公式:
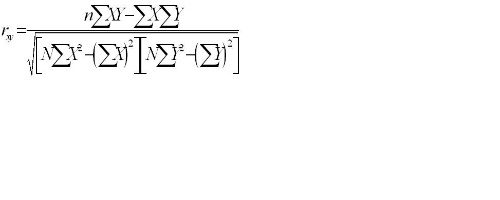
#數據 elt 清洗后(txt)
# 一般 user 和 item 分值化
# 比如 用戶下載,收藏,試聽 某item 等等
user items score
 .
.
# 結果輸出 (bdb)
# user item1:score1,item2:score2,item3:score3.
python<<EOF
import bsddb
db = bsddb.hashopen('user-items.db','c')
for row in open('user-item-sc.txt'):
row=row.split('\n')[0]
dr = row.split(':')
if not db.has_key(dr[0]) : db[dr[0]]=dr[1]+':'+dr[2]
else : db[dr[0]]=db[dr[0]]+';'+dr[1]+':'+dr[2]
db.close()
EOF
# 結果輸出 (txt)
# user user score
python<<EOF
import bsddb
from math import *
db = bsddb.hashopen('user-items.db','c')
def ps(u1,u2):
um1={}
for v in db[u1].split(';') :
v=v.split(':')
um1[v[0]]=float(v[1])
um2={}
si=[]
for v in db[u2].split(';') :
v=v.split(':')
um2[v[0]]=float(v[1])
if um1.has_key( v[0] ) : si.append(v[0])
n = len(si)
if n ==0.0 :return None
sum1=sum( [um1[it] for it in si] )
sum2=sum( [um2[it] for it in si] )
sum1Sq=sum([ pow(um1[it],2) for it in si])
sum2Sq=sum([ pow(um2[it],2) for it in si])
pSum = sum( [ um1[it]*um2[it] for it in si ] )
num = pSum - (sum1*sum2/n)
den = sqrt( (sum1Sq-pow(sum1,2)/n )*( sum2Sq-pow(sum2,2)/n ) )
if den==0.0 : return None
return num/den
fc = open('user-user-sc.txt','w')
for i in xrange(1,43381):
for j in xrange(i+1,43381):
sc = ps(str(i),str(j))
if not sc == None: print >>fc, "%s\t%s\t%s" %(i,j,sc)
fc.close()
EOF
# 測試使用
python<<EOF
import bsddb
db = bsddb.hashopen('user-items.db','c')
print db['1']
EOF
25 30604 1.0
print um1['468'],um1['471']
2.0 1.0
(Pdb) print um2['468'],um2['471']
2.0 1.0
如果對大家對 推薦有一些了解,數據能到 用戶與用戶關系(分值化) ,是能干很多事情了。
比如:
1. 首先得到某用戶相近度最高的幾位活躍用戶,看這幾位用戶在看什么,聽什么 然后推薦出去
擴展:
把初始值 反過來 item user score ,然后統計出 item 和 item 之間的關系 。
當 消費某一產品 ,馬上推薦出 其他的相近的產品 (時時推薦)
整理 m.tkk7.com/Good-Game