,相當于連接成功。雙方通話的過程,是一方向電話機發出信號和對方從電話機接收信號的過程,相當于向socket發送數據和從socket接收數據。通話結束后,一方掛起電話機相當于關閉socket,撤消連接。
在電話系統中,一般用戶只能感受到本地電話機和對方電話號碼的存在,建立通話的過程,話音傳輸的過程以及整個電話系統的技術細節對他都是透明的,這也與socket機制非常相似。socket利用網間網通信設施實現進程通信,但它對通信設施的細節毫不關心,只要通信設施能提供足夠的通信能力,它就滿足了。
至此,我們對socket進行了直觀的描述。抽象出來,socket實質上提供了進程通信的端點。進程通信之前,雙方首先必須各自創建一個端點,否則是沒有辦法建立聯系并相互通信的。正如打電話之前,雙方必須各自擁有一臺電話機一樣。
socket 是面向客戶/服務器模型而設計的
socket 是面向客戶/服務器模型而設計的,針對客戶和服務器程序提供不同的socket 系統調用。客戶隨機申請一個socket (相當于一個想打電話的人可以在任何一臺入網電話上撥號呼叫),系統為之分配一個socket號;服務器擁有全局公認的 socket ,任何客戶都可以向它發出連接請求和信息請求(相當于一個被呼叫的電話擁有一個呼叫方知道的電話號碼)。
socket利用客戶/服務器模式巧妙地解決了進程之間建立通信連接的問題。服務器socket為全局所公認非常重要。讀者不妨考慮一下,兩個完全隨機的用戶進程之間如何建立通信?假如通信雙方沒有任何一方的socket 固定,就好比打電話的雙方彼此不知道對方的電話號碼,要通話是不可能的。
Socket的應用
Socket 接口是訪問 Internet 使用得最廣泛的方法。 如果你有一臺剛配好TCP/IP協議的主機,其IP地址是202.120.127.201, 此時在另一臺主機或同一臺主機上執行ftp 202.120.127.201,顯然無法建立連接。因"202.120.127.201" 這臺主機沒有運行FTP服務軟件。同樣, 在另一臺或同一臺主機上運行瀏覽軟件 如Netscape,輸入"http://202.120.127.201",也無法建立連接。現在,如果在這臺主機上運行一個FTP服務軟件(該軟件將打開一個Socket, 并將其綁定到21端口),再在這臺主機上運行一個Web 服務軟件(該軟件將打開另一個Socket,并將其綁定到80端口)。這樣,在另一臺主機或同一臺主機上執行ftp 202.120.127.201,FTP客戶軟件將通過21端口來呼叫主機上由FTP 服務軟件提供的Socket,與其建立連接并對話。而在netscape中輸入"http://202.120.127.201"時,將通過80端口來呼叫主機上由Web服務軟件提供的Socket,與其建 立連接并對話。 在Internet上有很多這樣的主機,這些主機一般運行了多個服務軟件,同時提供幾種服務。每種服務都打開一個Socket,并綁定到一個端口上,不同的端口對應于不同的服務。Socket正如其英文原意那樣,象一個多孔插座。一臺主機猶如布滿各種插座的房間,每個插座有一個編號,有的插座提供220伏交流電, 有的提供110伏交流電,有的則提供有線電視節目。 客戶軟件將插頭插到不同編號的插座,就可以得到不同的服務。
重要的Socket API
accept方法用于產生“阻塞”,直到接受到一個連接,并且返回一個客戶端的Socket對象實例。“阻塞”是一個術語,它使程序運行暫時“停留”在這個地方,直到一個會話產生,然后程序繼續;通常“阻塞”是由循環產生的。
getInputStream方法獲得網絡連接輸入,同時返回一個IutputStream對象實例。
getOutputStream方法連接的另一端將得到輸入,同時返回一個OutputStream對象實例。 注意:其中getInputStream和getOutputStream方法均會產生一個IOException,它必須被捕獲,因為它們返回的流對象,通常都會被另一個流對象使用。
一個Server-Client模型的程序的開發原理
服務器,使用ServerSocket監聽指定的端口,端口可以隨意指定(由于1024以下的端口通常屬于保留端口,在一些操作系統中不可以隨意使用,所以建議使用大于1024的端口),等待客戶連接請求,客戶連接后,會話產生;在完成會話后,關閉連接。
客戶端,使用Socket對網絡上某一個服務器的某一個端口發出連接請求,一旦連接成功,打開會話;會話完成后,關閉Socket。客戶端不需要指定打開的端口,通常臨時的、動態的分配一個1024以上的端口。
服務器端代碼
public class ResponseThread implements Runnable {
private static Logger logger = Logger.getLogger(ResponseThread.class);
// 用于與客戶端通信的Socket
private Socket incomingSocket;
/**
* 構造函數,用以將incomingSocket傳入
* @param incomingSocket
*/
public ResponseThread(Socket incomingSocket) {
this.incomingSocket = incomingSocket;
}
public void run() {
try {
try {
// 輸入流
InputStream inStream = incomingSocket.getInputStream();
// 輸出流
OutputStream outStream = incomingSocket.getOutputStream();
// 文本掃描器
Scanner in = new Scanner(inStream);
// 輸出流打印器
PrintWriter out = new PrintWriter(outStream,true);
while (in.hasNextLine()) {
String line = in.nextLine();
logger.info("從客戶端獲得文字:"+line);
String responseLine=line+" 門朝大海 三河合水萬年流";
out.println(responseLine);
logger.info("向客戶端送出文字:"+responseLine);
}
} finally {
incomingSocket.close();
}
} catch (IOException ex) {
ex.printStackTrace();
}
}
public static void main(String[] args) {
try {
// 建立一個對2009端口進行監聽的ServerSocket并開始監聽
ServerSocket socket=new ServerSocket(2009);
logger.info("開始監聽");
while(true){
// 產生阻塞,直到客戶端連接過來才會往下執行
logger.info("阻塞中,等待來自客戶端的連接請求");
Socket incomingSocket=socket.accept();
// 執行到這里客戶端已經連接過來了,incomingSocket就是創建出來和遠程客戶端Socket進行通信的Socket
logger.info("獲得來自"+incomingSocket.getInetAddress()+"的請求.");
// 開辟一個線程,并把incomingSocket傳進去,在這個線程中服務器和客戶機開始通信
ResponseThread responseThread=new ResponseThread(incomingSocket);
// 啟動線程
Thread thread=new Thread(responseThread);
thread.start();
}
} catch (IOException ex) {
ex.printStackTrace();
}
}
}
客戶端代碼
/**
* Socket客戶端類
* @author sitinspring
*
* @date 2008-2-26
*/
public class SocketClient{
private static Logger logger = Logger.getLogger(ResponseThread.class);
public static void main(String[] args){
try {
// 建立一個Socket,試圖連接到位于127.0.0.1的主機的2009端口,如果服務器已經在監聽則會接收到這個請求,accept方法產生一個和這邊通信的Socket
Socket socket=new Socket("127.0.0.1",2009);
logger.info("客戶端向服務器發起請求.");
try {
// 輸入流
InputStream inStream = socket.getInputStream();
// 輸出流
OutputStream outStream = socket.getOutputStream();
/**
* 向服務器發送文字
*/
// 輸出流打印器
PrintWriter out = new PrintWriter(outStream);
out.println("地震高崗 一派溪山千古秀");
out.flush();
/**
* 接收服務器發送過來的文字
*/
// 文本掃描器
Scanner in = new Scanner(inStream);
while (in.hasNextLine()) {
String line = in.nextLine();
logger.info("客戶端獲得響應文字="+ line);
}
} finally {
// 關閉Socket
socket.close();
}
} catch (IOException ex) {
ex.printStackTrace();
}
}
}
摘要: 工序任務指流水線式的工作場景,下一組工人的工件就是上一組工人的成品,一個活做完自己的部分就往下傳,直到活完成為止。
為了編程方便簡化了各個工序的工時,把它們都當成一樣的了。
代碼:
package com.sitinspring.autotask.domain;
import com.sitinspring.autotask.util.IdUtil;
...
閱讀全文

 /**//**
/**//**
 * Positive Integer Check
* Positive Integer Check
 */
*/
function isPositiveInteger(str) {
{
var regex=new RegExp("^[1-9]+\\d*$");
return regex.test(str);
}

/**//**
* Negative Integer Check
*/
function isNegativeInteger(str){
var regex=new RegExp("^-{1}\\d+$");
return regex.test(str);
}
/**//**
* Nonnegative Integer Check
*/
function isNonnegativeInteger(str){
var regex=new RegExp("^\\d+$");
return regex.test(str);
}
/**//**
* Integer Check
*/
function isInteger(str){
var regex=new RegExp("^-?\\d+$");
return regex.test(str);
}
/**//**
* Rational number Check
*/
function isRationalNumber(str){
var regex=new RegExp("^-?\\d+(\\.*)(\\d*)$");
return regex.test(str);
}
/**//**
* Letter Check
*/
function isLetter(str){
var regex=new RegExp("^[a-zA-Z]+$");
return regex.test(str);
}
/**//**
* Letter Integer Check
*/
function isLetterOrInteger(str){
var regex=new RegExp("^[a-zA-Z0-9]+$");
return regex.test(str);
}
/**//**
* Email Check
*/
function isEmail(str){
var regex=new RegExp("^\\w+([-+.]\\w+)*@\\w+([-.]\\w+)*\\.\\w+([-.]\\w+)*$");
return regex.test(str);
}
/**//**
* Character Check
*/
function isCharacter(str){
var regex=new RegExp("^[\u4E00-\u9FA5]+$");
return regex.test(str);
}
/**//**
* Currency Check
*/
function isCurrency(str){
return str.search("^\\d+(\\.\\d{0,2})*$")==0;
}
本文內容
何時該使用讀寫鎖.
讀寫鎖的寫法.
理解讀寫鎖和線程互斥的區別。
復習-同步化的概念
當一個方法或代碼塊被聲明成synchronized,要執行此代碼必須先取得一個對象實例或this的鎖定,這個鎖定要在synchronized修飾的方法或代碼塊執行完后才能釋放掉(無論這段代碼是怎樣返回的,是正常運行還是異常運行)。每個對象只有一個鎖定,如果有兩個不同的線程試圖同時調用同一對象的同步方法,最終只會有一個能運行此方法,另外一個要等待第一個線程釋放掉鎖定后才能運行此方法。
讀寫鎖應用的場合
我們有時會遇到對同一個內存區域如數組或者鏈表進行多線程讀寫的情況,一般來說有以下幾種處理方式: 1.不加任何限制,多見于讀取寫入都很快的情況,但有時也會出現問題. 2.對讀寫函數都加以同步互斥,這下問題是沒了,但效率也下去了,比如說兩個讀取線程不是非要排隊進入不可. 3.使用讀寫鎖,安全和效率都得到了解決,特別合適讀線程多于寫線程的情況.也就是下面將要展現的模式.
讀寫鎖的意圖
讀寫鎖的本意是分別對讀寫狀態進行互斥區分,有互斥時才加鎖,否則放行.互斥的情況有: 1.讀寫互斥. 2.寫寫互斥. 不互斥的情況是:讀讀,這種情況不該加以限制. 程序就是要讓鎖對象知道當前讀寫狀態,再根據情況對讀寫的線程進行鎖定和解鎖。
讀寫線程都要操作的數據類
讀寫線程都要操作的數據是鏈表datas。
注意其中try...finally 的寫法,它保證了加鎖解鎖過程是成對調用的
lpublic class DataLib {
private List<String> datas;
private ReadWriteLock lock;
public DataLib() {
datas = new ArrayList<String>();
lock = new ReadWriteLock();
}
// 寫入數據,這時不能讀取
public void writeData(List<String> newDatas) {
try {
lock.writeLock();
Test.sleep(2);
datas=newDatas;
} finally {
lock.writeUnlock();
}
}
// 讀取數據,這時不能寫入
public List<String> readData() {
try {
lock.readLock();
Test.sleep(1);
return datas;
} finally {
lock.readUnlock();
}
}
}
讀寫鎖ReadWriteLock類
public class ReadWriteLock{
// 讀狀態
private boolean isRead;
// 寫狀態
private boolean isWrite;
public synchronized void readLock(){
// 有寫入時讀取線程停止
while(isWrite){
try{
System.out.println("有線程在進行寫入,讀取線程停止,進入等待狀態");
wait();
}
catch(InterruptedException ex){
ex.printStackTrace();
}
}
System.out.println("設定鎖為讀取狀態");
isRead=true;
}
public synchronized void readUnlock(){
System.out.println("解除讀取鎖");
isRead=false;
notifyAll();
}
public synchronized void writeLock(){
// 有讀取時讀取線程停止
while(isRead){
try{
System.out.println("有線程在進行讀取,寫入線程停止,進入等待狀態");
wait();
}
catch(InterruptedException ex){
ex.printStackTrace();
}
}
// 有寫入時寫入線程也一樣要停止
while(isWrite){
try{
System.out.println("有線程在進行寫入,寫入線程停止,進入等待狀態");
wait();
}
catch(InterruptedException ex){
ex.printStackTrace();
}
}
System.out.println("設定鎖為寫入狀態");
isWrite=true;
}
public synchronized void writeUnlock(){
System.out.println("解除寫入鎖");
isWrite=false;
notifyAll();
}
}
寫線程類Writer -它用于往DataLib類實例中的datas字段寫數據
分析其中dataLib字段的用意。
注意并記住其中持續調用及使用隨機數的方法。
lpublic class Writer implements Runnable{
private DataLib dataLib;
private static final Random random=new Random();
private String[] mockDatas={"甲","乙","丙","丁","戊","己","庚","辛","壬","癸"};
public Writer(DataLib dataLib,String[] mockDatas){
this.dataLib=dataLib;
this.mockDatas=mockDatas;
Thread thread=new Thread(this);
thread.start();
}
public void run(){
while(true){
Test.sleep(random.nextInt(3));
int startIndex=random.nextInt(mockDatas.length);
ArrayList<String> newDatas=new ArrayList<String>();
for(int i=startIndex;i<mockDatas.length;i++){
newDatas.add(mockDatas[i]);
}
dataLib.writeData(newDatas);
}
}
}
讀線程類Reader -它用于從DataLib類實例中的datas字段讀取數據
分析其中dataLib字段的用意。
注意并記住其中持續調用及使用隨機數的方法。
public class Reader implements Runnable{
private DataLib dataLib;
private static final Random random=new Random();
public Reader(DataLib dataLib){
this.dataLib=dataLib;
Thread thread=new Thread(this);
thread.start();
}
public void run(){
while(true){
Test.sleep(random.nextInt(2));
List<String> datas=dataLib.readData();
System.out.print(">>取得數組為:");
for(String data:datas){
System.out.print(data+",");
}
System.out.print("\n");
}
}
}
將代碼運行起來
右邊的代碼創建了兩個寫線程和三個讀線程,它們都是對dataLib實例進行操作的。
五個線程都有一個dataLib字段,都提供了一個帶參構造函數以給datas字段賦值,這就保證了五個線程操作的都是一個實例的同一字段,也就是同一片內存。
讀寫鎖就是對這五個線程進行控制的。
當有一個讀線程在操作時,其它的寫線程無法進行操作,讀線程可以正常操作,互不干擾。
當有一個寫線程在操作時,其它的讀線程無法進行操作。
public class Test{
public static void main(String[] args){
DataLib dataLib=new DataLib();
String[] mockDatas1={"甲","乙","丙","丁","戊","己","庚","辛","壬","癸"};
Writer writer1=new Writer(dataLib,mockDatas1);
String[] mockDatas2={"子","丑","寅","卯","辰","巳","午","未","申","酉","戌","亥"};
Writer writer2=new Writer(dataLib,mockDatas2);
Reader reader1=new Reader(dataLib);
Reader reader2=new Reader(dataLib);
Reader reader3=new Reader(dataLib);
}
// 用于延時
public static void sleep(int sleepSecond){
try{
Thread.sleep(sleepSecond*1000);
}
catch(Exception ex){
ex.printStackTrace();
}
}
}
小結
當多個線程試圖對同一內容進行讀寫操作時適合使用讀寫鎖。
請理解并記住ReadWriteLock類讀寫鎖的寫法.
讀寫鎖相對于線程互斥的優勢在于高效,它不會對兩個讀線程進行盲目的互斥處理,當讀線程數量多于寫線程尤其如此,當全是寫線程時兩者等效。
本文內容
何時該使用線程鎖.
線程鎖的寫法.
以線程鎖的例子來理解線程的調度。
使用線程鎖的場合
程序中經常采用多線程處理,這可以充分利用系統資源,縮短程序響應時間,改善用戶體驗;如果程序中只使用單線程,那么程序的速度和響應無疑會大打折扣。
但是,程序采用了多線程后,你就必須認真考慮線程調度的問題,如果調度不當,要么造成程序出錯,要么造成荒謬的結果。
一個諷刺僵化體制的笑話
前蘇聯某官員去視察植樹造林的情況,現場他看到一個人在遠處挖坑,其后不遠另一個人在把剛挖出的坑逐個填上,官員很費解于是詢問陪同人員,當地管理人員說“負責種樹的人今天病了”。
上面這個笑話如果發生在程序中就是線程調度的問題,種樹這個任務有三個線程:挖坑線程,種樹線程和填坑線程,后面的線程必須等前一個線程完成才能進行,而不是按時間順序來進行,否則一旦一個線程出錯就會出現上面荒謬的結果。
用線程鎖來處理兩個線程先后執行的情況
在程序中,和種樹一樣,很多任務也必須以確定的先后秩序執行,對于兩個線程必須以先后秩序執行的情況,我們可以用線程鎖來處理。
線程鎖的大致思想是:如果線程A和線程B會執行實例的兩個函數a和b,如果A必須在B之前運行,那么可以在B進入b函數時讓B進入wait set,直到A執行完a函數再把B從wait set中激活。這樣就保證了B必定在A之后運行,無論在之前它們的時間先后順序是怎樣的。
線程鎖的代碼
如右,SwingComponentLock的實例就是一個線程鎖,lock函數用于鎖定線程,當完成狀態isCompleted為false時進入的線程會進入SwingComponentLock的實例的wait set,已完成則不會;要激活SwingComponentLock的實例的wait set中等待的線程需要執行unlock函數。
public class SwingComponentLock {
// 是否初始化完畢
boolean isCompleted = false;
/**
* 鎖定線程
*/
public synchronized void lock() {
while (!isCompleted) {
try {
wait();
} catch (Exception e) {
e.printStackTrace();
logger.error(e.getMessage());
}
}
}
/**
* 解鎖線程
*
*/
public synchronized void unlock() {
isCompleted = true;
notifyAll();
}
}
線程鎖的使用
public class TreeViewPanel extends BasePanel {
// 表空間和表樹
private JTree tree;
// 這個是防樹還未初始化好就被刷新用的
private SwingComponentLock treeLock;
protected void setupComponents() {
// 初始化鎖
treeLock = new SwingComponentLock();
// 創建根節點
DefaultMutableTreeNode root = new DefaultMutableTreeNode("DB");
tree = new JTree(root);
// 設置布局并裝入樹
setLayout(new BoxLayout(this, BoxLayout.Y_AXIS));
add(new JScrollPane(tree));
// 設置樹節點的圖標
setupTreeNodeIcons();
// 解除對樹的鎖定
treeLock.unlock();
}
/**
* 刷新樹視圖
*
* @param schemas
*/
public synchronized void refreshTree(List<SchemaTable> schemas) {
treeLock.lock();
DefaultTreeModel model = (DefaultTreeModel) tree.getModel();
DefaultMutableTreeNode root = (DefaultMutableTreeNode) model.getRoot();
root.removeAllChildren();
for (SchemaTable schemaTable : schemas) {
DefaultMutableTreeNode schemaNode = new DefaultMutableTreeNode(
schemaTable.getSchema());
for (String table : schemaTable.getTables()) {
schemaNode.add(new DefaultMutableTreeNode(table));
}
root.add(schemaNode);
}
model.reload();
}
講解
上頁中,setupComponents函數是Swing主線程執行的,而refreshTree函數是另外的線程執行(初始化時程序開辟一個線程執行,其后執行由用戶操作決定)。 refreshTree函數必須要等setupComponents函數把tree初始化完畢后才能執行,而tree初始化的時間較長,可能在初始化的過程中執行refreshTree的線程就進入了,這就會造成問題。
程序使用了一個SwingComponentLock來解決這個問題,setupComponents一開始就創建SwingComponentLock的實例treeLock,然后執行refreshTree的線程以來就會進入treeLock的wait set,變成等待狀態,不會往下執行,這是不管tree是否初始化完畢都不會出錯;而setupComponents執行到底部會激活treeLock的wait set中等待的線程,這時再執行refreshTree剩下的代碼就不會有任何問題,因為setupComponents執行完畢tree已經初始化好了。
讓線程等待和激活線程的代碼都在SwingComponentLock類中,這樣的封裝對復用很有好處,如果其它復雜組件如table也要依此辦理直接創建SwingComponentLock類的實例就可以了。如果把wait和notifyAll寫在TreeViewPanel類中就不會這樣方便了。
總結
線程鎖用于必須以固定順序執行的多個線程的調度。
線程鎖的思想是先鎖定后序線程,然后讓線序線程完成任務再接觸對后序線程的鎖定。
線程鎖的寫法和使用一定要理解記憶下來。
本文內容
本文將從一個現實例子來實際說明線程調度方法wait,notify和notifyAll的使用。
工廠中任務的領受和執行
某工廠執行這樣的機制:當生產任務下達到車間時會統一放在一個地方,由工人們來取活。
工人取活如此執行:一個工人手頭只能有一個活,如果沒做完不能做下一個,如果做完了則可以到公共的地方去取一個;如果沒有活可取則閑著直到來活為止。
本文就是講述怎樣使用線程的調度三方法wait,notify和notifyAll來實現這一現實活動的。
任務類Task-它用來實現一個”活”,其中關鍵的成員是完成需消耗的工時數manHour和已經完成的工時數completed
public class Task implements Comparable {
private String id;
private String name;
// 完成需消耗的工時數
private int manHour;
// 已經完成的工時數
private int completed;
// 優先級
private int priority;
// 接受任務者
private Worker worker;
public Task(String name, int manHour) {
this(name, manHour, 0);
}
public Task(String name, int manHour, int priority) {
id = IdUtil.generateId();
this.name = name;
this.manHour = manHour;
this.priority = priority;
this.completed = 0;
}
// 任務是否完成
public boolean isCompleted() {
return completed >= manHour;
}
// 添加完成度
public void addCompleted(int n) {
completed += n;
if (isCompleted()) {
completed = manHour;
if (worker != null) {
System.out.println("任務"+this+"處理完畢!");
}
}
}
public int compareTo(Object obj) {
Task another = (Task) obj;
return (another.priority) - this.priority;
}
public String toString() {
return "任務名:" + name + " 工人名:" + worker.getName() + " 完成度:" + completed
* 100 / manHour + "%";
}
public String getCompletedRatio() {
return " 完成度:" + completed * 100 / manHour + "%";
}
...getter/setter方法省略..
}
任務庫類TaskLibrary
這個類對應現實中的取活的地方,每個活Task放在這個類的成員tasks中,有兩個方法來添加單個任務和多個任務,還有一個fetchTask方法來供工人領受任務.
public class TaskLibrary {
private List<Task> tasks;
public TaskLibrary() {
tasks = new LinkedList<Task>();
}
// 添加單個任務
public synchronized void addTask(Task task) {
tasks.add(task);
notifyAll();
}
// 添加多個任務
public synchronized void addTasks(List<Task> moreTasks) {
tasks.addAll(moreTasks);
notifyAll();
}
public int getTaskSize() {
return tasks.size();
}
// 工人領受任務
public synchronized Task fetchTask(Worker worker) {
while (tasks.size() == 0) {
try {
System.out.println("任務告罄");
System.out.println("工人:" + worker.getName() + "進入閑置狀態");
wait();
} catch (InterruptedException ex1) {
ex1.printStackTrace();
}
}
Task task = tasks.get(0);
System.out.println("工人:" + worker.getName() + "取得任務:" + task.getName());
tasks.remove(task);
return task;
}
}
工人類Worker
public class Worker implements Runnable {
private String id;
private String name;
private Task currTask;
private TaskLibrary taskLibrary;
// 工作速度
private int speed;
public Worker(String name, int speed, TaskLibrary taskLibrary) {
id = IdUtil.generateId();
this.currTask = null;
this.name = name;
this.speed = speed;
this.taskLibrary = taskLibrary;
doWork();
}
// 開始干活
public void doWork() {
Thread thread = new Thread(this);
thread.start();
}
// 真正干活
public void run() {
while (true) {
if (currTask == null || currTask.isCompleted()) {
currTask = taskLibrary.fetchTask(this);
currTask.setWorker(this);
}
try {
Thread.sleep(1000);
System.out.println("正在處理的任務" + currTask + " 完成度"
+ currTask.getCompletedRatio() + "個.");
currTask.addCompleted(speed);
} catch (Exception ex) {
ex.printStackTrace();
}
}
}
。。。
}
運行代碼
TaskLibrary taskLibrary=new TaskLibrary();
taskLibrary.addTask(new Task("培訓",8));
List<Task> moreTasks=new LinkedList<Task>();
moreTasks.add(new Task("鍛造",4));
moreTasks.add(new Task("打磨",5));
moreTasks.add(new Task("車階梯",6));
moreTasks.add(new Task("熱處理",7));
moreTasks.add(new Task("去皮",8));
moreTasks.add(new Task("鏜孔",60));
moreTasks.add(new Task("鉆孔",10));
moreTasks.add(new Task("拉槽",11));
taskLibrary.addTasks(moreTasks);
Worker worker01=new Worker("王進喜",1,taskLibrary);
Worker worker02=new Worker("時傳詳",2,taskLibrary);
Worker worker03=new Worker("張秉貴",3,taskLibrary);
Worker worker04=new Worker("徐虎",3,taskLibrary);
taskLibrary.addTask(new Task("鑄造",8));
sleep(1);
taskLibrary.addTask(new Task("校驗",9));
sleep(2);
taskLibrary.addTask(new Task("內務",10));
sleep(3);
運行情況分析
一開始先初始化任務庫,然后進行給任務庫中添加任務,初始化工人實例時會把任務庫實例的地址傳入,工人實例初始化完畢后會調用doWork函數去任務庫取任務開始做,這會進入TaskLibrary類的fetchTask函數,這時如果沒有則會讓工人等待,有則把第一個任務給他,然后周而復始進行這一過程.
運行結果示例
工人:王進喜取得任務:培訓 工人:時傳詳取得任務:鍛造 工人:張秉貴取得任務:打磨 工人:徐虎取得任務:車階梯 正在處理的任務任務名:培訓 工人名:王進喜 完成度:0% 完成度 完成度:0%個. 正在處理的任務任務名:鍛造 工人名:時傳詳 完成度:0% 完成度 完成度:0%個. 正在處理的任務任務名:打磨 工人名:張秉貴 完成度:0% 完成度 完成度:0%個. 正在處理的任務任務名:車階梯 工人名:徐虎 完成度:0% 完成度 完成度:0%個. 正在處理的任務任務名:培訓 工人名:王進喜 完成度:12% 完成度 完成度:12%個. 正在處理的任務任務名:鍛造 工人名:時傳詳 完成度:50% 完成度 完成度:50%個. 任務任務名:鍛造 工人名:時傳詳 完成度:100%處理完畢! 工人:時傳詳取得任務:熱處理 正在處理的任務任務名:打磨 工人名:張秉貴 完成度:60% 完成度 完成度:60%個. 任務任務名:打磨 工人名:張秉貴 完成度:100%處理完畢! 正在處理的任務任務名:車階梯 工人名:徐虎 完成度:50% 完成度 完成度:50%個. 任務任務名:車階梯 工人名:徐虎 完成度:100%處理完畢! 工人:徐虎取得任務:去皮 工人:張秉貴取得任務:鏜孔 正在處理的任務任務名:培訓 工人名:王進喜 完成度:25% 完成度 完成度:25%個. 正在處理的任務任務名:熱處理 工人名:時傳詳 完成度:0% 完成度 完成度:0%個. 正在處理的任務任務名:去皮 工人名:徐虎 完成度:0% 完成度 完成度:0%個. 正在處理的任務任務名:鏜孔 工人名:張秉貴 完成度:0% 完成度 完成度:0%個. 正在處理的任務任務名:培訓 工人名:王進喜 完成度:37% 完成度 完成度:37%個. 正在處理的任務任務名:熱處理 工人名:時傳詳 完成度:28% 完成度 完成度:28%個. 正在處理的任務任務名:去皮 工人名:徐虎 完成度:37% 完成度 完成度:37%個. 正在處理的任務任務名:鏜孔 工人名:張秉貴 完成度:5% 完成度 完成度:5%個. 正在處理的任務任務名:培訓 工人名:王進喜 完成度:50% 完成度 完成度:50%個. 正在處理的任務任務名:熱處理 工人名:時傳詳 完成度:57% 完成度 完成度:57%個. 正在處理的任務任務名:去皮 工人名:徐虎 完成度:75% 完成度 完成度:75%個. 任務任務名:去皮 工人名:徐虎 完成度:100%處理完畢! 工人:徐虎取得任務:鉆孔
本文內容
Java進行線程調度的方法.
如何讓線程進入等待.
wait set概念的理解.
如何激活等待狀態的線程.
進行線程協調的方法
從上一章《線程的互斥》中我們知道,當方法體或代碼塊被synchronized方法修飾時,有一個線程在執行這部分代碼時,其它線程無法同時執行這部分代碼。但如果我們想進行更高效的處理如主動調整線程而不是讓線程被動等待和盲目競爭時該怎么處理呢?
在Java中,有三個方法可以對線程進行主動高效的控制,它們是wait,notify和notifyAll。
wait是主動讓線程等待的方法,而notify和notifyAll則是激活等待中的線程的方法。他們都是Object類的方法,也就是說任何對象都可以使用這三個方法。
Wait Set-線程的休息室
在學習使用wait,notify和notifyAll這三個方法之前,我們可以先理解一下Wait Set的概念,它是一個在某實例執行wait方法時,停止操作的線程的集合,類似于線程的休息室,每個實例都擁有這樣一個休息室。
Wait方法是用來把線程請入這個休息室的,而notify和notifyAll這兩個方法是用來將進入休息室休息的線程激活的。
wait Set是一個虛擬的概念,它既不是實例的字段,也不是可以獲取在實例上wait中線程的列表的方法.它只是用來幫助我們理解線程的等待和激活的。
Wait方法,將線程放入Wait Set
使用Wait方法時,線程即進入Wait set。如線程在執行代碼時遇到這樣的語句:xxObj.wait();則目前的線程會暫時停止運行,進入實例xxObj的wait Set.
當線程進入Wait Set時,即釋放了對該實例的鎖定.也就是說,即使是被synchronized修飾的方法和代碼塊,當第一個線程進入實例的wait Set等待后,其它線程就可以再進入這部分代碼了.
wait()前如果不寫某對象表示其前面的對象是this, wait()=this.wait();
notify方法-從wait set中激活一個線程
使用notify方法時,程序會從處于等待的實例的休息室中激活一個線程.代碼如下:
xxObj.notify();程序將從xxObj的wait set中挑出一個激活.這個線程即準備退出wait set.當當前線程釋放對xxObj的鎖定后,這個線程即獲取這個鎖定,從上次的停止點-執行wait的地方開始運行。
線程必須有調用的實例的鎖定,才能執行notify方法.
Wait set中處于等待狀態的線程有多個,具體激活那一個依環境和系統而變,事先無法辯明.我們大致可理解為隨機挑選了一個.
notifyAll方法-激活wait set中所有等待的線程
當執行notifyAll方法時,實例中所有處于等待狀態的線程都會被激活.代碼為:
xxObj.notifyAll();執行此代碼后xxObj的wait set中所有處于等待中的線程都會被激活.但具體那個線程獲取執行wait方法時釋放的鎖定要靠競爭,最終只能有一個線程獲得鎖定,其它的線程只能繼續回去等待.
notifyAll與notify的差異在于notifyAll激活所有wait set中等待的線程,而notify只激活其中的一個.
該使用notify還是notifyAll
建議:
1) 選擇notifyAll比notify穩當安全,如果notify處理得不好,程序會有隱患.
2) 選擇notifyAll比notify可靠,是大多數程序的首選.
3) 當你對代碼已經很清楚,對線程理解也很透徹時,你可以選擇使用notify,發揮其處理速度高的優勢.
當前線程必須持有欲調用實例的鎖定,才能調用wait,notify和notifyAll這三個方法.
如果代碼是xxObj.notifyAll(或wait, notify)(),則這行代碼必須處于synchronized(xxObj){…}代碼塊中.
如果代碼是this.notifyAll(或wait, notify)(),則這行代碼必須處于synchronized修飾的方法中.
前面說過, notifyAll和notify會激活線程去獲得進入wait時釋放的鎖定,但這個鎖定要等剛才執行notifyAll或notify方法的線程釋放這個鎖定才能獲取.
總結
1) wait,notify和notifyAll都是java.lang.Object的方法,它們用來對線程進行調度.
2) obj.wait()是把執行這句的線程放入obj的wait set中.
3) obj.notify()是從wait set中喚醒一個線程,這個線程在當前線程釋放對obj的鎖定后即獲取這個鎖定.
4) obj.notifyAll()是喚醒所有在obj的wait set中的線程,這批線程在當前線程釋放obj的鎖定后去競爭這個鎖定,最終只有一個能獲得,其它的又重新返回wait set等待下一次激活.
5) 執行這個wait,notify和notifyAll這三個方法前,當前線程(即執行obj.wait(), obj.notify()和obj.notifyAll()代碼的線程)必須持有obj的鎖定.