2012年3月2日
#
轉發 http://blog.chinaunix.net/uid-23093301-id-90459.html
問題來源:
創建一個游戲系統,其將運行在互聯網的環境中。客戶端通過WWW服務或特定的客戶端軟件連接到游戲服務器,隨著流量的增加,系統不斷的膨脹,最終后臺數據、業務邏輯被分布式的部署。然而相比中心化的系統,復雜度被無可避免的增大了,該如何降低各個組件之間的耦合度。
挑戰:
需要保證可伸縮性、可維護性、可更新性,需要將服務劃分為各個相對獨立的組件,組件被分布式的部署,它們之間通過進程間通信方式實現交互。服務的增加、刪除、改變都應該被支持。理想情況,以開發者的角度看,集中化的系統和分布式的系統在中心邏輯上沒有什么不同。為實現這個目標:
l 可以遠程的訪問服務,而對于訪問者,服務的位置應該是透明的。
l 提供服務的組件可以增加、刪除、改變,而且這些在運行期同樣應該被支持。
l 訪問服務的客戶端不應該關心服務的實現細節。
解決方案:
引入一個Broker組件,解耦客戶端和服務端。服務端注冊自己到Broker,通過暴露接口的方式允許客戶端接入服務。客戶端是通過Broker發送請求的,Broker轉發請求道服務端,并將請求的結果或異常回發給客戶端。通過使用Broker模式,應用可以通過發送消息訪問遠程的服務。
這一架構模式允許動態的改變、添加、刪除服務端,從客戶端的角度,這些都是透明的。
結構:
Broker模式定義了6中類:Client,Server,Client_Proxy,Server_Proxy,Broker,Bridge。
Server:
l 責任:處理特定領域的問題,實現服務的細節,注冊自己到Broker,處理請求并返回結果或異常。
l 協作類:Server_Proxy,Broker
Client:
Client是需要訪問遠程服務的應用程序,為此,Client發送請求到Broker,并從Broker上接收響應或異常。Client和Server只是邏輯上相關而已,實際上Client并不知道Server的確切位置。
l 責任:1. 實現用戶端功能,2. 發送請求到Broker,3. 接收相應和異常。
l 協作類:Broker,Client_Proxy
Broker:
Broker可以被看成消息轉發器。Broker也負責一些控制和管理操作。它能夠定位服務端的位置,若發生異常,能夠將異常捕獲傳給Client。Broker需要提供注冊服務的接口給Server。如果請求來自其他的Broker,本地的Broker需要轉發請求并最終將結果或異常回應給相應的遠程Broker。Broker提供的服務和name service非常相像(如DNS、LDAP)。
l 責任:1. 注冊服務。2. 提供服務API。3. 轉發消息。4. 容錯處理。5. 與其他Broker的交互。6。 定位服務。
l 協作類:Client_Proxy,Server_Proxy,Bridge
Client_Proxy:
連系Client和Broker,這一層保證了通訊的透明性,使Client調用遠程服務就像調用本地的服務一樣。
l 責任:1. 封裝特定的系統調用。2. 封裝通訊的參數、控制信息等。
l 協作類:Client,Broker。
Server_Proxy:
Server_proxy是與Client_Proxy相對應的,它接受請求,解包消息,解析出參數并調用服務的實現接口。
l 責任:1. 封裝特定的系統調用。2. 封裝通訊的參數、控制信息等。3. 調用server的服務接口。
l 協作類:Server,Broker。
Bridge:
Bridge用來連接各個Broker,一般這個組件是可選的。當系統是發雜的網絡組成時,有可能需要這一角色。
l 責任:1. 封裝特定的網絡特性。2. 傳遞Broker之間的通訊。
l 協作類:Broker。
應用場景一:
直接通訊方式。Client和Server相互理解他們之間的通訊協議。Broker主要完成Client和Server之間的握手。之后所有的消息、異常都是由Client與Server直接交互。(想象DNS)。簡單對象交互如圖:
應用場景二:
l Broker啟動,完成自身的初始化,之后進入事件循環,等待消息到來。
l Server啟動,首先執行自身的初始化,然后注冊自己到Broker。
l Broker接收Server的注冊請求,將其加入到可使用服務的列表,并回應Ack給Server。
l Server接收Ack,進入事件監聽循環,等待消息到來。
l Client調用遠程服務對象的方法,Client_Proxy封裝消息請其發送給Broker。
l Broker查詢可使用的Server,將請求轉發給Server。
l Server_Proxy解析消息,分離出參數和控制信息,并調用特定的Server實現接口。Server處理完的結果通過Server_proxy封裝成消息轉發到Server。
l Broker將相應消息轉發給正確的Client_Proxy,Client受到響應繼續其他邏輯。
簡單對象交互如圖:
應用場景三:
l Broker A接收到請求,交由Server處理,但是發現該Server位于其他的網絡節點。
l Broker A將請求轉發給Bridge A,Bridge A將請求進行必要的格式化,傳送給Bridge B。
l Bridge B將請求進行必要的格式化,轉化成Broker B可以理解的格式,并轉發給Broker B。Broker B執行場景二中的過程,處理的結果按如上逆序返回。
簡單對象交互如圖:
部署示意圖:
總結:
u 優點:
1. 服務的位置透明性。
2. 組件的可變性及擴展性。由于Server是注冊到Broker上的,所以Server可以動態的增加、刪除、改變。
3. Broker之間可交互。
4. 可重用性。
5. 由于組件的耦合度較小,調試和測試的工作也是可控的。
u 缺點:
1. 效率;增加了一層Broker的消息轉發,效率有所降低。
2. 容錯能力必須要特別考慮。
3. 調試和測試的工作加大。
大師的非凡能力來源于何處?思維方式是關鍵。科學證據告訴人們,沒有天生的大師,只有煉就的專家。只要擁有專家的思維,你就能成為大師!
1909年的一天。多張象棋桌圍成了一個圈,一個男子在圈內慢慢踱步。他的雙眼不斷掃描周圍的棋局,每隔兩三秒鐘就會下一步棋。而在圈外,數十位象棋迷不停地搔頭、苦想對策。這個人是誰?為什么他能以一人之力抗衡數十人的智慧?他就是國際象棋界的傳奇人物,古巴象棋大師卡帕布蘭卡(José Raúl Capablanca)。比賽結果毫無懸念,卡帕布蘭卡28局全勝。這只是他巡回表演賽中的一站,在整個巡回表演賽中,卡帕布蘭卡贏了168局。
為什么眨眼間他就能作出最正確的決定?面臨巨大的壓力,他能提前計算幾步?卡帕布蘭卡輕描淡寫地說:“我只提前看一步,但總是最正確的一步。”
這句話再簡單不過,卻開創了心理學研究的新紀元:象棋大師優于新手的地方就在于那電光火石間的思考。這種快速的、由知識引導的知覺,有時叫做“領悟”。在其他領域,專家們同樣具有“領悟”的本領。一次比賽完畢,象棋大師能記住自己走過的每一步棋;對于一段音樂,哪怕只聽過一遍,資深音樂家也能寫出樂章的曲譜。無論多么困難,象棋大師也能在瞬間想到最妙的棋著;不管多么復雜,經驗豐富的專業內科醫生有時只須瞥上病人幾眼,就能作出準確的診斷。
專家們的非凡技藝從何而來?源于天賦,還是得益于強化訓練?通過對象棋大師的研究,心理學家找到了答案。一個世紀的探索積累了大量研究成果,新的理論應運而生,人腦處理信息(信息的組織與提取)之謎也由此破解。這項研究的意義還不僅在于此,人類的教育事業也將從中受益:象棋棋手提高棋藝的技巧,可否用于提高學生們的閱讀、寫作和計算能力呢?
象棋是最好的研究對象
人類何時開始擁有專業技術?這也許要從祖先們的狩獵說起。對于他們而言,狩獵技術是維系生命的重要工具,不掌握它就難以生存。經驗豐富的獵人不僅知道獅子在哪里出沒,而且還能推斷出獅子的行蹤。從孩提時代開始,他們就得跟隨長輩練習追蹤技術。隨著年齡的增長,追蹤技術也日益嫻熟。“技術的熟練程度隨著年齡的增長而增長,35歲左右達到技術的巔峰,”美國加利福尼亞大學富勒頓分校的人類學家約翰?博克(John Bock)說道。練習追蹤技術要花費很多時間,可能比培養優秀的腦外科醫生還要費事。
相對于新手,如果在技術上沒有絕對優勢,那就難稱專家,只不過是多了一張唬人的文憑。這種披著專家外衣的人比比皆是。過去20年的研究結果表明,所謂的專業炒股者并不比業余者賺的錢多;知名品酒家對酒類的鑒別能力并不比饞酒的老農強;高學歷的精神病醫生并不比低文憑的同行出色……即使真的存在專業技術,如教學、工商管理,都很難去衡量,更別提如何去闡釋。
不過,棋藝卻可以度量、可以分解、可以接受試驗研究,并且十分直觀,尤其在比賽時,任何人都能隨時觀看。正是基于以上原因,認知科學家如獲至寶,將象棋作為研究思維理論的最佳試驗對象。于是象棋被稱作“認知科學的果蠅”。
對象棋手棋藝的度量,已經走在了其他任何比賽、運動或競技活動的前面。運用統計學公式,對棋手曾獲得的所有成績進行分析,就可以得到棋手的實力等級。然后根據棋手的等級與對手的實力,即可準確地推算出棋手的獲勝幾率。如果A棋手的等級分高于B棋手200點,那么在比賽中,A戰勝B的平均幾率為75%。不管棋手是頂級的還是普通的,這種預測都很準確。例如,俄羅斯特級象棋大師加里?卡斯帕羅夫(Garry Kasparov),他的等級分是2812點,而荷蘭象棋大師揚?蒂曼(Jan Timman)的等級分是2616點。如果二者對弈,那么卡斯帕羅夫就有75%的勝算。同樣,中等水平的棋手(1200點)與另一個1000點的棋手對弈,前者亦有75%的勝算。選手的等級分代表著他們的真正實力,以選手的等級為標準,心理學家就可以客觀地評估他們的專業技術,動態追蹤他們整個象棋生涯,而不會受到選手名氣的影響。
為什么認知科學家沒有選擇臺球或橋牌作為研究模型,而偏偏選擇象棋呢?可能是因為象棋比賽最考驗人的智慧。正如德國詩人歌德所言,象棋是“智慧的試金石”。象棋大師的技藝出神入化,令人嘆為觀止,人們將他們的能力歸因于他們“擁有魔力”的大腦。這種魔力在下盲棋時體現得淋漓盡致。法國心理學家阿爾弗雷德?比奈(Alfred Binet)是首個智力測驗的發明人之一。1894年,他曾請象棋大師描述他們下棋的過程。起初,他認為棋盤就像照片一樣存在于象棋大師的大腦中,但是他很快斷定,大師們大腦中的圖像還要抽象得多。他們整體把握棋子的位置關系而不注重具體細節,就像只關心馬而不關心馬的鬃毛一樣。
通過把握比賽的即時細節以及回想走過的棋步,盲棋大師能將腦海中的棋局補充完整。假設大師忘記了卒的準確位置,該怎么辦呢?他立即開始回想開局時的套路,因為在開局時,套路相對固定,而且已經爛熟于胸,因此很容易找到卒曾經所在的位置。他也可以回憶走過的棋步,通過推理來找到卒的位置――“前兩步我沒能抓住他的相,所以當時一定有卒在擋路……”他不必糾纏細節不放,利用組織完善的連接系統,可以重獲任何想要的細節。
如果大師們的魔力――超凡的計算、計劃能力都是以復雜的知識結構為基礎,那么就可以肯定,專業技術多半來源于刻苦訓練,而非上天的恩賜。荷蘭心理學家阿德里安?德赫羅特(Adriaan de Groot)是一位象棋大師。1938年,荷蘭舉行了一場國際象棋錦標賽,他利用主場之便,對普通棋手、專業棋手與世界頂級大師進行比較后,進一步鞏固了上述觀點。他曾使用的一種方法就是請棋手觀看節選自比賽的棋局,然后說出自己的想法。他發現,盡管專業棋手的分析能力要比普通棋手強,但是當他們的實力提升至大師級時,反而不會去思索更多的下法。因為在高手的心中,只會留下最妙的棋著――正如卡帕布蘭卡聲稱的那樣。
近來研究表明,德赫羅特的發現只展示了象棋大師的部分實力。在一場對弈中,如果大量而精確的計算無法避免時,大師們就會拿出真功夫,深入研究各種可能的棋步走法。這種能力,會讓普通棋手望塵莫及。同樣,知識淵博的物理學家遭遇難題時,也會比他的學生想出更多的解決辦法。然而在上述兩種情況下,專家依靠的不是與生俱來的強大的分析能力,而是多年來逐漸建立起來的知識結構。面對困難的棋局,一個實力平平的棋手可能會耗費大半個小時去計算、提前看許多步,然而總是錯過最正確的一步。相反,一個大師級的棋手根本不用有意識地去分析,立即就能看到精妙入微的一步。
德赫羅特還讓參加試驗的棋手在短時間內審視棋局,然后憑記憶重建棋局。在這樣的試驗條件下,任何棋手的實力都會暴露無遺。就算用長達30秒鐘的時間去回憶棋局,新手能記起的細節也是支離破碎的。而象棋大師,即使只瞟上幾眼,也能輕松重建棋局。這種差別源于一種特殊記憶,也就是對棋局的特異性記憶。特殊記憶是訓練的結果,因為在一般性的記憶測試中,大師的表現并不比其他人好。
同樣的現象還能從橋牌牌手(多場牌局后,仍記得出過的牌)、計算機程序設計師(能重組大量的計算機編碼)和音樂家(能記住大段大段的樂章)身上看到。在特殊領域,對主題事務的記憶能力,是衡量專業技術水平的重要標準。
一個不常見的案例也能證明,知識結構才是專家們戰無不勝的法寶。一個叫D.H(姓名不全)的業余棋手,經過9年的訓練,終于在1987年成為了加拿大一流的象棋大師。美國佛羅里達州立大學的心理學教授尼爾?蔡內斯(Neil Charness)指出,盡管這個棋手的實力已經今非昔比,但是他對棋局的分析范圍并不比從前廣泛,反而是日益精深的棋局知識和相關策略幫助他連連告捷。
非凡能力來自何方
在上世紀60年代,美國卡耐基-梅隆大學的心理學家赫伯特?西蒙(Herbert Simon,1978年諾貝爾獎得主)和威廉?蔡斯(William Chase),試圖通過研究專家的記憶局限性來更好地洞察專家的記憶能力。按照德赫羅特的研究思路,他們請各個級別的棋手重建曾被人動過的棋局。不過這盤棋局不是大師對弈后的殘局,而是一盤亂擺的棋局。在重建這盤隨機棋局時,棋手間的差距并不明顯。
因此,象棋運動中的特異性記憶不只取決于象棋這項運動,還取決于棋局的類型。這些實驗驗證了早期的研究結果,有力地證明了能力的非通用性,不同的領域需要不同的能力。早在一個世紀前,美國心理學家愛德華?桑代克(Edward Thorndike)就首先提出了上述理論。當時他指出,拉丁語說得好不等于英語水平高,幾何證明也不能教會人們在日常生活中運用邏輯思維。
象棋大師要處理的信息,數量極其龐大,似乎已經超越了人類記憶的極限。為了解釋他們這種超凡的能力,西蒙引入了模塊理論。1956年,美國普林斯頓大學的心理學家喬治?米勒(George Miller)曾發表過一篇著名的論文――《非凡的數字7±2》。米勒在論文中指出,人的記憶有一定的限度,每次只能處理5~9條信息。西蒙強調說,通過把不同層次的信息構建成一個一個模塊,大師就能突破記憶的極限。通過這種方法,他們會去捕捉5~9個模塊,而不是5~9個具體細節。
以“Mary had a little lamb”(瑪麗有一只小羊羔)這句詩為例。詩里的信息模塊數取決于讀者對詩歌與英語的熟悉程度。對于以英語為母語的人,這句詩是一個非常大的模塊――著名詩歌的一部分;對于懂英語卻不懂詩歌的人,這就是一句話――一個完整的模塊;對于記得單詞卻不明白含義的人,這句話是5個模塊(單詞);而對于認得字母,卻不認識單詞的人,這句詩就是18個模塊(字母)!
在象棋新手和象棋大師之間就能清楚地看到這種差別。假如有一個擺著20個棋子的棋局放在面前,新手和大師會怎么處理其中的信息呢?新手滿眼都是棋格,而棋子又有多種擺法,因此他獲取的信息模塊遠多于20個。那么大師呢?他會將棋局整體化,然后把整個棋局分割成5~6個模塊,這樣記起來不就輕松多了!根據獲取一個新的記憶模塊所花掉的時間,以及普通棋手成長為大師級選手所需要的時間,西蒙估算出了象棋大師的大腦中存儲的信息模塊數:5萬~10萬個!就像我們聽幾個字就能背出一首古詩一樣,象棋大師只要看一眼棋局,就能從記憶中提取出相應的信息模塊。
但是模塊理論還有缺陷。對一些記憶現象,例如當大師們精力分散時,他們的表現并沒有受到明顯影響,模塊理論就無法給出合理的解釋。佛羅里達州立大學的K?安德斯?埃里克森(K. Anders Ericsson)與蔡內斯認為,可能還存在另外一種機制,使得專家可以把長時記憶當作暫存區使用。埃里克森說:“訓練有素的棋手在不看棋盤的情況下,能以幾乎正常的水平下棋,要用模塊理論來解釋這樣的事例,幾乎不可能。因為你必須先了解棋局,然后才能在記憶中把它翻出來。”這一處理過程需要改變已有的信息模塊,就像倒背 “Mary had a little lamb”,雖然可以做到,但是很難,而且還會錯誤不斷。然而在下盲棋的時候,象棋大師仍然可以精準快速地下棋,讓對手無所適從。
埃里克森還引證了內科醫生的學習過程。醫生們先把信息變為長時記憶,當需要使用這些信息來診斷疾病時,再把它從記憶中提取出來。埃里克森還列舉了一個最普通、最常見的例子――閱讀。1995年,他在研究中發現,越是熟練的讀者越不容易受到干擾。就算閱讀被打斷,熟練的讀者也能在幾秒鐘的時間內恢復原有的閱讀速度。研究人員用長時工作記憶來解釋這一現象。這一說法似乎自相矛盾,因為長時記憶與工作記憶是兩個相互對立的概念。不過在2001年,德國康斯坦茨大學進行的大腦成像研究卻為這一說法提供了依據。研究結果表明,較之新手,專業棋手的長時記憶顯然更容易激活。
上世紀90年代末期,西蒙曾提出過一種競爭理論。英國倫敦布魯內爾大學的費爾南德?戈貝特(Fernand Gobet)對它推崇備至。競爭理論實際上是模塊理論的延伸,它引入了“模板”的概念,也就是一種極其典型并包含了大約12只棋子的大型布局。模板擁有許多插口,大師可以插入卒或者相這樣的變量。再以詩句“Mary had a little lamb”為例,如果某個詞的韻律與詩句中的詞等同,那么就可以用這個詞來替換詩中的詞。例如,用“Larry”替代“Mary”,用“pool”來替代“school”等等。任何知道原始模塊的人,都能在瞬間插入另一個詞。
天才是怎樣“煉”成的
要想在大腦中建立復雜的知識結構,就得不斷努力。西蒙提出了“十年規則”,他認為要掌握任何技藝,十年的艱辛歷程是無法避免的。即便是數學天才高斯,音樂奇才莫扎特,象棋神童菲舍爾,也得去拼搏、去奮斗,也許他們所付出的努力是常人難以想象的。
近年來,象棋天才似乎不斷涌現,但這都歸因于計算機的強大功能。計算機能讓孩子們研究海量的大師級比賽,頻繁地與大師級程序對抗,于是在較短的時間內,他們就能積累豐富的實戰經驗。1958年,15歲的菲舍爾獲得了象棋大師的稱號,當時這一消息震驚了全世界。而目前的記錄保持者、烏克蘭的謝爾蓋?卡爾亞金(Sergey Karjakin)獲得大師稱號時,僅有12歲零7個月!
埃里克森認為,光是練習遠遠不夠,還需要全身心投入,不斷挑戰極限、超越自我。就像業余愛好者,他們可能會用大量的時間來練習下棋、打高爾夫球、演奏樂器,卻始終達不到專業水平;然而一個經過正規訓練的學生,卻能在較短的時間內超過他們。這是一個很有趣的現象,說明練習和比賽對棋手的幫助似乎不如踏踏實實地學習。訓練和比賽的主要價值在于,新手可以從中發現自己的缺陷,從而在以后逐漸彌補。
在學習初期,新手往往興趣濃厚,鉆研勁兒十足。他們剛開始學習打高爾夫球或者開車時,技術的進步速度可用“神速”二字來形容。但是技術一旦攀升到一定的階段,例如跟上了高爾夫球友的節奏,或者考取了駕照,大多數人就松懈了。于是,他們變得懶散,技術也被荒廢。相反,訓練專家總是讓人不停地思考,因此參與學習的人就會自覺自律地去鉆研、不斷提高技術,從而縮小與高手之間的差距。
人類在進步,衡量專業水平的技術標準也在不斷提高。現在的高中生能在4分鐘內跑完一英里(約合1.6公里);學音樂的學生敢于演奏曾經只有名家才敢嘗試的曲子。如果說上述比較還不能讓人信服,那么我們再來看看象棋上的證據。英國人約翰?納恩(John Nunn)既是數學家,又是象棋大師。他利用計算機,比較了1911年和1993年舉行的兩屆國際象棋錦標賽。結果發現,現代棋手出錯的幾率要小很多,換言之,他們比前輩們下得更準確。納恩還研究了1911年的一個棋手下過的所有棋局。在當時,這個棋手算是一個中等級別的選手。按照今天的標準,他的等級分不會多于2100點,離大師級標準還有一大段距離。與普通棋手相比,百年前的大師仍然實力強勁,不過與今天的大師相比,可能就有一定的差距。
在卡帕布蘭卡的那個時代,計算機、象棋數據庫都還沒有出現,他們只能靠自己解決一切問題,正如巴赫、莫扎特和貝多芬。如果說今天的大師在技術上已經超越了曾經名滿天下的先輩們,然而在創造力方面他們卻難以望其項背。今天,剛畢業的物理學博士掌握的物理知識,恐怕連牛頓也要自嘆弗如,但是在這些博士中,有誰能像當年的牛頓一樣發現萬有引力定律?
說到這里,很多懷疑論者的耐心可能會蕩然無存。他們肯定會說,要步入卡耐基殿堂,除了練習、練習、再練習之外,還要付出更多的東西。雖然相信天資的重要性,尤其是專家和他們的學生對此深信不疑,然而奇怪的是,沒有任何證據來支持這一觀點。2002年,戈貝特曾做過一項研究。研究中,他用圖形記憶測驗衡量各級別棋手的視覺空間智能。結果發現,棋藝的高低與視覺空間智能的強弱根本沒有聯系。還有研究人員發現,職業裁判預見賽馬結果的能力與他們的數學能力也沒有什么關系。
... ...
摘要: 熵是信息理論中非常重要的一個概念,用來度量信息,在實踐中大量使用。
信息檢索最重要的概念TF/IDF(term frequency/inverse document frequency)就是基于信息熵理論。搜索引擎、新聞分類、文本相似度計算都使用這個概念。
閱讀全文
看Chomsky的書是因為在編譯原理課程中多次提到這個人,這是個變態天才,神一般的存在,而且還是活的。
Chomsky的語言學理論觀點在語言學、心理學和哲學領域都產生了廣泛而深刻的影響。Chomsky的哲學思想是一個貫穿了唯實論、自然主義和心智主義的連貫的、完整的體系。這一體系的核心是內在語言理論。但是這一理論觀點與傳統觀點分歧很大 ,因此遭受到哲學界的強烈攻擊。Chomsky正是在這些爭論的過程中不斷地發現問題并對自己的理論和觀點進行修改和補充 ,從而使其哲學系統乃至語言學理論系統更趨完善。哲學問題咱不關心這么無聊的問題留給哲學家們去扯。
理論方法
Chomsky語言學的理論方法概況起來講,是自然科學中形式主義的演繹方法,用Chomsky自己的話講,叫伽利略研究風格(Galileo Style),像伽利略為宇宙建立抽象的數學模型一樣,構建有關語言知識的抽象數學模型,相信類似數學一樣的形式主義的演繹推理模型具有自足自明的真理性。Chomsky的語言研究所追求的是從世界各種語言五花八門的句子樣式中抽象出幾個簡單的句法規則。
Chomsky的句法結構一書中把語言學看成跟自然科學中的其他科學一樣,可以從假設出發,進行推演并形式化。換句話說,非經驗主義是可能的。《句法結構》有一半篇幅用于英語語法的形式化。非經驗主義和形式化是轉換生成語法的首要標志。
把句法關系作為語言結構的中心并以此說明語句的生成是這場革命的又一表現。為了描寫和解釋語言現象,Chomsky在《句法結構》中論證了語法的生成能力,認為應該把語法看成是能生成無限句子的有限規則系統。
它以"核心句"為基礎,通過轉換規則描寫和分析不同句式之間的內在聯系。該書分析了以"馬爾可夫過程"為基礎的通訊理論,認為它只能生成有限狀態的語法,而這種"有限狀態的語法"不能生成象英語這種語言里含有不連續結構的所有合乎語法的句子。基于此,喬姆斯基提出了轉換語法模式,認為它才能生成所有合乎語法的句子而不會生成不合乎語法的句子。轉換語法模式由短語結構規則、轉換規則、語素音位規則三套規則構成。
短語結構規則有三種:合并、遞歸、推導式,其基本形式是x→y 。→讀作"改寫",這個公式就是將x改寫成y。短語結構規則生成的是"核心語符列",不經過轉換直接由這種語符列得出的基本句型叫"核心句"。
轉換規則包括:移位、刪略、添加。最后運用語素音位規則得出實際說出的句子。這三套規則中,最引人注目的是轉換規則,因為短語結構規則和語素音位規則實際上繼承了描寫語言學的"直接成分分析"和語素音位的分析,轉換是一種創新,它使語法具有更強的解釋力。
《句法結構》把語義排除在語法之外,這一時期的理論框架不包括語義部分。喬姆斯基認為,語法理論不應該建立在語義的基礎上,而應該用某種嚴格的、客觀的方法去代替對于模糊的語義的依賴。不過這一理論在后來的發展中做了重大的修正。
Chomsky 定義的四種形式語言文法中, 0 型文法又稱為 ( A )文法; 1 型文法又稱為 ( C ) 文法; 2 型語言可由 ( G ) 識別。
A .短語結構文法 B 前后文無關文法 C 前后文有關文法 D 正規文法
E 圖靈機 F 有限自動機 G 下推自動機
文法是用來定義語言的一個模型,常用的文法體系為Chomsky文法體系。
文法定義
文法G(Grammar)是一個四原組,G=(N,T,P,S),N(Non-terminator)是非終結符集合,T(Terminator)是終結符集合,P(Production)是產生式集合,S(Start)是起始符
其中:
N 交 T = 空集
P 是形式為 α -> β 的產生式
α ∈ (N∪T)*N+(N∪T)*,也就是說α中必須有一個非終結符
β ∈ (N∪T)* ,也就是說β可以是空串
S∈N
分類
0型文法(短語文法或無限制文法),識別0語言的機器叫做圖靈機
定義:P中產生式a-->b,其中a屬于V正閉包且至少含有一個非終結符,b屬于V星閉包
注:任何0型文法都是可遞歸可枚舉的
對0型文法作某些限制,可以得到其他文法的定義
1型文法 又稱上下文有關文法。生成式形式為 α->β, 且 |α| < |β| 并且不存在 A->ε
2型文法 又稱上下文無關文法。生成式形式為 A->α,即左邊必須只有一個非終結符
3型文法 又稱正則文法。
生成式 A->wB或A->w,稱為右線性文法
生成式 A->Bw或A->w,稱為左線性文法
0型文法 對生成式沒有任何限制的文法稱為0型文法。從0到3都是包含的關系,但是有特例,包含 A->ε 產生式的2,3型文法不屬于1型文法。
四種文法產生的語言分別稱為 上下文有關語言,上下文無關語言,正則語言,無限制性語言。
2型語言的表示法
2型語言是很重要的一種語言,除了用四元組的方法表示,此處再介紹兩種表示方法。
當人們要解釋或者討論程序設計語言本身時,經常又需要一種語言,被討論的語言叫做對象語言,即某種程序設計語言,討論對象語言的語言稱為元語言,即元語言是描述語言的語言。BNF范式通常被作為討論某種程序設計語言語法的元語言,而語法圖是與BNF范式的描述能力等價的另一種文法表示形式,因其直觀性而經常采用。
(1)巴科斯范式(Backus Normal Form,BNF)
2型文法生成式左端只有一個非終結符,所以可以把左端相同的生成式合并在一起,右端用|隔開,用::=代替->,所有非終結符用<>括起來,這是Backus為了描述AIGOL語言首次提出并使用的。
用BNF描述十進制整數的生成語法:
<無符號整數> ::= <數字>|<數字><無符號整數>
<數字> ::= 0|1|2|3|4|5|6|7|8|9
(2)語法圖
語法圖有四種基本形式
(3)推導樹
2型文法還經常用推導樹表示
節選自java.g
modifiers
:
( annotation
| 'public'
| 'protected'
| 'private'
| 'static'
| 'abstract'
| 'final'
| 'native'
| 'synchronized'
| 'transient'
| 'volatile'
| 'strictfp'
)*
;
Strictfp —— Java 關鍵字。
strictfp, 即 strict float point (精確浮點)。
strictfp 關鍵字可應用于類、接口或方法。使用 strictfp 關鍵字聲明一個方法時,該方法中所有的float和double表達式都嚴格遵守FP-strict的限制,符合IEEE-754規范。當對一個類或接口使用 strictfp 關鍵字時,該類中的所有代碼,包括嵌套類型中的初始設定值和代碼,都將嚴格地進行計算。嚴格約束意味著所有表達式的結果都必須是 IEEE 754 算法對操作數預期的結果,以單精度和雙精度格式表示。
如果你想讓你的浮點運算更加精確,而且不會因為不同的硬件平臺所執行的結果不一致的話,可以用關鍵字strictfp.
import語句可以導入一個類或某個包中的所有類
import static語句導入一個類中的某個靜態成員(方法或屬性)或所有靜態成員
語法舉例:
import static java.lang.Math.sin;
import static java.lang.Math.*;
例子:
//導入Math類中的所有static方法和屬性。
//這樣我們在使用這些方法和屬性時就不必寫類名。
import static java.lang.Math.*;//import static java.lang.Math;//這樣寫報錯
public class StaticImport {
public static void main(String[] args) {
// System.out.println(Math.max(3, 5));//沒有使用靜態導入
// System.out.println(Math.abs(1-9));//沒有使用靜態導入
System.out.println(max(3, 5));
System.out.println(abs(1-9));
}
注意:1默認包無法用靜態導入。
2如果導入的類中有重復的方法和屬性則需要寫出類名,否則編譯時無法通過。
}
概述:
在設計開發過程中經常會出現開發庫與測試庫不一致,測試庫與生產庫不一致,每次手工比對是個辛苦的活。
以前用java寫過一個數據庫結構比較工具,最近騰出功夫來學習了一下python,用python重寫了一下,已經提交到了github和sourceforage.
版本控制使用github
https://github.com/zhengys/dbcompare.gitsourceforage上邊放了exe文件(用pyinstaller打包的程序發現在部分win7上不能正常工作,
又用py2exe打包了一個64位版本的,已經上傳sourceforage , 感謝itshu的反饋)http://sourceforge.net/projects/databasecompare/files/通過這個工具可以做到簡單明了的看出區別。
對于數據庫和設計文檔不一致的情況,目前只能是先根據文檔生成數據庫,再和原來的庫做比對。未來考慮增加powerdesinger和數據庫的間直接比較。
目前只支持oracle,mysql,sqlserver,要是用的人多了再增加其它類型的數據庫。
使用:
功能類似文本比較工具,分別輸入數據庫連接信息,在結果頁面顯示比對結果。
操作很簡單看圖就知道怎么用了。
如圖:
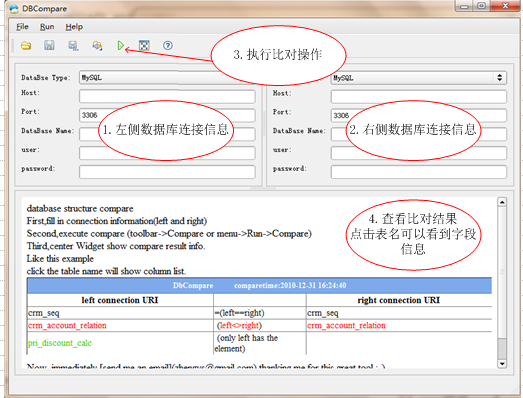
打包說明
一開始用py2exe打包,發現在winxp下用不了
改用pyinstaller打包,360會誤認為是木馬攔截,文件夾形式打包,比較占地方,壓縮后也得36MB.
可根據源碼自行打包。
首先解釋一下為什么它被稱之為SOCKS。其實該協議設計之初是為了讓有權限的用戶可以穿過過防火墻的限制,使得高權限用戶可以訪問一般用戶不能訪問的外部資源。當時設計者考慮到幾乎所有使用TCP/IP通信的應用軟件都使用socket(套接字,實際上是一組應用程序接口)完成底層的數據通信。為了方便軟件開發者使用該協議,協議設計者就刻意對應了幾組socket編程最經典的操作,并且將協議定名為SOCKS。
最先被廣泛使用的SOCKS協議是其第四版本,就是SOCKS4。IE和一些其他應用程序直接用“Socks”表示SOCKS4協議。該版本支持TCP的connect(作為客戶端連接)和listen(打開一個監聽端口),不支持UDP協議。SOCKS4A對SOCKS4作了一點增強,即允許客戶端將域名發送給SOCKS服務器,讓SOCKS服務器進行域名解析。
SOCKS5是第五版,相對第四版作了大幅度的增強。首先,它增加了對UDP協議的支持;其次,它可以支持多種用戶身份驗證方式和通信加密方式;最后,修改了SOCKS服務器進行域名解析的方法,使其更加優雅。經過這次脫胎換骨的升級,SOCKS5于1996年被IETF確認為標準通信協議,RFC編號為1928。經過10余年的時間,大量的網絡應用程序都支持SOCKS5代理。
SOCKS5雖然可以支持多種用戶身份驗證方式,但是應用程序真正實現的一般也只有兩種:不驗證和用戶名密碼驗證。所以大多數應用程序SOCKS5代理設置也只有用戶名/密碼這一種可選驗證方法。另外,盡管從SOCKS4開始,就支持打開TCP監聽端口,但是直到SOCKS5,也只允許這個端口接收一個客戶端連接。因此網絡服務提供者(如http服務器)不能使用SOCKS。實際上,很多SOCKS服務器的實現也不支持打開TCP監聽端口。
由于SOCKS5實際上仍然對應了socket的經典操作,所以有人利用這一點編寫了一種通用軟件,可以讓不支持SOCKS5協議的應用軟件也能通過SOCKS5服務器進行網絡通信,而應用軟件則對此一無所知。這類軟件最著名的莫過于SocksCap32了,它是Permeo公司(其前身是NEC北美公司的一個部門,而SOCKS最初就是NEC北美公司的工程師開發并維護的)早期推出的一款產品。用戶可以免費使用其試用版。試用版和正式版相比,沒有功能上的限制,只有使用時間的限制。但是到目前為止,Permeo總是會在老版本到期之前推出一個延后了期限的“新”版本,所以用戶實際上可以免費使用。SocksCap32是利用API鉤子,截獲應用軟件對socket函數的調用來實現對SOCKS5客戶端的模擬。盡管SocksCap32很有名,但是由于推出的時間較早,對很多現代應用軟件時常表現的力不從心,所以Permeo又提供了Permeo
Security
Driver(以下稱為PSD)。這款產品使用了驅動技術從底層直接截獲應用軟件的socket通信,因此幾乎可以為所有應用軟件提供SOCKS5客戶端的支持。PSD不提供試用版,但是可以找到其早期版本的注冊碼。
雖然說設計SOCKS協議的初衷是在保證網絡隔離的情況下,提高部分人員的網絡訪問權限,但是國內似乎很少有組織機構這樣使用。一般情況下,大家都會使用更新的網絡安全技術來達到相同的目的。但是由于SocksCap32和PSD這類軟件,人們找到了SOCKS協議新的用途——突破網絡通信限制,這和該協議的初衷實際上正好相反。比如某些網游的部分服務器設置為只接收部分地區的IP地址的連接。為了突破這種限制,可以找一個該地區的SOCKS5代理服務器,然后用PSD接管網游客戶端,通過SOCKS5代理服務器連接游戲服務器。這樣游戲服務器就會認為該客戶端位于本地區,從而允許進行游戲。還有一種情況是:防火墻僅允許部分端口(如http的80端口)通信,那么可以利用SOCKS5協議和一個打開80端口監聽的SOCKS5服務器連接,從而可以連接公網上其他端口的服務器。利用一些額外的技術手段,甚至可以騙過內部的http代理服務器,這時在使用內網http代理上網的環境下也可以不受限制的使用網絡服務,這稱之為SOCKS
over HTTP。通通通([url]www.tongtongtong.com[/url])是老牌SOCKS over
HTTP代理提供商,實現了所有的SOCKS5的連接功能,且有多組國內外服務器。信天游([url]www.xtyproxy.com[/url]),則是最近剛剛出現的代理服務提供商,功能和通通通相比還有差距,但是目前完全免費。當然,使用代理服務器后,將不可避免的出現通信延遲,所以應該盡量選擇同網絡(指網通/
電信),距離近的服務器。
sock5代理的工作程序是:
1.需要向代理方服務器發出請求信息。
2.代理方應答
3.需要代理方接到應答后發送向代理方發送目的ip和端口
4.代理方與目的連接
5.代理方將需要代理方發出的信息傳到目的方,將目的方發出的信息傳到需要代理方。代理完成。
由于網上的信息傳輸都是運用tcp或udp進行的,所以使用socks5代理可以辦到網上所能辦到的一切,而且不輿目的方會查到你的ip,既安全又方
便
sock5支持UDP和TCP,但兩種代理是有區別的,以下分類說明
如何用代理TCP協議
1.向服務器的1080端口建立tcp連接。
2.向服務器發送
05 01 00 (此為16進制碼,以下同)
3.如果接到 05 00 則是可以代理
4.發送 05 01 00 01 + 目的地址(4字節) +
目的端口(2字節),目的地址和端口都是16進制碼(不是字符串!!)。 例202.103.190.27 -7201 則發送的信息為:05 01 00 01 CA
67 BE 1B 1C 21 (CA=202 67=103 BE=190 1B=27
1C21=7201)
5.接受服務器返回的自身地址和端口,連接完成
6.以后操作和直接與目的方進行TCP連接相同。
如何用代理UDP連接
1.向服務器的1080端口建立udp連接
2.向服務器發送
05 01 00
3.如果接到 05 00 則是可以代理
4.發送 05 03 00 01 00 00 00 00 +
本地UDP端口(2字節)
5.服務器返回 05 00 00 01 +服務器地址+端口
6.需要申請方發送 00 00 00 01
+目的地址IP(4字節)+目的端口 +所要發送的信息
7.當有數據報返回時 向需要代理方發出00 00 00 01 +來源地址IP(4字節)+來源端口
+接受的信息
注:此為不需要密碼的代理協議,只是socks5的一部分,完整協議請RFC1928
在linux下開發,mysql數據庫是經常用到的,對于初學者來說,在linux怎么安裝卸載mysql數據庫,也許可能比較痛苦,這里簡單介紹下,怎么卸載msql數據庫。
a)查看系統中是否以rpm包安裝的mysql
- [root@linux ~]# rpm -qa | grep -i mysql
- MySQL-server-5.1.49-1.glibc23
- MySQL-client-5.1.49-1.glibc23
[root@linux ~]# rpm -qa | grep -i mysql
MySQL-server-5.1.49-1.glibc23
MySQL-client-5.1.49-1.glibc23
卸載MySQL-server-5.1.49-1.glibc23和MySQL-client-5.1.49-1.glibc23
- [root@linux ~]# rpm -e MySQL-client-5.1.49-1.glibc23
- [root@linux ~]# rpm -e MySQL-server-5.1.49-1.glibc23
[root@linux ~]# rpm -e MySQL-client-5.1.49-1.glibc23
[root@linux ~]# rpm -e MySQL-server-5.1.49-1.glibc23
b)查看有沒有mysql服務
- [root@linux ~]# chkconfig --list | grep -i mysql
- mysql 0:off 1:off 2:on 3:on 4:on 5:on 6:off
[root@linux ~]# chkconfig --list | grep -i mysql
mysql 0:off 1:off 2:on 3:on 4:on 5:on 6:off
刪除mysql服務
- [root@linux ~]# chkconfig --del mysql
[root@linux ~]# chkconfig --del mysql
c)刪除分散mysql文件夾
- [root@linux ~]# whereis mysql
- mysql: /usr/lib/mysql /usr/share/mysql
[root@linux ~]# whereis mysql
mysql: /usr/lib/mysql /usr/share/mysql
分別刪除
- [root@linux lib]# rm -rf /usr/lib/mysql/
- [root@linux lib]# rm -rf /usr/share/mysql
[root@linux lib]# rm -rf /usr/lib/mysql/
[root@linux lib]# rm -rf /usr/share/mysql
通過以上幾步,mysql應該已經完全卸載干凈了
原文地址:
http://blog.csdn.net/love__coder/article/details/6894566
一、 解析Linux應用軟件安裝包:
通常Linux應用軟件的安裝包有三種:
1) tar包,如software-1.2.3-1.tar.gz。它是使用UNIX系統的打包工具tar打包的。
2) rpm包,如software-1.2.3-1.i386.rpm。它是Redhat Linux提供的一種包封裝格式。
3) dpkg包,如software-1.2.3-1.deb。它是Debain Linux提供的一種包封裝格式。
而且,大多數Linux應用軟件包的命名也有一定的規律,它遵循:
名稱-版本-修正版-類型
例如:
1) software-1.2.3-1.tar.gz 意味著:
軟件名稱:software
版本號:1.2.3
修正版本:1
類型:tar.gz,說明是一個tar包。
2) sfotware-1.2.3-1.i386.rpm
軟件名稱:software
版本號:1.2.3
修正版本:1
可用平臺:i386,適用于Intel 80x86平臺。
類型:rpm,說明是一個rpm包。
注:由于rpm格式的通常是已編譯的程序,所以需指明平臺。在后面會詳細說明。
而software-1.2.3-1.deb就不用再說了吧!大家自己練習一下。
二、 了解包里的內容:
一個Linux應用程序的軟件包中可以包含兩種不同的內容:
1) 一種就是可執行文件,也就是解開包后就可以直接運行的。在Windows中所 有的軟件包都是這種類型。安裝完這個程序后,你就可以使用,但你看不到源程序。而且下載時要注意這個軟件是否是你所使用的平臺,否則將無法正常安裝。
2) 另一種則是源程序,也就解開包后,你還需要使用編譯器將其編譯成為可執行文件。這在Windows系統中是幾乎沒有的,因為Windows的思想是不開放源程序的。
通常,用tar打包的,都是源程序;而用rpm、dpkg打包的則常是可執行程序。一般來說,自己動手編譯源程序能夠更具靈活性,但也容易遇到各種問題和困難。而相對來說,下載那些可執行程序包,反而是更容易完成軟件的安裝,當然那樣靈活性就差多了。所以一般一個軟件總會提供多種打包格式的安裝程序的。你可以根據自己的情況來選擇。
三、 搞定使用tar打包的應用軟件
1. 安裝:
整個安裝過程可以分為以下幾步:
1) 取得應用軟件:通過下載、購買光盤的方法獲得;
2)解壓縮文件:一般tar包,都會再做一次壓縮,如gzip、bz2等,所以你需要先解壓。如果是最常見的gz格式,則可以執行:“tar –xvzf 軟件包名”,就可以一步完成解壓與解包工作。如果不是,則先用解壓軟件,再執行“tar –xvf 解壓后的tar包”進行解包;
3) 閱讀附帶的INSTALL文件、README文件;
4) 執行“./configure”命令為編譯做好準備;
5) 執行“make”命令進行軟件編譯;
6) 執行“make install”完成安裝;
7) 執行“make clean”刪除安裝時產生的臨時文件。
好了,到此大功告成。我們就可以運行應用程序了。但這時,有的讀者就會問,我怎么執行呢?這也是一個Linux特色的問題。其實,一般來說, Linux的應用軟件的可執行文件會存放在/usr/local/bin目錄下!不過這并不是“放四海皆準”的真理,最可靠的還是看這個軟件的 INSTALL和README文件,一般都會有說明。
2. 卸載:
通常軟件的開發者很少考慮到如何卸載自己的軟件,而tar又僅是完成打包的工作,所以并沒有提供良好的卸載方法。
那么是不是說就不能夠卸載呢!其實也不是,有兩個軟件能夠解決這個問題,那就是Kinstall和Kife,它們是tar包安裝、卸載的黃金搭檔。它們的使用方法,筆者會另行文介紹。在此就不加贅述了。
四、 搞定使用rpm打包的應用軟件
rpm可謂是Redhat公司的一大貢獻,它使Linux的軟件安裝工作變得更加簡單容易。
1. 安裝:
我只需簡單的一句話,就可以說完。執行:
rpm –ivh rpm軟件包名
更高級的,請見下表:
rpm參數 參數說明
-i 安裝軟件
-t 測試安裝,不是真的安裝
-p 顯示安裝進度
-f 忽略任何錯誤
-U 升級安裝
-v 檢測套件是否正確安裝
這些參數可以同時采用。更多的內容可以參考RPM的命令幫助。
2. 卸載:
我同樣只需簡單的一句話,就可以說完。執行:
rpm –e 軟件名
不過要注意的是,后面使用的是軟件名,而不是軟件包名。例如,要安裝software-1.2.3-1.i386.rpm這個包時,應執行:
rpm –ivh software-1.2.3-1.i386.rpm
而當卸載時,則應執行:
rpm –e software。
另外,在Linux中還提供了象GnoRPM、kpackage等圖形化的RPM工具,使得整個過程會更加簡單。這些軟件的具體應用,筆者會另行文介紹。
五、 搞定使用deb打包的應用程序
這是Debian Linux提供的一個包管理器,它與RPM十分類似。但由于RPM出現得更早,所以在各種版本的Linux都常見到。而debian的包管理器dpkg則只出現在Debina Linux中,其它Linux版本一般都沒有。我們在此就簡單地說明一下:
1. 安裝
dpkg –i deb軟件包名
如:dpkg –i software-1.2.3-1.deb
2. 卸載
dpkg –e 軟件名
如:dpkg –e software
Linux中find常見用法示例·
find path -option [ -print ] [ -exec -ok command ] {} \; #-print 將查找到的文件輸出到標準輸出
#-exec command {} \; -----將查到的文件執行command操作,{} 和 \;之間有空格
#-ok 和-exec相同,只不過在
操作前要詢用戶 ==================================================== -name filename #查找名為filename的文件
-perm #按執行權限來查找
-user username #按文件屬主來查找
-group groupname #按組來查找
-mtime -n +n #按文件更改時間來查找文件,-n指n天以內,+n指n天以前
-atime -n +n #按文件訪問時間來查GIN: 0px">-perm #按執行權限來查找
-user username #按文件屬主來查找
-group groupname #按組來查找
-mtime -n +n #按文件更改時間來查找文件,-n指n天以內,+n指n天以前
-atime -n +n #按文件訪問時間來查找文件,-n指n天以內,+n指n天以前
-ctime -n +n #按文件創建時間來查找文件,-n指n天以內,+n指n天以前
-nogroup #查無有效屬組的文件,即文件的屬組在/etc/groups中不存在
-nouser #查無有效屬主的文件,即文件的屬主在/etc/passwd中不存
-newer f1 !f2 找文件,-n指n天以內,+n指n天以前
-ctime -n +n #按文件創建時間來查找文件,-n指n天以內,+n指n天以前
-nogroup #查無有效屬組的文件,即文件的屬組在/etc/groups中不存在
-nouser #查無有效屬主的文件,即文件的屬主在/etc/passwd中不存
-newer f1 !f2 #查更改時間比f1新但比f2舊的文件
-type b/d/c/p/l/f #查是塊設備、目錄、字符設備、管道、符號鏈接、普通文件-size n[c] #查長度為n塊[或n字節]的文件
-depth #使查找在進入子目錄前先行查找完本目錄
-fstype #查更改時間比f1新但比f2舊的文件
-mount #查文件時不跨越文件
系統mount點
-follow #如果遇到符號鏈接文件,就跟蹤鏈接所指的文件
-cpio #對匹配的文件使用cpio命令,將他們備份到磁帶設備中
-prune #忽略某個目錄 ====================================================
$find ~ -name "*.txt" -print #在$HOME中查.txt文件并顯示
$find . -name "*.txt" -print $find . -name "[A-Z]*" -pri26nbsp; #對匹配的文件使用cpio命令,將他們備份到磁帶設備中
-prune #忽略某個目錄 $find . -name "[A-Z]*" -print #查以大寫字母開頭的文件
$find /etc -name "host*" -print #查以host開頭的文件
$find . -name "[a-z][a-z][0--9][0--9].txt" -print #查以兩個小寫字母和兩個數字開頭的txt文件
$find . -perm 755 -print
$find . -perm -007 -exec ls -l {} \; #查所有用戶都可讀寫執行的文件同-perm 777
$find . -type d -print 打印目錄結構
$find .
! -type d -print
打印非目錄文件find /usr/include -name '*.h' -exec grep AF_INEF6 {} \; 因grep無法遞歸搜索子目錄,故可以和find相結合使用。 在/usr/include 所有子目錄中的.h文件中找字串AF_INEF6
$find . -type l -print $find . -size +1000000c -print #查長度大于1Mb的文件
$find . -size 100c -print # 查長度為100c的文件
$find . -size +10 -print #查長度超過期作廢10塊的文件(1塊=512字節) $cd /
$find etc home apps -depth -print | cpio -ivcdC65536 -o /dev/rmt0
$find /etc -name "passwd*" -exec grep "cnscn" {} \; #看是否存在cnscn用戶
$find . -name "yao*" | xargs file
$find . -name "yao*" | xargs echo "" > /tmp/core.log
$find . -name "yao*" | xargs chmod o-w ====================================================== find -name april* 在當前目錄下查找以april開始的文件
find -name april* fprint file 在當前目錄下查找以april開始的文件,并把結果輸出到file中
find -name ap* -o -name may* 查找以ap或may開頭的文件
find /mnt -name tom.txt -ftype vfat 在/mnt下查找名稱為tom.txt且文件
系統類型為vfat的文件
find /mnt -name t.txt ! -ftype vfat 在/mnt下查找名稱為tom.txt且文件
系統類型不為vfat的文件
find /tmp -name wa* -type l 在/tmp下查找名為wa開頭且類型為符號鏈接的文件
find /home -mtime -2 在/home下查最近兩天內改動過的文件
find /home -atime -1 查1天之內被存取過的文件
find /home -mmin +60 在/home下查60分鐘前改動過的文件
find /home -amin +30 查最近30分鐘前被存取過的文件
find /home -newer tmp.txt 在/home下查更新時間比tmp.txt近的文件或目錄
find /home -anewer tmp.txt 在/home下查存取時間比tmp.txt近的文件或目錄
find /home -used -2 列出文件或目錄被改動過之后,在2日內被存取過的文件或目錄
find /home -user cnscn 列出/home目錄內屬于用戶cnscn的文件或目錄
find /home -uid +501 列出/home目錄內用戶的識別碼大于501的文件或目錄
find /home -group cnscn 列出/home內組為cnscn的文件或目錄
find /home -gid 501 列出/home內組id為501的文件或目錄
find /home -nouser 列出/home內不屬于本地用戶的文件或目錄
find /home -nogroup 列出/home內不屬于本地組的文件或目錄
find /home -name tmp.txt -maxdepth 4 列出/home內的tmp.txt 查時深度最多為3層
find /home -name tmp.txt -mindepth 3 從第2層開始查
find /home -empty 查找大小為0的文件或空目錄
find /home -size +512k 查大于512k的文件
find /home -size -512k 查小于512k的文件
find /home -links +2 查硬連接數大于2的文件或目錄
find /home -perm 0700 查權限為700的文件或目錄
find /tmp -name tmp.txt -exec cat {} \;
find /tmp -name tmp.txt -ok rm {} \; find / -amin -10 # 查找在
系統中最后10分鐘訪問的文件
find / -atime -2 # 查找在
系統中最后48小時訪問的文件
find / -empty # 查找在
系統中為空的文件或者文件夾
find / -group cat # 查找在
系統中屬于 groupcat的文件
find / -mmin -5 # 查找在
系統中最后5分鐘里修改過的文件
find / -mtime -1 #查找在
系統中最后24小時里修改過的文件
find / -nouser #查找在
系統中屬于作廢用戶的文件
find / -user fred #查找在
系統中屬于FRED這個用戶的文件
查當前目錄下的所有普通文件
--------------------------------------------------------------------------------
# find . -type f -exec ls -l {} \;-rw-r--r-- 1 root root 34928 2003-02-25 ./conf/httpd.conf
-rw-r--r-- 1 root root 12959 2003-02-25 ./conf/magic
-rw-r--r-- 1 root root 180 2003-02-25 ./conf.d/README
查當前目錄下的所有普通文件,并在- e x e c選項中使用ls -l命令將它們列出
=================================================
在/ l o g s目錄中查找更改時間在5日以前的文件并刪除它們:
$ find logs -type f -mtime +5 -exec -ok rm {} \;
=================================================
查詢當天修改過的文件
[root@book class]# find ./ -mtime -1 -type f -exec ls -l {} \;
=================================================
查詢文件并詢問是否要顯示
[root@book class]# find ./ -mtime -1 -type f -ok ls -l {} \;
< ls ... ./classDB.inc.php > ? y
-rw-r--r-- 1 cnscn cnscn 13709 1月 12 12:22 ./classDB.inc.php
[root@book class]# find ./ -mtime -1 -type f -ok ls -l {} \;
< ls ... ./classDB.inc.php > ? n
[root@book class]# =================================================
查詢并交給awk去處理
[root@book class]# who | awk '{print $1"\t"$2}'
cnscn pts/0 =================================================
awk---grep---sed [root@book class]# df -k | awk '{print $1}' | grep -v 'none' | sed s"/\/dev\///g"
文件
系統sda2
sda1
[root@book class]# df -k | awk '{print $1}' | grep -v 'none'
文件
系統/dev/sda2
/dev/sda1
1)在/tmp中查找所有的*.h,并在這些文件中查找“SYSCALL_VECTOR",最后打印出所有包含"SYSCALL_VECTOR"的文件名 A) find /tmp -name "*.h" | xargs -n50 grep SYSCALL_VECTOR
B) grep SYSCALL_VECTOR /tmp/*.h | cut -d':' -f1| uniq > filename
C) find /tmp -name "*.h" -exec grep "SYSCALL_VECTOR" {} \; -print
2)find / -name filename -exec rm -rf {} \;
find / -name filename -ok rm -rf {} \;
3)比如要查找磁盤中大于3M的文件:
find . -size +3000k -exec ls -ld {} ;
4)將find出來的東西拷到另一個地方
find *.c -exec cp '{}' /tmp ';' 如果有特殊文件,可以用cpio,也可以用這樣的語法:
find dir -name filename -print | cpio -pdv newdir
6)查找2004-11-30 16:36:37時更改過的文件
# A=`find ./ -name "*php"` | ls -l --full-time $A 2>/dev/null | grep "2004-11-30 16:36:37
二、linux下find命令的用法
1. 基本用法:
find / -name 文件名
find ver1.d ver2.d -name '*.c' -print 查找ver1.d,ver2.d *.c文件并打印 find . -type d -print 從當前目錄查找,僅查找目錄,找到后,打印路徑名。可用于打印目錄結構。
2. 無錯誤查找:
find / -name access_log 2 >/dev/null
3. 按尺寸查找:
find / -size 1500c (查找1,500字節大小的文件,c表示字節)
find / -size +1500c (查找大于1,500字節大小的文件,+表示大于)
find / -size +1500c (查找小于1,500字節大小的文件,-表示小于)
4. 按時間:
find / -amin n 最后n分鐘
find / -atime n 最后n天
find / -cmin n 最后n分鐘改變狀態
find / -ctime n 最后n天改變狀態
5. 其它:
find / -empty 空白文件、空白文件夾、沒有子目錄的文件夾
find / -false 查找
系統中總是錯誤的文件
find / -fstype type 找存在于指定文件
系統的文件,如type為ext2
find / -gid n 組id為n的文件
find / -group gname 組名為gname的文件
find / -depth n 在某層指定目錄中優先查找文件內容
find / -maxdepth levels 在某個層次目錄中按遞減方式查找
6. 邏輯
-and 條件與 -or 條件或
7. 查找字符串
find . -name '*.html' -exec grep 'mailto:'{}
ln是linux中又一個非常重要命令,它的功能是為某一個文件在另外一個位置建立一個同不的鏈接,這個命令最常用的參數是-s,具體用法是:ln –s 源文件 目標文件。
當我們需要在不同的目錄,用到相同的文件時,我們不需要在每一個需要的目錄下都放一個必須相同的文件,我們只要在某個固定的目錄,放上該文件,然后在 其它的目錄下用ln命令鏈接(link)它就可以,不必重復的占用磁盤空間。例如:ln –s /bin/less /usr/local/bin/less
-s 是代號(symbolic)的意思。
這里有兩點要注意:第一,ln命令會保持每一處鏈接文件的同步性,也就是說,不論你改動了哪一處,其它的文件都會發生相同的變化;第二,ln的鏈接又 軟鏈接和硬鏈接兩種,軟鏈接就是ln –s ** **,它只會在你選定的位置上生成一個文件的鏡像,不會占用磁盤空間,硬鏈接ln ** **,沒有參數-s, 它會在你選定的位置上生成一個和源文件大小相同的文件,無論是軟鏈接還是硬鏈接,文件都保持同步變化。
如果你用ls察看一個目錄時,發現有的文件后面有一個@的符號,那就是一個用ln命令生成的文件,用ls –l命令去察看,就可以看到顯示的link的路徑了。
指令詳細說明
指令名稱 : ln
使用權限 : 所有使用者
使用方式 : ln [options] source dist,其中 option 的格式為 :
[-bdfinsvF] [-S backup-suffix] [-V {numbered,existing,simple}]
[--help] [--version] [--]
說明 : Linux/Unix 檔案系統中,有所謂的連結(link),我們可以將其視為檔案的別名,而連結又可分為兩種 : 硬連結(hard link)與軟連結(symbolic link),硬連結的意思是一個檔案可以有多個名稱,而軟連結的方式則是產生一個特殊的檔案,該檔案的內容是指向另一個檔案的位置。硬連結是存在同一個檔 案系統中,而軟連結卻可以跨越不同的檔案系統。
ln source dist 是產生一個連結(dist)到 source,至于使用硬連結或軟鏈結則由參數決定。
不論是硬連結或軟鏈結都不會將原本的檔案復制一份,只會占用非常少量的磁碟空間。
-f : 鏈結時先將與 dist 同檔名的檔案刪除
-d : 允許系統管理者硬鏈結自己的目錄
-i : 在刪除與 dist 同檔名的檔案時先進行詢問
-n : 在進行軟連結時,將 dist 視為一般的檔案
-s : 進行軟鏈結(symbolic link)
-v : 在連結之前顯示其檔名
-b : 將在鏈結時會被覆寫或刪除的檔案進行備份
-S SUFFIX : 將備份的檔案都加上 SUFFIX 的字尾
-V METHOD : 指定備份的方式
--help : 顯示輔助說明
--version : 顯示版本
范例 :
將檔案 yy 產生一個 symbolic link : zz
ln -s yy zz
將檔案 yy 產生一個 hard link : zz
ln yy xx
1.Linux的變量種類
按變量的生存周期來劃分,Linux變量可分為兩類:
1.1 永久的:需要修改配置文件,變量永久生效。
1.2 臨時的:使用export命令聲明即可,變量在關閉shell時失效。
Linux 的變量可分為兩類:環境變量和本地變量
環境變量,或者稱為全局變量,存在與所有的shell 中,在你登陸系統的時候就已經有了相應的系統定義的環境變量了。Linux 的環境變量具有繼承性,即子shell 會繼承父shell 的環境變量。
本地變量,當前shell 中的變量,很顯然本地變量中肯定包含環境變量。Linux 的本地變量的非環境變量不具備繼承性。
Linux 中環境變量的文件
當你進入系統的時候,linux 就會為你讀入系統的環境變量,這些環境變量存放在什么地方,那就是環境變量的文件中。Linux 中有很多記載環境變量的文件,它們被系統讀入是按照一定的順序的。
1. /etc/profile :
此文件為系統的環境變量,它為每個用戶設置環境信息,當用戶第一次登錄時,該文件被執行。
2.設置變量的三種方法
2.1 在/etc/profile文件中添加變量【對所有用戶生效(永久的)】
用VI在文件/etc/profile文件中增加變量,該變量將會對Linux下所有用戶有效,并且是“永久的”。
例如:編輯/etc/profile文件,添加CLASSPATH變量
# vi /etc/profile
export CLASSPATH=./JAVA_HOME/lib;$JAVA_HOME/jre/lib
注:修改文件后要想馬上生效還要運行# source /etc/profile不然只能在下次重進此用戶時生效。
2.2 在用戶目錄下的.bash_profile文件中增加變量【對單一用戶生效(永久的)】
用VI在用戶目錄下的.bash_profile文件中增加變量,改變量僅會對當前用戶有效,并且是“永久的”。
例如:編輯guok用戶目錄(/home/guok)下的.bash_profile
$ vi /home/guok/.bash.profile
添加如下內容:
export CLASSPATH=./JAVA_HOME/lib;$JAVA_HOME/jre/lib
注:修改文件后要想馬上生效還要運行$ source /home/guok/.bash_profile不然只能在下次重進此用戶時生效。
2.3 直接運行export命令定義變量【只對當前shell(BASH)有效(臨時的)】
在shell的命令行下直接使用[export 變量名=變量值]
定義變量,該變量只在當前的shell(BASH)或其子shell(BASH)下是有效的,shell關閉了,變量也就失效了,再打開新shell時就沒有這個變量,需要使用的話還需要重新定義。
3.環境變量的查看
3.1 使用echo命令查看單個環境變量。例如:
echo $PATH
3.2 使用env查看所有環境變量。例如:
env
3.3 使用set查看所有本地定義的環境變量。
unset可以刪除指定的環境變量。
4.常用的環境變量
PATH 決定了shell將到哪些目錄中尋找命令或程序
HOME 當前用戶主目錄
HISTSIZE 歷史記錄數
LOGNAME 當前用戶的登錄名
HOSTNAME 指主機的名稱
SHELL 當前用戶Shell類型
LANGUGE 語言相關的環境變量,多語言可以修改此環境變量
MAIL 當前用戶的郵件存放目錄
PS1 基本提示符,對于root用戶是#,對于普通用戶是$
指令名稱 : chmod
使用權限 : 所有使用者
使用方式 : chmod [-cfvR] [--help] [--version] mode file...
說明 : Linux/Unix 的檔案存取權限分為三級 : 檔案擁有者、群組、其他。利用 chmod 可以控制檔案如何被他人所存取。
只能文件屬主或特權用戶才能使用該功能來改變文件存取模式。mode可以是數字形式或以who opcode permission形式表示。who是可選的,默認是a(所有用戶)。只能選擇一個opcode(操作碼)。可指定多個mode,以逗號分開。
options:
-c,--changes
只輸出被改變文件的信息
-f,--silent,--quiet
當chmod不能改變文件模式時,不通知文件的用戶
--help
輸出幫助信息。
-R,--recursive
可遞歸遍歷子目錄,把修改應到目錄下所有文件和子目錄
--reference=filename
參照filename的權限來設置權限
-v,--verbose
無論修改是否成功,輸出每個文件的信息
--version
輸出版本信息。
who
u
用戶
g
組
o
其它
a
所有用戶(默認)
opcode
+
增加權限
-
刪除權限
=
重新分配權限
permission
r
讀
w
寫
x
執行
s
設置用戶(或組)的ID號
t
設置粘著位(sticky bit),防止文件或目錄被非屬主刪除
u
用戶的當前權限
g
組的當前權限
o
其他用戶的當前權限
作為選擇,我們多數用三位八進制數字的形式來表示權限,第一位指定屬主的權限,第二位指定組權限,第三位指定其他用戶的權限,每位通過4(讀)、2(寫)、1(執行)三種數值的和來確定權限。如6(4+2)代表有讀寫權,7(4+2+1)有讀、寫和執行的權限。
還可設置第四位,它位于三位權限序列的前面,第四位數字取值是4,2,1,代表意思如下:
4,執行時設置用戶ID,用于授權給基于文件屬主的進程,而不是給創建此進程的用戶。
2,執行時設置用戶組ID,用于授權給基于文件所在組的進程,而不是基于創建此進程的用戶。
1,設置粘著位。
實例:
$ chmod u+x file 給file的屬主增加執行權限
$ chmod 751 file 給file的屬主分配讀、寫、執行(7)的權限,給file的所在組分配讀、執行(5)的權限,給其他用戶分配執行(1)的權限
$ chmod u=rwx,g=rx,o=x file 上例的另一種形式
$ chmod =r file 為所有用戶分配讀權限
$ chmod 444 file 同上例
$ chmod a-wx,a+r file 同上例
$ chmod -R u+r directory 遞歸地給directory目錄下所有文件和子目錄的屬主分配讀的權限
$ chmod 4755 設置用ID,給屬主分配讀、寫和執行權限,給組和其他用戶分配讀、執行的權限。
指令名稱 : chown
使用權限 : root
使用方式 : chown[-cfhvR] [--help] [--version] user[:group] file...
說明 : Linux/Unix 是多人多工作業系統,所有的檔案皆有擁有者。利用 chown 可以將檔案的擁有者加以改變。一般來說,這個指令只有是由系統管理者(root)所使用,一般使用者沒有權限可以改變別人的檔案擁有者,也沒有權限可以自己的檔案擁有者改設為別人。只有系統管理者(root)才有這樣的權限。
基于spring開發了個自定義標簽,功能測試正常,在myeclipse中提示編譯錯誤:
Multiple annotations found at this line:
- cvc-complex-type.2.4.c: The matching wildcard is strict, but no declaration can be found for element 'fw:annotation-handler'.
- schema_reference.4: Failed to read schema document 'http://www.300.cn/schema/annotation-handler.xsd', because 1) could not find the
document; 2) the document could not be read; 3) the root element of the document is not <xsd:schema>.
這個問題在以前改動struts配置文件的時候也出現過。在引入一些第三方jar容易出現這個問題。
雖然不影響使用,但是看著挺討厭的,找了一下解決方法。
菜單-->windows-->prefreneces 找到XML Catalog,在User Specified Entries添加xsd文件
有兩個地方要注意:
1.Key type設置為Schema location;
2.key 設置虛擬xsd地址,即
xsi:schemaLocation=" http://www.springframework.org/schema/task
http://www.springframework.org/schema/task/spring-task-3.0.xsd“
名稱對后邊的這一個。
自從搬到東邊住以后就很少去海淀圖書城了,因為想參加11月的軟考,端午去海圖找本考試大綱。
前幾年去海圖的時候,java方面的圖書都放在最顯眼的地方,能占好幾排書架,現在已經被andriod、ios取代。找了一圈才在一個不起眼的角落找到java系列圖書。c/c++這樣的書倒不見減少,比印象中還有增加。
從書市上看java最風光的時候已經過去了,一直做java方面的開發,對這方面的變化不敏感,還是賣書的對市場感受更直接。
各領風騷好幾年。
這幾天抽空看了本《問題分析與決策》,蘭德公司出版的,就是那個預言中國將出兵朝鮮的公司。挺好的一本書,不知道為什么中文版的特別少,找了半天。
老外做研究的風格,很少那種大而無當的空話,對問題分析的過程和分析者的心理活動做了大量研究工作。
我做過一段時間的系統分析工作,書中有些觀點讓人看起來心有戚戚焉,還有部分觀點是自己沒想到的,讀后很是能解惑。
做些簡單摘錄
很多人采用的處理問題與決策的辦法,根本沒有多大用處,甚至完全沒有用處。
引言蘭德提出這種問題分析方法的思路,從一個公司的某一個問題著手,追溯到解決這一問題的程序,仔細剖視每一步驟中的思想過程。
根據這些研究得出了很多概念和方法,認為問題分析與決策時管理上的行為,必須自覺和有系統的去做。
而且必要的話,還應該記錄下來。
分析問題是一項依照邏輯體系而進行的程序,首先是確定問題,然后是經過分析以及尋求原因,最后做決定。
每個階段包括若干基本的概念,其中一項基本概念是,一個問題乃是一件事“應該怎么樣”和“事實上是怎么樣的”兩者之間的偏差。
另一項概念是,這種偏差是由于某一種“變化”二造成的。除非先把這一變化準確的予以確定,否則一切糾正這一偏差的措施都只是揣測而已。
概念與方法
問題分析的兩個主要概念:
1.每個問題都是標準的預期效果所發生的偏差;
2.某種變化是造成這一問題的根本原因。
分析問題的七項基本概念
1.有標準;
2.問題就是情況與標準之間的偏差
3.偏差要準確的認定
4.分析問題的獨特性,受影響和沒受影響部分各有什么特點,區分開來;
5.只考慮與特殊變化有關的情況,通過界定問題范圍找出原因。
6.造成偏差的原因是從分析問題時發現的變化中推導出來的 。
7.最可能造成偏差的原因,是能解釋界定范圍內一切事實的那一項原因。
如何界定一個問題1.什么;2時間;3.地點4.幅度
如何尋求特點與變化
任何問題發生的原因,乃是一種變化;這種變化的影響是有限度的,只在某些地方有影響,在其他地方沒有影響。
這種變化,只存在于特定的范圍之內,或者只發生與那些可以區分出問題的“是”的一面某些因素上。
因此,要追究什么樣的變化會發生某一種影響,最有效的方法是只尋求那些僅存在于界定問題時所發現的各項特點的變化。
我們要找出來把事物區分開來的因素,分析問題的人必須從事物的不同點去思考。
(么東西出了問題,不是什么出了問題,減小范圍)
發生變化的線索就在,區分“是”與“不是”的特點中。
能看出特點與變化的能力是智慧的主要表現之一,在問題分析上是非常重要的。
一個問題的形成可能受許多因素的影響,但是真正動搖了事態均衡而引發問題的卻只有一種變化。
事先不界定問題和研求特點,一發現某項變化立即斷定這就是問題的原因所在是很危險的。
決策分析1.訂立決策的目標;
2.依據重要性將目標分類;
3.擬定可供選擇的措施;
4.把各種可行的辦法與目標加以對照衡量;
5.選擇最好的辦法作為暫時決策;
6.研究決策是否會有不良影響;
7.同時采取防止不良后果的措施。
之前做過一版工作流引擎,自己開發的。這段時間又以jbpm為內核做了一版流程系統,有些思考就記錄下來。
有一句話說的好,如果你手里有一把錘子你就看什么都像釘子。做流程系統的時候也遇到這類現象,因為對流程系統的不熟悉,在開發過程中就想到處都用工作流來處理問題。
其實引入一個新的東西,一定要先搞明白的它的適用場景,有什么價值。把握了這點后結合具體場景,就能很好的使用,而不會亂用。
一、工作流適用場景
以下兩種情況需要引入流程系統
1.分散系統整合(企業應用集成)
2.簡化業務系統的開發;
工作流的價值
1.業務流程獨立化;
2.優化改進流程更容易;
3.提供統一的監控頁面。
Ⅰ 、相對于分散系統,提供了統一的操作和監控頁面。對用戶更友好,過程可監控,業務規則更明確。
1.業務流程獨立化,業務規則不僅僅存在與工作人員的頭腦中。
2.提供了統一的監控界面,實現業務過程可監控;
3.有明確的規則,可以監控運行情況,為流程的優化提供了便利;
4.對用戶更友好;
Ⅱ 、相對于傳統業務系統方式
1.業務流程獨立化,業務規則不會淹沒于業務系統代碼中。避免業務系統開發完成后再次改動成本高的情況。
2.提供了統一的監控界面,實現業務過程可監控;原業務系統提供的報表對環節執行時間可能信息不足,一般只是簡單反應狀態變化。
3.有明確的規則,可以監控運行情況,為流程的優化提供了便利;
4.對于工作人員來講,這些改進其實是透明的,從用戶體驗的角度沒有什么變化。
所以對原業務系統的用戶來講,變化不大。引入流程系統更多的是為了監控和優化流程的方便,是從管理的角度考慮問題。
從流程系統提供的待辦事項列表進行操作,還是從業務系統的功能菜單進行操作,哪個更友好是UE設計的問題,跟流程系統無關。
業務系統功能菜單的劃分可能相對于待辦事項列表更直觀、定位更準確。(見下圖紅色箭頭對兩種方式的表示)
考慮到業務流程的復雜性,對于企業信息化系統引入流程系統可以便于優化流程,對于成熟的業務系統如財務軟件引入流程系統完全沒有必要。
補充說明:
1.當前任務列表方式,需要用戶不停的查看有沒有新任務到來;優點是在一個頁面可以看到全部待辦事項。
2.業務系統功能菜單方式,需要用戶不停的查詢工作進展并作出處理。優點是任務類型劃分更明確;
二、業務系統接入方式
1.在jsp頁面增加環節信息(環節編號,流程編號...);
2.業務系統aciton不變;
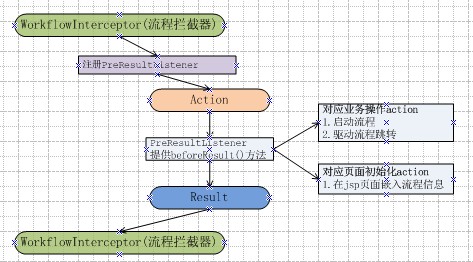
3.在業務系統action完成操作后,流程攔截器處理流程變化并記錄到數據庫;
4.流程監控頁面和待辦事項列表,不斷從流程數據庫查詢。
5.對于專業性比價強的的狀態值還是在業務系統維護,避免流程系統壓力過大。在需要監控改進的業務點交由流程系統調度,其它部分還是由業務系統處理。
.jpg) --------------------------------------
--------------------------------------
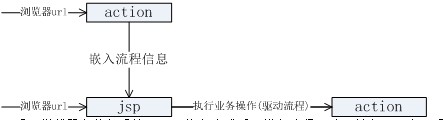
下邊是對struts項目接入流程系統的一個分析
1.業務系統jsp,action調用關系
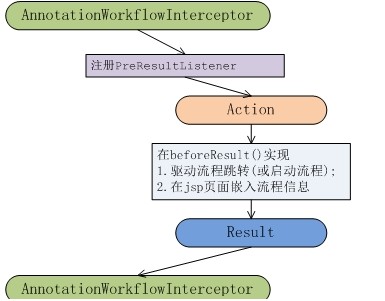
2.采用攔截器在業務系統action執行完成后,進行流程驅動,并在下一個jsp頁面注入流程信息。
主要邏輯都在beforeResult()方法中。3.數據結構
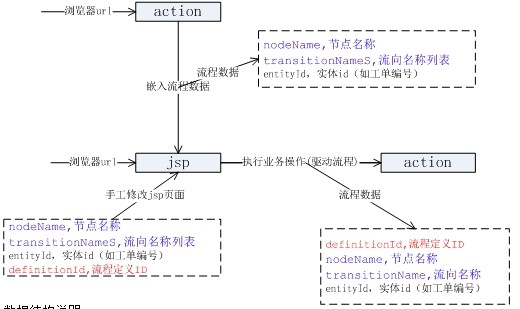
數據結構說明:
1.對于通用的流程數據可以在beforeResult()方法自動嵌入,為考慮交互效果在jsp自行設置流程信息;
2.jsp頁面流程數據應該包括:
1.nodeName
節點名稱,環節在流程定義中的名稱;
2.transitionNames
流向名稱列表,需要作出選擇的列表。
3.entityId
實體id,用于查詢流程實例ID。
3.在action執行完成后驅動流程所需要的數據:
1.definitionId
流程定義,說明是新啟動一個流程。
2.nodeName
節點名稱,根據流程實例ID和節點名稱查詢任務ID,每個節點只能是單任務的,否則jsp頁面無法提供taskId.
3.transitionName
流向名稱,根據流向選擇流程下一步跳轉的節點。串行節點不用transitionName 可為空。
4.entityId
實體id,查詢流程實例ID用。
4.對與工作流無關的action實行過濾,不做處理。
兩種過濾方式:
1.在action方法加注解;
2.在數據結構中增加數據項標記。
5.對與工作流無關的jsp頁面,不使用工作流tag即可。
-----------------------------
上邊是我一開始的想法,后來和同事討論后又做了些調整。編輯web文字比較麻煩,就不合在一起了。
1.對執行業務操作的action和進入jsp頁面的初始化action進行分類;
2.參數傳遞過程補充說明
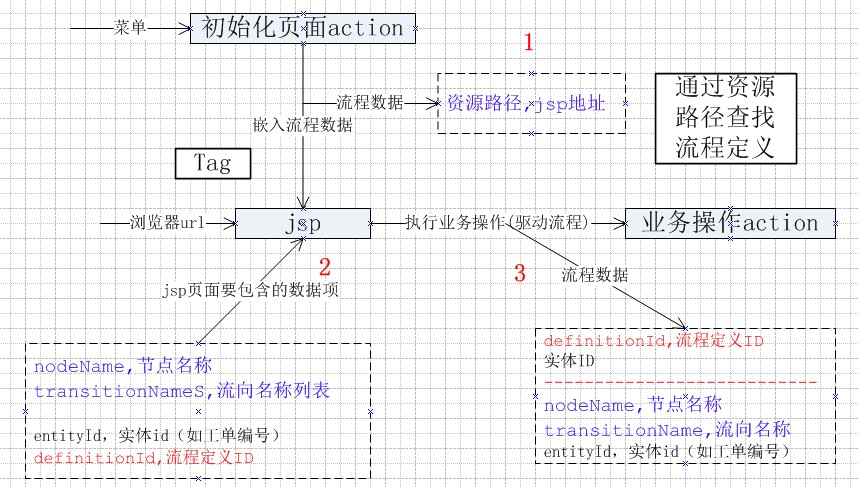
一個分為三步
倒著說
第三步,功能頁面jsp在提交參數時需附加(節點名稱、流向名稱、工單編號),流程引擎才能驅動流程;
第二步,要能夠向第三步提供數據,jsp頁面必須包含(節點名稱、流向名稱列表、工單編號),這些數據有兩個來源:1.收到在jsp頁面寫入;2.從第一步接收。
第一步,有同事建議,提供節點和資源路徑的關系表,通過資源路徑查找節點名稱。減少流程系統對業務系統的侵入。
----------------------------------
上傳的時候圖片丟了,重新補一下。
今天抽空整理些有關rest方面的理論。主要參考了幾篇網上的文章,做了些整理,原文見附錄。
一、起源
越來越多的人開始意識到,網站即軟件,而且是一種新型的軟件。
這種"互聯網軟件"采用客戶端/服務器模式,建立在分布式體系上,通過互聯網通信,具有高延時(high latency)、高并發等特點。
網站開發,完全可以采用軟件開發的模式。但是傳統上,軟件和網絡是兩個不同的領域,很少有交集;軟件開發主要針對單機環境,網絡則主要研究系統之間的通信。互聯網的興起,使得這兩個領域開始融合,現在我們必須考慮,如何開發在互聯網環境中使用的軟件。
RESTful架構,就是一種互聯網軟件架構。它結構清晰、符合標準、易于理解、擴展方便,所以正得到越來越多網站的采用。
二、名稱
Fielding將他對互聯網軟件的架構原則,定名為REST,即Representational State Transfer的縮寫。我對這個詞組的翻譯是"表現層狀態轉化"。
如果一個架構符合REST原則,就稱它為RESTful架構。
要理解RESTful架構,最好的方法就是去理解Representational State Transfer這個詞組到底是什么意思,它的每一個詞代表了什么涵義。如果你把這個名稱搞懂了,也就不難體會REST是一種什么樣的設計。
三、資源(Resources)
REST的名稱"表現層狀態轉化"中,省略了主語。"表現層"其實指的是"資源"(Resources)的"表現層"。
所謂"資源",就是網絡上的一個實體,或者說是網絡上的一個具體信息。它可以是一段文本、一張圖片、一首歌曲、一種服務,總之就是一個具體的實在。你可以用一個URI(統一資源定位符)指向它,每種資源對應一個特定的URI。要獲取這個資源,訪問它的URI就可以,因此URI就成了每一個資源的地址或獨一無二的識別符。
所謂"上網",就是與互聯網上一系列的"資源"互動,調用它的URI。
四、表現層(Representation)
"資源"是一種信息實體,它可以有多種外在表現形式。我們把"資源"具體呈現出來的形式,叫做它的"表現層"(Representation)。
比如,文本可以用txt格式表現,也可以用HTML格式、XML格式、JSON格式表現,甚至可以采用二進制格式;圖片可以用JPG格式表現,也可以用PNG格式表現。
URI只代表資源的實體,不代表它的形式。嚴格地說,有些網址最后的".html"后綴名是不必要的,因為這個后綴名表示格式,屬于"表現層"范疇,而URI應該只代表"資源"的位置。它的具體表現形式,應該在HTTP請求的頭信息中用Accept和Content-Type字段指定,這兩個字段才是對"表現層"的描述。
五、狀態轉化(State Transfer)
訪問一個網站,就代表了客戶端和服務器的一個互動過程。在這個過程中,勢必涉及到數據和狀態的變化。
互聯網通信協議HTTP協議,是一個無狀態協議。這意味著,所有的狀態都保存在服務器端。因此,如果客戶端想要操作服務器,必須通過某種手段,讓服務器端發生"狀態轉化"(State Transfer)。而這種轉化是建立在表現層之上的,所以就是"表現層狀態轉化"。
客戶端用到的手段,只能是HTTP協議。具體來說,就是HTTP協議里面,四個表示操作方式的動詞:GET、POST、PUT、DELETE。它們分別對應四種基本操作:GET用來獲取資源,POST用來新建資源(也可以用于更新資源),PUT用來更新資源,DELETE用來刪除資源。
六、綜述
綜合上面的解釋,我們總結一下什么是RESTful架構:
(1)每一個URI代表一種資源;
(2)客戶端和服務器之間,傳遞這種資源的某種表現層;
(3)客戶端通過四個HTTP動詞,對服務器端資源進行操作,實現"表現層狀態轉化"。
REST關鍵原則
一個簡單扼要的定義:REST定義了應該如何正確地使用Web標準,例如HTTP和URI。如果你在設計應用程序時能堅持REST原則,那就預示著你將會得到一個使用了優質Web架構(這將讓你受益)的系統。總之,五條關鍵原則列舉如下:
- 為所有“事物”定義ID
- 將所有事物鏈接在一起
- 使用標準方法
- 資源多重表述
- 無狀態通信
為所有“事物”定義ID
在這里我使用了“事物”來代替更正式準確的術語“資源”,因為一條如此簡單的原則,不應該被淹沒在術語當中。思考一下人們構建的系統,通常會找到一系列值得被標識的關鍵抽象。每個事物都應該是可標識的,都應該擁有一個明顯的ID——在Web中,代表ID的統一概念是:URI。URI構成了一個全局命名空間,使用URI標識你的關鍵資源意味著它們獲得了一個唯一、全局的ID。
值得被URI標識的事物——資源——要比數據庫記錄抽象的多。標識所有值得標識的事物,領會這個觀念可以進一步引導你創造出在傳統的應用程序設計中不常見的資源:一個流程或者流程步驟、一次銷售、一次談判、一份報價請求——這都是應該被標識的事物的示例。
將所有事物鏈接在一起
接下來要討論的原則有一個有點令人害怕的正式描述:“超媒體被當作應用狀態引擎(Hypermedia as the engine of application state)”,有時簡寫為HATEOAS。(嚴格地說,這不是我說的。)這個描述的核心是超媒體概念,換句話說:是鏈接的思想。鏈接是我們在HTML中常見的概念,但是它的用處絕不局限于此(用于人們網絡瀏覽)。
使用標準方法
在前兩個原則的討論中暗含著一個假設:接收URI的應用程序可以通過URI明確地做一些有意義的事情。如果你在公共汽車上看到一個URI,你可以將它輸入瀏覽器的地址欄中并回車——但是你的瀏覽器如何知道需要對這個URI做些什么呢?
它知道如何去處理URI的原因在于所有的資源都支持同樣的接口,一套同樣的方法(只要你樂意,也可以稱為操作)集合。在HTTP中這被叫做動詞(verb),除了兩個大家熟知的(GET和POST)之外,標準方法集合中還包含PUT、DELETE、HEAD和OPTIONS。這些方法的含義連同行為許諾都一起定義在HTTP規范之中。
資源多重表述
在實踐中,資源多重表述還有著其它重要的好處:如果你為你的資源提供HTML和XML兩種表述方式,那這些資源不僅可以被你的應用所用,還可以被任意標準Web瀏覽器所用——也就是說,你的應用信息可以被所有會使用Web的人獲取到。
無狀態通信
首先,需要著重強調的是,雖然REST包含無狀態性(statelessness)的觀念,但這并不是說暴露功能的應用不能有狀態——
事實上,在大部分情況下這會導致整個做法沒有任何用處。REST要求狀態要么被放入資源狀態中,要么保存在客戶端上。
或者換句話說,服務器端不能保持除了單次請求之外的,任何與其通信的客戶端的通信狀態。這樣做的最直接的理由就是可伸縮性—— 如果服務器需要保持客戶端狀態,那么大量的客戶端交互會嚴重影響服務器的內存可用空間(footprint)。(注意,要做到無狀態通信往往需要需要一些重新設計——不能簡單地將一些session狀態綁縛在URI上,然后就宣稱這個應用是RESTful。)
但除此以外,其它方面可能顯得更為重要:無狀態約束使服務器的變化對客戶端是不可見的,因為在兩次連續的請求中,客戶端并不依賴于同一臺服務器。一個客戶端從某臺服務器上收到一份包含鏈接的文檔,當它要做一些處理時,這臺服務器宕掉了,可能是硬盤壞掉而被拿去修理,可能是軟件需要升級重啟——如果這個客戶端訪問了從這臺服務器接收的鏈接,它不會察覺到后臺的服務器已經改變了。
REST風格的一個“化身”便是HTTP(以及一套相關的一套標準,比如URI)。
附錄:
1.深入淺出REST
http://www.infoq.com/cn/articles/rest-introduction2.理解Restful 架構
http://www.ruanyifeng.com/blog/2011/09/restful.html3.Rest和soap比較
http://www.infoq.com/cn/articles/rest-soap-when-to-use-each4.Rest和Rpc比較
http://xinklabi.iteye.com/blog/807220
定時程序時間格式,原文見http://blog.csdn.net/remote_roamer/article/details/6573173
一個cron表達式有至少6個(也可能7個)有空格分隔的時間元素。
按順序依次為
秒(0~59)
分鐘(0~59)
小時(0~23)
天(月)(0~31,但是你需要考慮你月的天數)
月(0~11)
天(星期)(1~7 1=SUN 或 SUN,MON,TUE,WED,THU,FRI,SAT)
7.年份(1970-2099)
其中每個元素可以是一個值(如6),一個連續區間(9-12),一個間隔時間(8-18/4)(/表示每隔4小時),一個列表(1,3,5),通配符。由于"月份中的日期"和"星期中的日期"這兩個元素互斥的,必須要對其中一個設置?.
0 0 10,14,16 * * ? 每天上午10點,下午2點,4點
0 0/30 9-17 * * ? 朝九晚五工作時間內每半小時
0 0 12 ? * WED 表示每個星期三中午12點
"0 0 12 * * ?" 每天中午12點觸發
"0 15 10 ? * *" 每天上午10:15觸發
"0 15 10 * * ?" 每天上午10:15觸發
"0 15 10 * * ? *" 每天上午10:15觸發
"0 15 10 * * ? 2005" 2005年的每天上午10:15觸發
"0 * 14 * * ?" 在每天下午2點到下午2:59期間的每1分鐘觸發
"0 0/5 14 * * ?" 在每天下午2點到下午2:55期間的每5分鐘觸發
"0 0/5 14,18 * * ?" 在每天下午2點到2:55期間和下午6點到6:55期間的每5分鐘觸發
"0 0-5 14 * * ?" 在每天下午2點到下午2:05期間的每1分鐘觸發
"0 10,44 14 ? 3 WED" 每年三月的星期三的下午2:10和2:44觸發
"0 15 10 ? * MON-FRI" 周一至周五的上午10:15觸發
"0 15 10 15 * ?" 每月15日上午10:15觸發
"0 15 10 L * ?" 每月最后一日的上午10:15觸發
"0 15 10 ? * 6L" 每月的最后一個星期五上午10:15觸發
"0 15 10 ? * 6L 2002-2005" 2002年至2005年的每月的最后一個星期五上午10:15觸發
"0 15 10 ? * 6#3" 每月的第三個星期五上午10:15觸發
有些子表達式能包含一些范圍或列表
例如:子表達式(天(星期) )可以為 “MON-FRI”,“MON,WED,FRI”,“MON-WED,SAT”
“*”字符代表所有可能的值
因此,“*”在子表達式(月 )里表示每個月的含義,“*”在子表達式(天(星期) )表示星期的每一天
“/”字符用來指定數值的增量
例如:在子表達式(分鐘)里的“0/15”表示從第0分鐘開始,每15分鐘
在子表達式(分鐘)里的“3/20”表示從第3分鐘開始,每20分鐘(它和“3,23,43”)的含義一樣
“?”字符僅被用于天(月)和天(星期)兩個子表達式,表示不指定值
當2個子表達式其中之一被指定了值以后,為了避免沖突,需要將另一個子表達式的值設為“?”
“L” 字符僅被用于天(月)和天(星期)兩個子表達式,它是單詞“last”的縮寫
但是它在兩個子表達式里的含義是不同的。
在天(月)子表達式中,“L”表示一個月的最后一天
在天(星期)自表達式中,“L”表示一個星期的最后一天,也就是SAT
如果在“L”前有具體的內容,它就具有其他的含義了
例如:“6L”表示這個月的倒數第6天,“FRIL”表示這個月的最一個星期五
注意:在使用“L”參數時,不要指定列表或范圍,因為這會導致問題
| 字段 |
|
允許值 |
|
允許的特殊字符 |
秒 |
|
0-59 |
|
, - * / |
分 |
|
0-59 |
|
, - * / |
小時 |
|
0-23 |
|
, - * / |
日期 |
|
1-31 |
|
, - * ? / L W C |
月份 |
|
1-12 或者 JAN-DEC |
|
, - * / |
星期 |
|
1-7 或者 SUN-SAT |
|
, - * ? / L C # |
年(可選) |
|
留空, 1970-2099 |
|
, - * / |
這篇也是轉載,改了中間部分內。
在基于注解方式配置Spring
的配置文件中,你可能會見到<context:annotation-config/>這樣一條配置,他的作用是式地向 Spring
容器注冊
AutowiredAnnotationBeanPostProcessor、CommonAnnotationBeanPostProcessor、
PersistenceAnnotationBeanPostProcessor 以及 RequiredAnnotationBeanPostProcessor 這 4 個BeanPostProcessor。
注冊這4個 BeanPostProcessor的作用,就是為了你的系統能夠識別相應的注解。
例如:
如果你想使用@Autowired注解,那么就必須事先在 Spring 容器中聲明 AutowiredAnnotationBeanPostProcessor Bean。傳統聲明方式如下:
- <bean class="org.springframework.beans.factory.annotation. AutowiredAnnotationBeanPostProcessor "/>
如果想使用@ Resource 、@ PostConstruct、@ PreDestroy等注解就必須聲明CommonAnnotationBeanPostProcessor
如果想使用@PersistenceContext注解,就必須聲明PersistenceAnnotationBeanPostProcessor的Bean。
如果想使用 @Required的注解,就必須聲明RequiredAnnotationBeanPostProcessor的Bean。同樣,傳統的聲明方式如下:
- <bean class="org.springframework.beans.factory.annotation.RequiredAnnotationBeanPostProcessor"/>
一般來說,這些注解我們還是比較常用,尤其是Antowired的注解,在自動注入的時候更是經常使用,所以如果總是需要按照傳統的方式一條一條配置顯得有些繁瑣和沒有必要,于是spring給我們提供<context:annotation-config/>的簡化配置方式,自動幫你完成聲明。
不過,呵呵,我們使用注解一般都會配置掃描包路徑選項
- <context:component-scan base-package=”XX.XX”/>
該配置項其實也包含了自動注入上述processor的功能,因此當使用 <context:component-scan/> 后,就可以將 <context:annotation-config/> 移除了。
本文轉載:http://mushiqianmeng.blog.51cto.com/3970029/723880
有一段時間沒有關注spring了,spring2.5就蠻夠用的,spring3出來后一直沒怎么關注。
這幾天抽空關注一下。干咱這行的還是要緊跟時代變化啊。
下邊這些內容是轉載51cto的一篇文章。
1、項目結構與構建變化
解壓后的立即發現,Spring 3.0的項目結構已經發現了巨大變化:
1、Spring3采用多項目結構源碼組織,不再是以前的單一方式,共26個項目,差不多每個項目對于一個分發的jar包,不過有些項目是空的,或者是為了構建而設。
2、不再提供完整打包文件spring.jar,而是20個jar(或稱bundle),一方面應該也是向osgi靠攏。
Spring 3.0的readme中說道:
Note that this release does not contain a 'spring.jar' file anymore, in contrast to previous Spring generations. Furthermore, the jar file names follow bundle repository conventions now.
(51CTO編輯快譯:與之前的Spring版本相反,此次發布不再包括spring.jar文件了。新版本中的jar文件命名由bundle版本庫的規則所決定。)
3、采用Ivy為主構建方式,當然仍然有Maven,項目結構由Maven管理。另外沒有打包全部的依賴包了,整個下載包比2.5的小了近一半
4、Spring3已經完全采用Java5/6開發和編譯構建,因此應該是不再支持Java1.4及更早版本了
2、框架結構的變化
框架結構的架構圖也進一步演變了,不再是原來那個簡單的方塊圖:

Spring3架構圖
跟原來的相比,DAO、ORM、JEE等模塊被劃歸到了一起,成為“數據訪問/集成”部分,Web層突出了自己的MVC(Servlet)和Portlet,核心容器增加了表達式語言。另外,對測試的支持也放到了整個架構中來了。所以整個框架重新劃分成了五部分。
因此,典型的全應用場景也相應變化,并提示使用自家的Tomcat:

關于eclipse的一些應用,開發過程中用到了就隨手記下。
1.Web App Libraries and Eclipse Build Path
在eclipse下創建web項目,在build path下會對應包含Web App Libraries 動態加載項目下/WebContent/WEB-INF/lib所有的jar文件。
好處是在項目增加或刪除jar包時不用總是修改build path配置文件,從cvs同步代碼的時候保持這部分不變。
2.system library
有些jar在開發的時候要用到,但是部署的時候不用部署到服務器。
比如:jsp-api.jar,servelet.jar,這些文件在tomcat jboss 下已經包含,重復部署的話會引起錯誤。
我以前的做法是在anr build.xml文件中打包生成war時刪除對應的jar包。
剛發現還有這么一種用法,在eclipse添加system library把jar添加到該庫下就不會部署到服務器。
如圖:主要tomcat-jar 一定要設置成system library

關于在創業公司工作的話題,以前跟同事討論過,剛看到這么一篇,轉載一下。
有人在Quora問了這個問題:What startup could make me a millionaire in four years if I got hired as an emplyee today?
Symbolic Analytics的創始人Brandon Smietana在下面做了很長的回答,內容很精彩,不過請勿對號入座:
大多數創業公司的退出(exit),都是通過M&A(并購),而不是通過IPO(首次公開募股),現在大多數的M&A價格都低于3000萬美元,最典型的價格是1500萬美元,現在我們來假設一個最樂觀的退出案例,從其中的數據中算出,我作為創始人和CEO,能夠拿多少錢;從而計算出,你,作為一個員工可能賺得的利益。
(一)
假定案例
1)我拿到1000萬的投資。
2)投資人擁有公司50%的股權(樂觀估計)。
3)我將公司以3000萬的價格出售。
4)我擁有30%的外流通股(Outstanding Share) ,非常樂觀的估計。
投資人還擁有優先股,通過并購,他們首先把自己投入的錢收回來,然后再參與省下的股權收益分紅。
1)在3000萬的退出中,投資人首先拿回他們投入的1000萬,剩下2000萬。
2)然后,優先股股東吃掉省下2000萬的50%的利益分紅,于是他們拿走另外1000萬。
3)現在,整個脫售的現金只剩下1000萬,分享這份利益的關系者包括大眾股東,公司員工,創始人和管理團隊。
我,作為創始人和CEO,享有最多的普通股股權,價值這1000萬美元的大概600萬。省下的400萬利益歸屬其他所有的普通股股東(包括所有的公司員工)
最典型的早期員工,在利益分紅中能拿到的資產不足CEO的1/30,因此,一位非常重要的早期員工,能夠從脫售中取得20萬美元的利益。
現在,讓我設想得不那么樂觀,相對實際一點。70%進入A輪融資的創業者,除了工資,其他什么利益都無法從公司獲得。因此作為一名員工,
1)有70%的可能,如果你在A輪融資的時候加入創業公司,你的普通股是沒有價值的。
2)與A輪以前的早期員工相比,A輪以后的員工通過股權或者期權能拿到的利益要少很多。
3)在A輪融資以后,新員工能夠拿到的最好的股權大概在0.3%左右。
4)無論什么樣的員工,他們的股權都會在管理層更換或者新一輪融資中被稀釋。
(二)
如果我進入的公司是”下一個Facebook”呢?
硅谷在過去的十年里發生了驚天動地的變化。這些變化,同時作用并且影響著IT員工們能從公司那里獲取的利益。
如果你在1998年以前(包含1998年)加入了一家在將來很成功的創業公司,那你一定已經賺了很多錢。但是,如果你加入的是Facebook,你所能獲取的利益價值可能就無法跟前者媲美了。那么,那些加入“下一個Facebook“的哥們兒,希望可能就更小了,以下是原因:
谷歌的早期員工在加入時,谷歌的估值還很低。
1)谷歌的估值,一路從4000萬漲到了2000億。
2)那些最早加入谷歌的清潔工,從谷歌獲得價值1000美元的股權,在2008年也價值400萬美元。
3)一個獲得了5萬美元股權的工程師,他的股權在2008年價值1億美元。
4)谷歌的大廚也獲得了價值2800萬的股權。
有四點原因說明,谷歌的員工為何能夠金融上收益如此好:
1)他們在公司處于很低估值的時候獲得股票期權。
2)從A輪融資到現在,谷歌的估值漲了4000倍。
3)公司員工以人為的超低協議價格獲得購買期權(大概只相當于每股股價的1/10還要低),因為當時IRS(美國國稅局)的409(a)條款還不存在呢。
4)由于協議價格足夠低,因此員工在行權時,繳納的是資本利得稅15%(Capital Gain Tax),而不是收入稅50%(Income Tax treatment)。
當谷歌發行股票給他的員工時:
1)公司處于低估值階段,而非后來的頂峰估值階段。
2)那時,美國國稅局還沒有執行409(a)條款,409(a)條款明確規定了員工期權的估值。
在十年以前,創業公司都會以低于估值的協議價格發給員工期權,以吸引有識之士。員工因此有可能通過公司IPO而一夜致富,他們行權的協議價格大概之相當于估值價的1/10。
而到今天,這么做就是不合法的了。現在,公司的主管們,依據83(b)條款,依然有權通過限制性股票(restricted stock)獲得低估股票(undervalued stock);但是,現在獲得將理性期權(Incentive Stock Options)的員工,就必須遵循IRS的的409(a)條款。同時,現在的員工,在行權時更可能繳納50%的收入稅,而不是15%的資本利得稅。
隨著更高的早期估值,現在的員工已經不太有可能有現金能夠行權,而且也不太有可能繳納資本利得稅,一般都繳納收入稅。409(a)條款通過明確規定,也防止了員工行權價像十年前那么低。現在,一個創業公司的員工,如果行使價值200萬美元的ISO期權(國際標準期權),在繳納了加州稅或者德州稅之后,仍然可能面臨50%的收入稅。
一般情況下:創始人和主管們獲得的是依據83(b)條款的限制性股票(Restricted Stock),并且繳納的是15%的資本利得稅,員工則更可能時取得福利期權(Incentive Options), 稅率相對更高。
因此,作為一名員工,即便有一天你的公司被賣了,你也可能要繳納50%的收入稅。
200萬瞬間就只剩100萬,而現在,舊金山的房價是300萬。
(三)創業公司估值之于員工的影響
以前所有關于谷歌員工勝出的理由,現在都有可能不復存在了。
新的創業公司,如Facebook,獲得很高的早期估值,因此,早期員工能獲得的利益相比以前的創業公司,就少很多了。
更重要的是,現在只有越來越少的大型IPO,取而代之的是越來越多的小型M&A。
圖片一: 1992年 — 2009年 風險投資也IPO和M&A交易的比例
大多數公司并沒有谷歌和Facebook那樣做得很好。即便在Facebook,也只有一小部分員工積累財富。
Zuckerberg在Facebook的股權大致相當于Facebook所有非主管的員工股權的總和(24%vs30%).。前50個Facebook的非主管員工所獲得的股權,差不多相當于后面25000個員工的總和。
股權就是金字塔,越升一級,差俱就越大。
在一個以3000萬被并購的公司退出案例里(見上),一個很成功的M&A退出。公司的CEO也差不多只能賺600萬美元。
(四)創業領域與員工回報的關系
有很多創業公司扎根在大眾互聯網領域(Customer Internet Space), 但是這個領域的投資回報率也最低。就拿Facebook舉例(最成功的消費者互聯網公司之一),它從每一個月度活躍用戶那里只能產生3美元/年的利益。
很少的大眾互聯網公司能夠通過廣告獲得盈利,像Ad.ly, Digg, Myspace, Twitter,還有很多其他的公司都很難達到大規模盈利,即便是用戶量非常龐大。
一個大眾互聯網公司,如果每個月的活躍用戶數有50萬,依照Facebook的盈利推算,一年的盈利也只有150萬美元。因此,不要把大眾互聯網當做救命稻草。
現如今,B2B/SaaS模式,以及生物技術市場,仍然能夠在市場上攫取上億的資金,但是,很少有人能有能力和經驗在這個市場里把公司做起來。但是,在這領域,卻有比大眾互聯網市場更多的盈利機會。
最有盈利空間的市場,最難發現創業公司。特別是,金融領域每年攫取的利潤占全美公司利益的70%,但是,在硅谷卻很難發現金融創業公司,即便有,也基本是大眾金融服務。
Protip: 從數據和理論上看,如果你是A輪以后加入大眾互聯網公司的員工一枚,你的股權幾乎就不值錢了。
Hadoop最近很火,到處都能看到,查了一下資料大概先了解一下其運行原理。
google在05年公開了Map/Reduce論文,MapReduce在處理巨量數據方面有明顯優勢。
google公司一個技術大牛jefffery Dean提出的這個算法,隨后很多小牛紛紛實現了Mapreduce,Hadoop是它的java實現,MapReduce概念直接推動了云計算概念的火爆。
沒有優秀算法云是沒法搞的。
這篇文章對Map/Reduce原理講的很清楚。
http://www.chinacloud.cn/download/Tech/MapReduceOverview.pdf
這個是Apache關系Hadoop的文檔,安裝、開發示例都有。
http://hadoop.apache.org/common/docs/r0.19.2/cn/mapred_tutorial.html
因為一直在做企業信息化方面的開發,有必要了解一下相關的理論。
同事推薦的幾本書。
霍頓(F.W.Horton)的信息資源管理(IRM)理論
威廉。德雷爾的數據管理(DA)理論
詹姆斯馬丁的信息工程方法論(IEM)
看了之后有些吃驚,很多概念和理論都是上世紀80年代,還有60年代就提出的概念,做了這么久的開發居然沒聽說過,在規劃方面沒有一定的理論指導,都是些野路子方法。
還有許多平時用到的概念和方法找到了淵源,原來是這哥們或那哥們提出,老外的版權意識就是強對幾十年前提出的理論都會整理出哪個觀點是哪個人提出的。
不然很多方法一直覺得理所當然是那么用的,看過這些資料才知道理論提出的背景,除了這種理論解決哪些問題還有哪些方法,各有什么優缺點。
信息工程理論總結起來,就是以數據規劃為基礎,自定向下規劃。并提供了一系列的技術用于自下向上的設計方法。對企業信息化中比較重要的業務流程有很大的篇幅。
目前的收獲是,1.在系統規劃方面有了完整的理論指導;2.了解了規劃、分析、設計階段會有哪些技術,哪些已掌握的技術需要加強、哪些技術需要學習。
老外的書翻譯過來的在中文版看著費勁,找了本國內編譯出版的,寫得不錯。
信息工程與總體規劃概述。
本書討論計算機信息系統總體規劃的方法論,重點是總體數據規劃。
第一章是本文的綜述,目的是使讀者盡快了解信息工程概念和總體數據規劃方法的大意,因此是全書的提綱。
第二章到第四章是信息工程產生的背景和方法論的分析。這三章按三個主題展開:數據處理危機與轉折;信息工程的原理、方法與工具;信息工程與結構化方法。
第五章到第十章比較全面深入地介紹總體數據規劃的一整套方法,是本書的主體。編者根據近幾年參與中大型企業計算機信息系統總體規劃設計工作的實踐,深感探討先進科學的方法論的極端重要性,特別是總體數據規劃的內容、方法,以及與后續開發工作的銜接等問題,更是迫切需要解決的。為此,我們較全面地翻譯介紹了詹姆斯·馬丁所倡導的一整套方法,供有興趣的讀者參考,從而盡快形成適合我國國情的總體規劃方法論。
第一章
從需求分析開始的傳統生命周期開發方法論
數據結構和數據是相對穩定的,而數據的處理過程則是經常變化的。總體數據規劃方法。
軟件工程僅僅是關于計算機軟件的規范說明、設計和編制程序的學科,實際上信息工程的一個組成部分。
信息工程的基本原理和前提是:
1.數據位于數據處理的中心。
2.數據是穩定的,處理是多變的。數據類型是不變的。
只有建立的穩定的數據結構,才能是行政管理或者業務管理上的變化為計算機信息系統所適應,這正是面向數據系統所具有的靈活性,面向過程系統往往不能適應管理上的變化需求。
3.用戶必須真正參與開發工作。Design with,not design for.
第二章
信息工程的組成部分
自定向下規劃和自下向上設計方法論
重點分為三個部分:
企業模型、實體關系分析和數據模型的建立(即主題數據庫的規劃),以及數據分布規劃。
總體數據規劃簡介
四類數據庫環境
1.數據文件;
2.應用數據庫
3.主題數據庫
4.信息檢索系統
規劃方法
1.進行業務分析建立企業模型
2.進行實體分析建立主題數據庫模型
3.進行數據分布分析
第三章
信息工程概貌
1.關于全面開放的規劃
2.關于業務分析
3.關于數據分析,數據可以表達成與使用無關
4.關于自動化工具
信息工程的基本組成
1.企業模型,企業模型的開發是在戰略數據規劃期間進行的。
2.借助實體關系分析,建立信息資源規劃。這是自頂向下的數據類型分析,這些數據是必須被保存起來的,還要分析他們之間是如何聯系的。
3.數據模型的建立,產生詳細的數據庫邏輯設計
導致信息工程產生的一個重要認識,是組織中存在的數據可以描述成與這些數據如何使用無關的形式,而且數據需要建立起一定的結構。這一點較面向對象的思想很接近,可以把數據模型任務是數據對象。
信息工程的建設基礎
戰略的數據規劃工作
信息工程方法論
1.關于企業信息化戰略規劃的方法
2.關于信息系統設計實現的方法
3.關于自動化開發工具
第四章結構化方法與信息工程
信息工程是在進行戰略需求規劃,信息需求規劃,總體數據規劃和數據分布規劃的基礎上,使用結構化設計和結構化編程的方法。
結構化系統分析
數據流圖
結構化系統設計
信息工程是面向數據的方法,結構化方法是面向過程的方法。前者可以使用未來,后者只能使用過去和現在。
戰略需求規劃
戰略需求規劃是信息工程的基礎工作,不僅要對現有需求規劃,還要對未來需求規劃。
1.加強用戶之間的溝通合作。
2.加強高層領導者之間的溝通并為之提供支持。
3.提高資源需求預測和分配的準確性。
4.提供內部mis的可行點。
5.提出新穎而高質量的應用系統。
信息需求規劃
信息需求:
1.事務處理工作的管理信息需求;
2.高層領導者的管理信息需求;
3.企業發展和改革發展方面的信息需求;
傳統的軟件工程和數據庫技術盡管有分析設計方法,但缺乏自頂向下的規劃,不能適應大型復雜系統的建設。信息工程強調總體規劃,形成了一套自頂向下規劃與自下向上設計的完成的方法學,為大型復雜系統的建設提供了保障。
第五章總體數據規劃的組織
戰略規劃
1.戰略業務規劃
2.戰略信息技術規劃
3.戰略數據規劃
戰略數據規劃,即總體數據規劃是信息工程規劃工作的核心和基礎,需要研究它的組織方法。
戰略規劃的目的是使信息系統的各部分能共同工作。
對戰略規劃的詳細程度要有恰當的理解。
第六章 企業模型
..........................
今天看了五章的內容,休息一下。
忙完手頭工作繼續學習,2012-2-28
總體數據規劃的第一步是進行業務分析,建立企業模型。(編者按:目前電信行業都已經建立起了完善的企業模型,其他行業還沒看到)
企業模型是對企業結構和業務活動 本質的、概況的認識。
用職能區域--業務過程--業務活動 這樣的層次結構來描述。
1.研制一個表示企業各職能區域的模型;
2.擴展上述模型,使它能表現企業的各項業務過程;
3.繼續擴展上述模型,使它能夠表現企業的各項業務活動。
依靠企業高層,分析企業的現行業務和長遠目標,按照企業內部的各種業務的邏輯關系,將他們劃分為不同的只能區域,弄清各職能區域包括的全部業務過程,再將各個業務過程細分為一些業務活動。
建立分析企業模型的過程,是對現行業務系統再認識的過程。
職能區域
職能范圍、業務范圍,是指一些主要的業務活動區域,如銷售、市場、財務、認識、生產。
職能模型,職能區域圖表
業務過程
企業模型的二級結構是業務過程的識別、命名、定義。這項工作主要由分析人員來完成。
1.業務過程與組織結構
2.識別業務過程的參考模式
產品、服務和資源四階段生命周期
計劃,獲得,保管,處置(編者按:原書有一張圖表,這里就不列出來了),模式的每一階段都有一些業務過程的類型。
3.業務過程與負責人
4.經驗
業務活動
每個業務過程中都存在一定數量的業務活動
業務活動分析
1.功能分解的程度
2.凝聚性活動,1.產生清晰可識別的結果,2.有清楚的邊界,3.是一個執行單元,4.自封閉的,獨立于其他活動。
3.冗余活動和功能組合,
企業模型的建立過程
可以理解為邏輯模型
企業模型的特點
完整性、適用性、永久性
關鍵成功因素
3~6個決定成功與否的因素
1.關鍵成功因素的確定
關鍵成功因素應該成為最高層管理人員管理控制企業系統的基礎,對一個行業來講關鍵成功因素差不多是相同的。
如食品公司:廣告效果,貨物分發,產品革新
2.關鍵成功因素的審查
第七章主題數據庫
獨立于應用的數據
數據庫環境的原則
1.企業的數據應該得到直接管理,與使用的職能分開;
2.數據描述不應由使用數據的應用包含,而應當由獨立的數據管理員設計;
3.數據應該獨立于現有機器資源;
4.使用統一的工具和設施管理資源;
5.有適當的安全和保密控制;
6.高層管理人員要參與數據庫的總體規劃和決策。
面向過程的系統分析方法
面向數據的系統分析方法
主題數據庫與組織內各類人、事、物相關,而不是與傳統的應用相關。
總的來說這部分沒什么干貨,就是對前面方法論的細化和再次說明。
這本書側重于方法論和理論概念。在規劃部分有具體的指導,在具體分析和設計技術上著墨不多。
第八章實體活動分析
第九章數據分布規劃
第十章規劃與開發建議
這兩天比較忙,后邊章先顧不上看了。
第八章和第九章應該跟軟件工程里的內容是一致的,原來項目開發時經常要用到。第十章討論BSP方法,要了解一下。